
У данной статьи есть две цели:
Протестировать производительность трёх систем объединения физических устройств в одно логическое, как для локального доступа к нему, так и для использования в качестве блочного массива для виртуализации.
Создание бэкэнда для кластера в виде одноконтроллерного хранилища.
Иными словами выводы данной статьи не применимы, когда Вам нужно:
Синхронное отказоустойчивое решение
Надежность >>> скорость
Долговременное решение, которое можно поставить и забыть
В связи со значительным удешевлением NVMe дисков на различных ресурсах (таких как авито) можно найти nvme диски дешевле их аналогов на SATA или SAS интерфейсе с таким же объёмом, но остаётся вопрос в их объединение в один логический диск.
К сожалению, текущие рейд контроллеры для NVMe дисков не отличаются особой дешевизной и\или количеством доступных разъёмов для их подключения, поэтому одним из вариантов является использование программного рейда.
Для тестирования выбраны программные рейды:
mdadm
lvm (и надстройка VDO)
ZFS
Про кажую из выбранных систем можно подробнее почитать:
Для тестирования локального массива были выбраны тесты описанные тут и тут.
Для тестирования блочного массива виртуализации будет использоваться HCIbench, а параметры взяты из следующей статьи.
Тестовый стенд
Сервер виртуализации:
Motherboard: Supermicro H11SSL-i
CPU: EPYC 7302
RAM: 4x64GB Micron 2933MHz
Сеть: 40GbE ConnectX-3 Pro, 10GbE/25GbE ConnectX-4 LN EN
ОС: ESXi 7U3 build 20036586
Сервер хранения (в дальнейшем гибридный сервер с PCIe Passthrough для тестов блочного хранилища):
Motherboard: Tyan S8030 (ver 1GbE)
CPU: EPYC 7302
RAM: 4x64GB Micron 2933MHz
Сеть: 40GbE ConnectX-3 Pro x2
Диски 1: 6 x PM9A3 1.92TB, форматированы в 512n
Диски 2: 1 x PM1725 3.2ТБ (не участвует в конфигурации рейда, но используется для сравнения)
Софт для тестов на физике:
Debian 12, ядро 6.1.0-10
FIO: 3.33-3
Софт для тестов поверх виртуализиации (to-be)
ОС: ESXi 7U3 build
ВМ: Ubuntu 22.04.03, ядро 6.2
FIO: 3.28-1
Список тестов FIO приведён ниже:
fio -name=seq_mbs_write_T1Q1N1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4M -iodepth=32 -rw=write -runtime=60 -filename=/dev/nvme1n1 && sleep 10 && fio -name=seq_mbs_read_T1Q1N1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4M -iodepth=32 -rw=read -runtime=60 -filename=/dev/nvme1n1 && sleep 10 && fio -name=rand_iops_write_T1Q128N1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=128 -numjobs=4 -group_reporting -rw=randwrite -runtime=60 -randrepeat=0 -filename=/dev/nvme1n1 && sleep 10 && fio -name=rand_iops_read_T1Q128N1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=128 -numjobs=4 -group_reporting -rw=randread -runtime=60 -randrepeat=0 -filename=/dev/nvme1n1 && sleep 10 && fio -name=rand_iops_read_T1Q1N1 -randrepeat=0 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=1 -rw=randread -runtime=60 -filename=/dev/nvme1n1 && sleep 10 && fio -name=rand_iops_write_T1Q1N1 -randrepeat=0 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=1 -fsync=1 -rw=randwrite -runtime=60 -filename=/dev/nvme1n1
Рассматриваться будет 2 сценария:
Raid 0 - (все же делают бэкапы) как крайний сценарий производительного решения, когда за сохранность данных (не доступность) отвечает или репликация или бэкапы.
Raid 5 - как хорошая схема для 6 дисков
В качестве блочного доступа будет использоваться iSER и NVMe-oF
Ниже приведена сводная таблица по дискам и график производительности:
Сводная таблица по дискам в системе
|
(MB/s) NVMe# |
NVMe0 (PM1725) |
NVMe1 (PM9A3) |
NVMe2 (PM9A3) |
Последовательная запись 4M qd=32 |
1 473.50 |
2 810.50 |
2 809.00 |
Последовательное чтение 4M qd=32 |
5 068.50 |
5 882.50 |
5 891.50 |
Случайная запись 4k qd=128 jobs=16 |
327.00 |
2 792.00 |
2 787.50 |
Случайное чтение 4k qd=128 jobs=16 |
3 957.00 |
4 620.00 |
4 619.00 |
Случайная запись 4k qd=1 fsync=1 |
163.50 |
233.00 |
233.50 |
Случайное чтение 4k qd=1 fsync=1 |
44.80 |
90.30 |
90.40 |
(MB/s) NVMe# |
NVMe3 (PM9A3) |
NVMe4 (PM9A3) |
NVMe5 (PM9A3) |
NVMe6 (PM9A3) |
Последовательная запись 4M qd=32 |
2 807.50 |
2 811.00 |
2 809.50 |
2 810.50 |
Последовательное чтение 4M qd=32 |
5 884.00 |
5 915.00 |
5 904.50 |
5 885.50 |
Случайная запись 4k qd=128 jobs=16 |
2 793.00 |
2 789.00 |
2 779.00 |
2 796.50 |
Случайное чтение 4k qd=128 jobs=16 |
4 615.00 |
4 537.50 |
4 526.50 |
4 619.50 |
Случайная запись 4k qd=1 fsync=1 |
231.50 |
230.00 |
231.00 |
232.00 |
Случайное чтение 4k qd=1 fsync=1 |
90.65 |
90.15 |
90.35 |
90.70 |

Ссылка на excel файл со всеми данными.
MDADM
Создание mdadm достаточно типично:
mdadm --create --verbose /dev/md0 --level=0 --raid-devices=6 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1
Для 5-ого рейда (Перед началом тестов было выждано 3 часа, пока создавался рейд)
mdadm --create --verbose /dev/md5 --level=5 --raid-devices=6 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1
RAID 0 |
mdadm-local-raid0 |
|
Последовательная запись 4M qd=32 |
11 980.80 MB/s |
- |
Последовательное чтение 4M qd=32 |
20 275.20 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
11 827.20 MB/s |
2 817 002.93 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
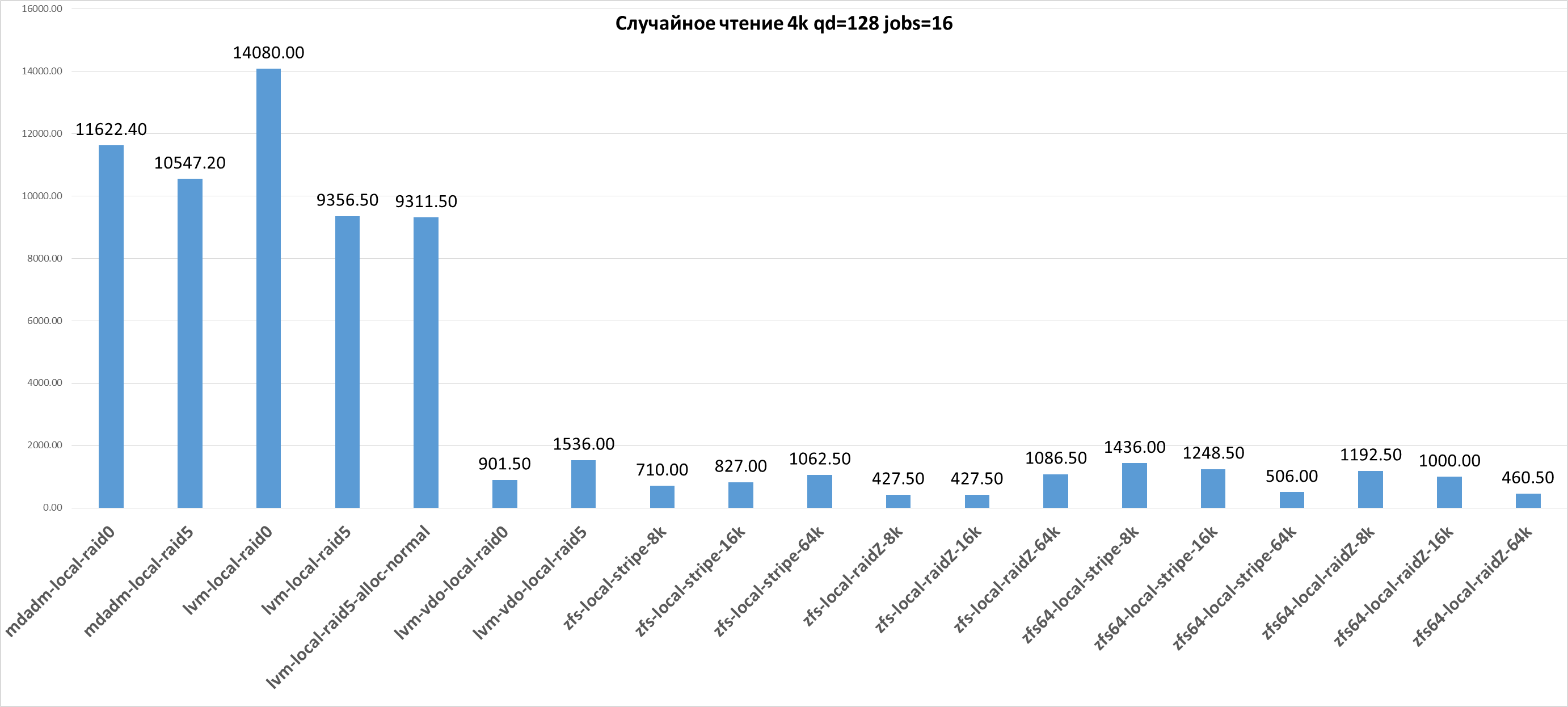
11 622.40 MB/s |
2 771 891.56 IOPS |
Случайная запись 4k qd=1 fsync=1 |
172.50 MB/s |
42 160.66 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
99.50 MB/s |
24 269.23 IOPS |
RAID 5 |
mdadm-local-raid5 |
|
Последовательная запись 4M qd=32 |
1 524.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
20 127.90 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
246.50 MB/s |
60 308.72 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
10 547.20 MB/s |
2 514 141.78 IOPS |
Случайная запись 4k qd=1 fsync=1 |
30.95 MB/s |
7 564.39 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
62.00 MB/s |
15 161.99 IOPS |
LVM
LVM - для создание используются параметры
lvcreate -i6 -I64 --type striped -l 100%VG -n lvm_stripe stripe
lvcreate -i5 -I64 --type raid5 -l 100%VG -n lvm_raid5 raid
RAID0 |
lvm-local-raid0 |
|
Последовательная запись 4M qd=32 |
10 905.60 MB/s |
- |
Последовательное чтение 4M qd=32 |
20 480.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
14 080.00 MB/s |
3 359 597.24 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
14 080.00 MB/s |
3 358 893.54 IOPS |
Случайная запись 4k qd=1 fsync=1 |
221.00 MB/s |
53 959.59 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
81.05 MB/s |
19 793.28 IOPS |
RAID5 |
lvm-local-raid5 alloc default |
|
Последовательная запись 4M qd=32 |
1 158.50 MB/s |
|
Последовательное чтение 4M qd=32 |
11 980.80 MB/s |
|
Случайная запись 4k qd=128 jobs=16 |
224.00 MB/s |
54 612.865 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
9 356.50 MB/s |
2 285 440.25 IOPS |
Случайная запись 4k qd=1 fsync=1 |
17.60 MB/s |
4 294.32 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
54.05 MB/s |
13 206.84 IOPS |
RAID5 |
lvm-local-raid5-alloc-normal |
|
Последовательная запись 4M qd=32 |
1 176.50 MB/s |
- |
Последовательное чтение 4M qd=32 |
11 468.80 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
227.00 MB/s |
55 452.76 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
9 311.50 MB/s |
2 274 871.33 IOPS |
Случайная запись 4k qd=1 fsync=1 |
23.00 MB/s |
5 599.71 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
56.85 MB/s |
13 879.59 IOPS |
LVM+VDO
Так как на Debian vdo просто нет, даже в виде пакета он добавлялся как модуль к ядру с использованием этого руководиства), тесты проводились с включённым дедупом, так как это параметр по умолчанию.
При создании использовались следующие параметры, так как по умолчанию VDO не поддерживает raid конфигурацию, поэтому пул создавался через lvconvert.
lvcreate -i6 -I64 --type striped -l 100%VG -n stripe-vdo lvm
lvconvert --type vdo-pool --virtualsize 8TB /dev/lvm/stripe-vdoRAID0 |
lvm-vdo-local-raid0 |
|
Последовательная запись 4M qd=32 |
735.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
2 279.50 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
415.50 MB/s |
101 344.40 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
901.50 MB/s |
220 089.32 IOPS |
Случайная запись 4k qd=1 fsync=1 |
6.14 MB/s |
1 534.41 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
39.00 MB/s |
9 520.67 IOPS |
lvcreate -i6 -I64 --type raid5 -l 100%VG -n lvm_raid5 raid5
lvconvert --type vdo-pool --virtualsize 8TB /dev/lvm/raid5-vdoRAID5 |
lvm-vdo-local-raid5 |
|
Последовательная запись 4M qd=32 |
230.50 MB/s |
- |
Последовательное чтение 4M qd=32 |
2 406.50 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
79.50 MB/s |
19 388.92 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
1 536.00 MB/s |
374 751.79 IOPS |
Случайная запись 4k qd=1 fsync=1 |
1.59 MB/s |
398.57 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
34.25 MB/s |
8 329.27 IOPS |
ZFS
После каждой группы тестов сервер перезапускался, т.е., к примеру, после тестов stripe 16k и перед тестами на 8k, чтобы однозначно очистить ARC.
Когда выйдет ZFS 3.0 с патчем O_DIRECT для nvme, я расширю её, сейчас же ZFS выглядит следующим образом:
v1 - блок 16k (новые дефолтные параметры), компрессия lz4 (не оказывает влияния на IOPS, по множественным заявлениям и по результатом тестов), дедуп выключен:
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O recordsize=16k nvme /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1
zfs create -s -V 10T -o volblocksize=16k -o compression=lz4 nvme/iserStripe |
zfs-local-stripe-16k |
|
Последовательная запись 4M qd=32 |
2 826.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
5 955.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
176.50 MB/s |
43 120.67 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
827.00 MB/s |
201 500.96 IOPS |
Случайная запись 4k qd=1 fsync=1 |
22.85 MB/s |
5 580.61 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
66.35 MB/s |
16 209.50 IOPS |
RaidZ |
zfs-local-raidZ-16k |
|
Последовательная запись 4M qd=32 |
1 701.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
3 967.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
154.50 MB/s |
37 638.80 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
427.50 MB/s |
104 231.22 IOPS |
Случайная запись 4k qd=1 fsync=1 |
11.30 MB/s |
2 757.17 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
28.75 MB/s |
7 017.52 IOPS |
2 - блок 8к (старые дефолтные параметры)
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O recordsize=8k nvme /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1
zfs create -s -V 10T -o volblocksize=8k -o compression=lz4 nvme/iserStripe |
zfs-local-stripe-8k |
|
Последовательная запись 4M qd=32 |
1 513.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
3 352.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
155.00 MB/s |
37 860.44 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
710.00 MB/s |
172 631.13 IOPS |
Случайная запись 4k qd=1 fsync=1 |
21.75 MB/s |
5 311.53 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
65.55 MB/s |
16 005.12 IOPS |
RaidZ |
zfs-local-raidZ-8k |
|
Последовательная запись 4M qd=32 |
1 035.50 MB/s |
- |
Последовательное чтение 4M qd=32 |
2 877.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
153.00 MB/s |
37 383.61 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
427.50 MB/s |
104 453.05 IOPS |
Случайная запись 4k qd=1 fsync=1 |
10.90 MB/s |
2 657.64 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
23.45 MB/s |
5 716.16 IOPS |
v3 - блок 64к (как просто большой блок)
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O recordsize=64k nvme /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1
zfs create -s -V 10T -o volblocksize=64k -o compression=lz4 nvme/iserStripe |
zfs-local-stripe-64k |
|
Последовательная запись 4M qd=32 |
4 778.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
5 121.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
183.50 MB/s |
44 785.15 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
1 062.50 MB/s |
259 321.58 IOPS |
Случайная запись 4k qd=1 fsync=1 |
22.80 MB/s |
5 559.02 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
65.85 MB/s |
16 085.35 IOPS |
RaidZ |
zfs-local-raidZ-64k |
|
Последовательная запись 4M qd=32 |
3 758.00 MB/s |
- |
Последовательное чтение 4M qd=32 |
4 269.00 MB/s |
- |
Случайная запись 4k qd=128 jobs=16 |
156.00 MB/s |
38 111.73 IOPS |
Случайное чтение 4k qd=128 jobs=16 |
1 086.50 MB/s |
265 232.02 IOPS |
Случайная запись 4k qd=1 fsync=1 |
17.90 MB/s |
4 372.47 IOPS |
Случайное чтение 4k qd=1 fsync=1 |
73.15 MB/s |
17 855.23 IOPS |
Также для ZFS дополнительно был сделан тест на 64 потока в виде 64 разных файлов на пуле:
recordsize=8k
Stripe |
zfs64-local-stripe-8k |
Последовательная запись 4M qd=32 |
1 242.50 MB/s |
Последовательное чтение 4M qd=32 |
3 123.00 MB/s |
Случайная запись 4k qd=128 jobs=16 |
275.50 MB/s |
Случайное чтение 4k qd=128 jobs=16 |
1 436.00 MB/s |
Случайная запись 4k qd=1 fsync=1 |
196.50 MB/s |
Случайное чтение 4k qd=1 fsync=1 |
1 439.00 MB/s |
RaidZ |
zfs64-local-raidZ-8k |
Последовательная запись 4M qd=32 |
981.00 MB/s |
Последовательное чтение 4M qd=32 |
3 756.00 MB/s |
Случайная запись 4k qd=128 jobs=16 |
187.50 MB/s |
Случайное чтение 4k qd=128 jobs=16 |
1 192.50 MB/s |
Случайная запись 4k qd=1 fsync=1 |
138.00 MB/s |
Случайное чтение 4k qd=1 fsync=1 |
1 209.00 MB/s |
recordsize=16k
Stripe |
zfs64-local-stripe-16k |
Последовательная запись 4M qd=32 |
2 346.00 MB/s |
Последовательное чтение 4M qd=32 |
4 508.00 MB/s |
Случайная запись 4k qd=128 jobs=16 |
296.50 MB/s |
Случайное чтение 4k qd=128 jobs=16 |
1 248.50 MB/s |
Случайная запись 4k qd=1 fsync=1 |
201.00 MB/s |
Случайное чтение 4k qd=1 fsync=1 |
1 228.50 MB/s |
RaidZ |
zfs64-local-raidZ-16k |
Последовательная запись 4M qd=32 |
1 579.00 MB/s |
Последовательное чтение 4M qd=32 |
5 044.00 MB/s |
Случайная запись 4k qd=128 jobs=16 |
186.00 MB/s |
Случайное чтение 4k qd=128 jobs=16 |
1 000.00 MB/s |
Случайная запись 4k qd=1 fsync=1 |
138.00 MB/s |
Случайное чтение 4k qd=1 fsync=1 |
1 003.50 MB/s |
recordsize=64k
Stripe |
zfs64-local-stripe-64k |
Последовательная запись 4M qd=32 |
5 252.50 MB/s |
Последовательное чтение 4M qd=32 |
6 260.00 MB/s |
Случайная запись 4k qd=128 jobs=16 |
241.00 MB/s |
Случайное чтение 4k qd=128 jobs=16 |
506.00 MB/s |
Случайная запись 4k qd=1 fsync=1 |
151.00 MB/s |
Случайное чтение 4k qd=1 fsync=1 |
562.00 MB/s |
RaidZ |
zfs64-local-raidZ-64k |
Последовательная запись 4M qd=32 |
3 658.50 MB/s |
Последовательное чтение 4M qd=32 |
5 737.50 MB/s |
Случайная запись 4k qd=128 jobs=16 |
177.00 MB/s |
Случайное чтение 4k qd=128 jobs=16 |
460.50 MB/s |
Случайная запись 4k qd=1 fsync=1 |
128.00 MB/s |
Случайное чтение 4k qd=1 fsync=1 |
504.50 MB/s |
Сводные графики по тестам:
Последовательная запись 4M qd=32

Последовательное чтение 4M qd=32

Случайная запись 4k qd=128 jobs=16

Случайное чтение 4k qd=128 jobs=16
Случайная запись 4k qd=1 fsync=1

Случайное чтение 4k qd=1 fsync=1

Вывод
mdadm и stripe LVM имеют +- одинаковую производительность, при этом vdo с настройками по умолчанию в режиме stripe демонстрирует производительность (для случайных операций) на уровне ZFS.
ZFS на 64 впрочем вырывается вперёд в тестах qd=1, так как он игнорируется fsync и эффективно это 64 операции для данного теста. В чтении на 64 одних потока же прекрасное работает ARC.
В стандартном состоянии - ZFS демонстрирует то, что ожидаешь от CoW системы ориетированной на HDD. Не особо быструю производительность на NVMe. Особенно грустно со случайным чтением с большое очередью.
Если строить таблицу беря mdadm за 100% получится следующая картина:
Raid0/Stripe
Raid0/Stripe |
mdadm-raid0 |
lvm-raid0 |
lvm-vdo-raid0 |
zfs-8k |
Последовательная запись 4M qd=32 |
100.00% |
91.03% |
6.13% |
12.63% |
Последовательное чтение 4M qd=32 |
100.00% |
101.01% |
11.24% |
16.53% |
Случайная запись 4k qd=128 jobs=16 |
100.00% |
119.05% |
3.51% |
1.31% |
Случайное чтение 4k qd=128 jobs=16 |
100.00% |
121.15% |
7.76% |
6.11% |
Случайная запись 4k qd=1 fsync=1 |
100.00% |
128.12% |
3.56% |
12.61% |
Случайное чтение 4k qd=1 fsync=1 |
100.00% |
81.46% |
39.20% |
65.88% |
Raid0/Stripe |
zfs-16k |
zfs-64k |
zfs64-8k |
zfs64-16k |
zfs64-64k |
Последовательная запись 4M qd=32 |
23.59% |
39.88% |
10.37% |
19.58% |
43.84% |
Последовательное чтение 4M qd=32 |
29.37% |
25.26% |
15.40% |
22.23% |
30.88% |
Случайная запись 4k qd=128 jobs=16 |
1.49% |
1.55% |
2.33% |
2.51% |
2.04% |
Случайное чтение 4k qd=128 jobs=16 |
7.12% |
9.14% |
12.36% |
10.74% |
4.35% |
Случайная запись 4k qd=1 fsync=1 |
13.25% |
13.22% |
113.91% |
116.52% |
87.54% |
Случайное чтение 4k qd=1 fsync=1 |
66.68% |
66.18% |
1446.23% |
1234.67% |
564.82% |
Отдельно сравнение ZFS 16k с\без дедупа:
zfs-local-stripe-16k |
zfs-local-stripe-16k-dedup |
|
Последовательная запись 4M qd=32 |
100.00% |
27.16% |
Последовательное чтение 4M qd=32 |
100.00% |
102.38% |
Случайная запись 4k qd=128 jobs=16 |
100.00% |
53.57% |
Случайное чтение 4k qd=128 jobs=16 |
100.00% |
97.94% |
Случайная запись 4k qd=1 fsync=1 |
100.00% |
97.16% |
Случайное чтение 4k qd=1 fsync=1 |
100.00% |
105.05% |
Raid5/RaidZ
Raid5/RaidZ |
mdadm-raid5 |
lvm-raid5 |
lvm-raid5-alloc-normal |
lvm-vdo-raid5 |
zfs-local-raidZ-8k |
Последовательная запись 4M qd=32 |
100.00% |
76.02% |
77.20% |
15.12% |
67.95% |
Последовательное чтение 4M qd=32 |
100.00% |
59.52% |
56.98% |
11.96% |
14.29% |
Случайная запись 4k qd=128 jobs=16 |
100.00% |
90.87% |
92.09% |
32.25% |
62.07% |
Случайное чтение 4k qd=128 jobs=16 |
100.00% |
88.71% |
88.28% |
14.56% |
4.05% |
Случайная запись 4k qd=1 fsync=1 |
100.00% |
56.87% |
74.31% |
5.13% |
35.22% |
Случайное чтение 4k qd=1 fsync=1 |
100.00% |
87.18% |
91.69% |
55.24% |
37.82% |
Raid5/RaidZ |
zfs-raidZ-16k |
zfs-raidZ-64k |
zfs64-raidZ-8k |
zfs64-raidZ-16k |
zfs64-raidZ-64k |
Последовательная запись 4M qd=32 |
111.61% |
246.59% |
64.37% |
103.61% |
240.06% |
Последовательное чтение 4M qd=32 |
19.71% |
21.21% |
18.66% |
25.06% |
28.51% |
Случайная запись 4k qd=128 jobs=16 |
62.68% |
63.29% |
76.06% |
75.46% |
71.81% |
Случайное чтение 4k qd=128 jobs=16 |
4.05% |
10.30% |
11.31% |
9.48% |
4.37% |
Случайная запись 4k qd=1 fsync=1 |
36.51% |
57.84% |
445.88% |
445.88% |
413.57% |
Случайное чтение 4k qd=1 fsync=1 |
46.37% |
117.98% |
1950.00% |
1618.55% |
813.71% |
Для дальнейших тестов с использованием iSER будут использоваться 3 основных варианта:
mdadm stripe
lvm stripe
ZFS stripe с блоком 16к
ZFS stripe с блоком 16к и дедупом
P.S. Если Вы считаете, что эти тесты неполные, в них что-то упущено или они некорректно - я открыт к любым предложениям по их дополнению.
Для теста zfs64 был использован следующий формат команды:
fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4M -iodepth=32 -rw=write -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4M -iodepth=32 -rw=read -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -invaqdlidate=1 -bs=4k -iodepth=128 -numjobs=16 -group_reporting -rw=randwrite -runtime=60 -randrepeat=0 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=128 -numjobs=16 -group_reporting -rw=randread -runtime=60 -randrepeat=0 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -randrepeat=0 -rw=randwrite -bs=4k -numjobs=1 -iodepth=1 -fsync=1 -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -randrepeat=0 -rw=randread -bs=4k -numjobs=1 -iodepth=1 -fsync=1 -runtime=60 -filesize=20G >> zfs64-.txt && echo "###" >> zfs64-.txt && sleep 60 && fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4M -iodepth=32 -rw=write -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4M -iodepth=32 -rw=read -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=128 -numjobs=16 -group_reporting -rw=randwrite -runtime=60 -randrepeat=0 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -iodepth=128 -numjobs=16 -group_reporting -rw=randread -runtime=60 -randrepeat=0 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -randrepeat=0 -rw=randwrite -bs=4k -numjobs=1 -iodepth=1 -fsync=1 -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt && sleep 30 && fio -name=test1 -ioengine=libaio -direct=1 -randrepeat=0 -rw=randread -bs=4k -numjobs=1 -iodepth=1 -fsync=1 -runtime=60 -filesize=20G >> zfs64-.txt && echo "***" >> zfs64-.txt
Комментарии (17)



knutov
08.08.2023 16:52Тесты супер, но есть вопросы к результатам теста по zfs. При локальном тестировании на 6 дисков имею значительно более хорошие результаты даже на крутящихся дисках, от чего кажется вероятным что что-то не так при доступе к по сети или в сочетании с доступа по сети с zfs.

Dante4 Автор
08.08.2023 16:52Более высокие показатели на какие именно тесты?
Все приведенные тесты в этой статье это локальное тестирование

navion
08.08.2023 16:52Было бы интересно сравнить с актуальной версией RAIDIX в RAID6/Z2. Практического применения ни RAID0, ни RAID5 давно не имеют.
Dante4 Автор
08.08.2023 16:52Не согласен, на малых объемах и на малом количестве дисков r5 имеет право на использование.
Тем более в этой статье речь не про хранилище для очень важных данных, а про быстрое хранение забэкаапленных данных или тех, что легко восстановить.

hogstaberg
08.08.2023 16:52Вот с пунктом неприменимости когда
Надежность >>> скорость
я бы поспорил. Тот же mdadm, например, давно обкатан и в плане надежности даст прикурить любым рейд-контроллерам.
Dante4 Автор
08.08.2023 16:52+1Здесь не совсем надёжность с точки зрения выбранного ПО, а с точки зрения выбранного уровня рейда и типов дисков.
В рамках этого стенда диски подключены через PCIe шину, а не через бэкплейн или рейд контроллер, поэтому при выходе из строя одного диска - система ляжет и нужен будет ребут, так как на горячую их не поменять
hogstaberg
08.08.2023 16:52+1Ну теоретически так-то pci-e hotswap уже давно is a thing. Вопрос к реализации в конкретных железках.
arheops
Где загрузка процессора и load average?
Где тестирование с процессором послабее?
Имхо по вашим графикам можно только понять, что если у вас супе-процессор и он справляется, все упирается в сами диски.
MrAlone
А зачем это тестировать? Раньше(лет дцать назад, в 2000-х) на RAID картах стояли отдельные процессоры на примерно 200-400Mhz, которые считали контрольные суммы, и была батарейка, чтоб кэш не пропал. Уже тогда у средних серверных CPU уходило не более 5% на поддержание RAID. А сейчас то зачем? Там и пол процента одного ядра не наберётся.
arheops
При 2500 гбайт записи в секунду?
К сожалению, это не так.
Как минимум это надо, чтоб понимать, можете ли вы что-то еще на этот сервер поставить или это будет только сторедж сервер.
MrAlone
Всё очень и очень просто - https://habr.com/ru/search/?q=nvme raid&target_type=posts&order=relevance Самое простое - https://habr.com/ru/companies/ruvds/articles/598357/ Опровергайте, у вас есть результаты сравнения железных рэйдов и софтовых, с удовольствием их посмотрю. Да и все здесь тоже с удовольствием посмотрят на ваши результаты.
nikweter
Допустим, про zfs в ваших ссылках ничего нет. Сам лично столкнулся что если бахнуть на массив запись в 64 потока, то IOPS, конечно, выдает офигенные, где-то 260К, вот только загрузка процессора при этом 60-70%. Не одного ядра, а всего процессора. И это AMD EPYC 74F3, мощный 24 ядерный проц. Особо не разбирался, производительность mdadm схожа на тех же дисках, он мне более привычен и не оказывает влияния на процессор.
MrAlone
И да, при "2500 гбайт записи в секунду" даже не знаю, какой уж процессор нужен. Наверное что-то из будущего, как и диски.