
Привет, Хабр!
Меня зовут Грошев Валерий, я Data Scientist и участник профессионального сообщества NTA.
Благодаря концепции открытого правительства, развиваемой в России, в свободном доступе появляются данные о работе государственных органов. Одной из таких площадок с данными является сайт Единой информационной системы (ЕИС) в сфере закупок. Там есть удобный поиск информации, но гораздо больше полезного можно найти на FTP версии сайта — ftp://ftp.zakupki.gov.ru, где хранятся архивы XML‑документов с публичной частью информации о состоявшихся закупках: извещения, протоколы, сведения о договорах. В моем случае была задача проверить, а размещаются ли протоколы и сведения о договорах в соответствии с требованиями 223-ФЗ.
План поста
Выбор инструмента
Первым вариантом решения было извлечение тэгов и запись в табличную СУБД, создавая для каждой из полных цепочек тэгов отдельный столбец. Сразу скажу, что такой подход не сработал в силу нескольких причин. Во‑первых, некоторые теги, имеющие один и тот же смысл и содержащие однородные данные, могли называться чуть‑чуть по‑разному, например, для извещений с разным способом закупки (запрос котировок, конкурс, запрос предложений). Во‑вторых, с течением времени даже для одного и того же типа закупки мог возникнуть дополнительный префикс. Так путь до тэга, содержащий «Номер извещения о закупке», может выглядеть как:
body_item_purchaseProtocolData_purchaseInfo_purchaseNoticeNumber
body_item_purchaseProtocolCCKESMBOData_purchaseInfo_purchaseNoticeNumber
ns2body_item_purchaseProtocolCCAESMBOData_purchaseInfo_purchaseNoticeNumber
ns2body_item_purchaseProtocolCCKESMBOOData_purchaseInfo_purchaseNoticeNumber
И это далеко не самый длинный пример списка разновидностей! Как следствие, получаю большое количество столбцов с пропущенными значениями, данные из которых могли бы образовать всего один столбец — с номером извещения. Если эта проблема ещё могла быть решена путем предварительного анализа всех возможных вариантов и создания унифицированного имени для всех похожих тэгов, то все равно оставалась более общая проблема, связанная с тем, что при записи древовидной структуры в таблицу пространство используется неэффективно. И отдельно стоит отметить, что единого трекера, описывающего с какого числа один тэг заменяется другим нет — есть лишь версии документаций портала ЕИС.
Вторым вариантом решения был материализованный путь. Он показал себя более эффективным в плане хранения, но все равно оставались сложности. Одна из них — скорость обработки входных архивов: загрузка данных из XML файлов в таблицы реляционной базы данных была низкой. И вторая — необходимость извлекать данные при дальнейшей работе в нужный для отчета формат требовало сложных SQL‑запросов и глубокого погружения в проект.
Поэтому появилось третье решение — XML‑ориентированные СУБД (Native XML DBMS) из числа свободно распространяемых (не проприетарных). Сайт DB-Engines содержит рейтинг СУБД разной направленности. Из доступных систем, которые работали с XML, мой выбор остановился на BaseX. Эта СУБД появилась как проект Кристиана Грюна (Christian Grün), который занимался поиском возможной оптимизации работы с большими массивами XML и в итоге в 2010 защитил докторскую диссертацию в Констанцском университете (Германия) на тему «Хранение и запросы больших экземпляров XML» («Storing and Querying Large XML Instances»). Посмотреть саму диссертацию и другие научные публикации по теме эффективного хранения данных и запросов к XML, скачать последнюю версию программы (на момент написания статьи это 10.5) или ознакомиться с документацией можно на официальном сайте BaseX.
О BaseX
BaseX написана на Java, а её дистрибутив очень легкий — текущая версия в zip‑архиве занимает примерно 11 Мб. После установки можем начать работу с GUI:

Но также возможна и работа с помощью командной строки. В примере ниже запустил программу, вывели справку по команде INFO и вышли из диалога. При этом BaseX прощается с пользователем, говоря на прощание «See you», «Have a nice day» или «Enjoy life».

Командная строка удобна для запуска заранее приготовленных скриптов для отбора данных (к ним перейдем чуть позже), но пользоваться возможностями BaseX, конечно, гораздо удобнее через графический интерфейс. Там можно управлять базами данных, писать и отлаживать запросы на языке запросов XQuery, выбирать способ визуализации отобранных данных: в виде дерева, таблицы, или графика.
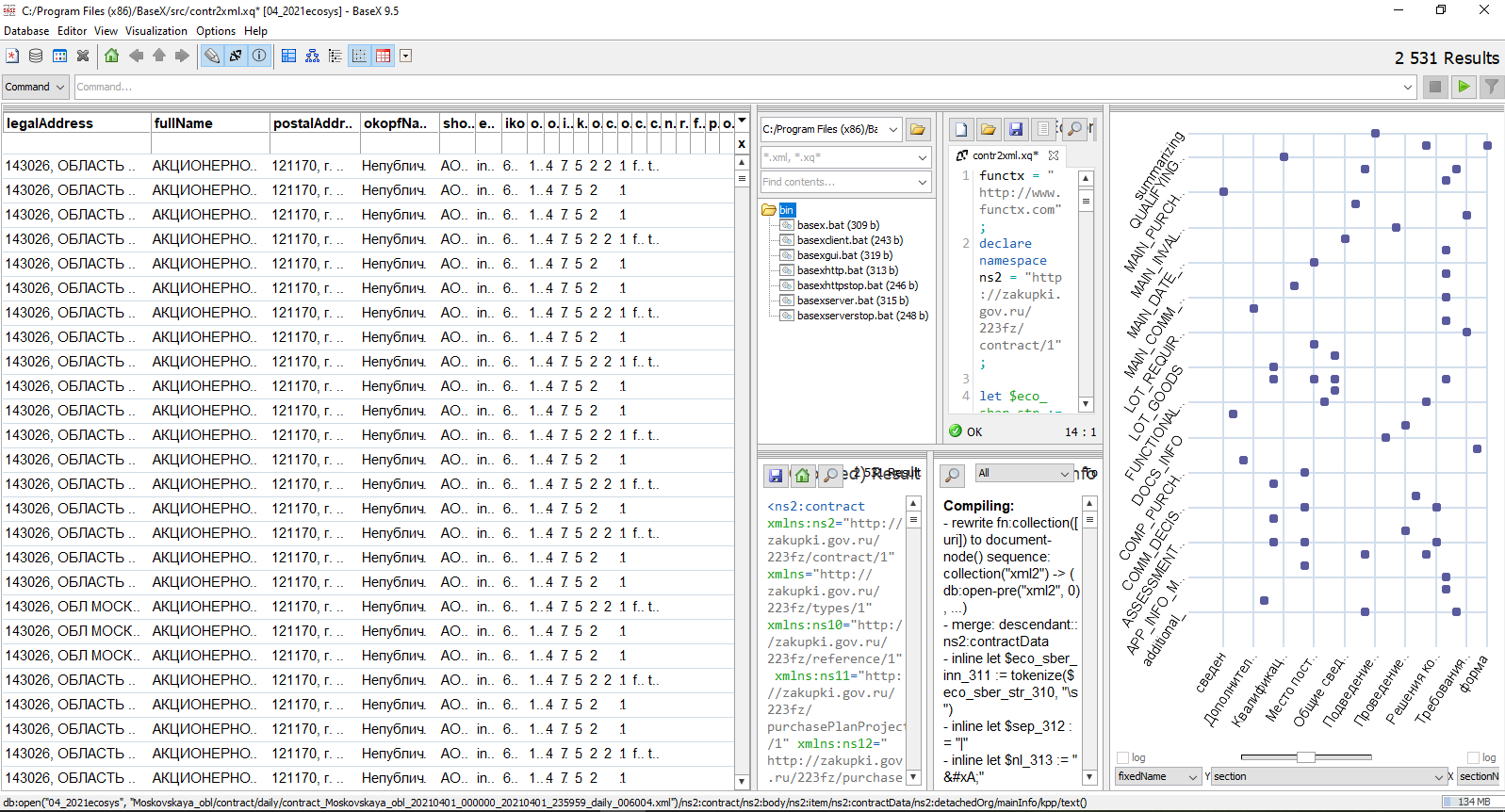
Для отбора данных из файла или базы данных XML используется язык запросов XQuery, который хоть и принципиально отличается от привычного многим SQL, тем не менее логичен по структуре формирования запроса. Основной синтаксис может быть описан инструкцией FLWOR, где:
F — for: «для», предложение, которое привязывает переменную‑итератор к какой‑то входной последовательности, например, последовательности узлов или отдельных значений;
L — let: «пусть», необязательное предложение, присваивающее значение переменной для конкретной итерации;
W — where: «где», необязательное предложение, позволяющее задать значения для фильтрации;
O — order by: «сортировать по», также необязательное предложение, задающее порядок для результатов запроса;
R — return: «вернуть», конструкция, определяющая в каком виде (например, применив одну из стандартных функций для обработки текста) и куда (на экран или в файл) выводить результат.
Достаточная подробная документация по BaseX и XQuery есть на сайте разработчиков программы. Также в интернете можно найти дополнительные источники, содержащие хорошие примеры и полезные советы, но, в основном, на английском. Например, на Learn Database или здесь.
Пример запроса XQuery, отбирающего часть тэгов из сведений о договоре, приведен ниже.
Пример запроса XQuery
import module namespace functx = "http://www.functx.com";
declare namespace ns2 = "http://zakupki.gov.ru/223fz/contract/1";
let $eco_str := file:read-text('C:\Users\u\data\inn59.txt')
let $eco_inn := fn:tokenize($eco_str, "\s")
let $sep := '|~'
let $nl := " "
let $fout := 'C:\Users\u\data\xq_results\contracts.txt'
let $collection := collection("tdb_contr")
for $file in $collection
for $t in doc(document-uri($file))//ns2:contractData/ns2:registrationNumber (: Рег.номер свед. о договоре:)
let $pack_guid := data($t/../../../../*:header/*:guid) (: Глобальный идентиф.информацион.пакета :)
let $cosved_create_dt := data($t/../ns2:createDateTime) (: Дата создания сведений о договоре :)
let $plan_reg_num := data($t/../ns2:planPosition/*:planRegistrationNumber) (: Регистрационный номер плана :)
let $plan_guid := data($t/../ns2:planPosition/*:planGuid) (: Идентификатор плана :)
let $plan_pos_num := data($t/../ns2:planPosition/*:positionNumber) (: Номер позиции плана :)
let $customer_name := functx:trim(string($t/../ns2:customer/*:mainInfo/*:fullName)) (: Полное наименование заказчика :)
let $customer_inn := string($t/../ns2:customer/*:mainInfo/*:inn) (: ИНН заказчика :)
let $placer_name := functx:trim(string($t/../ns2:placer/*:mainInfo/*:fullName)) (: Наименование орг-ции, создавшей договор :)
let $placer_inn := string($t/../ns2:placer/*:mainInfo/*:inn) (: ИНН организации, создавшей договор :)
let $contractRegNumber := data($t/../ns2:contractRegNumber) (: Регистрационный номер договора :)
let $name := data($t/../ns2:name) (: Наименование сведений о договоре :)
where $customer_inn = $eco_inn
let $r := concat(document-uri($file),$sep, $pack_guid,$sep, $t,$sep, $cosved_create_dt,$sep, $plan_reg_num,$sep, $plan_guid,$sep, $plan_pos_num,$sep, $customer_name,$sep, $customer_inn,$sep, $placer_name,$sep, $placer_inn,$sep, $contractRegNumber,$sep, $name,$sep, $nl)
return file:append($fout, $r)Решение
Для решения описанной в начале поста задачи были скачаны исходные архивы с XML‑файлами за разные периоды, которые суммарно занимали на диске от нескольких сотен мегабайт до десятков гигабайт.
При создании базы есть возможность отметить опцию «Парсить файлы в архивах», чтобы предварительно не распаковывать все имеющиеся файлы, а предоставить это сделать самой утилите. И второй важный момент при создании базы данных в случае архивированных XML — это отметить опцию «Включить имя архива в полный путь к документу». Если этого не сделать, то может возникнуть ошибка из‑за того, что в архивах с разными именами могут находиться файлы с одинаковыми короткими путями.
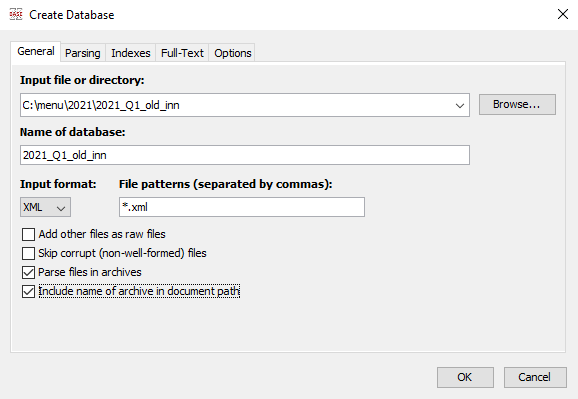
Процесс формирования базы данных из указанного местоположения с архивами файлов сопровождается окном статуса, где отображается текущий статус обработки.

Для 953 Мб исходных данных создание базы данных на стандартном рабочем месте пользователя занимает около 5 минут, что будет отражено в одном из окон графического интерфейса.
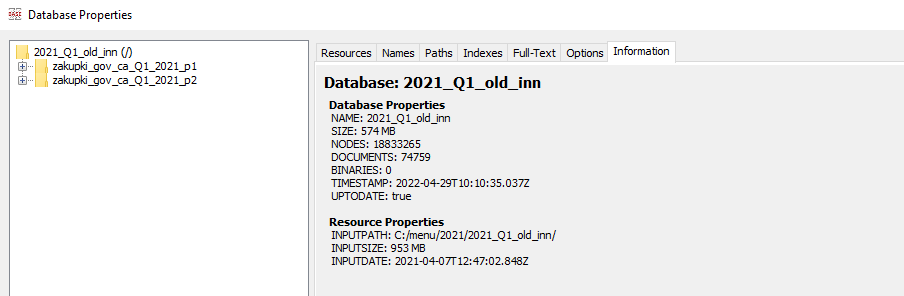
В свойствах созданной базы данных можно увидеть статистику: 574 Мб занимают файлы, в которые преобразовались исходные 927 архивов, занимающие 953 Мб. Всего обработано 18.8 млн тэгов в 74 759 XML-документах.
Извлеченные текстовые данные в некоторых случаях требуют дополнительной обработки, чтобы удалить ненужные переводы строк, спецсимволы, а также исключить нецелевое использование символа, выбранного в качестве разделителя столбцов. В сложном случае в качестве разделителя столбцов при выгрузке из BaseX использовалось сочетание двух стандартных разделителей — вертикальной черты и точки с запятой, т.к. и то, и другое по отдельности встречалось внутри текстовых полей. Для решения задач подобного рода использовался скрипт на Python в Jupyter Notebook.
Скрипт на Python
def prepare_csv(file_orig, enc):
"""Предобработка текстового файла перед загрузкой в датафрейм:
удаление лишних переносов строк
Усложненная версия -- два символа в качестве разделителя в итоге меняются на один."""
with open(file_orig, 'r', encoding=enc) as f:
text_raw = f.read()
# заменяем ненужные переводы строк и разделитель на пробелы / пробел+подчеркивание
pat1 = r'[^~]\n{1,20}' # переводы строк, которые не нужны
pat2 = r'\s\|\s' # вертикальная черта внутри значения поля
pat3 = r'\|\~'
text_clr = re.sub(pat1, " ", text_raw)
text_clr = re.sub(pat2, " _ ", text_clr)
text_clr = re.sub(pat3, "|", text_clr)
# выводим строку в новый файл
ffolder = os.path.dirname(file_orig)
f_name = os.path.splitext(os.path.basename(file_orig))[0]
f_name_mod = f_name + '_clr.csv'
file_in = os.path.join(ffolder, f_name_mod)
with open(file_in, 'w', encoding=enc) as f:
f.write(text_clr)
return file_inПолученный очищенный текстовый файл уже легко загружается в датафрейм Python-библиотеки pandas для формирования таблицы в удобном виде с возможностью выгрузки в Excel. Например, итоговая таблица выглядит так:
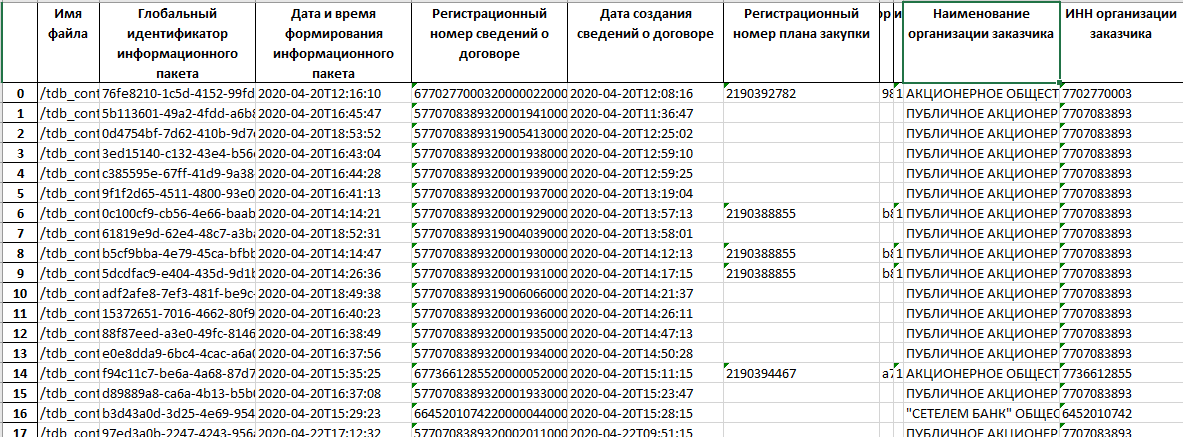
Результат
Анализ структуры данных с последующим применением языка запросов XQuery для СУБД XBase, а также скриптов на языке Python позволил сформировать суммарный отчёт с информацией о договорах на основе большого количества архивов с xml документами ресурса ЕИС. Применение данного подхода эффективно использует ресурсы компьютера в отличии от табличных СУБД и может быть использовано для решения задач, связанных с извлечением данных из наборов xml файлов.