

Некоторое время назад мной была представлена статья, посвященная дисковой подсистеме ОС Linux и среди прочих в комментариях к данной статье предлагалось рассмотреть работу с кэшем в файловой системе BTRFS. В этой статье я предлагаю вернуться к теме файловых систем в Linux и для начала посмотреть что из себя представляет BTRFS, где применяется и как с ней лучше работать. Данная статья предназначена для администраторов Линукс, имеющих практический опыт администрирования данной ОС.
Итак, файловая система BTRFS (B-Tree Filesystem) предназначена для работы в Unix-подобных операционных системах. Она была разработана компанией Oracle в 2007 году. BTRFS построена по принципу CoW (Copy on Write), то есть при чтении области данных используется общая копия, в случае изменения данных — создается новая копия. Данная технология используется для оптимизации многих процессов, происходящих в операционной системе.
Немного о деревьях
В BTRFS как и в других ФС все данные хранятся на диске по определенным адресам, которые в свою очередь сохранены в метаданных. Однако, здесь все данные организуются в B-деревья (те самые B-tree, которые присутствуют в названии ФС). Не вдаваясь в дебри математических наук, которыми многих из нас мучали в вузе, кратко поясню принцип поиска в таких деревьях.
При поиске B-Tree мы должны выбирать пути из нескольких вариантов. То есть, если мы ищем в дереве например, значение 30, как представлено на картинке ниже, то при обходе мы сначала проверим ключ в корне, 13 меньше 30, значит нам надо перейти на правого потомка, 17<30, 24<30, значит снова переходим на правого потомка и здесь находим нужное значение.
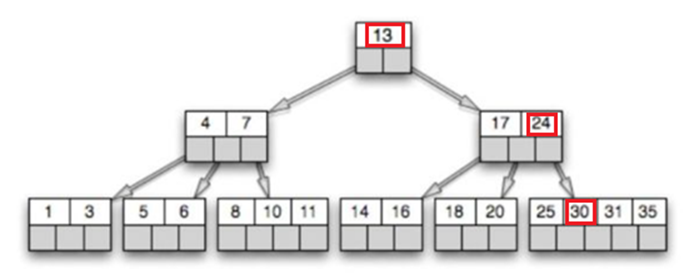
Какое все это имеет отношение к работе файловой системы? B-Tree в отличии от двоичных деревьев позволяет хранить много ключей в одном узле и при этом может ссылаться на несколько дочерних узлов. Это значительно уменьшает высоту дерева и, соответственно, обеспечивает более быстрый доступ к диску. Но вернемся к BTRFS.
Основные характеристики
Прежде всего, как положено при описании какой-либо технологии или решения, приведу основные характеристики BTRFS. Максимальный размер файла в данной ФС может составлять 2^64 байт или 16 экзабайт. При этом в BTRFS также реализована компактная упаковка небольших файлов и индексированные каталоги с экономией места. Для сжатия используются алгоритмы ZLIB, LZO, ZSTD, а также эвристика. Контрольные суммы для данных и метаданных вычисляются с помощью алгоритмов crc32c, xxhash, sha256, blake2b.
Ну а кроме этого, в BTRFS есть также динамическое распределение индексов, моментальные снимки с возможностью записи, снимки только для чтения и вложенные тома (отдельные корни внутренней файловой системы). Далее мы более подробно поговорим об этих технологиях и начнем с работы со снимками.
Снимки в файловой системе
При работе с файлами, в частности, при операции перезаписи данных, они по факту не перезаписываются, а та часть данных, которая подверглась модификации копируется на новое место. Затем просто обновляются метаданные о расположении изменившейся информации. Благодаря такому решению мы можем создавать мгновенные снимки файловой системы, которые не занимают места на диске, пока не было внесено много изменений. Ну а если старый блок больше не нужен, потому что он не является частью какого-либо снимка, то мы можем его автоматически удалить.
Работа с дисками
Как мы уже упомянули ранее BTRFS может работать с файлами до 16 Экзабайт. Хотя текущая реализация VFS Linux (виртуальной файловой системы, т.е. промежуточного слоя абстракции) имеет ограничение ядра до 8 Экзабайт. Но даже это уже огромный объем для работы с которым нужны соответствующие носители и BTRFS умеет эффективно работать с такими носителями. Большинство файловых систем используют диск целиком, от начала и до конца для записи своей структуры. Но BTRFS работает с дисками по-другому: независимо от размеров диска, мы делим его на блоки по 1 Гб для данных и 256 Мб для метаданных. Из этих блоков формируются группы, причем, каждая из которых может храниться на разных устройствах. При этом, количество таких блоков в группе может зависеть от уровня RAID для данной группы. Для управления блоками и группами используется специальное средство – менеджер томов, который уже интегрирован в файловую систему.
И еще одна небольшая плюшка. BTRFS при работе с небольшими файлами (по умолчанию до 8К) хранит их непосредственно в метаданных, тем самым снижая накладные расходы и уменьшая фрагментацию диска. Таким образом, наличие большого количества маленьких файлов, как минимум, не приведет к существенной просадке производительности.
Думаю, теории для этой статьи достаточно и сейчас самое время перейти к практике, а именно создать файловый раздел. В своем примере я буду по традиции использовать Ubuntu 22.04, однако другие современные дистрибутивы также должны поддерживать BTRFS
Разворачиваем BTRFS
Традиционно, процесс установки какого-либо ПО под Linux начинается с обновления пакетов:
sudo apt update
Далее в случае с Ubuntu 22.04 у меня поддержка ФС уже есть. Но в случае ее отсутствия необходимо было бы выполнить:
sudo apt install btrfs-progs -y
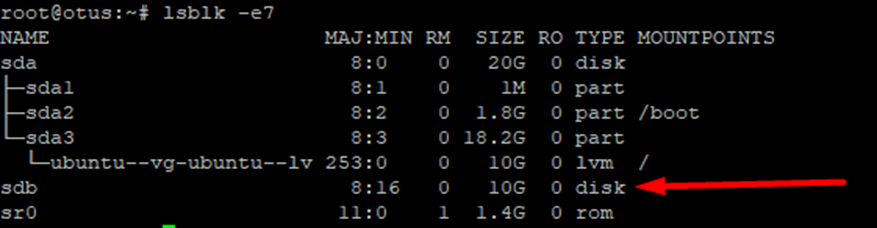
Далее нам потребуется неразмеченный диск. Посмотрим что у нас есть с помощью команды:
sudo lsblk -e7
В моем примере я буду работать с sdb размером 10 Гб.
Так как мы будем мучать sdb, то укажем его в параметрах утилиты cfdisk:
sudo cfdisk /dev/sdb
После запуска утилиты выбираем gpt.

Далее все достаточно стандартно: выбираем Free space. Так как я планирую использовать весь диск, то соответственно указываем использование всех 10 G.
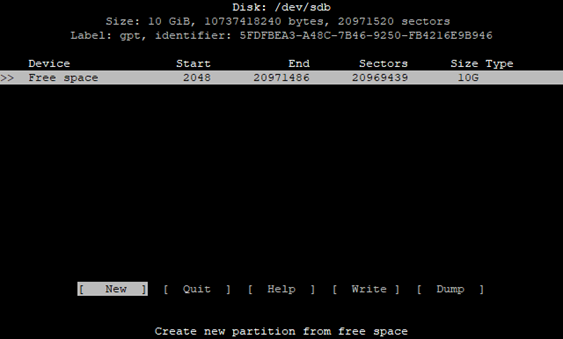
Если у вас планируется использовать только часть дискового пространства, тогда необходимо указать нужный размер. При этом можно использовать следующие сокращения для единиц измерения: M – мегабайты, G – гигабайты, T – терабайты.
Для сохранения изменений не забудьте нажать Write.
Теперь нам необходимо отформатировать созданный раздел в BTRFS.
sudo mkfs.btrfs -L data /dev/sdb
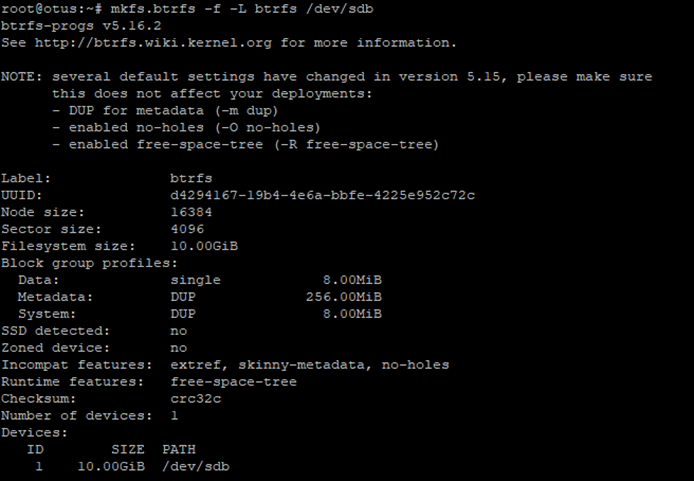
В результате мы получили полную информацию об отформатированном диске. Теперь подмонтируем BTRFS раздел. Для этого сначала создаем точку монтирования. В моем случае это каталог /btrfs. А затем подмонтируем sdb к этому разделу.
sudo mkdir -v /btrfs
sudo mount /dev/sdb /btrfs
И для того, чтобы убедиться в корректности выполненных операций, воспользуемся уже знакомой нам командой:
sudo lsblk -e7
Статистика использования
Поговорим немного о том, как можно смотреть различную статистику использования BTRFS дисков. Прежде всего воспользуемся командой:
sudo btrfs filesystem usage /data
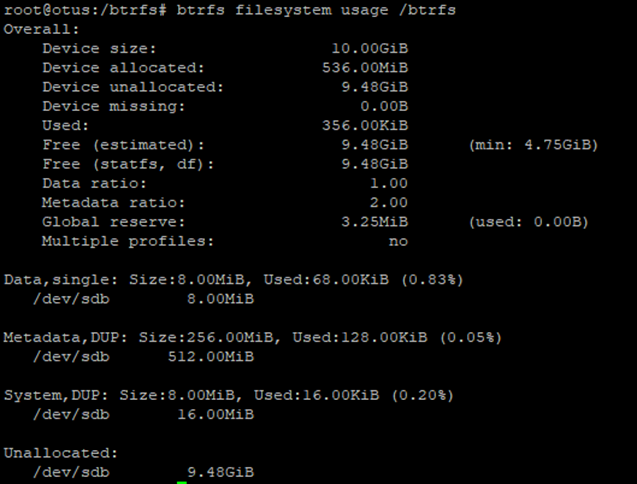
Вывод команды содержит различные значения. Посмотрим что означает каждое из них. В первой строке у нас идет общий размер диска – 10 Гб. Далее мы видим объем дискового пространства, зарезервированного для хранения данных и еще неиспользуемого пространства, которого естественно намного больше, так как пока на диск записано немного данных – сколько именно мы видим из значения поля Used. Отрадно, что значение Device missing равно 0.
Далее указаны методы (single или DUMP), которые используются для выделения дискового пространства для данных, метаданных и системных данных. При использовании single ФС хранит только одну копию данных, никакой дупликации не используется. Но при использовании DUP файловая система Btrfs выделит для одних и тех же данных дисковое пространство в разных частях файловой системы. Таким образом, в файловой системе будет храниться несколько копий (обычно две) одних и тех же данных.
Как можно видеть из рисунка выше, обычные данные у нас распределены в single режиме, а вот метаданные и системные данные используют DUP.
Заключение
В этой статье мы начали рассмотрение файловой системы BTRFS. Поговорили об основных преимуществах этой ФС и рассмотрели создание раздела под управлением BTRFS. В заключении хотелось бы заметить, что в сети можно встретить негативные отзывы об использовании данной ФС. Однако, все эти отзывы датированы началом 2010-х годов, когда система еще не была стабильна и могли происходить сбои. Но сейчас эта ФС поддерживается многими операционными системами, ее спецификация уже много лет не изменяется и ее можно использовать без опасения потерять свои данные.
В следующей статье мы продолжим рассмотрение BTRFS, и в частности поговорим об использовании нескольких дисков и создании отказоустойчивых конфигураций.
Также я хочу порекомендовать вам бесплатный урок от моих коллег из OTUS, которые расскажут, как можно собрать кастомную версию Nginx из исходников. Вы добавите нестандартные модули и библиотеки: модуль brotli, поддержку HTTP/3, библиотеку BogingSSL, RTMP-модуль. А также подготовите окружение и соберёте deb-пакет для установки в систему.
Комментарии (33)

aborouhin
00.00.0000 00:00+2Лет 7 назад переполз с BTRFS на ZFS на своих домашних серверах именно больно споткнувшись о глюк данной ФС... Бекапы всего важного были, но умершая на ровном ФС на разделе в несколько Тб убила массу моего времени на восстановление.
И вот буквально недавно на арендованном выделенном сервере вернулся к BTRFS. По одной простой причине - нужен был Debian и программный RAID1 средствами ФС из двух SSD, которые в этом сервере установлены. Возможности загрузить сервер с CD/USB нет. А ZFS не умеет сначала создать zpool из одного диска, а потом сделать из него зеркало, добавив второй. А вот BTRFS, как выяснилось, умеет! Так что получилось загрузиться из предустановленной на первый диск ОС, отформатировать второй диск в BTRFS, установить на него новую ОС, загрузиться в неё и добавить первый диск к зеркалу. Вот теперь надеюсь, что стабильность за прошедшие годы и правда улучшилась...
Johan_Palych
00.00.0000 00:00Несколько лет использую Fedora-у(не в проде). Проблем с btrfs не замечал.

13werwolf13
00.00.0000 00:00а в федоровский dnf уже подвезли плагин для snapper?
Johan_Palych
00.00.0000 00:00Завезли. Лень расписывать.
Вроде вразумительная статейка: Automatic btrfs snapshots and rollbacks using snapper

InikonI
00.00.0000 00:00+3А ZFS не умеет сначала создать zpool из одного диска, а потом сделать из него зеркало, добавив второй.
Умеет. И всегда умела.
zpool attachaborouhin
00.00.0000 00:00Спасибо. Самое смешное, что ведь и правда умеет, если это просто mirror, а не raidz.
А вот к авторам инсталлятора Proxmox VE у меня появилось очень много вопросов... (чтобы написать подробнее, надо поэкспериментировать, но у них очень своеобычный выбор вариантов установки на ZFS, который и ввёл меня в заблуждение)
InikonI
00.00.0000 00:00+1В Proxmox мне тоже не нравится установщик.
Очень ограниченный выбор.
Я например для корня не хочу ни zfs ни lvm использовать.
Да и под корень не очень удобно zfs использовать (так что может оно и к лучшему что перешли на btrfs).
Были проблемы именно с proxmox после какого то обновления переставал грузится с zfs.
Я для корня отрезаю часть от SSD диска и из остатка делаю zfs пул для вм и контейнеров.
Корневой раздел я бэкаплю с помощью veeam.
И для того что бы реализовать такое разбиение диска приходится после установки пере разбивать все в ручную и переделывать загрузчик.
Что дико не удобно.aborouhin
00.00.0000 00:00С проблемой незагрузки с ZFS тоже сталкивался... там рецепт починки совершенно шаманский, где-то до сих пор ссылка на него в закладках. Сделанный вывод на будущее из той ситуации - у сервера должен быть IP-KVM всегда :) Но этот баг давно починили, а вот поддержка BTRFS до сих пор официально с статусе preview, так что никто тем более ничего не гарантирует.
И именно для целей Proxmox у ZFS много плюсов. Репликация VM на другую ноду, скажем только с ZFS и работает. А заморачиваться со сложным разбиением диска тоже не хочется...
InikonI
00.00.0000 00:00Это да IP-KVM дюже полезная вещь, я даже для домашнего применения беру сервера с IP-KVM,
из первых это microserver gen8, затем PowerEdge T140 и сейчас PowerEdge T350.
А ZFS я безусловно с Proxmox использую, просто мне не нужна ZFS под корень.
Когда корень расположен на пуле ZFS вместе с другими данными то его потом и не изменишь так просто.
Пулы с данными, ВМ и контейнерами у меня отдельно.
Да и когда корень отдельно мне и бэкап проще делать (с помощью veeam).
И восстанавливать проще и быстрее.
А с IP-KVM так и к серверу ходить не надо.aborouhin
00.00.0000 00:00Дома-то у меня под корень отдельно диски, под данные отдельно. Физические. Соответственно, и объединены они в два разных пула (оба ZFS, правда, но в этом случае корень мог быть бы на чём угодно).
А вот на арендованном сервере физических дисков всего два. И есть задача, чтобы при вылете любого из них сервер продолжал спокойно работать на одном, пока я провайдеру отправляю заявку на замену почившего. И потом продолжал работать без длительного простоя после такой замены. И деление дисков на разделы эту задачу только усложнит. Ну т.е. я могу сделать два пула ZFS из двух разделов на каждом диске - но никаких плюсов по сравнению с общим пулом это не даёт. А если для корня не ZFS, но с избыточностью - то что? LVM? Совсем сложно - два разных механизма, и от такого усложнения риски, что при отвале одного из дисков что-то не взлетит как задумывалось, выше. Гибкость мне там не нужна, конфигурацию сервера я менять не могу, если что и будет меняться - буду параллельно поднимать новый сервер и поэтапно переносить всё на него.
InikonI
00.00.0000 00:00А как происходит бэкап Proxmox если корень на ZFS?
У меня корень на обычном разделе под ext4 (отрезан от SSD диска).
Как его бэкапить, и главное как восстанавливать я знаю.aborouhin
00.00.0000 00:00А зачем мне вообще бекапить сам Proxmox? Я бекаплю виртуальные машины на Proxmox Backup Server. В самом Proxmox изменено минимальное количество настроек, которые к тому же накатываются на него не вручную, а через Ansible (ну ладно, в Ansible пока не всё заведено, но я работаю в этом направлении).
Если сам гипервизор придётся переустанавливать или переносить на другой сервер - я практически моментально разверну новую инсталляцию Proxmox, и на неё уже восстановлю виртуалки из бекапа.
Впрочем, никто не мешает и корень на ZFS через zfs send куда-нибудь бекапить, если очень хочется.
А в Вашей схеме (если я правильно понял, и корень у Вас без избыточности на одном диске, а данные уже в ZFS mirror) получается, что избыточность ZFS пула вообще непонятно для чего. Ну разве что если отвалится второй диск в mirror, а не первый, она поможет. Но при отвале первого диска Вы получаете простой на время его замены и восстановления системы. А ровно для того, чтобы такого простоя не было, все RAID и существуют...
InikonI
00.00.0000 00:00Я бэкаплю сам proxmox потому что не хочу его снова настраивать вводить в кластер по новой и до устанавливать пакеты.
Дисков у меня достаточно много в сервере и 3 пула.
Да корень без избыточности, но у меня это домашнее применение и простой не так критичен.
Это не идеальная конфигурация и я ее не защищаю.
Просто мне понятно как ее обслуживать и главное восстанавливать.
ZFSonRoot я еще использовал где то с 2014 под debian.
И опыт по восстановлению загрузки с zfs накопил))
Просто с обычным разделом я могу восстановить сервер из бэкапа довольно быстро.
А вот сервер который не бэкапится я точно быстро не восстановлю.
Настройки сервера у меня тоже большей частью дефолтные, сторонних сервисов не установлено (разве что zabbix-agent).Если сам гипервизор придётся переустанавливать или переносить на другой сервер — я практически моментально разверну новую инсталляцию Proxmox
Да это удобно.
Поищу на досуге, раньше мне подобных инструкций не попадалось.
AlexKMK
00.00.0000 00:00Ansible + pvesh плагин?
Я раньше тоже бекапил условный etc и сильно боялся что придется раскатывать.
Один раз написал плейбук и теперь сплю спокойно по этому поводу, а волосы стали мягкие и шелковистые
InikonI
00.00.0000 00:00Ansible + pvesh плагин?
Спасибо попробую.
Если копировать только etc то это конечно маловато.
Я veeam-ом уже привык разделы вместе с загрузочной областью бэкапить. Удобно что можно посмотреть статусы бэкапа из консоли veaam.
Технология отлажена до автоматизма, включая и восстановление ))
13werwolf13
00.00.0000 00:00когда btrfs только появилась (емнип продвигаемая красношляпой) она превращалась в тыкву от каждого чиха, зачастую с невозможностью восстановить данные (за что и была отвергнута родителем), после чего разработку подхватила suse (тогда ещё novel) и на данный момент btrfs прекрасна, редко ломается, легко чинится, шустро работает, даёт много плюшек (ещё бы блочный сабволы как в zfs дали и тогда zfs стала бы ненужна).. в общем ванлав.
но факт, ext4 всё ещё более неубиваемая.

SamOwaR
00.00.0000 00:00+1больно споткнувшись о глюк данной ФС...
Было такое же, много лет назад, как только появилась в ванильном ядре.
Бэкапный рейд с BTRFS был забит под завязку. И потом что-то сломалось, и файловая система уже не монтировалась. Очень долго мучился, пока получилось расширить том ещё одним диском и потом система ожила. В те времена это была очень серьёзная проблема, когда заканчивается свободное место, особенно при наличии большого количества снимков и использования сжатия. Сейчас вроде починили. Ну то есть как - понять сколько у тебя фактически есть свободного места всё так же не просто, но хотя бы не падает.
Ну и важно понимать, что CoW подходит далеко не для всех задач. Если нужен swap файл - то есть специальная утилита чтобы создать его правильно, а для баз CoW вообще лучше отключать - есть множество бенчмарков.
А вот для бекапов эта ФС идеальная. Именно поэтому она всё чаще идёт как система по-умолчанию на NAS устройствах.

tuupic
00.00.0000 00:00+1Более того, btrfs на лету позволяет менять "топологию". Сделать из raid1 raid5, обратно, и т.д. Правда, это не на лету делается, и нужно btrfs balance звать

okhsunrog
00.00.0000 00:00+1Ну как же не умеет, умеет прекрасно. Я так на домашнем сервере переползал с btrfs с нативным RAID1 на ZFS (тоже с её родной реализацией RAID1). Изначально было 2 диска по 4 ТБ, отмонтировал ФС, почистил начало диска на одном из них, создал на нём ZFS пул. Потом смонтировал btrfs раздел на другом диске в degraded mode, перенёс данные на ZFS пул. После этого на втором диске тоже залил первые пару мегабайт нулями, чтобы стереть таблицу разделов и btrfs. После этого добавил диск к zfs с помощью замечательной команды zfs attach. По сути диск добавляется к существующему vdev и получается RAID1.
На всякий случай оставляю ссылочку на мануал https://openzfs.github.io/openzfs-docs/man/8/zpool-attach.8.htmlaborouhin
00.00.0000 00:00Спасибо, тут в комментах выше уже разобрались, что умеет. Просто задачка сделать ZFS была совмещена с задачкой поставить на этот ZFS proxmox, и вот его инсталлятор несколько странный выбор вариантов предлагает. Варианта "просто ZFS без RAID" нет вообще, "ZFS (RAID-1)" (mirror) сразу требует два диска, один диск можно выбрать только в варианте "ZFS (RAID-0)" (stripe)... Скорее всего, в последнем случае как раз и создаётся простой vdev и без mirror, и без stripe, к которому потом можно приаттачить второй диск для получения mirror - но это ж догадаться надо было... В общем, возможно, вооружённый этим знанием, и переползу с BTRFS на изначально запланированную ZFS таким образом, надо время выделить.


Johan_Palych
00.00.0000 00:00+2Зачем столько букв? Точка монтирования из статьи.
btrfs f df /btrfs #(btrfs filesystem df /btrfs) --- btrfs f us /btrfs #(btrfs filesystem usage /btrfs) --- btrfs f sh /btrfs #(btrfs filesystem show /btrfs) --- btrfs d u /btrfs #(btrfs device usage /btrfs) --- btrfs d st /btrfs #(btrfs device stats /btrfs)Рекомендую почитать
https://help.ubuntu.ru/wiki/btrfs
https://wiki.archlinux.org/title/Btrfs_(Русский)

Stanislavvv
00.00.0000 00:00+1Собственно, у меня из вопросов:
1) как относится к бедам на диске? ext4 можно при этом смонтировать в r/o даже если беды там, куда пытался накатиться журнал (-o noload) и потом смонтировать. Про бекапы не надо - они не делаются каждую секунду.
2) как относится к внезапным выключениям компа (aka бекап диска снапшотами снаружи вм)? ext4/xfs - нормально.

suprimex
00.00.0000 00:00Все ещё жду стабильной работы с RAID5. На данный момент RAID5 скорее не работает , чем работает, в отличии от MIRROR (пользую уже несколько лет , полет нормальный)
tuupic
00.00.0000 00:00Использовал пару лет raid5 для data и raid1 для metadata на 3х дисках. Проблем не было
suprimex
00.00.0000 00:00попробуйте поигратся с вышедшими из строя дисками, с битыми секторами, с их заменой (data на btrfs raid5) , с балансировкой после этого , и попробуйте не потерять при этом данные.
tuupic
00.00.0000 00:00Диск менял. Проблем не было, данные остались на месте. Конечно, это может быть ошибкой выжившего, но всё же проблем не было с raid5

sermart1234
00.00.0000 00:00Вот хочу домашний Nextcloud завезти. С зеркалированием данных. Вот думаю что лучше - btrfs или ext4 + mdadm? Планирую взять либо 2 HDD, либо 2 китайских SSD
rmrfchik
А зачем создавать таблицу разделов, если потом используется весь диск?
Mnemonic0
Есть мнение, что это такой фэншуй. Вцелом так правильно, вдруг потом что-то куда-то поедет. Как общий пример - нормас. Я одного не понял - зачем мне оно, если есть ext4. Я понимаю, что лимиты очень высокие - экзабайты и всё такое прочее, но и в ext4 - дофигилиард, я такое не съем.
SamOwaR
Мгновенные снимки, прозрачное сжатие.
aborouhin
Плюс scrub по расписанию, который автоматически исправляет побившиеся данные при наличии RAIDа, созданного средствами ФС, или как минимум позволяет понять, что они побились и надо бы восстановить из бекапа, заблаговременно.
aegoroff
А как быть с write amplification https://btrfs.readthedocs.io/en/latest/Hardware.html#solid-state-drives-ssd ?
Only users who consume 50 to 100% of the SSD’s actual lifetime writes need to be concerned by the write amplification of btrfs DUP metadata. Most users will be far below 50% of the actual lifetime, or will write the drive to death and discover how many writes 100% of the actual lifetime was.
честно говоря, только это останавливает от использования этой файловой системы - угроза повышенного износа дисков перевешивает все преимущества
rmrfchik
Использование /dev/sdb затирает таблицу разделов. Если уж таблица и раздел созданы, то использовать надо /dev/sdb1.