
Привет, Хабр! Меня зовут Сергей Баширов, я ведущий разработчик в Cloud.ru. Наша команда RnD занимается исследованиями и оптимизацией баз данных, файловых систем, объектных хранилищ, СХД и SDS в облачной инфраструктуре. И мы решили «импортозаместить в лучших традициях» pNFS. За дело взялись вместе с моим коллегой — Константином Евтушенко (@kevtushx).
К сожалению менеджеров и на радость нам, годной инструкции по настройке в интернете не оказалось. Софт с открытым исходным кодом из коробки не завелся: пришлось погружаться в детали, отлаживать и чинить. В статье расскажу, как всё было, какие ошибки и выводы мы сделали, а также поделюсь подробной инструкцией по настройке стенда с блочным типом доступа к серверам данных. Если интересно — добро пожаловать под кат!

За годы существования файловая система NFS обросла кучей стандартов и имеет множество реализаций. Как облачного провайдера, нас интересовал ее параллельный вариант и возможность применения на нашей инфраструктуре. Поэтому решили мы попробовать «импортозаместить» pNFS — свой SDS в компании имеется, почему бы и нет? Так возникла исследовательская задача: собрать из подручных средств стенд-прототип и по-быстрому измерить возможную производительность подобной системы.
Отмечу, что на тот момент в ядре Linux были проблемы, из-за которых даже правильно настроенный стенд иногда мог просто не работать. Истории о поиске и устранении этих недоработок будет посвящена отдельная статья. А пока расскажу, с чего мы начинали.
Изучаем особенности pNFS
Cначала мы, конечно, изучили всю теорию и выяснили принципиально важные для нас моменты.
Во-первых, в стандарте NFS 4.1 есть полезное нововведение — опциональный режим работы parallel NFS. Его главная идея заключается в разделении потоков данных и метаданных, что позволяет масштабировать серверы, на которых хранятся данные. Как это работает?
Для некоторой части пространства имен файловой системы всегда есть ровно один активный сервер метаданных — MDS, а также множество DS — серверов данных. Клиенты файловой системы подключаются к MDS, проходят аутентификацию, монтируют корневой каталог, выполняют поиск, открывают файлы и т. д. В pNFS все эти процессы очень похожи на обычный NFS. Но для доступа к блокам данных клиент запрашивает у MDS схему размещения файла на DS-серверах, а затем выполняет чтение или запись, коммуницируя напрямую с DS-серверами. Благодаря этому и должно происходить горизонтальное масштабирование потока данных.
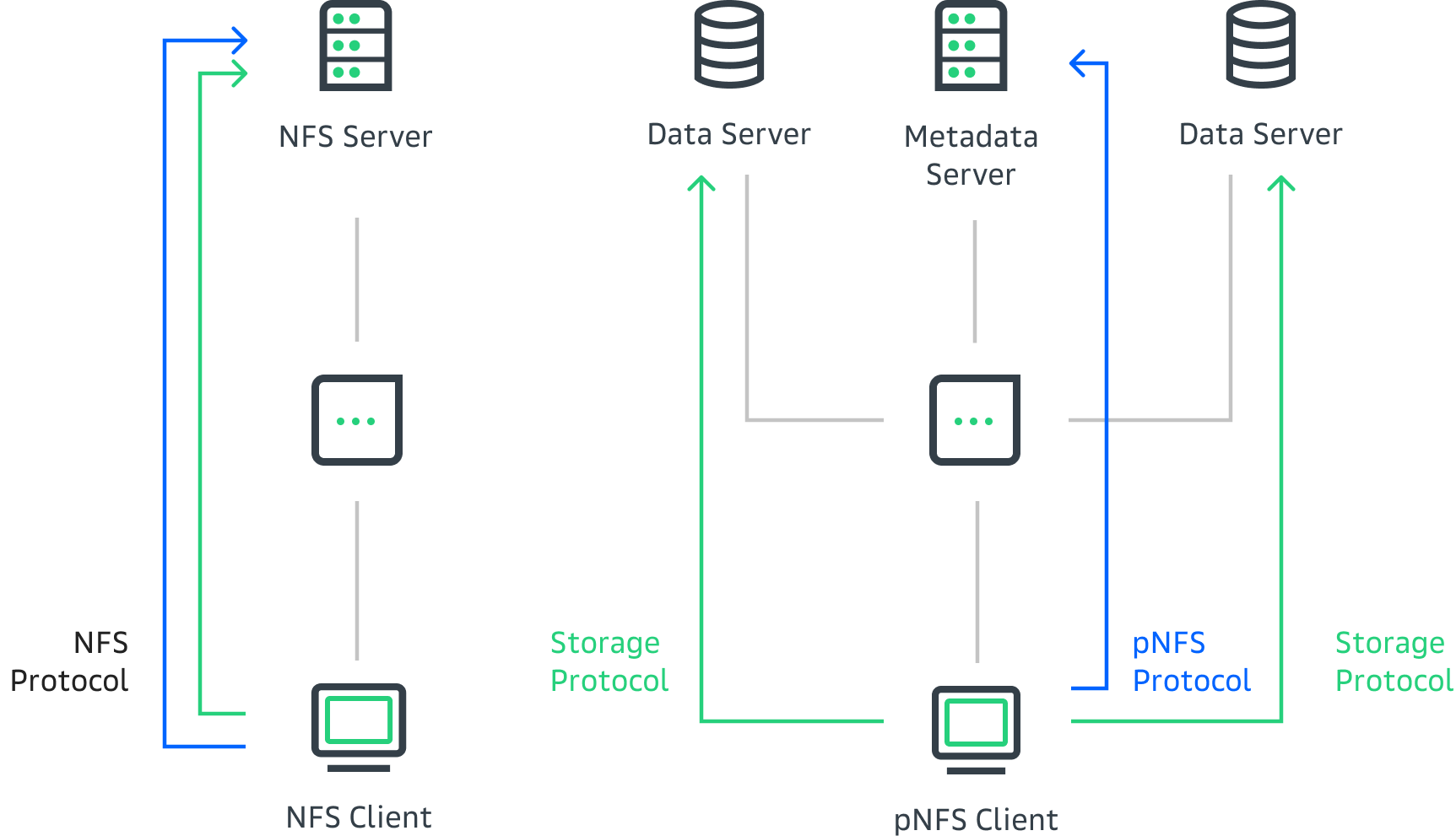
Второй принципиально важный момент касался правил размещения файлов на DS. pNFS оперирует понятием layout — по сути это схема размещения блоков данных файла на одном или нескольких DS. Потенциально возможно множество различных типов layout, но для RFC-5661, RFC-7862, RFC-8154 и RFC-8435 работают следующие основные стандарты:
NFSv4.1 Files — файловый доступ к данным, чередование данных между несколькими DS по протоколу NFS4.1;
OSD2 Objects — хранение файлов на объектных хранилищах OSD;
Block Volume — хранение данных на удаленных блочных устройствах, возможно объединение или чередование нескольких устройств;
Block SCSI — хранение данных на iSCSI устройствах, возможно объединение или чередование нескольких устройств;
Flexible Files — файловый доступ к данным на нескольких DS по протоколам NFSv3, NFSv4, NFSv4.1, NFSv4.2 (файл клиента представляется как один или несколько файлов на DS), поддерживается зеркалирование или чередование.
Ищем подходящие решения
В ходе подготовки мы изучили разные варианты уже готовых решений, некоторые из которых показались нам действительно интересными. Ниже сделали краткий обзор их возможностей и особенностей.
Проприетарные решения:
Clustered NFS (CNFS) — это вариант компании IBM, который они используют поверх своей кластерной файловой системы GPFS. В этом случае NFS-сервис фактически становится одним из способов доступа к GPFS и имеет с ней интеграцию.
NetApp ONTAP — решение поддерживает pNFS и layout типа NFSv4.1 Files, т. е. файловый доступ к серверам данных. По отзывам коллег он показывает хорошую скорость. Однако бывали ситуации, когда один из клиентов при чтении получал устаревшие данные из кеша. В техническом отчете TR-4067 «NFS in NetApp ONTAP» за 2021 год пишут, что изредка можно наткнуться на баг. Например, получить испорченные данные. Рекомендуют обновляться до последних версий.
pNFS в Dell EMC VNX — поддерживает только layout типа Block SCSI, т. е. блочный доступ к iSCSI-дискам. Для дисков подключенных через Fibre Channel используется мост iSCSI-to-FibreChannel.
Решения с открытым исходным кодом:
Первое open source решение, которое привлекло наше внимание — это user-space сервер NFS Ganesha. Он имеет реализацию pNFS для некоторых распределенных файловых систем, например, Ceph и Gluster. Из особенностей — поддерживаются файловые и объектные типы layout, однако документация проекта честно сообщает, что направление pNFS в комьюнити сейчас подзаброшено.
В NFS-сервере ядра FreeBSD поддерживаются оба типа файловых layout — Flexible Files и NFSv4.1 Files. Настраивать и запускать его мы не пробовали, поскольку нас интересовал только layout типа Block Volume.
Сервер NFS ядра Linux — решение, которое имеет реализацию layout следующих типов: Flexible Files, Block Volume и Block SCSI. При этом часть функционала реализована не полностью. Например, блочные типы layout могут экспортировать директории только для файловой системы XFS. Кроме того, не поддерживаются таблицы разделов на диске, логические разделы, а также объединение или чередование нескольких дисков. В реализации Flexible Files есть лишь минимальный функционал для разработки и тестирования кода клиента: один и тот же сервер выступает как в роли DS, так и в роли MDS.
Таким образом, все проприетарные решения используют собственную реализацию сервера, но поддерживают работоспособность открытого клиента на Linux. А вот серверы с открытым исходным кодом уже требуют значительных доработок.
Почему выбрали Block Volume Layout
У нас в Cloud.ru есть свой шустрый SDS, который умеет раздавать виртуальным машинам удаленные диски как устройства vhost-user-blk-pci. Так что после изучения теории по pNFS мы остановились на Block Volume Layout, а в качестве сервера для экспериментального стенда выбрали линуксовый nfsd. С точки зрения архитектуры эта комбинация выглядела привлекательно: в ней серверами данных (в терминологии pNFS) становились сервисы удаленных дисков SDS и оставалось только добавить в систему MDS.
Что касается ограничений реализации сервера в Linux, то тут препятствий для нас не было. Отсутствие поддержки таблиц разделов компенсировалось гибкостью облака: вместо того чтобы делать несколько логических разделов на одном диске, можно просто создать несколько дисков. Их объединение также не имеет особого смысла, поскольку объем виртуального диска можно увеличивать, а чередование и отказоустойчивость в облаке уже есть.
Как же работает блочный layout под капотом? Самое интересное здесь — это механизм доступа к данным файла. Вместо методов READ и WRITE, как в обычном NFS, клиент использует методы LAYOUTGET, LAYOUTCOMMIT и LAYOUTRETURN для работы с экстентами файла на MDS. А для доступа к самим данным пишет прямо на общее удаленное блочное устройство.
На уровне протокола RPC между клиентами и сервером метаданных файлы являются списками экстентов. Каждый экстент может быть в одном из нескольких состояний, определяющих допустимые над ним операции:
enum pnfs_block_extent_state {
// Данные валидны для чтения и записи
PNFS_BLOCK_READ_WRITE_DATA = 0,
// Данные валидны только для чтения
PNFS_BLOCK_READ_DATA = 1,
// Расположение на диске валидно, но содержит мусор, это новый экстент
PNFS_BLOCK_INVALID_DATA = 2,
// Расположение на диске не валидно, это дырка в файле
PNFS_BLOCK_NONE_DATA = 3,
};
struct pnfs_block_extent {
uint8_t volume_id[16];
uint64_t file_offset;
uint64_t length;
uint64_t storage_offset;
enum pnfs_block_extent_state state;
};
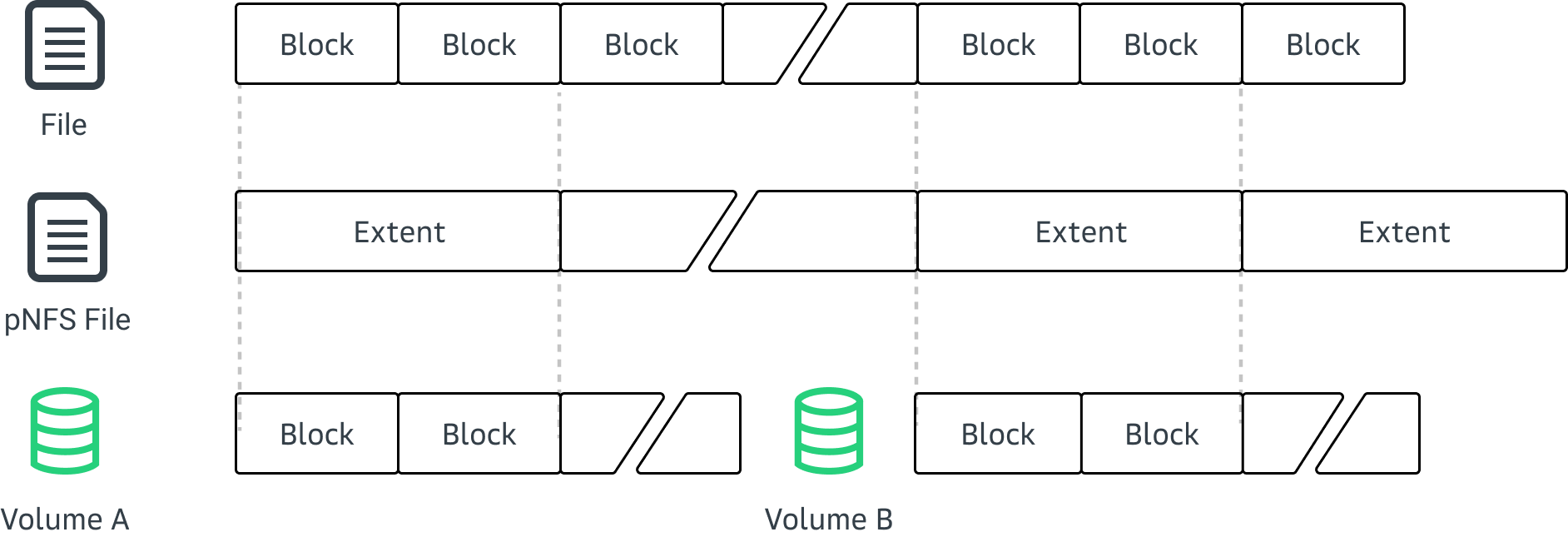
С помощью LAYOUTGET клиент получает список экстентов у MDS для открытого файла, а также право читать и писать в них. Обязательными параметрами в запросе идут смещение, желаемая длина и минимальная длина. Так же можно указать режим доступа для чтения и записи или только для чтения. В результате успешного выполнения запроса клиенту возвращается список экстентов файла. Первый экстент обязательно содержит запрошенное смещение, а все экстенты вместе покрывают непрерывный логический диапазон файла.
Изменения в файле, которые вносит клиент, нужно подтвердить запросом LAYOUTCOMMIT. Для sparse-файлов можно добавлять новые экстенты с данными вместо дырок. А используя параметр запроса last write offset, клиент может сообщить MDS об увеличении размера файла.
Вызовом LAYOUTRETURN клиент сообщает MDS о завершении работы с полученными экстентами для некоторой части или всего файла (либо всех открытых этим клиентом файлов).
Получается, что клиент взаимодействует с уже существующим файлом по следующей схеме:
Получает дескриптор файла вызовом LOOKUP на MDS.
Открывает связанный с дескриптором файл вызовом OPEN на MDS.
Получает схему размещения данных – LAYOUTGET на MDS.
Читает и пишет данные прямо на DS (удаленный диск).
Фиксирует изменения с помощью LAYOUTCOMMIT на MDS.
Отпускает экстенты файла вызовом LAYOUTRETURN на MDS.
Использует метод CLOSE на MDS, чтобы закрыть файл.
Плюсы и минусы блочного варианта pNFS
Как и любое другое решение, Block Volume Layout имеет свои преимущества и недостатки.
Плюсы:
разделение потоков данных и метаданных позволяет получить масштабирование работы с файлами;
тонкий программный стек без лишних абстракций между клиентами и удаленным блочным устройством.
Минусы:
баги в драйвере на клиенте могут приводить к повреждению чужих данных или даже всей файловой системы;
пользователь с правами администратора на клиентской машине может получить данные со всего диска.
Применительно к облачной инфраструктуре, перечисленные минусы не настолько фатальны. Отсутствие изоляции клиентов можно решить так: каждому пользователю сервиса создается свой pNFS на отдельном виртуальном диске и отдельной виртуальной машине для MDS. Дополнительную подстраховку можно организовать с помощью снапшотов общего диска и автоматических бэкапов.
Измеряем производительность: нюансы
Для оценки производительности блочных устройств и файловых систем мы использовали FIO — достаточно гибкий инструмент в плане тонкой настройки большого количества параметров тестирования.
Первоначально пытались завести pNFS версии 4.1. Для грубой прикидки решили оценить пропускную способность случайной записи большими блоками. Соответственно, команда запуска FIO была следующего вида:
fio ... --rw=randwrite --ioengine=libaio --direct=1 --size=10G --blocksize=128K --iodepth=256
Результат оказался плачевным — меньше сотни мегабайт в секунду на all-flash хранилище. При этом после повторного запуска FIO с теми же параметрами производительность превзошла все наши ожидания и была такой, как хотелось.
После эксперимента с запусками в одном и том же файле, а также в разных файлах, стало понятно — жутко тормозит создание новых файлов. Первичный анализ навел на мысль, что проблема может быть в sparse-представлении. Ведь под капотом pNFS у нас XFS, а значит новый файл — по умолчанию одна большая дырка. А в процессе измерения производительности происходит реальная аллокация экстентов перед каждой записью. Стало очевидно, что нужен костыль в виде опции fallocate для обхода. Поэтому запустили новый прогон с дополнительным флагом:
fio ... --rw=randwrite --ioengine=libaio --direct=1 --size=10G --blocksize=128K --iodepth=256 --fallocate=posix
Проверка подтвердила предположение и открыла еще один нюанс: сама пропускная способность была отличной, а вот предварительная аллокация файла с помощью fallocate работала крайне медленно. По ощущениям примерно столько же, сколько и прогон в новом файле без преаллокации. Запуск через strace показал, что для pNFS версии 4.1 нет реализации fallocate в ядре Linux:
newfstatat(AT_FDCWD, "/mnt/nfs/fio01.raw", 0x7ffc21e9feb0, 0) = -1 ENOENT (No such file or directory)
write(1, "seq_write: Laying out IO file (1"..., 49seq_write: Laying out IO file (1 file / 1024MiB)
) = 49
unlink("/mnt/nfs/fio01.raw") = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/mnt/nfs/fio01.raw", O_WRONLY|O_CREAT, 0644) = 6
fallocate(6, 0, 0, 1073741824) = -1 EOPNOTSUPP (Operation not supported)
fadvise64(6, 0, 1073741824, POSIX_FADV_DONTNEED) = 0
close(6) = 0
Решили, раз ядро не выделяет место на диске под файл, скорее всего, это делает glibc. Поиск по сорцам быстро дал результат: если системный вызов fallocate не поддерживается, то исполняется fallback-реализация в самой библиотеке C. Суть этой реализации в том, что для каждого 4 КБ блока в файле происходит запись одного нулевого байта. Таким образом круг замкнулся, и мы вернулись к проблеме медленной записи новых файлов.
Фрагмент реализации posix_fallocate в glibc
int
posix_fallocate (int fd, __off_t offset, __off_t len)
{
struct stat64 st;
...
/* Minimize data transfer for network file systems, by issuing
single-byte write requests spaced by the file system block size.
(Most local file systems have fallocate support, so this fallback
code is not used there.) */
unsigned increment;
{
struct statfs64 f;
if (__fstatfs64 (fd, &f) != 0)
return errno;
if (f.f_bsize == 0)
increment = 512;
else if (f.f_bsize < 4096)
increment = f.f_bsize;
else
/* NFS does not propagate the block size of the underlying
storage and may report a much larger value which would still
leave holes after the loop below, so we cap the increment at
4096. */
increment = 4096;
}
/* Write a null byte to every block. This is racy; we currently
lack a better option. Compare-and-swap against a file mapping
might additional local races, but requires interposition of a
signal handler to catch SIGBUS. */
for (offset += (len - 1) % increment; len > 0; offset += increment)
{
len -= increment;
if (offset < st.st_size)
{
unsigned char c;
ssize_t rsize = __pread (fd, &c, 1, offset);
if (rsize < 0)
return errno;
/* If there is a non-zero byte, the block must have been
allocated already. */
else if (rsize == 1 && c != 0)
continue;
}
if (__pwrite (fd, "", 1, offset) != 1)
return errno;
}
return 0;
}
Деваться было некуда, пришлось расчехлять Wireshark и смотреть на RPC. Благо протокол NFS поддерживается там из коробки.
Когда отфильтровали трафик по типу, в глаза бросилось подозрительно большое число запросов LAYOUTGET. Поэтому к аргументам FIO добавили еще одну опцию --debug=io, чтобы видеть оффсеты, по которым идут записи в файле. Стандарт NFS версии 4.1 на одном экране, трасса Wireshark на другом.
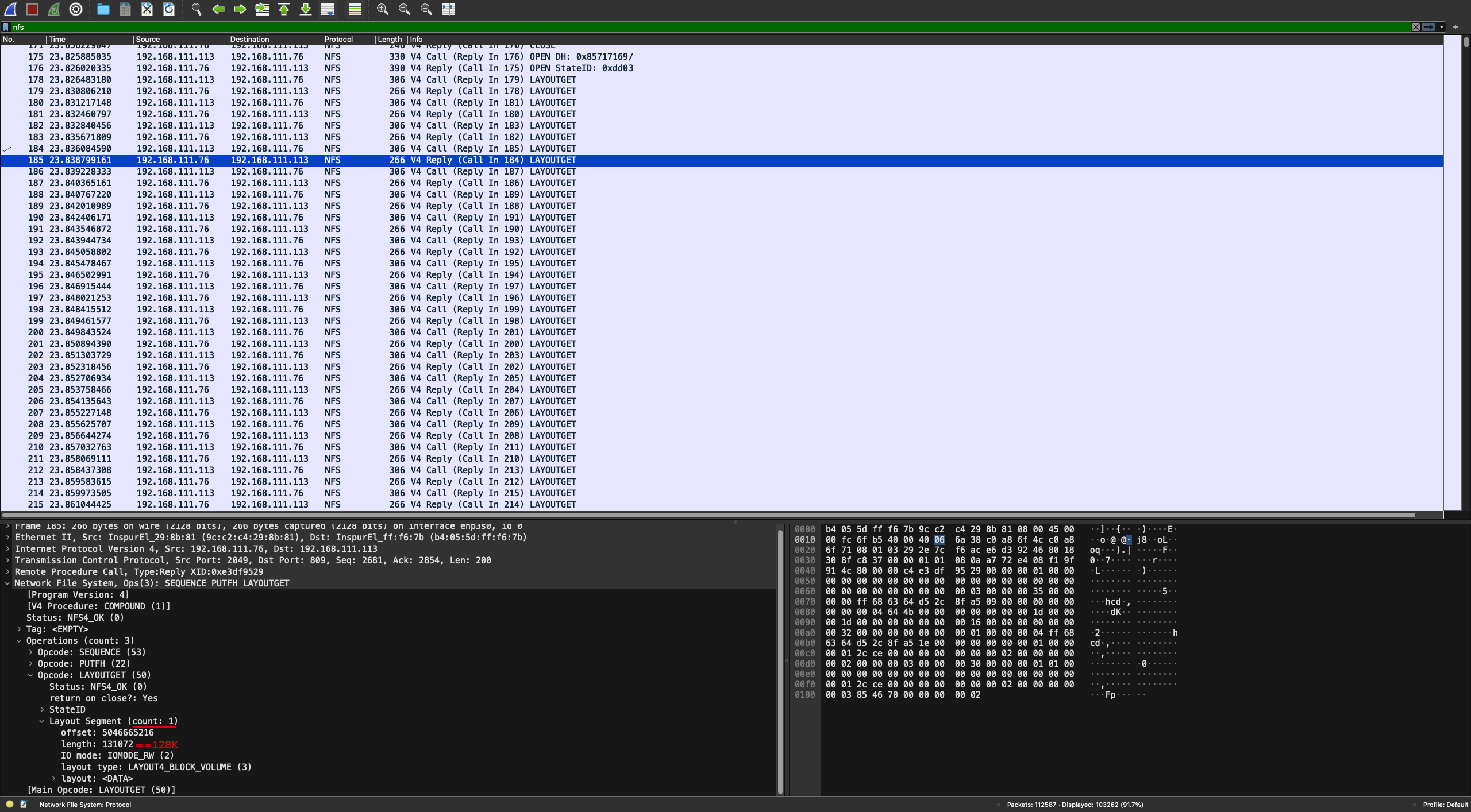
Разбор RPC-запросов клиента показал, что LAYOUTGET вызывался для каждого адреса, по которому писал FIO. То есть наше предположение про sparse-файлы было верным. А это, по сути, убивало смысл параллельности в pNFS, ведь каждая операция происходила с участием MDS. Более того, количество RPC-запросов к MDS оказалось очень большим и сильно замедляло работу системы. При дальнейшем изучении стандарта мы выявили, что это проблема самого стандарта: он не учитывает особенности работы со sparse-файлами.
Поэтому следующим шагом мы изучили стандарт NFS версии 4.2 на предмет изменений относительно версии 4.1. Буквально в самом начале документа нашли перечень, в который входила работа со sparse-файлами и резервирование места. Узнали, что появился новый RPC-вызов ALLOCATE, который умеет выделять место на диске под весь файл или его часть. Его-то и попробовали поискать в исходном коде сервера. К счастью, в nfsd уже реализована поддержка этого метода, оставалось использовать в настройках протокол NFS версии 4.2.
Переконфигурировали сервер и сделали еще один прогон с Wireshark, чтобы увидеть разницу. Результат оказался отличный: количество RPC для работы с одним файлом маленькое, общий трафик на MDS меньше мегабита, загрузка процессора и памяти на MDS низкая. Кроме того, пропускная способность ввода-вывода в файл близка к возможностям удаленного блочного устройства.
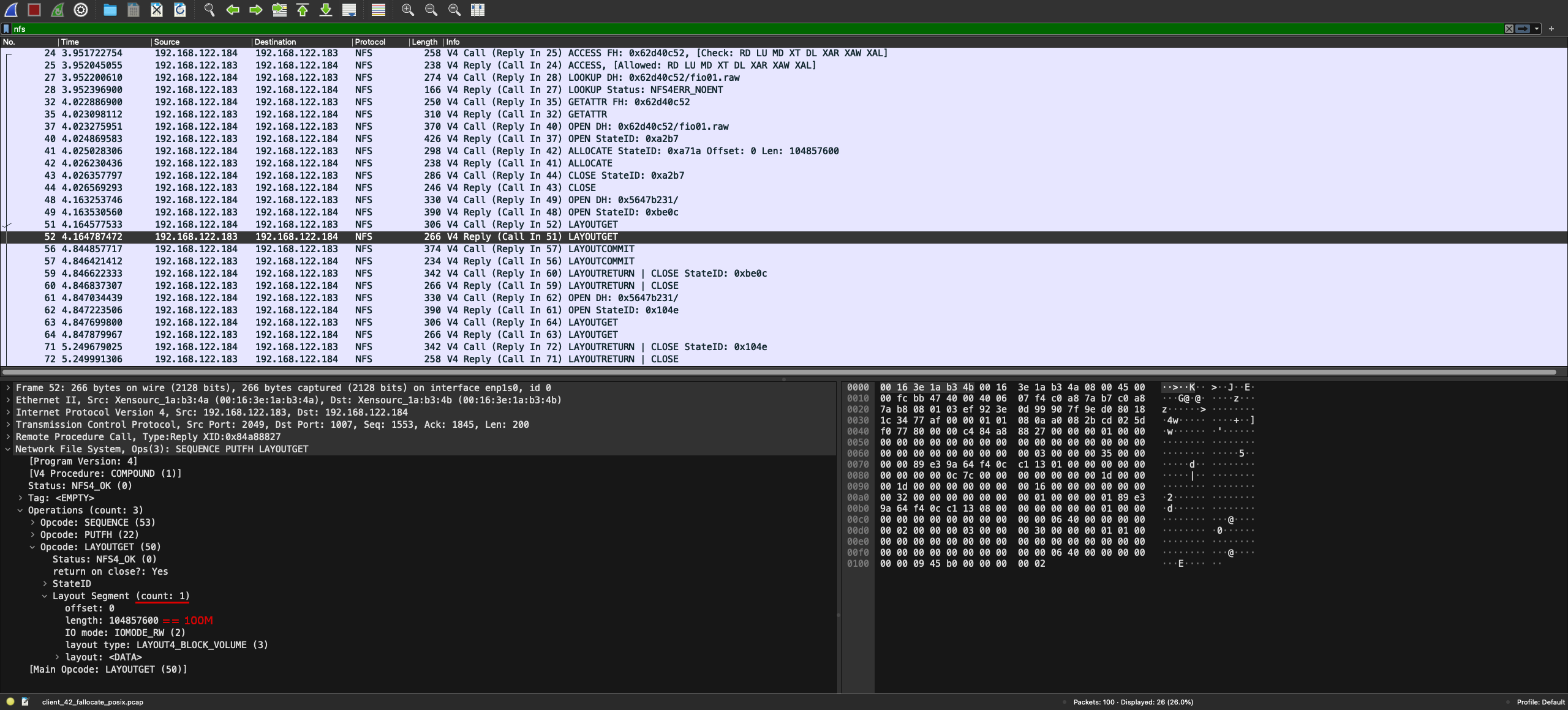
Так мы поняли, что для pNFS Block Volume Layout желательно использовать стандарт версии 4.2 и делать преаллокацию места на диске для эффективного ввода-вывода.
Измеряем производительность: первые результаты
Разобравшись с нюансами, мы решили сравнить производительность общего диска в нашем SDS без файловой системы и производительность размещенной на этом же диске файловой системы pNFS. Результаты представлены на графике:

Стоит отметить, что в нашем распоряжении был небольшой рабочий стенд на базе процессоров Intel Xeon Gold. Запускали 16 виртуальных машин, которые имитировали клиентскую нагрузку, а в случае с pNFS еще одна виртуальная машина выполняла роль MDS. Ко всем был подключен один SDS-volume в режиме для чтения и записи. На первом прогоне каждый клиент работал в своей области диска размером 10 ГБ, напрямую с блочным устройством. Затем создавалась файловая система и каждый клиент работал уже в отдельном файле размером 10 ГБ.
Настраиваем блочный вариант pNFS
Перед тем как рассказать про процесс конфигурирования сервера и клиента, сделаю важную ремарку: механизмы обнаружения, подключения и работы с удаленными блочными устройствами выходят за рамки стандарта NFS. Соответственно, для работы pNFS клиента и сервера нужно, чтобы общий диск был предварительно подключен и доступен на всех хостах. При настройке мы использовали наш собственный SDS, но, конечно, можно использовать и другие решения.
Как создать общие блочные устройства с помощью открытого ПО
Общее блочное устройство для нескольких виртуальных машин можно создать с помощью открытого ПО. Главное соблюдать правило: в виртуальные машины диск передавать как устройство virtio-blk, а не virtio-scsi. Для QEMU в качестве backend-реализации можно использовать несжатый файл qcow2 (если все виртуальные машины на одном и том же физическом хосте), iSCSI-диск, Ceph RBD или аналогичные решения.
Подготовка стенда
Итак, приступим к созданию стенда из нескольких виртуальных машин. Будем считать, что на них установлена Ubuntu 22.04 — в примерах команды и настройки для этой ОС.
Одна из машин должна выступать в качестве сервера MDS, а остальные — в качестве клиентов. Ко всем клиентам и MDS должен быть подключен один и тот же общий диск с возможностью чтения и записи, в примере это /dev/vda. В QEMU диск к виртуальной машине нужно подключать не как virtio-scsi, а как virtio-blk. В противном случае Linux будет пытаться использовать Block SCSI Layout вместо Block Volume Layout. Кроме того, клиенты должны иметь сетевое соединение с MDS. Мы использовали подсеть 192.168.1.0/24 и сервер с адресом 192.168.1.3.
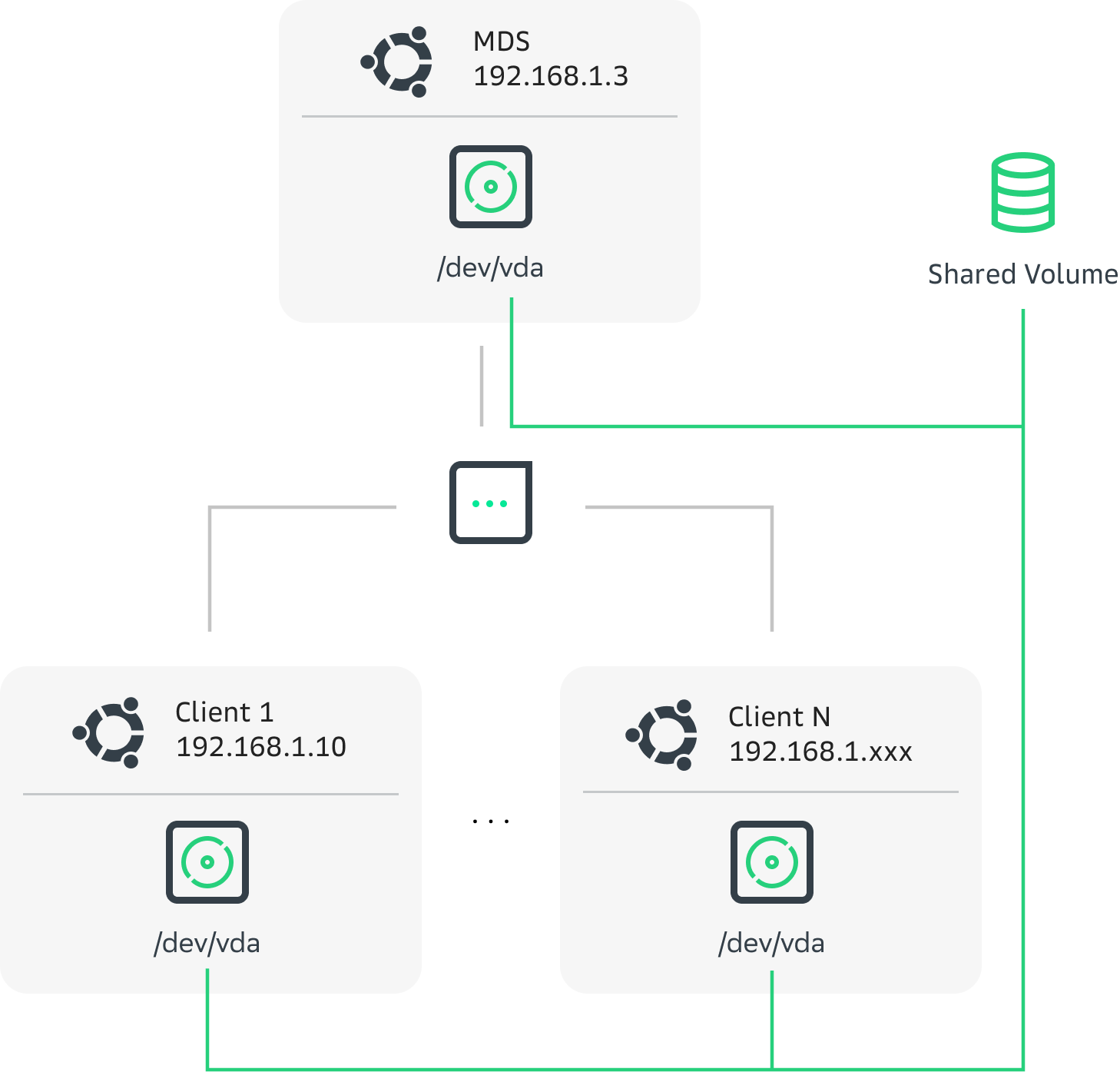
Настройка сервера
Перейдем непосредственно к настройке сервера.
Конфигурация ядра
Cначала убедимся, что ядро Linux собрано с нужными опциями. В Ubuntu 22.04 они включены по умолчанию. Проверить это можно заглянув в конфиг ядра.
admin@mds:~$ grep "CONFIG_NFSD_BLOCKLAYOUT=" /boot/config-$(uname -r)
CONFIG_NFSD_BLOCKLAYOUT=y
Если в вашем случае опция CONFIG_NFSD_BLOCKLAYOUT отсутствует или выключена, то нужно включить ее, затем пересобрать ядро с модулями, установить его и перезагрузить MDS.
Дополнительные пакеты
Устанавливаем пакеты с утилитами, которые мы использовали для настройки:
admin@mds:~$ sudo apt install xfsprogs util-linux nfs-kernel-server
Подготовка файловой системы
Как упоминали выше, существующая реализация pNFS Block Volume Layout в Linux умеет работать только с XFS и не поддерживает разметку на диске. Поэтому нужно создать файловую систему как показано ниже.
Дополнительные опции XFS можно добавлять на свое усмотрение, для простоты используем значения по умолчанию в примере.
# Проверяем, что диск появился в системе
admin@mds:~$ lsblk -f | grep vda
vda
admin@mds:~$ sudo mkfs -t xfs /dev/vda
admin@mds:~$ sudo mkdir /mnt/pnfs_export
admin@mds:~$ sudo mount -t xfs /dev/vda /mnt/pnfs_export
# Проверяем UUID файловой системы, он должен будет совпасть на всех хостах
admin@mds:~$ lsblk -f | grep vda
vda xfs b3517c3f-433d-4c3a-a29b-832fe7b99640 1T 1% /mnt/pnfs_export
Настройка и запуск nfsd
В файле /etc/nfs.conf включаем версию NFSv4.2. При этом остальные версии лучше сразу отключить. Опцию rootdir здесь не используем, а если она указана, то убираем или комментируем. Ниже пример файла конфигурации, который в итоге получился на Ubuntu 22.04.
[general]
pipefs-directory=/run/rpc_pipefs
[mountd]
manage-gids=y
[nfsd]
vers4.2=y
Настраиваем экспорт папки для клиентов из подсети 192.168.1.0/24 в файле /etc/exports по аналогии с примером ниже.
/mnt/pnfs_export 192.168.1.0/24(pnfs,rw,async,wdelay,fsid=0,crossmnt,insecure,no_root_squash,no_subtree_check)
Перезапускаем NFS сервис и проверяем, что сработало без ошибок.
admin@mds:~$ sudo systemctl restart nfs-kernel-server
admin@mds:~$ sudo systemctl status nfs-kernel-server
● nfs-server.service - NFS server and services
Loaded: loaded (/lib/systemd/system/nfs-server.service; enabled; vendor preset: enabled)
Drop-In: /run/systemd/generator/nfs-server.service.d
└─order-with-mounts.conf
Active: active (exited) since Tue 2023-07-27 13:18:03 UTC; 10s ago
Process: 1236 ExecStartPre=/usr/sbin/exportfs -r (code=exited, status=0/SUCCESS)
Process: 1248 ExecStart=/usr/sbin/rpc.nfsd (code=exited, status=0/SUCCESS)
Main PID: 1248 (code=exited, status=0/SUCCESS)
CPU: 20ms
Jul 27 13:18:03 pnfs systemd[1]: Starting NFS server and services...
Jul 27 13:18:03 pnfs systemd[1]: Finished NFS server and services.
Если всё окей, то переходим дальше.
Настройка клиента
Теперь займемся настройкой клиента.
Конфигурация ядра
Для работы pNFS клиента ядро должно быть собрано с опциями CONFIG_NFS_V4_2 и CONFIG_PNFS_BLOCK. В Ubuntu 22.04 они тоже включены по умолчанию. Проверить это можно так же, как это сделали мы в примере ниже.
admin@client1:~$ grep "CONFIG_NFS_V4_2=\|CONFIG_PNFS_BLOCK=" /boot/config-$(uname -r)
CONFIG_NFS_V4_2=y
CONFIG_PNFS_BLOCK=m
В противном случае нужно будет включить эти опции, пересобрать ядро с модулями, установить и перезапустить клиентскую машину.
Дополнительные пакеты
Устанавливаем необходимые пакеты для конфигурирования клиента как в примере ниже (однако серверный пакет для blkmapd тоже нужен).
admin@client1:~$ sudo apt install util-linux nfs-kernel-server
Настройка и запуск blkmapd
Теперь запускаем blkmapd сервис, который нужен для работы в режиме Block Volume Layout, и проверям его статус.
admin@client1:~$ sudo systemctl enable nfs-blkmap
admin@client1:~$ sudo systemctl start nfs-blkmap
admin@client1:~$ sudo systemctl status nfs-blkmap
● nfs-blkmap.service - pNFS block layout mapping daemon
Loaded: loaded (/lib/systemd/system/nfs-blkmap.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2023-07-27 13:34:00 UTC; 14s ago
Process: 616 ExecStart=/usr/sbin/blkmapd (code=exited, status=0/SUCCESS)
Main PID: 618 (blkmapd)
Tasks: 1 (limit: 4546)
Memory: 348.0K
CPU: 2ms
CGroup: /system.slice/nfs-blkmap.service
└─618 /usr/sbin/blkmapd
Jul 27 13:34:00 pnfsclient01 systemd[1]: Starting pNFS block layout mapping daemon...
Jul 27 13:34:00 pnfsclient01 blkmapd[618]: open pipe file /run/rpc_pipefs/nfs/blocklayout failed: No such file or directory
Jul 27 13:34:00 pnfsclient01 systemd[1]: Started pNFS block layout mapping daemon.
Если возникнет ошибка, создайте конфигурационный файл по инструкции ниже.
sudo mkdir -p /etc/systemd/system/nfs-blkmap.service.d
sudo cat /etc/systemd/system/nfs-blkmap.service.d/fixpipe.conf
[Service]
ExecStartPre=/usr/sbin/modprobe blocklayoutdriver
Теперь перезагружаем клиентскую машину и проверяем, что у сервиса хороший статус.
admin@client1:~$ sudo systemctl status nfs-blkmap
● nfs-blkmap.service - pNFS block layout mapping daemon
Loaded: loaded (/lib/systemd/system/nfs-blkmap.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/nfs-blkmap.service.d
└─fixpipe.conf
Active: active (running) since Thu 2023-07-27 13:36:18 UTC; 3s ago
Process: 1059 ExecStartPre=/usr/sbin/modprobe blocklayoutdriver (code=exited, status=0/SUCCESS)
Process: 1060 ExecStart=/usr/sbin/blkmapd (code=exited, status=0/SUCCESS)
Main PID: 1061 (blkmapd)
Tasks: 1 (limit: 4546)
Memory: 304.0K
CPU: 7ms
CGroup: /system.slice/nfs-blkmap.service
└─1061 /usr/sbin/blkmapd
Jul 27 13:36:18 pnfsclient01 systemd[1]: Starting pNFS block layout mapping daemon...
Jul 27 13:36:18 pnfsclient01 systemd[1]: Started pNFS block layout mapping daemon.
Если всё окей, то переходим дальше.
Монтирование файловой системы
Монтировать саму файловую систему XFS, которая на общем диске, клиентам не нужно, поэтому остается только примонтировать NFS папку с MDS сервера 192.168.1.3 и проверить, что всё хорошо.
# Проверяем UUID файловой системы, он должен быть как на сервере
admin@client1:~$ lsblk -f | grep vda
vda xfs b3517c3f-433d-4c3a-a29b-832fe7b99640
admin@client1:~$ sudo mkdir /mnt/pnfs
admin@client1:~$ sudo mount -t nfs4 -v -o minorversion=2,soft,timeo=30 192.168.1.3:/ /mnt/pnfs
mount.nfs4: timeout set for Thu Jul 27 13:50:05 2023
mount.nfs4: trying text-based options 'soft,timeo=30,vers=4.2,addr=192.168.1.3,clientaddr=192.168.1.10'
# Проверяем результат
admin@client1:~$ mount | grep nfs4
192.168.1.3:/ on /mnt/pnfs type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,soft,proto=tcp,timeo=30,retrans=2,sec=sys,clientaddr=192.168.3.10,local_lock=none,addr=192.168.1.3)
admin@client1:~$ sudo systemctl status nfs-blkmap
● nfs-blkmap.service - pNFS block layout mapping daemon
Loaded: loaded (/lib/systemd/system/nfs-blkmap.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/nfs-blkmap.service.d
└─fixpipe.conf
Active: active (running) since Thu 2023-07-27 13:36:18 UTC; 20min ago
Process: 1059 ExecStartPre=/usr/sbin/modprobe blocklayoutdriver (code=exited, status=0/SUCCESS)
Process: 1060 ExecStart=/usr/sbin/blkmapd (code=exited, status=0/SUCCESS)
Main PID: 1061 (blkmapd)
Tasks: 1 (limit: 4546)
Memory: 324.0K
CPU: 14ms
CGroup: /system.slice/nfs-blkmap.service
└─1061 /usr/sbin/blkmapd
Jul 27 13:36:18 pnfsclient01 systemd[1]: Starting pNFS block layout mapping daemon...
Jul 27 13:36:18 pnfsclient01 systemd[1]: Started pNFS block layout mapping daemon.
Jul 27 13:37:43 pnfsclient01 blkmapd[1061]: process_deviceinfo: 1 vols
Jul 27 13:37:43 pnfsclient01 blkmapd[1061]: map_sig_to_device: using device /dev/vda
Jul 27 13:37:43 pnfsclient01 blkmapd[1061]: decode_blk_volume: simple 0
Проверяем стенд
Теперь переходим к проверке стенда.
На стороне сервера
Надежный способ убедиться, что MDS корректно работает в блочном режиме pNFS — посмотреть на счетчики RPC-вызовов. Количество READ и WRITE не должно увеличиваться. Если другие режимы NFS не включали после перезагрузки сервера, то значения должны равняться нулю. При этом количество вызовов LAYOUTGET, LAYOUTRETURN и LAYOUTCOMMIT должно быть ненулевым и возрастать по мере работы с файлами.
admin@mds:~$ sudo nfsstat --server
Вывод nfsstat
Server rpc stats:
calls badcalls badfmt badauth badclnt
150 0 0 0 0
Server nfs v4:
null compound
1 0% 149 99%
Server nfs v4 operations:
op0-unused op1-unused op2-future access close
0 0% 0 0% 0 0% 5 0% 3 0%
commit create delegpurge delegreturn getattr
0 0% 0 0% 0 0% 0 0% 135 23%
getfh link lock lockt locku
3 0% 0 0% 0 0% 0 0% 0 0%
lookup lookup_root nverify open openattr
2 0% 0 0% 0 0% 3 0% 0 0%
open_conf open_dgrd putfh putpubfh putrootfh
0 0% 0 0% 142 24% 0 0% 2 0%
read readdir readlink remove rename
0 0% 0 0% 0 0% 1 0% 0 0%
renew restorefh savefh secinfo setattr
0 0% 0 0% 0 0% 0 0% 1 0%
setcltid setcltidconf verify write rellockowner
0 0% 0 0% 0 0% 0 0% 0 0%
bc_ctl bind_conn exchange_id create_ses destroy_ses
0 0% 0 0% 2 0% 1 0% 0 0%
free_stateid getdirdeleg getdevinfo getdevlist layoutcommit
0 0% 0 0% 1 0% 0 0% 112 19%
layoutget layoutreturn secinfononam sequence set_ssv
6 1% 3 0% 1 0% 146 25% 0 0%
test_stateid want_deleg destroy_clid reclaim_comp allocate
0 0% 0 0% 0 0% 1 0% 1 0%
copy copy_notify deallocate ioadvise layouterror
0 0% 0 0% 0 0% 0 0% 0 0%
layoutstats offloadcancel offloadstatus readplus seek
0 0% 0 0% 0 0% 0 0% 0 0%
write_same
0 0%
На стороне клиента
Аналогично тому, как делали это для сервера, стоит проверить счетчики RPC-вызовов.
admin@client1:~$ sudo mountstats
Вывод mountstats
Stats for 192.168.1.3:/ mounted on /mnt/pnfs:
NFS mount options: rw,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,acregmin=3,acregmax=60,acdirmin=30,acdirmax=60,soft,proto=tcp,timeo=30,retrans=2,sec=sys,clientaddr=192.168.1.10,local_lock=none
NFS mount age: 0:06:50
NFS server capabilities: caps=0xfffbc03f,wtmult=512,dtsize=1048576,bsize=0,namlen=255
NFSv4 capability flags: bm0=0xfdffbfff,bm1=0x40f9be3e,bm2=0x60803,acl=0x3,sessions,pnfs=LAYOUT_BLOCK_VOLUME,lease_time=90,lease_expired=0
NFS security flavor: 1 pseudoflavor: 0
NFS byte counts:
applications read 0 bytes via read(2)
applications wrote 10737418240 bytes via write(2)
applications read 23271464960 bytes via O_DIRECT read(2)
applications wrote 6940622848 bytes via O_DIRECT write(2)
client read 23271464960 bytes via NFS READ
client wrote 17678041088 bytes via NFS WRITE
RPC statistics:
154 RPC requests sent, 154 RPC replies received (0 XIDs not found)
average backlog queue length: 0
LAYOUTCOMMIT:
112 ops (72%)
avg bytes sent per op: 316 avg bytes received per op: 164
backlog wait: 3.758929 RTT: 15.062500 total execute time: 19.642857 (milliseconds)
LAYOUTGET:
6 ops (3%)
avg bytes sent per op: 240 avg bytes received per op: 196
backlog wait: 0.000000 RTT: 0.833333 total execute time: 0.833333 (milliseconds)
GETATTR:
4 ops (2%)
avg bytes sent per op: 181 avg bytes received per op: 240
backlog wait: 0.000000 RTT: 0.500000 total execute time: 0.500000 (milliseconds)
SEQUENCE:
4 ops (2%)
avg bytes sent per op: 124 avg bytes received per op: 80
backlog wait: 0.000000 RTT: 0.500000 total execute time: 0.500000 (milliseconds)
CLOSE:
3 ops (1%)
avg bytes sent per op: 276 avg bytes received per op: 193
backlog wait: 0.333333 RTT: 0.666667 total execute time: 1.666667 (milliseconds)
SERVER_CAPS:
3 ops (1%)
avg bytes sent per op: 164 avg bytes received per op: 164
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
OPEN_NOATTR:
2 ops (1%)
avg bytes sent per op: 264 avg bytes received per op: 320
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.500000 (milliseconds)
FSINFO: [2/1897]
2 ops (1%)
avg bytes sent per op: 164 avg bytes received per op: 176
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
ACCESS:
2 ops (1%)
avg bytes sent per op: 198 avg bytes received per op: 168
backlog wait: 0.000000 RTT: 0.500000 total execute time: 0.500000 (milliseconds)
LOOKUP:
2 ops (1%) 1 errors (50%)
avg bytes sent per op: 204 avg bytes received per op: 188
backlog wait: 0.000000 RTT: 0.500000 total execute time: 0.500000 (milliseconds)
EXCHANGE_ID:
2 ops (1%)
avg bytes sent per op: 252 avg bytes received per op: 108
backlog wait: 0.000000 RTT: 0.500000 total execute time: 0.500000 (milliseconds)
NULL:
1 ops (0%)
avg bytes sent per op: 44 avg bytes received per op: 24
backlog wait: 0.000000 RTT: 1.000000 total execute time: 2.000000 (milliseconds)
OPEN:
1 ops (0%)
avg bytes sent per op: 308 avg bytes received per op: 356
backlog wait: 0.000000 RTT: 2.000000 total execute time: 2.000000 (milliseconds)
SETATTR:
1 ops (0%)
avg bytes sent per op: 236 avg bytes received per op: 264
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
LOOKUP_ROOT:
1 ops (0%)
avg bytes sent per op: 152 avg bytes received per op: 260
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
REMOVE:
1 ops (0%)
avg bytes sent per op: 184 avg bytes received per op: 116
backlog wait: 0.000000 RTT: 1.000000 total execute time: 1.000000 (milliseconds)
PATHCONF:
1 ops (0%)
avg bytes sent per op: 156 avg bytes received per op: 116
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
FS_LOCATIONS:
1 ops (0%)
avg bytes sent per op: 152 avg bytes received per op: 132
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
CREATE_SESSION:
1 ops (0%)
avg bytes sent per op: 208 avg bytes received per op: 124
backlog wait: 0.000000 RTT: 0.000000 total execute time: 0.000000 (milliseconds)
RECLAIM_COMPLETE:
1 ops (0%)
avg bytes sent per op: 132 avg bytes received per op: 88
backlog wait: 0.000000 RTT: 4.000000 total execute time: 4.000000 (milliseconds)
GETDEVICEINFO:
1 ops (0%)
avg bytes sent per op: 188 avg bytes received per op: 144
backlog wait: 0.000000 RTT: 2.000000 total execute time: 2.000000 (milliseconds)
SECINFO_NO_NAME:
1 ops (0%)
avg bytes sent per op: 140 avg bytes received per op: 104
backlog wait: 4.000000 RTT: 0.000000 total execute time: 5.000000 (milliseconds)
ALLOCATE:
1 ops (0%)
avg bytes sent per op: 232 avg bytes received per op: 168
backlog wait: 0.000000 RTT: 2.000000 total execute time: 2.000000 (milliseconds)
А еще можно сделать мониторинг сетевого трафика, например, утилитой bmon (или аналогичной). По сравнению с объемом ввода-вывода в файлы, для Block Volume Layout объем передаваемых данных между клиентом и MDS должен быть очень маленьким.
Выводы
Итак, мы изучили теорию, развернули стенд, попытались его настроить, столкнулись с рядом проблем и героически их побороли. В результате сделали важные выводы и делимся ими с вами:
Архитектурно pNFS Block Volume Layout лучше всего сочетается с SDS. Роль серверов данных выполняют сами удаленные диски. Фактически добавляется только одна новая сущность — сервер MDS.
Производительность файловой системы порадовала, она оказалась близка к производительности самого SDS.
Масштабируемость архитектуры тоже оказалась хорошей — она пропорциональна возможностям SDS.
Для MDS сервера необходимо самостоятельно докручивать HA. Например, можно использовать Pacemaker или другой подобный инструмент.
Открытая реализация сервера с поддержкой блочного типа доступа к данным пока есть только в ядре Linux. Но и там заявлено, что в основном она для тестирования кода клиента. Так что используйте с осторожностью — есть большой шанс наткнуться на баги.
Как я отметил в начале статьи, даже правильно настроенный стенд может не работать в некоторых сценариях тестирования. Мы сталкивались с тем, что иногда при корректных запросах на сервере возникала ошибка NFSERR_BAD_XDR. А в отдельных случаях сам клиент терял часть экстентов, когда пытался коммитить изменения в файле, или же указывал неверный last write offset из-за ошибки целочисленного переполнения.
О том, как мы отлаживали ядро Linux, находили и чинили проблемы в коде, расскажем в нашей следующей статье про pNFS.
Что еще есть у нас в блоге:
Комментарии (3)

kvaps
09.09.2023 07:38+1Крайне познавательно, спасибо :)
Общее блочное устройство для нескольких виртуальных машин можно создать с помощью открытого ПО. Главное соблюдать правило: в виртуальные машины диск передавать как устройство virtio-blk, а не virtio-scsi. Для QEMU в качестве backend-реализации можно использовать несжатый файл qcow2 (если все виртуальные машины на одном и том же физическом хосте), iSCSI-диск, Ceph RBD или аналогичные решения.
Формат qcow2 не поддерживает конкурентный доступ на чтение/запись из нескольких виртуальных машин одновременно. Даже если вы отключите page cache, он не защищён на изменение метаданных из разных источников. Если интересно, писал об этом тут.
а в качестве сервера для экспериментального стенда выбрали линуксовый nfsd. С точки зрения архитектуры эта комбинация выглядела привлекательно: в ней серверами данных (в терминологии pNFS) становились сервисы удаленных дисков SDS и оставалось только добавить в систему MDS.
А вы не тестировали возможность использования nfs-ganesha в такой же схеме с block layout?
В QEMU диск к виртуальной машине нужно подключать не как virtio-scsi, а как virtio-blk. В противном случае Linux будет пытаться использовать Block SCSI Layout вместо Block Volume Layout.
Подскажите чем это может быть черевато, ведь virtio-scsi быстрее и поддерживает TRIM.
В pNFS все эти процессы очень похожи на обычный NFS. Но для доступа к блокам данных клиент запрашивает у MDS схему размещения файла на DS-серверах, а затем выполняет чтение или запись, коммуницируя напрямую с DS-серверами.
Архитектурно pNFS Block Volume Layout лучше всего сочетается с SDS. Роль серверов данных выполняют сами удаленные диски. Фактически добавляется только одна новая сущность — сервер MDS.
То есть правильно-ли я понимаю что при наличии shared LUN, использование pNFS с блочным лейаутом можно рассматривать как альтернативу OCFS2 и GFS2?
Интересует возможность растянуть одну общую файловую систему поверх shared LUN, которая будет работать в ReadWriteMany. Внутри неё планируется создавать QCOW2-диски для отдельных виртуальных машин, которые поддерживают снапшоты и прочее.

sbashiro Автор
09.09.2023 07:38+2Спасибо за хороший комментарий!
Формат qcow2 не поддерживает конкурентный доступ на чтение/запись...
Мы для теста сделали три виртуалки на одном образе: два клиента и один MDS. Сильно не проверяли на стабильность, по пару файлов между клиентами перекинуть удалось. Динамически расширяемый образ или сжатый точно не работают. Мы использовали образ фиксированного размера со статически предвыделенным местом на диске. Возможно, это просто RAW-image был, я уточню ещё раз.
А вы не тестировали возможность использования nfs-ganesha в такой же схеме с block layout?
В Ганеше просто нет реализации block layout вообще, т.е. все открытые реализации FSAL используют другие типы layouts.
По поводу virtio-scsi vs virtio-blk: можно использовать оба варианта, просто будет разный драйвер у клиента. Это очень похожие, но все таки разные layouts. Если клиент видит iSCSI-устройство, то его ядро будет грузить драйвер Block SCSI Layout. Мы же описывали как форсировать использование именно дайвера Block Volume Layout.
Например, в решениях у Dell используется Block SCSI (по описанию, которое я находил). Прицип действия аналогичный, только немножко другой формат структурок с экстентами и энумерации дисков в протоколе.
Я бы сказал, что тут все зависит от используемого SDS или СХД, т. е. как устройства раздаются в QEMU — от того и надо плясать.
То есть правильно-ли я понимаю что при наличии shared LUN, использование pNFS с блочным лейаутом можно рассматривать как альтернативу OCFS2 и GFS2?
Да, pNFS в режиме SCSI Block Layout будет работать на общем iSCSI диске, предоставлять кластерную файловую систему. Но проблема в том, что open source сервера пока не в состоянии production ready.
rgaliull
Классная полезная статья.
Хабр - торт.