
Краткое содержание первой части
В первой части статьи я рассказывал о создании цифрового юриста, способного отвечать на вопросы на основе 200-страничного регламента. Цель — работа такого юриста в закрытом контуре организации, без использования облачных технологий.
Для этого задания мы разработали фреймворк, позволяющий изменять LLM-модель и тип токенизации в реальном времени. В качестве эталона мы использовали GPT4 Turbo и ADA-02 для токенизации. Хотя такое решение не подходит для продакшн, оно отлично служит точкой отсчёта.
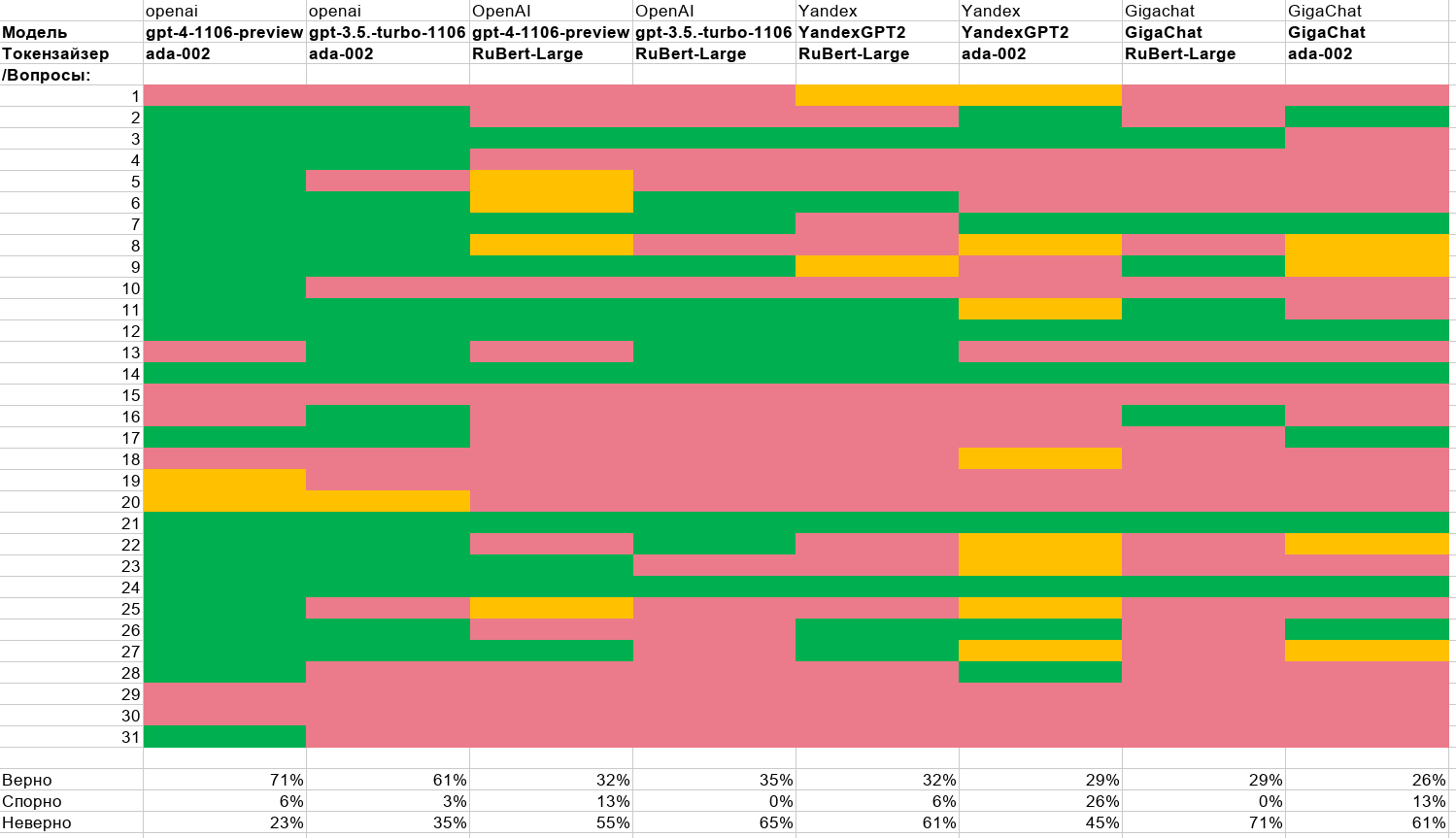
Особенностью нашего подхода стало собрание 31 вопроса, от простых до сложных, с последующей оценкой ответов юристами. Оценка была сделана руками, людьми, что делает её особенно ценной. Мы тестировали различные комбинации моделей и промптов, включая GPT4, GPT3.5, GigaChat и YandexGPT. Гипотеза об эталонной модели и токенайзере подтвердилась результатами от OpenAI (около 70% точных ответов). Однако токенайзеры от RuBert оказались не настолько эффективными, как ожидалось.
Более подробно об этом можно прочитать в первой части.
Сравнительная таблица из первой части
В этой части мы рассмотрим дообученный токенайзер и модели Saiga на базе Llama и Mistral.
Какой выбрать токензайзер (тот что создаёт векторное представление текста)?
Правильный выбор токенайзера в RAG аналогичен выбору ингредиентов для супа. Чтобы избежать перебора всех возможных вариантов и не нагружать проверкой наших юристов, я решил провести предварительную квалификацию.
Напомню, что в RAG промпт задачи формируется динамически. Вопрос (A) конвертируется в вектор, и выбираются наиболее близкие ему математические векторы фрагментов регламента, сортируемые по убыванию "близости". Затем из них формируется запрос. Например, для вопроса A наиболее близкими являются фрагменты текста P, D, F, G, при этом дистанция между векторами A-P больше, чем A-D. С этой задачей лучше всего справляется ADA-02 от OpenAI.
Таким образом, можно создать собственный токенайзер и сравнить, какие фрагменты текста он выдаст для такого же запроса. Если их последовательность совпадает с ADA-02, это отлично. В противном случае, эту ошибку можно измерить и анализировать.
Если скормить этот текст в СhatGPT и попросить зарисовать, он выделит суп как основный элемент.

В некотором смысле наш токензайзер должен выделять правильные элементы.
Методология поиска лучшего токенайзера
В качестве референса было я взял около 5000 текстовых фрагментов различного содержания: примеры вопросов, выдержки из регламента. Из этих данных случайным образом формировались 250 пар текстов для расчета косинусной близости для выбранного токенизайзера. Далее рассчитывал отклонение между значением эталонного ADA-02 и выбранного. Колебание этого отклонения и есть наш параметр. Если токензайзеры идентичны, то и среднееквадратичное отклонение между ними = 0.
Среднее квадратичное отклонение между каждой точкой позволило определить точность выбранного токенизатора. RuBert – Large демонстрировал погрешность около 10-11% в отношении ADA-02, sbert-nlu-ru-mt – 9-11%, что является улучшением, хоть и незначительным.
")
9Ембеддинг – это матрица чисел, поэтому задача адаптации локального токенизатора, такого как RuBERT или sbert‑nlu‑ru‑mt, заключается в преобразовании одной матрицы в другую. Классическая ML задача.

После исследований промпта в ChatGPT я остановился на трехслойной сети TensorFlow, без специальной настройки и подбора гиперпараметров (всё по умолчанию, что наверное упущение).
30 эпох обучения и был создан адаптер. Он переводит вектор RuBert (1024 параметра) в вектор OpenAI (1526 параметров). Этот адаптер будет эффективно работать только с текстами, близкими к определенной тематике.

Синтетические тесты показали, что ошибка снизилась с 9-11% до 6%. При этом использование sbert-nlu-ru-mt не дало прироста, поэтому был выбран RuBert-large в качестве основы.
Таким образом, был получен локально работающий токенизатор, близкий по эффективности к облачному ADA-02, что теоретически должно улучшить качество ответов.
Проверка на практике, как работает FineTuned токенайзер.
Возьмем наш эталон GPT-4 и пропустим через нашу машинку вопросов/ответов и отдадим на оценку ответов юристам. И мы получаем следующие результаты:
GPT-4 |
ADA-02 |
RuBert - Large |
RuBert-Large FineTuned |
Верно |
71% |
32% |
55% |
Спорно |
6% |
13% |
19% |
Ошибочно |
23% |
55% |
26% |
Значения правильных ответов на эталонной модели значительно выросли (с 32% до 55%). Ошибочных ответов уменьшилось в двое и равно эталонным (уменьшение с 55% до 26%, при 23% эталонных). Иными словами – наша стратегия сработала:
Правильный токенайзер повышает качество. Улучшение точности ембедингов с 11% до 6% даёт значимый результат.
Fine Tune токенайзера возможен
Аналогичный результат мы видим и для моделей YandexGPT. Количество правильных ответов растет, ошибочных падает:
YandexGPT |
ADA-02 |
RuBert - Large |
RuBert-Large FineTuned |
Верно |
29% |
32% |
45% |
Спорно |
26% |
6% |
13% |
Ошибочно |
45% |
61% |
42% |
Локальные модели
Пришло время к самому интересному. Я развернул локальные на базе Saiga2 (LLama2).
Решение не тестировать на токенизаторе от OpenAI и обычном RuBert было обоснованным, так как использование локальной модели с облачным токенизатором от OpenAI кажется абсурдным, а применение обычного RuBert нецелесообразно из-за его низкого качества.
Для сравнения я взял модели с двумя разными квантованиями. На 5 и 8. Первая может поместиться в видеокарту 3060 (12GB), вторая уже требует карты 3090 или 4090 (24GB).
Обе модели показали почти идентичные: 35% верных ответов, 52% ошибочных и 13% спорных ответов. Это немного лучше, чем у YandexGPT|GigaChat на базе обычного RuBert, но хуже, чем у RuBert-fine tuned.
В целом, YandexGPT немного превосходит Saiga LLama2, что является положительным моментом.
Итоговая сравнительная таблица:

А вот с fine-tune моделями у меня пока не всё получается как надо. Много галлюцинаций. Поэтому я планирую написать отдельную статью по этой теме, когда завершу эксперименты.
Влияние сложности вопросов на оценку
На данный момент задача RAG с использованием локальных моделей (в закрытом контуре) не решается в полной мере в лоб. Одновременно эту задачу можно решать, если есть доступ к OpenAI GPT4 с широким окном контекста, достигая 70-80% правильных ответов без особых усилий. Обратная сторона медали, кроме отсутсвия контура безопасности - это стоимость. Сейчас запрос будет обходиться где-то в 5-10 центов.
Основные ограничения локальных моделей, на мой взгляд связаны в первую очередь с (1) правильным формированием чанков первичного текста (2) токенайзерами,и в меньшей степени – с самими моделями. Недостатки моделей, по моему мнению, можно компенсировать более точными промптами и fine-tuning. Альтернативно, можно подождать развития технологий в ближайшие месяцы.
Работа над нарезкой и векторизацией данных – это задача требующая нашего внимания и которая не будет решена сама по себе. Доработка FineTune токенайзера представляется технически выполнимой. Нужно больше экспериментировать с гиперпараметрами модели.
По вопросу нарезки данных (чанков текста) возможны три пути. Первый, немного примитивный, но правильный с точки зрения продуктового подхода – ограничить RAG задачу информацией, которая умещается в 1-2 абзаца, возможно с ручной нарезкой.
Второй – изучить возможности и технологии графового представления данных для более сложной обработки.
Третий - ждать, пока появятся достойный локальные модели с длиной контекста (эффективной длинной) до 128К символов. Но это не наш путь.
Поэтому не прощаюсь ...
Комментарии (17)

naumov13ru
07.01.2024 20:28+1Очень интересно мне как юристу, но непонятно как программисту. Но это мои проблемы: последний раз я писал программу на бейсике ещё на спектруме. А квадратичные отклонения я помню (что есть такое) из курса правовой статистики, лет 27 назад, что сдал и забыл. В любом случае прошу автора не забрасывать тему, Legaltech наше будущее.

dvgureev Автор
07.01.2024 20:28+2На Хабре не просто найти баланс.
Но в части Legaltech, я бы сказал, что будущее все таки за машиночитаемыми договорами. Или базовые договора+ точечные машиночитаемые изменения.
Но это далёкая история.
Сейчас кажется, что графовое представление знаний все таки не умирает с появлением llm. Больших языковых моделей.
И тему я буду копать дальше. Обязательно.
naumov13ru
07.01.2024 20:28Сейчас Минюст РФ (словами Чуйченко) обещает ИИ в своём чат-боте что на портале правовой помощи. Я к тому будут ли они обучать минюстовскую LLM на корпусе судактов с "ГАС Правосудие". У Вас нет никаких сведений об этом?

bosco
07.01.2024 20:28+1Какие вообще критерии допустимости? Кажется, что рассматривать что-то с правильным ответом менее 98% - не серьёзно. А до этого, на первый взгляд, ещё фантастически далеко.
dvgureev Автор
07.01.2024 20:28+298% нет и у человека. В ходе обсуждения проекта мы иногда спорили, что является правильным ответом, а один из ответов был неожиданным для одного из коллег. Он не знал.
Поэтому более правильно сейчас кажется научить определять сложные и простые вопросы и в случае сложных делать пометку "данные не точные, хотите запросить консультацию?". А простые довести до уровня 100%.

avdosev
07.01.2024 20:28Правильно же понимаю, что это сравнение моделей без дообучения для задачи, стоковые модели?
Если да, то есть в планах дообучить?
dvgureev Автор
07.01.2024 20:28В целом да. Если конечно не считать, что Сайга это тоже дообученная Llama
Дообучение в работе, но пока без результатов. Есть сложности с промтом обучения и галлюцинациями. Но сделаем.
Как оказалось в большей степени узкое горлышко- это токенайзер и чанки , а не модель.
avdosev
07.01.2024 20:28Есть сложности с промтом обучения и галлюцинациями.
А что вы считаете галлюцинациями? По моим прикидкам их куча разновидностей, некоторые можно подтюнить настройками генерации, другие лучше исправлять фильтрацией и расширением обучающих данных.
Ещё интересно не упрётись ли вы в высокую долю копипасты в попытках уменьшить галлюцинации.
Пробовали обучать reward на людских оценках ответов от юристов?
Есть какие то метрики которые используете для оценки модели перед ручными разметками?

stanislav-belichenko
07.01.2024 20:28Наверняка глупый вопрос новичка, но в обоих частях не нашел ответа на него: а как можно даже для внутреннего использования начать использовать модель, которая ошибается даже хотя бы в 5% случаев? Особенно, если речь о юридических тематиках. Другими словами, что происходит такого, чтобы качество работы использующих эти ошибочные ответы не падало?
dvgureev Автор
07.01.2024 20:28Если в лоб, то:
1) руками разбить на куски, каждый из которых был законченный. Если список чего-то, то тогда весь список - один кусок.
2) Подключить gpt4 turbo с контекстом 128к
3) все что не вошло в п. 1 запретить использовать на уровне админ правил и может быть промтпом, если нельзя никак сократить.
При таком подходе думаю можно добиться 90+ процентов.
dvgureev Автор
07.01.2024 20:28Сложности начинаются, когда Вы захотите перенести все в закрытый контур.
vagon333
Вариант с онлайн (не локальной) моделью в 120к токенов не рассматриваете?
Я наконец получил нужный мне результат нарезки с использованием GPT4 128k токенов. Аккуратно нарезает текст.
Учитывая, что у меня 3.5тыс документов с текстом > 14k tokens, с доп. обработкой это порядка $4k для OpenAPI за нарезку всех текстов и пост-обработку.
А затем ежемесячный мелкий объем, зато не нужно растопыриваться, как та корова в бомболюке.
героиня
https://www.youtube.com/watch?v=hOlxSnrRt1I
dvgureev Автор
Не понял вопроса или Вы не прочитали первую часть.
Конечно можно использовать gpt4, это есть в выводах, но к сожалению такое решение вряд ли пройдёт инфобез в крупных компаниях, а в Российских и подавно.
Но если речь будет идти об открытой информации, вроде маркетинга, то gpt4 turbo вполне можно использовать и получить не менее 80% правильных ответов
vagon333
Первую часть читал, контекст уловил.
Пытаюсь донести идею - не усложнять, если есть возможность.
У крупных компаний такая возможность есть - ChatGPT Enterprise (https://openai.com/blog/introducing-chatgpt-enterprise), и некоторые известные мне компании в процессе прохождения InfoSec (занимает время).
У мелких (стартапов) - тоже. О чем и написал, как о личном опыте.
Насчет российских компаний - все верно, блокировка, но обходные пути существуют и ими пользуются.
dvgureev Автор
Понял. Я все же думаю Европейские компании будут стараться гайки прикручивать тоже. Тут даже дело не в цене или доступе. А в самом смысле, что если это станет core бизнеса, то быть в зависимости от кого-либо неправильно.
Как бытовое применение- да, как бизнес я бы много раз подумал.
А расскажите по какому принципу резали текст? 128 к в целом даёт большое пространство, но вот ембединги по такому размеру будут плохи кажется
vagon333
Обычный промпт: специализация, задача, ожидаемый результат, пример результата.
Хорошо что с этим промптом филонить перестал. А дальше - нарезка по section_start.
Только пришлось повозиться с настройкой.
Пример результата:
dvgureev Автор
А вектор по какой части делали?