

Привет! С вами Дмитрий Пшевский и Семён Попов, технические лидеры юнита Data в Сбере. Это вторая часть нашего материала о производительности сервисов при работе с Ignite.
В первой части мы рассказали, как перешли от монолита к микросервисной архитектуре, попробовали поработать с толстым клиентом и переключились на тонкого. Расскажем, какие сложности у нас возникли в процессе эксплуатации нашего решения в облачной инфраструктуре, почему пришлось минимизировать транзакционную логику на клиенте и к чему мы пришли в итоге. Статья написана на основе нашего доклада на JPoint 2023.
Поехали!
Какие были сложности
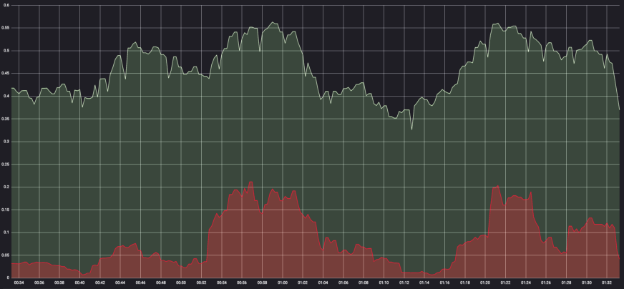
Как мы рассказывали раньше, мы перешли к использованию тонкого клиента. Но в какой-то момент транзакции периодически начали исполняться с замедлениями, и время отклика могло увеличиться на порядок. График ниже иллюстрирует этот процесс:

После комплексного анализа всех системных и прикладных метрик на сервисе мы начали обвинять в проблеме Apache Ignite. К счастью, у этой системы хорошая observability (наблюдаемость). И график ниже помог нам выявить корень проблемы.

Левая гистограмма показывает время выполнения транзакций на серверном узле (System Time), справа — на клиентском узле (User Time). Таким образом, получается, что на клиенте транзакция выполняется почти в 250 раз дольше, чем на самом кластере.
Что же могло привести к такой разнице?
После анализа прикладного кода и других плясок с бубном мы пришли к неутешительному для нас выводу: виновато облачное окружение. Наверняка почти все при развёртывании контейнеров в облаке выставляют requests и limits. Request — это требование, по которому оркестровщик ищет свободную ноду. А limit — физическое ограничение со стороны ОС, а именно — со стороны CFS bandwidth controller. Если выставить квоту в 600 millicore (0.6 CPU) на контейнер, контроллер сможет использовать 60 мс времени процессора каждые 100 мс. А если всё доступное время CPU потрачено, то это может привести к остановке исполнения пользовательского процесса. Это явление называется троттлинг (throttling).

При этом на графике среднего потребления CPU проблемы мы можем вообще не увидеть.

Так как же нам найти проблему?

Если для сбора системных метрик у вас используется cAdvisor, советуем добавить метрику container_cpu_cfs_throttled_seconds_total в графики и обращать внимание на её значение. Так, проблему мы нашли, но как её исправить?
В качестве быстрого решения можно увеличить лимиты или вообще их убрать. Но это может привести к нехватке ресурсов на самой worker node, и мы получим похожий результат, но уже для всех сервисов, развернутых на этой ноде.
Кроме того, в эксплуатации у нас выставлена переподписка с коэффициентом 3. Это значит, что на один физический CPU у нас будет приходиться три виртуальных. При полной нагрузке на ноду ресурсов хватит не всем. Если бы наш сервис не работал напрямую с Apache Ignite, наверное, можно было бы выставить на прикладном уровне таймауты поменьше и делать повторы на другие поды сервиса. Но это решение подходит не всем, и мы тоже увидели риски. Давайте посмотрим, как тонкий клиент работает с транзакциями. Он должен открыть транзакцию, выбрать координатор и привязать контекст к конкретной версии топологии.
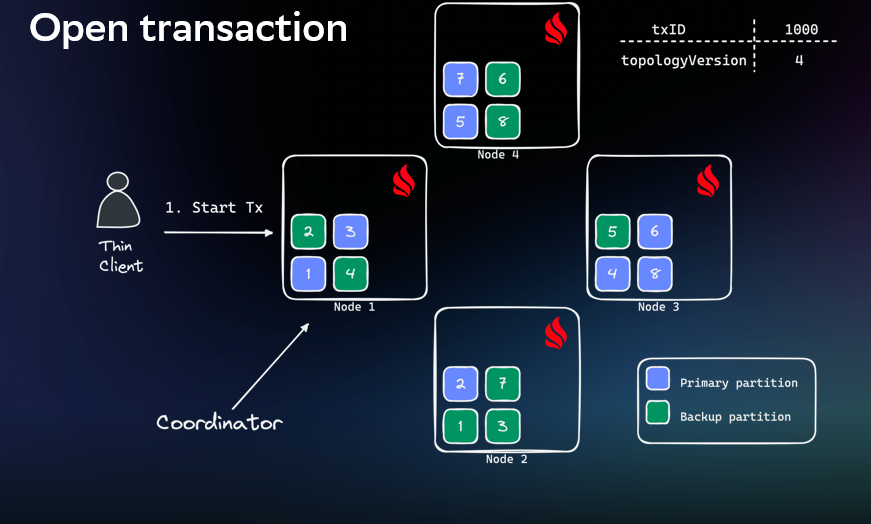
Дальше он должен записать данные. Чтобы обеспечить нужный уровень изоляции, IMDG использует блокировки на объекты. Они в Ignite бывают пессимистические (блокировка с ожиданием) и оптимистические (без ожидания).

Далее — распределённая транзакция и двухфазный коммит. Ignite опрашивает все ноды, которые участвуют в транзакции. Если все они отвечают, что могут сохранить изменения, мы коммитим эти изменения, сохраняя в наше постоянное хранилище.
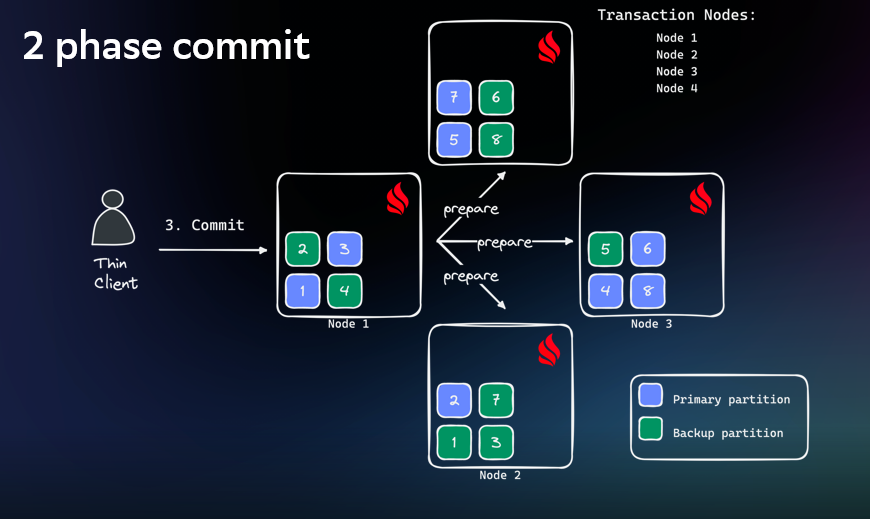
Но во время нашей транзакции может случиться и GC, и троттлинг. И таким образом миллисекундная транзакция может превратиться в секундную.
Есть ещё один интересный момент в журналах Ignite: если транзакция стала продолжительной (long running transaction), то можно увидеть такое сообщение:
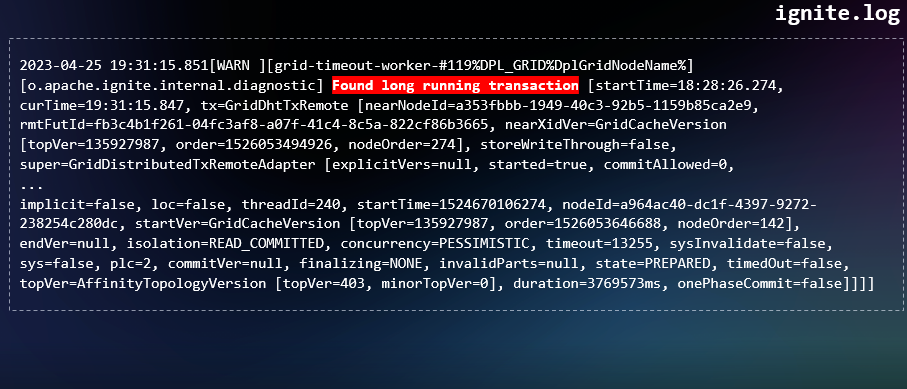
Такие продолжительные транзакции в совокупности с другими факторами могут привести к заморозке кластера Ignite. Давайте разберёмся, что это за факторы и как такое может произойти.
Partition Map Exchange
Главный фактор — Partition Map Exchange во время транзакции. Это процесс обновления карты распределения партиций, который синхронизует её на всех нодах кластера. Зачем нам нужна эта карта? Так как Apache Ignite — распределённая система, при запросе нужно правильно выбрать ноду, на которой находятся данные. Соответственно, по ключу можно вычислить партицию с помощью хэш-функции, а вот для выбора ноды кластера необходима дополнительная информация. Как раз во время этого процесса кластер Apache Ignite её и получает.
Итак, Partition Map Exchange может быть вызван в трёх случаях: если в кластер пришла или вышла нода (SIGTERM), скоропостижно его покинула (SIGKILL) или не отвечала в течение failure_detection_timeout. Представим, что одна из нод вышла из топологии, в то время как у нас идёт продолжительная транзакция. Процесс Partition Map Exchange не может быть завершён, так как до его выполнения необходимо завершить все текущие транзакции. Таким образом, обновить топологию мы не можем. В это время уже начинают приходить новые запросы, которые ожидают новой карты распределения. И будут ждать, пока не закончится длинная транзакция и пока всем не будет доставлена новая версия карты распределения. Самое простое решение в этой ситуации — устанавливать таймауты по умолчанию, как в примере ниже или в прикладном коде.
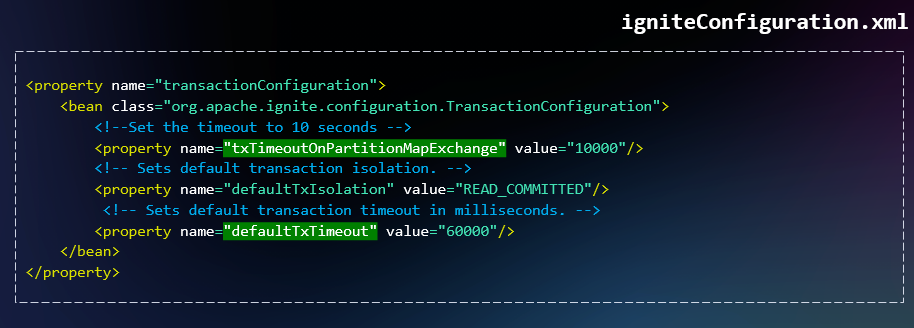
Такое решение позволит избежать серьёзной деградации кластера, но хотелось бы полностью устранить влияние PME.
Давайте сначала попробуем минимизировать ущерб от выхода узла. Для этого мы размещаем данные в ячейки: группируем резервирующие партиции так, чтобы они находились в рамках 3-4 узлов. Так при выходе узла мы повлияем только на эту ячейку. Дополнительно мы размещаем узлы, которые содержат одинаковые данные, по разным стойкам серверов. Если выйдет из строя стойка целиком, мы не потеряем данные, что для нас критично. Такая ячеистая конфигурация возможна благодаря функции Rendezvous affinity с дополнительным backup filter.
Но даже такие манипуляции не решают до конца проблемы, и неосторожное обращение с транзакциями, которое отягощается инфраструктурными проблемами, может в итоге привести к проблемам во всем кластере. Можно ли этого избежать? Да, но, как бы это странно ни звучало, нам нужно избавиться от причины всех бед — транзакций.
Избавляемся от транзакций
Первое, о чём тут нужно подумать, — возможно ли это? Что будет, если мы на клиентской стороне сделаем простой put, без открытия транзакций?
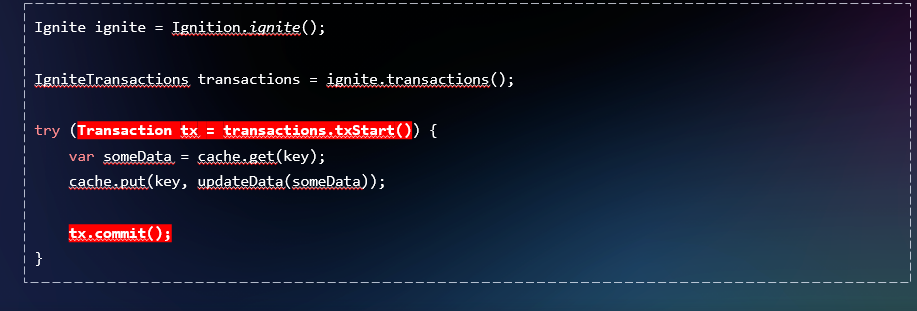
Мы можем открыть транзакцию явно, используя транзакционное API Ignite, но это приведёт к дополнительным вызовам кластера с клиентской стороны. Либо можно открыть транзакцию неявно, без вызова txStart(). У нас будет меньше возможностей контроля, так как серверный узел сам запускает, фиксирует и откатывает транзакцию. Уровень изоляции будет по умолчанию. Отличия между implicit- и explicit-транзакциями показаны ниже.

А если без транзакций не обойтись? В некоторых случаях, когда в транзакции задействован только один объект, оптимально будет переписать код на использование операции атомарного обновления. Она поддерживается в двух функциях: replace и putIfAbsent. И такая операция будет равносильна выполнению операций в транзакции. В нашем случае это дало прирост производительности почти в два раза:
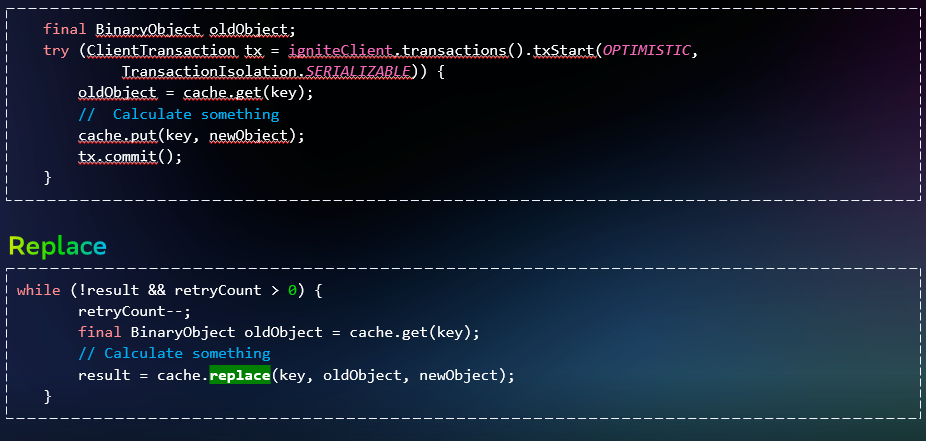
Но не все операции получится так оптимизировать. Что делать, если у нас тяжёлая транзакционная логика? К счастью для нас, на Apache Ignite можно писать сервисы. Они называются Service Grid. Вы реализуете такой сервис и выполняете в нём транзакционную логику. В данном случае транзакции будут координироваться непосредственно из кластера Apache. При этом у вас есть набор возможностей: конфигурировать размещение сервиса только на одном узле кластера (так называемый кластер singleton) или на каждом узле (node singleton).
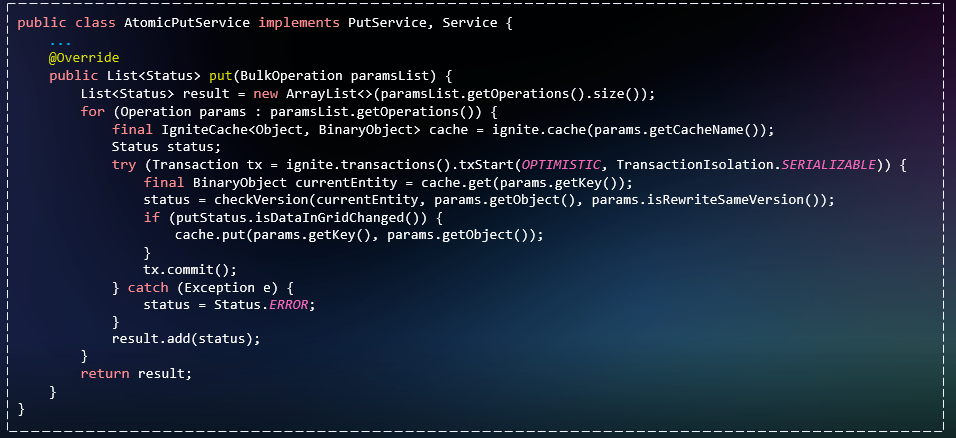
Если посмотреть на бенчмарк, ServiceGrid оказывается не настолько эффективным по сравнению с толстым клиентом Apache Ignite. Какое-либо сравнимое с толстым клиентом время мы получаем только в пакетных операциях.
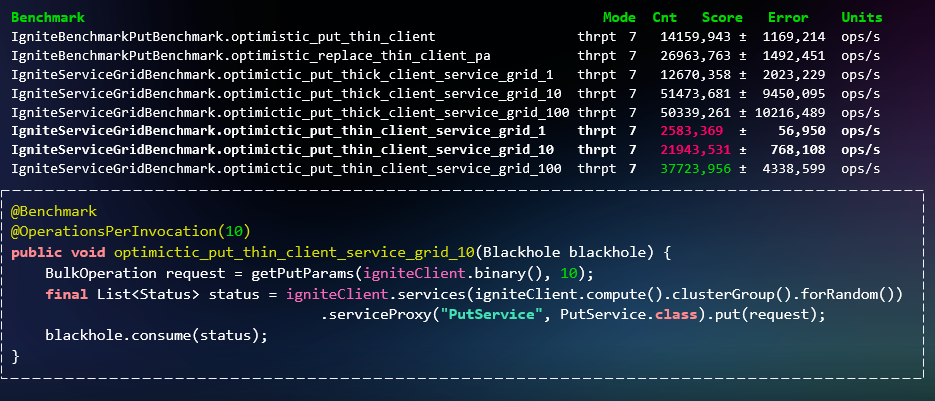
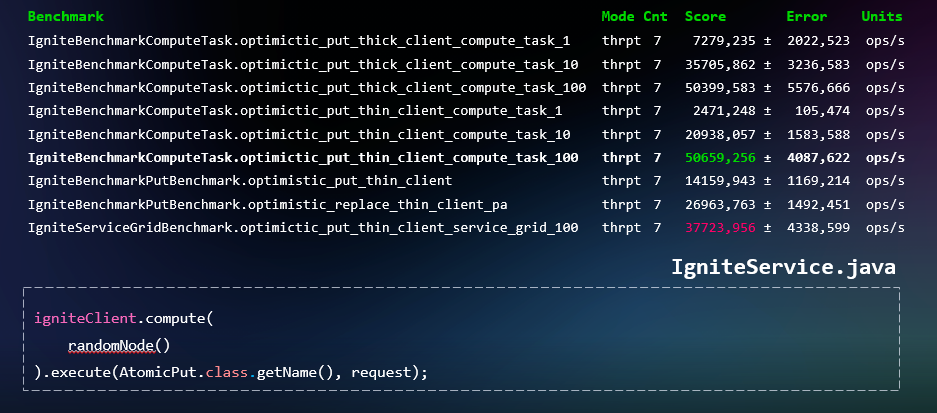
Но у Apache Ignite для работы с пакетными операциями есть кое-что более подходящее — ComputeTask. По сути, это аналог map reduce. И с его помощью можно реализовывать пакетные операции, которые с помощью распределения задач по узлам с данными будут выполняться намного быстрее.
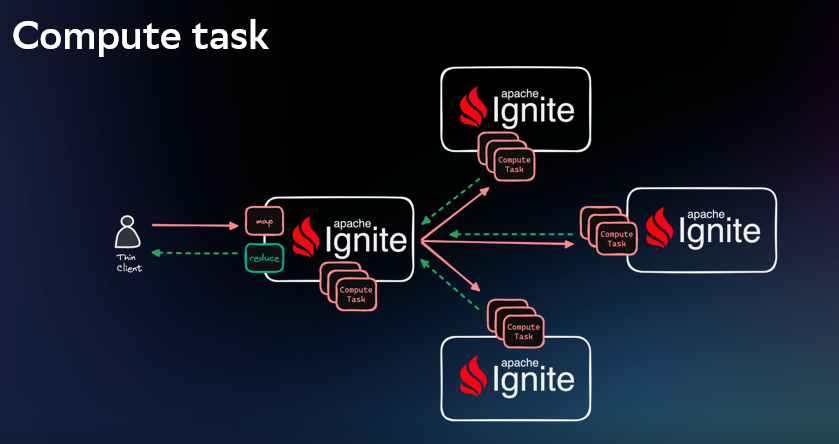
Для выполнения такого подхода нужно реализовать наследника класса ComputeTaskAdapter и два метода: map и reduce. Ниже пример реализации метода map, вычисляющего ноду, на которой должны храниться данные, и отправляющего на неё задачу по записи объекта.
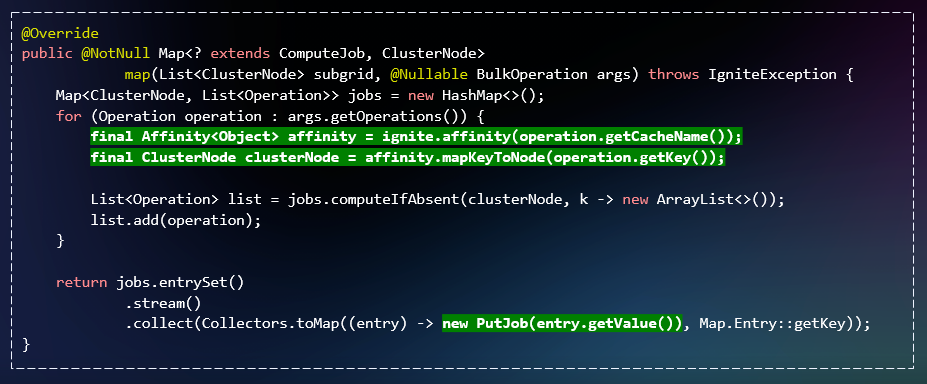
Непосредственно сама реализация ComputeJob выполняет транзакционную запись объекта.

После выполнения задачи мы должны обработать результаты на этапе reduce, агрегировать их и отправить тонкому клиенту в виде коллекции.
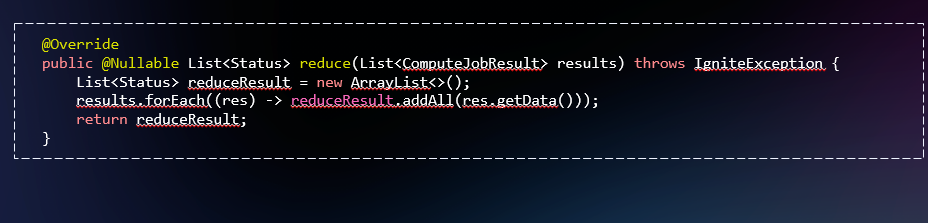
В итоге использование ComputeTask может существенно увеличить производительность для пакетных операций.
Примеры бенчмарков для разных типов клиентов можно найти в этом репозитории.
Давайте подведём итоги
Облачное окружение — это конкурентная среда. При миграции сервисов можно столкнуться с проблемами, вызванными как изоляцией ресурсов, так и увеличенным временем ответа из-за добавления новых агентов в цепочки вызовов (proxy, sidecar, разделение на микросервисы и т.д.). При проектировании новой архитектуры нужно помнить об этих факторах и по возможности устранять их, переходя на асинхронное взаимодействие, пакетные операции и другие решения.
Напомним характеристики нашей системы: у нас около 300 микросервисов, которые выдерживают нагрузку более 50 тысяч операций в секунду со средним временем отклика менее 50 мс на end-to-end взаимодействие. Чтение данных из Ignite на микросервисе составляет в среднем 5 мс. Клиенты взаимодействуют с нашей системой повсеместно: в мобильном приложении СберБанк Онлайн, в отделениях Сбера и даже при авторизации по Сбер ID.
Миграция с монолита на микросервисы — сложный процесс. В предыдущей части мы рассказали, что пробовали работать с толстым клиентом, но при работе с ним возникали проблемы (спойлер: он не совсем подходит для cloud-окружения). Мы бы не справились с процессом миграции без перехода на тонкого клиента Apache Ignite, переноса транзакционной логики на атомарные операции и ComputeTask, а также устранения лишних прокси между клиентами и кластером Apache Ignite.
Огромное спасибо коллегам из СберТеха, которые развивают Apache Ignite и его коммерческий форк Platform V DataGrid. Благодаря их глубокой экспертизе в ядре мы успешно мигрировали свой Data-проект с иностранного вендора на Platform V DataGrid и получаем высококвалифицированную техническую поддержку 24/7.