
Предисловие и тема статьи
Меня зовут Дмитрий Гуреев. Я занимаю должность CDTO в одной из медицинских компаний и параллельно веду работу по популяризации ИИ в среднем бизнесе. Генеративные модели привлекли мое внимание в феврале 2022 года. Тогда я внедрил цифрового ассистента для полевых продавцов. Система позволяет им озвучивать результаты встреч в телеграм-бот, на основе чего формируется официальный протокол, который затем записывается в Битрикс.
Мои исследования продолжились, и летом 2022 года хороший знакомый из крупной компании предложил совместный эксперимент. Задача состояла в создании цифрового юриста, способного отвечать на вопросы первой линии, используя в качестве базы знаний 200-страничный регламент из более чем 1200 пунктов. Каждый пункт содержал информацию о том, что можно и что нельзя делать, сроках, ответственности и прочем. Все это должно было функционировать в закрытом контуре.
Задача представлялась крайне интересной:
Объем регламента значительно превышал максимальный размер промпта, даже для GPT4-Turbo (128к), который вышел позже.
Все должно было работать локально, требования ИБ, что исключало готовые решения.
Мы договорились двигаться последовательно, начиная с использования возможностей OpenAI, постепенно переходя к отечественным облачным решениям YandexGPT и GigaChat, подбору локальных токенайзеров и внедрению Saiga, включая кастомизированные варианты.
К августу мы сформировали Dream-Team (ИТ + Бизнес):
Я взял на себя роли TeamLead, инвестора (железо и аутсорс части решений)
Знакомый возглавил группу из четырех экспертов-юристов, которые на каждом этапе валидировали систему.
Эта статья является промежуточным итогом наших работ. Мы исследовали различные модели и типы токенайзеров, а эксперты оценивали качество работы модели. На сегодня это, возможно, самое подробное и детальное исследование в данной области, где для оценки привлекались живые люди из бизнеса и я надеюсь, что оно окажется полезным.
Методология
Использование больших языковых моделей для поиска ответов по документам является классическим подходом. Я не буду углубляться в методологию, так как уже существует множество статей на эту тему (на langchain, или вот на habr), а лишь напомню основной принцип.
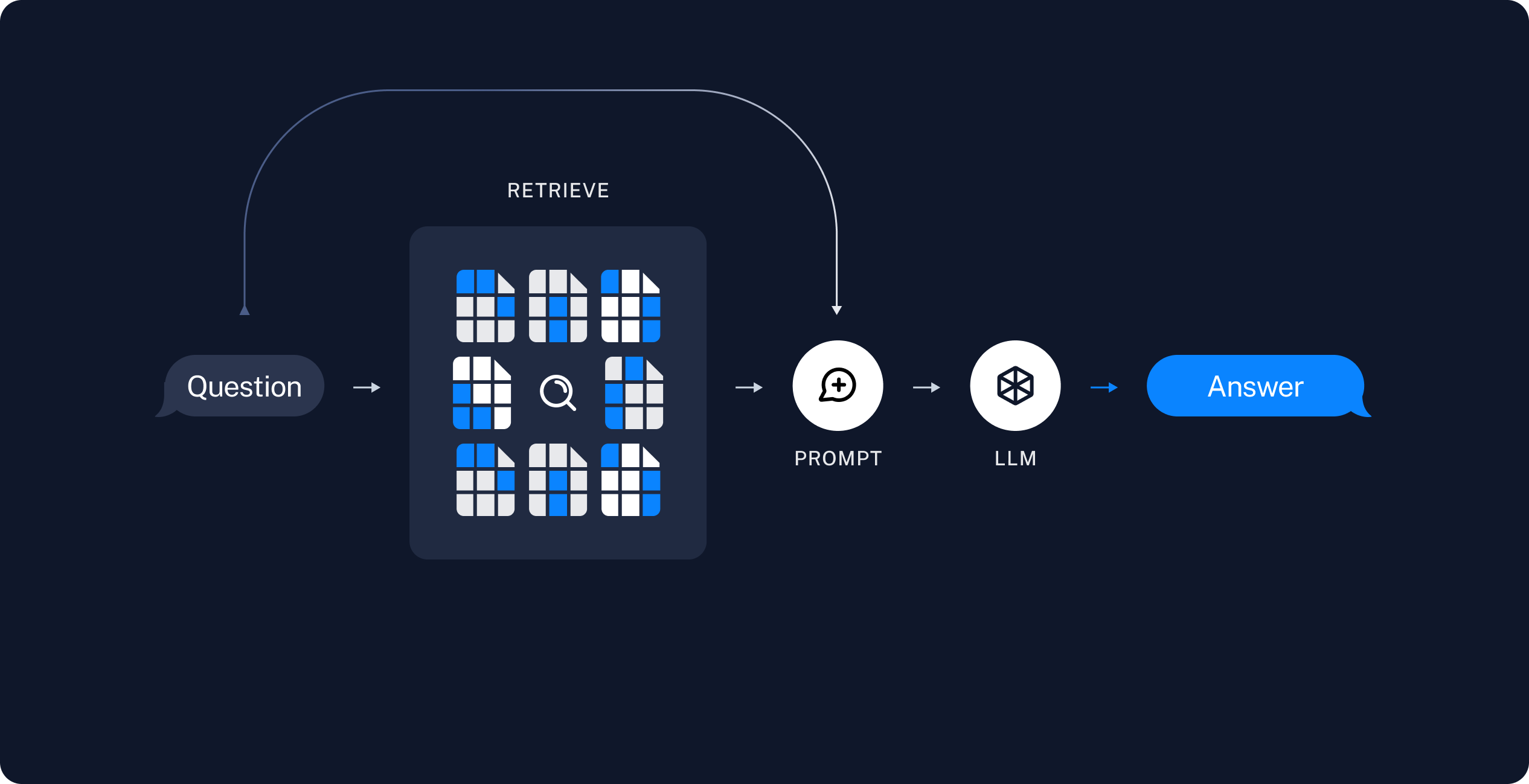
Основной принцип заключается в разбиении большого документа, который нельзя поместить в промпт, на мелкие части или чанки. Затем, когда задается вопрос, система ищет наиболее релевантные куски текста, где может находиться ответ. Из них формируется финальный промпт:
Ты цифровой юрист. Твоя задача отвечать на вопросы используя части текста из регламента. Ответь на вопрос: [вопрос] Используя сведения из следующих кусков текста: [текстовые куски]. Отвечай кратко. Ничего не придумывай. Если ответ не знаешь, то так и скажи.
Реализация этого механизма включает несколько этапов:
Разбить текст на чанки (100-400 слов).
Перевести эти чанки в векторный вид для последующего выбора наиболее релевантных с помощью косинусной близости.
Сформировать промпт из этих кусков.
Отправить промпт в выбранную модель и получить ответ.
Таким образом, нам предстоит:
Подобрать алгоритм разбития текста на чанки (куски).
Подобрать токензайзер для получения эмбедингов по этим кускам.
Подобрать промпт.
Подобрать модель.
Классическое описание данного механизма, описанное в Langchain, предполагает:
Делить текст по переносам строк, стараясь сохранить слова целыми, с ограничением по количеству символов или токенов.
Для токенизации предлагается использовать модель ada-002 от OpenAI.
Использование OpenAI для генерации ответа.
Это подход отлично работает, если не стоит задача использовать отечественные или локальные решения. Так как исходный документ был публичным и не содержал коммерческой тайны, то мы решили использовать модель на базе GPT4-Turbo (10К контекст) с их родным токенайзером ada-002 для рефернса.
Однако, исходя из нашей задачи, мы должны были последовательно перебрать различные модели и токенайзеры, чтобы выбрать наиболее близкий к рефернс. В итоге мы получили:
Один алгоритм чанкования.
Четыре вида токенайзеров: ada-002, RuBert, YandexEmbeding, RuBert Finetuned.
Один промпт.
7 видов моделей: GPT4, GPT3.5, YandexGPT, GigaChat, Saiga, FineTuned Saiga.
В первой части мы рассмотрим 2 вида токензайров и 4 модели. Во второй части статьи остальные.
Итого первая часть состоит 8 комбинаций настроек.
Наши эксперты сформировал 31 вопросов от простых, до достаточно сложных на пересечении нескольких тем. Целью было получить 248 ответов (31 вопрос * 8 комбинаций), каждый из которых будет проверен вручную на адекватность с оценкой: верно, спорно, неверно.
Результаты можно увидеть в конце статьи, а теперь давайте рассмотрим каждый из этапов.
Делаем чанки
В классическом подходе предлагается разбивать текст на абзацы или, где это невозможно, по словам с некоторым перекрытием. Этот метод хорош, когда каждый абзац содержит законченную мысль, абзацы схожи по размеру и структуре. Однако, в случае с юридическими документами, некоторые абзацы могут быть подпунктами более крупных разделов. Например, пункт 3.3.3 описывает случаи, когда запрещено использовать температурную перевозку, с подпунктами 3.3.3.1 и 3.3.3.2, детализирующими отдельные случаи. Важно не разделять такие связанные пункты.
Мы также заметили, что чем длиннее чанк, тем хуже качество токенизации – она становится более обобщенной. Поэтому мы решили, что оптимальный чанк – это не только техническое, но и творческое решение, которое учитывает контекст. В итоге выбрали чанки размером до 150 слов, сгруппированные в соответствии с иерархией документа. Для этого был разработан скрипт, который анализирует структуру документа, создавая чанки, максимально крупные в рамках ограничений.
Токенизатор (получение эмбедингов)
Каждый чанк необходимо было преобразовать в вектор, который затем записывался в PSQL. Мы рассмотрели различные варианты: облачные сервисы OpenApi (ada-002) и YandexEmbeding (с ограничением до 10 запросов в секунду), а также множество локальных вариантов, включая Word2Vec, RuBert, rugpt и даже слои эмбеддингов у Llama.
Облачные сервисы работали отлично, хотя у Яндекса была низкая квота по умолчанию, а у Сбера (ГигаЧат) мы не нашли подходящего токенайзера.
С локальными вариантами было сложнее. Пришлось написать что-то вроде автотеста. Выбрали около 10 вопросов и соответствующими куски регламента, где точно есть ответ на них. Далее меняя разные токенайзеры смотрели, какие из них покажут хорошую косинусную близость между вопросом и куском.
RuBert-Large оказался наиболее адекватным для нашей задачи, с использованием среднего пулинга (mean pooling). Скрытый слой Llama оказался полностью бесполезным. RuGPT, Fred и прочие от ai-forever - оказались хуже.
Промпты
Мы понимаем, что от промпта многое зависит, но для эксперимента решили оставить классический вариант: Ты цифровой юрист. Твоя задача отвечать на вопросы используя части текста из регламента. Ответь на вопрос: [вопрос] Используя сведения из следующих кусков текста: [текстовые куски]. Отвечай кратко. Ничего не придумывай. Если ответ не знаешь, то так и скажи..
Размер промпта ограничили до 10000 символов, так как этот размер хорошо подходил под все рассматриваемые модели, несмотря на разное количество занимаемых токенов для русских символов в разных моделях (например, 2-3 символа на каждый из 4096 токенов у Llama или 1 токен = 1 символ для GPT4).
Модели
Для нашего проекта мы использовали несколько источников: доступ к OpenAI, YandexGPT, GigaChat, а также мощную видеокарту 4090 для запуска и обучения локальных моделей. В качестве базовых моделей были выбраны Llama и Saiga, а также мы попытались обучить собственную модель. Подробности об этом будут во второй части статьи.
Для работы с облачными моделями мы устанавливали температуру генерации ответов на ноль, чтобы повысить точность и уменьшить креативность ответов. Доступы к моделям были получены через API.
Обвязка и devops
Для управления таким количеством параметров мы разработали бэкенд на Python, который был помещен в Docker-контейнер. Бэкенд обладает интерфейсом OpenAPI для взаимодействия с внешними системами. Это решение позволяло нам на лету изменять документы, модели, промпты и различные токенайзеры, обеспечивая максимальную универсальность и гибкость. Бэкенд работает как на CPU, так и на GPU, что позволяет тестировать локальные модели параллельно с облачными.

Также был создан микросервис для телеграм-бота, позволяющий легко добавлять документы в канал.
Дополнительно мы написали валидационный скрипт, который формировал ответы на вопросы, перебирая различные варианты на нашем бэкенде.
Итоги
Мы подошли к наиболее интересной части. Напомню, что эксперты задали 31 вопрос, на который система отвечала, используя разные комбинации моделей и токенайзеров. Каждый ответ затем был оценен экспертами вручную по следующей градации: верно (зелёный), спорно (желтый), неверно (красный).
Давайте теперь рассмотрим общую картину результатов. По горизонтали расположены вопросы, по вертикали – комбинации параметров. В ячейках таблицы указан цвет, соответствующий оценке ответа.

Из результатов тестирования видно, что GPT4-Turbo с использованием родного токенайзера ada-02 показал лучшие результаты: 71% ответов оценены как верные и только 23% как неверные. Наименее эффективной оказалась модель GigaChat с локальным токенайзером RuBert-Large. Результаты YandexGPT были чуть лучше, но разница несущественна.
Интересно отметить, что модели OpenAI также показали плохие результаты на токенайзере RuBert. Это подтверждает предположение, что неправильный выбор кусков текста (ошибка токенайзера) для формирования промпта приводит к неверным ответам. Почти во всех случаях, когда модели OpenAI давали неверные ответы, другие модели также показывали низкие результаты.
На основе первых данных стало ясно, что стоит сосредоточиться на разработке локализованных под конкретную задачу токенайзеров и использовать ada-002 в качестве эталонного токенайзера. Это подчеркивает важность правильного выбора инструментов для обработки и подготовки текста перед использованием языковых моделей. Не менее важно, чем сами модели.
На основе представленных данных можно провести анализ эффективности моделей и токенайзеров:
Неверные ответы:

С использованием токенайзера RuBert-Large количество неверных ответов у всех моделей значительно увеличивается, превышая 55%. Это подтверждает, что выбор токенайзера является критически важным для точности модели.
Наибольший процент ошибок у GigaChat с RuBert-Large (71%), а наименьший – у GPT4 с ada-02 (23%).
Спорные ответы:

Наибольшее количество спорных ответов наблюдается у моделей YandexGPT2 и GigaChat с токенайзером ada-02. Это может указывать на несовершенство этих моделей, а также на потенциальную возможность улучшения результатов за счет оптимизации промптов.
С RuBert-Large спорных ответов меньше, что может быть связано с более низкой точностью этого токенайзера в целом.
Верные ответы:

Наилучшие результаты по количеству верных ответов показывает GPT4 с ada-02 (71%).
Результаты YandexGPT2 и GigaChat значительно ниже, даже с использованием токенайзера ada-02. Это может свидетельствовать о том, что данные модели менее эффективны в данной задаче, либо требуют дополнительной настройки промптов.
Выводы и что наш ждет во второй части
Первая часть исследования показывает, что необходимо сосредоточить усилия на улучшении токенайзеров для повышения точности ответов и на доработке промптов для уменьшения количества спорных ответов. Во второй части статьи будут представлены:
Токенайзер от Яндекса.
Улучшенный (Fine-tuned) RuBert токенайзер.
Локальная модель Saiga.
Дообученная модель Saiga.
Комментарии (50)

MaxSergeev
22.12.2023 09:14Для юридических документов лучше рассмотреть ручную нарезку на чанки (создать специализированный документ).
Если же нужно автоматически (или полуавтоматически), то использовать граф, в нем хорошо отображаются разные взаимосвязи типа "все вышесказанное относится еще и к п. 104" и отлично будет видны отношения один ко многим когда написанное в пункте относить к каждому пункту ниже.
Никакие нарезки чанков на такое не способны из-за особенностей самой структуры юридических документов.
dvgureev Автор
22.12.2023 09:14Да, Макс. Согласен ручная разметка вообще топчик. И кстати это может быть намного дешевле в итоге, чем городить онтологический граф.
MaxSergeev
22.12.2023 09:14Для текущего кейса точно было б круто. А если еще структуру документа переделать специально под этот сервис, я думаю при прочих равных gpt4 90-95% показал бы.
И еще -- мне очень понравились результаты gpt3 -- очень мало неточных! Или да или нет. Конкретная модель )) -- все "нет" точно можно обработать ))

vagon333
22.12.2023 09:14Ручная - не всегда вариант.
Иногда объемы и human error не позволяют использовать ручную.
Вообще, для меня нерезка - showstopper в проекте.
Банковское регулирование.
Законов в базе - 112тыс., активных законов 7.6тыс.
Впереди обновление законов 2024 и у меня легкая паника.
GPT4 нещадно филонит на текстах с 2к+ токенов, т.е. нарезка - must have.
Толкового решения у меня нет.
Внимательно читаю подход в статье.dvgureev Автор
22.12.2023 09:14Верно подмечено.
Для художественной и профессиональной литературы, где одна и та же мысль повторяется многократно в разных абзацах достаточно чанкирования по абзацам и даже работает по словам с 20% перекрытием.
Для регламентов важен каждый пункт.
А вы все законы через ada пускаете? Я бы предложил локальный токенайзер. Дешевле.
vagon333
22.12.2023 09:14А вы все законы через ada пускаете?
Не совсем.
У меня 4 последовательных промпта обработки закона:
- разбивка на сегменты (и под-сегменты) до размера 1к токенов
- идентификация требований (с добавлением заголовка-контекста в каждый сегмент)
- пробразование требований
- генерация цифровых правил с опорой на схему банковских данных.
Использую GPT4 128k токенов на разбивку большого текста на сегменты (этап 1), далее GPT4 на остальные этапы.
На малых текстах, когда сегментация не требуется, проблем нет.
На больших GPT4 128k лажается с разбивкой на сегменты и теряет контекст т.к. режет текст не всегда на логические куски. Но часто подбирает аккуратно.dvgureev Автор
22.12.2023 09:14А можете пояснить термин "идентификация требований"? Возможно это профессиональный сленг в банковской сфере.
И термин цифровые правила тоже. Вы имеете ввиду онтологические графы знаний?
vagon333
22.12.2023 09:14А можете пояснить термин "идентификация требований"?
Да, конечно.
Требования - regulatory requirements.
Раньше эти требования определяли вручную, но это большой объем, срезали углы.
Тут все как с кащеевой жизнью:
- у государства масса регуляторов (агенства, инвесторы)
- у регуляторов законы
- в законах требования
- требования основаны на банковских данных
А теперь задача: упростить проверку banking data на regulatory compliance.
Я в банковской regulatory compliance - трансформируем банковские законы в опросники, чтоб компании могли проверять свои банковские данные на соответствие законам.dvgureev Автор
22.12.2023 09:14Если привести условный пример, то он такой:
П. 3.5.667.88 при сохранении биометрических данных человек не должен носить медицинскую маску.
Вы пишите опросник:
Есть ли среди фотографий клиентов те, которые в маске? Да/нет
vagon333
22.12.2023 09:14Упрощенно - да.
Если у вас в основном цифровые данные, то вопросы можно трансформировать в цифровые правила.
Но сначала - да, нужно создать пары вопрос-ответ.
MaxSergeev
22.12.2023 09:14Да, при таких объемах -- точно не вариант. Но тут вопрос в точности ответов и кол-ве допустимых ошибок. Если их нужно минимизировать -- придется тюнинговать.
Вообще, я уже склоняюсь к мысли, что или граф или просто изменение самой формы документов (предварительное преобразование). Типа сделать так чтобы подпункт нижнего уровня включал в себя и все верхние + перекрестные отсылки. Да, будет дублирование, но вектор будет более специализированный, что позволит дать точный ответ. Теоретически )))dvgureev Автор
22.12.2023 09:14Вот сейчас у меня нижний пункт включает верхний по возможности.
Но в целом ты прав. Тут надо еще покапать как мы, как люди ищем ответы. Есть мысли, что вектора тоже тупиковый путь.
MaxSergeev
22.12.2023 09:14Вектор -- это быстро )) поэтому еще долго они будут с нами. То есть сама архитектура должна поменяться чтобы они отвалились.
dvgureev Автор
22.12.2023 09:14Да вот не хочется прямо совсем кастом под любой документ. Надо ближе к людям. Кто научился читать юридические документы, тот может прочитать любой.
vagon333
22.12.2023 09:14Вообще, я уже склоняюсь к мысли, что или граф или просто изменение самой формы документов (предварительное преобразование).
Граф - модно, но намучался с графовой базой при создании ontology для банковской сферы. При разрастании типов (не кол-ва) граф напоминает неконтролируемый mess.
Предварительное преобразование - это и делаем, с использованием GPT4 128k.
В идеале: нужен семантический анализ документов с формированием иерархической структуры, чтоб разбивку на сегменты согласно структуре, не разрывая контекст.
Надеялся здесь стыбрить решения. :)

SergioT4
22.12.2023 09:14вопросов от простых, до достаточно сложных
...
вручную на адекватность с оценкой: верно, спорно, неверно
Надо тогда надо сгруппировать результаты по ещё и по сложности, для групп "простая" , "средняя" и "сложная".
А то получится что простые и сложные имеют один и тот же вес в результате, что скрывает коненную картинку. Например если по сложным правильных ответов будет 0%, а по простым 100%, то это о многом скажет по сравнению со случаем когда например по простым будет 85%, по средним 60%, а по сложным 40%.
dvgureev Автор
22.12.2023 09:14А какая бизнес разница?
Если пользователи будут получать ответы некорректные, то это в любом случае плохо. Мы не можем просить задавать только простые вопросы.
Еще проблема, что сложность субъективна. По одному из вопросов у нас возник спор.
Звучит пункт примерно так: Заказчик должен подписать акт приемки через 5 дней после уведомления о доставке в электронной системе, но не позднее 20 дня.
Вопрос: может ли заказчик подписать акт приемки на 5 день после уведомления?
Мнения юристов, меня и GPT разошлись
SergioT4
22.12.2023 09:14не можем просить задавать только простые вопросы.
Если на сложные вопросы правильных ответов близко к 0% и есть критерий по которому можно определить что он сложный, то можно предлагать перенаправить на эксперта, можно даже за дополнителньую оплату.
Мнения юристов, меня и GPT разошлись
Ну тогда надо было добавить в тестирование несколько реальных юристов которые сидят на ответах в первой линии. А потом ваши эксперты их ответы бы тоже под мелкоскопом разглядели, может и там 100% не случилось бы. Важно подсунуть эти вопросы в рабочем порядке, а не как отдельное тестирование, т.е. чтобы у них не включился режим повышенной внимательности.
dvgureev Автор
22.12.2023 09:14Согласен с комментариями. Маршрутизация по сложности интересный вариант.
Надо думать.

shadrap
22.12.2023 09:14Я понимаю что вопрос мой не в области исследований, но все же стоимость в отношении к % правильных ответов,нужно добавить к сравнению! Моих коллег остановила именно эта характеристика. Сложность вопроса очень эвристический параметр, например в параметрах химических сред в формулировках нет ничего сложного,но несовпадение одного лишь параметра убивает все на корню.
dvgureev Автор
22.12.2023 09:14Поясните мысль. Стоимость ответа?
shadrap
22.12.2023 09:14Конечно в идеале хочется видеть общую комплексную стоимость решения пусть даже и ориентировочную. То на чем мы остановились было 0.18долл это промпт+ комплишн /1к токенов. Плюс сервисная поддержка. Плюс стоимость человеческого ресолвера неправильных ответов. Поясню общую мысль- была похожая попытка создания автоматизированного консультанта по олигонуклеотидной сборке. Итоговая стоимость решения на базе модели с учётом подключения человека на спорные ответы оказалась на порядок выше стоимости обычного человека. И даже апроксимация в будущее с учётом изменения стоимости обоих не дала выигрыша языковой модели.
dvgureev Автор
22.12.2023 09:14Олиги на llm?
Оригинально. Так ведь природа nlp иная чем последовательность нуклеотидов.
Там же есть правила обработки.
Но если абстрагироваться, то 1к токенов это мало. Можно и на локальной модели запускать. А что было в качестве датасета?
shadrap
22.12.2023 09:14А что значит иная природа ?
Там довольно простые правила генерации, если рассматривать праймерные последовательности , 1к токенов это для сравнения. Ембединги через аду, дата-сет не большой, не буду врать про объем.
dvgureev Автор
22.12.2023 09:14Тогда хочется понять лучше какая была задача. Я занимался несколько лет молекулярной биологии, точнее моя компания поставляла в т.ч. синтезированные олиги.
Была задача генерации или интерпретации последовательности?
shadrap
22.12.2023 09:14Если вы занимались синтезом - у каждой группы есть свой протокол, последовательность предоставляемая заказчиком не должна содержать ситуаций которые могут привести к появлению хайр-пинов, селф-димеров , экзон-экзон джанкшн должен быть справедливо описан для 3 прайм или 5 прайм и тд и тп.
dvgureev Автор
22.12.2023 09:14И эту задачу решать с помощью llm? Очень оригинально. Снимаю шляпу.
shadrap
22.12.2023 09:14Вопрос был,можно ли заменить человеческую приёмку машиной.
А в чем вы видите не соответствие лм?
dvgureev Автор
22.12.2023 09:14Ну потому что это только по символьному выражению буквы. Но их онтологический смысл иной. Хотя возможно что-то философское здесь можно найти. Последовательность как язык.

Andriljo
22.12.2023 09:14Добрый день, а какую версию ruBERT large вы взяли? sbert-nlu-ru-mt надеюсь?
dvgureev Автор
22.12.2023 09:14В моем случае лучше всего подошёл https://huggingface.co/ai-forever/ruBert-large
Из синтетических тестов. Я перебрал почти все.
Andriljo
22.12.2023 09:14Эта модель не является хорошим эмбеддером для задачи RAG. Уровня ada2 только sbert-nlu-ru-mt в том же репо. Это можно посмотреть в бенчмарке Encodechka. От качества ретривера много зависит в RAG.
https://huggingface.co/ai-forever/sbert_large_mt_nlu_ru вот эта модель и пуллинг из её карточки, можно с нормализацией l2 результат будет ещё лучше.
dvgureev Автор
22.12.2023 09:14Именно этот же вывод в первой части.
Вообще ruBert можно дофайнтюнить на предметной области до ada.
Спасибо за пример. Кажется именно его я упустил, но проверю.
APXEOLOG
Почему было решено делить на синтетические чанки вместо выделения каждого пункта в отдельный чанк? У вас же информация уже разделена логически.
Рассматривали ли идею генерации краткого содержания каждого из пунктов и использования его в качестве "чанка" (или, еще интереснее, комбинирования таких содержаний в большой промт для, например, Claude)?
Не знаю точно какого размера в среднем у вас контекст при ответе на вопрос, но в целом, не получится ли так что можно просто все релевантные пункты запихнуть в один контекст и тогда токенизация и вектроризация вообще не нужны?
janvarev
(или, еще интереснее, комбинирования таких содержаний в большой промт для, например, Claude)?
Все-таки таргет у такой системы - локальный запуск, а для опенсорс моделей вроде как 100к нормального контекста нет, и рассчитывать на него не приходится.
dvgureev Автор
Все так. Если нет никаких ограничений по облаку и зарубежным сервисам, то можно не заморачиваться и просто бить на огромные куски. GPT4-Turbo контекст больше Claude. 128К токенов. Это десятки страниц... И он работает, только дорого получается. около 0.2 $ за запрос.
APXEOLOG
У последней версии Claude контекст - 200К токенов (и вроде как они готовят версию на 400К).
Вопрос цены конечно тоже стоит, но тут именно с точки зрения исследования было бы интересно проверить - если просто запихивать все относительное релевантное в контекст, будет ли % хороших ответов выше. Может быть клиенты готовы платить и по 0.2$ за запрос, если качество ответа хорошее
dvgureev Автор
Принято. Добавлю Claude в исследование.
Меня уже попросили Мистраль добавить.
MaxSergeev
Было б интересно добавить в таблицу стоимость токена. Понятно, что информация быстро устареет, но все же ).
SergioT4
Я бы ещё попробовал сделать fine-tune для чатгпт версий, т.е. скормить регламент и попробовать протестировать против этой версии.
Ещё вариант попробовать на подготовительных шагах происпользовать более дешёвые версии для обогащения промпта для более дорогого, т.е. чатгпт 3.5 в десять раз дешевле и если сделав три-четыре запроса в 3.5, мы сможем извлечь информацию которая сможет улучшить качество конечного запроса к 4, то это будет стоить того.
Например можно послать запрос к 3.5, что-то типа (просто пример не зная специфики регламента):
После этого использовать для получения релевантных данных из регламента и запроса к 4.
dvgureev Автор
Да, так можно, но это не приближает к задаче локального RAG
SergioT4
Надо правду себе сказать - локальный вариант в минимально подходящей конфигурации года ещё два-три не реален.
Это будет осознанным обманом клиента, если вы будите получать результат хуже чем 10% ошибок. С локальной версией, судя по данным, будет больше 50%.
Если у вас цель создать иллюзию ответа, то конечно ок.
dvgureev Автор
Мне кажется своим комментарием Вы пошли в какую-то не ту степь.
В части суждения о том, что является моей целью и про иллюзию ответа. А лишь обозначил, что копание в Openai противоречит задачи эксперимента.
Цель исследования, а это первая часть его, вполне обозначена конкретно в начале. Локальная модель. Получилось или нет увидим позже, но тратить время на то, что точно не входит в рамки эксперимента- зачем?
Более того внедрение подобного робота в процесс требует в ближайшее годы участие человека. Неважно локальная модель или облачная.
dvgureev Автор
По первому вопросу (Иерархия):
В юридических документах пункты могут содержать очень мало информации и релевантны только в сочетании с родительским пунктом. Например:
Товар можно отправлять в термоконтейнерах, когда:
1. Есть указание в заказе наряде
1.2. Груз содержит реагенты с хранением до -4
Товар нельзя отправлять в термоконтейнерах, когда:
2.1. Есть указанием в заказе наряде
2.2. Есть груз содержит реагенты с хранением более 15 градусов
Соответственно пункты 1.1. и 2.1. индентичны и имеют смысл только в сочетании с родителем.
По второму вопросу (суммаризация чанка):
Рассматривал в теории, но пока решил отказаться. Так как вопросы по тексту задавали с очень конкретным контекстом: перечисли случаи когда можно делать хххх. Сколько дней даётся на подписание документа Y. А можно ли подписать акты на 12 день? А на 9 дней после приемки? ---- Кажется, что при суммаризации все эти детали потеряются.
Но соглашусь, что гипотезу можно проверить и делать вектора по саммари.
По окну контекста:
Так смысл состоит в том, чтобы выбрать эти релевантные пункты. В самом начале я вообще перевёл регламент на английский язык и смог запихнуть большую главу сразу в промпт. И это работало. Но хочется как-то более оптимально.
Хотя конечно были идеи, все перевести на английский и кидать сразу по 50 страниц.... Но эта идея разбивается о требование, чтобы все работало в закрытом контуре или хотя бы на отечественных решениях.
APXEOLOG
Да, этот момент я упустил, у Вас там OpenAI в таблице, так что я думал, что ограничений нет никаких
dvgureev Автор
Да, он используется исключительно как референс. Я думаю, что никто не будет отрицать, что GPT4 на сегодняшний день это эталон. Поэтому все локальные решения нужно делать сравнивая с ним в %.