

Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой, который обычно сводится к тому, что задача X теперь уже решена и мы были в очередной раз по гроб облагодетельствованы.
В этот раз мне прислали ссылку на репозиторий Bark, который по сути является некой интерпретацией статьи VALL-E от известной корпорации добра. В частности, согласно заявлениям авторов, их репозиторий обещает:
Синтез на всех популярных языках от английского до китайского;
Возможность GPT-style управления выдаваемым аудио;
Возможность дикторов "говорить" на иностранных языках;
Войс-клонинг "этичненько" залочен;
Всё это в высоком качестве как у современного нейросетевого синтеза и в "риалтайме", с моделями "более 100M параметров";
Давайте разберемся так ли это.
Реплицируемые статьи, размер дистрибутивов
В описании приводятся ссылки на статьи AudioLM, VALL-E, Encodec и многочисленные эффективные имплементации трансформер-модулей, которые ставятся при установке библиотеки.
У первой статьи не указано на чем они тренировали свои модели (как часто делает другая корпорация добра), у второй и третьей соответственно на 16 V100 и 8 A100, что сразу наводит на мысли.
В описании довольно обтекаемо написано:
Running Bark requires running >100M parameter transformer models. On modern GPUs and PyTorch nightly, Bark can generate audio in roughly realtime. On older GPUs, default colab, or CPU, inference time might be 10-100x slower.
На практике при запуске модели она последовательно скачала несколько файлов размером 5.35GB, 3.93GB и 3.74GB, не уточнив, что это были за файлы. Также она скачала токенайзеры и непосредственно сам Encodec размером 88MB, на фичах которого эта модель основана. При этом потребление VRAM менялось в процессе загрузки модели (явно какие-то оптимизации по типу работы в FP16 или дальше) и итоговое потребление составило в районе 6GB как для 3090, так и для 1080 Ti, что неплохо. Тут нужно отдать должное, именно в этом моменте над оптимизацией поработали (авторы библиотек, на которых эта модель основана).
Скорость работы
Не буду растекаться мыслью по древу, просто свёл свои наблюдения и сравнения с нашими моделями синтеза:
Bark |
Наши лучшие модели |
|
|---|---|---|
Размер модели |
5.35GB + 3.93GB + 3.74GB |
38 MB |
Encodec |
88M |
- |
Частота дискретизации |
24 kHz |
24 kHz (также есть 8 и 48 kHz) |
Скорость на 3090 |
~0.5 |
300-400 (внутри сервиса) |
Утилизация 3090 |
30-40% |
5-10% |
Скорость на 1080 Ti |
~0.35 |
200-300 (внутри сервиса) |
Утилизация 1080 Ti |
100% |
5-10% |
Скорость на 4 потоках процессора |
- |
80-90 |
Скорость на 1 потоке процессора |
- |
40-50 |
Занимает памяти на GPU |
6GB |
2GB, но можно и поставить кратно меньше |
Тут в принципе сложно ожидать чего-то иного от рекуррентных огромных моделей. Я не стал закапываться внутрь кода, но понятно по прогресс-индикаторам, что там относительно большие рекуррентные трансформеры. Об их "особенностях" чуть ниже.
Справедливости ради, у нас всё не доходят руки обновить наши публичные модели синтеза на самые супер-быстрые (но в этом году мы скорее всего и до этого доберемся, если случится ряд благоприятных событий):
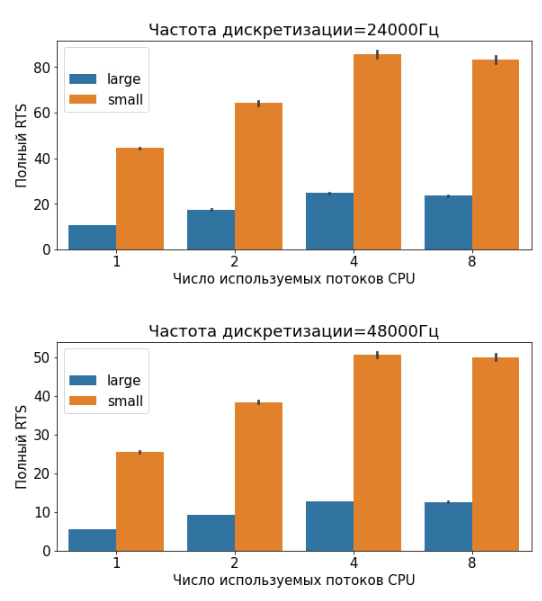
С "продуктовостью" Bark-a всё в принципе понятно (GPU go brrr) вернемся к нашим "баранам" и поговорим про самое интересное - качество синтеза. Интересующимся товарищам могу посоветовать также провести параллели с тем, что происходит в мире, с новыми компьютерными играми, ценами на новые видеокарты и рынком майнинга, и сделать очевидные выводы.
Качество аудио
Авторы не пишут об этом, но модель явно натренирована на LibriTTS и выдает аудио с частотой дискретизации 24 kHz. Написано, что модель детектирует язык по тексту.
Попробуем:
text_prompt = """Привет, меня зовут Петя! Я гопник, гоп-стоп, мы подошли из-за угла!"""
audio_array = generate_audio(text_prompt)
Получается что-то такое:
Hidden text
Так, модель явно не поняла, что это русский язык по тексту. Попробуем с музыкой:
text_prompt = """♪ Гоп-стоп, мы подошли из-за угла ♪"""
audio_array = generate_audio(text_prompt)
Hidden text
Теперь модель поняла что это русский язык. Но в целом какого-то реального контроля не присутствует, много артефактов и в целом это конечно звучит качественно, но не очень осмысленно.
Попробуем упростить задачу, подсказать модели голосами каких дикторов надо говорить и добавить смех:
text_prompt = """Привет, меня зовут Петя! Я гопник, гоп-стоп, мы подошли из-за угла! [laughs]""")
audio_array = generate_audio(text_prompt, history_prompt="ru_speaker_1"
В этот раз дикторы почему-то плавают:
Hidden text
При этом при повторной генерации могут получаться сильно разные аудио. На основном языке, английском, такие артефакты менее выражены, но всё равно присутствуют. Попробуем сгенерировать ту же фразу разными дикторами из разных языков (тут сразу все примеры):
Hidden text
Речь на «иностранном» языке, кстати очень похожа на наши эксперименты при смешивании русского и английского, или русского и татарского языков, что косвенно свидетельствует, что модели учат примерно похожие фичи.
Общие наблюдения про качество аудио
Основные выводы такие:
Доступно не так много дикторов (ограничения датасета);
В целом качество для синтеза относительно высокое, но артефакты, пропуск слов, «плавание диктора», фантазии модели или галлюцинации присутствуют почти в каждом втором или первом аудио (зависит от языка). Дикторы зачастую не являются консистентными;
На слух частота дискретизации не всегда выдерживается, или аудио сопровождаются статиком;
Модель довольно хорошо научилась ставить ударения в русском языке, есть даже какая‑то степень генерализации на неизвестные или редкие слова;
На омографах и омографах с ё модель предсказуемо не работает;
При это возможности явно прописывать ударение или омографы с ё нет возможности;
У модели нет типичных артефактов вокодеров, но есть артефакты, когда в речи диктора даже на своем родном языке появляется акцент или «заплетается» язык;
Дает ли такая модель новые возможности?
Пока мы видим, что, с точки зрения продуктовости, модель имеет многочисленные недостатки перед обычным моно‑ и много‑язычным синтезом.
Основная фишка многоязычных «больших» моделей — в генерализации на новых дикторов, новые языки, в возможности добавлять всякие вздохи‑ахи и в zero‑shot трансфере, но тут авторы «этично» закрыли эту функцию … в модели на питоне. У меня довольно мало желания искать заветное место, где эта фишка «открывается».
Давайте разберем фишки одна за одной. Генерализация на дикторов работает довольно спорно, есть многочисленные галлюцинации и артефакты, которые никак не контролируются. При этом эта функция не является удивительной даже для наших моделей, которые на три порядка быстрее. Например некоторые дикторы из нашего бота в телеграме завелись буквально с пары минут речи. В общем случае необязательно увеличивать модель в 100 — 1,000 раз, чтобы она работала на большом числе разнообразных дикторов.
Генерализация на новые языки. Тут довольно прикольно, что дикторы могут говорить на «иностранных» языках. Но опять же, основная фишка тут, позволяющая ускорить модель в 1000 раз — это грамотная схема токенизации. В частности наша модель для 9 языков народов Индии прекрасно с этим справляется благодаря грамотной токенизации, подсказанной носителем языка. Конечно не все комбинации дикторов и языков хорошо звучат, и там тоже есть легкий или средний акцент. Сложно в маленькой модели, например, соединить русский и английский языки, но это всего лишь требует чуть больше инжиниринга, а не в 1000 раз больше вычислительных ресурсов. Относительно хорошо ситуация обстоит с языками народов РФ, где нам «подарили» похожие алфавиты и почти фонетическое письмо.
Генерализация на «ахи‑вздохи» и музыку. Это действительно уникальная фича, и наверное добавить смех это прикольно. Но знаете как еще на практике это можно сделать? Записав 5 примеров смеха и просто добавляя их в аудио. Да, еще на практике можно творить чудеса, прибегая к звукоподражанию, если письмо фонетическое. Музыка же тут не особо как‑то прямо контролируется.
Выводы

В целом в текущем состоянии данная модель скорее является демонстрацией возможностей огромных моделей и представляет довольно мало практического интереса, даже если закрыть глаза на ее «продуктовость» по скорости и галлюцинации.
Интересно также посмотреть со стороны, как окно овертона смещается, что в гейминге (новые игры с графоном тормозят даже на картах типа 4070), что в ML в сторону мягких намеков, что мягко говоря ценник на вход повышается с 1 карты до 8–16–32 A100 / V100 и логичного вывода, что такие модели лучше покупать через облако у правильных поставщиков.
В этой связи можно, например сравнить показатели популярности новой модели для генерации картинок от Сбера (картинки сами по себе в 10 — 100 раз популярнее, чем аудио) и показатели популярности Bark, которая сразу возникла, но уже с правильным pedigree (у репозиториев с более чем 3000 звезд график нельзя посмотреть публично). К сожалению, ML‑зима уже наступила, но с фронта, которого не все ждали, с фронта геополитического.
Amareis
Мне в принципе кажется что с ML нынче творится GPU-шовинизм какой-то. Наглядный пример - llama, которая и на CPU показывает хорошие результаты. Осталось только научить модели нормально обучаться на CPU, а не требовать от них эквивалента сотен лет человеческого времени для этого.
SozTr
Тут вопрос ресурсов, если у тебя нету ресурсов, то вариантов особенно нету. А если есть, ты можешь попробовать сделать прорыв, а потом уже оптимизировать и снизить цену на порядок (как в случае openai).