
Это история из профессионального опыта, поэтому её лучше передавать от основного действующего лица, который в ней непосредственно участвовал. Поэтому...
Меня зовут Вадим Опольский и я работаю data-инженером и участвую в проведении онлайн-тренингов. В статье есть ссылки на воркшопы, чтобы повторить практические вещи из Apache Flink, о которых я расскажу. А обсудим мы следующие проблемы:
Неравномерный поток данных;
Потери данных при передаче их из Kafka в storage;
Масштабирование и скейлинг;
Backpressure;
Мелкие файлы на HDFS;
Стриминговый процессинг.
Масштаб задачи и контекст
В крупной логистической компании с более 50 тысячами пунктов приема/выдачи заказов. Клиенты приходят в них и оформляют заказы, которых бывает более 2,5 миллионов в день. Каждая доставка порождает набор событий, которые несут информацию, например, о ее состоянии. И таких событий может быть 500-700 миллионов в день. События отправляется курьерами, центрами выдачи и сортировки грузов. И все они в реалтайме попадают в Kafka. Нагрузка в пике для отдельных топиков может достигать более 500 тысяч событий в секунду.
Для батчевой обработки в Big Data и чтобы данная информация была полезна бизнесу, необходимо сформировать историю или лог событий. На его основе в дальнейшем можно запустить батчевую обработку и получить полезную для бизнеса информацию. Для хранения истории удобно использовать storage Hadoop Distributed File System, а для батчевой обработки, например, Spark.
С другой стороны, в стриминге и в Big Data бывают задачи, когда нужно на лету обрабатывать одно или несколько событий, посчитать онлайн-агрегаты, окна и другую стриминговую аналитику. А потом сгрузить это всё в базу данных типа Cassandra или завести всё в Rest, чтобы предоставить бизнесу удобный доступ к просмотру результатов.

С другой стороны, в какой-то момент архитектура может измениться, и, например, вместо Hadoop Distributed File System захочется использовать распределенный кэш на основе Postgres, или построить стриминговый пайплайн Kafka to Kafka, где тоже будут происходить онлайн трансформации.
Какие гарантии доставки могут быть при сбоях
Когда мы передаем данные из одного storage в другой могут быть потери, которые регулируются уровнями гарантий доставки:
At most once: никаких гарантий. В источнике могут быть месседжи 1, 2, 3 и т.д., а в получателе мы можем терять сообщения или они там будут задублированны.
At least once: точно всё, но будут дубли. Это следующий более интересный уровень гарантий. Мы точно получим все сообщения из источника в получателе. Но могут возникнуть проблемы, когда в получателе дублируются некоторые месседжи. В принципе, для некоторых задач Big Data это нормально.
Exactly once: точно всё, без дублей. Есть задачи, которые требуют, чтобы абсолютно все месседжи из источника попадали в получатель, и при этом не возникало дубликатов.
Такую передачу для Big Data можно организовать как стриминговый пайплайн, который будет работать 24/7. Давайте рассмотрим с какими проблемами можно встретиться:
Какие проблемы могут возникнуть?

Неравномерный поток данных. События зависят от бизнеса компании, а бизнес компании построен так, что чем больше клиентов приходит в определенное время, тем больше событий происходит. А приходят они неравномерно: в промежуток времени с 8 до 12 и с 4 до 8 событий много, потому что люди в свободное время приходят что-то заказывать или отправлять. В другое время событий меньше. Поэтому очень желательно иметь возможность обрабатывать данные в любое время суток и при любой нагрузке.
Обработчики падают и пропадают данные. Kafka — это распределенный storage и хочется читать данные из Kafka в параллельном режиме. Но в таком режиме обработчики могут падать, а данные пропадать.
Горизонтальное масштабирование. Так как у нас все работает в распределенном режиме, то что будет, если бизнес компании вырастет через год в 10-50 раз? Каким образом мы можем масштабировать этот пайплайн?
Пропускная способность получателя ниже, чем у источника. Данные в Kafka мы и читаем, и пишем, в этом состоит задумка. Процессы будут происходить быстрее, чем запись, например, на HDFS. Таким образом будет накапливаться буфер данных, и данные из этого буфера могут пропадать.
Неконтролируемый размер файлов на выходе. Это ещё одна проблема, популярная для Hadoop Distributed File System — большое количество мелких файлов на выходе.
Необходимость стриминговой обработки. Если в процессе чтения или написания нам нужно сделать обработку, окна, таймеры и т.д.
Чтобы решить эти проблемы, можно написать код на Java Client API, используя Scala, Java или Python. Но к сожалению, это не решит всех проблем.
Причины отсутствия единого решения
Поддержка консистентности при сбоях в распределенной системе. Если какая-то часть обработчиков упадёт, а другая будет работать — что произойдёт с получателем?
Exactly once через коммит офсетов останется в ответственности разработчика. Разработчик должен подумать об этом самостоятельно.
Сложно отслеживать состояние джобы. Если мы напишем код и запустим его, то для поддержки и DevOps будет важно отслеживать состояния работы кода и всех связанных с ним проблем, которые будут происходить внутри. Делать это нужно до того момента, пока он не упадет, например, пока не возникнут проблемы с backpressure.
Нужно организовать backpressure и балансировать данные между инстансами в случае перекоса. Если у нас в Kafka партиции и есть перекос, то в какой-то партиции данных будет больше, а мы хотим балансировать при их чтении и записи, чтобы файлы появлялись равномерно. Как это сделать, тоже должен придумать разработчик. Всё это может смягчить и частично решить проблемы. Но по-настоящему решить их может только Apache Flink.
Apache Flink
Это немецкий стартап с 2014 года, который написан на Java и под капотом у него Akka. С ростом его популярности Alibaba вложил в него 90 млн $. Flink изначально дизайнился именно для задач стриминга.
Особенности Apache Flink:
Процессинг с гибкими механизмами хранения состояния (stateful), то есть поддержка состояния в распределенном режиме;
Ориентация на низкие задержки и высокую пропускную способность;
Поддержка стриминговой аналитики любой сложности;
Распределённая работа на кластере и масштабирование;
Более 12 коннекторов с параллельным i/o к самым популярным storages, которые поддерживают чтение и запись в параллельном режиме, что важно для задач Big Data:

Есть красивый UI, API и более тысячи метрик для отслеживания состояния джобы:

Метрики можно сгружать в InfluxDB, Prometheus и т.д. Соответственно, можно контролировать статус джобы через web API.
Nifi, Kafka Connect, StreamSets, Apache Flume, Apache Gobblin и Druid и их ограничения
В мире инструментов Big Data есть и другие варианты: Nifi, Kafka Connect, StreamSets, седой уже Apache Flume и молодые инструменты Apache Gobblin и Druid. У этих инструментов есть ограничения.
Угроза для прода. У StreamSets и у Nifi нет возможности версионировать код в Git. С одной стороны это удобно для разработчиков, а с другой стороны для специалистов, которые работают с production.
Не рассчитаны на реализацию фреймворка для типовых процессов. Например, на проекте, на котором я работаю, была задача разработать инструмент, который бы позволял вычитывать данные из одного storage из Kafka в разных форматах (Avro или JSON). Потом с помощью конфигов можно было бы сконфигурировать пайплайн так, чтобы он писал данные в один из рассматриваемых storage, и формат можно было каким-то образом конфигурировать. У нас на продакшене сейчас работает более 200 пайплайнов для Flink.
Не позволяют реализовать сложную логику. Вы можете скачать демо и повторить воркшопы, которые я записал на YouTube. Демо-проект сделан с помощью Docker Compose.

Есть генератор, который отправляет месседжи в Kafka со скоростью 1000 месседжей в секунду. Apache Flink, который представлен координирующей нодой Job manager и рабочими нодами Task manager вычитывает данные из Kafka, отправляет их в HDFS, в Cassandra или в Kafka в другой топик. Воркшоп с запуском и демонстрацией демо проекта.
Какие у этих решений существуют проблемы и какие фичи у Flink могут их решить.
Проблемы Nifi, Kafka Connect, StreamSets, Apache Flume, Apache Gobblin и Druid и их решения
Неравномерный поток данных, который может вдруг образоваться в исходном топике Kafka
Под капотом у Flink есть Akka Actors.
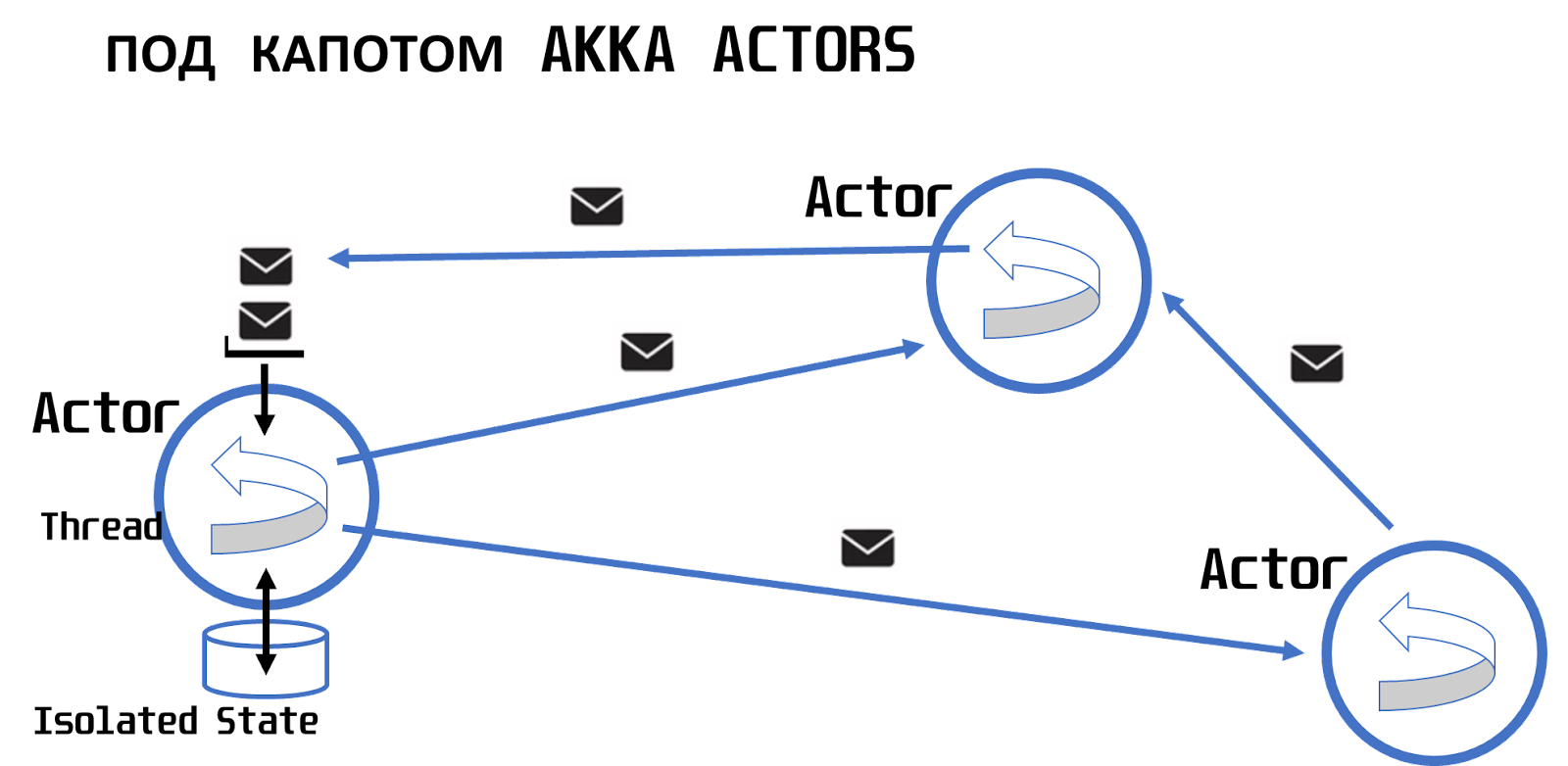
Модель actors — модель, где в каждом actor в один момент времени в одном акторе работает только один тред. Он последовательно обрабатывает месседжи, которые получают от других actors и отправляют друг другу асинхронно. Плюс, есть изолированный state. Он изолирован, чтобы не было проблем с коллизиями и concurrency.

Архитектура, реализованная в Flink, то есть каждый job manager и каждый task manager — это, по сути, actor или система actors, которые обмениваются сообщениями, в том числе, и на кластере, находясь на разных машинах, позволяет иметь очень маленькую задержку в обработке данных, а с другой стороны, обрабатывать миллионы месседжей в секунду.
AKKA:
Асинхронный обмен сообщениями;
Изолированный state;
Fault tolerance.
Flink:
Миллисекундная задержка;
Миллионы месседжей в секунду/
Благодаря этому мы решаем проблему с неравномерным потоком данных.
Обработчики падают и пропадают данные
Еще одна проблема — это падение обработчиков и, соответственно, риск, что данные могут исчезнуть.
Схема работы генератора Kafka:
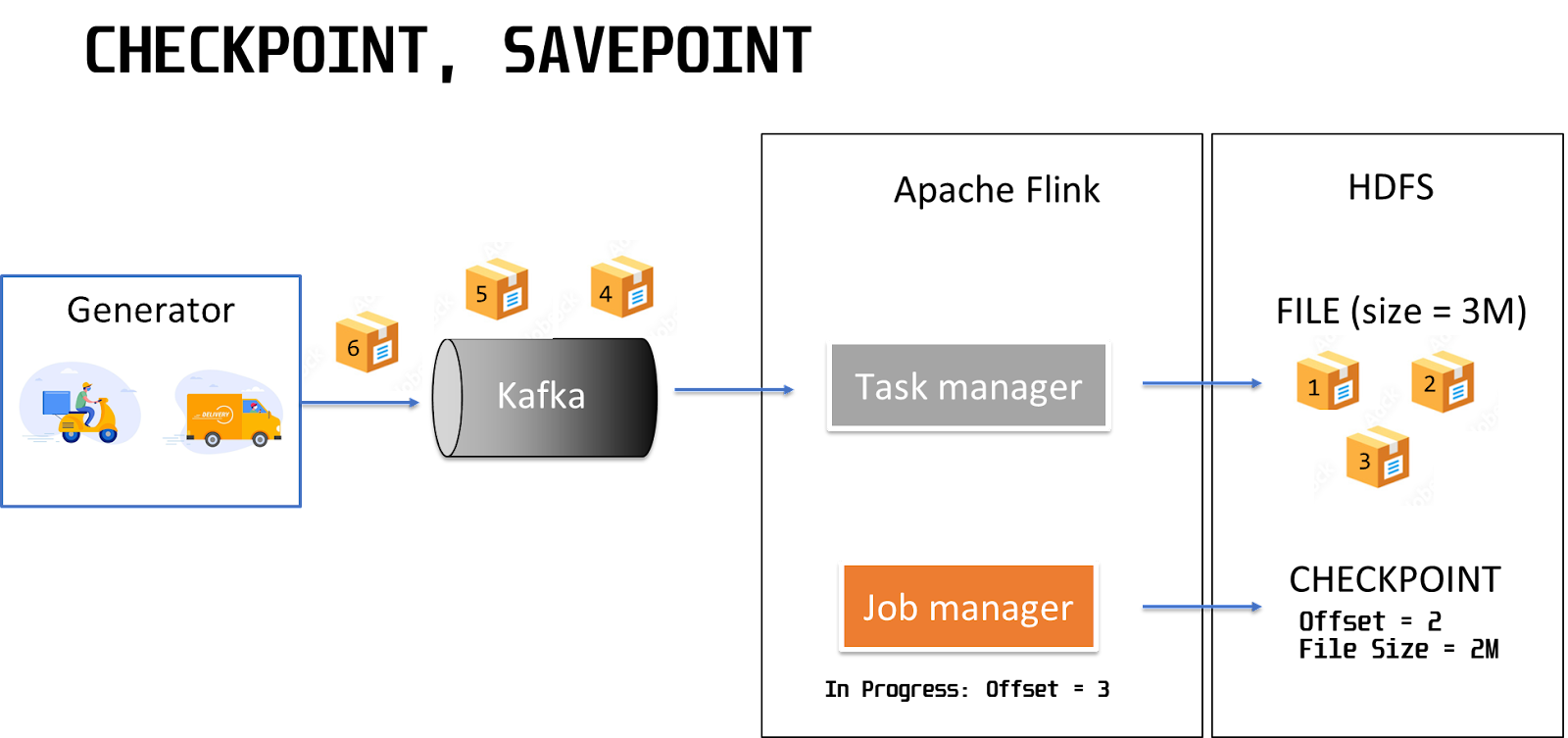
Продюсер отправляет в Kafka месседж с номером 1, Flink вычитывает этот месседж, происходит его обработка, мы фиксируем это сообщение в получателе на HDFS. То есть месседж с номером 1 записывается на HDFS и после этого мы фиксируем контрольную точку, которая называется checkpoint. В этой контрольной точке фиксируется офсет — номер месседжа в партиции Kafka. Также через механизм state стоит зафиксировать размер файла (File Size). Допустим, каждый месседж увеличивает размер конечного файла на 1 Мб.
Дальше происходит обработка следующего месседжа. Месседж попадает на HDFS. После его попадания на HDFS фиксируется новый офсет. Очень важно, что это происходит не одновременно — сначала мы пишем бизнес-информацию, потом записываем номер офсета.
При обработке третьего сообщения мы успеваем его записать в конечный storage, но не успеваем обновить checkpoint. Происходит какая-то авария, рестарт Flink, и появляется вопрос — с какого офсета начинать чтение в рестартованной джобе.

Так как у нас есть checkpoints, и мы зафиксировали, что последний успешно обработанный месседж был месседж с номером 2, то можно читать данные с третьего месседжа (2 + 1). Если мы это сделаем, то на конечном получателе в HDFS появятся дубликаты. Месседж с номером 3 будет дублирован.

Так как в checkpoint зафиксирован не только номер месседжа, но ещё и размер файла в момент, когда мы записали месседж и сделали его ’checkpoint. А значит при рестарте можно сравнить фактический размер файла с тем размером, который зафиксирован в checkpoint. В случае, если эти размеры не совпадают, выполним команду HDFS file truncate, которая усечет файл в получателе до размера, когда был зафиксирован корректный checkpoint.
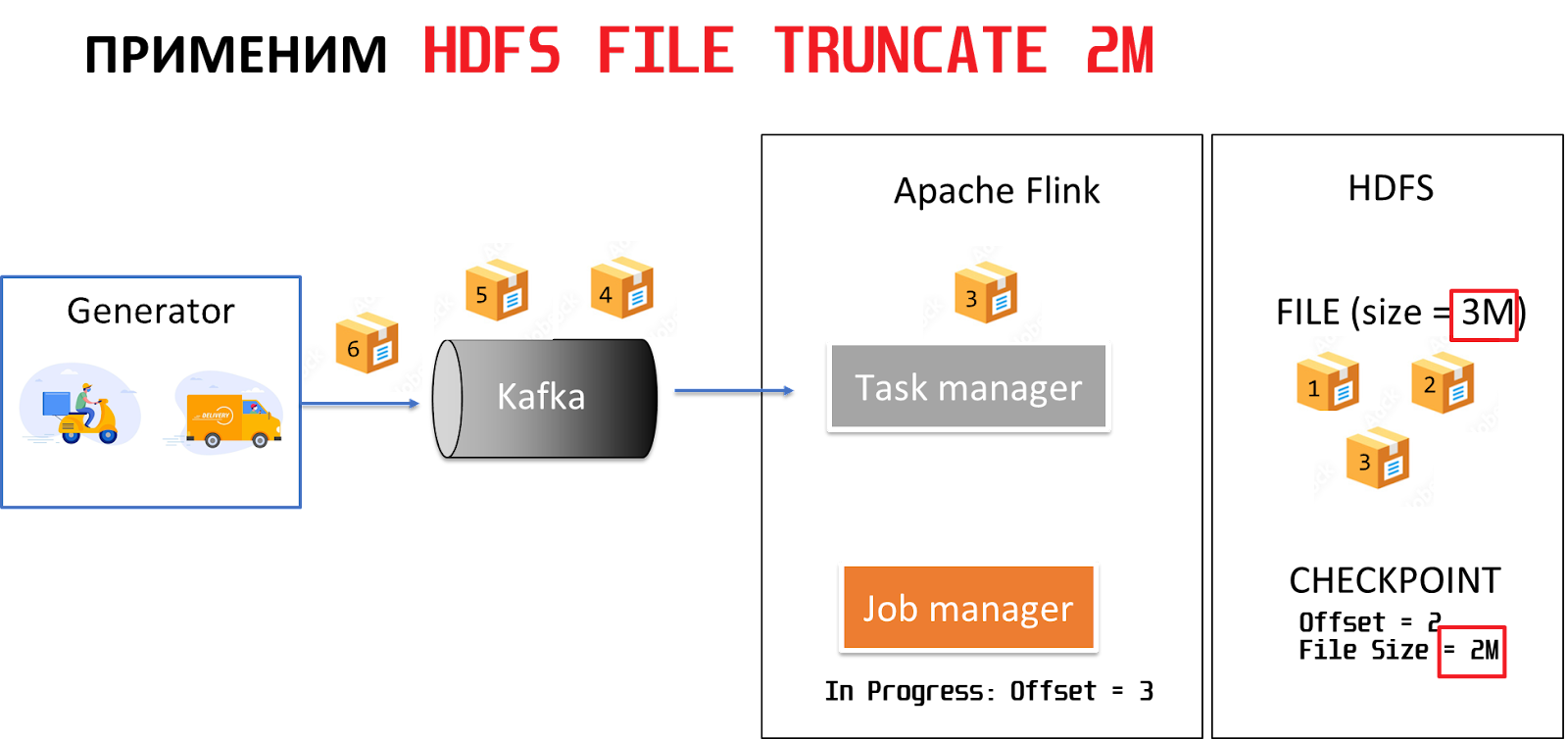
Так мы удалим третий месседж из HDFS, повторно обработаем его Flink, но при этом не создадим дубликатов в конечном получателе. Обработка будет продолжаться. Дальше пойдет четвертый месседж и т.д. Можно предположить, что это будет exactly once.
В придачу у Flink еще есть механизм барьеров, который также помогает в этом кейсе в распределенной работе.
Что будет, если у нас в получателе не HDFS, а Cassandra?
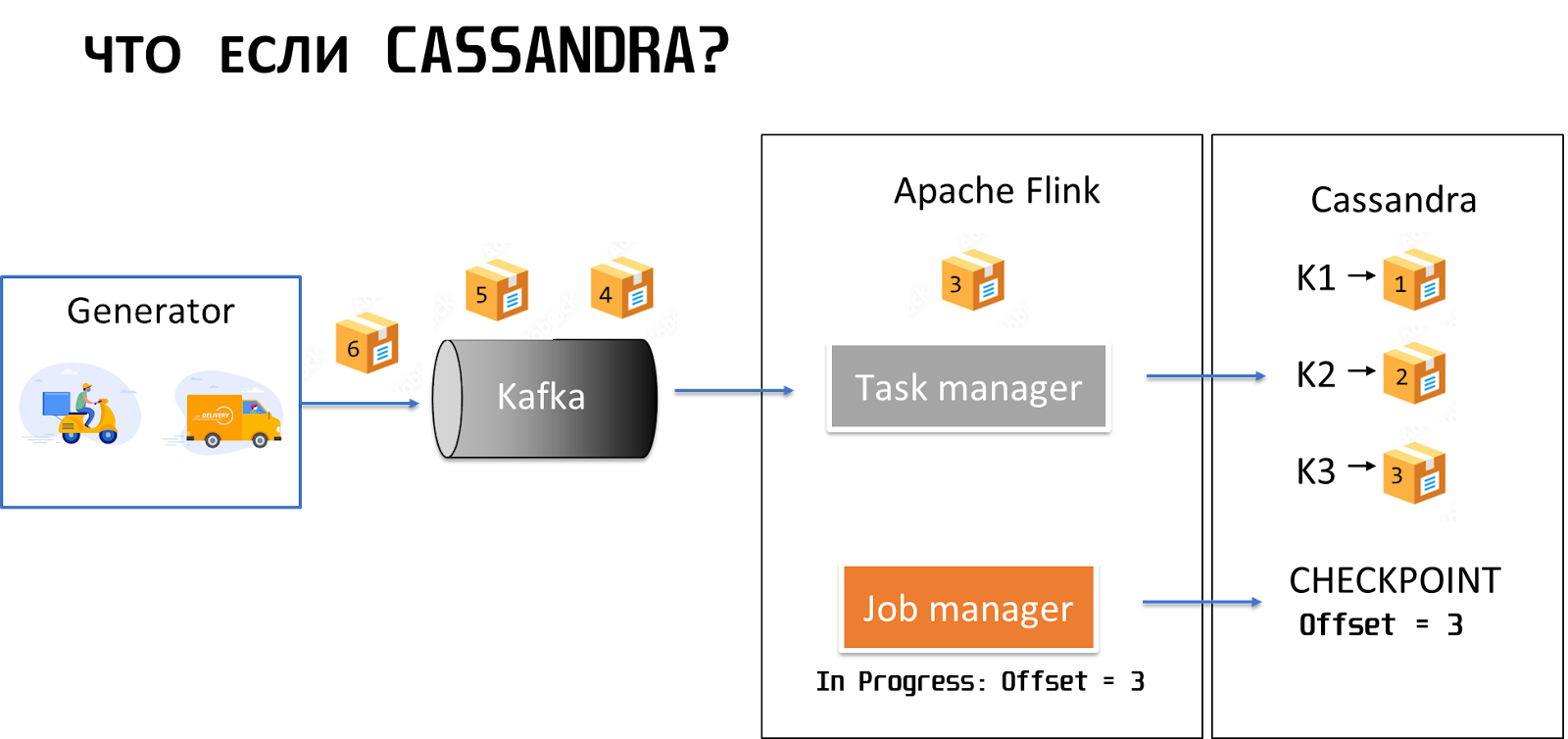
В этом случае можно просто фиксировать офсеты, потому что Cassandra — это key-value storage, она идемпотентна к отправке дубликатов. То есть сколько бы дубликатов одной записи мы не отправили в Cassandra, в конечном состоянии у нас все равно пройдет upsert по ключу, и мы получим только одну уникальную запись.

Поэтому в случае с Cassandra можно получить exactly once, как говорится, for free.
В случае с Postgres можно применить архитектуру, когда есть таблица, куда мы вносим бизнес-данные, и в эту же таблицу дублируем колонку с офсетом.
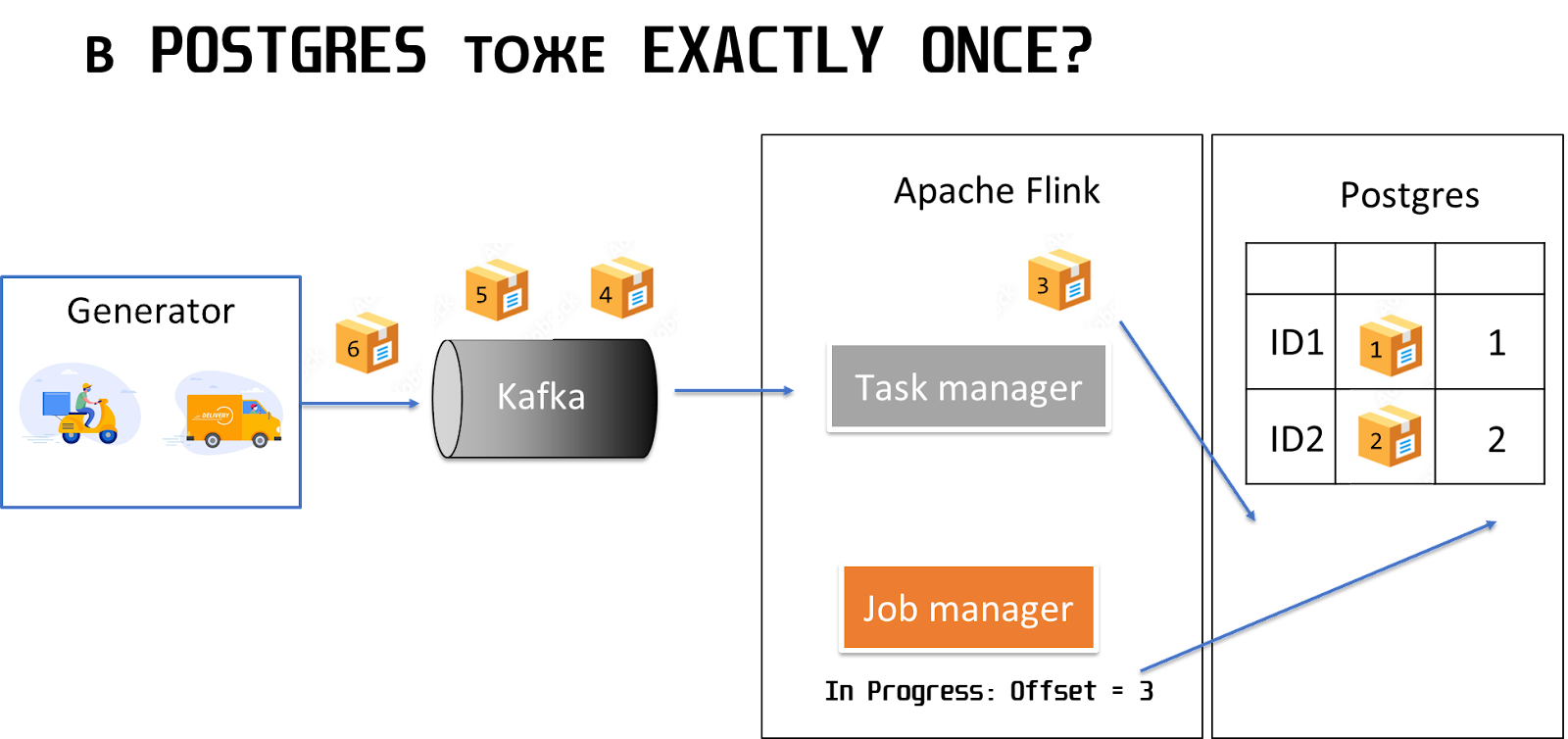
В этом случае одновременно записывается бизнес-информация и фиксируется офсет. Таким образом, возможно, не будет ситуации, когда мы сначала запишем бизнес-информацию, а офсет недозапишем. У нас либо запишется целая строка, либо не запишется ничего. Если будет сбой при рестарте, можно просто взять максимальный офсет и прочитать следующий за ним месседж.
В случае пайплайна Kafka to Kafka можно использовать транзакции, которые доступны в Kafka с 10-й или с 11-й версии, и включить в транзакцию запись данных в топик и запись в commit offset.

Если вдруг что-то пойдет не так, например, с обновлением офсета или с записью данных в топик, то так как они будут входить в транзакцию, произойдет откат. В этом случае у нас тоже не будет проблем из-за того, что какие-то данные записались, а офсет не обновился.
Демонстрация рестарта Apache Flink с примерами того, что данные не пропадают и не появляются дубликаты.
Так как у нас стриминговый пайплайн, что делать, если джоба упала посреди ночи или на длинных праздниках, а поддержки нет?
Эту проблему в Apache Flink можно решить с помощью стратегии восстановления. Таких фичей есть несколько, рассмотрим некоторые из них.

Fixed delay позволяет автоматически перезапустить Flink-джобу через определенный интервал времени. Например, такой код на Java позволяет сделать рестарт Flink-пайплайна 3 раза с интервалом в 10 секунд.
Failure rate — более продвинутый вариант стратегии восстановления.

Позволяет не только автоматически рестартовать джобу через определенный интервал времени, но и фиксировать счетчик таких рестартов за определенный промежуток. Если использовать Failure rate с такими конфигурациями, то джоба будет рестартиться 3 раза на интервале в 5 минут, и каждые 5 минут счетчик рестартов будет обновляться.
В последних версиях Flink есть ещё одна стратегия, которая позволяет бесконечно перезапускать Flink, причем когда задано минимальное и максимальное время.

Время постепенно увеличивается, таким образом, когда время между рестартами достигнет максимума, рестарт будет происходить через это максимальное время.
Иногда мы не хотим, чтобы происходил рестарт, например, когда надо протестировать пайплайн, то чем быстрее мы получим какой-то exception с причиной, почему этот пайплайн упал, тем лучше для всего процесса разработки. В таком случае можно использовать стратегию None, которая ничего не будет делать при возникновении ошибки. Эту стратегию не рекомендуется использовать на продакшене, а первые три вполне подходят.

Фичи Flink Savepoint, Checkpoint и стратегии восстановления позволяют решить проблему с падением обработчиков и коллизиями в данных.
Какие еще проблемы приземления данных?
Горизонтальное масштабирование
Есть большой поток данных из топика Kafka (500k месседжей в секунду), который необходимо обработать. Однако, для того, чтобы сделать это быстро и эффективно, мы должны распараллелить обработку на кластер из машин ограниченной мощности. Если мы не используем кластер, то это может занять много времени, что замедлит процесс обработки. Обработка большого потока данных на одной машине может быть очень медленной и неэффективной. Однако, если мы используем кластер, то мы можем распараллелить процесс и обработать данные гораздо быстрее.
Давайте посмотрим, из чего состоит Flink пайплайн

Source;
Это группа операторов, которые вычитывают данные (события из бизнес-процесса) из Kafka или откуда-нибудь ещё. В демо-проекте каждое событие представлено набором филдов Java-класса:

Здесь есть deliveryId, а также есть статус доставки, время, координаты, ID курьера и т.д.
Операторы обработки. Например, это фильтрация, трансформация, группировка и т.д.
Sink. Это группа операторов, которые позволяют записать результат в конечный storage.
Чтобы реализовать обработку в Flink , необходимо написать код. Flink поддерживает Java, Scala и Python (в посл версии Flink).

Как примерно выглядит этот код:

Стриминговый API у Flink реализован через DataStream. Он типизирован классом DeliveryRide, как в Spark DStream, либо в Structure стриминговый как DataFrame. Мы получаем DataStream из Flink Kafka Source.
Дальше происходит обработка. Здесь используется toString. Конечно, так делать не стоит, если вам надо только привести к toString. Но для демо-проекта это подойдет.
Все это замыкается оператором Sink. Это немножко похоже на API Akka Stream.
Обратите внимание, что в этом коде нет ничего про распараллеливание с помощью каких-то Java, Scala и Python фичей. Преимущество Flink в том, что под капотом он распараллелит пайплайн сам.
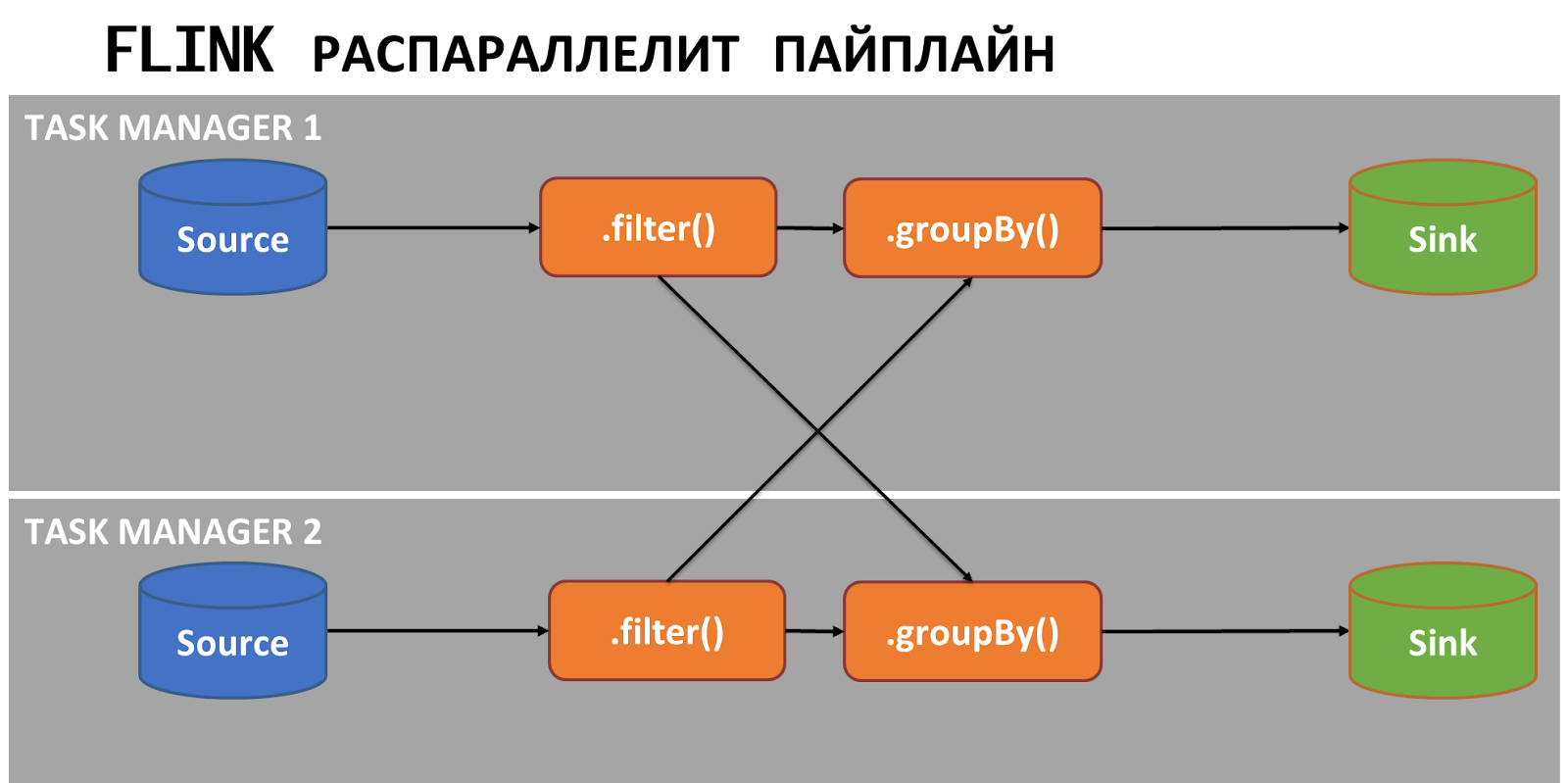
В кластере будут созданы task менеджеры, каждый из которых может работать на отдельной ноде. Но с точки зрения разработчика это будет один пайплайн, который работает распределённо и не только на кластере, но и внутри самого task менеджера.

Apache Flink - идеальное решение для распараллеливания процессов и достижения максимальной производительности.
С помощью Flink можно легко распараллелить пайплайн на несколько слотов внутри пода, контейнера или ноды. Кроме того, он идеально коррелирует с источником данных Kafka, который также является распределенной системой, и получателем HDFS, который хранит данные в блоках на Data Node.
Используя ресурс-менеджеры, такие как Yarn, Cube и Mesos, Apache Flink позволяет оптимально использовать ресурсы кластера. Кроме того, можно легко перезапустить пайплайн в режиме standalone, добавить нод в кластер и не беспокоиться о каких-либо проблемах.
В воркшопе есть примеры, как использовать Flink для оптимизации работы пайплайнов и достижения максимальной производительности. Например, как Flink поведет себя при аварии в кластере, если захотим сымитировать аварию, например, прибить ноды, на которых крутятся task-менеджеры.
Используйте Apache Flink для оптимизации вашего пайплайна и получите максимальную производительность системы!
Пропускная способность получателя ниже, чем у источника
При работе с данными возможна ситуация, когда скорость чтения данных превышает скорость их записи. В этом случае между читателем и писателем может образоваться буфер данных, который не может бесконечно увеличиваться. С течением времени такой буфер может столкнуться с проблемами, например, сообщения будут скидываться либо с начала, либо с конца, или джоба в целом может полностью остановиться.
На схеме изображена такая ситуация:

Source может читать данные из топика Kafka очень быстро, отправляя их в следующую группу операторов с трансформацией. Однако, трансформация или запись может работать медленнее, что может приводить к переполнению памяти и буфера между чтением и обработкой и потере данных.
Для решения этой проблемы, в Apache Flink встроен механизм backpressure, который позволяет информировать операторы о необходимости замедления чтения данных, например, для Source, чтобы скорость чтения была не скорости обработки.
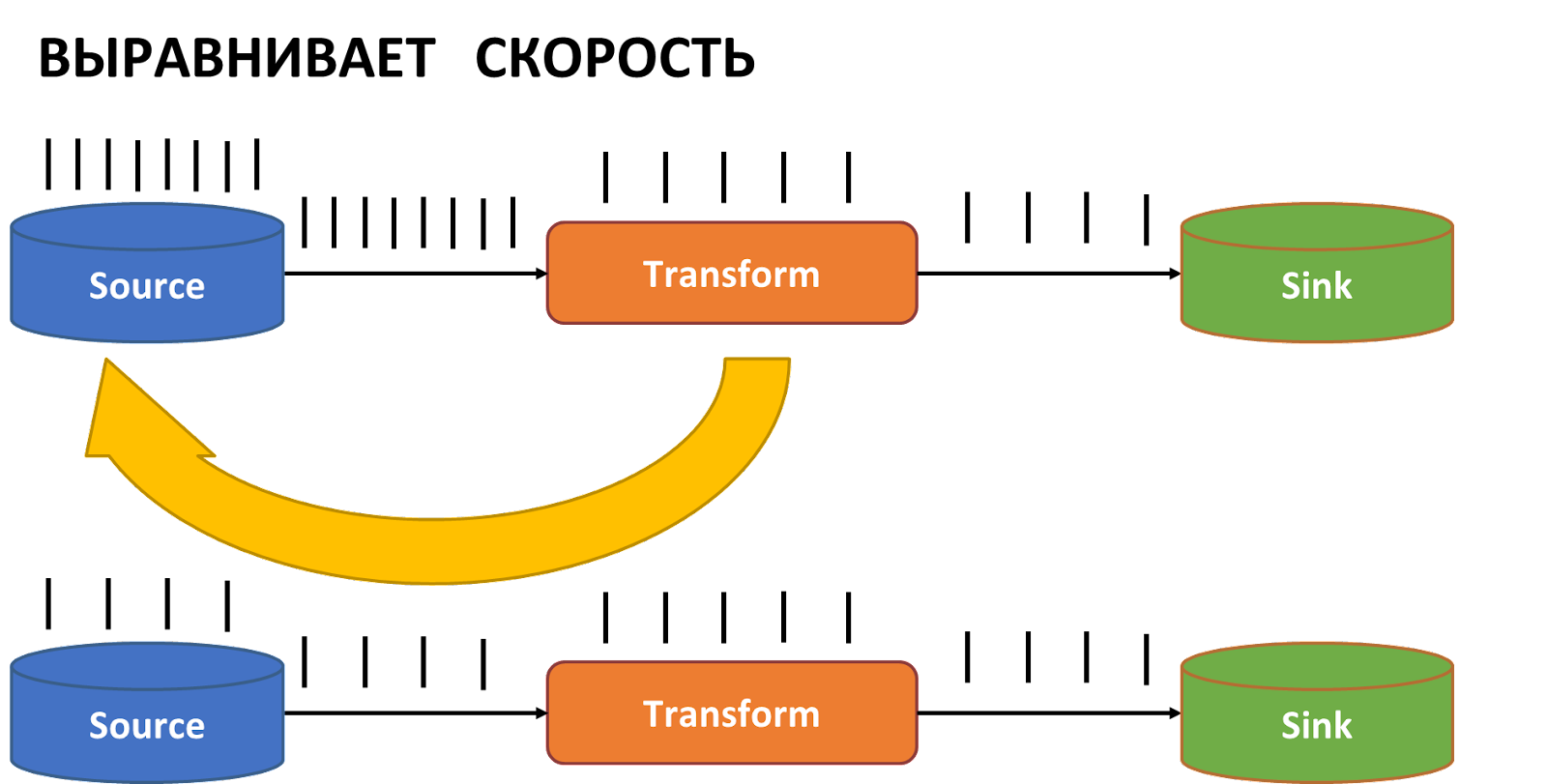
Таким образом обработка будет распределена более равномерно и не возникнет ситуации, когда буфер переполняется и данные пропадают.
Кроме того, в UI и в метриках мы можем также отслеживать рост переполнения данных, с помощью метрики BackPressure. Это очень удобно.

Встроенный механизм backpressure позволяет решить проблему с переполнением буфера и как следствием потерей сообщений, когда она меньше, чем у источника.
Неконтролируемый размер файлов на выходе
При работе с HDFS могут возникнуть проблемы с большим количеством мелких файлов, например размером около 1 Мб. В таком случае Name Node, ответственная за координацию файловой системы в HDFS, может столкнуться с проблемой переполнения оперативной памяти из-за большого количества записей о расположении файлов в кластере.
Однако, Flink предусмотрел эту проблему и предоставляет гибкие интерфейсы роллирования файлов при работе с различными файловыми системами, в том числе с HDFS, Object Storage, локальными файловыми системами и различными форматами данных, включая AVRO, Parquet, ORC, JSON и текстовые файлы. Использование File sink интерфейса позволяет эффективно решать данную проблему.

Пример кода, с помощью которого можно, во-первых, указать получатель, то есть куда будем записывать данные:

И некоторые политики для мержа мелкий файлов:

Одной из этих политик является максимальное время, после которого будет происходить отсечка файла. Файл закроется, создастся новый файл.
Еще один параметр:

В случае если месседжи перестали вдруг поступать из Kafka, он позволяет не держать наполовину заполненный файл открытым, а подождать указанное в коде 5 секунд, и тоже его закрыть.
Киллер-фича это параметр — это максимальный лимит файла.

Например, мы можем указать, что максимальный размер файла 200 Мб. В случае, когда файл достигнет 200 Мб, файл автоматически закроется и мы получим файлы примерно одинакового размера. Эти файлы могут быть в трёх разных состояниях:
In-Progress. Файл открыт для добавления новых записей из FileSink, мы всё ещё пишем месседжи в файл.
Pending. Файл закрыт для добавления новых записей из FileSink, ожидает коммита, закрыт для считывания получателем. Запись в файл уже завершена, но мы его ещё не закоммитили
Finished. Файл закоммичен и открыт для считывания получателем.
Гибкие настройки роллирования файлов для получателя позволяют решить проблему с неконтролируемым размером, с мелкими файлами на HDFS.
Нужна стриминговая обработка
Если есть не только input/output операции, а ещё хотелось бы что-то посчитать на лету, сделать это можно с помощью нескольких фичей. Мы их не будем подробно рассматривать, это можно сделать самостоятельно с помощью воркшопа.
Streaming и batch. Apache Flink поддерживает не только стриминг, в последних версиях они реализовали batch.
Stateful. В стриминге есть поддержка работы со state. Если state очень большой, то Flink очень хорошо работает с RocksDB — embedded базой, которая запускается на каждом task-менеджере.
Поддержка работы с окнами. Это tumbling окна, sliding (скользящие) окна, session-окна, global windows, куда будут включены все данные;
Process & event time в стриминге. В event time есть поддержка watermarks, то есть отсечение данных, которые чуть-чуть опоздали с приходом.
Timers. Это очень классная штука. С помощью таймера можно реализовать оповещение, сложную логику обработки месседжей.
Stream joins. Можно джойнить стримы, причем даже использовать небольшой буфер, если данные в каком-то из стримов запаздывают.
Filter and transform. Это базовые операции фильтрации, группировки, различные трансформации, обогащения, дедупликация и т.д.
Асинхронная запись в несколько получателей. Если мы читаем данные из Kafka и хотим записывать их, с одной стороны, и на HDFS, и в Cassandra, и куда-то еще.
Воркшоп — запись в несколько получателей.
Flink поддерживает стриминговую аналитику и таким образом закрывает последнюю проблему.
Выводы
У нас была задача и поток данных, которые летели в реалтайме в Kafka. Был вопрос, что выбрать для того, чтобы эти данные обрабатывать, формировать историю, делать еще какие-то агрегаты.
Мы рассмотрели проблемы, которые могут появиться, и как Apache Flink решает эти проблемы:
Неравномерный поток данных — Akka actors под капотом.
Обработчики падают и пропадают данные — Сheckpoints, restart strategies.
Горизонтальное масштабирование — есть горизонтальное масштабирование.
Пропускная способность получателя ниже, чем у источника — Backpressure механизм.
Неконтролируемый размер файлов на выходе —гибкие настройки роллирования.
А если еще нужна стриминговая обработка? — поддержка стриминговых вычислений.