

Друзья, всем привет! Идемпотентность в проектировании API — не просто формальность. Это свойство, часто рассматриваемое как способ получения одинакового ответа на повторяющийся запрос, на самом деле означает гораздо больше...
Так что же такое идемпотентность?
Идемпотентность запроса — это обеспечение возможности многократного вызова запроса с гарантией того, что состояние системы изменится только один раз.
В условиях нестабильного мира, в котором клиенты и серверы подвержены временным сбоям и разрывам соединения в процессе обмена запросами, идемпотентность становится незаменимым инструментом для повышения устойчивости системы.
Идемпотентность «из коробки»
Понимание того, когда дополнительный контроль идемпотентности необходим, а когда его можно избежать, является важным аспектом разработки API. Если все внешние системы, с которыми взаимодействует сервис, обладают свойством идемпотентности, то дополнительный контроль на стороне API сервиса может быть излишним. В таких случаях запросы к внешним системам могут быть повторены без опасений, поскольку они обеспечивают гарантию однократного изменения состояния системы.
Использовать идемпотентность «из коробки» в таких сценариях является эффективным решением, поскольку это упрощает код и снижает вероятность ошибок, связанных с управлением идемпотентностью вручную.
Контроль идемпотентности
Неидемпотентные действия характеризуются тем, что их выполнение может привести к изменениям в системе, и эти изменения не могут быть гарантированно повторены без возможных побочных эффектов. Примеры неидемпотентных действий: отправка электронного письма, создание новой сущности без явного уникального идентификатора. Если хотя бы одно действие в запросе является неидемпотентным, то таким считается и весь запрос. Для обеспечения идемпотентности таких запросов нужно дополнительно контролировать на уровне API сервиса. Контроль включает в себя использование уникальных идентификаторов запросов (ключей идемпотентности) и логику обработки возможных конфликтов.
Ключ идемпотентности
Ключ идемпотентности — это уникальное значение, которое создаётся на стороне клиента и отправляется на сервер вместе с запросом. Ключ является инструментом для идентификации и контроля за повторными запросами. Для него рекомендуется использовать формат UUID.
Когда клиент желает повторить запрос, он отправляет новый, включая тот же ключ идемпотентности:
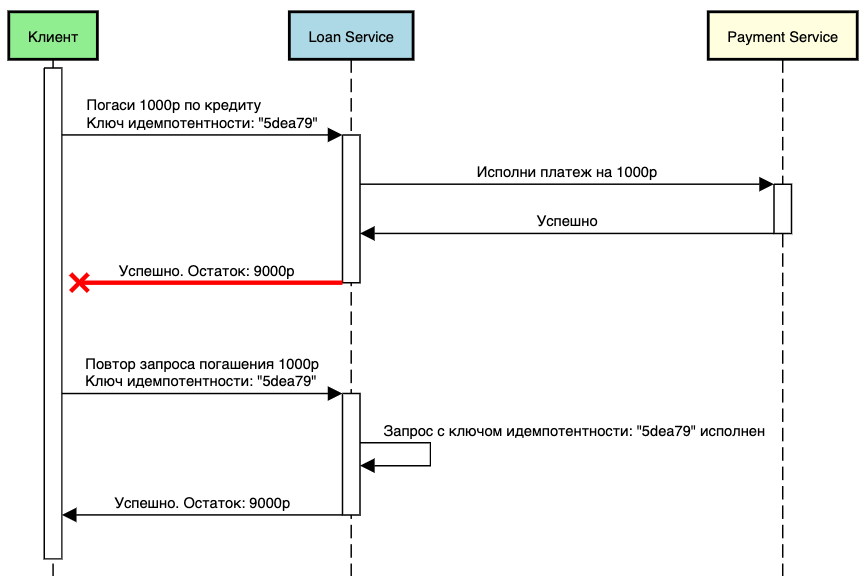
Но если бы запрос к сервису Loan не обладал свойством идемпотентности, то произошла бы следующая ситуация при повторе запроса:
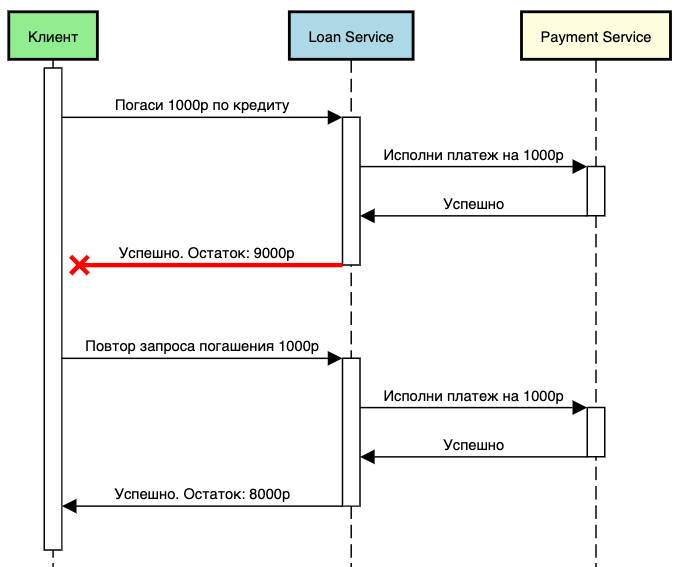
Где контролировать идемпотентность
Вопрос о том, где следует контролировать идемпотентность, становится важным на этапе разработки. Хотя добавление логики контроля в контроллер может показаться простым решением, оно не является оптимальным. Вместо этого предпочтительнее внедрить блок контроля идемпотентности между клиентом и контроллером с бизнес логикой, на уровне инфраструктуры:

Такой подход обладает несколькими преимуществами:
- Снижение зависимости от изменений в бизнес-логике контроллера. Это означает, что изменения в бизнес-логике не повлияют на механизм идемпотентности, что обеспечивает более гибкую и устойчивую систему.
- Унификация логики обработки для всех запросов. Это упрощает поддержку и обеспечивает единый стандарт в системе.
Выбрав подходящее место для контроля идемпотентности, необходимо также определить, какие функции будет выполнять этот блок.
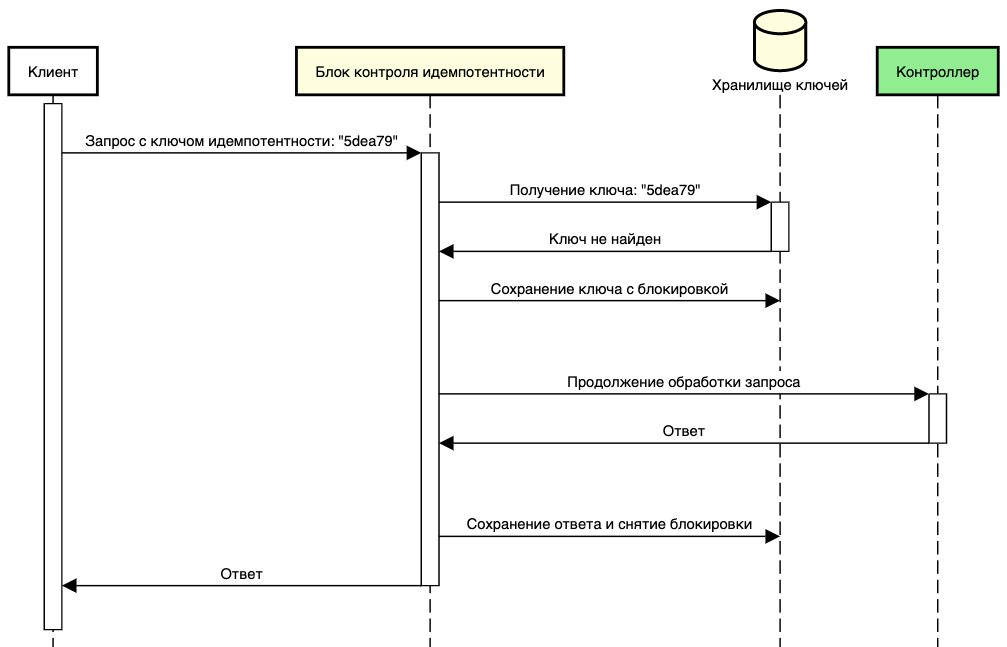
Обработка нового запроса
При поступлении нового запроса с уникальным ключом идемпотентности необходимо осуществить обработку, состоящую из следующих шагов:
- Новый запрос с уникальным ключом идемпотентности требует сохранения соответствующей информации в хранилище данных. Это позволяет отслеживать состояние запроса и его уникальный ключ.
- Для предотвращения возможных конфликтов блокировка устанавливается на этапе обработки запроса. Она гарантирует, что операции будут выполнены последовательно и предотвращает параллельную обработку запросов с одним ключом идемпотентности.
- Исполнение бизнес-логики контроллера.
- По завершении исполнения запроса блок отвечает за сохранение ответа в хранилище данных. Это позволяет клиенту получить тот же результат при повторном запросе.
- После сохранения ответа, блок освобождает блокировку, позволяя другим запросам с тем же ключом идемпотентности продолжить своё выполнение.
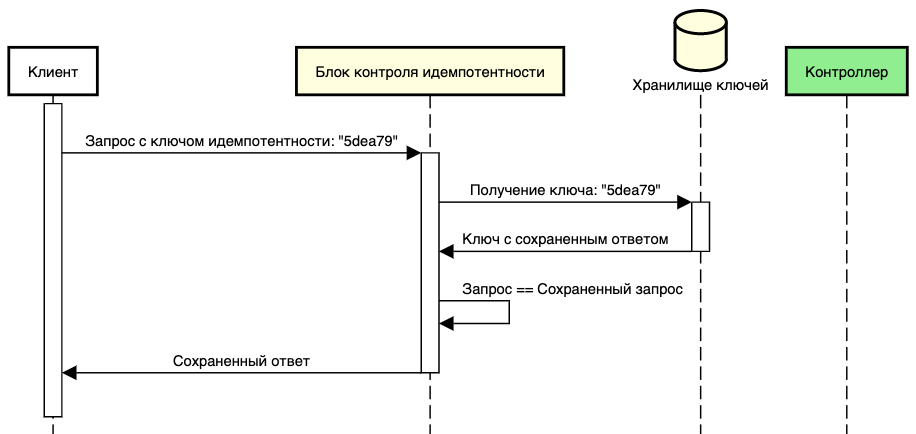
Повторная обработка запроса
Обработка повторного запроса, состоит из следующих этапов:
- Блок контроля идемпотентности проверяет наличие ключа из текущего запроса в хранилище данных.
- Если ключ уже имеется в хранилище и связан с сохранённым ответом, то блок возвращает этот ответ, обозначая успешное завершение запроса.
- Дальнейшая обработка запроса и выполнение бизнес-логики контроллера не происходят, поскольку запрос уже успешно обработан.
Такой механизм обеспечивает идемпотентное исполнение повторного запроса и, как следствие, предотвращает избыточные вычисления, связанные с повторной обработкой запроса, что способствует повышению эффективности и отзывчивости системы.
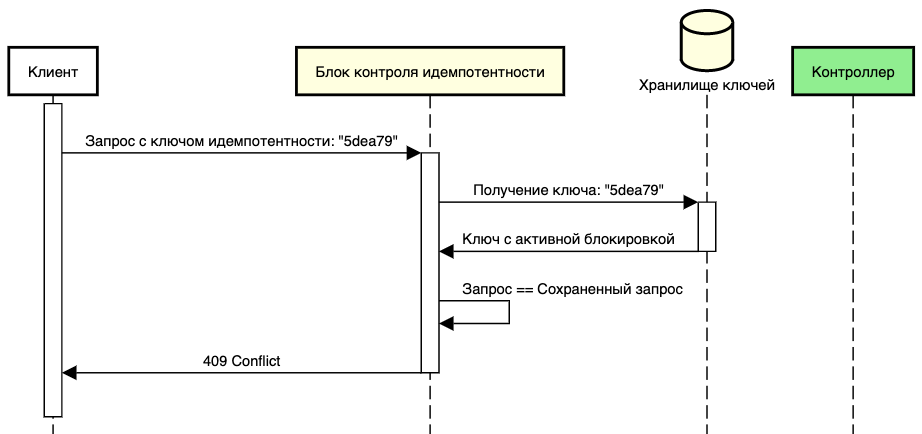
Обработка запроса при активной блокировке
Одной из ключевых задач блока контроля идемпотентности является предотвращение параллельного исполнения конфликтующих запросов с использованием одного ключа. Для этого важно устанавливать блокировку на время обработки запроса. Одним из вариантов обработки запроса с заблокированным ключом является возврат ошибки с кодом 409 Conflict.
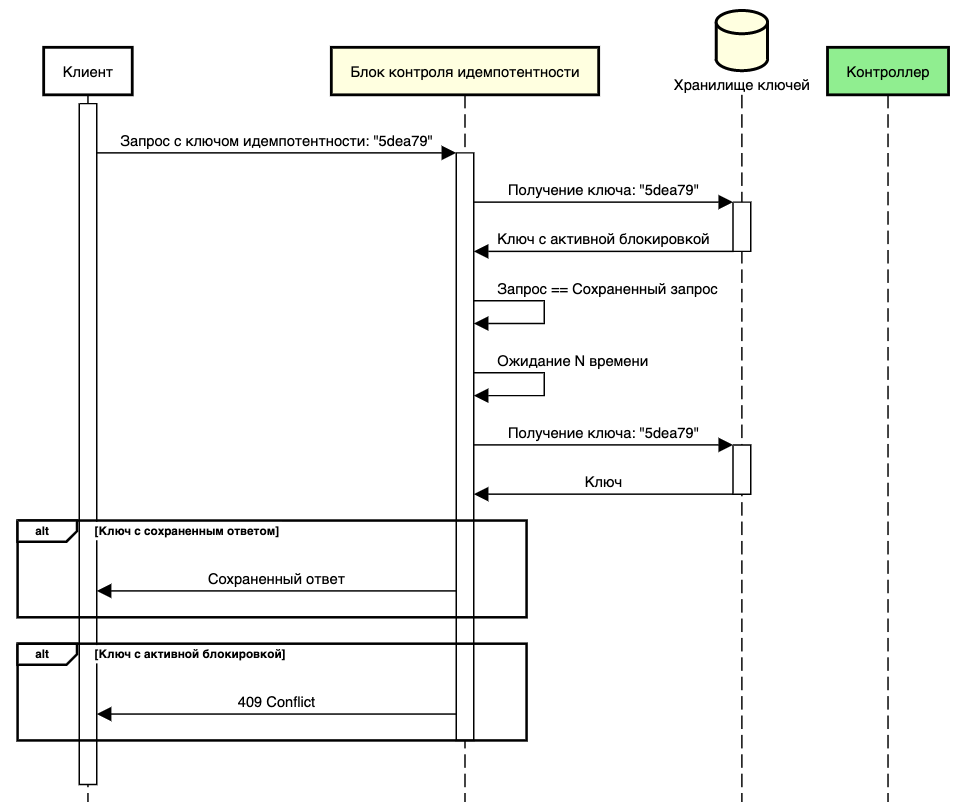
Для улучшения клиентского опыта, помимо ошибки 409 Conflict можно также возвращать информацию о времени, через которое клиенту стоит повторить запрос. Это делается с помощью заголовка Retry-After. Когда мы возвращаем его, мы переносим ответственность за повтор запроса на сторону клиента. Но можно использовать более гибкий подход к обработке запросов с заблокированным ключом, оставив часть ответственности на стороне сервера.
Получив запрос с заблокированным ключом идемпотентности, включается режим ожидания. Через определённый период мы проверяем, завершил ли текущий обладатель блокировки выполнение запроса. Если ответ уже готов, то мы направляем его клиенту, создавая впечатление успешного выполнения бизнес-логики запроса. При этом предотвращаем повторное исполнение, гарантируя идемпотентность. В случае отсутствия готового ответа после ожидания, мы можем также вернуть ошибку 409 Conflict, сообщая клиенту о невозможности повторного выполнения запроса в настоящий момент. Такой гибкий и невидимый для клиента подход обеспечивает более плавное взаимодействие, минимизируя его вовлечённость в управление временем повтора запросов.
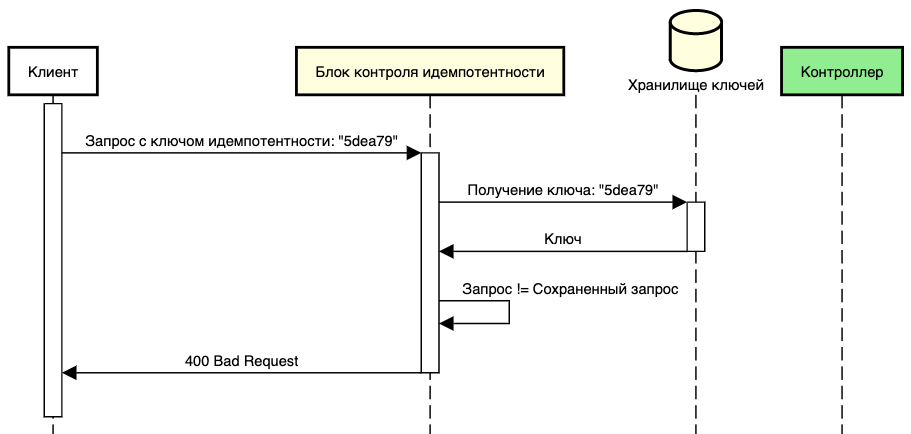
Обработка изменённого запроса
В ходе обработки необходимо сопоставлять запросы, где ключ служит лишь одним из критериев. Мы должны сравнить текущий запрос с тем, который уже был исполнен с этим ключом. Это необходимо для предотвращения потенциальных угроз безопасности сервиса. Блок контроля идемпотентности нацелен на полное исключение возможности возврата сохранённого ответа на изменённый запрос, опираясь исключительно на совпадение ключа идемпотентности. В случае выявления несовпадений между запросами система немедленно выдаёт ошибку с кодом 400 Bad Request. Это обеспечивает защиту от подобных сценариев.
Блок контроля идемпотентности должен обеспечивать высокую степень настройки при сравнении запросов, обеспечивая максимальную гибкость в реализации API. При сопоставлении необходимо обязательно учитывать соответствие HTTP-метода и URI-путей. Можно добавить дополнительные варианты проверок, такие как:
- Возможность учитывать содержимое тела запроса при определении идентичности запросов.
- Учёт различий в заголовках запросов для дополнительной точности идемпотентного сравнения.
- Сравнение параметров запросов.
- Учёт временных меток запросов для предотвращения возможных конфликтов.
Детали реализации
После определения расположения и ключевых требований к блоку контроля идемпотентности давайте рассмотрим некоторые детали практической реализации.
Контроль идемпотентности в Spring MVC
В рамках Spring MVC для реализации логики контроля идемпотентности наилучшим образом подходят перехватчики Handler Interceptor. Действуя после DispatcherServlet и перед контроллером, они обеспечивают мощный инструмент предварительной обработки запросов, а также позволяют формировать ответы и проводить постобработку на стадии возврата ответа.
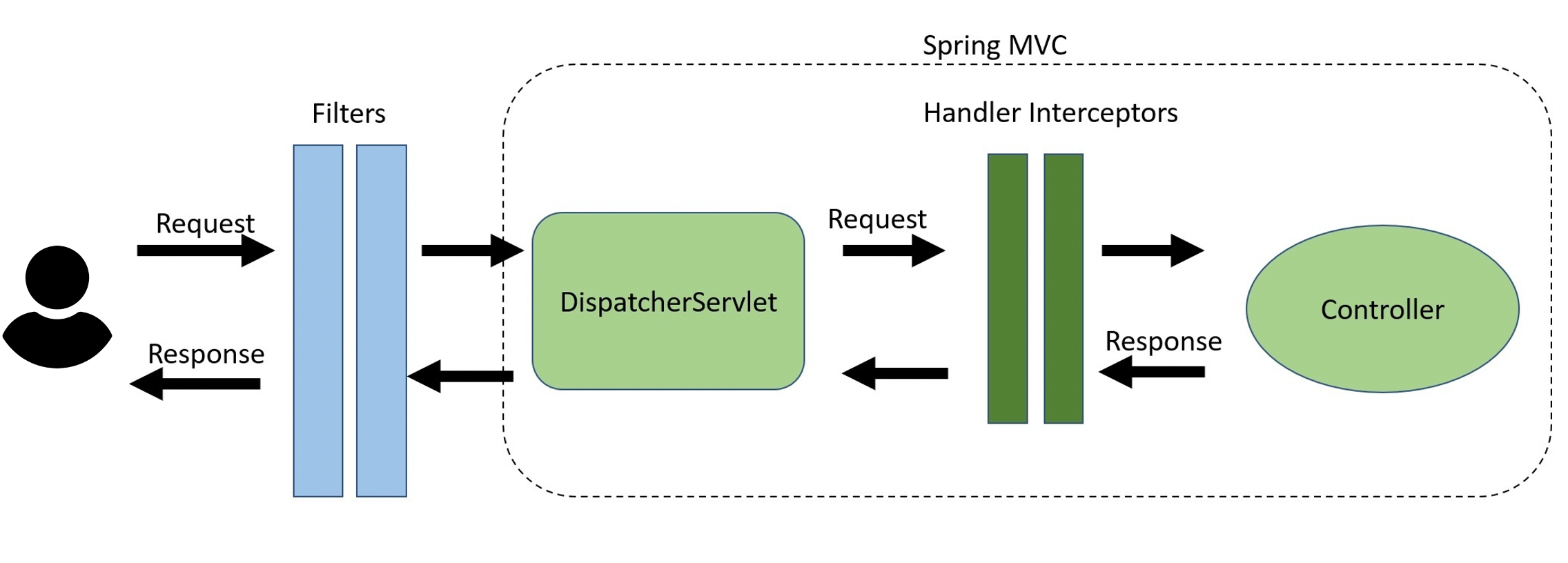
Перехватчик
Для начала создайте класс перехватчика:
public class IdempotentControlInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// Логика, выполняемая перед выполнением контроллера
return true; // true - продолжить выполнение запроса, false - прервать выполнение
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
// Логика, выполняемая после выполнения контроллера, но до формирования ответа
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// Логика, выполняемая после завершения обработки запроса и формирования ответа
}
}Потом зарегистрируйте созданный перехватчик в конфигурации Spring MVC. Это можно сделать с помощью определения бина WebMvcConfigurer.
@Configuration
public class WebConfig {
@Bean
public WebMvcConfigurer idempotencyWebConfigurer() {
return new WebMvcConfigurer() {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new IdempotentControlInterceptor());
}
}
}
}Теперь IdempotentControlInterceptor будет выполняться перед и после каждого HTTP-запроса, позволяя встроить логику контроля идемпотентности в приложение.
Проблема InputStream и OutputStream в HttpServletRequest и HttpServletResponse
В стандартной реализации HttpServletRequest для доступа к телу запроса требуется использовать InputStream, который разрешает чтение только единожды. Для поддержки многократного доступа к телу запроса можно использовать класс-обёртку: org.springframework.web.util.ContentCachingRequestWrapper.
Аналогичная проблема возникает и с HttpServletResponse, и с объектом OutputStream. Для возможности повторного доступа к телу ответа применяется: org.springframework.web.util.ContentCachingResponseWrapper.
Важно отметить, что переопределение объекта запроса или ответа в HandlerInterceptor невозможно, но это можно сделать с помощью фильтра.
Использование классов-обёрток обеспечивает необходимую гибкость и многократный доступ к содержимому запроса и ответа в процессе их обработки.
public class ContentCachingFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
// Оборачиваем запрос и ответ
ContentCachingRequestWrapper cachingRequest = new ContentCachingRequestWrapper(request);
ContentCachingResponseWrapper cachingResponse = new ContentCachingResponseWrapper(response);
try {
// Передача обернутых запроса и ответа по цепочке фильтров
filterChain.doFilter(cachingRequest, cachingResponse);
} finally {
// Очистка буферов
cachingResponse.copyBodyToResponse();
}
}
}Класс OncePerRequestFilter гарантирует, что doFilterInternal будет вызван только один раз для каждого запроса. Чтобы фильтр начал участвовать в обработке запросов, его необходимо зарегистрировать.
Хранилище ключей
Для удовлетворения функциональных требований блока контроля идемпотентности необходимо наличие хранилища, в котором будут храниться ключи и связанная с ними информация о запросах. Хранилище играет одну из основных ролей в обеспечении идемпотентности запросов, предоставляя механизм для отслеживания уникальных ключей и связанных с ними данных. Выбор подходящего хранилища зависит от требований к производительности, масштабируемости и сохранности данных.
Пример схемы хранилища для реляционной СУБД: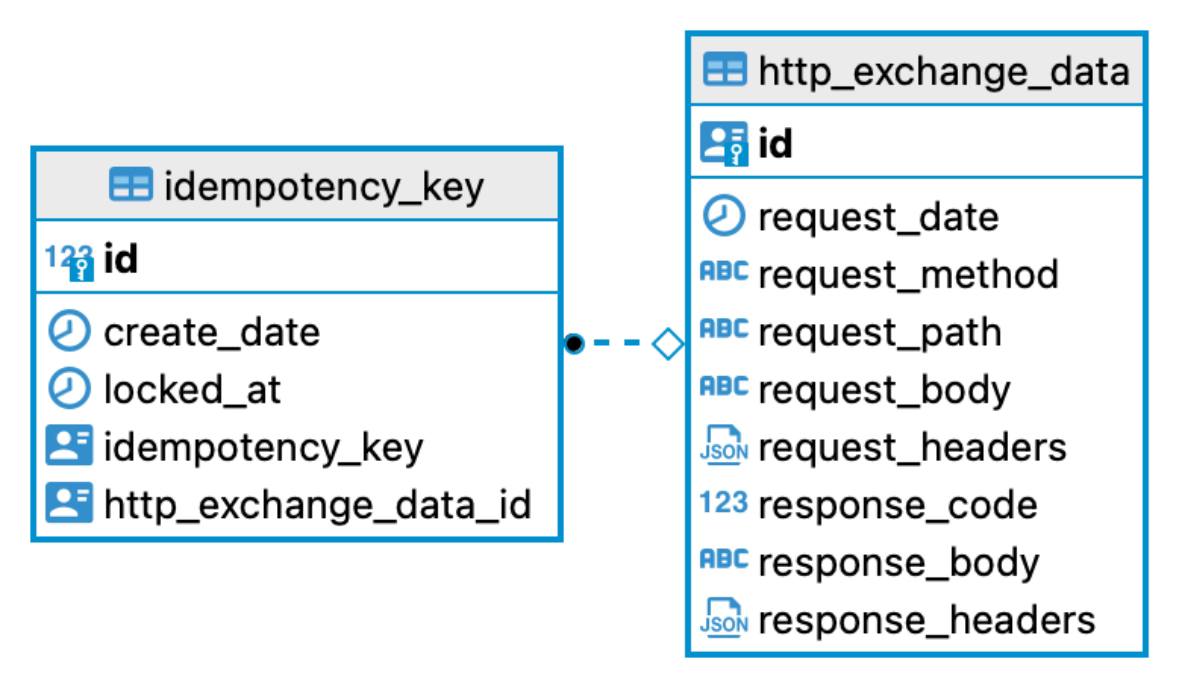
Способы извлечения ключей
При реализации блока контроля идемпотентности необходимо также уделить внимание способу извлечения ключа из запроса. Обычно его передают в заголовке Idempotency-Key. Однако существуют сценарии, когда ключ может содержаться в теле запроса или в query-параметрах.
Блок контроля идемпотентности проектируется как инфраструктурный компонент, который может переиспользоваться в различных сервисах. Для адаптации к разнообразным сценариям использования необходимо реализовать механизм настройки способа извлечения ключа. Интерфейс для извлечения из запроса предоставляет возможность расширения функциональности блока контроля идемпотентности, минимизируя изменения в его структуре:
public interface KeyExtractor {
Optional<IdempotencyKey> extractKey(HttpServletRequest request);
}Нужно ли контролировать все запросы?
Необходимость в контроле каждого запроса часто представляется избыточной, особенно учитывая, что не все запросы требуют строгого контроля идемпотентности. Например, информационные запросы, или запросы, предназначенные для повторного выполнения, могут быть освобождены от дополнительных проверок.
Для эффективного контроля идемпотентности через Handler Interceptor разумно применять селективный подход. Для определения тех запросов, которые нуждаются в контроле, можно использовать аннотации на уровне контроллера или его методов.
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Idempotent {
long lockExpireTime() default 30L;
TimeUnit lockExpireTimeUnit() default TimeUnit.SECONDS;
Class<? extends KeyExtractor>[] keyExtractors() default {HeaderKeyExtractor.class};
Class<? extends RequestEqualityChecker> requestEqualityChecker() default DefaultRequestEqualityChecker.class;
}Аннотация Idempotent позволяет тонко настроить параметры контроля идемпотентности, подстраиваясь под конкретные требования каждой конечной точки и обеспечивая высокую степень адаптации. С помощью аннотации можно настроить максимальное время удержания блокировки, чтобы обрабатывать ситуации с вечными блокировками, а также выбрать реализации для извлечения ключа из запроса и определить метод сравнения запросов.
Управление блокировками
Поскольку мы решили устанавливать блокировку на время обработки запроса, необходимо снимать её как при успешном исполнении запроса, так и при неуспешном, когда установленное время блокировки истечёт. Блокировка снимается, когда ответ из контроллера поступает в блок контроля идемпотентности. Блок должен успешно сохранить ответ и лишь затем освободить блокировку. Но возможны ситуации, когда этот процесс не удаётся выполнить, например из-за сбоя в системе. В таких случаях важно внедрить механизм автоматического освобождения блокировок, предотвращая их «вечное» удержание.
Важно также рассмотреть стратегию обработки запросов с блокировкой, которая устарела из-за истечения времени. Если сервис может восстановить контекст исполнения запроса, такие запросы можно рассматривать как новые. Если восстановление контекста невозможно, то лучше сообщить клиенту о невозможности продолжения обработки запроса, предотвращая возможные нарушения идемпотентности.
Ограничение времени жизни (TTL) для ключей идемпотентности
Долгосрочное хранение ключей избыточно, поскольку они остаются актуальными лишь в течение короткого времени, когда исполняются повторные запросы. Обычно значение TTL для ключей составляет 1 день, что обеспечивает баланс между эффективным освобождением ресурсов и достаточным временем для поддержки идемпотентности в различных сценариях использования.
Заключение
Учёт возможности сбоев в распределённой системе и способов их устранения имеет первостепенное значение для создания надёжных и предсказуемых API. Достичь этого позволяют логика повторов на клиенте и идемпотентность на сервере.
Идемпотентность — очень важная концепция для построения устойчивых систем, поэтому при проектировании необходимо учитывать это свойство. Хотя основная идея кажется, на первый взгляд, простой, реализация может быть более или менее сложной в зависимости от базовой архитектуры системы и требований.
Всем нам успехов в разработке гибких и надежных API! ????
Комментарии (4)

EasyGame
19.12.2023 09:27Защита от дюпа для начинающих. Да еще и с блокировкой запроса. Но зато много-много умных слов.
На самом деле этот подход просто отправит систему в аут при наличии 10-20 RPS по такой схеме. Просто мечта дудосера.


vic_1
19.12.2023 09:27А транзакции в БД уже перестали работать? Кейс на превой картинке укладывается в транзакционный запрос или это очередные микросервисы?
ris58h
На моменте взятия блокировки в БД создаётся запись о текущей операции?
Как обрабатывается ситуация, когда ошибка произошла на этапе снятия блокировки или сохранения информации о выполненном запросе?