
В предыдущих сериях
Сказка про Method as Parameter #dotnet #methods #gc
Сказка про Guid.NewGuid() #os_specific #dotnet #microoptimization
Иногда приходится разбираться, почему .NET приложение работает "плохо". Не так, как мы ожидали. Тупит, медленно работает, зависает, запросы «не исполняются», утекает память или потребляется слишком много CPU.
Есть множество способов, как разбираться в таких ситуациях. Сегодня мы немного обсудим, что это за способы. Когда и какой способ нужно использовать. И более детально рассмотрим один из инструментов: PerfView.
Художественное отступление, шутка на текущую тему. Для того, чтобы узнать самое интересное, читать текст под катом совершенно не обязательно.
Утро не задалось с самого начала. За окном стоял смог, моросил мелкий противный дождь. Айдел Плюшкин сидел на своём большом кресле и плевался, что кофе снова горчит. Сетовал на смог, из-за которого у него обязательно должна была разболеться голова.
— Разгильдяи, лентяи, — ворчал он себе под нос, — ходят туда сюда и ничего не делают!
Айдел Плюшкин всегда был недоволен работой своего предприятия. Ему казалось, что все работают слишком медленно. Что все заняты чем угодно, только не полезной работой.
В очередной раз пролистав журнал расходов и доходов, Айдел наконец-то решил нанять инспектора. Чтобы тот изучил эффективность работы его предприятия, оценил рабочих. И обязательно рассказал, кто ленится больше всего и кого нужно уволить, а кого заставить работать ещё больше! Среди объявлений первым ему попался Перформанс Вьюевич. С ним и договорились.
Весь день инспектор бегал по предприятию с большущим блокнотом и что-то в него писал. Его зоркие глазки метались из стороны в сторону, ничего не упуская. Кто сделал какой шаг и в какую сторону. Кто что сказал, кто какую работу выполнил. К концу дня у Айдела на столе лежала огромная стопка бумаги, исписанная разными цифрами, разрисованная разными графиками.
— Общая статистика. Сидеть на рабочем месте, 42%. Сидеть на кухне, 18%. Идти по коридору, 13%. Разговаривать в переговорке, 12%… хм… , — Плюшкин читал отчеты. — Ага, Аллочка… Провела на рабочем месте 69% времени. Из них заполняла недельный отчет 58%, смотрела котиков 11%. Сидела на кухне 22% времени. Из них пила кофе 10%, обедала 8%, ещё 4% не распознано…
— Это что такое? — возмутился Плюшкин. — Дак что мне делать-то? Кого мне уволить, кого ещё нанять? Кому выговор сделать и заставить больше работать? Что мне делать с этим вашим отчетом?
— Вы просили инспекцию, вот вам инспекция. Тут всё подробно расписано. Кто что делал, когда. Даже визуализация есть, сортировка по процентам, — Перформанс Вьюевич вежливо улыбался.
— И что, мне теперь самому изучать это всё?!
— Как вам угодно. Я же не знаю и не могу знать, чем должно заниматься ваше предприятие. Кофе оно должно потреблять, или ходить по коридорам. Быть может отчеты заполнять, или просматривать картинки в интернете. Моё дело простое, подробно и понятно показать, что да как у вас происходит. А вот что вы с этой информацией делать будете, это уже ваша забота.
Способы анализа эффективности работы приложения
Фундаментально их можно разделить на два типа. Снепшоты (дампы) и трейсы.
Снепшоты (дампы)
Снепшот — это «копия», или замороженное состояние процесса (или ОС) или его части в какой-то момент времени. Получив такой артефакт, можно пристально изучать, а что же такое было в приложении в этот конкретный момент времени. Важно понимать, что такой артефакт не показывает никакой динамики, он статичен — в каком виде вы застали приложение в момент вызова команды снятия снепшота, только то вы и увидите.
Самый распространённый и, наверное, единственный способ снятия снепшота приложения — дампы. Для .NET приложений это .NET дампы. Есть Java-дампы, Go-дампы, дампы всей ОС, и т.д.
Какую информацию можно извлечь из дампа .NET приложения?
Состояние всех потоков. Какой стектрейс у каждого треда, в каком он состоянии.
Всю память и все .NET объекты. Можно смотреть как на статистику (кого и сколько), так и на контент и дерево ссылок. Например, можно заглянуть прямо в контент json'а из «того самого запроса» и изучить его. Или посмотреть, какой заголовок был у вон того http-запроса. Или посмотреть, а кто держит ссылку на миллион вон тех объектов.
Какой поток держит определённую критическую секцию (лок), а какие потоки ожидают её освобождения.
Посмотреть на ASM-код, в который превратилось ваше приложение после работы jit'а. И более того, увидеть, на какой «строчке» стоит каждый поток. А иногда можно даже подебажить по нему, расставляя brake-point'ы!
Изучать unmanaged-память.
Трейсы
Трейсы — это запись каких-то эвентов, возникающих в процессе (или даже в ОС) в течение всего времени записи этого трейса. В дальнейшем различные инструменты умеют читать и анализировать эту ленту событий, визуализируя её понятным способом, предоставляя функции для анализа и агрегации. Основная ценность таких инструментов — возможность изучать работу приложения в динамике.
Есть несколько достаточно популярных и широко известных инструментов.
Wireshark позволяет записывать информацию о сетевых вызовах в ОС. Дамп «сети» в определённый момент времени малополезен — вы увидите лишь часть информации. Текущий TCP пакет, а не все. Только лишь http запрос, или только http ответ. А в трейсе можно увидеть всё, в течение всего времени запроса, в том числе какой-нибудь UDP с DNS-резолвом. Есть куча аналогичных консольных инструментов для Linux.
Для Windows (любых приложений) есть очень мощный инструмент: WPR (windows performance recorder) и WPA (windows performance analyzer). Это инструменты для сбора и анализа трейсов windows-приложений.
Для .NET приложений — есть некоторый зоопарк.
Есть консольный инструмент для сбора трейса на любой ОС, dotnet-команда:
dotnet trace.Есть dottrace от jetbrains, который умеет анализировать результат
dotnet traceс любой ОС. В том числе умеет сам собирать трейс с любой ОС своим собственным консольным инструментом и, естественно, анализировать его в своём собственном UI.Есть PerfView, им можно собирать трейс только на Windows, а анализировать можно как свои собственные трейсы, так и артефакты команды
dotnet traceс любой ОС.
Для других языков есть Go-трейсы, Java-трейсы, … Опустим трейсы WPR и Wireshark, как и многие другие, и поговорим только о трейсах непосредственно .NET приложений. Какую информацию можно извлечь из трейса .NET приложения?
Какие стеки и какие функции, сколько раз и как долго (или на сколько чаще и на сколько дольше остальных) находились на вершине стека в течение всего времени трейса.
Какие объекты, в каком количестве, какого размера, из каких функций и стеков создавались (или на сколько чаще остальных создавались) в течение всего времени трейса.
Когда и какие объекты собирались GC. В том числе и времена работы GC-тредов. Агрегированная статистика о GC за всё время трейса.
Прочие эвенты: Exceptions, ThreadStart, Jit, Custom (да, в теории, можно даже самому создавать из кода свои собственные эвенты!)
В чем различие Trace и Dump
В трейсе (по крайней мере в доступных на сегодняшний день) вы не сможете покопаться в контенте каждого .NET объекта, ведь они не собираются все и целиком (иначе трейс был бы невероятно огромен). У вас не будет точного описания процесса «в каждый момент времени», чтобы смотреть на состояния потоков. Зато один такой «момент времени» полностью запечатлён в дампе, со всем контентом каждого объекта и состоянием каждого потока.
Стоит рассмотреть на примерах, когда полезен один инструмент, но малополезен другой.
Если у вас раз в минуту утекает один объект, то даже сняв огроменный трейс за 10 минут, вы этого не увидите. 10 созданных объектов утонут в информации о миллионе других эвентов, возникших за эти 10 минут. А если снять дамп через пару суток после старта процесса, можно будет увидеть тысячи подозрительных утёкших объектов.
Если у вас приложение потребляет очень много CPU, вы можете посмотреть на дамп и увидеть там небольшое число совершенно различных тредов. Например, вам просто не повезло и в момент снятия дампа виновная функция не исполнялась. Или вы не сможете без глубокого анализа кода выяснить, а какая из этих функций чаще и дольше всех работает. Зато в трейсе можно увидеть, что за какое-то длительное время определённая функция вызывалась намного чаще остальных. Была замечена на вершинах стеков, то есть в исполнении, чаще остальных.
Если у вас приложение страдает от длительных GC пауз, вы можете сделать дамп и не увидеть там ничего подозрительного, всех объектов по чуть-чуть, ничего выделяющегося. Зато можно снять трейс и увидеть, что какой-нибудь объект создаётся очень часто, просто достаточно быстро собирается GC, и потому в дампе вы не застанете их в большом количестве. И наоборот, страдать от длительных GC пауз можно и от большого числа долгоживущих объектов, которые редко создаются, но очень долго живут в процессе, и заметить которые поможет только дамп.
Если ваше приложение просто зависло и ничего не делает, не обрабатывает запросы, или перестали обновляться настройки в фоновом потоке, в трейсе вы ничего и не увидите. Ничего же не происходит, всё зависло, никаких эвентов нет. Зато в дампе можно увидеть, живы ли вообще эти потоки, в каком состоянии они застряли, на каких стеках. Можно будет изучить критические секции и состояния каких-нибудь булевых флажков.
Когда приступать к анализу
Это немаловажный вопрос. Универсального ответа на него не существует, но можно дать некоторые рекомендации. Важно учитывать, что часть инструментов может аффектить производительность приложений, но в среднем, если приложения небольшие, этот эффект почти незаметен.
«Плохая ситуация» случается редко и не удаётся воспроизвести в тестовых окружениях. Как только она случилась, можно бежать и пытаться успеть проанализировать её специализированными инструментами. Иначе другого случая может не представиться и вы так и не выясните причину, факап снова когда-нибудь случится.
У вас кластер равнозначных реплик и в данный момент «плохая» только какая-то их часть, которую не жалко потерять (как если бы померла железка). Можно смело идти анализировать приложение.
«Плохая ситуация» не устраняется сама собой и вы всё равно планируете перезапускать приложение, контейнер или весь сервер. Лучше потратить ещё минутку и получить артефакт(ы), который может пролить свет на природу проблемы, чтобы не допустить её в дальнейшем.
В рамках «работы над техдолгом», для оценки эффективности работы приложения. Например, такое может быть актуально для крупных сервисов с множеством реплик. Если у вас 10 реплик и вы найдёте кусок кода, который потребляет 10% ресурсов, и сможете его оптимизировать до нуля, то вам будет нужно уже не 10, а 9 реплик. А ещё, так можно предупреждать заранее те проблемы, которые могут вскрыться при дальнейшем росте нагрузки.
Про безопасность
В дампах и трейсах содержится чувствительная информация!
Пользовательские запросы с перс-данными;
Пользовательские ключи и пароли;
Код и прочая информация о системе и окружении.
Поэтому такие артефакты нужно хранить только в безопасных местах. Никаких открытых файловых шар, даже «ненадолго, только поделиться с соседом». Дампы и трейсы желательно удалять после использования. И ни в коем случае не показывать наружу компании.
Также важно и полезно подготовить все инструменты заранее. Чтобы в час X не искать, а где же вон тот инструмент. Например, все инструменты сбора таких артефактов полезно установить в базовые образы. Заготовить проверенные и настоящие инструменты для работы, раскладывать их на сервера при деплоях. И не качайте, не тащите на прод что попало, что вы скачали впопыхах во время факапа, это очень опасно!
PerfView
Сегодня более детально мы остановимся на этом инструменте. Просто потому, что мне он очень нравится.
PerfView — инструмент сбора и анализа трейсов. С помощью PerfView можно собирать трейс только на Windows. А анализировать можно как его собственные артефакты, так и артефакты команды dotnet trace с любой ОС.
В чем я вижу плюсы и удобства этого инструмента:
Легковесность. Он весит 17MB, при своей работе потребляет очень мало ресурсов. Его легко скачать и унести на любую машину, им же снять и проанализировать на месте трейс.
Бесплатность. Не нужны никакие лицензии.
Скорость и понятность: он летает, он простой и понятный.
Он мощный. В нём реально провести даже не тривиальные исследования. Где-то не так удобно, как в dottrace, а где-то даже наоборот проще.
В минусы можно отнести:
Отсутствие каких-то интеллектуальных анализов и сравнений двух трейсов, которые можно встретить в dottrace. PerfView просто визуализирует собранную информацию по выбранными фильтрам и сортирует.
Визуализация тоже отстает от dottrace, никаких красивых кнопок, менюшек и плавных плашечек. Только суровый инженерный дизайн. Но иногда простота даже лучше, чем перегруженность информации.
Проанализируем что-нибудь
Потренируемся на чем-нибудь простом и тривиальном. Напишем какое-нибудь приложение и посмотрим, что про него покажет PerfView.
Тренируемся на кошках
using System;
namespace PerfViewExample
{
class Program
{
private static readonly Random random = new Random();
private static void Main(string[] args)
{
DoSorting(10_000);
}
private static void DoSorting(int size)
{
while (true)
{
var array = CreateNewArray(size);
Array.Sort(array);
}
}
private static int[] CreateNewArray(int size)
{
var arr = new int[size];
for (var i = 0; i < size; i++)
arr[i] = random.Next();
return arr;
}
}
}Наше приложение будет while true создавать массив и сортировать его. Запустим наше приложение, узнаем, какой у него pid. В моём случае pid равен 8552.
Скачиваем PerfView с официального сайта MS. Открываем его, из меню жмём Collect -> Collect. Вводим нужный pid и выбираем дополнительные опции: .NET Calls и .NET Alloc, чтобы увидеть более точную картину по вызываемым функциям и собрать информацию о всех вызванных new в программе.
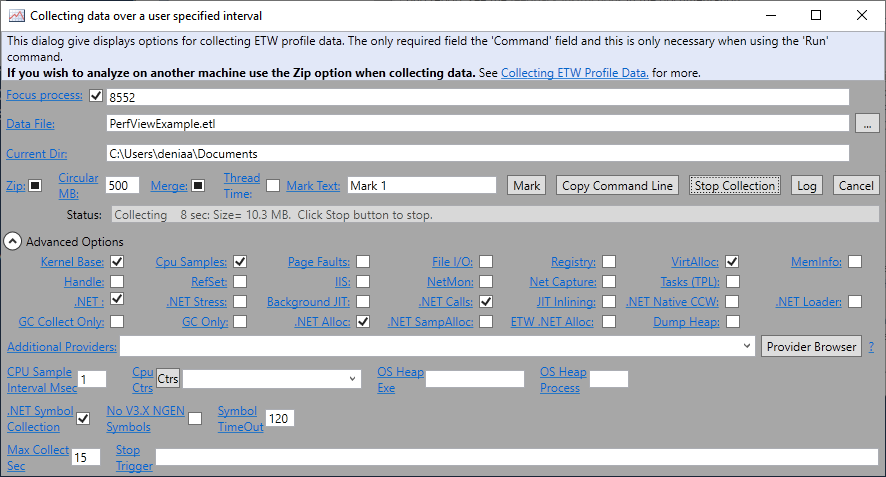
Собрать трейс можно и иным способом, который подойдёт и для Linux. Для этого нужно установить dotnet trace и вызвать команду dotnet trace collect.
dotnet trace collect -p 8552По умолчанию dotnet trace собирает только информацию о CPU-работе. Как собрать информацию про .NET объекты и многое другое можете ознакомиться в документации на официальном сайте. Для этого там есть специальные profile.
На практике лично я предпочитаю собирать трейс с помощью инструмента dotnet trace. Это более родной для дотнета метод, его проще иметь в актуальном состоянии, он консольный и метод работы с ним одинаковый и на Linux и на Windows.
Откроем тем же PerfView собранный трейс, зяглянем в коллекцию CPU Stacks. Если трейс был записан с помощью dotnet trace, коллекция будет называться ThreadTime. Именования сущностей, группировки и внешний вид всего происходящего внутри будут совсем чуть-чуть различаться в зависимости от того, каким инструментом был собран трейс. Но смысл у них абсолютно одинаковый.
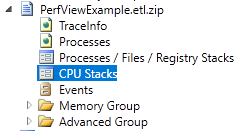
Выбрав нужный процесс (в списке будут видны все, существовавшие на момент записи трейса, а вот не пустая информация будет только в том, чей pid мы указали), перед нами откроется вот такое окошко:
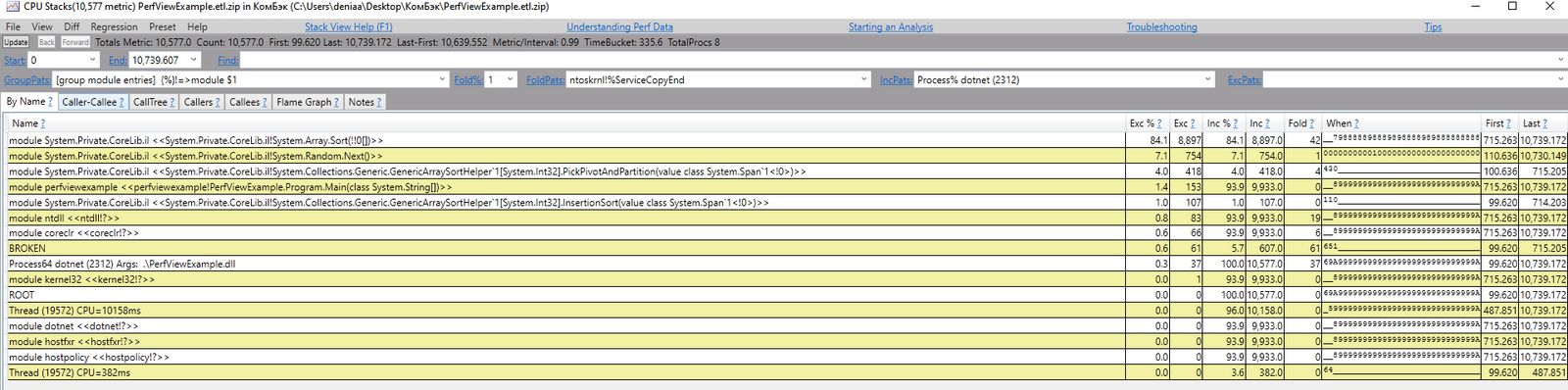
Уже на нём видны знакомые нам имена методов: Array.Sort, Random.Next, и другие. А также проценты — сколько процентов времени было проведено в этих функциях.
Можно перейти на вкладку CallTree и развернуть всю цепочку вызовов, включая Main и наши Array.Sort, в виде дерева. По ходу погружения внутрь дерева (проставлением галочки на узле, внутрь которого хотим провалится), проценты снижаются — они показывают, какой процент времени занял этот узел и все под ним.
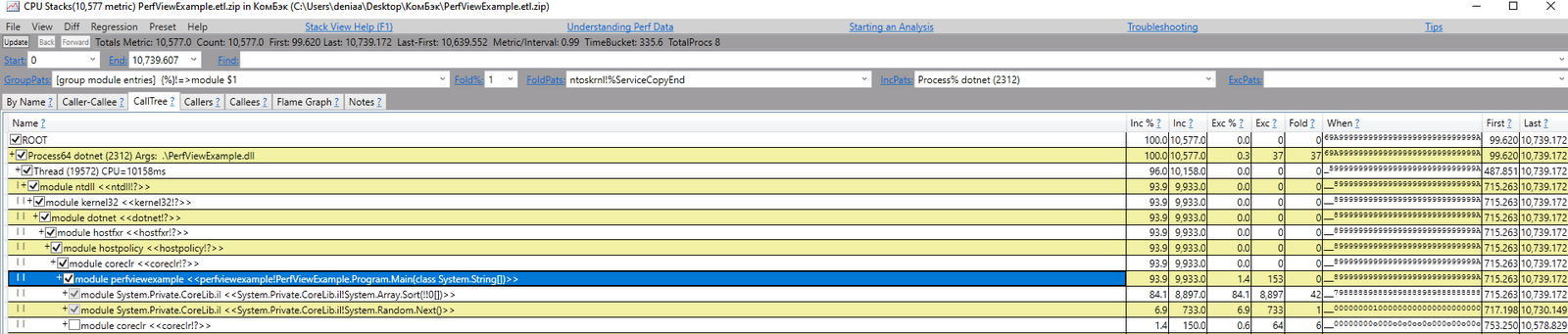
Так, например, видно, что 93% времени работы программы во время записи трейса было потрачено внутри метода Main. Причем, 84.1% времени были именно внутри Array.Sort, а 6.9% времени в Random.Next.
Но не всегда удобно рассматривать дерево от самого корня (например в случаях, когда много асинхронного кода и корнями будут выступать потоки тредпула). Не просто так на первой страничке, на вкладке By Name, нам уже заботливо показали топ функций. Если дважды кликнуть по интересующей функции, можно увидеть «дерево наоборот»: откуда эту функцию вызывали, и по какой ветке чаще всего. В нашем случае мы увидим лишь одну ветку (такой код мы написали). Вот что будет, если дважды кликнуть по Array.Sort с первой вкладки:
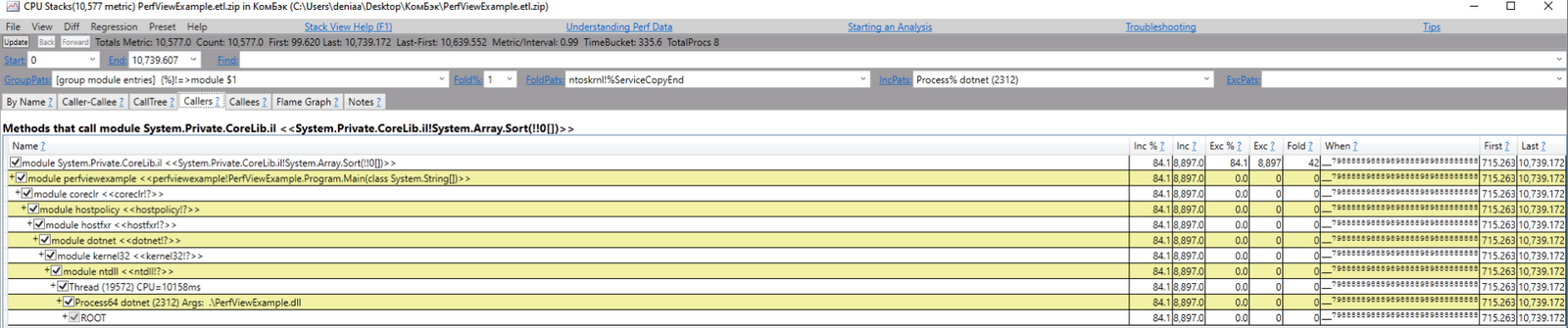
Такими нехитрыми манипуляциями можно изучать любой процесс, любую функцию. Изучать, на что тратится больше всего времени внутри приложения. Конкретно здесь мы четко увидели, что больше всего времени потратилось на сортировку (84%), а на заполнение массива (вызовы Random.Next) всего ~7%.
Кстати, если присмотреться, то в трейсе видно, будто Array.Sort вызывался прямо из Main. Хотя в коде между ними присутствует вызов метода DoSorting. Так случилось из-за оптимизаций при компиляции. Компилятор или джиттер заинлайнили метод, устранив лишний вызов. И на трейсе мы видим то, как работает уже соптимизированная программа. Это стоит иметь в виду — в трейсе не всегда видно ровно то, что написано в коде.
Возьмём что-нибудь настоящее
Такие простые и учебные трейсы не дают никакого представления о том, как выглядят трейсы настоящих, нагруженных и сложных приложений. Давайте убьём двух зайцев. Посмотрим на трейс большого приложения, а заодно попробуем посмотреть на другую коллекцию. Не на CPU, а на .NET аллокации.
У меня есть информация (по графикам и логам), что в приложении Zebra.Master есть некоторый фон блокирующих GC. Пока что они случаются не часто и не так длительно, чтобы серьезно повлиять на пользователей. И пока это не стало серьезной проблемой, попробуем понять, из-за чего же у нас такие GC. Весь разбор трейса дальше — нисколько не подготовка. Прямо перед написанием этого текста я снял трейс с настоящего приложения (компонента кластера Zebra, это наше самописное хранилище) и сейчас впервые на него смотрю.
Чтобы изучить, каких объектов создаётся больше всего, нужно открыть коллекцию GC Heap Alloc. Остальные вы можете изучить сами, прочитав в документации, что они в себе содержат.

Перед нами откроется уже знакомое окно. Только вместо имен функций у нас имена типов. Я буду аккуратен и приложу скрины трейса с реального приложения. В общем случае так лучше не делать, но в этих скринах не будет ничего криминального, кроме имён типов каких-то объектов и малозначимых методов.

Наше внимание сразу должна была привлечь первая строчка с большими процентами — LargeObject. Это те объекты, которые очень большие, и потому попадают сразу в LOH, а не в Gen0. И известно, что объекты в LOH очень негативно влияют на GC.
Остановимся ещё на смысле столбцов. Если с процентами (Exc %) всё понятно, то там есть и другие. Особенно интересны нам столбцы Exc и Exc Ct.
Exc — это то, сколько байт было аллоцировано под все объекты в этой строчке.
Exc Ct — это то, сколько раз был вызван new этих объектов.
То есть, если вызвать два раза new long[10], то мы увидим значения Exc Ct = 2, а Exc ~= 2 (раза) * (10 (размер массива) * 8 (размер long'а) + небольшой константный оверхед на заголовок массива).
Что ещё подозрительного, кроме LargeObject, сразу видно в этом трейсе? То, что аж 9.1% созданных объектов — это System.Func:

Это очень плохо. Зачем постоянно создавать какую-то функцию? Почти наверняка её можно создать всего один раз и правильно закешировать. Если это удастся, мы на 9.1% снизим количество генерируемого мусора в процессе, что должно положительно сказаться на длительностях GC-пауз.
Но больше всего нас интересует LargeObject. Давайте сделаем на ней дабл-клик и поисследуем, что там внутри:
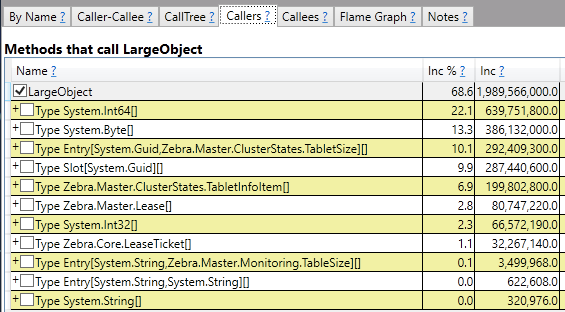
Эта строчка распалась на вот такие типы. Будем исследовать, откуда же они взялись. Не смотря на то, что эти типы из LargeObject, дальнейшая работа с ними никак не будет отличаться от работы с типами не из LargeObject.
Посмотрим, откуда создаются большие массивы long'ов (Int64[]). Если проставить галочку в квадратике перед этим типом, раскроется дерево, откуда этот тип создавали. Те методы, где этот new вызывали.
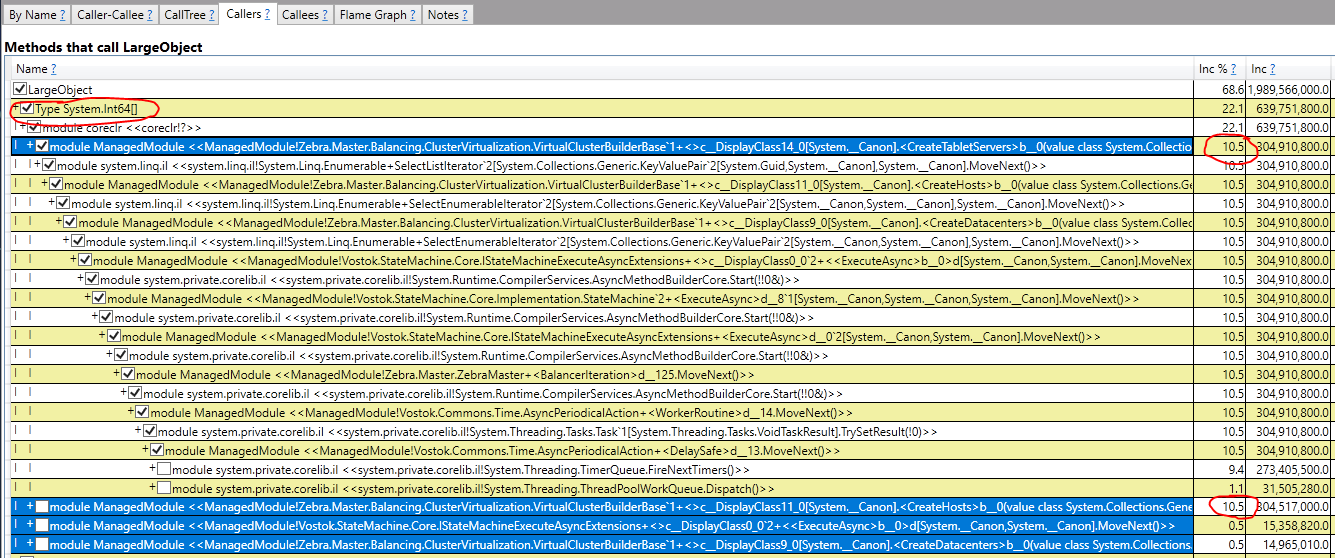
В нашем случае видно, что этот тип создавали из 4х функций. Причем из первых двух чаще всего: по 10.5% из 22.1%, то есть почти все. У первой функции я развернул стек ещё глубже.
Получается, у нас есть всё что нужно. Мы знаем, какие типы создавались в процессе чаще и больше всех (если проанализируем аналогичным образом все остальные типы из топа). Мы знаем, из каких функций и даже из каких стеков их создавали. Дальше мы можем сформулировать гипотезу: если мы избавимся совсем или хотя бы просто снизим количество мусора, который мы только что обнаружили, это должно помочь GarbageCollector'у и паузы от его работы будут не такими частыми и не такими длительными.
Как именно оптимизировать эти места трейс нам не подскажет. Он может лишь показать на то, что вероятнее всего является проблемой здесь и сейчас. Поэтому в рамках этой статьи мы не будем смотреть в код в найденные функции и пытаться понять, а как же нам избавиться от этих массивов совсем, или сделать размеры массивов поменьше, или пореже их создавать. Это уже не касается темы данной статьи.
Посмотрим на какую-нибудь экзотику
Только лишь для демонстрации возможностей трейсов и PerfView, разберём один интересный случай. Однажды, во время нагрузочного тестирования новой фичи в одном приложении, мы столкнулись с ThreadPool starvation'ом. В процессе кончился тредпул, CPU улетело в 100%. Приложение практически перестало адекватно работать. Мы повторили такой нагрузочный тест и сняли в момент проблемы трейс.
Важно отметить, что для того, чтобы понять, что за потоки забили весь тредпул, нужно снять дамп, а не трейс. В трейсе мы скорее всего не увидим, что за потоки уже созданы и где они застряли. Ведь в трейсе приложения, которое в состоянии 100% CPU и забитого тредупла, мы увидим лишь агонии процесса, его попытки поделать что-то полезное.
Мы рассматриваем этот трейс сейчас просто из интереса, чтобы посмотреть на хитрые случаи.
Я продемонстрирую возможность наблюдать в трейсах все возможные эвенты, произошедшие в приложении. Не только CPU работу или аллокации объектов. Для этого воспользуемся коллекцией Any Stacks. В трейсах, снятых с помощью dotnet trace, она будет прямо в корне трейс-файла. В трейсах, снятых с помощью PerfView, она будет в папке Advanced Group. В моём случае это был dotnet trace, снятый с Linux-машины с .NET 6.
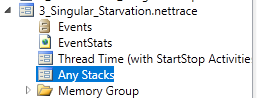
Тут мы увидим знакомую картинку, но с интересными именами. Я сразу размечу цветами некоторые группы, и потом дам им объяснения.
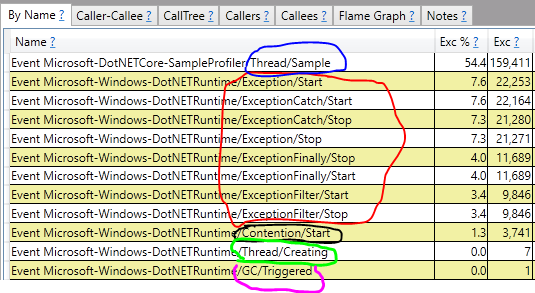
CPU-эвенты
Синим цветом выделены эвенты Thread/Sample. Это те самые эвенты, которые отвечают за CPU работу — эвенты о функциях и стеках, которые сейчас исполняются. Если сделать по ним дабл-клик, то мы провалимся в окошко, очень похожее на то, что мы видели про CPU работу. Это ровно оно и есть. Мы увидим методы, проценты, сколько времени они работали, и стеки, откуда их вызывали. В данном случае дольше всего работали методы из тредпула (у нас ведь ThreadPool starvation, не удивительно), но можно увидеть и всякое другое, например метод Log или даже конструкторы строчек.

Кстати, продемонстрирую ещё одну возможность PerfView, которая часто бывает полезна. Вот мешают нам, например, всякие методы с ожиданиями, вроде Task.Delay, Semaphore.Wait. Мы хотим изучать трейс, исключив их из процентов и из выборки, чтобы чище оценить всё остальное. Кликаем по ненужной строчке правой кнопкой, жмём Exclude Item, и всё пересчитывается уже без этой строки:

Exceptions
Красным цветом выделены различные эвенты про эксепшны. Где они возникали, кто их перехватывал и как обрабатывал.
Critical Sections
Очень интересные эвенты выделены чёрным цветом. Эти эвенты возникают тогда, когда кто-то пытается захватить критическую секцию (lock), а она занята. Когда таких ситуаций много — это плохо. Обычно это признак того, что у вас высокая конкуренция на один лок и его пропускной способности не хватает. А активная борьба за лок — дорогостоящее занятие. В нашем случае таких эвентов было 3095 за всё время трейса:
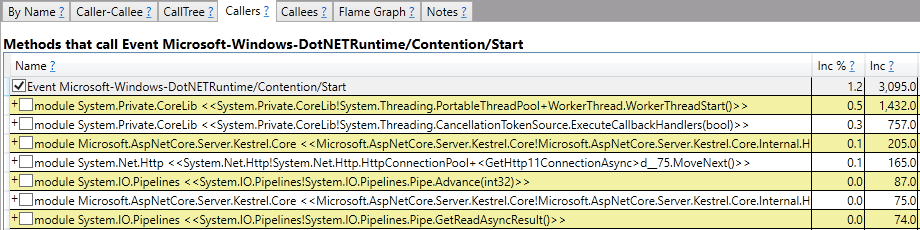
Причем почти все — внутри работы ThreadPool и CancellationTokenSource. Пока рано предполагать, что именно они являются причиной нашей плохой ситуации. Быть может, это следствие. Но лок действительно можно найти в коде PortableThreadPool_WorkerThread в .NET 6 (в итоге мы попадём вот на эту строчку).
Threads
Зелёным цветом выделены эвенты про треды. В данном случае мы видим эвенты о создании новых тредов.
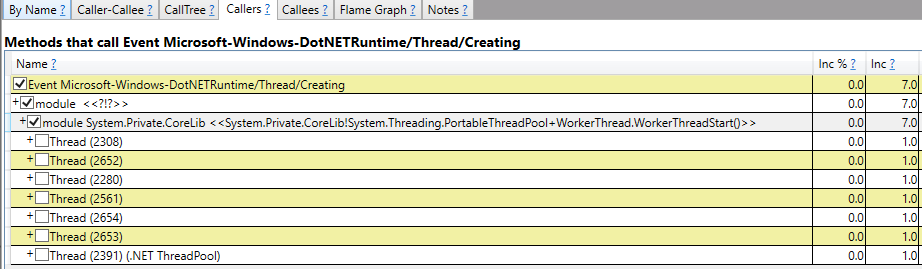
И это логично. У нас ThreadPool starvation — не хватает WorkerThread'ов для выполнения работы, поскольку остальные заблокированы. И, как видно в трейсе, именно тредпул создавал новые треды. За всё время сбора трейса тредпул был вынужден создать 7 новых WorkerThread'ов.
GC
Розовым цветом выделены эвенты о GC. В наш трейс попал только один — тригер GC.
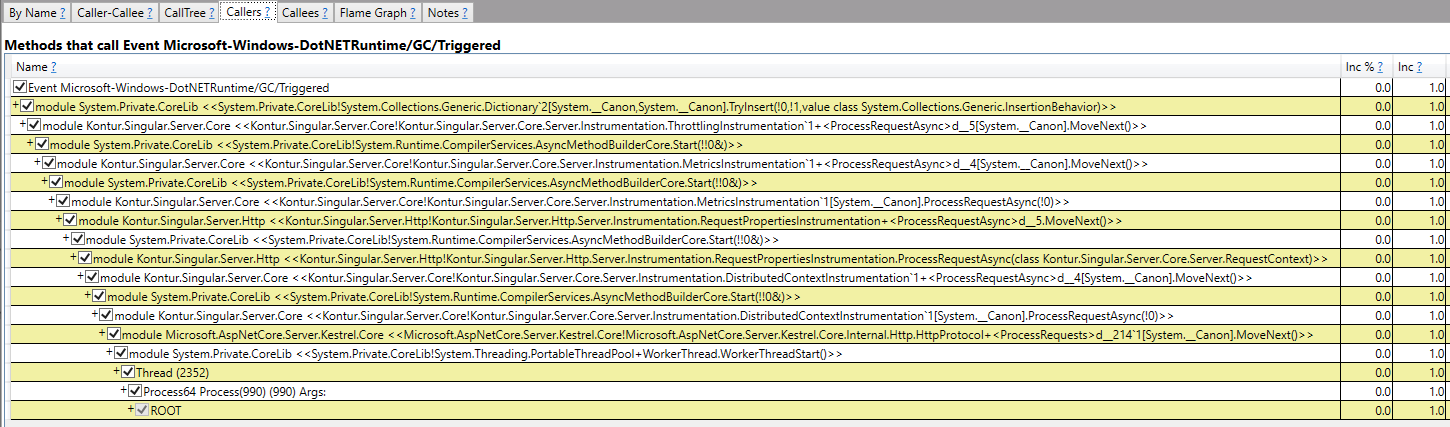
Методу TryInsert в словаре не повезло. Быть может, он был вынужден сделать resize и попал под какие-нибудь эвристики, что надо передать GC, что пора что-нибудь собрать.
Вместо вывода
Мы совсем кратко и обзорно прошлись по самым верхам практик и инструментов анализа эффективности работы приложений. Затем детальнее посмотрели на один из инструментов сбора и анализа .NET трейсов — PerfView.
Как вы могли заметить, трейсы не говорят вам, как нужно поправить код. Они даже не показывают, в чем проблема. Они не могут вам сказать, что есть причина, а что следствие. Более того, даже не всегда можно понять, что именно вы видите в трейсе.
Трейсы всего лишь содержат в себе информацию о том, что происходило в приложении в течение всего времени снятия трейса. А инструменты их анализа пытаются как-то визуализировать собранную информацию, подать её в понятном для человека виде. Строить какие-то гипотезы, сверять их с кодом, проводить мысленные эксперименты, вносить изменения в код и проверять «помогло ли» всё равно придётся человеку.
Работа с трейсами — это не какое-то уникальное знание, навык или запрещённая магия. Это просто ремесло. Несложная, монотонная работа. Требующая терпения, внимательности, скрупулёзности и знания кодовой базы анализируемого проекта. Не стоит бояться работы с трейсами. Надо просто делать.
Комментарии (5)

oblomov86
00.00.0000 00:00"Розовым цветом выделены эвенты...", "Зелёным цветом выделены эвенты..." - но на скриншотах этого нет. В некоторых случаях картинки без ваших пометок.

deniaa Автор
00.00.0000 00:00Фразы "<таким-то> цветом выделены эвенты.." расположены в тематических подпараграфах (CPU, Exceptions, ...) одного большого параграфа "Посмотрим на какую-нибудь экзотику".
В этом корневом параграфе "Посмотрим на какую-нибудь экзотику" соответствующими цветами выделены обозреваемые коллекции эвентов (на странице PerfView со всеми типами эвентов). А в подпараграфах представлены скриншоты тех страниц PerfView, которые открываются, если провалиться (даблкликом) внутрь соответствующих коллекций эвентов, которые этим самым цветом и были выделены.
Наверное, из-за большого объема это не очень очевидно считалось.
atd
Спасибо за подробный обзор!
Могу лишь упомянуть, что если интересует только CPU-bound нагрузка, то интеловский VTune намного проще и удобнее
deniaa Автор
Да, VTune тоже интересный и достойный инструмент.
Я сам им не пользовался и всего лишь несколько раз наблюдал опыт его использования коллегами, поэтому не могу претендовать на объективность. Но в целях "просто поделиться опытом использования" могу рассказать, что я заметил:
10-секундные трейсы с высоконагруженных .NET приложений на Linux открывались по несколько часов (в сравнении с WPA или PerfView это на два порядка дольше).
Чтобы открыть трейсы .NET- приложений с Linux приходилось плясать с бубном, но половина символов так и осталась Unknown.
Если ты хочешь заглянуть глубже, чем в .NET вызовы на Linux, то даже учитывая предыдущий пункт этот инструмент ценен и приносит много пользы.
Вполне вероятно, мы просто неправильно его готовили.
atd
между разными системами не пробовал передавать трейсы, так что не скажу ничего хорошего ))
Но в пределах одной системы их гранулярность можно настраивать, чтобы было не так тяжко. Самый мелкий интервал удобно ставить для микробенчмарков, а для нагруженных приложений приходится ставить побольше