
Исследовать поисковый спрос — обычная задача для SEO-специалиста: просто собираешь запросы и их частотность, смотришь сезонность и делаешь выводы. Но что если нужно исследовать целую сферу бизнеса типа авторынка, на котором представлено очень много брендов, а сроки и ресурсы ограничены? Включаем воображение и расширяем инструментарий. Делюсь своим хитрым способом.
Я Женя Кузнецов, диджитал-стратег. В рамках рабочей задачи мы с коллегами исследуем китайский авторынок в РФ, и анализ поискового спроса — часть этой работы. Я решил распарсить Вордстат за два года и собрать список всех брендов с интентами и сезонностью, а потом визуализировать в BI, чтобы увидеть наглядную динамику и тренды. Расскажу пошагово.

1. Собрираем список брендов и синонимов
В Google-таблицах я составил список всех китайских брендов, представленных на рынке и хоть сколько-нибудь известные бренды из других стран для сравнения. Включил названия на английском и на русском.
Обычно пользователи ищут по русской транскрипции, но таких словоформ может быть несколько. Если к «европейцам» все уже привыкли, то с «китайцами» сложнее — чего стоит написать бренд KAIYI по-русски. Я придумывал словоформы сам и с помощью поисковых подсказок Яндекса, а потом в Вордстате проверял, пишут ли так пользователи.


2. Собираем список интентов
К собранным брендам нужны были интенты, чтобы можно было увидеть поисковые цели и сравнивать их между собой. За определением интентов я пошел в SpyWords (кстати, он доступен бесплатно, если у вас есть тариф «Оптимум» в Elama). Здесь можно посмотреть, по каким группам фраз в поиске находятся официальные сайты брендов.
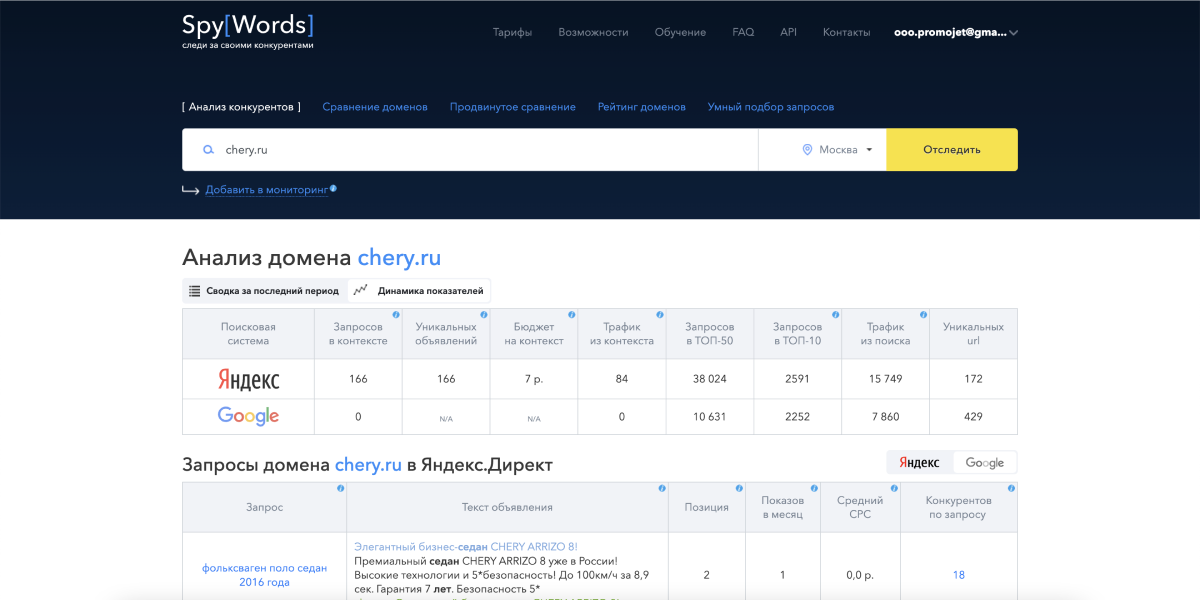

Tip: эту же задачу можно решить еще так — выгружаете все фразы по одному бренду из Вордстата, кластеризуете их с помощью сервиса Разбивака и анализируете получившиеся группы.
Так мы получили список поисковых интентов:
официальный сайт,
официальный дилер,
модельный ряд,
комплектации,
цена,
купить,
кредит,
лизинг,
рассрочка,
отзывы,
обзор,
тест драйв,
сервис.
3. Перемножаем два списка поэлементно
Чтобы получить «оценку сверху» по всем кластерам запросов для каждого бренда, нужно было добавить интенты к списку всех брендов.
Есть два способа сделать это:
Вручную — сразу в Google-таблицах. Записываем все бренды в первую колонку, а интенты в первую строку таблицы и перемножаем. Но, чтобы получить список всех брендов в табличном виде, придется проделать много монотонной работы.
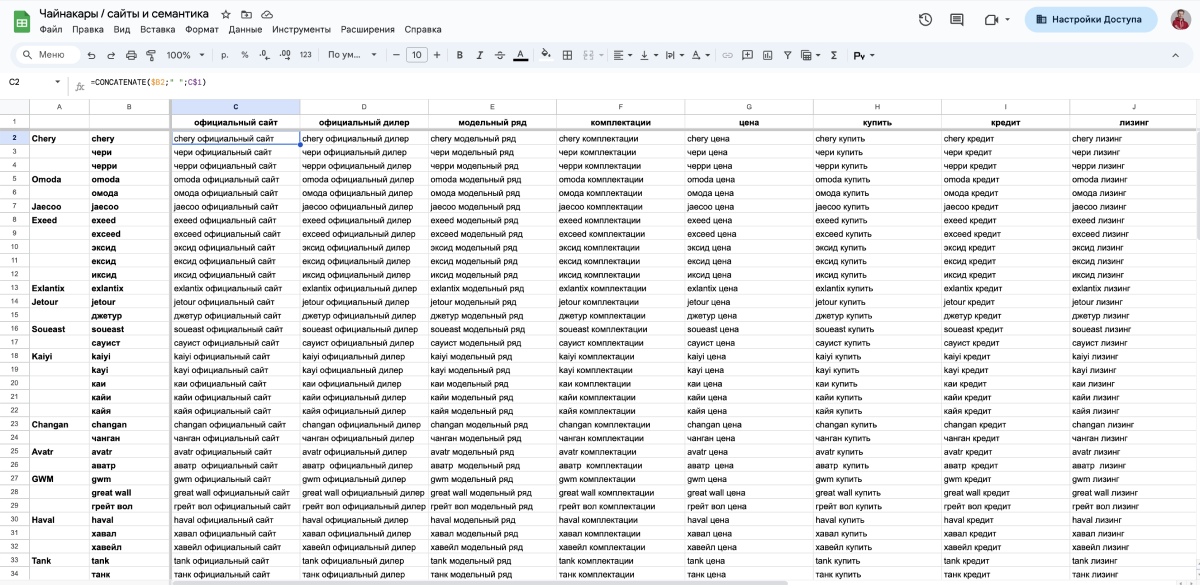
Автоматически — с помощью простого цикла на Python и библиотеки gspread. Спойлер: так гораздо быстрее.
1) Открываем таблицу, получаем содержимое и сохраняем в Data Frame.

2) Генерируем список ключевых фраз, перемножая список брендов со списком интентов.
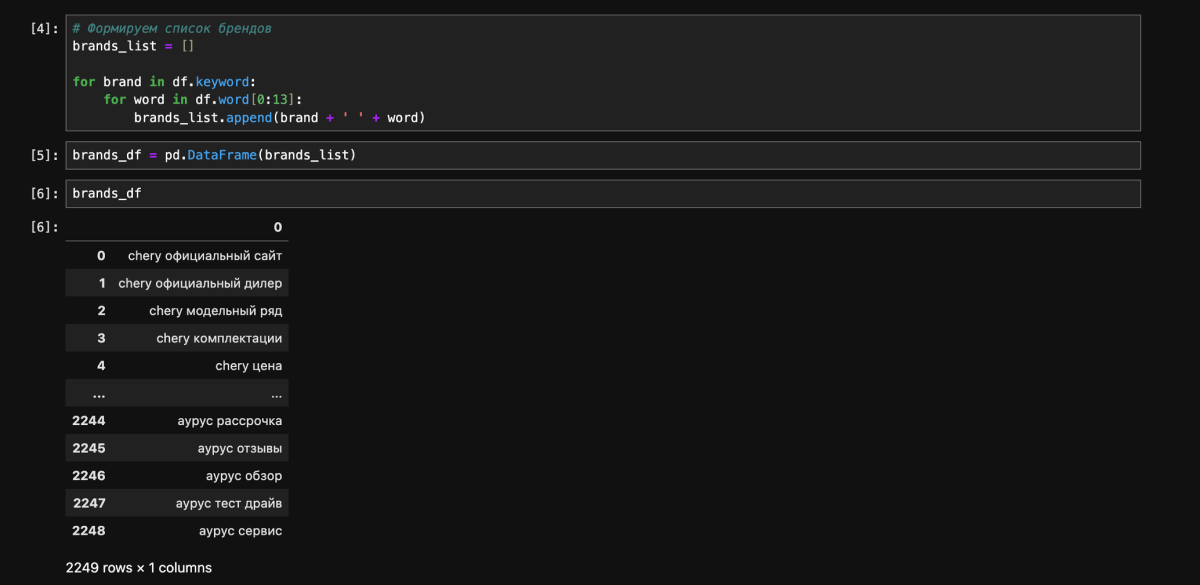
4. Получаем примерную семантику
Вместо 100+ запросов, получилось 2000+ запросов без лишнего сбора и кластеризации семантики.
5. Собираем частоты и сезонности
Я загрузил запросы в KeyCollector и запустил парсинг сезонности. На сбор данных ушло примерно 4–5 часов.
Дополнительно для удобства разложил все фразы на группы — при выгрузке группа добавляется в отдельную колонку, что позволяет объединить словоформы в группы по брендам. Эту же задачу можно решить при обработке на Python — примеры дальше.
На выходе получил CSV-файл со списком запросов и популярностью по месяцам.
6. Обрабатываем данные
Ручная предобработка данных заняла бы очень много времени, поэтому я снова воспользовался Python.
1) Загрузил данные в Data Frame и сделал таблицу вертикально ориентированной при помощи метода .melt.
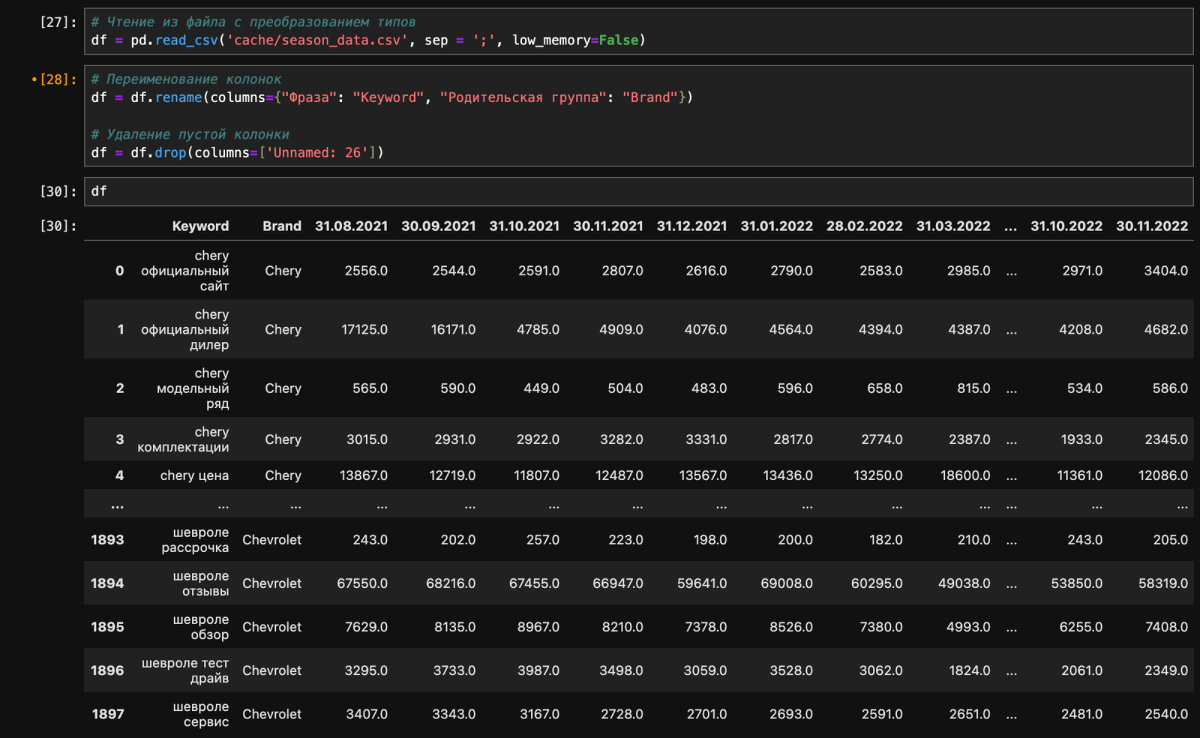

2) Привел даты в формат yyyy-mm-dd при помощи метода .to_datetime.

3) Составил список соответствий в формате «Часть фразы — интент», чтобы объединить в группы фразы типа «… цена» и «…купить».
4) Обработал дата-фрейм с помощью метода .map. После этого появилась колонка с поисковыми интентами.
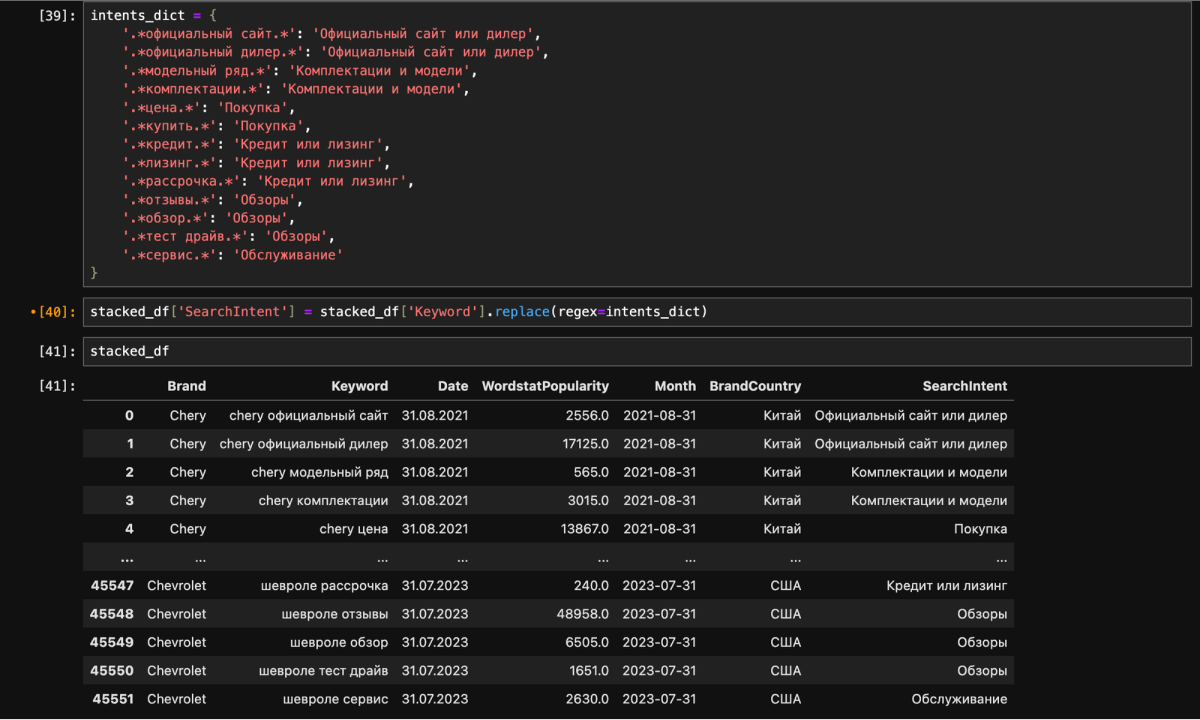
5) Составил словарь соответствий бренд — страна, чтобы добавить страны бренда ко всем запросам.

6) Обработал дата-фрейм с помощью метода .map.

В моем примере в дата-фрейме уже есть список всех брендов, поскольку я разбил фразы на группы в интерфейсе KeyCollector, однако эту же задачу можно решить с помощью Python по аналогии с обработкой поисковых интентов, описанной выше.

Итого, получилась таблица со следующими параметрами:

7. Выгружаем данные в ClickHouse
Эту таблицу можно было бы сохранить в CSV или Google Sheets. Но я выбрал третий вариант — через ClickHouse.
1) Подключился к базе. Использовал библиотеку из справки Яндекса — в ней уже есть функции для записи и чтения.
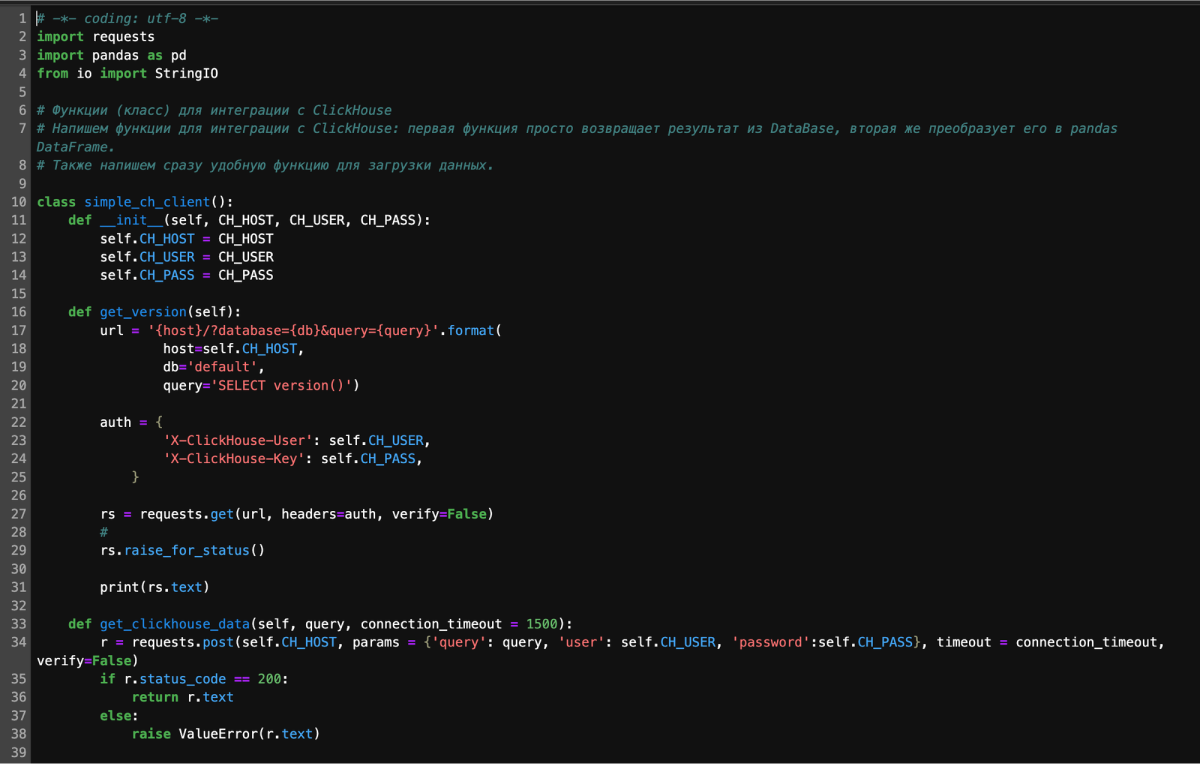

2) Создал таблицу заново, указав типы данных. Записал туда наш DataFrame.
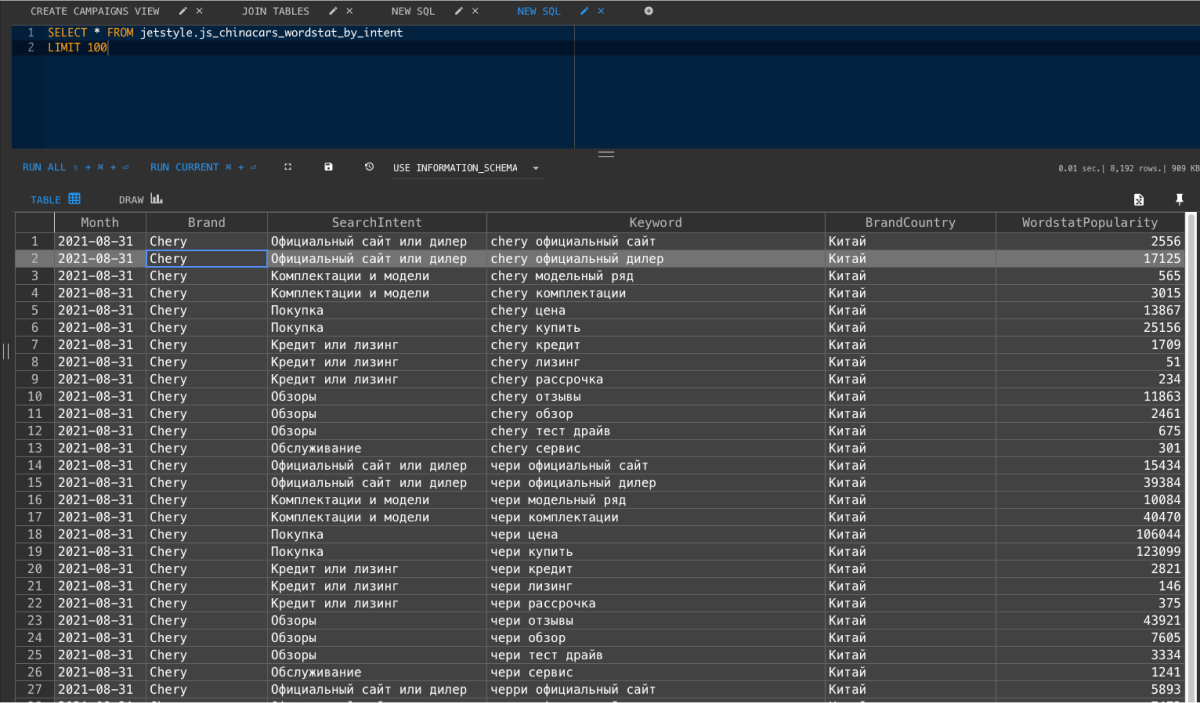
8. Строим чарты
Используя Data Lens, подключился к базе и построили необходимые чарты.

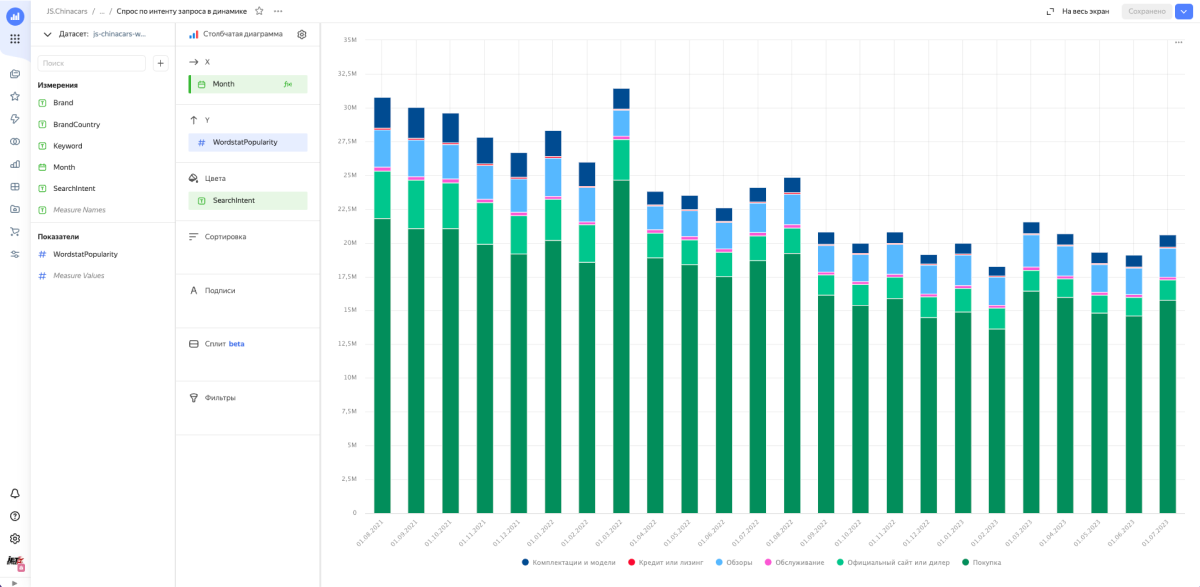
Собранные чарты мы объединили в дашборд и добавили туда фильтры.

Дата-аналитикам на заметку
Так за восемь не очень простых, но экономящих время шагов получилась наглядная визуализация того, что происходит со спросом на автомобильном рынке в разрезе по бренду, стране бренда и поисковому интенту в динамике.
А помог в этом набор стандартных инструментов:
KeyCollector — с его помощью можно легко и быстро собирать запросы и сезонности. К нему нужен аккаунт Яндекс Директ и proxy.
Google-таблицы: в них можно складывать результаты и визуализировать с помощью простеньких графиков.
И продвинутых средств:
Python и библиотека Pandas — можно автоматизировать некоторые рутинные задачи.
ClickHouse — место, куда можно удобно сложить собранные данные. Можно остаться и в Google-таблицах, но ClickHouse надежнее и с заделом на будущее.
Yandex Data Lens — BI-инструмент от Яндекса, в котором можно построить продвинутую визуализацию данных.
Экспериментируйте — и тогда вы сможете решать сложные задачи быстро!
Prion
Непонятно зачем подключали к Кликхауз и ДатаЛенз, если бы можно сделать визуализацию в том же Jupyter. У Jupyter достаточно библиотек по визуализации (seaborn например) и с самими данными работает прекрасно, включая работу с SQL. У меня большие сомнения, что кто то будет использовать отчет многократно и вряд ли нужен интерактив для сторонних пользователей.
simplicityworks Автор
1. Почему DataLens и интерактив: просто потому что это часть экшн-плана с плакатом, подготовкой исследования и активностями на выставке. Да, для одиночного отчета лучше подойдет аналитика в Python/Excel/и т.д., но как added-value на лендинге интерактив в DataLens смотрится гораздо выигрышнее для конечного потребителя (маркетолога у автодилера/дистрибьютора). Плюс эту историю можно развивать в разные стороны и заготовка в виде БД + Дашборда про который знают игроки на рынке — отличное начало;
2. Почему Clickhouse: можно было сделать в юпитере, можно было подключить гугл таблицы к DataLens/LookerStudio/Другой bi-системе, можно было использовать любую другую БД, которая справится с такой задачей и имеет коннектор к BI-системе. Просто это то решение с которым активно работаю для выгрузок из LogsAPI метрики и почему-бы не воспользоваться той же СУБД, раз она уже развернута на VDS. С гугл таблицами было бы проще, но в долгосрочной перспективе работать с базой надежнее и проще мигрировать;
3. Многократное использование: обратная связь от рынка говорит об обратном;
simplicityworks Автор
Не уверен, можно ли постить ссылки (в статье пришлось все их удалить), но потыкаться в дашборд можно тут.