
В предыдущих сериях
Микрооптимизации:
Сказка про Method as Parameter #dotnet #methods #gc
Инструменты анализа эффективности работы приложения. PerfView #performance_analysis #trace #perfview
Пародия на замыкания #dotnet #methods #gc
yield return #dotnet #il-code
Про тредпул:
ThreadPool.Intro #dotnet #threadpool
ThreadPool. async/await #dotnet #threadpool #il_code
ThreadPool.Chain #dotnet #threadpool
Про низкоуровневое:
Reciprocal throughput #microoptimization #low-level
Сказка про Branch prediction #microoptimization #low-level
Разное:
Сказка про Guid.NewGuid() #os_specific #dotnet #microoptimization
Ходят слухи, что foreach быстрее for. А ещё ходят слухи, что for быстрее foreach. Пора разобраться, что быстрее!
Художественное отступление, шутка на текущую тему. Для того, чтобы узнать самое интересное, читать текст под катом совершенно не обязательно.
— Саня, Саня, а давай проверим, что лучше плавает? Мой самолёт или твой поезд?
— Ого, пошли на речку, проверим!
…
— Ха, твой поезд утонул раньше моего самолёта!
— Ну и ладно. А давай проверим, что лучше летает? Утюг или кирпич?
— Давай, сейчас я утюг из дома возьму, а ты кирпич со стройки возьми
…
— Кидаем, раз, два, три!
— Ого, утюг дальше улетел. Это наверное потому, что у него форма аэродинамическая!
— Давай ещё что-нибудь проверим. Как думаешь, из чего лучше парашют получится, из простыни или скатерти? Можно с чердака проверить.
…
— Эй, бездари, чего без дела шляетесь? А ну уроки делать!
— Ну мааам. Мы тут вообще-то исследованиями физическими занимаемся.
— Уроки сделаешь, потом исследовать будешь. Кстати, ты утюг не трогал? Никак найти не могу.
Сначала определим область применимости, где можно взаимозаменять for и foreach. В первую очередь это массивы. Также, это списки — List. А ещё, сюда можно отнести интерфейс списка — IList. Под этим интерфейсом можно спрятать как обычный List, так и массив (делать свои реализации мы не будем). Всякие извращенные случаи, например словари, где можно устроить for по ключам-int'ам, рассматривать не будем.
Заготовим наши коллекции:
public class ForeachVsFor
{
private List<int> list; //Список
private IList<int> iListOverList; //Список под интерфейсом IList
private int[] array; //Массив
private IList<int> iListOverArray; //Массив под интерфейсом IList
[GlobalSetup]
public void Setup()
{
var length = 45;//It's a good number. Not too small, not too big.
var ints = new List<int>(length);
for (var i = 0; i < length; i++)
{
ints.Add(i);
}
list = ints;
iListOverList = ints;
array = ints.ToArray();
iListOverArray = array;
}
}Дабы исследуемый цикл не был совершенно без тела, будем делать на каждой итерации простую операцию — сложение. Будем складывать все числа в коллекции. А ещё, чтобы добавить перчинки, давайте будем проверять и на Net6, и на Net7!
Массивы
Начнём от простого к сложному, то есть с массивов. Как вы думаете, что быстрее:
[Benchmark]
public int ForArray()
{
var summ = 0;
for (int i = 0; i < array.Length; i++)
{
summ += array[i];
}
return summ;
}
[Benchmark]
public int ForeachArray()
{
var summ = 0;
foreach (var e in array)
{
summ += e;
}
return summ;
}
[Benchmark]
//Этот код присутствует здесь для тех, кто помнит про safety-check'и
//в индексации массива, которые перепроверяют границы массива (https://habr.com/ru/companies/skbkontur/articles/737858/).
public unsafe int ForUnsafeArray()
{
var summ = 0;
var length = array.Length;
fixed (int* ptr = array)
{
var pointer = ptr;
var bound = pointer + length;
while (pointer != bound)
{
summ += *pointer;
pointer += 1;
}
}
return summ;
}Результаты бенчмарка для массива под катом.
| Method | Runtime | Mean | Gen0 | Allocated |
|---------------------- |--------- |----------:|-------:|----------:|
| ForArray | .NET 6.0 | 25.52 ns | - | - |
| ForeachArray | .NET 6.0 | 15.87 ns | - | - |
| ForUnsafeArray | .NET 6.0 | 17.75 ns | - | - |
|---------------------- |--------- |----------:|-------:|----------:|
| ForArray | .NET 7.0 | 24.37 ns | - | - |
| ForeachArray | .NET 7.0 | 15.71 ns | - | - |
| ForUnsafeArray | .NET 7.0 | 18.22 ns | - | - |Для начала обратим внимание, что foreach действительно быстрее for на массивах, причем намного.
Далее, ForUnsafe действительно намного быстрее обычного For. В чем разница между For и ForUnsafe мы уже знаем — в лишней проверке на ненарушение границ массива на каждой итерации при индексации.
И ForUnsafe лишь чуть-чуть хуже Foreach. Не будем изучать эту разницу под микроскопом в ASM-коде.
Между Net6 и Net7 разница совсем не существенная.
Списки
Перейдём к спискам, то есть List. У них под капотом, как известно, тоже массив. Но проверим и его, всё-таки методы у него свои. Как вы думаете, что быстрее:
[Benchmark]
public int ForList()
{
var summ = 0;
for (int i = 0; i < list.Count; i++)
{
summ += list[i];
}
return summ;
}
[Benchmark]
public int ForeachList()
{
var summ = 0;
foreach (var e in list)
{
summ += e;
}
return summ;
}Результаты бенчмарка для списка под катом.
| Method | Runtime | Mean | Gen0 | Allocated |
|---------------------- |--------- |----------:|-------:|----------:|
| ForList | .NET 6.0 | 32.96 ns | - | - |
| ForeachList | .NET 6.0 | 49.89 ns | - | - |
|---------------------- |--------- |----------:|-------:|----------:|
| ForList | .NET 7.0 | 32.25 ns | - | - |
| ForeachList | .NET 7.0 | 36.08 ns | - | - |
Старые запуски на массиве, чтобы были перед глазами (только Net7)
|---------------------- |--------- |----------:|-------:|----------:|
| ForArray | .NET 7.0 | 24.37 ns | - | - |
| ForeachArray | .NET 7.0 | 15.71 ns | - | - |Для начала обратим внимание, что в случае списков for действительно быстрее foreach, причем намного (для массивов было наоборот!). Но только на Net6! А на Net7 разница уже не такая существенная, хотя и все равно присутствует. Не будем изучать, почему в Net7 лучше. Лучше — и замечательно.
Отдельно отметим, что оба варианта сильно проигрывают обоим вариантам для массива.
Массив под интерфейсом IList
Перейдём к интерфейсам. У нас есть переменная типа IList, в которую мы просто присвоили наш массив. Проверим, изменится ли что-нибудь при работе с массивом не напрямую, а через интерфейс IList.
[Benchmark]
public int ForIListOverArray()
{
var summ = 0;
for (int i = 0; i < iListOverArray.Count; i++)
{
summ += iListOverArray[i];
}
return summ;
}
[Benchmark]
public int ForeachIListOverArray()
{
var summ = 0;
foreach (var e in iListOverArray)
{
summ += e;
}
return summ;
}Результаты бенчмарка для массива под IList под катом.
| Method | Runtime | Mean | Gen0 | Allocated |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverArray | .NET 6.0 | 210.78 ns | - | - |
| ForeachIListOverArray | .NET 6.0 | 197.25 ns | 0.0076 | 32 B |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverArray | .NET 7.0 | 220.61 ns | - | - |
| ForeachIListOverArray | .NET 7.0 | 230.32 ns | 0.0076 | 32 B |
Старые запуски, чтобы были перед глазами (только Net7)
|---------------------- |--------- |----------:|-------:|----------:|
| ForList | .NET 7.0 | 32.25 ns | - | - |
| ForeachList | .NET 7.0 | 36.08 ns | - | - |
|---------------------- |--------- |----------:|-------:|----------:|
| ForArray | .NET 7.0 | 24.37 ns | - | - |
| ForeachArray | .NET 7.0 | 15.71 ns | - | - |Первое, что бросается в глаза — это то, что foreach теперь мусорит объектами!
Второе, что бросается в глаза — foreach на Net7 стал хуже, чем на Net6!
Ну и третье, что бросается в глаза — обращения к IList'у примерно на порядок хуже, чем обращения просто к списку или массиву!
Список под интерфейсом IList
Повторим предыдущий эксперимент с интерфейсом IList. У нас есть переменная типа IList, в которую мы просто присвоили наш список. Проверим, изменится ли что-нибудь, при работе со списком не напрямую, а через интерфейс IList.
[Benchmark]
public int ForIListOverList()
{
var summ = 0;
for (int i = 0; i < iListOverList.Count; i++)
{
summ += iListOverList[i];
}
return summ;
}
[Benchmark]
public int ForeachIListOverList()
{
var summ = 0;
foreach (var e in iListOverList)
{
summ += e;
}
return summ;
}Результаты бенчмарка для списка под IList под катом.
| Method | Runtime | Mean | Gen0 | Allocated |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverList | .NET 6.0 | 190.77 ns | - | - |
| ForeachIListOverList | .NET 6.0 | 309.41 ns | 0.0095 | 40 B |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverList | .NET 7.0 | 187.43 ns | - | - |
| ForeachIListOverList | .NET 7.0 | 355.90 ns | 0.0095 | 40 B |
Старые запуски, чтобы были перед глазами (только Net7)
|---------------------- |--------- |----------:|-------:|----------:|
| ForList | .NET 7.0 | 32.25 ns | - | - |
| ForeachList | .NET 7.0 | 36.08 ns | - | - |
|---------------------- |--------- |----------:|-------:|----------:|
| ForArray | .NET 7.0 | 24.37 ns | - | - |
| ForeachArray | .NET 7.0 | 15.71 ns | - | - |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverArray | .NET 7.0 | 220.61 ns | - | - |
| ForeachIListOverArray | .NET 7.0 | 230.32 ns | 0.0076 | 32 B |Как и в предыдущем случае, foreach мусорит объектами; foreach на Net7 заметно хуже, чем на Net6; обращения к IList'у примерно на порядок хуже, чем обращения просто к списку или массиву.
Интересные дополнительные наблюдаемые эффекты: Foreach на IList'е под которым List значительно хуже, чем на том IList, под которым array. А для For наоборот.
Почему так не эффективны обращения к IList
Полный ответ на этот вопрос был бы достаточно объемным. Но давайте сделаем первый шажок. Посмотрим на IL-код, например метода ForeachIListOverList.
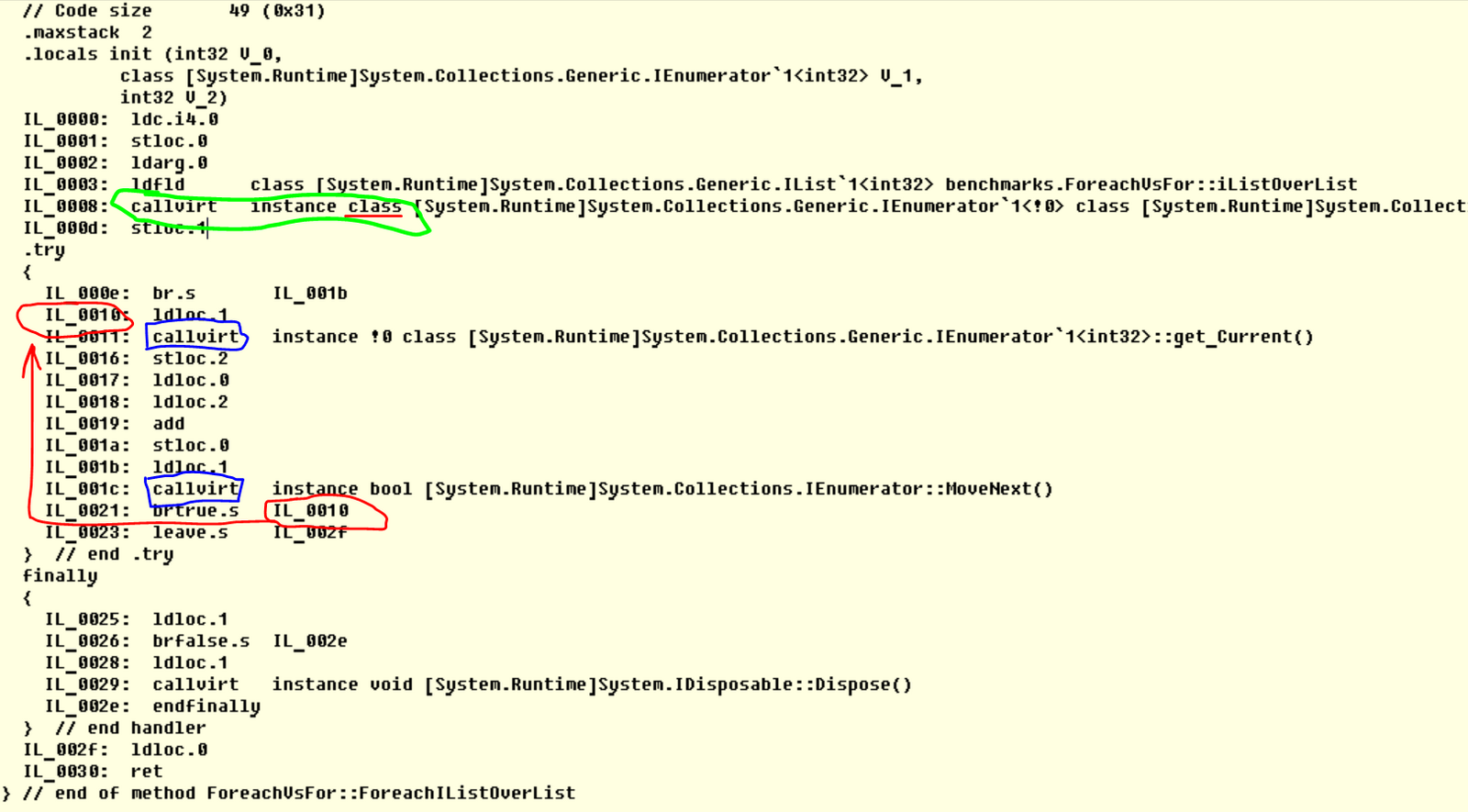
Красным выделен переход от одной итерации цикла к другой. Синим — вызовы виртуальных методов GetCurrent и MoveNext у enumerator'а. Который чуть выше мы и создали, чем и намусорили — я выделил это зелёным цветом и подчеркнул, что создался там класс, то есть объект на хипе.
Теперь давайте взглянем на IL-код метода ForeachList.

Красным выделен переход от одной итерации цикла к другой. Синим — вызовы уже не виртуальных, а обычных методов GetCurrent и MoveNext у enumerator'а. Который чуть выше мы и создали. Но мы им не намусорили — я выделил это зелёным цветом и подчеркнул, что создался там valuetype, то есть структура на стеке. Да, дотнет умный и когда уверен в ситуации, для обычного List'а создает специальный легковесный Enumerator, который структура.
В остальном код одинаковый. Из чего следует, что вот эти виртуальные вызовы очень дорогие. И это действительно так. Это легко понять, если углубиться в то, как работают интерфейсы. Сейчас разбирать это мы не будем, иначе размер статьи увеличится в несколько раз.
Что можно улучшить
Давайте попытаемся уменьшить число виртуальных вызовов. В случае с foreach у нас ничего не выйдет. Метода bool TryMoveNext(out T value), увы, не существует. Но давайте посмотрим на код с for в случае с IList'ом. Например, на ForIListOverList.

Красным отмечен цикл. Синим — виртуальные вызовы методов. GetItem — это и есть индексация. А вот GetCount — похоже, что это вызов свойства .Count! Действительно, если это интерфейс, откуда дотнету знать, что реализация под ним всегда будет возвращать одно и то же значение на вызов свойства Count? Получается, на каждой итерации мы вызываем дорогой виртуальный метод Count. Но если мы знаем, что коллекция внутри не меняется, мы можем воспользоваться этим и закешировать размер коллекции, чтобы не «извлекать» её заново на каждой итерации цикла.
[Benchmark]
public int ForIListOverList()
{
var summ = 0;
for (int i = 0; i < iListOverList.Count; i++)
{
summ += iListOverList[i];
}
return summ;
}
[Benchmark]
public int ForIListOverList2()
{
var summ = 0;
var upperBound = iListOverList.Count;
for (int i = 0; i < upperBound; i++)
{
summ += iListOverList[i];
}
return summ;
}Аналогичный код я написал и для случая iListOverArray. Проверим, поможет ли.
| Method | Runtime | Mean | Gen0 | Allocated |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverList | .NET 6.0 | 190.77 ns | - | - |
| ForIListOverList2 | .NET 6.0 | 115.69 ns | - | - |
| ForIListOverArray | .NET 6.0 | 210.78 ns | - | - |
| ForIListOverArray2 | .NET 6.0 | 125.25 ns | - | - |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverList | .NET 7.0 | 187.43 ns | - | - |
| ForIListOverList2 | .NET 7.0 | 113.02 ns | - | - |
| ForIListOverArray | .NET 7.0 | 220.61 ns | - | - |
| ForIListOverArray2 | .NET 7.0 | 124.65 ns | - | - |Работает! Версии с циферкой 2, те, где мы закешировали размер коллекции, действительно быстрее. Если открыть IL-код, то вы убедитесь, что внутри тела цикла действительно пропал вызов GetCount. Он вызывается один раз до цикла и кешируется, что мы и написали в C#-коде. И заметно, что уменьшив число вызовов виртуальных методов в два раза, производительность увеличилась тоже почти в два раза, что ещё раз подтверждает их высокую стоимость.
Почему на Net7 обращение к IList'у медленнее, чем на Net6?
К сожалению, у меня нет на это ответа. Если сравнить ASM-код всего нашего бенчмарка на Net6 и Net7, кроме собственно вызова виртуальных методов, то он абсолютно идентичен (на 99%, но различия не выглядят значимыми для производительности). То есть вся разница именно где-то внутри дотнета при работе с интерфейсами и\или энумераторами. Эта история требует какого-то дополнительного исследования и вероятно, она не ограничится только лишь IList'ом. При этом, можно отметить такие наблюдения:
Код с For-циклами по IList'у работает одинаково на Net6 и Net7;
Код с Foreach-циклами по IList'у на Net7 ощутимо медленнее;
Весь прочий код со списками или массивами, что for, что foreach, без IList'а, либо одинаков на Net6 и Net7, либо Net7 чуть-чуть побыстрее.
Если кто-то знает причины этой деградации, поделитесь ими в комментариях!
Полная таблица бенчмарка
// * Summary *
BenchmarkDotNet=v0.13.4, OS=Windows 10 (10.0.19045.2486)
Intel Core i7-4771 CPU 3.50GHz (Haswell), 1 CPU, 8 logical and 4 physical cores
.NET SDK=7.0.102
[Host] : .NET 6.0.13 (6.0.1322.58009), X64 RyuJIT AVX2
.Net 6.0 : .NET 6.0.13 (6.0.1322.58009), X64 RyuJIT AVX2
.Net 7.0 : .NET 7.0.2 (7.0.222.60605), X64 RyuJIT AVX2
| Method | Runtime | Mean | Gen0 | Allocated |
|---------------------- |--------- |----------:|-------:|----------:|
| ForIListOverList | .NET 6.0 | 190.77 ns | - | - |
| ForIListOverList2 | .NET 6.0 | 115.69 ns | - | - |
| ForeachIListOverList | .NET 6.0 | 309.41 ns | 0.0095 | 40 B |
| ForList | .NET 6.0 | 32.96 ns | - | - |
| ForeachList | .NET 6.0 | 49.89 ns | - | - |
| ForArray | .NET 6.0 | 25.52 ns | - | - |
| ForeachArray | .NET 6.0 | 15.87 ns | - | - |
| ForUnsafeArray | .NET 6.0 | 17.75 ns | - | - |
| ForIListOverArray | .NET 6.0 | 210.78 ns | - | - |
| ForIListOverArray2 | .NET 6.0 | 125.25 ns | - | - |
| ForeachIListOverArray | .NET 6.0 | 197.25 ns | 0.0076 | 32 B |
| ForIListOverList | .NET 7.0 | 187.43 ns | - | - |
| ForIListOverList2 | .NET 7.0 | 113.02 ns | - | - |
| ForeachIListOverList | .NET 7.0 | 355.90 ns | 0.0095 | 40 B |
| ForList | .NET 7.0 | 32.25 ns | - | - |
| ForeachList | .NET 7.0 | 36.08 ns | - | - |
| ForArray | .NET 7.0 | 24.37 ns | - | - |
| ForeachArray | .NET 7.0 | 15.71 ns | - | - |
| ForUnsafeArray | .NET 7.0 | 18.22 ns | - | - |
| ForIListOverArray | .NET 7.0 | 220.61 ns | - | - |
| ForIListOverArray2 | .NET 7.0 | 124.65 ns | - | - |
| ForeachIListOverArray | .NET 7.0 | 230.32 ns | 0.0076 | 32 B |Выводы
Непосредственные
foreach быстрее for на массивах, по крайней мере на int[]. Но unsafe-реализация for может догнать foreach.
for быстрее foreach на списках, по крайней мере на
List<int>. Хотя, на Net7 foreach значительно ускорили. Но for он так и не догнал.Обращения к IList'у как к коллекции что с помощью for, что с помощью foreach, очень дороги на каждой итерации из-за виртуальных вызовов методов. При этом, foreach на IList'е аллоцирует объект энумератора. А ещё, foreach на IList'е деградирует на Net7 по сравнению с Net6.
Более полезные
В местах, действительно чувствительных к производительности, не место этим всяким ООПшным штучкам с интерфейсами. Виртуальные вызовы крайне дороги. Даже если от интерфейсов никуда не деться, старайтесь минимизировать их вызовы, например, кешировать то, что можно закешировать. Иначе легко может оказаться, что 90% времени работы программы потрачено не на ваш полезный код, а на проделки дотнета.
Впрочем, если подходить к вопросу оптимизаций работы именно с интерфейсами (особенно своими собственными, не дотнетными), то иногда можно кое-что сделать. В том же Net7 появились возможности в связке sealed-классов с PGO.
Никогда не делайте предположений, что что-то быстрее чего-то, не проведя бенчмарков на приближенных к реальности данных в нужном окружении. Реальность намного сложнее, чем мы можем себе представить. Как можно было заметить, в одних условиях побеждает одно решение, а в других другое.
Не всегда всё новое лучше всего старого. Иногда, даже в таких вещах как DotNet, архитекторам приходится чем-то жертвовать в угоду другим целям, выпуская новые версии. И если у вас система чувствительна к производительности, стоит тщательно все проверять.
Комментарии (18)

a-tk
27.06.2023 05:56+2Итератор List-а медленнее чем у массива хотя бы потому, что дополнительно выполняется проверка, что коллекция не изменилась между итерациями.

Linder666
27.06.2023 05:56а разве в for цикле не может происходить такая же автопроверка?
//первый поток for (int i = 0; i<ListInt.Count; i++){ Colsole.WriteLine(ListInt[i]++); } //второй поток for (int j = 0; j<10; j++){ ListInt.Add(j); Swap(ListInt.Last(),ListInt(j));//поменять местами элементы }Разве в первом потоке на очередной итерации не выпадет исключение, что коллекция изменилась?
a-tk
27.06.2023 05:56+4Чтобы она происходила, её надо написать. Если Вы её не написали, то надо смотреть упоминания поля
_versionв исходнике:https://github.com/microsoft/referencesource/blob/master/mscorlib/system/collections/generic/list.cs
Ответ отрицательный.

leveter
27.06.2023 05:56Полагаю, комментарий был относительно того, что List - это тот же массив, но в котором добавлены методы, как пример, проверки на переполнение и, в случае необходимости, увеличение массива. И это происходит на каждой итерации цикла. Массив же, является основой, которая ничего не делает, кроме непосредственно тех задач, которые на него возложены в конкретной команде.

freeExec
27.06.2023 05:56В цикле for из статьи происходит только чтение значений из массива, так что там нет никакой проверки на изменчивость.

nronnie
27.06.2023 05:56В массиве вообще нет проверки на изменчивость. В списке есть внутреннее поле версии, которое увеличивается при любой модификации списка внутри соответствующих методов, итератор (реализация
IEnumerator) сохраняет у себя значение этого поля в момент своего создания, а потом сверяет его с текущим значением в списке при каждомNext(). Так, по крайней мере, было реализовано до .NET 5, за последние версии стопроцентно не скажу, потому что лично по исходникам не проверял. Это защитный механизм от сюрпризов с пропуском или повторным чтением итератором элементов в случае изменения коллекции, а поскольку для массива элементы не могут добавляться или удаляться, то там такая защита не нужна.

aamonster
27.06.2023 05:56А можно как-то сказать компилятору "зуб даю, не менялась!"?

Fedorkov
27.06.2023 05:56+1Для этого существуют массивы.
Если есть желание извратиться, можно через рефлексию получить приватный list._items и перебирать его.
a-tk
27.06.2023 05:56+2Можно вытащить
Spanс помощью https://learn.microsoft.com/en-us/dotnet/api/system.runtime.interopservices.collectionsmarshal.asspan?view=net-7.0

Politura
27.06.2023 05:56+2Было-бы интересно глянуть на результат сравнения их обоих с linq. Когда-то давно linq был очень медленным. Несколько лет назад была статья на хабре, где на массивах он проигрывал for/foreach, а на коллекциях толи сравнялся с ними, толи выигрывал. Интересно как теперь с ним обстоят дела в нет7.

deniaa Автор
27.06.2023 05:56+3Производительность LINQ сильно привязана к generic-типу коллекции, типу самой коллекции, с которой происходит работа, и к собственно самой функции вызова. Ведь LINQ это не просто перечисление, это и какая-то полезная нагрузка.
Там, например, на .Net7
.Sum()на массивах чисел работает с помощью SIMD. А на каком-то сложном IEnumerable - просто складывает влоб. А в нашем случае сложение выбрано как относительно нейтральная и бесплатная полезная нагрузка. (Будь у нас какой-нибудь супер-умный компилятор, как у C++, то он бы тоже мог заметить возможность переписать код с использованием SIMD). Кстати, это и не только обсуждалось в предыдушей статье про reciprocal throughput (и отдельного внимания там заслуживают ветки в комментариях, например вот эта).Поэтому рассматривать производительность LINQ в сравнении с перечислением foreach и циклом for в отрыве от функции и типа коллекции просто неправильно. Такое исследование, конечно, интересно, но скатится в перечисление огромного числа случаев. Больше пользы можно извлечь из чтения патчноутов: что конкретно в LINQ в новом .Net'е улучшили.
nronnie
27.06.2023 05:56Сделал сейчас такой эксперимент:
var array = new int[42]; var ilist = array as IList<int>; var arrayEnumerator = array.GetEnumerator(); var ilistEnumerator = ilist.GetEnumerator(); Console.WriteLine(arrayEnumerator.GetType()); // System.ArrayEnumerator Console.WriteLine(ilistEnumerator.GetType()); // System.SZGenericArrayEnumerator`1[System.Int32]Получается, что
GetEnumerator()дляT[]возвращает разные реализации если вызвать его напрямую, и если сначала массив привести кIList<T>. Стало интересно, какую реализацию при этом используетforeach, потому что первый вариант вообще недженериковый, а значит, а значит, в случае него там может быть оверхед на боксинг-анбоксинг. Но дизассемблером пока что не ковырял.

tania_012
27.06.2023 05:56-3Вопросы этой статьи действительно имели высокую ценность в благословенные времена малых компьютерных ресурсов и немногих продуктов — изобретать лучшие алгоритмы было очень полезным и весьма почетным занятием.
Те времена прошли, "железо" пошло в рост в экспоненциальный рост и он продолжается, вот Intel создала суперкомпьютер Aurora, 85 тысяч процессоров, ожидается, что Aurora станет первым в мире суперкомпьютером, теоретически достигшим пиковой производительности более 2 экзафлопс (1 экзафлопс означает миллиард миллиардов операций в секунду). Опять же квантовые компьютеры вот-вот родятся.
А еще, пользуясь ростом "железа" многие энтузиасты создали множество продуктов, в том числе и языков программирования, которые не оптимизированы на скорость — можно несколько жизней потратить на их улучшения, которые в общем-то никому не будут нужны.
Т.е. я как бы намекаю на то, что применять энергии исследований лучше на специальных областях, там не только хакерство) и там действительно есть востребованность, даже мне вот нужно кое-что узнать)

Anton-V-K
27.06.2023 05:56+1"железо" пошло в рост в экспоненциальный рост и он продолжается
По-моему, для технологий на текущем уровне развития всё же есть физический предел, и вряд ли рост сейчас идёт по экспоненте. См., напр., https://habr.com/ru/articles/405723/
Так что никогда не поздно подрихтовать алгоритм вечного цикла, чтобы он работал чуточку быстрее ;)
deniaa Автор
27.06.2023 05:56+3Несомненно, если выбирать язык под задачу с требованием иметь фокус на производительность - выбирать C# не стоит.
Но это не значит, что на C# нельзя писать эффективные и высоконагруженные приложения - ещё как можно.
И это не значит, что в задачах, решаемых на C#, да и любом другом языке с фокусом на удобстве, безопасности и скорости процесса разработки, не могут возникать задачи оптимизации.
Например, мотивация для таких задач может быть сугубо экономическая. На определённом масштабе кластера даже из C#-приложений могут достигать сотен инстансов (а то и больше). И пара недель работы инженера над оптимизацией такого приложения на условные 10% потребления ресурсов могут сполна окупиться. При этом, рост до такого масштаба - это не повод переписывать приложение на условный C++.
применять энергии исследований лучше на специальных областях
Я всецело разделяю рационалистический подход. Но всегда остаются материи из разряда "это просто интересно (и полезно)", "это весело (и полезно)", "мне это доставляет удовольствие (и, судя по всему, не только мне)". А ещё, всегда присутствует фактор глубины знания. От знания устройства инструмента, с которым ты работаешь, результат твоей работы с этим инструментом на длительном промежутке становится точно не хуже. А, я уверен, только лучше.
tania_012
27.06.2023 05:56Я всецело разделяю рационалистический подход. Но всегда остаются материи из разряда "это просто интересно (и полезно)", "это весело (и полезно)", "мне это доставляет удовольствие (и, судя по всему, не только мне)".
Я прекрасно вас понимаю — сама такая — просто делать выговоры другим много легче)) чем себе.
Обидно же — временами, когда осознаешь краткость жизни — что передовые отряды уже прошли по непаханному, все там перерыли, упорядочили, записали в книги и поставили в библиотеки — а ты заново проходишь… И это в то время, когда стоит повернуть голову и вот они — настоящие таинственные джунгли, совсем рядом — и 10 лет учиться-экипироваться не надо.
Это я о себе. Мне обидно, поэтому ругаю вас. А кого же еще?
Dotarev
А можно про это намекнуть ссылками? Что-то Google мало что полезного дает..
deniaa Автор
Рекомендую ознакомиться со всеми статьями целиком, но я приведу ссылки на абзацы именно про sealed-классы:
https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-6/#peanut-butter
https://devblogs.microsoft.com/dotnet/performance_improvements_in_net_7/#analyzers