
Через любую высоконагруженную систему ежесекундно проходит огромный поток трафика. Релизы, хотфиксы, ddos-атаки, невалидные и ухудшающие эксперименты и многие другие события могут привести к проблемам, которые влияют на пользователей. Поэтому такие ситуации не терпят задержек.
Можно провести простую аналогию: если вы чем-то заболели, то лучше узнать об этом как можно раньше и тем самым минимизировать побочные эффекты после и в процессе выздоровления. Так и в сервисе: будь то баннерная крутилка, поиск, маркетплейс или онлайн-доставка пиццы.
Меня зовут Владимир Точилин, я работаю в группе развития рекламных продуктов и стабильности. Вместе со своим коллегой, Александром Самусенко, я расскажу, как мы создали новый инструмент realtime-детекции разладок в проде рекламных технологий. Мы работаем с системой, где на отдельные кластеры нагрузка превышает 1000000 RPS.
Исследование причин аномалий — тоже занимательная задача, которую нам приходится решать повседневно, но сегодня сфокусируемся на том, как получилось максимально быстро «зажигать лампочку» при определённых проблемах в системе.
Историю будет интересно прочитать аналитикам, разработчикам и менеджерам любого уровня.
Про фрод и мониторинг
В любом сервисе можно придумать сотни метрик — рекламные технологии не исключение. Часть из них носят технический характер и их понимают только узкие специалисты, а часть понятна всем: например, показы, клики, деньги, CTR (конверсия показов в клики), CPC (стоимость клика). Мы внимательно следим за такими метриками, поскольку когда их поведение отличается от ожидаемого, в системе могут быть проблемы.
Давайте посмотрим на примеры такого необычного поведения.

 относительно здорового (зелёного)")
В обоих случаях видны характерные резкие падения метрик вниз, отражающие потенциальную проблему системы в первом случае и явную во втором — показы не могли упасть так резко из-за изменения поведения пользователей, это мы резко перестали показывать баннеры на площадках. Далее будем называть такие падения разладками. Разладки вверх тоже являются сигналом о том, что возможно что-то идёт не так.
Одной из особенностей интернет-рекламы является наличие мошенников, которые всячески пытаются истощить бюджеты рекламодателей, не принося реальных конверсий. Накрутку просмотров, кликов и конверсий ботами либо с помощью других механизмов мы называем фродом. Зачастую это происходит массово и видно на графиках невооружённым взглядом.
Борьбу с такими ситуациями ведёт наша система антифрода: она с помощью своих алгоритмов не даёт списывать деньги с рекламных кампаний за данные действия. Но её работа и сервисы биллинга увеличивают время получения данных о реальных показах, кликах и деньгах. В связи с этим у нас есть два вида трендов: чистые после антифрода и биллинга и быстрые до них.
К лету 2022 года у нас было два класса детекторов разладок:
Пул мониторингов на очищенных от фрода данных с лагом больше получаса. Их основной принцип работы основан на классических методах статистики: для выбранных случайных величин проверяем принадлежность доверительным интервалам, которые, в свою очередь, являются нестационарными функциями от сезонности с шагом 5, 10 или 30 минут. Чем меньше шаг, тем шире доверительный интервал и тем меньше время реакции.
Несмотря на высокую полноту пула, некоторые разладки система может поймать только через час и позже. В нашем понимании эти мониторинги достигли своего пика: можно увеличить их полноту, только сильно уменьшив точность и наоборот.
Пул мониторингов, который основан на том же принципе, но работает поверх быстрых данных. Из-за периодических наплывов фрода у них не самая высокая точность и низкая полнота. Подобного рода разладки (как на синем графике) нас не интересуют, потому что такой трафик будет обнулен — нет смысла лишний раз зажигать лампочку.

Точность мониторингов очень важна, иначе на них никто не будет реагировать. Если научиться различать реальные просадки на быстрых трендах от фродового шума, можно узнать о проблемах в среднем на полчаса раньше. Дебаг проблемы начнётся заметно раньше, а значит получится привести систему к здоровому состоянию с минимальными потерями.
Для мониторингов критично важны три характеристики: точность, полнота и время реакции. У существовавших алгоритмов на чистых данных были проблемы во времени реакции, а на данных с фродом — недостаточные точность и полнота.
Сделать явное статистическое правило с хорошими характеристиками полноты и точности на быстрых неочищенных данных практически невозможно, поэтому мы решили обучить классификатор. Эту задачу мы разбили на несколько этапов:
Собрать обучающие данные по логам.
Разметить разладки.
Придумать факторы, зафиксировать приёмочные метрики.
Обучить модель.
Построить регулярный процесс с поставкой данных.
Сделать пайплайн доразметки и дообучения.
Учим классификатор искать разладки
Сбор данных
Получение обучающей выборки с нуля оказалось самым трудоёмким этапом задачи. В качестве базы для подготовки датасета мы выгрузили из логов реальные тренды кликов по главным срезам с января 2021 года по август 2022 года. Причём мы выгружали как очищенные от фрода данные, так и «грязные».
Разметка должна была показывать классификатору, что такое хорошо, а что такое плохо, и таким образом отфильтровать фродовый шум в трендах. Фокусируемся только на раскладках вниз, т.к. разладки вверх тяжело отделить от наплывов фрода - на графиках они будут выглядеть одинаково. Оставим их поиск мониторингам по чистым данным.
Но размечать руками столько данных было безумно и нерационально. Поэтому для определения потенциальных разладок по чистым данным мы запускали аналог статистических мониторингов из первой группы с более узкими доверительными интервалами. Это нужно для того, чтобы в полученном для ручной разметки датасете получить recall ≈ 1. Все подсветившиеся таймстемпы были помечены как подозрительные.
Разметка данных
Потенциальные разладки мы выгрузили в таблицу и вместе с командой сделали экспертную разметку в несколько итераций. Но с первого подхода получилось неидеально, так как у каждого было немного разное понимание того, на что стоит звенеть.

В итоге вывели основное правило разметки: разладка в обучающей выборке должна быть заметна как на чистых данных, так и на зашумлённых.
После переразметки и выкидывания лишних точек получились наборы примерно по 40—50 разладок на каждом срезе. В процессе отладки помогла генерация pdf-файла с графиками рядов, помеченных как помеченных проблемные. Так было гораздо удобнее увидеть, что шло на вход модели, чем перепроверять внутренние дашборды по списку дат.
Так, например, удалось обнаружить, что в какой-то момент слетела сортировка точек в датафрейме, и вместо нормальных рядов на вход подавались битые последовательности точек.

Далее разметка соединялась с агрегатом по неочищенным данным, потому что именно они будут подаваться на вход классификатору. Таким образом мы получили датасет органических данных.

Модель
В качестве модели мы использовали CatBoost Classifier. Входные данные представляли собой табличку, в которой для значения кликов каждой точки мы добавляли хвост из кликов в предыдущих. К слову, для описания резких падений важнее не абсолютные значения кликов в точках, а безразмерные отношения между соседними, в особенности между последними.
dt_i = clicks_i / clicks_i-1 Все подобные переходы между соседними пятиминутками в выборке тоже были вынесены в признаки.
Помимо этого, мы выделили следующие факторы, чтобы модель могла разграничить здоровые и нездоровые тренды:
разница кликов с медианой за окно и модуль разницы;
СКО до последней точки и СКО с последней точкой;
отношение кликов к среднему за окно;
категориальные индексы пятиминуток, тридцатиминуток, часа внутри дня, а также день недели и
is_weekendдля обучения на стандартную сезонность трендов;отношение суммы кликов за последние 30 минут к предыдущим 30 минутам;
max(clicks/clicks_-1, clicks/clicks_-2, clicks/clicks_-3): если все отношения под максимумом сильно меньше 1, это признак явной проблемы.
Посмотрим на пример:

Похоже на разладку, но это не она — это «отплыв» фрода. При большом отношении кликов в предыдущей точке относительно данной (
dt_click_fall), разница с медианой до этой точки маленькая. По этому фактору можно различитьclick_median_diffи сделать вывод по хвосту, что это не просадка.
А вот это уже разладка. Здесь большой
dt_click_fallи значительный отрицательный дифф с медианойclick_median_diff.
Среди гиперпараметров Catboost классификатора особенно полезной была корректировка весов классов (class weights) для частичной компенсации дисбаланса.
В итоге у нас получилась вполне рабочая модель, которая могла отличить разладку от фрода. Вот метрики на первой итерации разметки и модели:

А это метрики после переразметки с доработкой CatBoost:

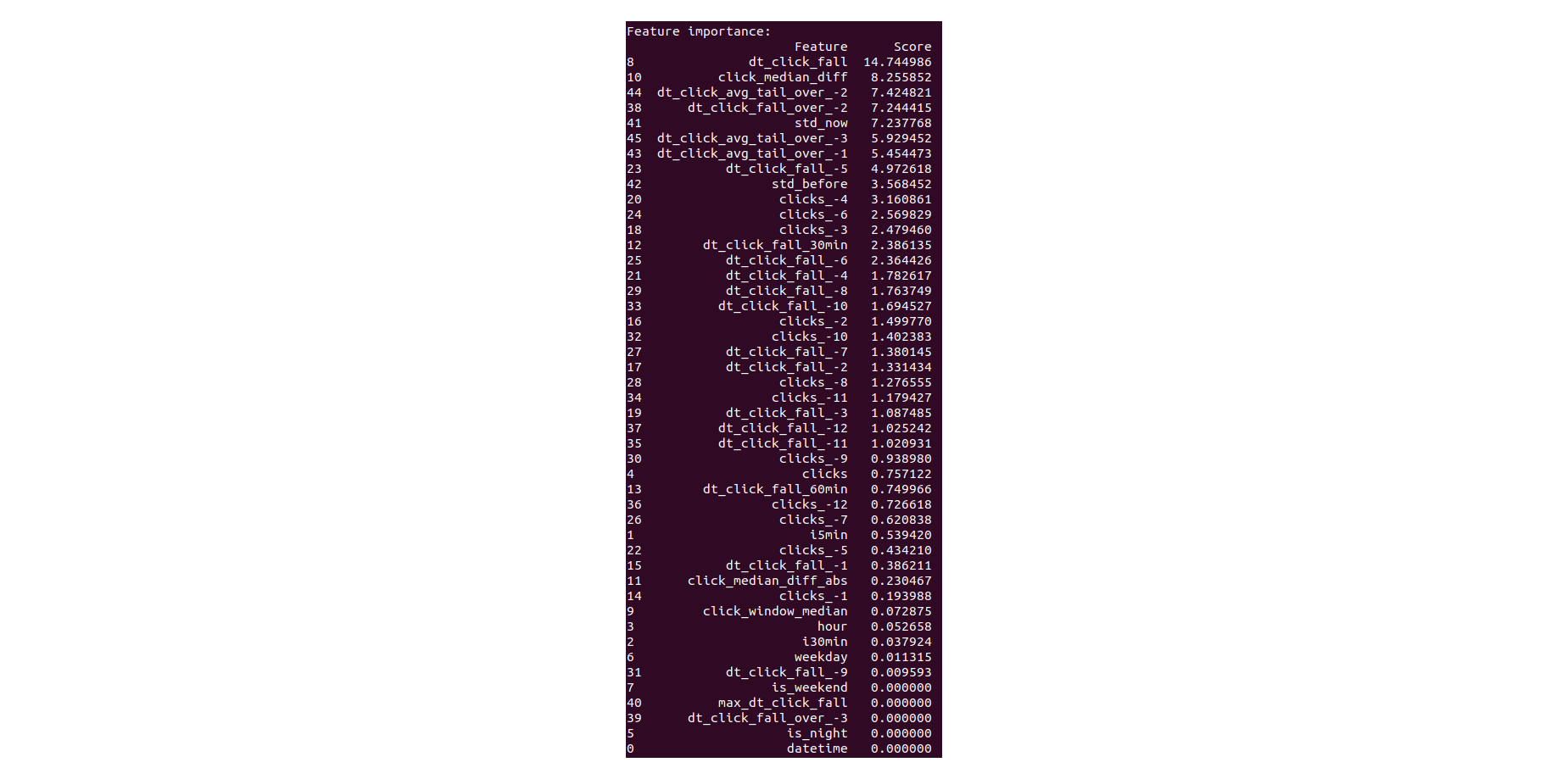
Итоговый Feature Importance на одном из срезов:
Генерация синтетики
После обучения CatBoost на органических данных мы получили модель, оповещающую о разладках в среднем два раза из трёх возможных. Этот результат намного лучше статистических мониторингов на шумных данных, но ведь можно и лучше!
Мы стали смотреть, с какими примерами классификатор справляется хорошо, а с какими не очень. К удивлению, мы обнаружили среди false negatives самые явные просадки тестовой части датасета, когда тренд падает в окрестность нуля, но не подсвечивается классификатором.
Чтобы подтвердить гипотезу о том, что модель плохо ловит именно сильные разладки, мы сгенерировали синтетический тестсет с примерами очень плохих разладок, например, когда после стабильного хвоста точка падает в ноль кликов. Результат воспроизвёлся.
Это было логично, ведь если мы не предоставили достаточно похожих примеров (хорошо, что таковых было мало в реальной практике) в обучающей выборке для fully-supervised-модели, такой тренд может классифицироваться как угодно.
Тогда мы выделили разные типы разладок, которые точно нельзя упускать. На их основе был сгенерирован пул синтетических разладок и добавлен в обучающую выборку.
Классы сгенерированных разладок:
Последняя точка упала в ноль.
Последняя точка упала кратно.
Несколько последних точек падают с разной амплитудой.
Аналогично перечисленным, но в процессе происходит наплыв фрода.
Случайный тренд из органики со сдвигом вниз последней точки.
Для трендов с первого по четвёртый выбирался рандомный base_value в диапазоне допустимых значений для кликов. У обычных точек были значения — base_value + random_noise, а разладочные по формулам опускались вниз — coef * (prev_value + random_noise).
А ещё в датасете поддерживался инвариант разладки, что она хотя бы на 5% ниже предыдущей точки, даже если предыдущая тоже разладочная.

Финальные метрики после добавления синтетики стали намного лучше:

С учётом погрешностей в разметке и пограничных случаев, единичный precision до этого этапа свидетельствовал о переобучении. При этом был значительный прирост в recall.
Быстрая статистика и регуляризация, настройка сообщений

Для получения прод-решения мы дополнительно наладили сбор данных из источников быстрой статистики и собрали граф, который запускает классификаторы по нашим срезам. Регулярный процесс дёргает граф каждые пять минут в дневное время — ночью тренды более шумные и реагировать ASAP нет смысла.
При обнаружении просадки система отправляет сообщение в Telegram дежурных с проблемным срезом и временем алерта.

Результаты
С начала работы детектора в середине сентября 2022 года были выявлены десятки инцидентов разных масштабов с минимальным лагом по времени. Среди них были даже такие, на которые не среагировали мониторинги по чистым данным. То есть раньше мы бы их просто упустили и потенциально продолжили жить с багом в системе.
В итоге мы получили процесс, который значительно ускорил нашу реакцию при разладках и увеличил полноту пула мониторингов, не потеряв в точности. Среди дальнейших планов развития системы мониторингов — создать готовое решение, которое позволит любому менеджеру, аналитику или разработчику задать простой конфиг и узнавать о проблемах на произвольном выбранном срезе с большой полнотой, точностью и лагом не более часа с помощью наших алгоритмов.
thevlad
Добавлю, лишь что это все давно живет в статистике, в до ML эпоху, под кейвордом change point detection
tochillin Автор
Привет! Дело в том, что статистический change point detection фолсит при резком наплыве/отплыве фродовых кликов, поэтому использовать его для лампочки о том, что __все горит_ было нельзя
thevlad
Насколько я понимаю, в современных подходах к change point detection, так же как и в статье используется бинарный классификатор.