
Привет! Меня зовут Александр Тарханов, я тимлид команды платформы в 05.ru.
Сегодня расскажу о набирающем популярность тренде Platform Engineering и постараюсь ответить, что это, зачем необходимо и как это реализовать.
Определение
Platform Engineering — один из главных технологических трендов 2024. Это методология проектирования и объединения инструментов и рабочих процессов, построение абстракций, которые помогают снизить когнитивную нагрузку на разработчиков в эпоху облачных технологий. Иначе говоря, это такой способ организации вашей конкретной корпоративной вселенной, где командам разработчиков облегчают жизнь, упростив доступ к ресурсам — в самом широком смысле слова. Взамен бизнес получает ускорение цикла разработки продуктов.
Совокупность таких инструментов и процессов называют Internal Developer Platform (IDP). IDP создаётся командой с использованием подхода «платформа как продукт». Это означает, что команда платформы должна относиться к разработчикам как к своим внутренним клиентам. Что логично, ведь основная цель создания и внедрения IDP — избавить разработчиков от непрофильных задач. Дополнительная производительность не берётся из ниоткуда: чтобы воткнуть программисту ещё один тикет в рабочий день, надо какой-то другой тикет оттуда выбросить.
Почему в этом возникла необходимость? Что за проблему невозможно было решить другими методами и средствами, что пришлось придумывать Platform Engineering?
Традиционные команды не успевают
Специализацию работников для повышения производительности придумали даже раньше Первой технической революции. Традиционная структура IT-отдела выглядит как несколько разделённых команд разработчиков и системных администраторов. Разработчики отвечают за программирование приложения. Когда всё готово, они передают упакованное приложение администраторам. Администраторы отвечают за развёртывание и запуск приложения. Таким образом, мы всегда имеем выделенные операционные группы с надлежащим опытом.
Всё было хорошо, пока скорость не была критическим фактором для бизнеса. Процесс был негибким и медленным. Разработчики ждали обратной связи от администраторов, когда им требовалось какое-то изменение инфраструктуры или возникала необходимость в инфраструктурных ресурсах. С другой стороны, администраторы ждали, пока разработчики что-то исправят в приложении, что влияло на развёртывание.
DevOps вам в помощь
С приходом Agile появилась парадигма DevOps, решающая самые критичные проблемы традиционных команд. Главное: были устранены вопросы коммуникации между разработкой приложения, его запуском и эксплуатацией. Всё это стало единой командой. Получился гораздо более гибкий и быстрый способ работы.
Теперь есть одна команда, в которой либо сами разработчики, либо выделенный DevOps-инженер управляют контейнерами docker, настраивают платформу CI/CD и создают пайплайны, пишут манифесты Kubernetes, настраивают ведение логов, мониторинг. Также поддерживают всю эту инфраструктуру по мере развития инструментов, выхода новых релизов сервисов. И всё это — в дополнение к фактической разработке приложений.
Однажды лебедь, рак и тестер…
Парадигма DevOps повышает гибкость, скорость, эффективность, но также добавляет колоссальную когнитивную нагрузку на команду.
Допустим, есть 10 таких команд, разрабатывающих различные приложения. У всех — одни и те же проблемы и потребности. Каждая команда делает всё по-своему, используя свой стек. В итоге получаем 10 команд DevOps, создающих и эксплуатирующих 10 различных платформ для доставки и запуска своих приложений. Это крайне неэффективно, расточительно и создаёт высокую нагрузку на отдельных инженеров. Таким образом, у команды остаётся меньше времени на реализацию бизнес-требований. Кроме того, в каждую команду требуется добавить опытного инженера, что означает рост затрат на человеческие ресурсы. А ещё всё это становится трудно масштабировать.
Касса самообслуживания
Как Platform Engineering решает обозначенные выше проблемы?
В эпоху до появления супермаркетов вам надо было спросить у продавца через прилавок, есть ли у него сметана, потом выяснить, какой жирности, и рассказать, сколько вам нужно и в какую тару налить. Отличный квест по развитию навыков коммуникации, но создаёт очереди, часто приводит к недопониманию и существенно снижает пропускную способность магазина. Вот бы все товары стандартизировать и исключить из этой схемы человеческий фактор! Хотя постойте-ка…
Каждому приложению в любом проекте нужна система контроля версий, CI/CD, запуск в какой-либо среде выполнения, например Kubernetes, которому, в свою очередь, нужна базовая инфраструктура. Приложение базовой инфраструктуры нуждается в мониторинге и ведении логов, в надлежащей безопасности и так далее. В общем, существует очень много областей, которые необходимо настроить для правильной работы приложения. И каждая из этих областей имеет множество различных инструментов и технологий, которые команда платформы стандартизирует в масштабе всей организации.
Звучит так, как будто мы пришли к традиционному взаимодействию, когда разработчики запрашивают инфраструктурные ресурсы у другой команды. Поэтому, чтобы предоставить доступ к инфраструктуре, команда платформы берёт необходимые инструменты, стандартизирует их и настраивает должным образом, создаёт слой абстракции с удобными интерфейсами. Это может быть WebUI, API или cli-приложение. Теперь команды разработчиков могут самостоятельно обслуживать любые необходимые им услуги и инструменты. Таким образом, команда платформы создаёт внутреннюю платформу разработчиков — Internal Developer Platform.

Плюсы и минусы, как вы любите
Подведём итог. В отличие от традиционной или DevOps-команды, построение работы Platform team имеет очевидные преимущества для обеих сторон.
Плюсы для команды платформы:
Отсутствие TicketOps, а следовательно, не нужно отвлекаться на проблемы и запросы разработчиков и тестировщиков, можно сосредоточиться на работе над стратегическими инициативами.
Стандартизированная инфраструктура, которую легко обслуживать.
Плюсы для разработчиков:
Самообслуживание. Разработчики могут легко развернуть, сменить конфигурацию или даже уничтожить новое окружение, не погружаясь в тонкости Kubernetes.
Отсутствие локального окружения. Нет необходимости разворачивать всю локальную инфраструктуру для разработки.

Как создать IDP
Итак, мы ответили на вопросы, что такое платформенная разработка и откуда она появилась. Рассмотрим теперь, как создать IDP, адаптированную для конкретной организации.
Универсального ответа нет, вам придётся собирать компоненты, исходя из собственных параметров. На примере нашей команды постараюсь обозначить общие принципы.
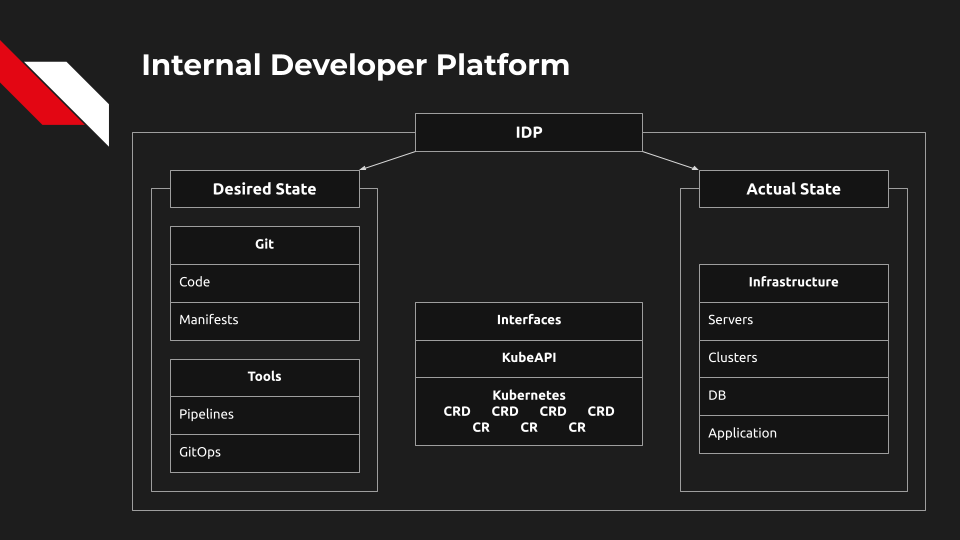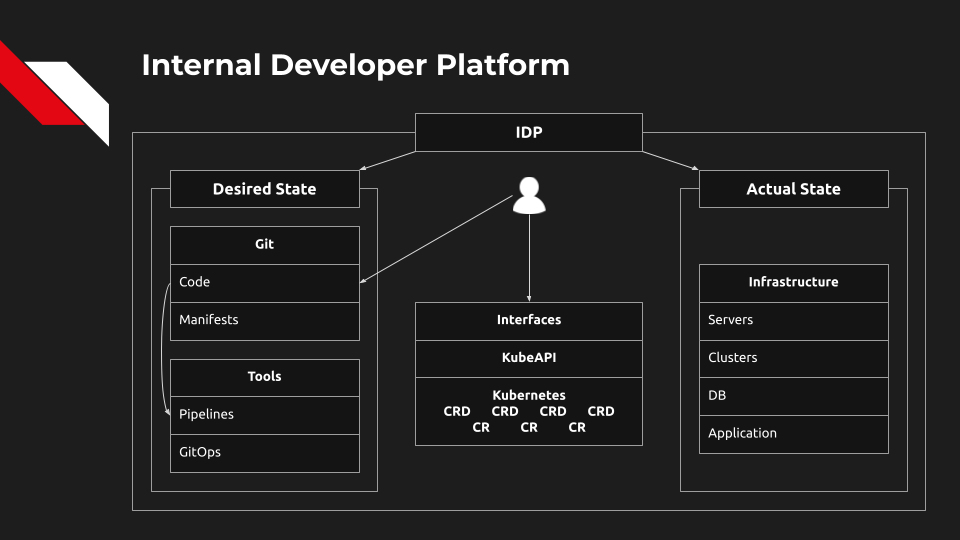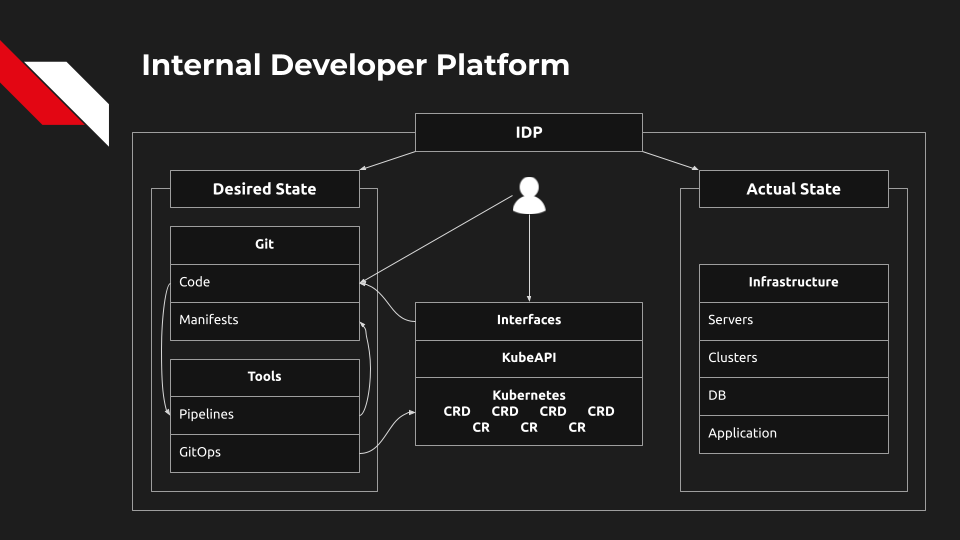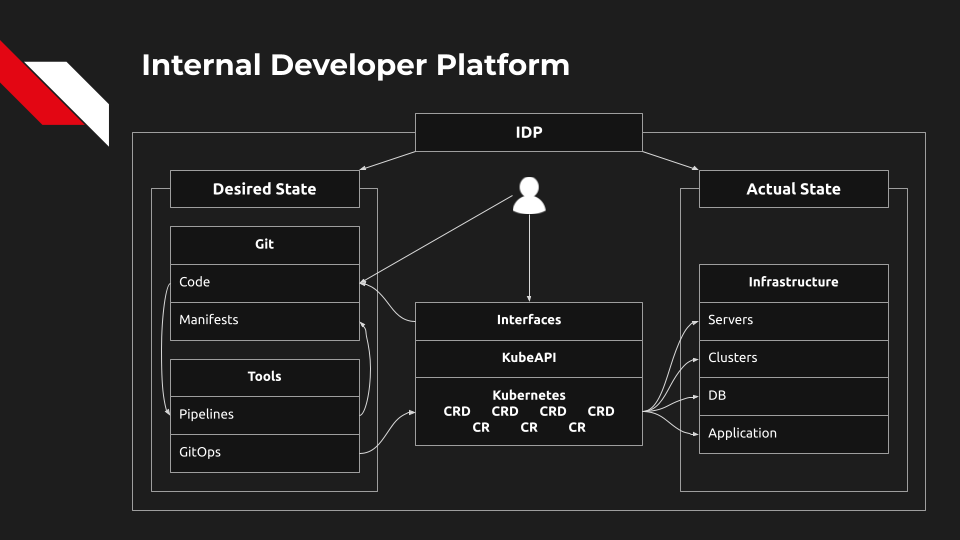
Начнем с цели. Цель состоит в том, чтобы предоставить услугу, которая обеспечивает жизненный цикл любой системы. В этот жизненный цикл входят следующие этапы: изменение желаемого состояния системы, выполнение определенных операций или действий, вследствие которых фактическое состояние переходит в желаемое, а также возможность наблюдения за фактическим состоянием системы.
Из точки Actual State в точку Desired State. Повторить
Сначала поговорим об Actual State, о фактическом состоянии системы. Это ресурсы, работающие в нашей системе. У нас есть инфраструктура, состоящая из серверов, кластеров, баз данных и т. д. Также у нас есть приложения, они могут быть нашими, которые мы сами разрабатываем, или какими-то сторонними, которые мы не разрабатываем, но тем не менее должны запустить.
Чтобы получить фактическое состояние, необходимо определить Desired State, или желаемое состояние системы. Делается это путём написания кода, манифестов и прочих конфигурационных файлов. Наша цель — преобразовать желаемое в реальность. Теперь нам надо где-то сохранить это желаемое состояние, и единственное разумное место для его хранения — это Git.
Internal Developer Platform предоставляет разработчикам возможность изменять желаемое состояние системы и наблюдать за фактическим состоянием системы, и для этого нам нужны интерфейсы. Это может быть что угодно: одни предпочитают работать в консоли, другие — щёлкать элементы на экране. Для того чтобы это всё работало, нам нужен API под пользовательским интерфейсом. Волевым решением делаем замах большим топором и отрубаем всё, кроме единого API.
На сегодня основной кандидат на это место — Kubernetes API. KubeAPI гарантирует, что фактическое состояние всегда совпадает с желаемым. Это мощный универсальный API с хорошим планировщиком, он был создан расширяемым, через него мы можем управлять любыми ресурсами. Причём контейнеры — это всего лишь небольшая часть того, чем он может и должен управлять.
Ключом всей этой истории является Custom Resource Definitions (CRD), для лучшего понимания давайте переведём как «описание кастомных ресурсов». Они важны, потому что позволяют определить почти всю необходимую инфраструктуру. У нас есть backend-приложение? Определим для него CRD. Для него нужна база данных? Определим CRD и для неё. И так далее. Мы можем создать описания ресурсов, адаптированные для конкретной аудитории. У нас появляется возможность создать абстракцию, чтобы разработчики могли писать манифесты на основе этих CRD и преобразовывать их в ресурсы, собственно Custom Resource (CR).

IDP & Humans: step-by-step guide
Рассмотрим, как будет выглядеть процесс взаимодействия людей с IDP.
Всё начинается с того, что разработчик пишет код и отправляет его в репозиторий. Далее выполняются пайплайны с шагами, которые создают образ, запускают тесты, отправляют артефакты в какой-то реестр — и так далее.
Сами пайплайны могут изменять Desired State. Например, если пайплайн создал новый образ контейнера, он должен изменить тег образа в манифесте в репозитории Git.
Разработчики могут также изменять манифесты напрямую через Git или через интерфейсы IDP. Неважно, взаимодействует разработчик с Git напрямую или через интерфейс: результат должен быть отправлен в Git и сохранён там.
Теперь инструменты GitOps должны обнаружить расхождение между состояниями манифестов, основанных на CRD, и привести желаемое состояние к фактическому. Кстати, это может быть буквально что угодно: контейнер в кластере, новый кластер, новая база данных, новое окружение...
Платформа также должна помогать наблюдать за желаемым состоянием: собирать необходимую информацию и предоставлять её в удобной форме.
Эфемерные окружения под запрос
Одним из ключевых достоинств Internal Developer Platform является возможность создания эфемерных окружений. Эфемерные — значит временные, они могут быть созданы и уничтожены по запросу, в том числе автоматически при определенном событии. Таким событием может быть, например, создание Merge Request.
Помимо автоматического создания, можно создавать временные среды в зависимости от конкретной потребности. Например, для тестирования разработок в изолированной среде. Это ускоряет как разработку, так и циклы выпуска. Эфемерные среды экономят время, которое обычно тратится на настройку постоянной среды. Это снижает нагрузку на DevOps и не требует постоянного наращивания и поддержки инфраструктуры.
Также особенностью эфемерных сред является то, что ими можно поделиться через уникальный URL-адрес. Различные заинтересованные стороны получают доступ к новой среде через URL-адрес и могут тестировать изменения кода, что также способствует улучшению коммуникаций между командами.
Эфемерные окружения являются клоном production-среды. Часто ошибка появляется только в рабочей среде, но не в промежуточной версии. Это может быть связано с разными конфигурациями окружений. Эфемерные среды — это копии вашей производственной среды, включая всю конфигурацию и список сервисов. Также эфемерная среда в идеале должна иметь те же данные, что и рабочая. Это гарантирует, что ваша временная среда станет настоящей копией production.
Примеров использования эфемерных окружений множество: для каждого Merge Request, для анализа производительности, для end-to-end тестирования, для onboarding, демонстрационные окружения для заинтересованных сторон. Добавляйте свои по вкусу.
Окружения для разработчиков — что в планах
В нашей компании мы особо выделяем и ценим создание эфемерных окружений для удалённой разработки. Это позволяет сотрудникам вести разработку в изолированной среде без необходимости настройки локального окружения.
Процесс разработки заключается в следующем: разработчик открывает свой ноутбук, свой любимый IDE и начинает программировать. Он может без проблем запустить своё приложение и протестировать его.
Но что делать, когда появляются зависимости, — например, нам надо развернуть базу данных, брокер сообщений, ещё пару сервисов. Тогда могут возникнуть проблемы в ресурсах машины, да и в настройке всей этой инфраструктуры. Появляется потребность подключиться к сервисам, расположенным где-то удалённо. Но как мы к ним подключимся? Можно, конечно, открыть порты в этих сервисах, но это небезопасно. Более того, это не будет работать, если вам нужна связь в обе стороны: например, если вы работаете над бэкендом и удалённый фронтенд должен подключиться к вашему сервису.
Здесь на помощь приходит утилита Telepresence, она поможет настроить коммуникацию вашего приложения с удалёнными сервисами так, как будто они находятся в локальной сети. Звучит отлично, но в некоторых случаях необходимо, чтобы приложение, над которым вы работаете, также было развёрнуто удалённо.

Далее предположим, что у разработчика в кластере развёрнуто личное временное окружение, в своём пространстве имён или в виртуальном кластере — не важно.
При внесении правки в приложение мы можем собрать новый образ, отправить его в реестр, затем развернуть в кластере. В автоматизации такого процесса нам может помочь утилита Skaffold от Google. На самом деле отправка в реестр — шаг опциональный, но тем не менее это очень медленный процесс: собирать образ после каждой правки.

В итоге мы хотим, чтобы каждое изменение в коде мгновенно было доступно и в кластере. И такие решения тоже есть, например DevSpace. Они отвечают за синхронизацию наших локальных файлов с контейнерами, работающими в кластере.

Мы планируем попробовать каждый из этих инструментов.
Инструментарий
На слайде я собрал инструменты для разработки платформы, которые мы уже используем или планируем использовать:

Буквально в нескольких предложениях объясню наш выбор конкретных инструментов. Всё пространство можно разделить на пять плоскостей.
Developer Control Plane: здесь разработчики приложений взаимодействуют с платформой. Она включает в себя: IDE — для написания кода, Version Control — для хранения кода и манифестов, Remote Development — для удалённой разработки в кластере, Developer Portal — для каталога сервисов, хранения документации и интерфейса IDP (красным — то, что мы планируем использовать).
Integration and Delivery Plane: здесь происходит создание и хранение образов, а также создание и управление конфигурациями приложений и инфраструктуры. Включает в себя: CI — для пайплайнов после очередных изменений репозиториев, Image Registry — для хранения контейнеров, Pipelines — прочие пайплайны для работы платформы, CD — для синхронизации желаемого и текущего состояний.
Monitoring and Logging Plane: эта плоскость для наблюдения за сервисами и инфраструктурой. Всю плоскость Observability также можно поделить на три основных столпа: трассировка, мониторинг и логирование.
Security Plane: плоскость безопасности сосредоточена на системе управления секретами. Менеджер секретов хранит информацию о конфигурации, такую как пароли, ключи API или сертификаты TLS, необходимые приложению или службе во время выполнения.
Resource Plane: именно здесь находится фактическая инфраструктура, включающая в себя кластеры, базы данных, хранилища и прочие сервисы.
Таким образом выглядит наш инструментарий.
Полезные ссылки
Ресурсы
Статьи
Видео
Комментарии (6)

dididididi
24.04.2024 18:04Я когда читал, у меня сфинткрометр из соседнего бы поста зашкаливал.
Звучит, как кошмар. Ещё одна абстракцияя которая будет постоянно падать, ломаться а девопсеры будут ныть что тут всё гибко и легко, просто ты не туда нажал, нам терь три дня восстанавливать

starhanov Автор
24.04.2024 18:04+1Любая абстракция, если её реализовать так, что она будет постоянно падать и ломаться, звучит как кошмар.
dididididi
24.04.2024 18:04Любая абстракция, которая реализует всё и сразу будет падать и ломаться.
Если б вы сказали, что ребята, вот мы прямыми руками сделали настройки на aws для жава-постгря-реакт-кафка пять лет её вылизывли, повыкидывали всё лишнее и теперь у нас конфетка, а тут к ней инструкия, то я б восхитился.
А вот когда сделали всё и сразу на любой язык и всё возможные технологии, то блин... Этот не звучит как надежно, просто, удобно. А звучит, как потрать сутки, чтоб объяснить твоёй проге, что в моём проекте нет Кафки, какого фига она падает с kafkaException.
PetyaUmniy
А почему "отсутствие локального окружения" так безапеляционно записывается в безусловные плюсы? Помоему это неочевидно.
Наличие локального окружения разработки может напорядки (буквально) сократить (как минимум для интерпритируемых языков) RTT между: написал код - увидел результат. Например в нашем случае имеется много проектов на php, результат внесения изменений в которые можно увидеть "нажав f5" на localhost'е. В противном же случае разработчику пришлось бы ждать отработки десятков разных сущностей под капотом ci pipeline'а (банально подготовить репо, собрать образы, прогнать линтеры, запустить развертывание review окружения, прогнать jobs, миграции и init контейнеры). Получить RTT меньше минуты с удаленным окружением на (нашей) практике невозможно.
А эта скорость: код -> результат, это именно то для чего devops организовался, это его основное предназначение. И она напрямую конвертируется в скорость поставки фитч на прод и комфорт работы разработчика (которому не нужно больше держать в памяти контекст предыдущего запуска CI и сопоставлять его с изменениями, которые он уже успел написать вперед пока pipeline pending).
dididididi
Ахах. У нас от 40 минут до полутора часов будет перезапускаться.
starhanov Автор
Удаленная разработка происходит следующим образом: у разработчика есть своё пространство в кластере, там развернуто его окружение, он локально разворачивает сервис, разрабатывает его, пишет юнит тесты, если ему надо проверить локальную версию сервиса во всем окружении, он подключает локальный код к кластеру и любая локальная правка попадает в под, минуя весь процесс CI/CD.
Да, это очевидный плюс, так как не у каждого есть машина, которая позволит развернуть всю инфраструктуру (postgres, rabbitmq, kafka, temporal, jaeger, krakend), десятки backend сервисов и всё это ещё и поддерживать. Плюс разработка ведётся в приближенном к production кластеру.