
Привет, Хабр! Меня зовут Максим Кита, я разработчик баз данных, специализируюсь на анализе, планировании и выполнении запросов, а также на оптимизации производительности.
Статья была подготовлена в начале года, когда я еще работал в ClickHouse. В ClickHouse я отвечал за словари, JIT-компиляцию, анализ и планирование запросов, но больше всего занимался оптимизациями производительности. Об этом и поговорим!
Я расскажу о высокоуровневой архитектуре ClickHouse, CI/CD, тестировании производительности, интроспекции, абстракциях и алгоритмах и выборе библиотек для высокопроизводительных приложений. Поделюсь ниндзя-техниками, которые помогут ускорить ваши системы. Вы сможете попробовать эти советы и практики на своем проекте и оценить насколько они полезны.

Высокоуровневая архитектура ClickHouse
ClickHouse — это колоночная база данных. Все данные хранятся и обрабатываются поколоночно:
Во время выполнения запроса читаются только необходимые колонки.
Происходит улучшенное сжатие данных, за счёт локальности данных.
Оба фактора значительно сокращают объем операций ввода-вывода во время выполнения запроса.
В ClickHouse данные обрабатываются блоками. Блок содержит несколько столбцов со строками. Максимальное количество строк в блоке по умолчанию 65 505. Блок — это всего лишь массив колонок. Колонка — это массив примитивного типа. И такой подход в движке выполнения работы с массивами имеет следующие преимущества:
Улучшает утилизацию кэшей и пайплайна CPU.
Позволяет компилятору автовекторизовать код с использованием SIMD инструкций.

Массив у нас — это не std::vector, а PODArray. Он отличается от std::vector тем, что использует специальный аллокатор из ClickHouse, который поддерживает операцию realloc, используя функцию mremap для больших массивов.
В ClickHouse не делают memset во время операции resize, в отличии от std::vector. Встречается практика, когда необходимо реализовать следующий функционал — есть несколько входных массивов и нужно что-то записать в выходной массив. Часто это делается в цикле, а перед ним для выходного массива нужно сделать resize, чтобы сразу писать по индексу, так как в таком случае компилятор сможет векторизировать код.
Ещё одна особенность PODArray в ClickHouse это padding 15 байт на конце массива. Это позволяет не обрабатывать хвосты во время функции memcpy, а это дает дополнительную производительность.
Колонки сложных типов состоят из колонок простых типов. Например:
Nullable — это колонка с данными и колонка, которая содержит битовую маску является элемент null или нет.
Array — это колонка с данными и колонка с оффсетами.
Const — константная колонка, представляет собой просто одно значение.

В коде за всё это отвечает полиморфный класс IColumn. В этом классе объявлены методы, необходимые для выполнения различных реляционных операторов. Среди них, например, фильтрация, получение перестановки для сортировки и прочие методы.
В большинстве функций ClickHouse работающих с IColumn этот тип приводится к какому-то конкретному и функция ClickHouse работает с ним уже без использования виртуальных функций из IColumn, просто со специализацией.

Когда запрос попадает в ClickHouse, его сначала парсят в АST, затем делают довольно сложные AST-оптимизации. После из AST строится и оптимизируется логический план выполнения запроса. Из логического плана выполнения запроса строится и оптимизируется физический план выполнения запроса, а дальше физический план просто выполняется.
CI/CD Pipeline
Очень важная вещь, за счёт которой разработка ClickHouse двигается быстро — это CI/CD pipeline.

Он состоит из следующих компонентов:
Функциональные, интеграционные тесты.
Санитайзеры: ASAN, MSAN, TSAN, UBSAN, под которыми запускаются все тесты.
Дополнительные фаззеры типов данных и кодеков сжатия данных. Все они тоже работают под санитайзерами.
Специальный AST фаззер, генерирующий разные запросы.
Стресс-тесты. В ClickHouse есть специальный стресс-тест с санитайзером, который переопределяет методы у condition variable, у mutex, чтобы создавать больше contention, и рассылает сигналы остальным потокам. Ещё есть специальные тесты, где ClickHouse рандомизирует все настройки.
Тесты производительности.
Тесты производительности
Тесты производительности запускаются на каждый commit в каждом pull request и на каждый commit в master. Это некоторый XML-файл.

Запрос пишется в секции query. Дополнительно используются подстановки, например мы хотим протестировать запрос используя разные функции или разные данные.
Результаты тестов производительности выглядят так:
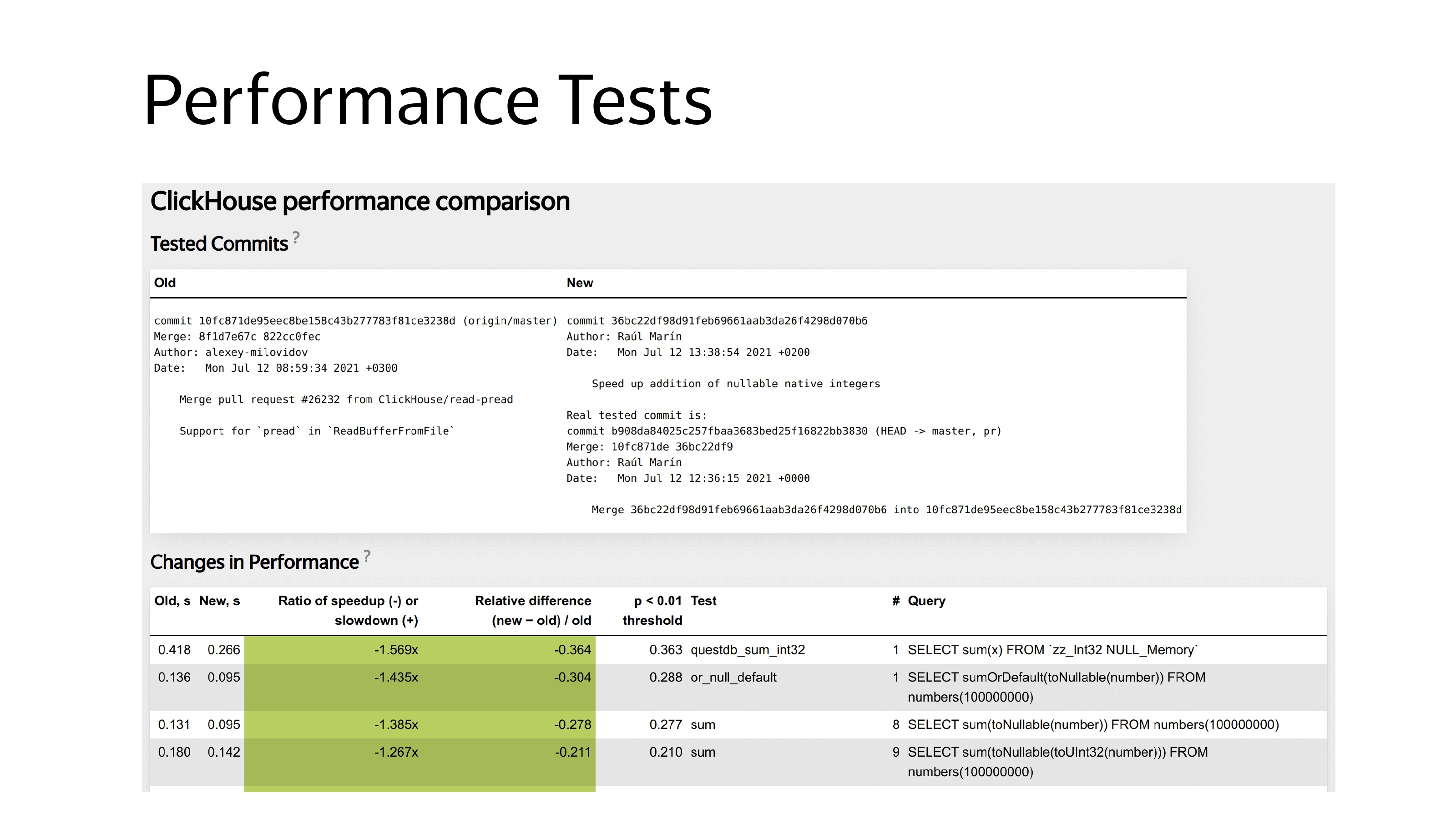
Есть старый и новый commit, есть данные насколько изменилась производительность и какие это были запросы и в каких тестах они находились. Во время запуска тестов производительности ClickHouse собирает различные статистики.
Это делается, чтобы проанализировать изменения и при необходимости провести отладку. Например, есть статистика собранная с помощью perf, показывающая количество циклов CPU, вот так выглядит график:

После тестов производительности можно посмотреть количество циклов CPU. Старый запрос обозначается фиолетовыми треугольниками, а новый — зелёными. То же самое есть и для других счетчиков perf, например cache misses.
Такая статистика очень полезна. Например, при оптимизации, можно найти лишний if, убрать его и запросы ускорятся. Затем можно посмотреть на статистику branch misses и увидеть, что их стало меньше.
Многие думают что тесты производительности нужны только для нахождения регрессий, но это не совсем так. Тесты производительности — это инструмент, который помогает находить места для ускорения производительности во многих сценариях. С ним можно пробовать:
Разные аллокаторы и смотреть, как ClickHouse отреагирует на смену аллокатора, какие запросы ускорились, чтобы была возможность потом пойти и посмотреть за счет чего они ускорились вручную.
Разные библиотеки, например, поменять библиотеку для парсинга JSON.
Разные опции компилятора. Например, включить на максимум loop unrolling и смотреть, что ускорилось. Потом пойти и посмотреть за счет чего эти запросы ускорились, скорее всего там будет какой-нибудь цикл и локально в этих циклах сделать этот loop unrolling.
Пробовать разные компиляторы, например GCC, clang.
Включать AVX, AVX2, AVX512 и смотреть, какие запросы запросы ускорились, скорее всего были векторизованы какие-нибудь циклы и для циклов вручную сделать dynamic dispatch.
Чтобы писать запросы для тестов производительности, нужно придерживаться некоторых правил:
Запрос не должен быть слишком короткий, иначе он ничего не измеряет.
Запрос не должен быть очень длинным, так как он подвержен различным внешним факторам, например: диски, сеть, баги в ядре, перегретый CPU — всё это может повлиять на результаты тестов производительности.
Запрос должен тестировать какой-то функционал в изоляции.
Например многие разработчики при попытках оптимизации производительности хеш-таблиц, начинают тестировать свои хеш-таблицы на случайных данных. Лучше всегда тестировать на реальных данных. Взять их можно с сайта ClickHouse, где используются обфусцированные данные Яндекс Метрики.

Теперь подробнее про то как работают тесты производительности:
На одном сервере запускаются две версии ClickHouse одновременно, один до коммита, второй после коммита.
Запускаются тесты производительности и выполняются запросы то с одним, то с другим сервером.
Считаются медианы и собираются различные статистики, например CPU Branch Misses, CPU Cache Misses.
Используя статистические методы считается максимальная разница в медианном запуске запроса (T), которую можно получить, если ничего не поменялось.
Используя D разницу медианных запусков запросов и T, можно понять существенные были изменения в производительности или нет.
Нестабильные запросы
Вроде бы всё просто, но есть один момент. Что если статистика производительности изменилась, к примеру, на 10%, хотя никаких изменений не вносили?
Производительность для таких запросов просто скачет. Их называют нестабильные запросы. Это большая проблема для тестирования производительности. Нужно разбираться, почему так происходит. Самые основные проблемы:
лишние аллокации;
большие копирования;
может быть плохо написан сам запрос;
разные внешние факторы — проблемы с дисками, с сетью, background-активности.
Удалять или переписывать тесты производительности, нужно только если плохо написан запрос. Во всех остальных случаях, следует глубоко разобраться, что там всё-таки произошло.
Возьмем для примера следующий тест производительности.

В нем мы смотрим на NLP функции из ClickHouse. В тесте используются функции которые могут определить язык или charset. Результаты этого теста производительности были нестабильны, но почему это происходило было непонятно.
В реализации этих функций использовался следующий цикл:

В цикле мы создаем хеш-таблицу, в эту хеш-таблицу записываем n-граммы, а после сравниваем их с уже заготовленными словарями. Далее мы смотрим с каким из словарей было самое близкое соответствие.
Мы аллоцируем хеш-таблицу внутри цикла, и это является основной проблемой. В итоге мы это место потестировали и поменяли эту хеш-таблицу, на хеш-таблицу которая будет аллоцирована на стеке. В ClickHouse есть свой framework для хеш-таблиц, и мы взяли ее оттуда. Когда это сделали, произошло увеличение производительности примерно до четырёх раз, буквально на ровном месте:

Introspection
В ClickHouse мы собираем все что мы можем собрать в user-space. Для каждого запроса собирается довольно большое количество profile events, которые затем можно анализировать.

Используя системный вызов getrusage, мы собираем следующие метрики: RealTimeMicroseconds, UserTimeMicroseconds, SystemTimeMicroseconds, SoftPageFaults, HardPageFaults.
Дополнительно мы собираем taskstats из procFC.
Еще используя proc файловую систему, мы собираем следующие статистики:
OSCPUVirtualTimeMicroseconds, OSCPUWaitMicroseconds (с доступом /proc/thread-self/schedstat).
OSIOWaitMicroseconds (с доступом /proc/thread-self/stat).
OSReadChars, OSWriteChars, OSReadBytes (с доступом /proc/thread-self/io).
С помощью системного вызова perf_event_open для каждого конкретного запроса можно включить perf профилировщик внутри ClickHouse, и собрать например количество CPU cache misses, CPU branch misses.
Ещё есть метрики, которые специфичны для ClickHouse, сейчас их больше 300. Например, сколько файлов было открыто во время запроса, сколько времени потрачено на чтение с дисков, на пересылку данных по сети, статистика Zookeeper и Jemalloc.
Все эти метрики можно экспортировать в Graphite и Prometheus.

Сделав запрос в system.query_log и указав query_id, можно посмотреть например статистику perf events. Сколько было затрачено циклов CPU на каждый запрос, сколько было branch misses.
Ещё в ClickHouse периодически собирают stack traces со всех потоков в обработчике сигналов. Для этого бинарник должен быть скомпилирован с опцией -fasynchronous-unwind-tables. Ещё нужна специальная библиотека для раскрутки стека. В ClickHouse используют свою версию LLVM libunwind библиотеки, которая умеет раскручивать стек. Дорабатывать ее пришлось по следующим причинам:
Если во время раскручивания стека, секция .eh_frame содержит неправильные инструкции раскручивания (баг в компиляторе, баг в написанном от руке ассемблере). Тогда в LLVM libunwind произойдет краш.
Библиотека раскрутки стека должна быть безопасной для сигналов, например не должно быть аллокаций во время раскрутки стека.
Например, мы можем посмотреть стектрейсы у всех потоков из system.stack_trace:

Бывают ситуации, когда заходишь на сервер, а на нем произошел deadlock. С ClickHouse чтобы увидеть, что сейчас происходит на сервере достаточно сделать запрос из system.stack_trace. В описанном коде видно, что есть поток, он ждёт на condition variable пока начнётся запрос или какого-то сигнала.
Когда есть возможность собирать stacktraces, можно делать ещё более крутые штуки. Например, сгенерировать Flame Graph, прямо не выходя из ClickHouse.

Что такое Flame Graph, можно почитать здесь. По нему смотрят в каких stacktraces больше всего времени проводилось.

Одна из проблем у разработчиков — как измерять производительность в распределённой системе. Потому что во время распределённого запроса трудно проанализировать каждый сервер, участвовавший в выполнении запроса.
В ClickHouse можно обращаться ко всем таблицам в кластере, используя cluster табличную функцию.

То есть произошёл запрос, вы собрали статистики со всех участников запроса в кластере, поагрегировали, затем можно их анализировать.
Abstractions and algorithms
Опустимся на уровень ниже. Самое важное — интерфейсы высокопроизводительных систем должны быть определены алгоритмами.

Здесь не работает top-down подход. Если сначала дизайнить какие-то общие интерфейсы, а потом пытаться писать низкоуровневые структуры данных — это всё работать не будет, так как интерфейс должен определяться структурой данных. Для каждой структуры данных можно подобрать оптимальный интерфейс, например чтобы там не было лишних копирований. Интерфейсы должны раскрывать структуры данных.
Высокопроизводительная система поначалу должна работать хорошо как минимум на одном конкретном сценарии. В ClickHouse основной сценарий это агрегация данных, которые помещаются в оперативную память.
Дизайнить систему нужно, исходя из возможностей вашего оборудования. Предположим, у вас есть хеш-таблица. Если все данные помещаются в кэши, то всё нормально, если не помещаются, то нужно посчитать доступ к основной памяти. Например, доступ к основной памяти 100 наносекунд, затем можно посчитать, и посмотреть, сколько должно быть лукапов в секунду на одно ядро и проверить, тормозит ваша хеш-таблица или нет.
Стоит отметить, что нет никакой серебряной пули или лучшего алгоритма для конкретной задачи. Для решения нужно пробовать разные алгоритмы, подходы, смотреть что работает, а что нет. Обязательно делать всё это на реальных данных. Нужно учитывать, что все алгоритмы подвержены распределению данных. Например, алгоритмы фильтрации, join, сортировки зависят от количества уникальных значений.

Когда перед вами стоит сложная задача, лучше представить её в виде нескольких простых задач и разбирать их по-отдельности. Потом выбранные для задачи структуры данных и алгоритмы, можно начинать тюнить низкоуровневыми трюками. Это могут быть различные специализации, SIMD-инструкции, JIT-компиляция.
Самое важное в ClickHouse — это агрегация. Главное архитектурное решение — выполнять агрегацию эффективно как на одном сервере, используя множество потоков, так и используя множество серверов. В таком случае получается масштабируемая архитектура. Например, чтобы быстрее выполнять агрегацию на одном узле, нужно докинуть туда оперативки. Чтобы масштабироваться горизонтально, добавляем шардов.
Основной компонент агрегации — это фреймворк для хеш-таблиц, в нём находится множество специализированных хеш-таблиц. Например, хеш-таблица для строк, маленькие и большие хеш-таблицы, двухуровневые хеш-таблицы, всякие lookup-таблицы и прочие хеш-таблицы.
После того как основная часть готова, можно начинать добавлять специализации. Для Nullable, Low Cardinality, Sparse колонок в ClickHouse оптимизировали множество низкоуровневых вещей. Например, уменьшали количество аллокаций, уменьшали размер структур данных в памяти, объединяли множество операций вместе, чтобы уменьшить количество виртуальных вызовов. Затем в GROUP BY добавили JIT-компиляцию и кэш-предсказания размера хеш-таблиц.
Оптимизировать производительность – значит пытаться делать много разных подходов и почти всегда без результатов.
Для каждой задачи есть множество степеней свободы. Например разберем задачу сортировки данных.

Сортировка данных бывает:
стабильная/нестабильная;
во внешней памяти/в оперативке;
с лимитом/без лимита;
данные отсортированы/почти отсортированы/не отсортированы;
какое распределение данных/количество уникальных значений;
можно ли использовать векторизированный алгоритм сортировки;
можно ли аллоцировать дополнительную память.
Если начать отвечать по всем этим пунктам, то поиск оптимального алгоритма значительно ускорится.
Хороший дизайн это когда есть низкоуровневая вещь хорошо оптимизированная. Вокруг неё вы делаете высокоуровневые абстракции, например, красивые С++ интерфейсы.
В ClickHouse это работает во многих местах.
Есть агрегация. Это обёртка над фреймворком хеш-таблиц.
Есть компоненты поменьше, например, RangeCache словарь. Это обёртка над статическим интервальным деревом, которое находится в оперативной памяти.
Есть сортировка и вставка в MergeTree. Это обертка над фреймворком для сортировки с большим количеством специализаций.
Недавно в ClickHouse начали улучшать фреймворк для сортировки. Добавляли специализации, меняли структуры данных. Удалось ускорить вставку в MergeTree.

Для вставки в MergeTree нужна сортировка, когда вы вставляете данные, их нужно отсортировать по первичному ключу и затем записать на диск. После улучшения фреймворка для сортировки, вставка в MergeTree работает в 2-3 раза быстрее.
Фреймворк для сортировки используется и для выполнения ORDER BY. Улучшив общий фреймворк для сортировки, мы ускорили и обычную сортировку данных, от 2 до 10 раз:

За счет использования общего низкоуровневого компонента во множестве мест, в дальнейшем при оптимизации этого компонента, все места, которые используют его, будут работать быстрее.
Libraries
Если кто-то говорит, что в интернете есть самая быстрая библиотека или алгоритм, то мы пробуем использовать ее в ClickHouse.

Во внешних зависимостях есть:
Разные алгоритмы для парсинга (jsons, floats).
Разные интеграции (Azure, S3).
Встроенные хранилища (RocksDB).
LLVM для JIT-компиляции.
Стандартная библиотека С++, чтобы build был герметичный.
Почти во всех библиотеках CI/CD система ClickHouse находит баги. Мы их чиним, сообщаем об этом мейнтейнерам, и стараемся всё это смержить в upstream. Также в ClickHouse есть множество своих форков внешних библиотек, в случае большого количества наших изменений в библиотеке. Все они постоянно поддерживаются, например это POCO и LLVM libunwind.
Вообще в ClickHouse мы не боимся добавлять лишнюю внешнюю зависимость, потому что уверены, что CI/CD система сделает свою работу и найдет баги там, где они есть.
Low Level techniques
Если всё рассказанное выше уже сделано у вас в системе, но этого не хватает и нужно ускорить не ускоряемое, подойдут другие подходы.
JIT-компиляция
JIT-компиляция позволяет трансформировать динамическую конфигурацию в статическую. Не все функции и алгоритмы легко скомпилировать, но если это сделать иногда можно получить очень серьезное улучшение производительности.
JIT-компиляция — это не серебряная пуля, у неё есть своя стоимость. Увеличивается потребление памяти, за счет того что нужно хранить скомпилированный код. За счет времени компиляции может ухудшится латентность в разогревающих запросах. К тому же нужен человек, который разбирается в JIT-компиляции для поддержки инфраструктуры.

В моем блоге можно поподробнее почитать про это или посмотреть мое выступление на Highload++ Foundation 2022.
В ClickHouse есть специальные случаи GROUP BY при которых все три агрегатных функции sum(a), avg(b), count(c) будут скомпилированы в одну функцию. Это делается для того чтобы уменьшить количество виртуальных вызовов. Например, в некоторых случаях может быть 1000 агрегатных функций sum по разным колонкам в одном запросе.
Когда происходит ORDER BY по трем колонкам, получаются лишние виртуальные вызовы, за счет того что приходится сравнивать сначала по первой колонке, затем по второй, затем по третьей. Чтобы этого избежать компаратор компилируется в одну функцию.
Во всех случаях мы превращаем динамическую конфигурацию в статическую.
Если взять, к примеру, выполнение выражений. Для выражения a + b * c + 5 строится дерево выражений. Оно состоит из колонок, функций и констант. Его обходят снизу вверх. При этом нужно где-то хранить промежуточные значения, происходят лишние виртуальные вызовы. Это динамическая конфигурация, хотелось бы всё это скомпилировать в одну мощную, красивую функцию.
Для выражения а + b * с + 5, вот так выглядит cкомпилированная функция псевдокодом на С++:

Есть одна функция, есть результирующая колонка, есть входные колонки, константа и цикл. Он векторизуется, и производительность будет очень серьёзная. Это ассемблер, который получается после того как эту функцию скомпилировать:

Здесь не нужно понимать, что написано, главное, что есть серьёзные инструкции и всё векторизовано. На изображении отмечено, что константа 5 тоже была заинлайнена в этот ассемблер, то есть можно прикинуть насколько быстро это будет работать.
Dynamic Dispatch
Вторая техника как всё ускорить называется Dynamic Dispatch. Подробнее я рассказывал о ней в своем блоге.

ClickHouse распространяется как универсальный бинарный файл. Он по умолчанию поддерживает старый instruction set SSE4.2. Но, как известно, есть новые instruction sets. Например, AVX, AVX2, AVX512.
ClickHouse делает различные оптимизации, для AVX2 или AVX512, что-то нам приносят сторонние компании, например, Content Square и Intel. Хочется использовать эти оптимизации, но не жертвовать переносимостью. В таком случае можно использовать технику Dynamic Dispatch.
Весь код будет скомпилирован с SSE4.2, но конкретные выборочные функции, ClickHouse компилирует с другими instruction sets. На этапе выполнения, используя инструкцию CPUID у процессора, мы смотрим поддерживает ли процессор AVX, AVX2, AVX512. Если да, ClickHouse использует эти специализации функций. Сейчас компиляторы могут векторизировать даже довольно сложные циклы, и этим нужно пользоваться.
Например, для Clang чтобы скомпилировать функции с использованием других instruction sets нужно использовать специальную прагму attribute push. Мы можем завернуть эту специальную прагму в свои макросы:

Затем мы можем используя эти макросы сделать дополнительные обертки, и помечать части кода которые мы хотим скомпилировать используя AVX2 или например AVX512. Вот так может выглядеть пример использования нашего фреймворка:

Определяется код с дефолтным instruction set, с AVX2, с AVX512. Затем используется dispatch функция. Там есть if isArchSupported, где мы проверяем поддерживается ли AVX2. Если да, вызывается функция с AVX2.
Это все работает только для standalone функций, но довольно часто встречается ситуация когда есть какой-то класс, вы знаете, что упираетесь в функцию в этом классе, но выносить ее как standalone функцию совершенно не хочется. Для этого можно с использованием макросов помечать атрибутом конкретную функцию, а не секцию с кодом.

Мы хотим вставить определенный атрибут перед именем функции. Нам также нужно сгенерировать функции с разными именами. В идеале с суффиксами типа SSE42, AVX2, AVX512.

Решение такое, мы разделяем функцию на заголовок (MULTITARGET_FUNCTION_HEADER), имя и тело (MULTITARGET_FUNCTION_BODY), чтобы вставить определенный атрибут перед именем функции и поменять ее имя.

Выглядит этот макрос не очень красиво, но работает эффективно. Функция разбивается на заголовок, с темплейтами и типом возвращаемого значения. Дополнительно функция разбивается на имя и тело. Перед именем функции вставляется атрибут, а после имени добавляется суффикс.
В итоге получается готовая инфраструктура. Теперь остаётся найти места куда поставить этот макрос так, чтобы всё работало быстро. Чтобы находить такие места, собираем код с AVX, AVX2, AVX512 и запускаем тесты производительности. Затем смотрим какие же функции ускорились. Если функция ускорилась, наверняка там где-то есть цикл. Находим и заворачиваем его в макросы.
Вот несколько примеров как это работает.

Для агрегатных функций, таких как sum, average есть дополнительная специализация когда ключей в GROUP BY нет, то есть просто считаем значение агрегатной функции для всех значений поля из таблицы. Видно, что тут есть цикл. Теперь это нужно всё завернуть в макрос:

Дополнительно делается dispatch функция. Вот так она выглядит:

Видно как работает dynamic dispatch инфраструктура в ClickHouse. Выбираем какие специализации использовать, оборачиваем функцию в макрос, и делаем dispatch функцию.
В результате всё ускорилось довольно серьёзно:

Для sum и average почти все функции ускорились в 1,5-2 раза. Некоторые дополнительные функции ускорились ещё больше:

Такую же оптимизацию мы применили в унарных функциях. Цикл в реализации унарных функций выглядит так:

Есть входной массив функции и выходной массив, куда хотим записать результат этой унарной функции. Выходной массив уже имеет нужный размер. Идём циклом по первому массиву и применяем Op::apply — это такой темплейтный метод, который реализует функционал конкретного унарного оператора.
Заворачиваем всю эту функцию в макросы. В данном примере всё выглядит намного чище:

В результате мы получили значительное ускорение:

Мы используем данную инфраструктуру во множестве мест в ClickHouse.

Для АVX2 мы используем такие оптимизации почти везде, где это возможно.
С АVX512 всё немного сложнее — у некоторых инструкций есть сайд эффекты, за счёт которых частота CPU может понижаться. Это может влиять как на ClickHouse, так и на какое-нибудь соседнее приложение, которое с ним работает.
Для последних Intel-процессоров, таких как Rocket Lake и Ice Lake эту проблему уже починили. Можно в процессе выполнения проверить какой модели ваш процессор. Если модель подходит, то использовать АVX512 оптимизации.
Заключение
В заключение можно сказать следующее:

Внутри всей производительности в ClickHouse лежит CI/CD пайплайн. Это не случайно. Когда люди оптимизируют какие-то вещи, там почти всегда появляются баги, edge-кейсы. Всё это нужно уметь аккуратно тестировать. Тесты производительности — это ядро CI/CD инфраструктуры.
Без глубокой интроспекции в системе тяжело оптимизировать производительность. В хорошем случае, когда всё всегда работает, она не нужна. Но когда что-то работает плохо, нужно понимать что происходит внутри системы. Даже если вы улучшили производительность, нужно посмотреть реально ли поменялись метрики.
Для высокопроизводительных систем интерфейсы должны определяться алгоритмами. После того как вы выбрали основные алгоритмы и интерфейсы, можно переходить к обработке специальных случаев, например, Nullable, LowCardinality. И затем после всего этого пора начинать улучшать производительность на низком уровне, менять data layout, добавлять JIT-компиляцию и Dynamic Dispatch.