
С этим докладом я выступал на недавней конференции VK Kubernetes Conf 2023. В нем рассказывается, какие правила безопасности в Kubernetes действительно необходимы, и разбираются пять шагов, которые помогают улучшить безопасность.

Актуальность вопроса в Kubernetes
Про безопасность знают все, но далеко не всегда делают всё правильно. В итоге нам приходится разбираться с разными последствиями этого.
Почему сегодня вопрос безопасности в Kubernetes приобрел такую остроту?
Ответ прост — Kubernetes уже давно перестал быть хайповой технологией. Сейчас это стандарт, который используется в крупном, малом и среднем бизнесе.

Различные исследования показывают: кластеров под управлением Kubernetes скоро станет еще больше.

Кажется, что чем выше их число, тем лучше. Kubernetes призван решить все наши проблемы: упростить операции, ускорить доставку, увеличить количество деплоев в день и т.д. Что может пойти не так?
В первую очередь на этапе внедрения новой для нас технологии мы сталкиваемся с недостатком экспертизы.
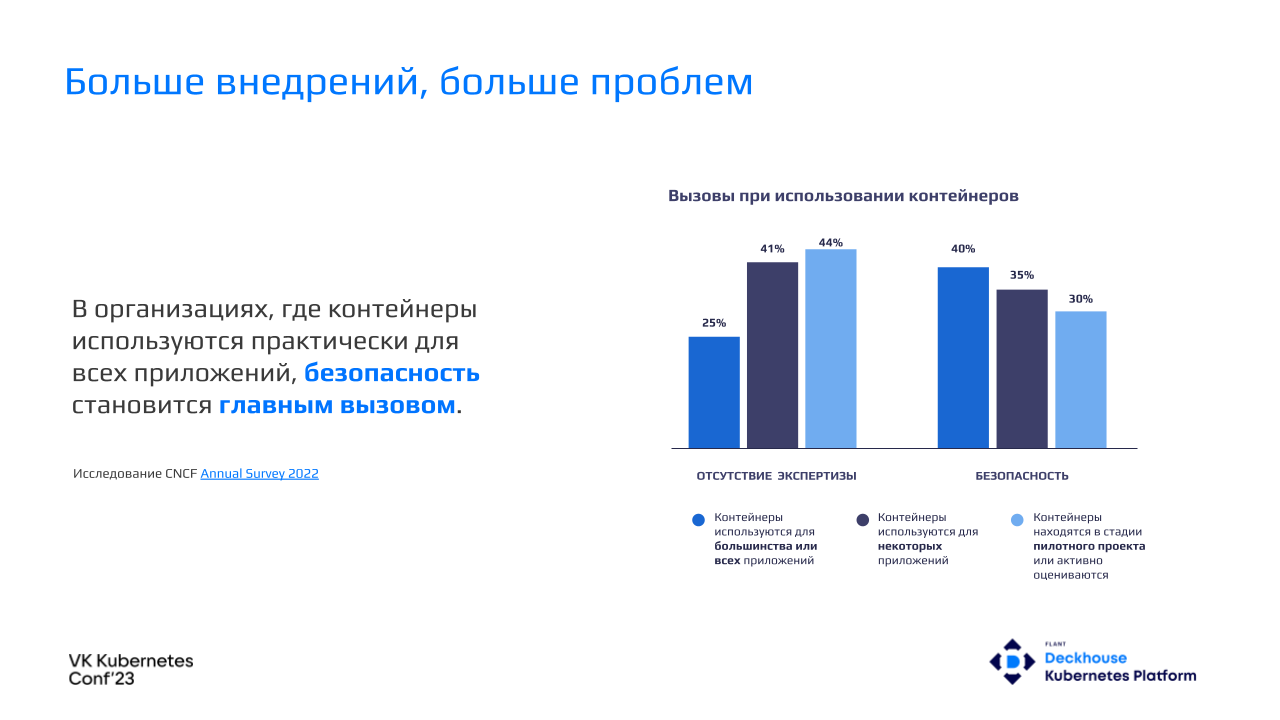
Накапливая ее и перенося все новые и новые рабочие нагрузки в кластер, мы начинаем задумываться о других проблемах. Зачастую в организациях, в которых контейнеры используются практически для всех приложений, безопасность становится главным вызовом.
Как показал опрос Red Hat, лишь 7% респондентов не сталкивались с инцидентами в области безопасности.

Kubernetes должен был ускорить развертывание приложений, но в итоге более половины респондентов откладывали или задерживали деплой приложений из-за проблем с безопасностью в кластере.

Как же быть? Как перестать беспокоиться и начать получать удовольствие от Kubernetes? Как начать использовать его по-максимуму?
О стандартах безопасности
Есть множество стандартов безопасности (международные, отечественные), которые говорят нам, как правильно делать Kubernetes.
Одним из самых известных является Kubernetes CIS Benchmark — стандарт от Center for Internet Security.

В нем содержатся конкретные инструкции о том, как сделать кластер безопасным (вплоть до того, какие флаги указать у API-сервера). Описывается, как правильно настроить компоненты control plane, конфигурацию, worker-узлы, политики и так далее.
Еще есть стандарт от Payment Card Industry Security Standards Council (вышел в 2022 году).

В него входят такие крупные платежные системы, как Visa и MasterCard. От CIS Benchmark он отличается тем, что ограничивается рекомендациями о том, как правильно выстроить процессы относительно средств оркестрации в целом. В нем нет советов конкретно для Kubernetes.
Также в 2022 году ФСТЭК выпустила свой стандарт с требованиями по безопасности к средствам контейнеризации.

Кроме того, есть множество других стандартов как от коммерческих, так и от некоммерческих организаций. Их дополняют спецификации и всевозможные чек-листы от компаний, производящих софт, связанный с безопасностью Kubernetes.
Общая идея всех стандартов
Стандартов много, но все они пересекаются между собой и имеют единый смысл. Заключается он в следующем: рассматривать безопасность в Kubernetes следует послойно.

Модель 4C называется так по первым буквам каждого слоя: Code, Container, Cluster и Cloud. В ней для каждого слоя приводятся свои рекомендации по безопасности.

Начинаем со слоя Code и организуем защиту используемых приложений и библиотек. Далее контролируем среду исполнения, ограничиваем доступ к Kubernetes control plane и узлам кластера, и, наконец, настраиваем безопасный доступ к API облака и инфраструктуре.
Понятно, что когда у злоумышленников есть доступ к API облака, неуязвимость кода в контейнере теряет всякое значение: они просто удалят виртуальные машины, скопируют диски и так далее.
Далее мы поговорим о слоях Code, Container и Cluster.
Пять шагов к безопасности в Kubernetes
Изучив все эти стандарты, проанализировав спецификации, пройдя кучу опросников служб информационной безопасности (мы внедряем нашу Kubernetes-платформу у многих Enterprise-клиентов; для этого сначала приходится общаться со службами ИБ и выполнять их требования), мы поняли, что 5 шагов к безопасности достаточно, чтобы удовлетворить 90% требований.

Рассмотрим их подробнее.
Шаг первый: корректная конфигурация кластера Kubernetes

Прежде всего необходимо запустить пресловутый CIS-бенчмарк и проверить, насколько настройка узлов и control plane соответствует тому, что описано в стандарте. Самая распространенная реализация этого стандарта — kube-bench: запустили, прогнали, посмотрели файлы, предупреждения, исправили их, и можно идти дальше.
При возможности следует ограничить сетевой доступ к Kubernetes API, настроить white-листы, включить доступ только через VPN и так далее.
Каждый пользователь должен уникально идентифицироваться при доступе к Kubernetes API. Это нужно для последующего проведения аудита и понимания, кто и какие действия провел; также это пригодится для грануляции RBAC'ов.
Должны выдаваться только необходимые RBAC'и. Например, некий оператор в кластере получает список всех подов. В этом случае не нужно выдавать ему возможность видеть все секреты и тем более редактировать их.
Кажется, что все просто. Но давайте рассмотрим реальные примеры.
Как дела с managed Kubernetes обстоят у российских облачных провайдеров?

Я развернул кластеры у пары провайдеров и запустил CIS-бенчмарк. Ошибок и предупреждений практически не было (тестировались только worker’ы, т.к. не у всех провайдеров доступны control plane-узлы). Затем я посмотрел, как организован доступ в мой только что развернутый кластер — ведь взаимодействие со новым кластером мы всегда начинаем с получения доступа к Kubernetes API.
Скачав kubeconfig, я обнаружил, что внутри используется группа system:masters. При этом в первом пункте чек-листа по безопасности в Kubernetes четко указано: после развертывания кластера никто не должен в нем аутентифицироваться как system:masters.
Сертификат выписан на месяц: если кто-то украдет у меня этот kubeconfig, придется перевыпускать все CA в кластере, потому что отозвать доступ у группы system:masters без этого невозможно.
Как видим, даже облачные провайдеры нарушают базовые принципы, поэтому о них говорить всегда актуально.
Шаг второй: сканирование образов
Теперь настало время подумать о том, какой софт мы будет запускать в кластере, и сделать его хотя бы минимально безопасным. Самым простым решением кажется сканирование используемых образов.
Провести его можно на разных этапах: на этапе конвейера CI/CD, настроить сканирование registry по расписанию или сканировать все образы, которые используются в кластере. Для этого существует множество решений. Каждый выбирает сам, что ему больше подходит — self-hosted или SaaS. Самое главное — следовать базовым принципам.
После сканирования следует проанализировать его результаты.

Нужно смотреть критические проблемы, warning-инциденты, которые у нас возникают, разбирать найденные уязвимости. Самое главное здесь — подходить к вопросу с холодной головой: если мы нашли критическую уязвимость, это еще не значит, что ее можно эксплуатировать.
Также следует использовать базовые образы. Если у нас есть golden image, и мы нашли в нем CVE, то его достаточно просто заменить и перезапустить все CI/CD.
И самый мой любимый момент — не нужно тащить лишние зависимости. Например, всякие инструменты для дебага не должны оказываться в образах для production. Для компилируемых языков собираем артефакт, в нем компилируем бинарный файл, копируем его в golden image, и уже его запускаем в production. Чем больше лишних зависимостей, тем выше риск обнаружить в них CVE.
Шаг третий: сетевая безопасность
Итак, мы собрали приложение и подготовили его к работе. Теперь нужно подумать, как запускать его в нашем новом классном кластере Kubernetes.
И первым в голову приходит то, что нужно сделать его безопасным именно с точки зрения сети:
CNI в кластере должен поддерживать сетевые политики;
Ingress и egress-политики должны быть настроены для всех компонентов кластера;
все соединения по умолчанию должны быть явно разрешены.
На практике я сталкивался с тем, что клиенты обращаются к нам за аудитом. Говорят, что у них все хорошо, Kubernetes развернут, все ходят со своими сертификатами… В итоге мы и правда видим: у разработчиков есть доступ только в пространство имен stage.

При этом живут клиенты в «коммунальном» кластере — многие клиенты, в том числе Enterprise-уровня, разворачивают несколько больших кластеров, в которых stage и production существуют в рамках одного control plane. Разработчики спокойно хотят в stage, но оттуда могут попадать куда угодно, в том числе и в production-базы данных, потому что сегментация сети и сетевая изоляция отсутствуют.
Такое часто встречается на практике. Что с этим можно сделать?
У себя в платформе мы используем Cilium. В нем есть визуальный редактор, в котором буквально в три клика можно настроить подходящую политику. Она разрешит разработчику ходить только в рамках своего пространства имен и обращаться к Kubernetes DNS.
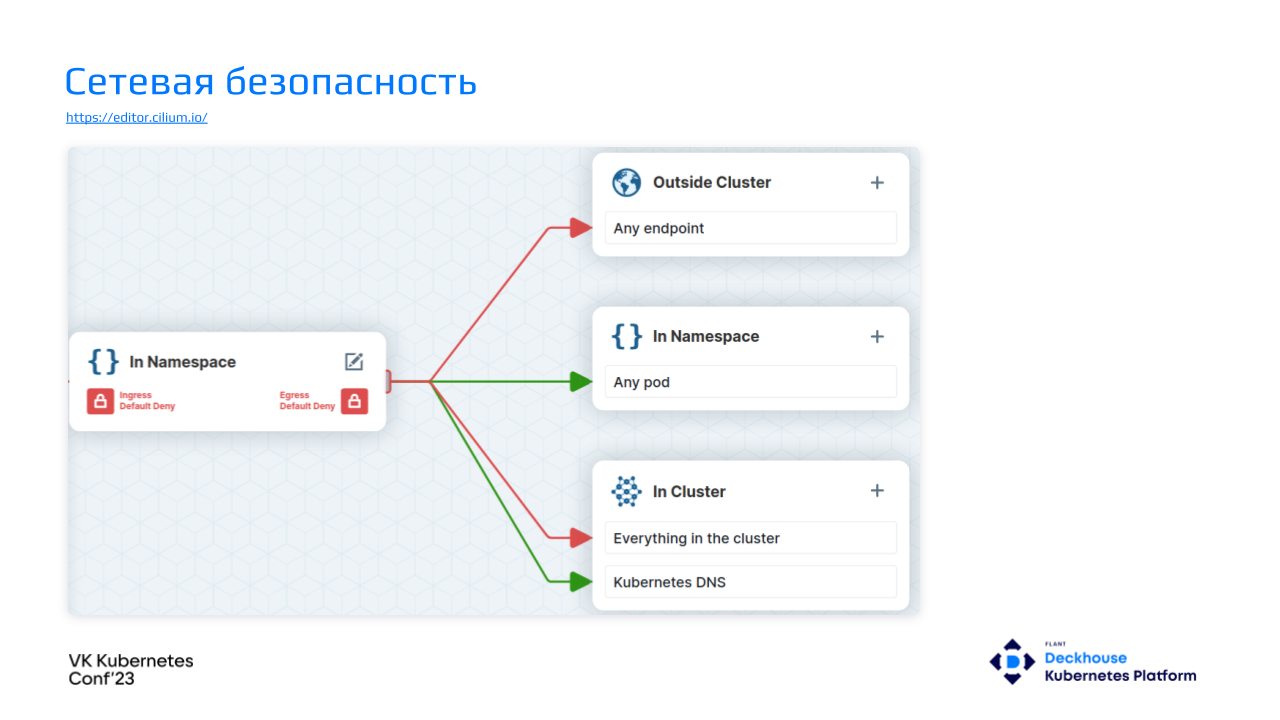
Вот так выглядит созданная egress-политика:
egress:
- toEndpoints:
- matchLabels:
io.kubernetes.pod.namespace: kube-system
k8s-app: kube-dns
toPorts:
- ports:
- port: "53"
protocol: UDP
rules:
dns:
- matchPattern: "*"
- toEndpoints:
- {}В данном случае она решает все проблемы.
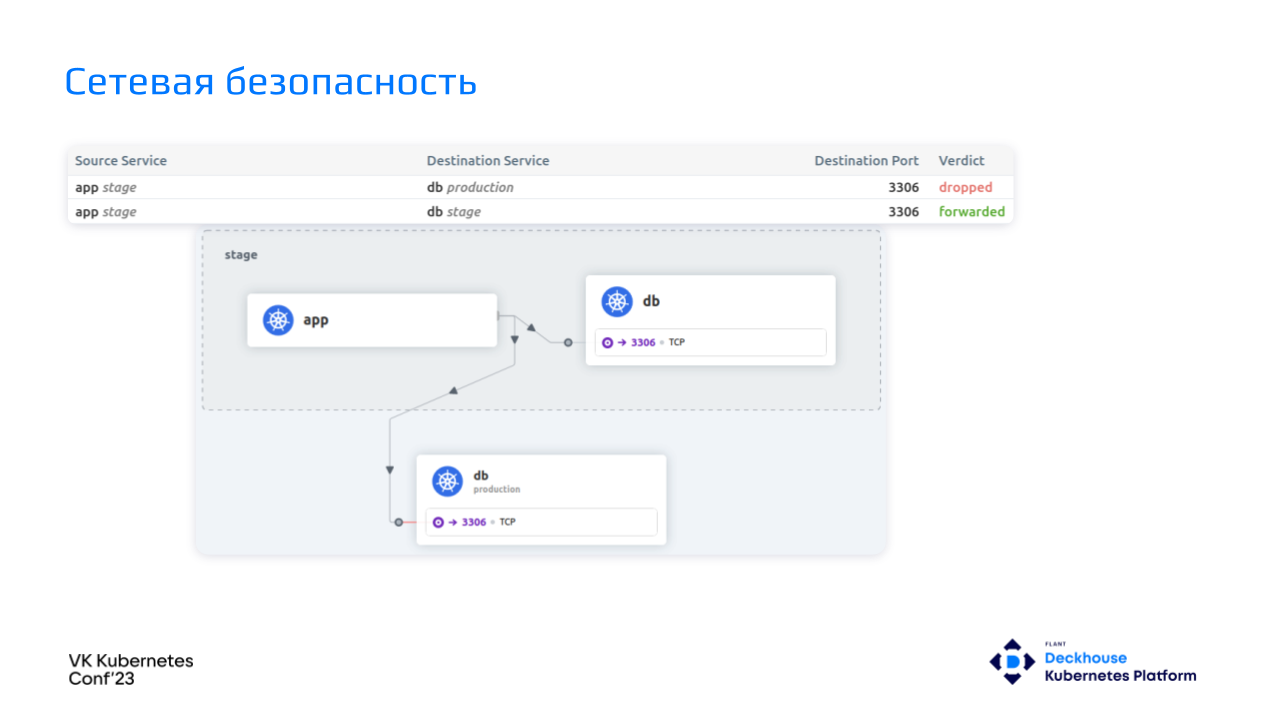
Разработчик может ходить в БД только в рамках stage и не может попадать в production.
Бывают и еще более ужасные вещи, когда пароли и названия stage- и production-баз совпадают. Если у разработчиков или инженеров достаточно пытливый ум, то запросы из stage начинают лететь в production-базу.
Политики необходимо внедрять также в случае, если у каждого сервиса свой отдельный кластер.
Давно пора уйти от правила «доверяй, но проверяй» или считать, что все, что разворачивается в закрытый контур, по умолчанию безопасно. Нужно отслеживать и понимать, кто и куда обращается. Это очень важно.
Кроме того, необходимо внедрить подход «политики как код». Он идентичен подходу «инфраструктура как код» и означает, что политики безопасности деплоятся вместе с приложением из Git-репозитория.
Внедрять все это необходимо на самом старте — в этот момент соответствующие практики привить гораздо проще. При введении нового компонента сразу должны описываться его сетевые взаимодействия и разворачиваться политики. В уже работающую инфраструктуру внедрять политики гораздо сложнее.
Шаг четвертый: контроль над запускаемыми приложениями
Мы обсудили сетевую безопасность, но остается еще такое понятие, как runtime — хост, на котором будет запускаться наш контейнер.
Запрос в Kubernetes проходит достаточно длинную цепочку. Одним из ее элементов является Admission Controller, который валидирует создаваемые в кластере объекты.
В Kubernetes 1.23 есть Pod Security Admission, который закрывает базовые потребности.
Существуют Pod Security Standards, которые, среди прочего, запрещают запускать поды от root, использовать host network и так далее. Если этих политик недостаточно, можно воспользоваться следующими вариантами:
В каких случаях стандартов Pod Security Standards недостаточно? Мы у себя в платформе составили список этих случаев и создали CRD OperationPolicy, которое работает поверх ресурсов Gatekeer. Пример его конфигурации:
apiVersion: deckhouse.io/v1alpha1
kind: OperationPolicy
metadata:
name: common
spec:
policies:
allowedRepos:
- myregistry.example.com
requiredResources:
limits:
- memory
requests:
- cpu
- memory
disallowedImageTags:
- latest
requiredProbes:
- livenessProbe
- readinessProbe
maxRevisionHistoryLimit: 3
imagePullPolicy: Always
priorityClassNames:
- production-high
checkHostNetworkDNSPolicy: true
checkContainerDuplicates: true
match:
namespaceSelector:
labelSelector:
matchLabels:
operation-policy.deckhouse.io/enabled: "true"
Пользователям рекомендуем сразу настраивать этот инструмент. В него входят следующие базовые принципы:

Самые важные, по моему мнению, точки контроля:
не разрешаем разработчикам использовать образы напрямую с Docker Hub в определенных пространствах имен, требуя конфигурации доверенного registry.
заставляем использовать priorityClass'ы.
В своей практике я нередко сталкивался с ситуациями, когда, например, у системы логирования приоритет был выше, чем у бэкенда. Результат — не совсем корректная работа системы в целом.
Какие вещи в целом закрывает Admission Controller?

Самый яркий пример — довольно старая CVE от 2019 года, до сих пор сохраняющая актуальность: если запустить контейнер от root, можно получить доступ к хосту. Риски стать жертвой этой уязвимости многократно повышаются, если разработчикам разрешено запускать образы из любых недоверенных registry.
В завершение этого шага хочется подчеркнуть, что описывать политики безопасности приложений просто необходимо. Больше контроля — меньше вероятность возникновения ошибки, а значит и ниже вероятность стать жертвой уязвимости.
Шаг пятый: аудит и регистрация событий
После запуска приложения хочется понимать, что происходит внутри Kubernetes и всей системы.

Речь сейчас не про мониторинг и снятие метрик с подов. Речь про аудит событий.
В Kubernetes встроен классный аудит «из коробки» — аудит Kubernetes API, который очень легко настроить. Пишем логи в файл или в stdout, собираем и отгружаем в систему сбора логов, а уже в ней — анализируем.
Пример простой политики сборки запросов, которые отправляются к ресурсам типа pods:
apiVersion: audit.k8s.io/v1
kind: Policy
omitStages:
- RequestReceived
rules:
- level: RequestResponse
resources:
- group: ""
resources: ["pods"]В результате мы получаем вот такой лог:
{
"kind": "Event",
"apiVersion": "audit.k8s.io/v1",
"level": "RequestResponse",
"auditID": "28eff2fc-2e81-41c1-980b-35d446480e77",
"stage": "ResponseComplete",
"requestURI": "/api/v1/namespaces/default/pods/nginx-6799fc88d8-5p7x5",
"verb": "delete",
"user": {
"username": "system:serviceaccount:d8-service-accounts:gitlab-runner-deploy",
"uid": "fd5a6209-c893-4b77-adf7-90500ecd2723",
"groups": [
"system:serviceaccounts",
"system:serviceaccounts:d8-service-accounts",
"system:authenticated"
]
},
...Здесь видно, что сервисный аккаунт удалил под NGINX.
Достаточно ли этого? На самом деле нет.
Помимо сборки таких событий, их необходимо и анализировать. Если сервисный аккаунт удалил под или создал какой-то ресурс в production, то, вероятно, это легитимная операция, потому что мы что-то деплоим. А вот если простой пользователь со своей учеткой пошел что-то править и создавать в production, то это уже проблема. Хотелось бы получить о ней алерт и узнать, что в кластере какая-то подозрительная активность.
Также необходимо регистрировать события непосредственно в хостовой ОС и в среде исполнения. Например, команда crictl exec не пройдет через аудит Kubernetes API, и мы не узнаем, что кто-то вошел в под, хотя знать это хотелось бы. Плюс хотелось бы иметь информацию о том, какие вообще процессы запускаются внутри контейнеров.
Для решения таких вопросов есть приложения, которые реализуют runtime security. В Deckhouse мы используем для этого Falco. Он выполняет следующие функции:
разбор системных вызовов на хосте;
получение аудит-лога от Kubernetes API через Webhook backend;
проверка потока событий с помощью сконфигурированных правил;
отправка алертов в случае нарушения правил.
Схема работы:
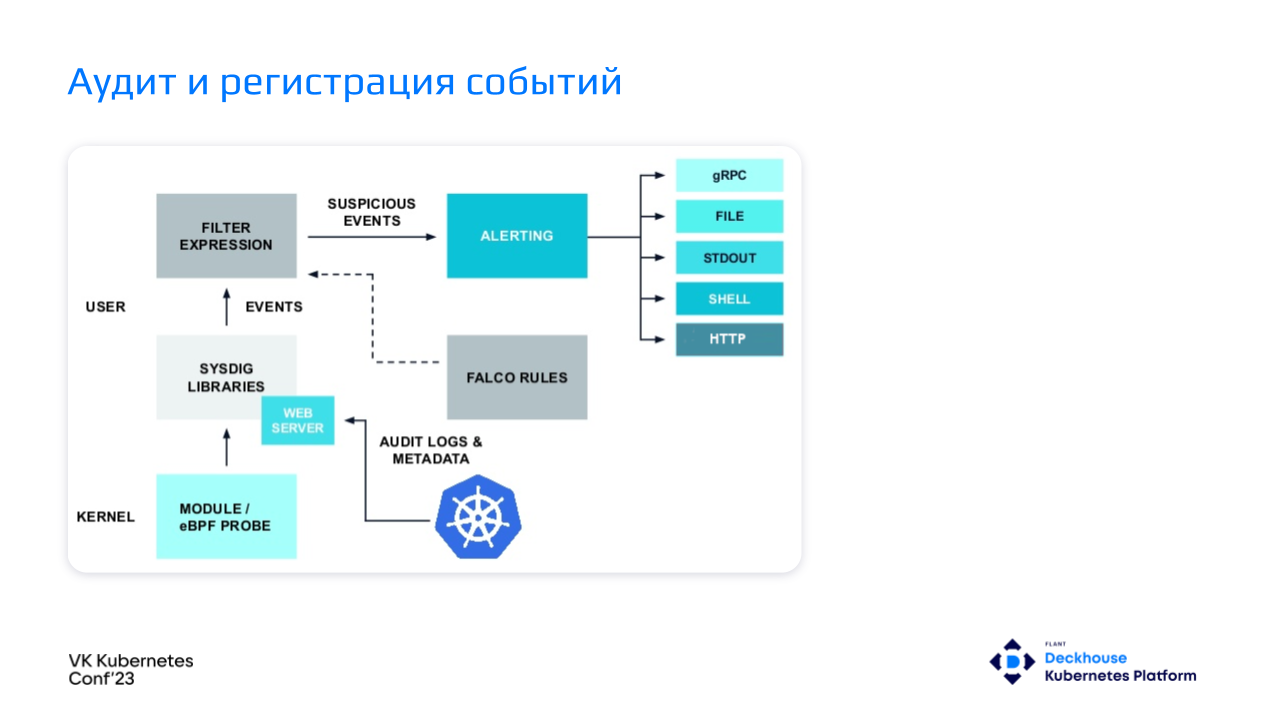
У нас есть ядро, в нем есть технология eBPF, которая собирает системные вызовы, есть вебхук, который собирает события с Kubernetes API, есть Falco с загруженными правилами. Он проверяет поступающие события на соответствие этим правилам и в случае чего передает данные в алертинг-систему.
Falco разворачивается в виде DaemonSet'а на все узлы кластера.

Как выглядит под с Falco?

В нем есть:
init-контейнер, в котором загружается eBPF-программа;
Falco, собирающий события и обогащающий их метаданными;
shell-operator, который собирает Falco audit rules и подготавливает правила для Falco;
метрики отдаем с помощью falcosidekick;
доступ к метрикам ограничен с помощью kube-rbac-proxy.
Falco audit rules также выполнены в виде Custom Resource, что дает возможность проверки относительно OpenAPI спецификации, а также это просто удобнее — работать с примитивами Kubernetes:
apiVersion: deckhouse.io/v1alpha1
kind: FalcoAuditRules
metadata:
name: host-audit-custom
spec:
rules:
- list:
name: cli_proc_names
items: [crictl, docker]
- macro:
name: spawned_process
condition: (evt.type in (execve, execveat) and evt.dir=<)
- rule:
name: Crictl or docker cli are executed
desc: Detect ctl or docker are executed in cluster
condition: spawned_process and proc.name in (crictl, docker)
output: Crictl or docker are executed (user=%user.name user_loginuid=%user.loginuid command=%proc.cmdline pid=%proc.pid parent_process=%proc.pname)
priority: Warning
tags: [host]Созданные Falco audit rules на лету трансформируются в обычные Falco-правила:
- items:
- crictl
- docker
list: cli_proc_names
- condition: (evt.type in (execve, execveat) and evt.dir=<)
macro: spawned_process
- condition: spawned_process and proc.name in (cli_proc_names)
desc: Detect crictl or docker are executed in cluster
enabled: true
output: Crictl or docker are executed (user=%user.name user_loginuid=%user.loginuid
command=%proc.cmdline pid=%proc.pid parent_process=%proc.pname)
priority: Warning
rule: Crictl or docker cli are executed
source: syscall
tags:
- hostFalco-правило содержит листы и макросы, позволяющие переиспользовать кусочки коды и писать более понятные и лаконичные условия.
По приведенному выше правилу в логах мы увидим следующее:
{
"hostname": "demo-master-0",
"output": "14:17:03.188306224: Warning Crictl or docker are executed (user=<NA> user_loginuid=1000 command=crictl ps pid=273049 parent_process=bash) k8s.ns=<NA> k8s.pod=<NA> container=host",
"priority": "Warning",
"rule": "Crictl or docker cli are executed",
"source": "syscall",
"tags": [
"host"
],
"time": "2023-03-14T14:17:03.188306224Z",
"output_fields": {
"container.id": "host",
"evt.time": 1678803423188306200,
"k8s.ns.name": null,
"k8s.pod.name": null,
"proc.cmdline": "crictl ps",
"proc.pid": 273049,
"proc.pname": "bash",
"user.loginuid": 1000,
"user.name": "<NA>"
}
}
{
"hostname": "demo-master-0",
"output": "14:43:34.760338878: Warning Crictl or docker are executed (user=<NA> user_loginuid=1000 command=crictl stop 067bd732737af pid=307453 parent_process=bash) k8s.ns=<NA> k8s.pod=<NA> container=host",
"priority": "Warning",
"rule": "Crictl or docker cli are executed",
"source": "syscall",
"tags": [
"host"
],
"time": "2023-03-14T14:43:34.760338878Z",
"output_fields": {
"container.id": "host",
"evt.time": 1678805014760339000,
"k8s.ns.name": null,
"k8s.pod.name": null,
"proc.cmdline": "crictl stop 067bd732737af",
"proc.pid": 307453,
"proc.pname": "bash",
"user.loginuid": 1000,
"user.name": "<NA>"
}
}Пользователь с UID 1000 запустил команду crictl ps или crictl stop.
Правила Kubernetes Audit выглядят примерно так же:
- required_plugin_versions:
- name: k8saudit
version: 0.1.0
- macro: kevt_started
condition: (jevt.value[/stage]=ResponseStarted)
- macro: pod_subresource
condition: ka.target.resource=pods and ka.target.subresource exists
- macro: kcreate
condition: ka.verb=create
- rule: Attach/Exec Pod
desc: >
Detect any attempt to attach/exec to a pod
condition: kevt_started and pod_subresource and kcreate and ka.target.subresource in (exec,attach)
output: Attach/Exec to pod (user=%ka.user.name pod=%ka.target.name resource=%ka.target.resource ns=%ka.target.namespace action=%ka.target.subresource command=%ka.uri.param[command])
priority: NOTICE
source: k8s_audit
tags: [k8s]В них также есть макросы, листы и все то, что умеет Falco. Например, это правило в логах отобразит, что кто-то пошел в под через Kubernetes API:
{
"hostname": "demo-master-0",
"output": "18:27:29.160641000: Notice Attach/Exec to pod (user=admin@example.com pod=deckhouse-77f868d554-8zpt4 resource=pods ns=d8-system action=exec command=mkdir)",
"priority": "Notice",
"rule": "Attach/Exec Pod",
"source": "k8s_audit",
"tags": [
"k8s"
],
"time": "2023-03-14T18:27:29.160641000Z",
"output_fields": {
"evt.time": 1678818449160641000,
"ka.target.name": "deckhouse-77f868d554-8zpt4",
"ka.target.namespace": "d8-system",
"ka.target.resource": "pods",
"ka.target.subresource": "exec",
"ka.uri.param[command]": "mkdir",
"ka.user.name": "admin@example.com"
}
}Но просто генерировать метрики недостаточно. Администратор кластера должен получать информацию о том, что в кластере происходит подозрительная активность. Поскольку все метрики отправляются в Prometheus, нужно создать для них правило:
apiVersion: deckhouse.io/v1
kind: CustomPrometheusRules
metadata:
name: runtime-audit-pod-exec
spec:
groups:
- name: runtime-audit-pod-exec
rules:
- alert: RuntimeAuditPodExecAlerts
annotations:
description: |
There are suspicious attach/exec operations.
Check your events journal for more details.
summary: Falco detected a security incident
expr: |
sum(rate(falco_events{rule="Attach/Exec Pod"}[5m])) > 0Их можно настроить либо на конкретные события Falco, либо на события с определенным уровнем критичности.
Самое ценное, что есть в Falco — это Falco-правила. Они глубоко кастомизируемые, их нужно писать под конкретные приложения и под конкретную инфраструктуру. У нас есть набор базовых правил, которые можно посмотреть на GitHub.
Перечень полезных правил:
Я часто слышу, что аудит и регистрация событий нужны только компаниям enterprise-уровня для прохождения сертификаций, но это не совсем так. Falco очень полезен для разбора инцидентов, в том числе не связанных с безопасностью. Например, для поиска сбойных операторов в кластере, осуществивших нелегитимное удаление каких-то подов.
Одним их самых важных элементов аудита и регистрации событий является реагирование на угрозы — администратор должен сразу получать уведомления о том, что в кластере происходит что-то, что требует внимания.
Заключение
Безопасность — это циклический процесс. Всегда есть куда двигаться.

Постоянно появляются новые угрозы, новые технологии. Вопрос безопасности Kubernetes до конца не решен и требует внимания.
Сам по себе Kubernetes — это большая система, в которую необходимо устанавливать дополнительные компоненты, чтобы повысить безопасность. И здесь самое главное не забывать уделять время организации этой безопасности. Очень часто бизнес хочет как можно быстрее развернуть Kubernetes, быстрее перевести туда приложения, а на безопасность не остается времени. В таком случае нужно внедрить хотя бы часть описанных выше решений, которые закроют основные проблемы.
Если времени совсем нет, стоит посмотреть в сторону готовых решений. Есть как отечественные вендоры, поставляющие софт для безопасности в кластере, так и зарубежные. Также можно рассмотреть вариант с готовыми платформами, которые способны закрыть многие вопросы безопасности.
Видео и слайды
Видеозапись выступления (~50 минут):
Презентация:
P.S.
Читайте также в нашем блоге: