
Всем привет! Меня зовут Антон и я руковожу Big Data платформой в "Детском мире".
На Хабре проходит сезон больший данных, и я решил что это отличная возможность поделиться нашим опытом внедрения Dbt (инструмент для оркестрации Sql витрины). На хабре уже статьи по инструменту, в моей статье, покажу как пришли от запуска ноутбука в Zeppelin к промышленному решению запуска большого количества витрин написанных на SparkSql в OnPrem Hadoop.
Введение
Какие задачи мы хотим решать?
У нас есть разграничение по задачам с Дата Аналитиками, они пишут витрины на Sql и ставят задачи на регулярную выгрузку витрин из Операционного хранилища.
Дата Инженеры строят пайплайны по выгрузке данных и ставят витрины на регулярное обновление.
Что у нас есть?
Zeppelin Notebook
Airflow запущенный в Kubernetes (позже станет ясно зачем это уточнение)
Gitlab
Hadoop
Spark Thrift Server
К чему хотим прийти?
Витрины данных по методологии с GitOps
Порядок в Sql из коробки
Ускорение разработки тестирования и доставки витрин
Поиск зависимостей в витринах данных
Довольные Аналитики и Инженеры
Zeppelin Notebook

Сначала было всего 3 витрины и хотелось быстро поставить их на регулярное построение, для этого мы сделали Zeppelin ноутбук и поставили его на регулярный запуск в определенное время. Быстро и работает, ура ура.
За пару месяцев появились еще витрины, и стало пахнуть жареным так как витрины это большое полотно sql то стало тяжело ориентироваться в ноутбуке, плюс мы начали путаться что за чем идет.
Утра стало начинаться с разбора почему у нас с витринами что то не так, пора что то то делать.
Airflow + SparkOperator
Витрин стало около 8 и аналитики раз в пару дней просили их обновить.
Мы добавили витрины в git, но в них все равно надо было высматривать зависимости.
Первый оператор попавшийся под наблюдение SparkSqlOperator он делает все как мы и хотим даешь ему sql он его запускает, НО есть нюанс он работает только в client mode spark job, а мы в кубере, где внутри пода кубернетесовские адреса, задача стартовала в yarn, но падала с ошибкой.
Caused by: java.io.IOException: Failed to connect to kuber-worker-07.svc.cluster.local:37177
Тогда пришла идея сделать свой SqlRunner, суть проста берет файл sql и запускает его, через spark-submit, теперь мы запускаем наши sql с помощью airflow.
Внедрение Gitlab для Аналитиков
Как ни странно это один из самых непростых этапов для этого нам пришлось, научить наших аналитиков в работе с коммитами, ветками, мерж реквестами.
Также выяснится неприятный момент что на Windows запустить sql-запрос в Spark не получается так как есть какие-то несовместимости библиотек python, а wsl не взлетел из за vpn, для этого мы придумали триггер в Gitlab CI чтобы вообще никак не зависит от машин аналитиков.
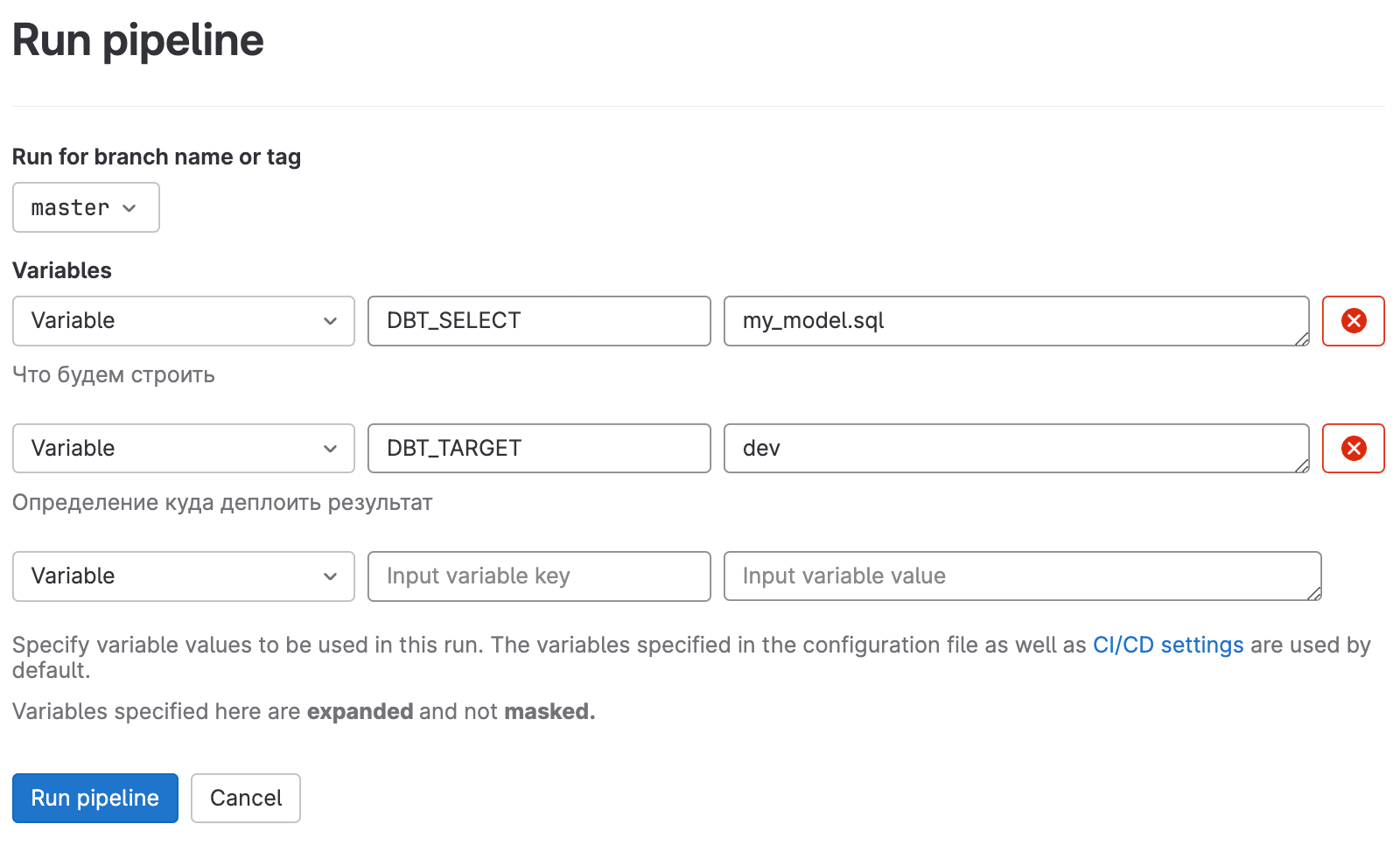
Как понять что коммит валидный в Gitlab CI/CD?
С начала мы по regex проверяем где не проставлены ref и source в секции FROM
Для этого у нас существует специальная база в hive и конфигурация дбт которая создает из витрин только вьюхи. То есть когда мы запускаем в Airflow мы создаем настоящее витрины которые отрабатывают по полчаса, а 20 вьюх могут создаться за пару минут.
07:23:40 Finished running 18 view models in 0 hours 1 minutes and 3.60 seconds (63.60s).
07:23:40
07:23:40 Completed successfully
07:23:40
07:23:40 Done. PASS=18 WARN=0 ERROR=0 SKIP=0 TOTAL=18так мы понимаем что не сломали что то технически

Бизнес правильность лежит на плечах аналитиков.
Airflow + SparkOperator + Dbt
У нас есть Airflow + SparkOperator + Dbt, теперь надо заставить их дружить.
Сразу скажу что варианты запуска в Dbt Cloud мы не рассматриваем.
Остается 2 способа запуска витрин из Airflow
Вызвать dbt run и ждать выполнения https://docs.astronomer.io/learn/airflow-dbt
Прочитать manifest.json и на его основе создавать SparkSubmitOperator https://www.astronomer.io/blog/airflow-dbt-1/
Первый способ требует spark thrift server он у нас есть, но запущен с лимитами по ресурсам, и предназначен для adhoc запросов, и не получится для каждой витрины контролировать ресурсы.
Второй способ это то что нам нужно, у dbt есть команда compile благодаря которой в папке target появятся sql файлы, а это то что нужно для нашего SqlRunner.
Остался важный вопрос как понимать что источники для dbt уже готовы?
Для этого мы используем ExternalTaskSensor мы написали специальный метод утилитный который по названию таблицы выдает нам таску на которую надо ссылаться.
У этого подхода есть много плюсов:
мы зависим от внешних систем для понимания готовности наших витрин
во вкладке DAG Dependencies мы видим что от чего зависит

В сенсоре мы можем перейти на ссылаемую таску.

Визуализация

Вот такой граф в одном из проектов, салатовые это источники, синие это витрины, даже представить не могу сколько времени заняло бы делать с даг со всеми сенсорами на источники.
Документация
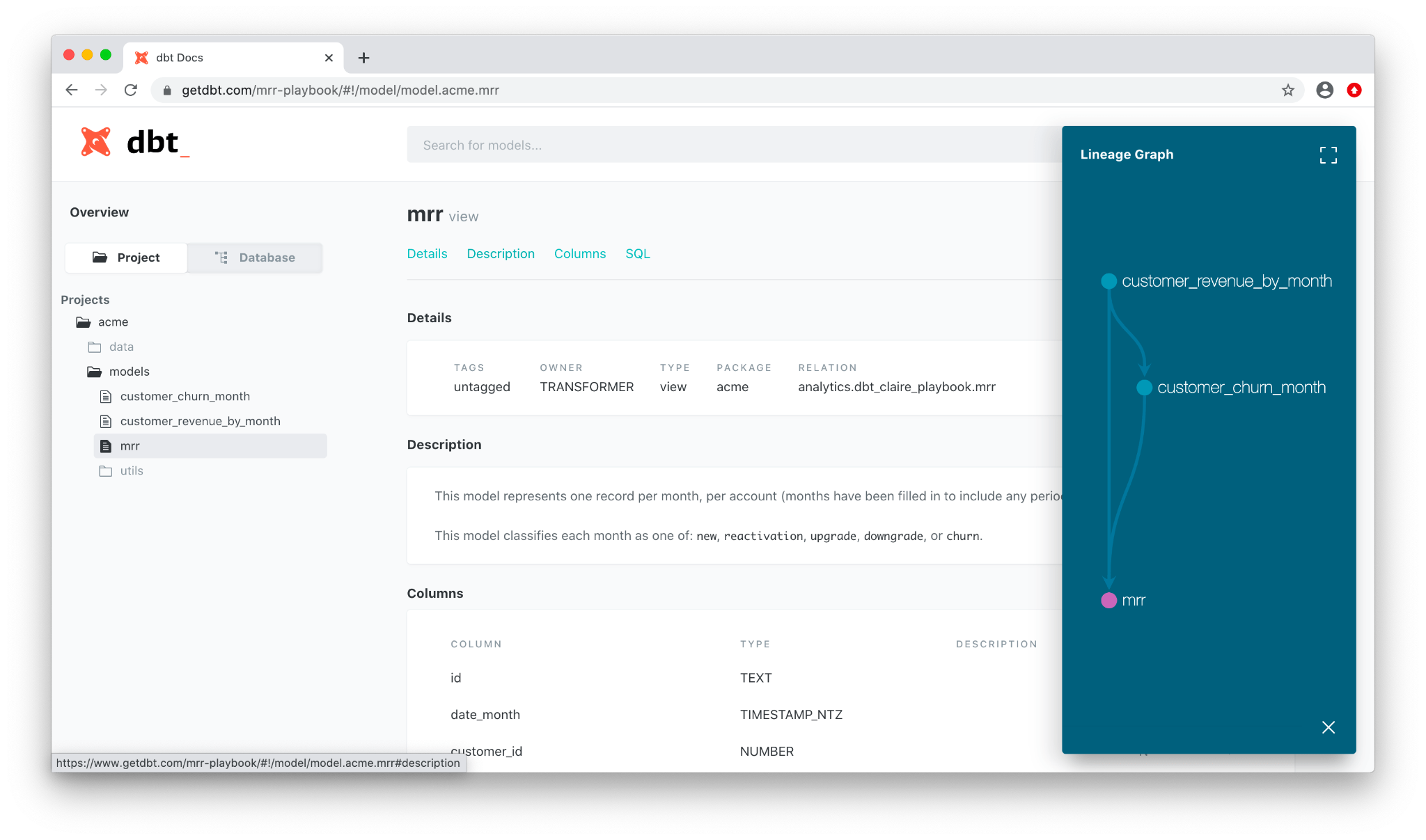
Также в Dbt можно проследить откуда взялась колонка, и подтянуть документацию.
Итоги
Мы очень довольны инструментов, так как он позволяет нам выполнять свои задачи намного быстрее и удобнее, предоставляет визуализацию и документацию из коробки.
Комментарии (3)

pecmapm
07.06.2023 08:45Антон, спасибо за статью! Интересно узнать ваши кейсы по использованию dbt. Не думали использовать vscode для аналитиков и инженеров в контейнерах? Не думали использовать redash (https://redash.io/) для аналитиков?

BioQwer Автор
07.06.2023 08:45Не думали использовать vscode для аналитиков и инженеров в контейнерах?
да я пытался, но версии не сходились gitlab, на тот момент эти контейнеры были в beta.
и в целом оказалось что ребятам удобнее тестить запрос локально а потом скриптом править его, что расставлять ref и sourceНе думали использовать redash (https://redash.io/) для аналитиков?
Будем использовать, но не для spark thrift а для clickhouse.
Redduck119
Детский Мир постоянно шлет мне рекламу, хотя мы уже выросли и не являемся их клиентами. А внуков пока не ждем еще лет 5. В пустую тратит свои ресурсы.
Подправьте свои бигдаты!