

В научно‑популярных статьях и докладах, обучающих материалах по системам компьютерного зрения упор нередко делается на основную компоненту — тяжелые (или не очень) нейронные сети, которые неким волшебным образом обрабатывают картинку, и на выходе отдают результат.
Однако каждый ли вход в сеть стоит обрабатывать? Обучающие датасеты заранее подобраны и размечены, мусора и шума там чаще всего относительно мало, чего нельзя сказать о данных на входе в реально работающие системы. Особенно если данные загружаются обычными пользователями.
Мы не можем гарантировать, что сеть корректно обработает любой вход. Да, есть способы оценить, насколько модель уверена в своем ответе, но уже после обработки входа, когда мы потратили вычислительные ресурсы. Можем ли мы сказать заранее, что корректно обработать изображение не получится, что оно скорее всего не содержит достаточно информации? Давайте попробуем разобраться на примере реальной задачи.
Итак, мы продолжаем цикл статей о создании CarDamageTest — сервиса дистанционной оценки технического состояния автомобилей на основе фото‑ и видеоматериалов. Сегодня мы познакомимся с задачей image quality assessment — оценкой качества изображения.
В статье вы узнаете, зачем системам компьютерного зрения вообще нужна оценка качества входа, когда с ней лучше, чем без нее, как ее построить и какие проблемы могут возникнуть в процессе.
Первая половина статьи носит скорее развлекательный характер, тогда как вторая половина рассчитана на начинающих специалистов в компьютерном зрении (хотя вполне может быть полезна и более опытным коллегам) и просто интересующихся обработкой изображений.
Мотивация - а давайте сделаем свой сервис?
Для начала определимся, зачем нам вообще строить лишний модуль на входе. Разве нейронка не может сама определить, «нравится» ей вход или нет? А может, можно «скормить» изображение сети, а затем определить по выходу, мусор там был или нет?
Давайте представим программиста Васю, который хочет сделать приложение на смартфон. Вася немного увлекается ML и хочет применить знания на практике. Приложение принимает на вход фотографию и оценивает, кот на фотографии или собака. Наш программист полон энтузиазма и без тени сомнения заходит на первую итерацию!
Готовые датасеты котопсов уже есть. Вася берет довольно маленькую доступную предобученную модель (хочется же легкое и удобное приложение), доучивает ее на нашем датасете. Метрики отличные! Пишется приложение, встраивается модель, проверяется на своем коте, вуаля! Все работает. Однако, первый же человек, которому Вася дает смартфон с приложением, неожиданно для него, фотографирует свой палец. А приложение говорит ему, что это кот. «Плохой ты, Вася, программист, и приложение у тебя негодное», — говорит знакомый, отдает обратно телефон и уходит по своим делам, оставляя Василия наедине со своими мыслями.
Ну, все ясно! У сети всего два выхода, один для кота, второй для собаки. Василий решает прикрутить третий выход для всего остального, тогда модель должна начать работать корректно. Парсит еще десять тысяч изображений из поисковика для чего угодно, кроме котов и собак, учит сеть и … метрики по котопсам падают. Очевидно, что распределение данных на входе в сеть стало шире, и ее (сети) емкости уже не хватает для построения более сложных правил. Вася увеличивает размер сети. Учится она уже дольше (ведь докинули еще десять тысяч фотографий), размер приложения стал больше, работает оно дольше, но на фотографию пальца оно уже корректно отвечает, что ни кота, ни собаки тут нет. Наш программист приходит в гости к своему другу и дает ему приложение. А друг берет и наводит его на диван, на котором в обнимку спят кот и собака. Приложение отвечает, что на картинке кот. «Плохой ты, Вася, программист, и приложение у тебя неприглядное», — говорит наш товарищ, отдает обратно телефон и уходит на кухню за горячими напитками, оставляя Василия наедине со своими мыслями.
-
Действительно! На картинке может быть много котов или собак, или одновременно коты и собаки. Василий видит два варианта: можно прикрутить к классификатору еще один выход, который говорил бы, что на картинке больше одного животного. А можно заменить классификатор на детектор. Тогда детектор бы выделял на фотографии рамкой кота или собаку и делал подпись. Для первого варианта Васе придется самому делать датасет, и от этого ему становится грустно. Для второго варианта датасет уже есть. Да и предобученные модели, определяющие котов и собак, тоже есть. Проблема с пальцем решается сама собой — его модель просто не будет детектировать. Сделал! Дал приложение коллеге с работы. А у коллеги на смартфоне камера хуже, чем на Nokia 7700. Приложение видит котов и собак повсюду! Но только не там, где они реально есть. Проверять приложение на штанах коллеги Василий не рискнул.

Штаны коллеги Василия Страдающий от бренности бытия программист докидывает все больше и больше данных в модель. Применяет сильные аугментации — замыливает, затемняет, обрезает картинки. Вариативность обучающих данных растет просто неприлично. Чтобы сохранить метрики на приемлемом качестве, Вася увеличивает размер модели. И вот уже и учится модель не 10 минут, а весь рабочий день,
кажется пора покупатьDGX-2,да и приложение весит вместо пяти мегабайт все сто, хотя работать стало, безусловно лучше. Только никто ставить его не хочет, бесполезное. Вот если бы оно породу определяло… «Плохой я, наверное, программист, да и эти ваши нейронки все скверные. Пойду тиктоки снимать», — думает Василий, осознавая наконец сложность задачи.

Конечно, ситуация выше весьма утрированная (но это не точно). Подытожим. Несмотря на имеющиеся у нас возможности учить нейронные сети end‑to‑end (т. е. получили сырой вход и отдали готовый результат, с нюансами пусть сеть разбирается сама), такой способ построения системы имеет недостатки:
Предопределенная человеком структура, ограничения и правила вносят априорные знания о данных. Если такой структуры нет, сети придется строить их самостоятельно. Значит, сеть скорее всего будет больше.
В обучающем датасете обязательно должно быть достаточно примеров, на которых сеть сможет выстроить упомянутые правила. Если правил больше, то и данных, весьма вероятно, потребуется больше.
Для большого черного ящика страдает интерпретируемость: становится сложнее сказать, почему сеть приняла то или иное решение.
Конечно, плюсы у end‑to‑end систем тоже присутствуют. Сеть может построить правила, которые вручную запрограммировать очень сложно в разумное время. Или правила, о которых человек и не подозревал (в том числе правила, которых не существует). Если данных много, вычислительные возможности позволяют, а сама задача позволяет обучение без предварительной разметки человеком, то end‑to‑end системы могут быть довольно мощными, за примерами далеко ходить не надо: последние успехи генеративных моделей действительно впечатляют.
Если же данных мало (или вообще нет), данные имеют сложную структуру, а вычислительные ресурсы ограничены, то компонентные системы за счет априорных знаний проявляют себя во всей красе.
Наша система по оценке повреждений автомобилей состоит из множества модулей. Входные модули сужают вариативность поступающих данных. Один из них — модуль оценки качества изображения, наряду с другими, которые определяют наличие автомобиля, наличие необходимых ракурсов и т. д. Меньше вариативность данных — меньше нужно собственно данных для обучения модели, да и сама модель тоже будет меньше и быстрее.
Фактически, в основные модули, которые ищут повреждения, попадают только те изображения, на которых в принципе можно найти повреждения, и эти изображения качественные настолько, чтобы мы были уверены в результате.
Хорошо, с необходимостью оценки качества изображений разобрались. А какие вообще есть способы оценки качества изображений?
Методы оценки качества изображений
Вообще, методы оценки качества отдельных изображений можно разделить на три большие группы:
Референсные (Full‑reference). Если у нас есть исходная картинка и «испорченная» картинка, то мы можем измерить, насколько конкретно плохая картинка дальше от хорошей по каким‑либо критериям. Сюда относятся, например PSNR и SSIM.
Полуреференсные (Reduced‑reference). У нас есть «испорченная» картинка и некоторая информация, извлеченная из оригинального изображения (бинарные маски, негативы, статистики о распределении цвета и пр). Или только информация, извлеченная из обоих изображений, без наличия самих изображений.
Нереференсные (No‑reference). Есть только одно изображение, качество которого нужно измерить. Здесь есть как продвинутые методы типа BRISQUE, так и попроще, вроде оценки контрастности.
Нас интересуют нереференсные методы. С ними все тоже непросто. Мы, как настоящие ML инженеры, можем забить все гвозди микроскопом собрать датасет с «плохими» картинками и обучить очередной классификатор. Что же нас останавливает? По большому счету это не решение проблемы, а эскалация ее на один уровень выше. Ведь мы по‑прежнему не знаем, как именно отличать плохие изображения от хороших, а значит, не можем разметить датасет. Размечать «на глаз», очевидно, плохая идея. Ведь модели не «видят» также, как человек, а значит и ориентироваться на человеческий глаз мы не можем. К тому же это субъективная история, зависящая от разметчика.
Также, при бинарной постановке задачи (т. е. хорошая или плохая картинка), мы не сможем объяснить пользователю, почему мы не приняли эту фотографию и как ему все‑таки снять свою машину, чтобы быть уверенным в результате.
Ах да, мы еще не обозначили требования к системе оценки качества изображений? Ну тогда…
Требования к модулю оценки качества
Итак, мы хотим:
Чтобы фотографии, на которых модель (например, сегментации повреждений) будет работать плохо, в эту модель не попадали.
Внятно объяснить пользователю, почему то или иное изображение было отклонено, и дать совет, как это исправить.
Оно должно работать быстро. Мы также работаем с видео, а в видео много кадров, поэтому мы хотим их отфильтровать за минимальное время.
Желательно, чтобы все работало на CPU просто потому, что инференс на GPU дороже.
Закатаем рукава
По п.1 наших требований снова напрашивается решение: а давайте соберем и разметим некий датасет для этой модели (сегментации повреждений), проверим метрики на каждом изображении, и те изображения, на которых модель будет работать плохо, и будут считаться плохими? Резонно. Однако, во‑первых, где гарантия того, что мы сможем собрать в нашем датасете достаточно граничных случаев для генерализации моделью‑фильтром? Во‑вторых, покроем ли мы все возможные граничные случаи? И как проверять итоговое решение? Собрать второй датасет? Но ведь он будет смещен точно также. К тому же, мы не выполним п.2 требований.
Давайте посмотрим на проблему с другой стороны: а что вообще может пойти не так? Ведь мы знаем, что снимать автомобиль будут на камеру смартфона. Исключим моменты, когда на кадре вообще нет автомобиля или его части, или автомобиль будет перекрываться препятствием, или он будет слишком грязным, или погребен под снегом — этим будут заниматься другие модули. А мы сосредоточимся на качестве изображения. Что у нас остается?

Хороших новостей сразу две. Можно заметить, что такие артефакты легко доступно объяснить пользователю: «изображение слишком смазанное» или «автомобиль плохо освещен». А еще все эти проблемы можно измерить численно.
Нам понадобится Python (3) и библиотеки numpy, opencv, albumentations.
import numpy as np
import cv2
import albumentations as A
def read_image(path: str) -> np.ndarray:
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return imgРазмытие
Строго говоря, заблюренной может быть не вся картинка, а только задний фон, или только автомобиль. Можно построить карту размытия, как описано в работе LBP‑based Segmentation of Defocus Blur, и сопоставить ее с положением автомобиля на изображении.
")
Но не будем пока все усложнять, и для первой версии рассмотрим очень простой метод:
def blur_score(img: np.ndarray) -> np.float64:
return cv2.Laplacian(img, cv2.CV_64F).var()Он оценивает блюр по всему изображению. Если считать блюр после детекции, когда автомобиль вырезается из полного изображения, то работает не сильно хуже более сложных методов.
Для проверки методов будем использовать аугментации из библиотеки albumentations. Возьмем относительно чистое референсное изображение и будем его ухудшать, проверяя результат численно и визуально. В качестве параметра, контролирующего ухудшение, используем параметр blur_limit функции Blur в виде blur_limit=(kernel_size, kernel_size).

График зависимости blur score от размера ядра
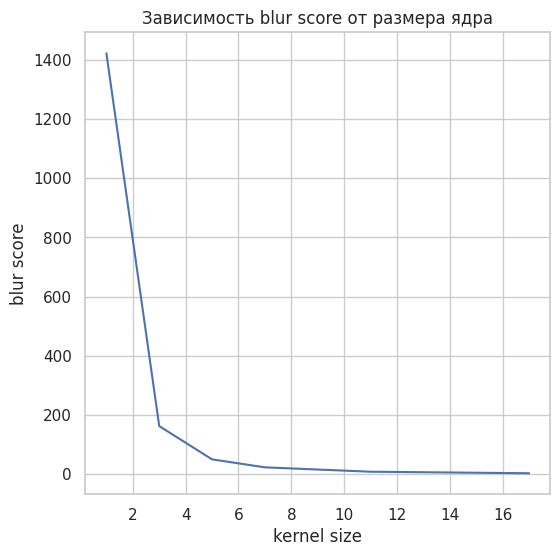
Как видим, зависимость нелинейная, и blur_score быстро падает с ростом размера ядра. Следует помнить, что нелинейные зависимости сулят дополнительные сложности при подборе порогов. Посмотрим, как blue_score поведет себя при фокусе.

Наша функция реагирует на изменения, но, как и ожидалось, значение пропорционально «смазанной» площади изображения. Поэтому, если высок риск получения сервисом подобных изображений, стоит рассмотреть более продвинутые способы оценки блюра.
Затемненность
Чем отличается темная картинка от светлой на уровне пикселей? Очевидно, интенсивностью. Поэтому давайте просто конвертируем изображение в черно‑белое и посчитаем среднее.
def gray_score(img: np.ndarray) -> float:
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
rating = cv2.mean(img)[0] / 255.0
return ratingПроверить тоже просто - будем умножать значения пикселей на коэффициент меньше 1.
def darken_image(img: np.ndarray, mult: float = 1.0) -> np.ndarray:
augmented_image = (img * mult).round().astype(np.uint8)
return augmented_image
Понятно, что зависимость между multiplier и gray_score будет линейной, но проверим для порядка.
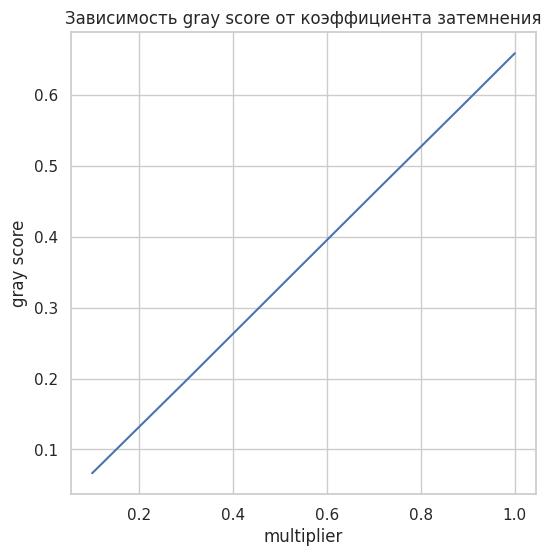
Недостаток тот же, что и у функции по оценке блюра: часть изображения может быть светлой, а часть темной. Мы же оцениваем среднее, что может дать ложный результат.
Контрастность
Контрастность - это разница в яркости между соседними светлыми и темными участками изображения. Посчитать контрастность изображения можно по-разному. Для демонстрации возьмем RMS метод. Перед расчетом контрастности лучше немного заблюрить изображение, так результаты будут более стабильными.
def contrast_score(
img: np.ndarray,
blur_kernel: tuple[int, int] = (11, 11)
) -> np.float64:
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
blurred = cv2.GaussianBlur(gray, blur_kernel, 0)
contrast = blurred.std()
return contrastДля изменения контрастности можно воспользоваться этим советом:
def adjust_image_contrast(
img: np.ndarray,
contrast: float = 1.0
) -> np.ndarray:
brightness = int(round(255*(1-contrast)/2))
augmented_image = cv2.addWeighted(img, contrast, img, 0, brightness)
return augmented_image
График зависимости contrast score от коэффициента затемнения
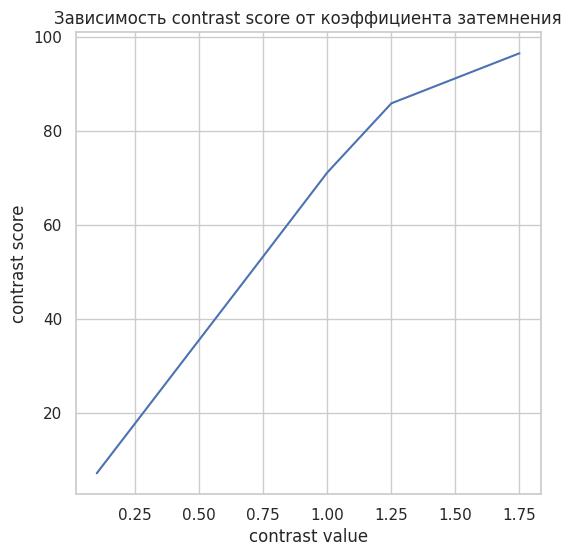
Зависимость скора от контрастности также линейная, ломается только на этапе насыщения.
Засветка
Строго говоря, свет может быть прямым или отраженным. Прямой - когда свет бьет прямо в камеру, отраженный видно на 4 изображении выше. Эффекты от такого воздействия могут отличаться на разных камерах с разными настройками.
Подходы тоже могут быть разными. Например, можно находить яркие места на изображении, а затем считать их суммарную или максимальную площадь.

Для примера возьмем самый простой подход. Конвертируем изображение в HSL цветовую модель, и посчитаем среднее по светлоте (канал L). Возможно, это не в точности то, что мы хотим, но в качестве базового решения может сработать.
def luminance_score(img: np.ndarray) -> np.float64:
img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
luminance = img.reshape(-1, 3)[:, 1].mean()
return luminanceПросто поднимать luminance мы не будем: очевидно, что зависимость будет линейной, и наш скор будет прекрасно детектировать изменения. Вместо этого, снова воспользуемся albumentations, и функцией RandomSunFlare. Эта аугментация помещает на изображение случайную солнечную вспышку. Нам случайность не нужна, поэтому зафиксируем все параметры, кроме радиуса вспышки.
def image_sunflare(img: np.ndarray, radius: int = 100) -> np.ndarray:
transform = A.RandomSunFlare(
flare_roi=(0.7, 0.2, 0.71, 0.21),
angle_lower=0.5,
angle_upper=0.51,
num_flare_circles_lower=2,
num_flare_circles_upper=3,
src_radius=radius,
always_apply=True
)
augmented_image = transform(image=img)['image']
return augmented_image
Хорошо. А что насчет более темного изображения?

При радиусе вспышки в 500 для второго изображения выход функции равен 150, тогда как для снежного изображения без вспышки функция оценивает засветку в 170. Поэтому для фильтрации изображений с яркими бликами данный метод не подходит, что ожидаемо: глобальный метод вряд ли будет адекватно оценивать локальные артефакты. Тем не менее, он отбросит сильно засвеченные изображения. Справедливости ради, в реальности такие изображения будут приходить очень редко, поэтому для первой итерации можно эту историю пока оставить в таком виде.
Отчасти этой же проблеме (смещенной оценке локальных артефактов) подвержены глобальные методы по оценке контрастности и затемненности — темные машины будут в среднем всегда получать скоры хуже, чем светлые. Однако, физику тоже никто не отменял: для оценки светлой машины в принципе нужно меньше света, чем для темной.
Хорошо, с методами оценки изображений для первой итерации определились. Что дальше?
Калибруем фильтр
Для начала договоримся о терминологии.
Целевая модель — это модель, под которую мы делаем фильтрацию изображений. Например, если мы хотим сегментировать повреждения, тогда целевой моделью будет сегментатор. Мы должны уметь измерять интересующую нас метрику целевой модели.
Что делать, если целевых моделей несколько? Например, после фильтров работает каскад моделей. Тогда нужно разработать метрику, которая учитывает выход со всего каскада, и калибровать фильтр уже на ней.
Оценочные функции — это наши методы оценки качества изображения: gray_score, luminance_score и т. д.
Мы научились численно измерять качество изображений. Теперь нужно как‑то установить пороги, при пересечении которых мы будем изображение отфильтровывать, а пользователю возвращать фидбэк — что отфильтровано, почему и как это исправить. Либо, если входящих изображений несколько, а ответ нужно дать только один, мы можем выбрать, какое изображение использовать.
Для поиска порогов нам нужен калибровочный датасет для целевой модели. Для начала вполне сойдет валидационный датасет, на котором проверяется целевая модель при обучении, хотя нужно помнить, что оценка на нем может быть смещена.
Наивный метод
Здесь мы предполагаем, что оценочные функции между собой не коррелируют, что, по крайней мере в нашем случае, неправда. Но на то он и наивный метод.
Выбираем одну оценочную функцию и воздействующую на оценки этой функции аугментацию изображений. Например, оценочной функцией будет contrast_score, измеряющая контрастность изображения, а аугментацией adjust_image_contrast, которая эту контрастность изменяет.
Измеряем метрику целевой модели на калибровочном датасете, а также среднее значение оценочной функции на этом датасете. Метрикой может быть F1, IoU, mAP, или любая другая метрика, которая нас интересует.
Слегка «портим» датасет выбранной аугментацией. т. е. проходимся по всем изображением функцией adjust_image_contrast, установив параметр contrast чуть меньше или больше единицы. Снова выполняем пункт 2.
Еще больше «портим» датасет, т. е. проходимся по исходному датасету функцией adjust_image_contrast, изменив contrast немного больше, чем в прошлый раз. И снова замеряем метрику целевой модели. и т. д.
В результате мы можем построить функцию зависимости метрики целевой модели от значения оценочной функции. Из которой, исходя из допустимого падения метрик, можно выбрать пороги. Повторяем для каждой оценочной функции.
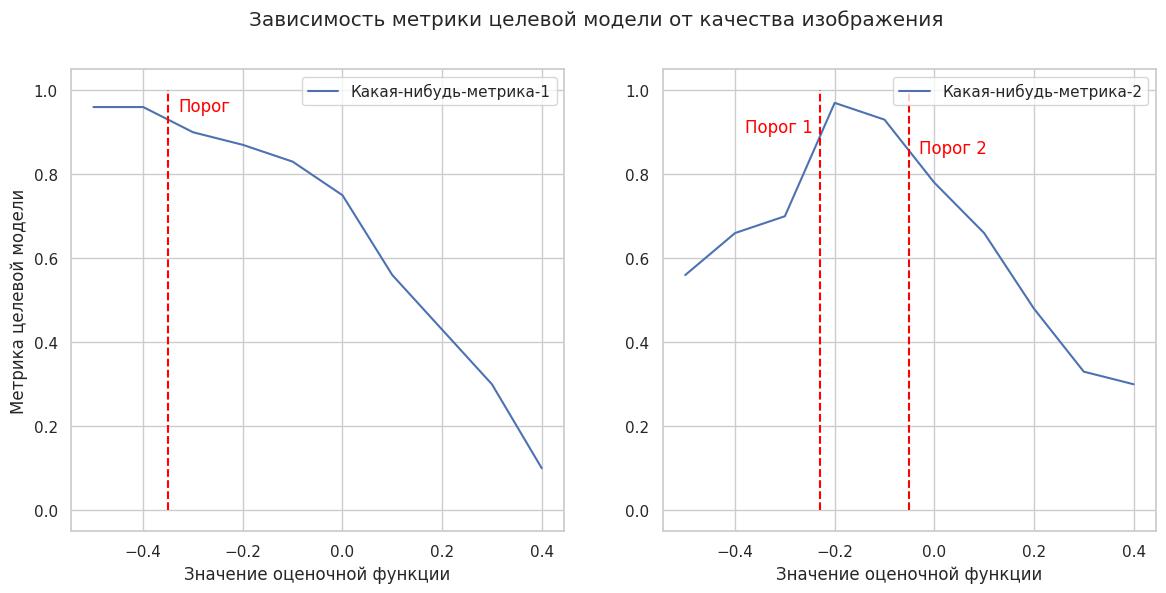
К достоинствам данного метода можно отнести простоту и скорость реализации, к недостаткам, как и было сказано, низкую точность, т.к. метод не учитывает взаимосвязь оценочных функций. Также придется вычислять метрику по датасету каждый раз при изменении силы аугментации, что может быть долго при большом датасете и большом количестве оцениваемых параметров изображения.
Метод аппроксимации
С точки зрения математики, мы пытаемся аппроксимировать некую функцию, которая принимает на вход значения оценочных функций, а на выход отдает метрику целевой модели. Зная рельеф функции в окрестности точки максимума (или минимума, в зависимости от того, с какой метрикой мы работаем), можно выбрать пороги оценочных функций.
Здесь можно действовать несколькими способами. Если метрика целевой модели подразумевает достаточно гладкую оценку качества каждого сэмпла (например, IoU), то можем оценивать каждый сэмпл независимо, и наша задача упрощается.
-
Проходим по калибровочному датасету, фиксируя значение метрики на каждом сэмпле. В качестве метрики целевой модели возьмем IoU.
Файл
IoU
1.jpg
0.68
2.jpg
0.88
-
«Портим» каждый сэмпл случайными аугментациями (случайные аугментации, случайные комбинации аугментаций и случайная сила аугментаций), записываем значения всех оценочных функций и значение метрики. Прогоняем датасет N итераций. На выходе получаем следующую таблицу. В таблице для примера указаны все рассмотренные нами оценочные функции.
Файл
blur
contrast
luminance
gray
IoU
1.jpg
312
30
97
0.45
0.67
1.jpg
351
22
98
0.20
0.59
1.jpg
764
30
67
0.50
0.34
2.jpg
76
10
52
0.54
0.88
2.jpg
45
12
63
0.33
0.76
Определяем порог падения метрик — насколько мы готовы пожертвовать метриками ради удобства пользователя. Например, мы готовы допустить снижение метрик до 10%, в противном случае изображение возвращаем. Тогда в примере выше для 1.jpg минимальным значением IoU будет 0.612, а для 2.jpg 0.792.
-
Формируем табличный датасет. Каждая строка в нем, это «испорченный» сэмпл из калибровочного датасета с зафиксированным снижением целевой метрики и значениями оценочных функций. Переходим к задаче бинарной классификации. Классом будет снижение метрик не выше порога: 1 — метрики остались в коридоре 10%, 0 — ниже порога. IoU^ — это порог метрики, рассчитанный из самой первой таблицы в п.1 умножением на 0.9.
Файл
blur
contrast
luminance
gray
IoU
IoU^
target
1.jpg
312
30
97
0.45
0.67
0.612
1
1.jpg
351
22
98
0.20
0.59
0.612
0
1.jpg
764
30
67
0.50
0.34
0.612
0
2.jpg
76
10
52
0.54
0.88
0.792
1
2.jpg
45
12
63
0.33
0.76
0.792
0
-
Строим на новом датасете интерпретируемую модель, например логистическую регрессию. Фичами для модели будут значения оценочных функций. Не забудьте удалить значения целевой метрики, ведь на реальных данных метрик не будет. Итоговая таблица для обучения модели будет выглядеть так:
blur
contrast
luminance
gray
target
312
30
97
0.45
1
351
22
98
0.20
0
764
30
67
0.50
0
76
10
52
0.54
1
45
12
63
0.33
0
Теперь, при поступлении изображения в наш сервис, мы можем получить значения оценочных функций, определить уровень риска и принять решение о дальнейших действиях. В случае, если мы изображение не принимаем, достаем из модели‑фильтра фичи, которые сильно повлияли на решение, и на их основе формируем фидбэк.
Хорошо, а что если метрика не подразумевает гладкую оценку каждого сэмпла? Например, у нас задача классификации, метрика целевой модели — F1. Эта метрика оценивает весь датасет целиком, на каждом сэмпле ее не посчитать. Навскидку можно предложить два варианта:
Перейти к оценке каждого сэмпла. Например, можно оценивать уверенность модели в классе при классификации.
Масштабироваться на уровень выше. Теперь, каждой строкой в табличном датасете для калибровки будет не отдельный сэмпл, а целый проход по всему датасету с фиксированными аугментациями. Фичами будут средние значения оценочных метрик по датасету. Этот вариант может быть вычислительно очень тяжелым, особенно в случае с нейросетями.
К достоинствам метода можно отнести довольно высокую точность. К недостаткам необходимость оценки каждого сэмпла, что не всегда возможно. Либо вычислительную сложность, если оценивать метрику на уровне всего датасета, а не отдельного сэмпла.
Статистические методы
Для оценки порогов можно воспользоваться статистическими тестами. Например, методом Learn then test (LTT). Суть метода заключается в множественных статистических тестах для каждого набора параметров (например, порогов оценочных функций). Нулевой гипотезой выступает превышение риском (который рассчитывается из выходов целевой модели) некоторого порога. Собственно, мы ищем набор параметров, отклоняющих нулевую гипотезу, не забывая делать поправку на множественную проверку гипотез.
К сожалению, на выходе мы скорее всего получим множество наборов параметров, среди которых все еще нужно выбрать лучший. К тому же необходимо определиться, как именно собирать наборы порогов для статистических тестов — это может быть случайное сэмплирование или изменение порогов по какому‑либо закону.
Заключение
Итак, мы выполнили поставленные требования. Научились отсеивать изображения, на которых целевая модель будет работать неудовлетворительно. Причем, делать это по понятным интерпретируемым критериям. Метод работает быстро, позволяя фильтровать изображения на дешевых CPU, легко распараллеливания вычисления и достигая высокой пропускной способности.
Мы описали базовый, но законченный подход к фильтрации изображений, который вы можете использовать в своем сервисе. Фильтрация изображений позволяет:
Ускорить работу сервиса за счет экономии вычислительных ресурсов, поскольку сервис будет обрабатывать запросы избирательно, не тратя вычисления на шум и «мусор».
Повысить качество ответов сервиса: пользователь оценивает работу искусственного интеллекта с точки зрения интеллекта естественного. Когда сервис отвечает на замыленное изображение, что оно замылено, вместо уверенного неправильного ответа, это повышает уровень доверия клиента.
Удешевить работу сервиса в случае избыточных поступающих сигналов. Если из каждой секунды видео обрабатывать два кадра вместо тридцати, то это даст возможность обслуживать в десяток раз больше запросов в единицу времени на том же железе. Оценка качества изображения выступает в роли критерия для выбора лучших кадров.
Если вам интересно самостоятельно протестировать нашу систему фильтрации, вы можете легко сделать это в приложении CarDamageTest (Android/AppStore/AppGallery) на собственном или арендованном авто. Попробуйте снять автомобиль ночью или при ярком свете дня, за забором или в сугробе снега, а может, вы захотите обмануть систему и снять разные автомобили? Всегда будем рады обратной связи.
P. S. У некоторых читателей, возможно, возник вопрос: а при чем тут сосиска из заголовка? А мы сами не знаем:) Этот заголовок предложила GPT после ознакомления со статьей. Почему бы и нет?
Ссылки
Датасет для классификации котов и собак: https://www.kaggle.com/competitions/dogs-vs-cats/overview
Задача детекции в компьютерном зрении: https://en.wikipedia.org/wiki/Object_detection
Common objects in context - открытый датасет для детекции: https://cocodataset.org/#home
Репозиторий open-source детектора YOLOv8: https://github.com/ultralytics/ultralytics
Пиковое отношение сигнала к шуму (PSNR): https://ru.wikipedia.org/wiki/%D0%9F%D0%B8%D0%BA%D0%BE%D0%B2%D0%BE%D0%B5_%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81%D0%B8%D0%B3%D0%BD%D0%B0%D0%BB%D0%B0_%D0%BA_%D1%88%D1%83%D0%BC%D1%83
Индекс структурного сходства (SSIM): https://ru.wikipedia.org/wiki/SSIM
No-Reference Image Quality Assessment in the Spatial Domain (BRISQUE): https://live.ece.utexas.edu/publications/2012/TIP%20BRISQUE.pdf
LBP-based Segmentation of Defocus Blur: https://www.cs.usask.ca/faculty/eramian/defocusseg/defocusSeg.pdf
Blur detection with OpenCV: https://pyimagesearch.com/2015/09/07/blur-detection-with-opencv/
Библиотека для аугментации изображений Albumentations: https://albumentations.ai/
Библиотека для обработки изображений OpenCV: https://opencv.org/
Библиотека для вычислений numpy: https://numpy.org/
Контрастность изображений: https://en.wikipedia.org/wiki/Contrast_(vision)#Formula
Detecting multiple bright spots in an image with Python and OpenCV: https://pyimagesearch.com/2016/10/31/detecting-multiple-bright-spots-in-an-image-with-python-and-opencv/
Logistic regression: https://en.wikipedia.org/wiki/Logistic_regression
Learn then Test: Calibrating Predictive Algorithms to Achieve Risk Control: https://arxiv.org/pdf/2110.01052.pdf
Multiple comparisons problem: https://en.wikipedia.org/wiki/Multiple_comparisons_problem
AnyLog
на первой картинке надо - увидел жигули когда снял очки!