
What's up guys!
В этой статье мы поговорим про NumPy. Это статья-шпаргалка для начинающих пользователей NumPy, надеюсь она будет вам полезна.
*Изначально я хотел выложить этот материал как курс по NumPy для новичков, но решил опубликовать в открытый доступ, поэтому не удивляйтесь, как сильно тут может быть что-либо разжёвано.

{kind=link}
Что же такое NumPy?
NumPy ( Numerical Python ) — это библиотека Python с открытым исходным кодом, которая используется практически во всех областях науки и техники. Это универсальный стандарт для работы с числовыми данными в Python, лежащий в основе научных экосистем Python и PyData. Пользователи NumPy включают всех, от начинающих программистов до опытных исследователей, занимающихся современными научными и промышленными исследованиями и разработками.
Библиотека NumPy содержит многомерные массивы и матричные структуры данных. NumPy можно использовать для выполнения множества математических операций с массивами. Он добавляет в Python мощные структуры данных, гарантирующие эффективные вычисления с массивами и матрицами, и предоставляет огромную библиотеку высокоуровневых математических функций, которые работают с этими массивами и матрицами.
Вот несколько областей, где NumPy активно используется:
Научные и инженерные вычисления;
Машинное обучение и искусственный интеллект;
Обработка данных;
Визуализация данных;
Высокопроизводительные вычисления;
Установка NumPy
Для того, что бы установить NumPy через pip воспользуйтесь командой:
pip install numpyЕсли вы используете Anaconda, то аналогично:
conda install numpyПеред использованием не забудьте также импортировать NumPy
import numpy as npМассивы в NumPy
В чем разница между списком Python и массивом NumPy?
NumPy предоставляет вам огромный выбор быстрых и эффективных способов создания массивов и манипулирования числовыми данными внутри них. Хотя список Python может содержать разные типы данных в одном списке, все элементы в массиве NumPy должны быть однородными. Математические операции, предназначенные для выполнения над массивами, были бы крайне неэффективны, если бы массивы не были однородными.
Зачем использовать NumPy?
Массивы NumPy быстрее и компактнее, чем списки Python. Массив потребляет меньше памяти (что очень важно для оптимизации скорости вычислений или используемой мощности) и удобен в использовании. NumPy использует гораздо меньше памяти для хранения данных и предоставляет механизм указания типов данных. Это позволяет еще больше оптимизировать код.
Массив — это центральная структура данных библиотеки NumPy. Массив представляет собой сетку значений и содержит информацию о необработанных данных, о том, как найти элемент и как его интерпретировать. Он имеет сетку элементов, которые можно индексировать различными способами . Все элементы одного типа, называемые массивом "dtype".
Массив может быть проиндексирован кортежем неотрицательных целых чисел, логическими значениями, другим массивом или целыми числами.
Пример инициализации одномерного массива:
a = np.array([1, 2, 3, 4, 5, 6])Я напомню, что np - это обращение к библиотеке NumPy. Мы сделали это при импортировании библиотеки для того, что бы каждый раз не писать numpy.
Обращение к элементам одномерного массива:
print(a[0])Этот код выведет первый элемент массива, в данном случае "1".
Пример инициализации двумерного массива:
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])Для справки: Двумерный массив (он же матрица) - это одномерный массив, элементами которого являются одномерные массивы. Другими словами, это набор однотипных данных, имеющий общее имя, доступ к элементам которого осуществляется по двум индексам.
Двумерные массивы удобнее записывать так:
a = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])При такой записи структура массива более понятна.
Обращение к элементам двумерного массива немного отличается, и если мы напишем так:
print(a[0])То мы получим: "[1, 2, 3, 4]", потому что это и есть первый элемент этого двумерного массива. А если нам надо обратится к конкретному значению, то мы должны использовать следующий код:
print(a[1][2])В этом случае будет выведено значение "7", находящееся во второй строке и третьем столбце матрицы. Для того что бы наглядно продемонстрировать, как это работает я написал такой код:
# 0 1 2 3
a = np.array([[1, 2, 3, 4], #0
[5, 6, 7, 8], #1
[9, 10, 11, 12]]) #2
print(a[1][2])Здесь под комментариями отмечены индексы элементов по строкам и столбцам. В обращении к конкретному элементу указывается сначала индекс строки, а потом столбца.
Для вывода массива можно использовать команду print.
a = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
print(a)В этом случае массив будет выведен так же как и записан:
#Вывод кода выше:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]Для "красивого" вывода этого массива поставьте "*" перед именем массива. Вот так:
print(*a)В этом случае вывод всегда будет в строчку:
#Вывод:
[1 2 3 4] [5 6 7 8] [ 9 10 11 12]Немного о типах данных, которые поддерживает NumPy.
Тип данных |
Описание |
|---|---|
|
Булевы значения ( |
|
Тип по умолчанию — целое число (то же, что |
|
Идентичный |
|
Целое число для использования в качестве индексов (то же, что и |
|
Байт (от — 128 до 127) |
|
Целое число (от -32768 до 32767) |
|
Целое число (от -2147483648 до 2147483647) |
|
Целое число (от -9223372036854775808 до 9223372036854775807) |
|
Целое число без знака (от 0 до 255) |
|
Целое число без знака (от 0 до 65535) |
|
Целое число без знака (от 0 до 4294967295) |
|
Целое число без знака (от 0 до 18446744073709551615) |
|
Обозначение |
|
Число с плавающей точкой половинной точности; бит на знак, 5-битная экспонента, 10-битная мантисса |
|
Число с плавающей точкой единичной точности; бит на знак, 8-битная экспонента, 23-битная мантисса |
|
Число с плавающей точкой двойной точности; бит на знак, 11-битная экспонента, 52-битная мантисса |
|
Обозначение complex128 |
|
Комплексное число, представленное двумя 32-битными |
|
Комплексное число, представленное двумя 64-битными |
Наиболее важными атрибутами объекта ndarray являются:
a.ndim - этот атрибут возвращает количество измерений массива.
Например такой код:
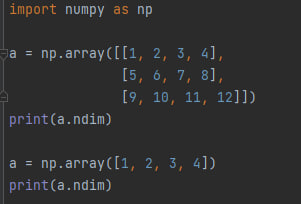
Вернёт 2, так как массив, который объявлен первым двумерный, и 1, так как массив, который объявлен вторым одномерный.
a.shape - возвращает кортеж, указывающий размер массива в каждом измерении.
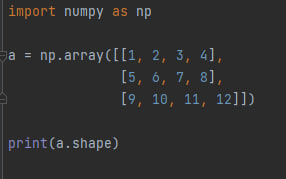
Код из примера выше вернёт (3, 4)так как массив a имеет 3 строки и 4 столбца.
a.size - возвращает общее число элементов массива (фактически это произведение элементов, возвращаемым shape)
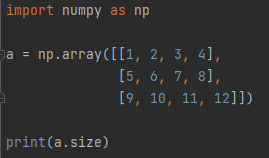
Как уже говорилось ранее код выше вернёт 12.
a.dtype - возвращает тип элементов массива. Кроме стандартных типов, в NumPy есть собственные типы данных. Об основных типах данных в NymPy мы поговорим в следующем шаге.

Обратите внимание на то, что этот код вернёт тип int32 (один из собственных типов NumPy), но если мы добавим в массив хотя-бы одно число с плавающей точкой, как здесь:
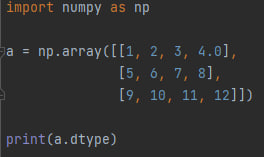
*обратите внимание на элемент в конце первой строки
В этом случае вывод будет float64, так как число 4.0 - относится к типу float.
a.itemsize - возвращает максимальный размер одного элемента в массиве в байтах. Для массива типа int32 вывод будет 4, а для массива типа float64 - 8.
Вот пара примеров:

Здесь массив a имеет тип int32, так как все элементы массива - целые числа. Вывод этой программы будет 4.
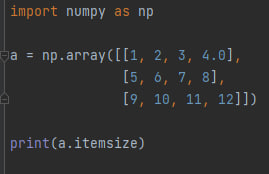
Вывод этого кода будет 8, так как имеет один элемент типа float, а это значит что тип массива - float64.
a.diagonal() - возвращает диагональ матрицы. В скобках можно указать индекс первого элемента диагонали (по умолчанию - 0). Пример:
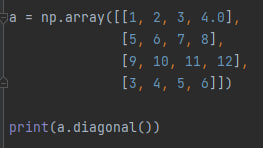
Я использовал квадратную матрицу, где число столбцов равно числу строк, но этот метод работает так же и с прямоугольными матрицами. Этот код вернёт: [ 1. 6. 11. 6.].
a.sum() - возвращает сумму всех элементов массива.
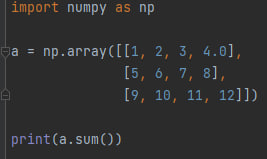
К примеру этот код вернёт 78.0. Дополнительный 0 появляется потому что в массиве присутствуют дробные числа.
a.mean() - возвращает средне арифметическое всех элементов массива. Пример:
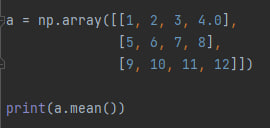
Этот код вернёт 6.5
Кроме этого существуют функции min() и max(), которые возвращают минимальное и максимальное значение из элементов массива, а так же argmin() и argmax(), которые возвращают индексы наименьшего и наибольшего элементов массива соответственно.
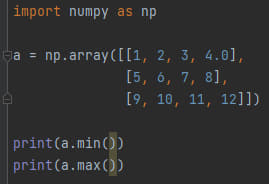
Это код вернёт 1.0 и 12.0.
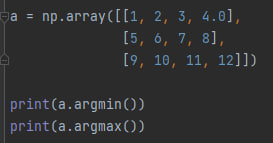
А этот 0 и 11, именно такие индексы имеют элементы со значением 1 и 12.
Основные функции NumPy
np.zeros((n, m)) - создаёт массив размером n*m, заполненный нулями. Из полезных дополнительных функций - после кортежа с размерностью массива вы можете указать тип элементов в массиве (это не обязательно, по умолчанию - float64). Пример использования:
import numpy as np
a = np.zeros((2, 4), int)
print(a)Этот код выведет такой массив:
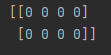
Если бы я не указал тип данных или указал бы float он выглядел бы так:

Здесь нули после точки просто "опущены".
np.ones((n, m)) - создаёт массив размером n*m, заполненный единицами. Работает так же точно как и np.zeros(). Пример:
import numpy as np
a = np.ones((2, 3))
print(a)Код выведет такую матрицу:
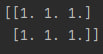
np.empty((n, m)) - возвращает пустой (не инициализированный) массив размером n*m. Он заполнен "мусором". Используя такие массивы будете осторожны, а лучше всегда задавайте начальные значения элементов массива. Атрибуты такие же как и у предыдущих функций.
Использование:
import numpy as np
a = np.empty((2, 3))
print(a)Вывод (на каждом компьютере каждый раз будет разным):

Ещё раз повторю: НЕ рекомендую использовать.
np.copy(a) - создаёт копию массива a. Применение:
import numpy as np
a = np.array([[1, 2, 3, 4.0],
[5, 6, 7, 8],
[9, 10, 11, 12]])
b = np.copy(a)
print(b)Вывод это программы будет такой:
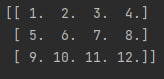
Кроме этого для создания копии массива мы можем использовать np.array(a, copy=True). Это будет так:
import numpy as np
a = np.array([[1, 2, 3, 4.0],
[5, 6, 7, 8],
[9, 10, 11, 12]])
b = np.array(a, copy=True)
print(b)Вывод будет идентичен выводу предыдущего кода.
np.eye(n) - создаёт квадратную матрицу (параметр n - число столбцов = числу строк) с единицами на главной диагонали (от верхнего левого до нижнего правого угла), остальные позиции занимают нули.
Вы можете использовать это примерно так:
import numpy as np
a = np.eye(4)
print(a)В этом случае вы получите такой ответ:
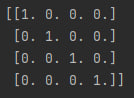
Кстати, после параметра n вы так же можете указать тип данных.
np.dot(a, b) - скалярное произведение двух массивов. В коде его можно записывать по разному, например a.dot(b) или a @ b - тоже будут работать. Пример:
*для демонстрации работы этой функции я использую другой набор массивов, нежели чем у остальных (так надо, потом поймёте)
import numpy as np
a = np.array([[1, 2, 3, 4.0],
[5, 6, 7, 8],
[9, 10, 11, 12],
[3, 4, 5, 6]])
b = np.eye(4)
print(np.dot(a, b))
print(a.dot(b))
print(a @ b)Массив a - объявлен в коде, а массив b - это матрица с единицами на главной диагонали (она же единичная матрица).
Все эти строки кода выведут один и тот же результат:
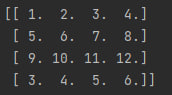
Кстати, хочу обратить ваше внимание на интересное свойство единичной матрицы. При умножении на неё массив не меняется, как например здесь, массив a после умножения на единичную матрицу b не изменился. Эта особенность используется достаточно часто, например в глубоком обучении.
np.prod(a) - преумножение всех элементов в массиве. Пример использования:
print(np.prod(a))Этот код вернёт:
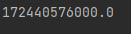
np.sin(), np.cos(), np.tan() и т.д. - вернёт синус, косинус, тангенс и т.д. соответственно. Могут быть применены как к одному числу, так и к массиву с любым числом измерений. Пример:
import numpy as np
a = np.array([[1, 20, 0, 6],
[5, 4, 7, 8.0],
[9, 0, 110,0],
[2, 4, 5, 6]])
print(np.sin(a))
print(np.cos(a))
print(np.tan(a))
print(np.sin(45))
print(np.cos(90))
print(np.tan(45))Комментировать этот код я не буду, я думаю, что здесь всё и так понятно. Вот что этот код выведет (для удобства чтения между "принтами" я добавил пустую строку):
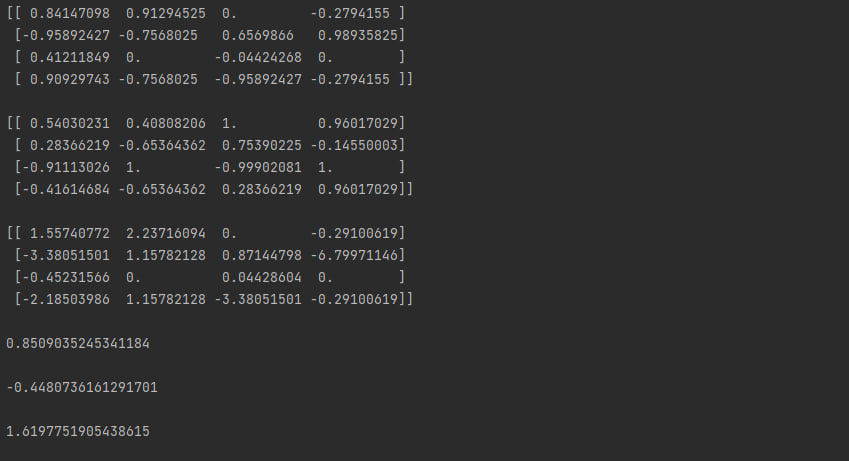
Как мы видим все эти функции отлично работают и с массивами и с отдельными числами.
np.sqrt() - возвращает квадратный корень числа или массива в скобках. Пример:
import numpy as np
a = np.array([[1, 20, 0, 6],
[5, 4, 7, 8.0],
[9, 0, 110,0],
[2, 4, 5, 6]])
print(np.sqrt(a))
print(np.sqrt(25))И, вывод этого кода:

Все остальные функции для работы с массивами в общем то совпадают с обычными математическими операциями. В NumPy они выполняются поэлементно и каждую из них при желании можно заменить вложенными циклами. Далее я приведу таблицу доступных операций и примеры их использования.
Операция |
Описание |
+ |
Сложение массивов или массива с числом |
- |
Вычитание массивов или массива с числом, либо используется как унарный минус |
* |
Умножение массивов или массива с числом |
/ |
Деление массивов или массива с числом |
// |
Целочисленное деление массивов или массива с числом |
** |
Возведение в степень (указывается или число или массив) |
% |
Вычисления остатка от деления (указывается или число или массив) |
import numpy as np
a = np.array([[1, 2, 3, 4.0],
[5, 6, 7, 8],
[9, 10, 11, 12],
[3, 4, 5, 6]])
b = np.array([[2, 3, 5, 6],
[3, 2, 7, 9],
[2.3, 6, 6, 7.0101],
[2.5, 5, 4, 5.0]])
print(a + b)
print(a - b)
print(a * b)
print(a / b)
print(a // b)
print(a % b)
print(a ** 2)Вы можете переписать этот код у себя и посмотреть вывод этого кода, я не стал помещать его сюда, так как он очень большой и не очень понятный с первого взгляда.
Кроме этого вы можете получить все уникальные элементы из массива, используя функцию np.unique(). Пример её использования:
import numpy as np
b = np.array([[2, 3, 5, 6],
[3, 2, 7, 9],
[2.3, 6, 6, 7.0101],
[2.5, 5, 4, 5.0]])
print(np.unique(b))Как видим, в массиве b имеются повторяющиеся элементы, после вызова функция выведет только уникальные, т.е.:
[2. 2.3 2.5 3. 4. 5. 6. 7. 7.0101 9. ]
Сортировка массива NumPy:
np.sort(a) - эта функция возвращает отсортированную копию входного массива. Сам массив при этом не изменяется.
Давайте я покажу вам, как это работает, а заодно приведу пример работы с сортировкой:
import numpy as np
a = np.array([[1, 20, 3, 6],
[5, 4, 7, 8],
[9, 10, 110, 12],
[2, 4, 5, 6]])
print(f"{a} \n")
print(np.sort(a))
print(f"\n {a} \n")
*Символы \n означают перенос на следующую строку.
Вывод этого кода будет примерно таким:
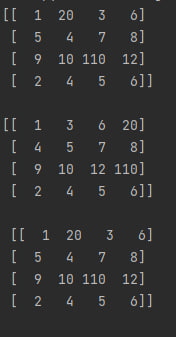
Как мы видим, первая строка print(f"{a} \n") должна вывести оригинальный массив. Затем строка print(np.sort(a)) выводит отсортированный массив не изменяя его при этом. И в конце строка print(f"\n {a} \n") опять выводит оригинальный массив. Между выводами массивов проставлены пропуски строки для наглядности.
Кроме этого, обратите внимание на то, что массив сортируется построчно. Для того, что бы отсортировать его по "столбцам" необходимо указать параметр 0 через запятую, после названия массива. В этом случае код будет выглядеть так:
import numpy as np
a = np.array([[1, 20, 3, 6],
[5, 4, 7, 8],
[9, 10, 110, 12],
[2, 4, 5, 6]])
print(np.sort(a, 0))И работать так:
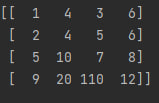
Если вы хотите отсортировать массив и при этом перезаписать его используя np.sort(), сделайте так:
import numpy as np
a = np.array([[1, 20, 3, 6],
[5, 4, 7, 8],
[9, 10, 110, 12],
[2, 4, 5, 6]])
a = np.sort(a)
print(a)
В данном случае мы просто перезаписываем переменную. Вывод этого кода такой же как и в первом случае.
np.argsort(a) - возвращает как бы "массив с индексами", указывающий на то как был отсортирован массив. Пример использования:
import numpy as np
a = np.array([[1, 20, 3, 6],
[5, 4, 7, 8],
[9, 10, 110, 12],
[2, 4, 5, 6]])
print(np.argsort(a))
print("")
print(a)
И вывод этого кода:

Здесь сначала выводится массив индексов, а затем оригинальный массив для сравнения. Что бы лучше разобраться с работой этого участка кода я рекомендую переписать его у себя и попробовать "поиграться" со значениями элементов массива.
Ещё некоторые функции:
np.random.random() - возвращает массив чисел типа float в диапазоне от 0.0 до 1.0. На вход принимает длину списка. Пример использования:
import numpy as np
print(np.random.random(6))
Вывод:

np.random.randint() - возвращает случайное целое число в указанном диапазоне. Третьим параметром size можно передать длину возвращаемого массива. По умолчанию она равна 1. Пример использования:
import numpy as np
print(np.random.randint(0, 10, size=10))
Вывод:

np.random.rand(n, m) - принимает на вход два параметра и возвращает массив, заполненный случайными числами, размера n*m. Пример:
import numpy as np
print(np.random.rand(3, 3))Вывод будет выглядеть примерно так:

np.ramdom.normal(n, m, size=(x, y)) - возвращает выборку из нормального (гауссовского) распределения, где n - "центр" распределения, m - отклонение, а кортеж в параметре size - размеры возвращаемого массива (x*y). Пример использования:
import numpy as np
print(np.random.normal(1, 3, (3, 2)))
И вывод этого кода:
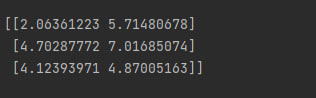
np.arange(n, m, x) - возвращает массив, где n - начало, m - конец а x - "шаг" между элементами массива. Пример:
import numpy as np
print(np.arange(0, 25, 5))
Вывод:

На этом статья подошла к концу. Если я что-то забыл или где-то ошибся - пишите в комментарии или ЛС.
От автора:
Спасибо, что дочитали статью до конца, надеюсь она была вам полезна и сэкономила вам время. Если хотите повлиять на выход дальнейших статей, то можете подписаться на мой telegram-канал, там в том числе будут опросы касаемо выходов новых статей а так же разнообразные интересные материалы (это статья в pdf там тоже будет). Если хотите со мной связаться или предложить тему для статьи - мои контакты есть на сайте.
Ещё раз спасибо, что дочитали до сюда!
Удачи!
mc2
Немного прикладного смысла к данной статье:
https://pabloinsente.github.io/intro-linear-algebra