
Мы много лет уже используем в качестве основной базы данных PostgreSQL. За это время он зарекомендовал себя быстрой и надежной СУБД. Однако, есть в PostgreSQL одна проблема, с которой приходится сталкиваться достаточно часто. К сожалению, реализация логики временных таблиц в нем имеет ряд недостатков, которые отрицательно сказываются на производительности системы.
Одним из свидетельств наличия проблемы является то, что для временных таблиц в Postgres Pro была добавлена специальная функция fasttrun, а в Postgres Pro Enterprise существенно доработана работа с ними (см. пункт 4).
Наиболее активно временные таблицы используют платформы, в которых разработчик не работает напрямую с базой данных, а таблицы и запросы генерируются непосредственно самой платформой. В частности, к ним относится платформа 1С или ее открытый и бесплатный аналог - платформа lsFusion.
В этой статье я опишу почему приходится использовать временные таблицы, в чем суть проблемы, и как улучшить производительность путем настроек операционной системы и PostgreSQL.
В чем проблема
Временные таблицы в PostgreSQL реализованы примерно так же, как и обычные таблицы. Разработчиков можно понять, так как иначе им приходилось бы всюду делать две ветки кода отдельно для обычных и временных таблиц. Это бы значительно усложнило логику СУБД и добавило бы проблем с точки зрения надежности и производительности. С другой стороны, варианты использования временных таблиц очень ограничены, и множество механизмов, используемых для обычных таблиц, для временных являются избыточными. В частности, они гарантировано не используются несколькими подключениями одновременно, не подвержены блокировкам, не требуют надежности записи и т.д.
Как и для обычных таблиц, информация о временных находится в системных таблицах PostgreSQL. Кроме того, для каждой таблицы создается один или несколько файлов на диске (по умолчанию, в той же папке, что и файлы для обычных таблиц).
Одним из побочных эффектов такой реализации временных таблиц в PostgreSQL является поддержка транзакционности. Если временные таблицы изменялись внутри транзакции, а она потом откатывается, то и временная таблица вернется в состояние до начала транзакции. В большинстве случаев такое поведение не очень то и нужно, а также создает определенный overhead.
Проблема заключается в том, что временные таблицы необходимо часто очищать. Делать это с помощью DELETE ALL плохо, поскольку PostgreSQL использует MVCC в том числе и для временных таблиц, а удаление записей в этой модели - относительно медленный процесс. Поэтому приходится использовать TRUNCATE.
TRUNCATE просто создает новый файл на диске и делает UPDATE таблицы pg_class. Это легко проверить, если сделать запрос, подобный этому, и посмотреть, что происходит на диске после каждого из них:
CREATE TEMPORARY TABLE t0 (key0 integer);
SELECT relfilenode FROM pg_class WHERE relname = 't0';
TRUNCATE t0;
SELECT relfilenode FROM pg_class WHERE relname = 't0';На диске будет создан сначала один файл вида t0_9782399, а затем другой с новым relfilenode.
Кроме того, после добавления записей во временную таблицу приходится делать ее ANALYZE, чтобы PostgreSQL знал правильную статистику данных в ней. ANALYZE, в свою очередь, также изменяет системные таблицы и обращается к диску (в функции visibilitymap_count).
При большом количестве TRUNCATE и ANALYZE возникают две проблемы :
Таблица pg_class (и другие системные таблицы) разрастается. Если pg_class после VACUUM FULL занимает 30 МБ, то через пару часов она может вырасти до 1 ГБ. Учитывая, что к системным таблицам обращаются очень часто, увеличение ее размера в определенной степени увеличивает нагрузку на процессор. Плюс по этой причине часто срабатывает autovacuum самой таблицы pg_class.
Постоянно создаются новые и удаляются старые файлы, что требует обращения к файловой системе. И все бы ничего, но в случае большой загрузки дисковой системы с постоянной ротацией буферов, это начинает тормозить пользователей, которые в обычном состоянии выполняют действия, не требующие обращения к диску, хотя у них все данные уже находятся в общих буферах. А вот TRUNCATE временных таблиц "останавливает" их в ожидании обращения к диску (хотя на самом деле их размер не превышает temp_buffers, и диск нет смысла использовать).
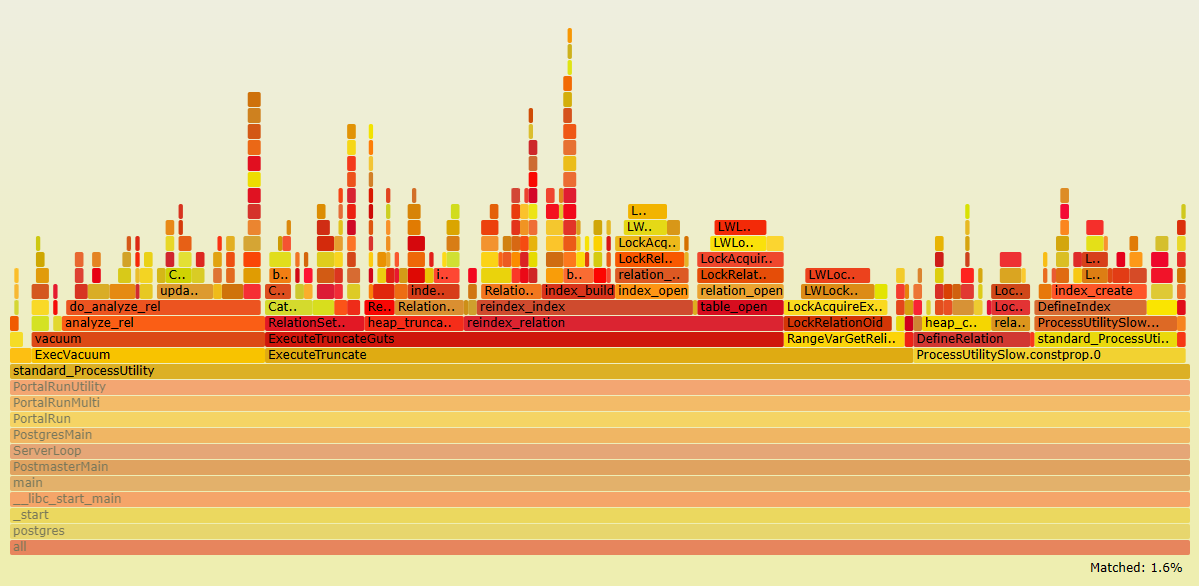
В результате работа со временными таблицами (именно в части DDL) использует значительную часть процессорного времени :

Причем непосредственно обращение к файловой системе занимает 13.5% CPU :

Теоретически, вся работа с файлами должна происходить внутри кэша диска, и как минимум не ждать обращения к IO, а как максимум вообще не обращаться к диску. Однако, во-первых, кэши диска активно используются и для основной базы данных, а, во-вторых, пусть даже в асинхронном режиме, время от времени, все равно будет идти запись, что создает дополнительные IO операции. Мы для теста вынесли все временные таблицы на отдельный диск, и там была достаточно большая запись на диск при почти полном отсутствии чтения :


Проблема усугубляется тем, что все файлы, которые создаются для временных таблиц лежат фактически в одной папке. Их количество в определенные моменты времени может доходить до нескольких сот тысяч. К сожалению, не все файловые системы (например, xfs) хорошо обрабатывают такое количество файлов в одной директории. При этом файлы не просто лежат, а постоянно создаются и удаляются с огромной скоростью.
Также большую часть времени процессы проводят в LWLockAttemptLock, который вызывается из LockRelationOID.

В нормальной ситуации вызовы LWLockAttemptLock проходят достаточно быстро и сильно не влияют на производительность. Однако, это является потенциальным bottleneck, и может приводить к очень сильной деградации работы всего сервера БД. В частности, у нас такое наблюдалось из-за проблем с виртуализацией, поскольку внутри LWLockAttemptLock использует функции ядра по синхронизации процессов. Однажды была ситуация, когда в PostgreSQL количество одновременных процессов в статусе active достигло 150, среди которых 100 висели в блокировке LWLock / LockManager на запросах CREATE TEMPORARY TABLE и TRUNCATE.
Зачем их использовать
Часто нам ставят в упрек, что мы слишком активно используем временные таблицы, и можно было бы обойтись без них. Мы бы конечно с радостью избавились от их использования, но, к сожалению, существуют как минимум три ситуации, когда тяжело придумать иной способ.
Промежуточные вычисления
Существуют ситуации, когда надо провести какие-то сложные вычисления для определенного подмножества объектов. В этом случае, часто бывает выгоднее всего сначала записать ключи объектов во временную таблицу, а затем уже использовать ее для расчета конкретных значений при помощи JOIN. Можно, конечно, всегда встраивать в запросы исходные фильтры подмножества объектов, но это может привести к повторению одних и тех же вычислений, что будет менее эффективно.
Неправильная статистика
У PostgreSQL относительно простой, но в то же время быстрый, алгоритм планирования запросов. Однако, у него есть одна большая проблема. Он строит план, и затем придерживается его, даже если он оказался ошибочным. В худшем случае может получится ситуация, когда в промежуточных вычислениях PostgreSQL ожидает 1-2 записей, а фактически оказывается в тысячи раз больше. В результате выполнение Nested Loop приводит к огромной сложности алгоритма, что приводит к зависанию процесса с большой загрузкой CPU. К сожалению, в PostgreSQL нет возможности указывать hint’ы, как в некоторых других СУБД. В качестве workaround платформа lsFusion, когда видит “зависший” запрос по timeout’у, сначала отменяет запрос, а затем разбивает его на несколько с использованием временных таблиц. К сожалению, определить, где именно ошибся PostgreSQL, очень тяжело, поэтому алгоритм разбиения - эвристический. В результате работы алгоритма сначала отдельными запросами во временные таблицы записываются некоторые промежуточные данные (например, вложенные подзапросы), а затем эти таблицы после выполнения ANALYZE используются в итоговом запросе. Тем самым у PostgreSQL уже будет правильная статистика промежуточных вычислений, и последующий план будет более точный.
Хранение изменений
Во время работы в системе, когда пользователь делает какие-то изменения, то в базу данных они записываются не сразу, а только при нажатии кнопки Сохранить. Только в этот момент начинается транзакция, и идет непосредственно публикация в базу данных изменений с проверкой ограничений и пересчетом всех зависимых полей. Однако, до сохранения все изменения хранятся во временных таблицах. На это существует несколько причин.
Во-первых, уменьшаются расходы, связанные с передачей данных между сервером приложений и СУБД. Например, пользователь изменил какие-то данные на форме - они записались во временную таблицу, а в момент сохранения будет просто выполнен INSERT или UPDATE из нее уже в основную таблицу.
Во-вторых, это упрощает логику вычислений. Например, при необходимости посчитать какой-то показатель с учетом изменений, можно сделать SELECT SUM(COALESCE(<основная таблица>.field, <временная таблица>.field) … FROM <основная таблица> FULL JOIN <временная таблица> ON … GROUP BY …
Если же хранить изменения на сервере приложений (или вообще на клиенте), то придется все необходимые данные передавать туда же, и уже там проводить соответствующие вычисления. Это приведет как к большему потреблению памяти, так и к дублированию логики вычисления значений на СУБД и сервере приложений, если эти же показатели надо будет вычислять в SQL-запросах. Кроме того, все таблицы на формах у нас построены в виде “динамических списков”. То есть на клиент в целях оптимизации передается только “видимое окно” данных. Соответственно, например, всех строк документа, необходимых для расчета показателей, на клиенте и сервере приложений может просто не быть.
Конечно, такой подход имеет и свои недостатки. Главных из них является значительное усложнение кластеризации и горизонтального масштабирования. Поскольку временные таблицы в PostgreSQL привязаны к подключениям, то их приходится “закреплять” за конкретными пользователями. Соответственно переключение между серверами возможно только с переносом на новый сервер временных таблиц. Однако, на практике нам пока достаточно вертикального масштабирования. За счет достаточно оптимальных запросов, у самых крупных наших клиентов, с несколькими тысячами одновременно работающих пользователей, хватает ресурсов одного сервера БД с 48 ядрами (с HT - 96) и 512ГБ памяти.
Поскольку, как правило, во время работы требуются одни и те же временные таблицы, то, чтобы постоянно не создавать и удалять таблицы, мы их “кэшируем”, очищая при помощи более легковесной команды TRUNCATE. Это уменьшает нагрузку на базу данных, так как очистка временной таблицы требует меньше ресурсов, однако увеличивается количество одновременных файлов на диске (пока таблица находится в кэше, но не используется).
Что делать
На данный момент, по разным причинам мы работаем исключительно с базовой версией PostgreSQL. Как вариант, можно было бы попробовать использовать Postgres Pro Enterprise, но пока эта проблема не так критична, чтобы клиенты были согласны потратить деньги на закупку соответствующих лицензий.
Однако существует один подход в Linux, который позволяет значительно уменьшить использования диска временными таблицами. Он заключается в выделении для временных таблиц отдельного RAM-диска. Причем для этого не требуется никаких изменений в коде программы, а указанную процедуру можно делать на работающей базе без остановки СУБД или приложения.
В PostgreSQL есть опция temp_tablespaces, которая определяет в какой tablespace, по умолчанию, будут создаваться все временные таблицы. Если значение пусто, то временные таблицы создаются рядом с основными таблицами базы данных.
Для реализации нашей задачи сначала нужно создать новый tablespace специально под временные таблицы. Перед этим нужно определить директорию, в которой будут храниться файлы пространства таблиц. Например, пусть это будет /mnt/dbtemp. После создания каталога нужно установить права доступа, которые требует PostgreSQL :
mkdir /mnt/dbtemp
chmod 700 /mnt/dbtemp
chown postgres:postgres /mnt/dbtempДалее заходим в psql и выполняем следующую команду :
CREATE TABLESPACE temp LOCATION '/mnt/dbtemp';В результате внутри /mnt/dbtemp будет создан пустой каталог вида PG_13_202007201. По мере использования tablespace’а в нем будут создаваться директории под каждую базу данных, а также каталог pgsql_tmp. В последнем будут создаваться файлы во время выполнения SQL-запросов, если промежуточные расчеты не влезли в work_mem.
Теоретически, можно в память загружать весь каталог PG_13_202007201. Однако, тогда теряет смысл параметр work_mem, поскольку при превышении его опять же пойдет запись в память, а не на диск. По этой причине, мы обычно делаем RAM-диск исключительно для нужной базы данных, а не для всего каталога.
Для того, чтобы появился каталог под нужную базу данных, проще всего зайти в psql и сделать :
CREATE TEMPORARY TABLE mytemptable (key0 int8) TABLESPACE temp;
DROP TABLE mytemptable;После этого в каталоге tablespace появится директория вида 936082, который равен внутреннему идентификатору базы данных. Именно этот каталог будем загружать в память. Для этого добавим в /etc/fstab следующую строку :
tmpfs /mnt/dbtemp/PG_13_202007201/936082 tmpfs rw,nodev,nosuid,noatime,nodiratime,size=1G 0 0После чего непосредственно монтируем RAM-диск при помощи команды :
mount /mnt/dbtemp/PG_13_202007201/936082При этом важно правильно подобрать размер RAM-диска. В примере выше он равен 1GB, но значение можно поменять по своему усмотрению. Нужно помнить, что величина RAM-диска - это его лимит, и пока на нем нет данных, то память фактически не используется. С другой стороны, большой лимит может привести к тому, что или закончится память, или операционная система уйдет в своп.
Есть еще одна особенность, которую надо учитывать при работе с временными таблицами в PostgreSQL. Если в момент выполнения INSERT INTO <временнная таблица> закончится место на RAM-диске, то СУБД кинет ошибку, но файл останется, а место не освободится. После этого даже TRUNCATE <временная таблица> будет выдавать ошибку, так как эта команда сначала должна создать новый файл, а это будет невозможно из-за отсутствия места. Единственное, что можно будет сделать в такой ситуации - это DROP TABLE <временной таблицы>. Кстати, платформа lsFusion делает все это автоматически.
Если все прошло успешно, то остается только поменять опцию temp_tablespaces в postgresql.conf :
temp_tablespaces = 'temp'И, чтобы она применилась, в psql запустить :
SELECT pg_reload_conf();Сразу после этого все новые временные таблицы начнут создаваться уже в памяти, и через некоторое время все туда переедут.
Как результат, при анализе perf, время вызовов функций ext4 сокращается до 1.6%, при этом работа с tmpfs практически не видна :
Комментарии (16)

gpin
27.09.2023 13:07В частности, они гарантировано не используются несколькими подключениями одновременно
А чем обеспечивается эта гарантия? Сама СУБД запрещает использовать одну временную таблицу двумя подключениями?
Мне казалось, я что-то такое делал

IvanPetrof
27.09.2023 13:07В отличие, например, от oracle, в postgres временные таблицы не создаются заранее каким-нить админом. В postgres временная таблица прежде чем использоваться должна быть создана самим сеансом. И она создаётся в контексте этого сеанса и для остальных она как бы не существует.

grufos
27.09.2023 13:07Временные таблицы хранятся пока конкретный сеанс с БД существует. Соответственно, если произойдет разрыв коннекта, то временные таблицы исчезнут. Как вы решаете эту проблему? Ведь пользователь может долго что-то делать, прежде чем решит нажать на кнопку сохранить. К этому моменту, в связи с особенностями инфраструктуры, коннект к БД может быть оборван. Вы как-то умеете восстанавливать все ранее записанные данные во временные таблицы ? К примеру ведете свой транзакционный лог...или как-то иначе... И ещё ведь такой подход требует иметь возможность подключения к БД одновременно всех заявленных пользователей, а это может быть очень большое число....Это приведет к большому расходу ресурсов сервера и к замедлению его работы.

CrushBy Автор
27.09.2023 13:07-1Да, если произойдет разрыв соединения данные теряются. Но на практике разрывы соединения у нас бывают только, если сеть ляжет (что маловероятно, сервер приложений и сервер БД обычно соединены очень коротким путем), либо если весь PostgreSQL ляжет, что бывает крайне редко.
По сути, нужно такое же количество соединений, сколько и количество одновременно работающих пользователей. И да, в PostgreSQL одно соединение - один процесс в ОС. Приводит ли это к большому расходу сервера и замедлению работы ? Все относительно.
Вот сейчас снял на одном из работающих серверов :ps aux | grep postgres | wc -l
Результат :2284Собственно, там сейчас залогинено приблизительно такое же количество пользователей. Shared buffers - 256GB, temp_buffers и work_mem по 96MB. Да, каждый процесс использует свое количество памяти, но соединения автоматически время от времени закрываются и открываются, что убивает процессы и очищает память (новый процесс тратит немного памяти). Всего этими процессами вне shared_buffers используется 150ГБ памяти. При этом есть еще большой резерв по памяти.
Если честно, не наблюдал какого-то overhead'а idle процессами postgres. Если он и есть, то не очень большой.

ptr128
27.09.2023 13:07Я выкручиваюсь через unlogged tables, добавляя в уникальный ключ идентификатор процесса. Но вот truncate к ним тогда не применим. Только delete. Зато delete на них выполняется быстро. И статистики не нужно обновлять на каждый чих.

rombell
27.09.2023 13:07+1Вы используете пул соединений? Баунсер или что-то другое?

Veidt
27.09.2023 13:07Есть внутренний пул соединений, куда складываются неиспользуемые потоками соединения без временных таблиц / транзакций, и потом выдаются при необходимости новым потокам. Но так как таких соединений не сильно много по понятным причинам, особой роли этот пул не играет.
Правда есть важный механизм асинхронного "перестарта соединений", когда отдельный поток периодически собирает (весьма хитрым скорингом) соединения, которые давно работают, использовали много временных таблиц, и т.п. и асинхронно перестартовывает такие соединения (создает новое соединение, копирует все временные таблицы в новое соединение, закрывает старое соединение, и это все не прерывая поток использующий старое соединение). Это очень важно, так как у PostgreSQL есть не совсем объяснимая утечка памяти на долгоживущих соединениях, использующих временные таблицы. Кстати этот же механизм перестарта соединений может использоваться в том числе для кластеризации. Баунсеры к сожалению такого делать не умеют (они просто ограничивают использование временных таблиц ЕМНИП).
ЗЫ: Есть еще пул временных таблиц в соединении, но это из другой оперы.
igor_suhorukov
Ох, давно жду in memory table в PostgreSQL
CrushBy Автор
Ну в целом, если у вас очень большие shared_buffers, и поставить очень долгий checkpoint, а wal вынести куда-нибудь отдельно, то чтения и записи диска будет минимально.
Другое дело, что конечно для хранения исключительно в памяти подойдет лучше другая архитектура. Но тогда непонятно, что делать с ACID, и как сделать, чтобы можно было использовать в OLTP системах.
igor_suhorukov
Исключительно для temporary table/тестов. Где совсем не нужна транзакционность и MVCC, WAL и все оверхеды в PostgreSQL связанные с ними.
Veidt
Ну в temporary table я бы не сказал, что прям совсем не нужна транзакционность. Потому как если в них хранятся какие-то (пусть и временные) данные, вы проводите транзакцию и, в том числе, изменяете эти временные таблицы (что бывает часто), а потом ловите скажем update conflict, то вам нужно заново начать транзакцию. И если вы не откатите временные таблицы на начало транзакции у вас будет нецелостное состояние и повторить транзакцию заново (что подразумевается при update conflict) уже не получится.
ptr128
Там, где ACID не обязателен, можно разгрузить wal при помощи unlogged table, используя их повторно с идентификатором процесса и очищая их delete.
CrushBy Автор
Да, такой подход возможен, но мы не можем это использовать, как минимум, по трем причинам. Во-первых, определенный ACID нужен (в том числе и для временных таблиц, чтобы при откате транзакции не потерялись в них данные). Во-вторых, временные таблицы создаются автоматически в разных случаях, и если держать unlogged table под все случае для всех разновидностей ключей/колонок - их будут тысячи. А в третьих, если все записывать в одну таблицу, то на 2000 пользователях, где у каждого будет по 100 записей, то в таблице будет 200.000 записей, и работа с ней будет значительно медленнее, чем с 2000 таблиц по 100 (скорее всего, даже не окупятся затраты на дополнительный DDL).
ptr128
Если не требуется индексов, то обхожусь массивами записей. Иногда даже когда нужна индексация, scan where в unnest даёт меньший оверхед, чем temp table с индексом. Собственно говоря, если добавить в массивы индексацию, то и получим in memory temp table.
CrushBy Автор
У нас временные таблицы создаются автоматически. И, к сожалению, заранее неизвестно сколько там будет записей (чаще всего, чтобы посчитать количество записей, которые вернет запрос, по сложности сопоставимо с выполнением самого запроса). И если там окажется 100.000 записей, то таким темпами можно забить всю память. А с временными таблицами есть защита, что в случае превышения temp_buffers они пойдут на диск.