

Если зайти на Papers With Code и посмотреть на лидерборд для image classification на ImageNet (а также различных его вариациях), то можно обнаружить в топ-5 модель с незамысловатым названием model soups.
В этой статье мы разберемся с тем, что это такое, и кратко пробежимся по основным моментам оригинального папера (здесь и далее я буду коверкать слово «paper» именно так).
В двух словах
Понятие «model soup» было предложено в папере 2022 года «Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time», написанном в соавторстве Google Research, Meta AI Research и несколькими университетами.
Для начала вспомним, как выглядит стандартный процесс обучения модели: мы обучаем модель с различными вариациями гиперпараметров, а затем выбираем лучшую из них, измерив качество на evaluation set. После этого все модели, кроме наилучшей, отправляются в корзину.
Авторы папера предлагают отказаться от такого расточительства и найти применение оставшимся моделям. Это можно сделать с помощью ансамблирования, например, бэггинга: усреднять logits всех моделей. Однако в таком случае время инференса ансамбля увеличивается пропорционально количеству вошедших в него моделей.
Идея model soup заключается в том, чтобы усреднять не logits, а непосредственно веса моделей. В этом случае на инференсе мы запускаем лишь одну модель, и время не увеличивается.
Важный момент: model soup будет работать лишь в случае файнтюнинга уже предобученной модели. Если объединить в «суп» модели, обученные с нуля, можно получить абсолютно неадекватное решение. Даже если веса для всех моделей были инициализированы одними и теми же значениями. О том, почему это так, поговорим чуть позже.
Различные рецепты model soups
В папере предлагается три различных рецепта model soups:
uniform soup — тривиальное усреднение весов моделей
:
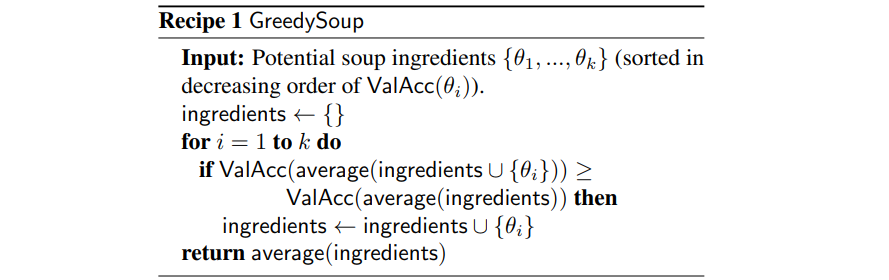
greedy soup — жадный алгоритм, в котором мы добавляем модель в «суп» только в том случае, когда это позволяет увеличить точность:
learned soup — усреднение весов моделей с выученными коэффициентами
(
— функция потерь,
— evaluation set,
— коэффициент калибровки)
Сравнение с ансамблями
Авторы приводят результаты тестирования бэггинга и различных рецептов «супов» при файнтюнинге модели CLIP ViT-B/32 на ImageNet. Accuracy оценивается как на тестовой выборке самого ImageNet, так и на distribution shift датасетах — ImageNet-V2, ImageNet-R, ImageNet-Sketch, ObjectNet, ImageNet-A.
.")
Из таблицы выше видно, что «супы» сопоставимы с ансамблями по accuracy на ImageNet и даже имеют преимущество на distribution shifts датасетах. При этом, как было упомянуто ранее, сложность model soup не зависит от количества вошедших в «суп» моделей, тем временем как для ансамбля мы имеем дело с линейной зависимостью .
Схожие результаты были получены и при файнтюнинге на ImageNet ViT-G/14, предобученного на JFT-3B:

Однако в обоих примерах выше модели предобучены на больших датасетах. И авторы показывают, что это влияет на прирост accuracy, получаемый с помощью техники model soup. Так, для предобученной на ImageNet-22k модели, model soup даёт уже не столь значительный прирост accuracy.
Помимо классификации изображений, авторы также исследовали применимость model soup к решению задач классификации текстов на примере 4 задач из бенчмарка GLUE: MRPC, RTE, CoLA и SST-2:

Если вам не хватило исследований выше, вы можете найти больше результатов в оригинальной статье.
Почему это вообще работает?
Функции потерь нейронных сетей не являются выпуклыми, и при их минимизации решение может сходиться к разным локальным минимумам. Так почему же усреднение весов в случае файнтюнинга приводит к адекватному решению? Ответ кроется в папере Google 2020 года «What is being transferred in transfer learning?». Его авторы приходят к выводу, что при файнтюнинге предобученных моделей решения всех моделей остаются в окрестности одного и того же локального минимума (авторы называют её «basin» — «впадина»). В то же время модели, обученные с нуля, даже если они инициализированы одинаково, таким свойством не обладают.
Вдохновившись этим открытием, авторы model soup исследуют форму поверхности loss-функции и приходят к выводу, что среднее нескольких решений может лежать ближе к минимуму loss-функции, чем каждое из решений по отдельности.
На изображении ниже приведен 2D-срез training loss и поверхности test error. Символом![]() обозначена предобученная модель, а символами
обозначена предобученная модель, а символами ![]() ,
,![]() ,
,![]() — полученные из неё с помощью файнтюнинга модели. Из графика видно, что среднее двух решений, полученных с помощью файнтюнинга, может находиться ближе к минимуму функции.
— полученные из неё с помощью файнтюнинга модели. Из графика видно, что среднее двух решений, полученных с помощью файнтюнинга, может находиться ближе к минимуму функции.
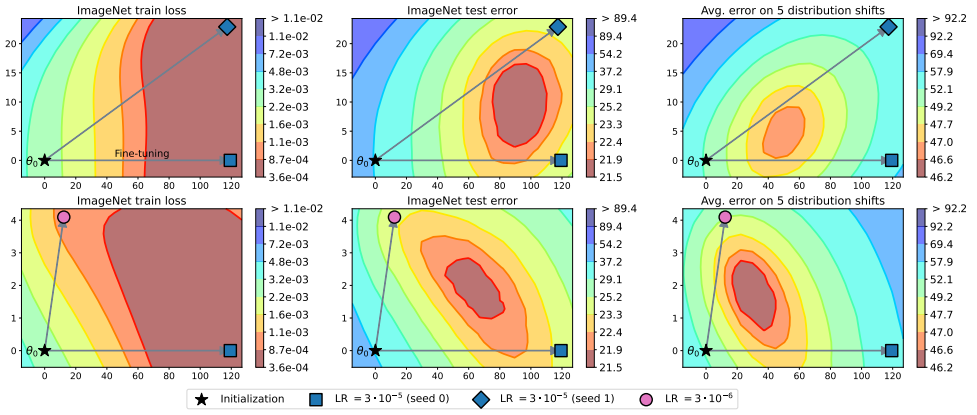
Однако стоит отметить, что при выборе слишком большого learning rate при файнтюнинге модели могут выходить за пределы одной «впадины». Поэтому при использовании model soup стоит использовать умеренный learning rate.
Также можно заметить, что угол между решениями (обозначенный серыми стрелками на изображении выше) может влиять на точность среднего. Авторы предоставляют отдельное исследование данной зависимости и приходят к выводу, что чем ближе этот угол к 90°, тем больший выигрыш мы получаем при усреднении решений:

В свою очередь на угол между решениями влияет то, какой гиперпараметр мы изменяем. На изображении выше видно, как влияет изменение random seed, learning rate и аугментаций.
Напоследок
В 2023 году вышла ещё одна статья, посвященная model soups: «Model soups to increase inference without increasing compute time». В ней авторы сравнивают model soups, построенные на основе трёх разных архитектур — ResNet, EfficientNet и ViT-G. Однако ResNet и EfficientNet модели они обучают с нуля, что ожидаемо ведёт к получению неадекватного model soup решения. Разумеется, такое сравнение архитектур нельзя считать корректным.
В то же время было бы действительно любопытно проверить, как ведут себя model soups в контексте сверточных моделей. Возможно, это тема для следующей статьи на Хабре?
Kwent
Спасибо за статью, кажется, это уже изобретали раньше под названием SWA :) там как раз идея что сперва учим норм, а в конце "немного шатаем" и усредняем веса полученных шатаний, чтобы не заботиться об одинаковом претрейне и правильном подборе lr