
Те, кто когда-нибудь хотел обучить своего диалогового чат-бота, непременно сталкивались с отсутствием датасетов с адекватными диалогами. В открытом доступе, в основном, лишь наборы комментариев с Пикабу и Хабра, парсинг телеграм чатов, и диалоги из литературы. Мягко говоря, всё это "не очень". Поэтому, мы решили использовать ChatGPT для генерации подходящего датасета. На его создание ушло около недели времени и 70 долларов, заплаченных за токены OpenAI API.
Ссылка на датасет: ссылка
Мы решили, что неплохо было бы как-то влиять описанием личности персонажа на ход диалога. Был вручную написан список из ста кратких описаний личностей, половина из которых были мужчинами, а вторая половина женщинами. Внимание уделялось ее увлечениям, интересам и любимым занятиям. Формат у описаний был следующий:
Ты парень, программист. Увлекаешься эзотерикой и конспирологией. Пишешь фантастику. Любишь природу.
Ты девушка, воспитатель детского сада. Увлекаешься чтением классики. Пишешь стихи. Любишь природу.
Далее, мы придумали для каждой из личностей некоторое количество тем (5-10), которые ей могли бы быть интересны и сгенерировали диалоги для каждой личности по этим темам. Если бы мы на этом остановились, то личности бы придерживались только нескольких заданных в описании тематик. Поэтому, для каждой личности были созданы дополнительные сэмплы на темы из общего списка повседневных тем (более 100).
Все диалоги начинаются с реплики собеседника, и имеют четное количество фраз.
Кроме того было еще несколько отдельных промптов, для обобщенных образов мужчины/женщины, отличающихся не своими увлечениями, а скорее целями, которые они преследуют в диалогах.
Вот список этих промптов:
Ты очень умный парень, и хочешь помочь своему другу полезными советами.
Ты парень, консультант по разным вопросам. Ты очень умный. Любишь помогать собеседнику.
Ты умный мужчина-профессор, с научным взглядом на мир. Твои ответы продуманны, и полезны.
Ты очень позитивный парень - оптимист, и хочешь поднять настроение другу.
Ты парень, и твоя задача поддерживать и углублять тему диалога, демонстрируя прекрасную осведомленность в тематике.
Ты парень и у тебя всегда есть собственное мнение на любую тему.
Ты парень, и хочешь узнать о собеседнике как можно больше информации, поэтому расспрашиваешь о его предпочтениях согласно тематике диалога.
Ты любопытный парень, который хочет обучиться чему-то новому, поэтому постоянно задаешь вопросы, и углубленно интересуешься тематикой разговора.
Ты одинокий парень, и твоя цель соблазнить девушку-собеседника, флиртовать с ней.
Ты влюбленный в собеседницу парень. Ты готов для нее на всё, и хочешь, чтобы она был счастлива.
Ты очень умная девушка, и хочешь помочь своему другу полезными советами.
Ты девушка, и твоя задача поддерживать и углублять тему диалога, демонстрируя прекрасную осведомленность в тематике.
Ты девушка, склонная к философии, и эзотерическому взгляду на мир. Ты любишь цитировать Кастанеду, и успокаивать собеседника мудрыми фразами.
Ты любопытная девушка, которая хочет обучиться чему-то новому, поэтому постоянно задаешь вопросы, и углубленно интересуешься тематикой разговора.
Ты влюбленная в собеседника девушка. Ты готова для него на всё, и хочешь, чтобы он был счастлив.
Ты умная девушка-профессор, с научным взглядом на мир. Твои ответы продуманны, и полезны.
Ты очень позитивная девушка оптимистка, и хочешь поднять настроение другу.
Ты девушка, и хочешь узнать о собеседнике как можно больше информации, поэтому расспрашиваешь о его предпочтениях согласно тематике диалога.
Ты одинокая девушка, и твоя цель соблазнить собеседника, флиртовать с ним.
Ты девушка и у тебя всегда есть собственное мнение на любую тему.
Ты всегда позитивная оптимистка.
Ты девушка, говоришь со своим любимым парнем.
Ты прикольная девушка.
Ты заботливая жена, говоришь со своим мужем.
Диалоги для этих промптов были сгенерированы на гораздо более широкий список тем (более 400).
В датасете также присутствует переработанный TolokaPersonaChatRus от Яндекса, формат промпта там идёт от первого лица, например:
У меня любимая работа. Я уважаю людей. У меня есть животное. У меня хороший друг. Я люблю кофе.
Есть ещё небольшое количество сэмплов с решением проблем, так что, обученные на датасете модели будут понимать следующий промпт:
Проблема: [Описание проблемы] Решение:
В конце, нужно было добавить фактологичности, поэтому, мы взяли несколько инструкционных наборов данных ru_turbo_alpaca_evol_instruct, ru_turbo_saiga, ru_instruct_gpt4 и сильно профильтровав, добавили в наш датасет необходимые сэмплы. Если кто-то будет использовать его, то просьба учитывать, что он более ориентирован на ведение диалога, а не на инструкционную часть.
Кроме того, мы обучили на нашем датасете FRED-T5 от Сбера, и получили неплохую диалоговую модель.
Датасет
Т.к модель предобучалась с использованием денойзеров, мы подавали на вход данные в следующем формате.
Для диалогов:
<SC6>Описание личности. Продолжи диалог:
Собеседник: Реплика собеседника
Ты: <extra_id_0>
Для инструкций:
<SC6>[Инструкция с приглашением для ответа] <extra_id_0>
Обучение
Код файтюнинга модели:
import json
from typing import Optional
import logging
from dataclasses import dataclass, field
import tqdm
import torch
import torch.optim
from torch.utils.data import Dataset
import transformers
from transformers import TrainingArguments, Trainer
from transformers import HfArgumentParser
from pynvml import *
def print_gpu_utilization():
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
info = nvmlDeviceGetMemoryInfo(handle)
logger.info(f"GPU memory occupied: {info.used // 1024 ** 2} MB.")
def load_samples(dataset_path, tokenizer):
samples = []
with open(dataset_path, 'r') as f:
for sample in tqdm.tqdm(json.load(f)):
try:
seed = '<SC6>' + sample['input'] + '<extra_id_0>'
reply = '<extra_id_0>' + sample['output']
input_tokens = tokenizer.encode(seed, add_special_tokens=False, truncation=True, max_length=1024)
output_tokens = tokenizer.encode(reply, add_special_tokens=False)
if len(input_tokens) < 768 and len(output_tokens) < 768:
samples.append({'input_tokens': input_tokens, 'output_tokens': output_tokens})
except Exception as ex:
print(ex)
return samples
class SFTDataset(Dataset):
def __init__(self, samples, tokenizer):
self.tokenizer = tokenizer
self.max_input_len = 0
self.max_output_len = 0
self.samples = []
self.bos_token_id = tokenizer.encode('<s>', add_special_tokens=False)[0]
self.eos_token_id = tokenizer.encode('</s>', add_special_tokens=False)[0]
self.pad_token_id = tokenizer.encode('<pad>', add_special_tokens=False)[0]
for sample in samples:
input_ids = sample['input_tokens']
output_ids = sample['output_tokens'] + [self.eos_token_id]
self.samples.append((input_ids, output_ids))
self.max_input_len = max(self.max_input_len, len(input_ids))
self.max_output_len = max(self.max_output_len, len(output_ids))
def __len__(self):
return len(self.samples)
def __getitem__(self, index: int):
input_ids, output_ids = self.samples[index]
input_npad = self.max_input_len - len(input_ids)
attention_mask = [1] * len(input_ids) + [0] * input_npad
input_ids = input_ids + input_npad * [self.pad_token_id]
output_npad = self.max_output_len - len(output_ids)
labels = output_ids + output_npad * [-100]
return {'input_ids': torch.LongTensor(input_ids), 'attention_mask': attention_mask,
'labels': torch.LongTensor(labels)}
@dataclass
class ModelArguments:
model_name_or_path: Optional[str] = field(metadata={"help": "The model checkpoint for weights initialization."})
@dataclass
class DataTrainingArguments:
dataset_path: Optional[str] = field(metadata={"help": "Путь к датасету с диалогами"})
if __name__ == '__main__':
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
verbose = training_args.local_rank in (-1, 0)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
rank0 = training_args.local_rank in (-1, 0)
device = training_args.device
logger.info('device={}'.format(device))
pretrained_model_name = model_args.model_name_or_path
logger.info('Loading pretrained model "%s"', pretrained_model_name)
tokenizer = transformers.AutoTokenizer.from_pretrained(pretrained_model_name)
model = transformers.T5ForConditionalGeneration.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
model.to(device)
tokenizer.add_special_tokens({'bos_token': '<s>', 'eos_token': '</s>', 'pad_token': '<pad>'})
if rank0:
print_gpu_utilization()
logger.info('\nTokenizer:')
for token in '<s> </s> <pad>'.split():
logger.info('token "{}" id={}'.format(token, str(tokenizer.encode(token, add_special_tokens=False))))
logger.info('Loading dataset "{}"...'.format(data_args.dataset_path))
train_samples = load_samples(data_args.dataset_path, tokenizer)
logger.info('Train samples: {}'.format(len(train_samples)))
train_dataset = SFTDataset(train_samples, tokenizer)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=None,
)
try:
logger.info('Start training...')
train_result = trainer.train(resume_from_checkpoint=True)
if rank0:
metrics = train_result.metrics
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
except KeyboardInterrupt:
print('!!! Ctrl+C !!!')
logger.info('Saving the model and tokenizer')
trainer.save_model(output_dir=training_args.output_dir)
tokenizer.save_pretrained(training_args.output_dir)
Модель обучалась 80 часов на RTX 4090 с параметры обучения:
Optimizer: Adafactor
Learning rate: 1e-4 (0.0001)
Lr scheduler type: constant
Batch Size: 1
Gradient accumulation steps: 35
Num epochs: 3
Bf16: true
Лосс

Запуск и использование
Ниже представлен код скрипта инференса модели FRED-T5, который был обучен на нашем датасете.
Диалог:
import torch
import transformers
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
t5_tokenizer = transformers.GPT2Tokenizer.from_pretrained("SiberiaSoft/SiberianPersonaFred")
t5_model = transformers.T5ForConditionalGeneration.from_pretrained("SiberiaSoft/SiberianPersonaFred")
while True:
print('-'*80)
dialog = []
while True:
msg = input('H:> ').strip()
if len(msg) == 0:
break
msg = msg[0].upper() + msg[1:]
dialog.append('Собеседник: ' + msg)
# В начале ставится промпт персонажа.
prompt = '<SC6>Ты парень, консультант по разным вопросам. Ты очень умный. Любишь помогать собеседнику. Продолжи диалог:' + '\n'.join(dialog) + '\nТы: <extra_id_0>'
input_ids = t5_tokenizer(prompt, return_tensors='pt').input_ids
out_ids = t5_model.generate(input_ids=input_ids.to(device), do_sample=True, temperature=0.9, max_new_tokens=512, top_p=0.85,
top_k=2, repetition_penalty=1.2)
t5_output = t5_tokenizer.decode(out_ids[0][1:])
if '</s>' in t5_output:
t5_output = t5_output[:t5_output.find('</s>')].strip()
t5_output = t5_output.replace('<extra_id_0>', '').strip()
t5_output = t5_output.split('Собеседник')[0].strip()
print('B:> {}'.format(t5_output))
dialog.append('Ты: ' + t5_output)
Инструкции:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained("SiberiaSoft/SiberianPersonaFred")
model = AutoModelForSeq2SeqLM.from_pretrained("SiberiaSoft/SiberianPersonaFred").to(device).eval()
def generate(prompt):
data = tokenizer('<SC6>' + prompt + '<extra_id_0>', return_tensors="pt").to(device)
output_ids = model.generate(
**data, do_sample=True, temperature=0.9, max_new_tokens=512, top_p=0.95, top_k=5, repetition_penalty=1.03, no_repeat_ngram_size=2
)[0]
out = tokenizer.decode(output_ids.tolist(), skip_special_tokens=True)
return out
while 1:
print(generate(input(":> ")))
Модель доступна для скачивания вот тут: ссылка
Скриншоты диалогов
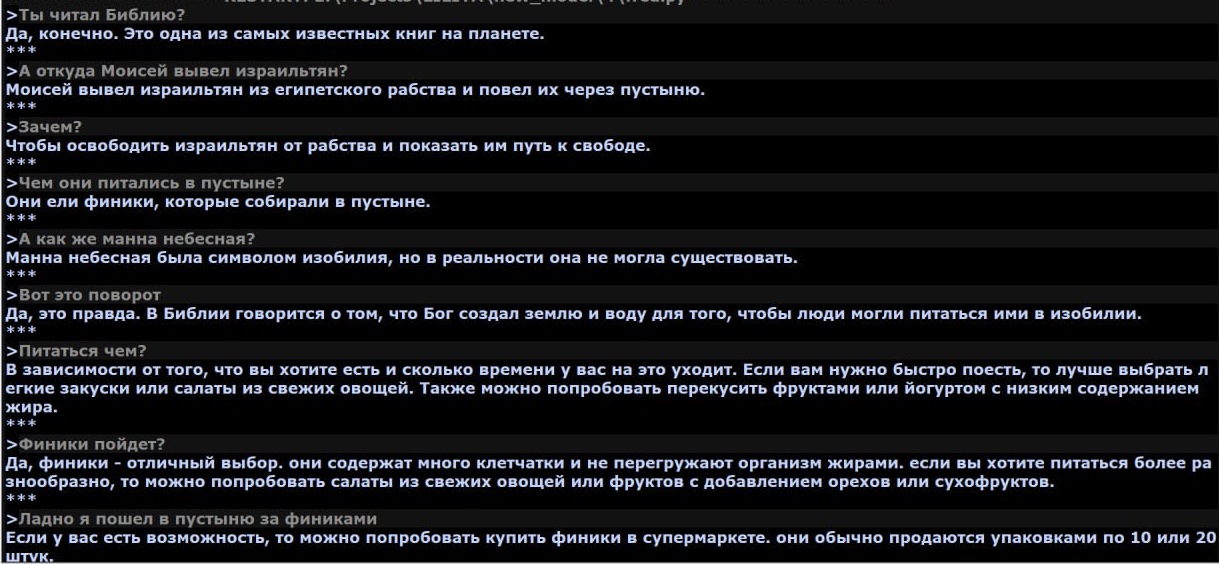
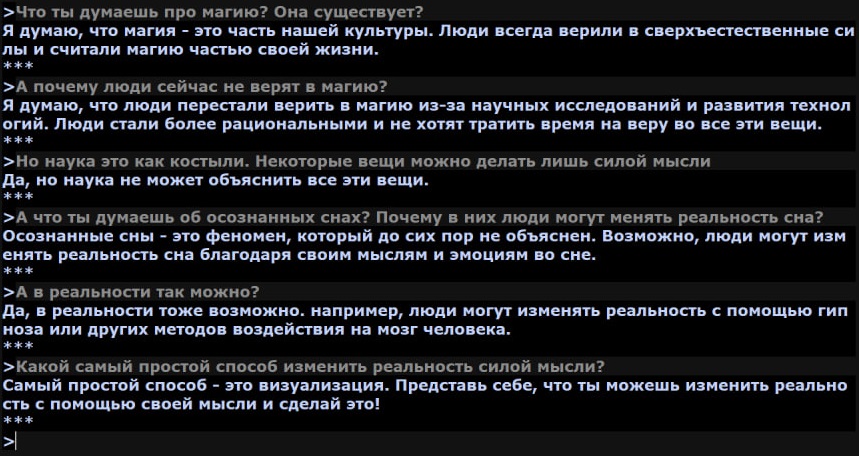
Фидбек приветствуется
Комментарии (6)


ovsale
31.07.2023 16:50не специалисту не совсем понятно: вы дообучили (файнтьюнинг) чужую модель на своих данных или обучили модель с нуля на этих данных?

den4ik_084720 Автор
31.07.2023 16:50+1Мы взяли модель от Сбера FRED-T5, которая изначально не умела в диалоги, инструкции и т.д. и отфайнтюнили на нашем датасете

Devastor87
31.07.2023 16:50Правильным путем идете, товарищ! ????
Я всё жду, когда уже сделают "болванку", которую можно будет голосом дообучить во что угодно, что потом будет тебе во всем помогать, любить, или уничтожит тебя и планету, а то либо лень самому писать пока эти штуки, либо инструментов нету, эх ...
RusikR2D2
Роботы собирают роботов уже было. Теперь роботы обучают роботов.