
Первая статья была посвящена производительности со стороны локальной системы (https://habr.com/ru/articles/753322/).
Смысл данной статьи остаётся схожей, показать максимальную производительность, когда вопрос сохранности данных решается репликами или бэкапами.
Цель данной статьи протестировать производительность трёх систем объединения физических устройств в одну логическую группу при использовании iSER и NVMe-oF.
В рамках данной статьи будут сравниваться три системы, продемострирующие самые высокие показатели по результатам тестов из первой части.
mdadm raid0
LVM stripe
ZFS stripe (default lz4)
А также самое функциональное решение из доступных бесплатных бэкэндов:
ZFS stripe с компрессией и дедупликацией
При подключении через iSER и NVMe-oF.
Оглавление:
1. Тестовый стенд:
Сервер виртуализации 1:
Motherboard: Supermicro H11SSL-i
CPU: EPYC 7302
RAM: 4x64GB Micron 2933MHz
Сеть: 40GbE ConnectX-3 Pro, 10GbE/25GbE ConnectX-4 LN EN
ОС: ESXi 7U3 build 20036586
Сервер виртуализации 2:
Motherboard: Tyan S8030 (ver 1GbE)
CPU: EPYC 7302
RAM: 4x64GB Micron 2933MHz
Сеть: 40GbE ConnectX-3 Pro x2 (Один адаптер прокинут в ВМ)
ОС: ESXi 7U3 build 21930508
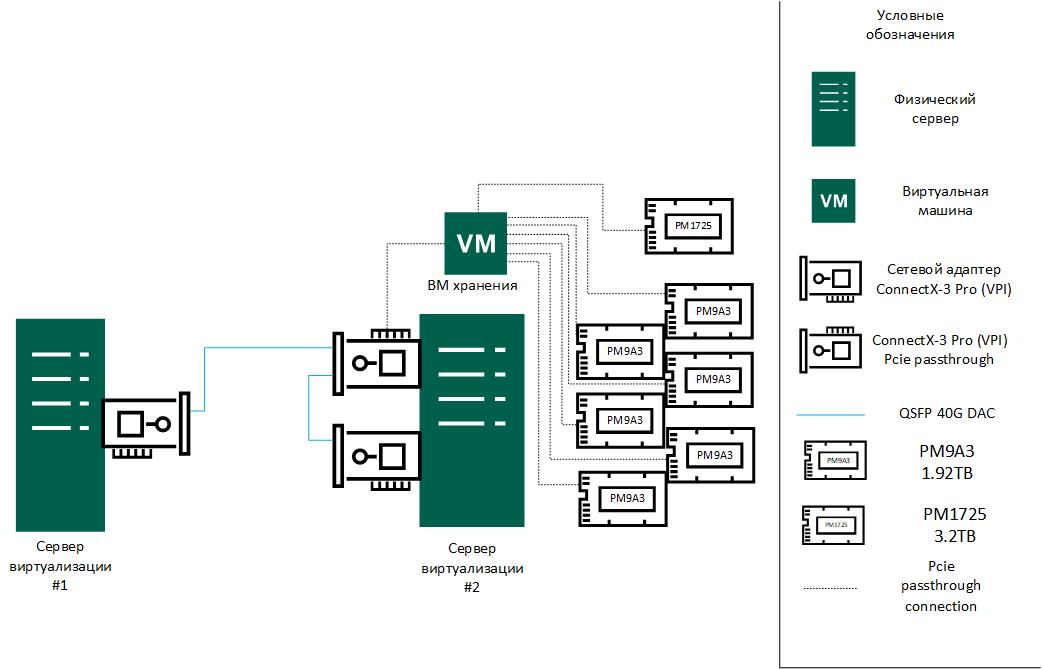
ВМ хранения на сервере виртуализации #2, которая будет предоставлять блочный доступ для хоста 1 и хоста 2:
ОС: Ubuntu 22.04, ядро 6.2.0-26 (mitigations=off)
vCPU: 8
RAM: 64GB (для ZFS расширена до 128ГБ)
Диски: 6xPM9A3 1.92TB (обновлены до версии GDC5902Q)
Схема подключения:
Примечание: Для HCIbench отсутствует документация по тому как поменять код тестирования на использование /dev/nvme0nX, вместо /dev/sdX, в связи с этим тесты проводятся с использованием pvscsi.
Согласно тестам различие между pvscsi и nvme контроллером лежит в пределах погрешности измерения 5% (подробнее в таблице тестов) для версии 7U3, так как полноценный NVMe back-to-back был реализован только в 8U2, которая уже не поддерживается ConnectX-3 :(
Параметр Prepare Virtual Disk Before Testing выставлено в значение Random. Тесты проводятся с использованием - 4 ВМ с двумя дисками по 100ГБ, 8 vCPU, 16GB RAM.
Для выбора тестов ориетиром для параметров были взяты значения из следующего источника.
-
Тест 1:
VDbench - 4k - 80% rng - 50/50 r/w - 8 thread per disk
-
Тест 2:
VDbench - 8k - 80% rng - 75/25 r/w - 8 thread per disk
-
Тест 3:
VDbench - 64k - 80% seq - 75/25 r/w - 8 thread per disk
-
Тест 4:
VDbench - max_iops_read - 4k - 100% rng - 100/0 r/w - 8 thread per disk
-
Тест 5:
VDbench - max_iops_write - 4k - 100% rng - 0/100 r/w - 8 thread per disk
Для тестирования падения скорости в результате добавления прослойки в виде ВМ использовались тесты из первой части, результаты ниже в таблице и графика (погрешность +-5%,):
SCSI controller (pvscsi) |
NVMe controller |
% pvscsi=100% |
|
Последовательная запись 4M qd=32 |
4603.11 МБ/с |
4594.44 МБ/с |
99.81% |
Последовательное чтение 4M qd=32 |
4618.22 МБ/с |
4618.33 МБ/с |
100.00% |
Случайная запись 4k qd=128 jobs=16 |
558.56 МБ/с |
541.06 МБ/с |
96.87% |
Случайное чтение 4k qd=128 jobs=16 |
589.72 МБ/с |
581.89 МБ/с |
98.67% |
Случайная запись 4k qd=1 fsync=1 |
54.61 МБ/с |
60.02 МБ/с |
109.90% |
Случайное чтение 4k qd=1 fsync=1 |
28.28 МБ/с |
29.76 МБ/с |
105.21% |
Результаты тестов iperf3 между ConnnectX-3 Pro, выполнялись путём проброса ConnectX-3 Pro в ВМ на каждом из хостов, т.е. схема выглядит следующим образом:

Результатом стало:
Sender |
34.93 Gbits/sec |
Receiver |
34.21 Gbits/sec |
Округляя в меньшую сторону, получаем:
34 Gbits/sec (или 4.25 Gbytes/s)
Относительно OFED. Для тестов также использовалась Ubuntu 20.04 с ядром 5.5 и установленным для него OFED, но Ubuntu 22.04.03 с ядром 6.2 продемонстрировала выше производительность и повторяемость в iperf3.
iperf3
Тесты выполнялись в соответствии с данными рекомендациями (https://fasterdata.es.net/performance-testing/network-troubleshooting-tools/iperf/multi-stream-iperf3/)
s1: [ ID] Interval Transfer Bitrate Retr
s1: [ 5] 0.00-10.00 sec 15.2 GBytes 13.0 Gbits/sec 1062 sender
s1:
s1: iperf Done.
s2: - - - - - - - - - - - - - - - - - - - - - - - - -
s2: [ ID] Interval Transfer Bitrate Retr
s2: [ 5] 0.00-10.00 sec 14.8 GBytes 12.7 Gbits/sec 1856 sender
s2:
s2: iperf Done.
s3: - - - - - - - - - - - - - - - - - - - - - - - - -
s3: [ ID] Interval Transfer Bitrate Retr
s3: [ 5] 0.00-10.00 sec 10.0 GBytes 8.59 Gbits/sec 1027 senderСуммарно 34.29 Gbits/sec
И с флагом -bidir
s1: [ ID] Interval Transfer Bitrate Retr
s1: [ 5] 0.00-10.00 sec 13.4 GBytes 11.5 Gbits/sec 1705 sender
s1: [ 5] 0.00-10.04 sec 13.2 GBytes 11.3 Gbits/sec receiver
s1:
s1: iperf Done.
s2: - - - - - - - - - - - - - - - - - - - - - - - - -
s2: [ ID] Interval Transfer Bitrate Retr
s2: [ 5] 0.00-10.00 sec 10.4 GBytes 8.93 Gbits/sec 2171 sender
s2: [ 5] 0.00-10.05 sec 10.1 GBytes 8.61 Gbits/sec receiver
s3: - - - - - - - - - - - - - - - - - - - - - - - - -
s3: [ ID] Interval Transfer Bitrate Retr
s3: [ 5] 0.00-10.00 sec 16.8 GBytes 14.5 Gbits/sec 1513 sender
s3: [ 5] 0.00-10.04 sec 16.7 GBytes 14.3 Gbits/sec receiver
s3:
s3: iperf Done.Сравнивания производительность NVMe дисков при их подключении напрямую в ОС или через VMware с PCIe passthrough можно говорить о том, что производительность не меняется, так как результаты находятся в пределах 2% погрешности.
Тесты
PM1725 |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
1820.50 МБ/c |
1826.50 МБ/c |
Последовательное чтение 4M qd=32 |
4518.00 МБ/c |
4553.50 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
1504.00 МБ/c |
1502.50 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
3488.00 МБ/c |
3514.50 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
148.50 МБ/c |
172.50 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
42.90 МБ/c |
45.45 МБ/c |
PM9A3 (0369) |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
2811.00 МБ/c |
2811.00 МБ/c |
Последовательное чтение 4M qd=32 |
5822.50 МБ/c |
5845.00 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
2807.00 МБ/c |
2806.00 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
4601.00 МБ/c |
4746.50 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
211.50 МБ/c |
175.50 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
98.25 МБ/c |
87.80 МБ/c |
PM9A3 (6310) |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
2811.00 МБ/c |
2811.00 МБ/c |
Последовательное чтение 4M qd=32 |
5846.50 МБ/c |
5835.50 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
2806.50 МБ/c |
2807.00 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
4610.00 МБ/c |
4743.00 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
211.50 МБ/c |
178.00 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
98.30 МБ/c |
87.85 МБ/c |
PM9A3 (6314) |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
2811.00 МБ/c |
2811.00 МБ/c |
Последовательное чтение 4M qd=32 |
5839.00 МБ/c |
5844.00 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
2806.00 МБ/c |
2807.00 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
4602.50 МБ/c |
4746.00 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
209.00 МБ/c |
174.50 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
98.65 МБ/c |
87.20 МБ/c |
PM9A3 (3349) |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
2811.00 МБ/c |
2811.00 МБ/c |
Последовательное чтение 4M qd=32 |
5844.00 МБ/c |
5835.50 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
2807.00 МБ/c |
2806.50 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
4598.50 МБ/c |
2328.00 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
208.00 МБ/c |
201.50 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
98.10 МБ/c |
94.90 МБ/c |
PM9A3 (1091) |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
2811.00 МБ/c |
2811.00 МБ/c |
Последовательное чтение 4M qd=32 |
5827.00 МБ/c |
5842.50 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
2806.50 МБ/c |
2807.50 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
4514.00 МБ/c |
4651.00 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
205.50 МБ/c |
172.50 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
98.00 МБ/c |
87.40 МБ/c |
PM9A3 (0990) |
Физический |
Через PCIe passthrough |
Последовательная запись 4M qd=32 |
2810.50 МБ/c |
2811.00 МБ/c |
Последовательное чтение 4M qd=32 |
5849.50 МБ/c |
5857.00 МБ/c |
Случайная запись 4k qd=128 jobs=16 |
2797.50 МБ/c |
2807.00 МБ/c |
Случайное чтение 4k qd=128 jobs=16 |
4489.00 МБ/c |
4646.00 МБ/c |
Случайная запись 4k qd=1 fsync=1 |
206.00 МБ/c |
183.50 МБ/c |
Случайное чтение 4k qd=1 fsync=1 |
97.20 МБ/c |
88.05 МБ/c |
Рассматриваться будет 2 сценария:
Выдача блочного устройства через iSER с помощью LIO (настройка осуществляется с помощью targetcli-fb с мастер ветки репозитория)
-
Выдача блочного устройства через NVMe-oF с помощью SPDK.
Небольшое отступление - сперва планировалось использовать нативную реализацию ядра - nvmet (https://enterprise-support.nvidia.com/s/article/howto-configure-nvme-over-fabrics--nvme-of--target-offload), но она не поддерживается VMware (https://koutoupis.com/2022/04/22/vmware-lightbits-labs-and-nvme-over-tcp/ https://communities.vmware.com/t5/ESXi-Discussions/NVMEof-Datastore-Issues/td-p/2301440), поэтому был использован SPDK (https://spdk.io/doc/nvmf.html, https://spdk.io/doc/bdev.html)
2. iSER
Со стороны Linux:
В настройках LIO прописывается enable_iser boolean=true на уровне портала:
set attribute authentication=0 demo_mode_write_protect=0 generate_node_acls=1 cache_dynamic_acls=1Дополнительно для девайса прописаны следующие опции (https://documentation.suse.com/ses/7/html/ses-all/deploy-additional.html):
set attribute emulate_3pc=1 emulate_tpu=1 emulate_caw=1 max_write_same_len=65535 emulate_tpws=1 is_nonrot=1Со стороны VMware:
esxcli rdma iser addЗатем настройка аналогична настройкам как для iSCSI массива.
Производительность mdadm с тестами FIO из первой части на 1 ВМ выглядит следующим образом:
mdadm raid0 1ВМ |
МБ/c |
IOPS |
Последовательная запись 4M qd=32 |
3632.00 МБ/c |
866.20 |
Последовательное чтение 4M qd=32 |
3796.50 МБ/c |
902.14 |
Случайная запись 4k qd=128 jobs=16 |
352.00 МБ/c |
85736.44 |
Случайное чтение 4k qd=128 jobs=16 |
559.50 МБ/c |
136797.19 |
Случайная запись 4k qd=1 fsync=1 |
39.80 МБ/c |
9712.06 |
Случайное чтение 4k qd=1 fsync=1 |
26.10 МБ/c |
6382.21 |
Конечный график выглядит следующим образом:

2.1 MDADM
mdadm --create --verbose /dev/md0 --level=0 --raid-devices=6 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1mdadm - iSER |
МБ/с |
IOPS |
4k-50rdpct-80randompct |
486.78 МБ/с |
124615.40 |
8k-75rdpct-80randompct |
941.52 МБ/с |
120514.50 |
64k-75rdpct-80randompct |
3445.29 МБ/с |
55124.70 |
4k-0rdpct-100randompct |
495.13 МБ/с |
126752.90 |
4k-100rdpct-100randompct |
483.9 МБ/с |
123877.10 |
2.2 LVM
lvcreate -i6 -I64 --type striped -l 100%VG -n nvme_stripe nvmeLVM - iSER |
МБ/с |
IOPS |
4k-50rdpct-80randompct |
514.27 МБ/с |
131652.90 |
8k-75rdpct-80randompct |
957.10 МБ/с |
122509.10 |
64k-75rdpct-80randompct |
3710.36 МБ/с |
59365.80 |
4k-0rdpct-100randompct |
535.9 МБ/с |
137192.80 |
4k-100rdpct-100randompct |
505.42 МБ/с |
129386.40 |
2.3 ZFS
v1 (without dedup)
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O recordsize=128k nvme /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 zfs create -s -V 10T -o volblocksize=16k -o compression=lz4 nvme/iserZFS - iSER |
МБ/с |
IOPS |
4k-50rdpct-80randompct |
131.77 МБ/с |
33734.00 |
8k-75rdpct-80randompct |
343.34 МБ/с |
43947.40 |
64k-75rdpct-80randompct |
1418.62 МБ/с |
22698.20 |
4k-0rdpct-100randompct |
80.81 МБ/с |
20690.60 |
4k-100rdpct-100randompct |
251.38 МБ/с |
64354.60 |
v2 (with dedup)
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O dedup=on -O recordsize=128k nvme /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 zfs create -s -V 10T -o volblocksize=16k -o compression=lz4 nvme/iserZFS - iSER |
МБ/с |
IOPS |
4k-50rdpct-80randompct |
56.75 МБ/с |
14525.60 |
8k-75rdpct-80randompct |
174.89 МБ/с |
22385.60 |
64k-75rdpct-80randompct |
384.76 МБ/с |
6156.20 |
4k-0rdpct-100randompct |
28.73 МБ/с |
7355.00 |
4k-100rdpct-100randompct |
200.54 МБ/с |
51337.80 |
3. NVMe-oF:
Со стороны Linux:
Помимо банальной установки SPDK (https://spdk.io/doc/getting_started.html), есть 1 нюанс. На момент написания статьи SPDK из мастера не работает с VMware по причине реализации проверки на параметр responder_resources == 0. Со стороны VMware этот параметр равен 1 (https://github.com/spdk/spdk/issues/3115). Поэтому необходимо собрать версию 23.05.x, поэтому процесс установки spdk будет начинаться не с - пофикшено в c8b9bba
git clone https://github.com/spdk/spdk --recursive
modprobe nvme-rdma
modprobe rdma_ucm
modprobe rdma_cm
scripts/setup.sh
screen - либо другая сессия, либо можно написать демона, который будет запускать его сам
build/bin/nvmf_tgt
ctrl+a d - отключение от сессии screen и возврат в консоль
scripts/rpc.py nvmf_create_transport -t RDMA -u 8192 -i 131072 -c 8192
scripts/rpc.py nvmf_create_subsystem nqn.2016-06.io.spdk:cnode1 -a -s SPDK00000000000001 -d SPDK_Controller
scripts/rpc.py bdev_aio_create /dev/md0 md0
scripts/rpc.py nvmf_subsystem_add_ns nqn.2016-06.io.spdk:cnode1 md0
scripts/rpc.py nvmf_subsystem_add_listener nqn.2016-06.io.spdk:cnode1 -t rdma -a 10.20.0.1 -s 4420
scripts/rpc.py nvmf_subsystem_add_listener nqn.2016-06.io.spdk:cnode1 -t rdma -a 10.20.0.5 -s 4420Со стороны VMware:
esxcli system module parameters set -m nmlx4_core -p "enable_rocev2=1" (в противном случае будет ошибка "Underlying device does not support requested gid/RoCE type.")
Затем в веб создаётся VMware NVME over RDMA Storage Adapter, в controller задаётся IP адрес ВМ, указанный ранее, в поле порт - порт 4420
Производительность mdadm с тестами FIO из первой части на 1 ВМ выглядит следующим образом:
mdadm raid0 1ВМ |
МБ/с |
IOPS |
Последовательная запись 4M qd=32 |
4593.00 МБ/с |
1095.55 |
Последовательное чтение 4M qd=32 |
4618.00 МБ/с |
1101.67 |
Случайная запись 4k qd=128 jobs=16 |
542.00 МБ/с |
132417.04 |
Случайное чтение 4k qd=128 jobs=16 |
575.50 МБ/с |
140674.20 |
Случайная запись 4k qd=1 fsync=1 |
61.50 МБ/с |
15013.28 |
Случайное чтение 4k qd=1 fsync=1 |
30.35 МБ/с |
7418.52 |
Конечный график выглядит следующим образом:

3.1 MDADM
mdadm --create --verbose /dev/md0 --level=0 --raid-devices=6 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1mdadm - NVMe-oF |
MB/s |
IOPS |
4k-50rdpct-80randompct |
570.59 МБ/c |
146070.90 |
8k-75rdpct-80randompct |
1113.46 МБ/c |
142522.10 |
64k-75rdpct-80randompct |
5775.06 МБ/c |
92401.00 |
4k-0rdpct-100randompct |
593.87 МБ/c |
152033.00 |
4k-100rdpct-100randompct |
540.54 МБ/c |
138378.60 |
3.2 LVM
lvcreate -i6 -I64 --type stripe -l 100%VG -n lvm_stripe stripeLVM - NVMe-oF |
MB/s |
IOPS |
4k-50rdpct-80randompct |
596.39 МБ/с |
152675.70 |
8k-75rdpct-80randompct |
1160.72 МБ/с |
148572.30 |
64k-75rdpct-80randompct |
5826.39 МБ/с |
93222.20 |
4k-0rdpct-100randompct |
618.22 МБ/с |
158267.10 |
4k-100rdpct-100randompct |
559.45 МБ/с |
143219.80 |
3.3 ZFS
v1 (without dedup)
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O recordsize=128k nvme /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 zfs create -s -V 10T -o volblocksize=16k -o compression=lz4 nvme/iserNVMe-oF ZFS |
MB/s |
IOPS |
4k-50rdpct-80randompct |
131.18 МБ/с |
33585.30 |
8k-75rdpct-80randompct |
344.21 МБ/с |
44057.10 |
64k-75rdpct-80randompct |
1409.13 МБ/с |
22546.10 |
4k-0rdpct-100randompct |
78.63 МБ/с |
20129.20 |
4k-100rdpct-100randompct |
267.21 МБ/с |
68406.10 |
v2 (with dedup)
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O dedup=on -O recordsize=128k nvme /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 zfs create -s -V 10T -o volblocksize=16k -o compression=lz4 nvme/iserNVMe-oF ZFS (dedup) |
MB/s |
IOPS |
4k-50rdpct-80randompct |
56.1 МБ/с |
14362.50 |
8k-75rdpct-80randompct |
183.32 МБ/с |
23464.70 |
64k-75rdpct-80randompct |
355.83 МБ/с |
5693.00 |
4k-0rdpct-100randompct |
28.07 МБ/с |
7185.10 |
4k-100rdpct-100randompct |
211.7 МБ/с |
54195.40 |
4. Вывод
LVM показывает самые высокие результаты, поэтому если брать его за 100%, то результаты тестов будут выглядеть следующим образом:
iSER |
LVM |
mdadm |
ZFS |
ZFS dedup |
4k-50rdpct-80randompct |
100.00% |
94.65% |
25.62% |
11.04% |
8k-75rdpct-80randompct |
100.00% |
98.37% |
35.87% |
18.27% |
64k-75rdpct-80randompct |
100.00% |
92.86% |
38.23% |
10.37% |
4k-0rdpct-100randompct |
100.00% |
92.39% |
15.08% |
5.36% |
4k-100rdpct-100randompct |
100.00% |
95.74% |
49.74% |
39.68% |
NVMe-oF |
LVM |
mdadm |
ZFS |
ZFS dedup |
4k-50rdpct-80randompct |
100.00% |
95.67% |
22.00% |
9.41% |
8k-75rdpct-80randompct |
100.00% |
95.93% |
29.65% |
15.79% |
64k-75rdpct-80randompct |
100.00% |
99.12% |
24.19% |
6.11% |
4k-0rdpct-100randompct |
100.00% |
96.06% |
12.72% |
4.54% |
4k-100rdpct-100randompct |
100.00% |
96.62% |
47.76% |
37.84% |
ZFS как и ожидалось демонстрирует не самые высокие результаты, но это, в том числе, связано с нагрузкой по CPU, но и в целом на это влияет тот факт, что ZFS не приспособлен для быстрой работы с NVMe.
Все результаты тестов доступны тут и таблица excel тут (да, все таблицы в архиве, так как гугл таблицы ломают формулы).
График всех тестов с группировкой по используемому протоколу подключения выглядит следующим образом (график дублируется из пункт 2 и 3)


График всех тестов с группировкой по используемому софт рейду





P.S. Если Вы считаете, что эти тесты неполные, в них что-то упущено или они некорректны - я открыт к любым предложениям по их дополнению.
Комментарии (28)

red_void
24.09.2023 00:50+1На локальной системе у вас получилось, что mdadm'овый рейд быстрее LVM на паттернах последовательной записи и, особенно, однопоточного случайного чтения. А через сеть получается, что LVM строго быстрее. Почему так может быть?
И еще за методологию хочется спросить. Вы делали одни и те же тесты несколько раз, а потом усредняли? Или просто один раз тест проводили и записывали результаты?

mrobespierre
24.09.2023 00:50+1Вот да поддержу про методологию. Что по sysctl на Ubuntu, как минимум vm.dirty_bytes, vm.dirty_background_bytes, vm.dirty_expire_centisecs и vm.dirty_writeback_centisecs? Стандартные хорошо работают если памяти всего 1-2 гига, и плохо, если больше.

outlingo
24.09.2023 00:50Бесполезный и бессмысленный совет в лучшеих традициях краго-культа.
Эти параметры относятся к VFS и page cache, а при тестировании дисков fio принято запускать с флагом direct=1, что приводит к тмоу, что вы можете в эти параметры хоть что записать, потому что значения не используются.
P.S.: ZFS это вообще отдельная песня, но на нее эти параметры тоже не действуют (по другим причинам, но те мне менее)
mrobespierre
24.09.2023 00:50https://github.com/openzfs/zfs/issues/11407
это какой-то другой zfs, или там в обсуждении идиоты одни обсуждают уменьшение dirty bytes кеша и его положительный эффект?
outlingo
24.09.2023 00:50+2Там альтернативно талантливые люди героически создают себе проблемы и потом их потужно перемогают.
Суть их проблемы в том, что они создали ZVOL, создали на нем файловую систему и смонтировали ее (в /blobs, но это не имеет значения - достаточно того что они создали ФС поверх блочного устройства ZVOL). В результате у них создалось два кэша - один page cache над ZVOL и второй внутри ZFS ее собственными средствами. После чего они ломанулись героически решать указанную проблему.
В случае же этой статьи (и c учетом предыдущей) ясно, что авторы также используют ZVOL, но в отличие от людей по ссылке, они, действуя вполне разумно, подают его в ядерный таргет линукса, а в нем ZVOL подключется как /backstore/blockio (при попытке засунуть блочное устройство в /backstores/fileio targetcli ругается). По умолчанию, writeback кэш там не используется (да и writethrough тоже0 и устройство открывается как раз в режиме direct I/O.
Поэтому да, повторю - параметры тюнинга VFS и кэшей здесь не используются и результата не дадут.

Dante4 Автор
24.09.2023 00:50Если обратиться к первой статье, то LVM был в среднем на 6% быстрее чем mdadm. Тут же наблюдается схожая картина.
К тому же прошу не забывать, что тесты не являются аналогичными.

ildarz
24.09.2023 00:50+1Я похожие показатели на 4K random получал с дисковой полки через стандартный 25G iSCSI без всяких NVMe и оффлоадов на виндовом хосте с бэкенда на SAS накопителях, и не на RAID-0, а на вариации RAID-6. Что-то у вас явно не так, особенно в случае с ZFS, которая часто используется в качестве бэкэнда в современных хранилищах и такого ужаса, конечно же, там не показывает.
Dante4 Автор
24.09.2023 00:50Коллега, прошу тогда тесты в студию. Если у Вас массив на 6 дисков в 6-м показывал схожие результаты на двух хостах, то я бы с удовольствием увидел Ваш стенд и методику тестирования.
ildarz
24.09.2023 00:50Тот массив давно уже в работе, а лишнего железа у меня сейчас нет. Но из того, что я вижу у вас - ПСП-то сетевух вы померяли, но на рэндом тестах важна не она, а латентность, и основное влияние NVMe-of в теории именно на нее должно быть (собственно в ней и есть основной провал между DAS и SAN на SSD). Не хотите посмотреть на неё, и на чисто сетевую, и на подключенные по сети диски?
А про ZFS ничего не могу сказать, тут я чисто на сторонние данные ориентируюсь.
Dante4 Автор
24.09.2023 00:50Боюсь тогда я не совсем понимаю, какие именно параметры Вы сравниваете.
Вы даже не описали:
сколько у Вас портов iSCSI
есть ли коммутатор
с помощью чего Вы давали нагрузку
какие у Вас сервера
сколько серверов
сколько дисков было
какого они (диски) объёма
какой сторадж у Вас был для объединения
ildarz
24.09.2023 00:50Задача "как получить 150К иопс с нескольких NVМe дисков" мне не видится настолько интересной, чтобы всерьез тратить время на углубление в детали. Я просто отметил, что схожая производительность по iSCSI в принципе нормальна для AFA хранилищ без всякого NVMe.
Основной смысл NVMe-of, как я уже писал, в снижении времени отклика, которое в случае стандартного iSCSI совершенно несопоставимо с DAS на флэше. Вы же время отклика, как я понимаю, вообще не меряли, поэтому тесты на random io у вас по сути неполноценны.
Dante4 Автор
24.09.2023 00:50Коллега. Вы говорите, что такую же производительность видели и на системе с 25Г iSCSI, не уточняя, что это была за система и сколько она стоила. Если у Вас были абсолютно аналогичные тесты в таких же условиях, то это другая ситуация.
Но говоря, что поделка на 6 дисков за ~160к (сервер+диски) показывает такие же результаты как массив стоимостью в 500к+ рублей - спасибо, приятно знать.
ildarz
24.09.2023 00:50Я вам про Фому, вы про Ерему. Еще раз - проведите замеры латентности, сравните со стандартным iSCSI, и вот там будет видно, дает ли какой-то профит NVMe-oF в вашем конфиге (сейчас этого не видно) или же вы настройки сделали, а особого результата они не дали.
Dante4 Автор
24.09.2023 00:50Я не совсем понимаю причём тут iSCSI в целом, так как я вообще не сравниваю ничего из этого с iSCSI. Вся статья идёт вокруг соединений с использованием RDMA.
ildarz
24.09.2023 00:50Еще раз. По результатам вашей статьи пока не складывается впечатления, что задействование iSER и NVMe-oF у вас дало результаты, для которых эти технологии в принципе были созданы (а именно, борьба с проблемой многократно более высокого времени отклика SAN по сравнению с DAS на SSD).
То есть вы вот что-то сделали - и оно как-то заработало. Ну ок, а насколько хорошо? Или вы априори так твердо уверены, что выжали максимум из доступных технологий?
Dante4 Автор
24.09.2023 00:50Я априори уверен, что использовать iSCSI будет медленнее. Можно ли получить такие же цифры с ним в других условиях на других серверах с другим количеством дисков на enterprise массиве? Да, можно. За х10 стоимости.
Касаемо выжать всё - для этого мне нужны 2x100Г сетевые карты x16 pcie 4.0 (~252 Гбит/с), а не 2x40Г x8 pcie 3.0 (~63 Гбит/с).
Тест iSCSI vs iSER vs NVMe-oF не совсем планировался, так как их много и без этого.
Время отклика доступно в архивах, так как HCIbench также замеряет его.
Причина почему я не стал его выводить на графики в том, что latency&глубина очереди&скорость&iops все являются связанными параметрами. Нельзя иметь выше iops и выше задержку при неизменной глубине очереди. Или выше скорось, при более высокой задержке при равной глубине очереди. Если это не так прошу меня просвятить
ildarz
24.09.2023 00:50Хорошо, последняя попытка. NVMe-over-Fabrics_Performance_Characterization.pdf (systor.org) - смотрите на разницу DAS/NVMe-oF, сравните с вашим случаем. Ни на какие мысли не наводит?

Paul_Arakelyan
24.09.2023 00:50Для того, чтоб использовать ZFS - надо изучить КАК оно работает и дальше думать своей головой, а не гуглом и хау-ту. Ужас в том, что нужно отталкиваться от применения, а не пытаться играть в синтетику на настройках по-умолчанию (хорошо хоть не 1М recordsize выставили). Сжатие - используют, чтоб "влезло побольше" (например, библиотека стим :) ), или "прочиталось чуть быстрее с медленных накопителей" (hdd 2.5" sata 7200), возможно - "съёкономить ресурс флэша" (очень спорный случай - перезапись мелких блоков приведёт к перезаписи громадного куска данных). Но никак не для "поднять производительность".
А уж дедупликация - это не о производительности совсем. Это о её катастрофе :).
Dante4 Автор
24.09.2023 00:50Про сжатия - уже было проверено (и не только мной), что оно не даёт негативных показателей для скорости.
По дедуп - это больше для справки, на случай, если его захотят включить при использовании NVMe носителей.

riv9231
24.09.2023 00:50Хотелось бы добавить, что zfs в простейшей конфигурации: несколько vdev без special (для метаданных), slog (для ускорения синхронной записи), dedup (для ускорения дедупликации) и cache - без этого всего, zfs скорее способ получить высокую надежность хранения данных при удовлетворительном быстродействии. Используя же все механизмы заложенные в этот комбайн вы можете построить по настоящему хорошо адаптированное для нагрузки решение.
Кроме того, меня расстраивают попытки сравнивать производительность zfs с чем-то простым типа lvm. Вот вам пример: 8 SAS дисков 15KRPM собранные в конфигурацию RAID10+LVM, которая просто в щи уделывает zfs на тех же дисках в синтетических тестах, еле-еле вывозили нагрузку от пары десятков виртуалок с базами данных. Важно отметить, что использовались снимки LVM. Когда эту связку заменили на zfs версии 0.6 (это самые первые версии zfsonlinux), нагрузка на диски упала до 6%, в то время как мы получили возможность делать не один снимок, после которого 40% утилизация дисков возрастала до 80%, а несколько сотен снимков, без роста нагрузки на диски + получили возможность инкрементальной асинхронной репликации.
И то же самое можно сказать почти про каждый аспект технологии zfs. Например, на приведенных ТС графиках, видно, что zfs уступает, не менее чем в 2 раза в лучшем случае по iops. Так это не удивительно, там же управление транзакциями добавляет как раз +100% iops минимум. Подключите special vdev и эта дополнительная нагрузка перейдёт на него. Это особенно полезно в комбинированных пулах на НЖМД, где метаданные вынесены на твердотельные накопители.
Ещё пример, дедупликация. Практика показывает, что удовлетворительное быстродействие можно получить подключив dedup vdev на nvme intel optane. Каждый optane vdev даст примерно 1Гбит скорости дедупликации (это очень грубо), если для dedup будет использоваться что-то типа SATA intel s3710, то можно рассчитывать примерно на 100 мегабит скорости дедупликации (тоже очень грубо).
Как выглядит подходящее использование zfs? У вас огромный пул из нескольких десятков или сотен НЖМД, объединенных, например в множество vdev raid-z2 объемом от 100ТБ до единиц ПБ, данные хранятся с подходящим сжатием, это дает x2..x3 к вашим условным 100ТБ, горячие данные кэшированы на твердотельных накопителях, это дает высокую скорость чтения, у вас есть slog для ускорения синхронной записи, а асинхронная и так достаточно быстра, т.к. zfs использует writeback. Вы не переживаете из-за потери данных при сбое питания, т.к. данные всегда записывают консистентно, а там где это требуется, приложения используют синхронную запись, которая не будет потеряна при сбое питания. Кроме того у вас нужное количество dedup vdev, по этому ваши виртуальные 300ТБ могут увеличиться ещё в несколько раз. По этому, в вашей системе может хранится около 1ПБ данных на хранилище НЖМД объемом в ~100ТБ и если вы всё учли, то это будет работать с удовлетворительной скоростью. И над всем этим великолепием ещё и создаются консистентные снимки, содержимое которых инкрементально передается на другую такую-же систему в соседнем ЦОД. Наверное единственное слабое место этой системы будет в латентности - вот что имеет смысл измерять. Я ещё забыл тут написать про шифрование.
Можно ли построить что-то подобное на других технологиях и не потерять данные? На mdadm + LVM - точно нет. Вы, неизбежно потеряете данные рано или поздно, т.к. нет контрольных сумм и нет транзакционной записи. Причем о потери данных, вы возможно, не узнаете, пока не станет слишком поздно. Я имею в виду, что mdadm как и аппаратные raid-массивы не имеют возможности отличить корректные данные возвращаемые накопителем от данных с ошибками.
zfs - это карьерный самосвал в мире файловых систем. Глупо сравнивать его только по скорости даже с картингом (lvm). Когда говорят, что zfs - быстраф FS, имеется в виду, что вы сможете повесить на неё большую полезную нагрузку, чем на другие варианты организации тех же накопителей при разумном подходе. На деле так и происходит, но этого, к сожалению, не могут выявить синтетические тесты. Наверное, более правильным вариантом тестирования zfs было бы записать профиль некой эталонной нагрузки и попробовать воспроизводить его параллельно увеличивая количество потоков до тех пор пока не будут достигнуты предельные показатели по латентности.
Paul_Arakelyan
24.09.2023 00:50"
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O recordsize=128k" и далее читают кусками по 4К. По части ZFS - cтатья о "Сдуру можно и ... сломать".Для того, чтоб прочитать ваши 4К - нужно прочитать то количество блоков, во что сжали 128К, разжать, выдать ваши 4К из 128К - оверхед огромный по всем частям процесса. Если нужно читать рандом 4К и иметь профит от сжатия - нужно балансировать с размером блока и recordsize. Иногда, наплевав на "рекомендации", делать blocksize 2К при физических 4, и recordsize 8-16K. Чтение невыровненных по recordsize данных - тоже весело, 2х нужно прочитать-распаковать.Короче, ZFS - это не серебрянная пуля, а решение требующее понимания с какими данными и как будут работать.
Ну и полу-холиварный срач по поводу "а шото у меня фря 13 веселее убунты 22 в рандоме работала" (создаём ФС - ext4 на zfs volume, заливаем пачку исходников, один и тот же пул отдаём из фри и линукса, читаем их tar ) - разводить не буду, т.к. настраивать zfs в линуксе - "не начинал".
Dante4 Автор
24.09.2023 00:50Да, как я упоминал - используются настройки по-умолчанию. Также отмечу, что стоит обратить внимание, что я использовал zvol, который читает блоками по 8к (раньше по 4к).
В данной статье нет цели максимально оптимизировать mdadm\lvm\ZFS под конкретные тесты\среду\нагрузку - все настройки являются по-умолчанию. Кроме сжатия для ZFS, но насколько мне известно, доказано многочисленными тестами, что lz4 не оказывается влияния на производительность zvol. Если у Вас есть другая информация - я буду рад её узнать
Про чтение кусками по 4к, 8к, 64к - к сожалению, я не знаком с настройками, которые запретят ОС в виртуализации читать свои данные по 4к, когда они хотят считать 4к.

gudvinr
Вам стоит поработать над графиками и представлением данных, потому что и в первой и во второй статье всё с ними печально.
Например, у вас ни на одном графике не подписана вертикальная ось, и что именно там за попугаи и какое направление (меньше или больше) лучше — не понятно.
Можно было бы сопоставить с данными из таблиц, но таблицы у вас разбросаны по статье и сгруппированы отличным от графиков образом:
в графике к вас идут ФС сгруппированые по тестам, а в таблицах тесты сгруппированые по ФС.
Последовательность изложения тоже довольно непонятная, т.к. нет оглавления или нумерации вложенности (1, 1.2, 1.2.3 и пр.) нет, то очень просто запутаться где заканчивается секция, и начинается подсекция.
В целом конечно данные есть, и из них можно сделать выводы, но статью читать очень сложно, поэтому для этого нужно постараться. Но если вам, как писателю, нужно постараться один раз, то каждый читатель это будет делать снова и снова отдельно.
Dante4 Автор
Спасибо за Ваш комментарий, доработал с точки зрения оформления.
Графики сгруппированы двумя образами, первый по используемому рейду (где заголовок это протокол подключения, а содержимое графика это рейды) и по используемому протоколу (где заголовок это рейд, а содержимое графика это протоколы подключения)