
Benjamin Treynor Sloss (один из авторов SRE) «SRE это то что происходит, когда вы просите разработчиков вытроить команду эксплуатации».
Вместо какого-то четкого определения SRE, давайте сначала разберем, что относится к основным принципам SRE:
Для эксплуатации используется принципы из мира разработки
Использование Service Level Objectives (SLO)
Автоматизация всего что можно автоматизировать
Ускорение внесения изменений за счет снижения цены ошибок (mean time to repair (MTTR))
Тесная работа с разработчиками
Команды SRE сами определяют свои задачи и распределяют нагрузку
Service Level Indicators
Service level indicators (SLIs) это фундаментальная концепция, которая лежит в основе других концепций SLI.
Для того, чтобы определять свои собственные SLI необходимо ответить на вопрос:
Какие аспекты отказоустойчивости сервиса релевантны для клиентов?
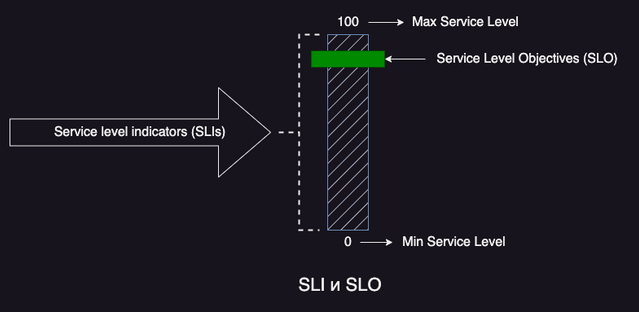
SLI – это то что необходимо измерять, например доступность и задержки. SLO это пороговое значение, которое сервис не должен превышать. SLO находится между минимальным сервисным уровнем 0 и максимальным сервисным уровнем 100.
SLO и SLI определяются с точки зрения потребителей сервиса. SLO в опосредованном виде показывает удовлетворенность потребителя услугой/сервисом.
Для одного SLI может быть определено несколько SLO.
Service Level Objectives
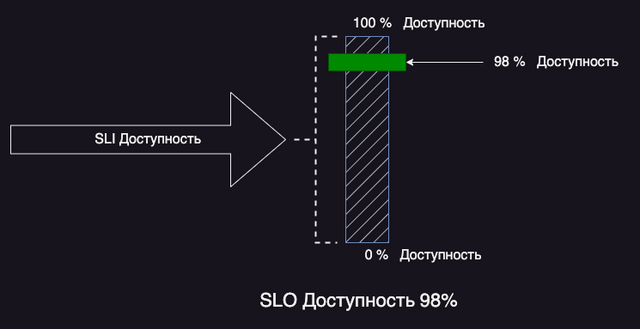
Ниже приведен пример SLO Доступность 98%. Как показано в диаграмме ниже SLI – это индикатор доступности, а SLO – это пороговое значение (98%) определенное для данного сервиса. Сервис согласно SLO должен быть доступен для потребителей 98% времени.
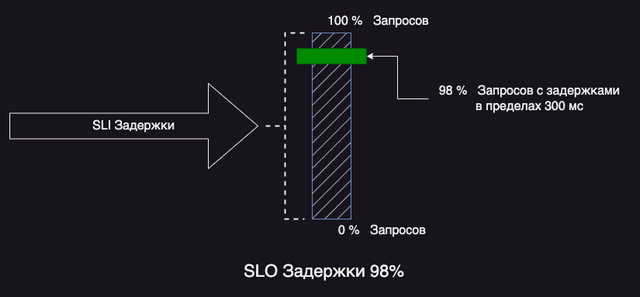
В следующем примере SLI – это задержки. SLO для данного сервиса это 98% запросов к API должны возвращать ответ в пределах 300 миллисекунд.
SRE предполагает подробное документирование всех процессов. При определении SLO одной из рекомендаций является составление документа описывающее общее видение и цели которые преследуют SLO, а так же перечисление всех участвующих в разработке SLO сторон.
Пример документа с определением SLO:
Определение SLO: Название сервиса
Витрина SLO: Ссылка
Автор документа: <>
Команда: <>
Участники: Кто то еще вносил лепту в этот документ?
Дата рассмотрения: <Дата>
Дата последнего обновления: <Дата>
Дата согласования: <Дата>
Error budget
Бюджеты на ошибки автоматически рассчитываются на основе SLO. Бюджет на ошибки – это максимальная надежность сервиса (100%) минус пороговое значение SLO.
2% бюджет на ошибки в данном примере назначается на три рабочие недели. Это значит, что сервис может быть недоступен максимум 2% от всех запросов за три недели.
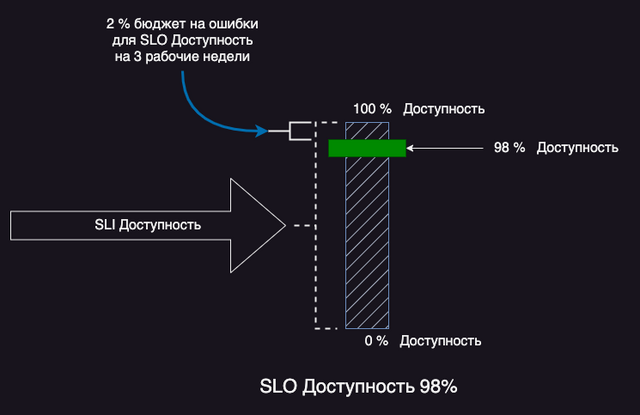
Еще один пример бюджета на ошибки для SLO Задержки 95%:
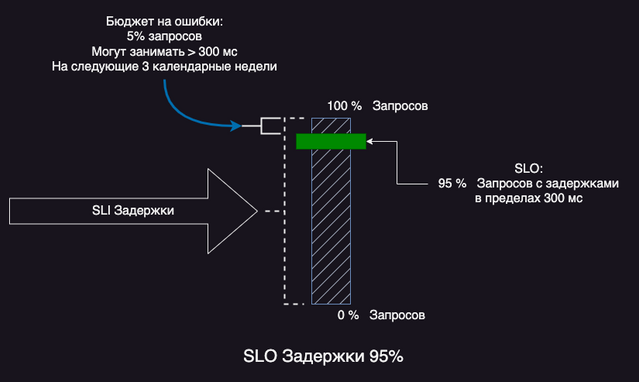
После то окончания срока SLO (это может быть несколько рабочих недель и месяцев) бюджет на ошибки обнуляется.
Error Budget Policy
Error Budget Policy отвечает на вопрос какие технические и организационные действия должны быть предприняты в случае нарушения SLO?
Пример документа с определением Error Budget Policy:
Error budget |
Пороговое значение |
Действия |
|---|---|---|
SLO |
X |
Действие |
SLO |
X |
Действие |
SLO |
X |
Действие |
SLO |
X |
Действие |
SLO |
X |
Действие |
SLO |
X |
Действие |
SLO |
X |
Действие |
Postmortem
В русском языке «postmortem» буквально переводится как «Посмертная записка». Однако, этот термин имеет определенную коннотацию, поэтому вместо него можно использовать «Служебная записка» и «Постмортем».
Постмортем (postmortem) – это описание инцидента, которое содержит информацию о последствиях вызванных инцидентом, шаги которые были предприняты для смягчения последствий, корневая причина и последующие действия. Цель постмортема – это понимание корневых причин приведших к инциденту и разбор превентивных действий, которые можно предпринять, для предотвращения подобных инцидентов в будущем.
Постмортем пишется в свободной форме. Единственным требованием к этому документу является своевременность – 24-72 часа рекомендованное время для написания отчета с разбором корневой причины инцидента.
DevOps и DevSecOps
Методы SRE и DevOps тесно связаны друг с другом. В некоторых источника можно встретить утверждение, что SRE является имплементации философии DevOps.
DevOps это модель связывающая людей, процессы и технологии для доставки ценности до конечного потребителя. DevOps должен соединять разработку (Dev) и эксплуатацию (Ops) и оптимизировать жизненный цикл программного обеспечения (SDLC).
Принципы DevOps:
Уменьшение барьеров между командами и отделами
Имплементация постепенных изменений
Разработка и внедрение новых инструментов/автоматизации
Измерение и внедрение метрик там где это возможно
Автоматизация в DevOps прежде всего связана с непрерывной доставкой (Continuous Delivery): сборка кода, развертывание инфраструктуры, тестирование и мониторинг.
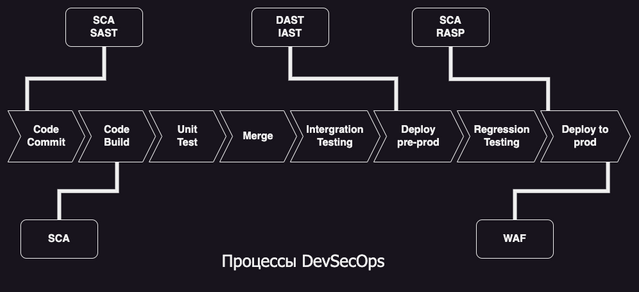
Пример современного конвейера CI/CD использующего принципы DevOps и DevSecOps:
В чем разница между DevOps и SRE?
SRE и DevOps должны дополнять друг друга. Команды, которые внедряют техники SRE, обычно улучшают свои операционные показатели. В масштабах организации, команды, которые приоретизируют доставку кода и операционную надежность, обычно находятся в лидерах по эффективности и производительности.
SLI, SLO, бюджеты на ошибки и постмортемы – это основополагающие концепции в SRE. Без этих индикаторов нельзя говорить о том, что организация внедрила SRE.