

Привет, Хабр! С вами Андрей Чернов — Java-архитектор микросервисов в СберТехе.
Это третья часть материала про то, как мы развиваем Platform V SessionsData — высокопроизводительное распределённое in-memory хранилище для общего контекста сессионных запросов key-value. В первой части я рассказал, почему мы решили создать собственный микросервис, а во второй — как нам удаётся достигать высокой доступности сервиса. Сегодня поговорим о том, какие наработки помогут нам и дальше развивать Platform V SessionsData.
Platform V DataGrid вместо СУБД
Начну с отказа от базы данных и персистентного хранения в целом. Но вначале расскажу, почему мы вообще решили отказаться от базы данных.
Во-первых, у нас в ней хранятся только записи об активных сессиях для нашей админки, самих данных там нет. А значит, они не критичны для нашего сервиса. При отказе от базы мы всего лишь не увидим активных сессий в админке. Именно поэтому мы ранее уже заменили синхронные обращения к базе данных на асинхронные, о чём я писал во второй части.
Во-вторых, сессии живут недолго: в среднем 5 минут. Поэтому персистентность при хранении таких данных не нужна.
В-третьих, записи в базе данных у нас компактные и помещаются в памяти сервера.
Поэтому мы планируем заменить базу на Platform V DataGrid — решение для распределённого хранения данных, основанное на Apache Ignite и доработанное до enterprise-уровня в области безопасности и отказоустойчивости.
Вместо выделенного кластера Ignite мы создадим свой. Используя несколько jar-файлов от Platform V DataGrid, сделаем служебный сервис — servant, — каждый узел которого станет нодой Ignite. Такие узлы сами образуют кластер Ignite в Kubernetes. Пока планируем использовать стандартную топологию «кольцо» и REPLICATED-режим кеша, чтобы на каждой ноде кластера была полная копия данных.

Мастер будет обращаться к servant по выставленному REST API через Ingress Gateway c Round robin-балансировкой. Это необходимо для гибкости: у мастеров не будет соединения c базой, а servant при одних настройках может быть Ignite, а при других — использовать базу данных, как раньше.
Избавившись от СУБД, мы окончательно защитимся от её отказов, архитектурной избыточности, и к тому же сможем сэкономить. А дальше расскажу про доработку, которая поможет ещё больше усилить безопасность нашего сервиса для потребителей.
Авторизация доступа к данным
Крупные компании работают с большим количеством микросервисов. И каждому из них нужно защищать свои контракты при работе с данными в Platform V SessionsData: другие сервисы, которые знают имя секции данных, могут прочитать её или изменить. Приведём абстрактный пример: у микросервисов «Билеты» и «Маршруты» могут быть общие секции данных, и им не хотелось бы, чтобы к этим данным был доступ у кого-то ещё.
Чтобы защитить доступ к данным, мы возьмём объединённый сервис авторизации, основанный на Open Policy Agent и являющийся частью продукта Platform V IAM, где он доработан до уровня enterprise в области безопасности и отказоустойчивости. При этом субъектами прав доступа будут не конечные пользователи, а микросервисы, работающие у него «под капотом». Как это будет работать: каждый микросервис при развёртывании импортирует в сервис авторизации политики доступа к своим секциям.
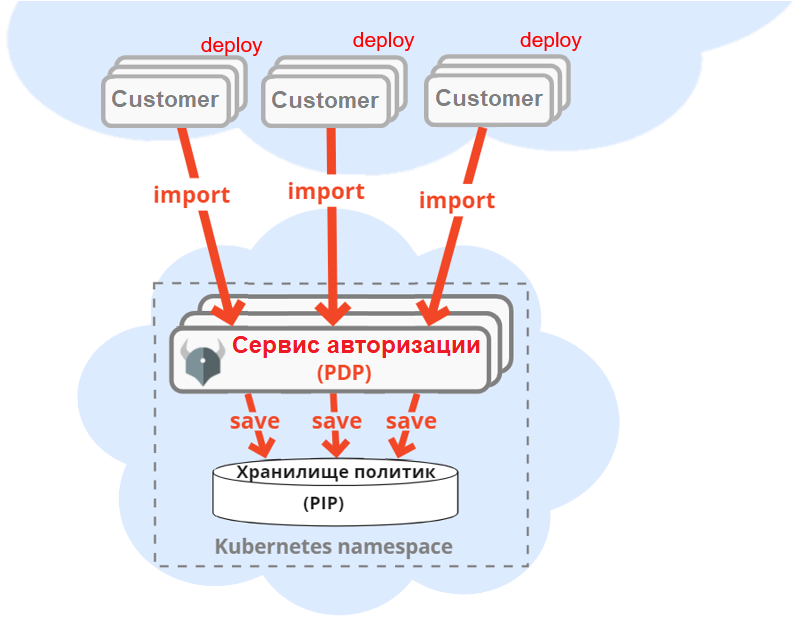
Наш мастер-сервис при обращении к секциям идёт в сервис авторизации по REST API и получает ответ, разрешено обращение или нет. Сервис авторизации проверяет доступ по всем импортированным в него политикам.

Политики конкретно для этого инструмента авторизации пишутся на декларативном языке Rego. Но в Platform V используется универсальная политика, написанная на Rego, которая просто интерпретирует файлы JSON ACL Policy с политиками. Выглядят они примерно так:

Здесь у микросервиса tickets (билеты) есть право на чтение и запись секции pricesPerKilometer (цены за километр).
Что станет со временем задержки мастер-сервиса, если он на каждый запрос клиента будет обращаться к сервису авторизации? Мастер будет кешировать ответы сервиса авторизации. Они статичны и могут поменяться только при переразвёртывании сервисов. Комбинаторное количество возможных ответов тоже невелико, и легко поместится в памяти мастера.

Идеальный вариант — вообще никогда не инвалидировать этот кеш. Лучше периодически актуализировать его асинхронными обращениями к сервису авторизации. Так длительность задержки наших мастеров практически не увеличится после прогрева кеша. И в итоге благодаря авторизации наш сервис станет ещё безопаснее для потребителей.
«Неклиентские» сессии
Одна из наших задач — облегчить работу нагруженным персистентным хранилищам. Для этого мы придумали специальные сессии, не привязанные к конкретным конечным пользователям. Любой микросервис при создании такой сессии может задать любую длительность жизни данных. Такие долгоживущие сессии могут называться «неклиентские», «служебные» или «технические» — всё это про них.
Приведу интересный пример. Допустим, при создании клиентских сессий в них загружаются редко изменяемые справочники. Это позволяет в каждой сессии обращаться к персистентным хранилищам только раз. Но решение можно оптимизировать, если в одну «неклиентскую» сессию загрузить все справочники из хранилищ и периодически актуализировать их асинхронным worker-ом. Тогда при создании каждой клиентской сессии достаточно будет просто переложить нужные справочники из «неклиентской», то есть из оперативной памяти в оперативную, не обращаясь к диску.

Например, если в сервисе очень часто создаются клиентские сессии, тем самым каждую минуту выполняется 100500 обращений к персистентным хранилищам справочников. А с использованием «неклиентской» сессии это всего одно обращение в минуту от асинхронного worker-а актуализатора. Нагруженные персистентные хранилища скажут за такое «спасибо».
Автоматическое внедрение sidecar в сервис потребителя
И напоследок расскажу про наши планы внедрения slave sidecar оператором Kubernetes. Как я писал во второй части в разделе «Хранилище не в контейнере», slave sidecar у нас теперь находится в контейнере внутри подов потребителей, которых может быть очень много. Они подключают наш sidecar в поды по инструкции:
• вставить в Deployment описание контейнера slave sidecar:

• вставить в Deployment описание томов для нашего sidecar:

• добавить в свой дистрибутив конфигурационный файл с параметрами запуска sidecar (превращается в ConfigMap при развёртывании):

• добавить в свой дистрибутив ConfigMap с параметрами runtime-поведения sidecar-а:

Заниматься этим вручную рутинно, и можно наделать ошибок. Особенно учитывая, что копируемые куски YAML могут поменяться при изменении версии slave sidecar.
При этом мы хотим дать опциональную возможность низконагруженным потребителям работать без нашего кеширующего slave sidecar. В таком случае наш клиентский jar в приложении потребителя будет сразу обращаться к мастер-хранилищу.
Поэтому мы планируем сделать оператор Kubernetes, который будет внедрять наш sidecar в Deployment потребителей. Это упростит им работу и позволит удобно подключать и отключать наш sidecar. Пользователю нужно будет только добавить в Deployment аннотации для нашего оператора. Включаем sidecar флагом и задаём его параметры:

Или просто выключаем sidecar. В этом случае потребитель поменяет у себя в настройках localhost-овый URL для связи со slave на URL мастера:

Оператор будет следить за появлением каждого нового Deployment в namespace потребителя и внедрять туда slave sidecar, если это указано в аннотациях.

Такое решение позволит потребителям легко подключать и отключать наш sidecar, не выполняя рутинной работы.
Подводим итоги
В этой и предыдущих статьях я рассказал о том, как мы развиваем собственный продукт Platform V SessionsData, который помогает микросервисам Сбера хранить данные сессий клиентов. При этом Platform V SessionsData отлично справится с аналогичными задачами и в приложениях вне Сбера.
Надеюсь, что мой рассказ был вам полезен. Спасибо за ваше внимание, и до встречи!