
В блоге компании опубликовано уже немало постов, посвященных векторизации, вот, например, довольно обстоятельный обзор принципов автовекторизации. С каждым выходом новых процессоров Intel тема становится все более актуальной для достижения максимальной производительности приложения. В этом посте я расскажу о Vectorization Advisor, который входит в знакомый многим Intel® Advisor XE и позволяет решить множество проблем векторизации кода. Однако сначала о том, зачем это нужно.

Рисунок 1. Ширина векторных регистров для разных микроархитектур процессоров
Важной частью новых микроархитектур процессоров является увеличения длины векторных регистров и появление новых наборов векторных инструкций, всем известных как MMX, SSE, AVX и AVX2, благодаря которым несколько однотипных операций становится возможным выполнять за одну инструкцию. Чтобы лучше понять, насколько векторизация может ускорить вашу программу, взглянем на следующий график.
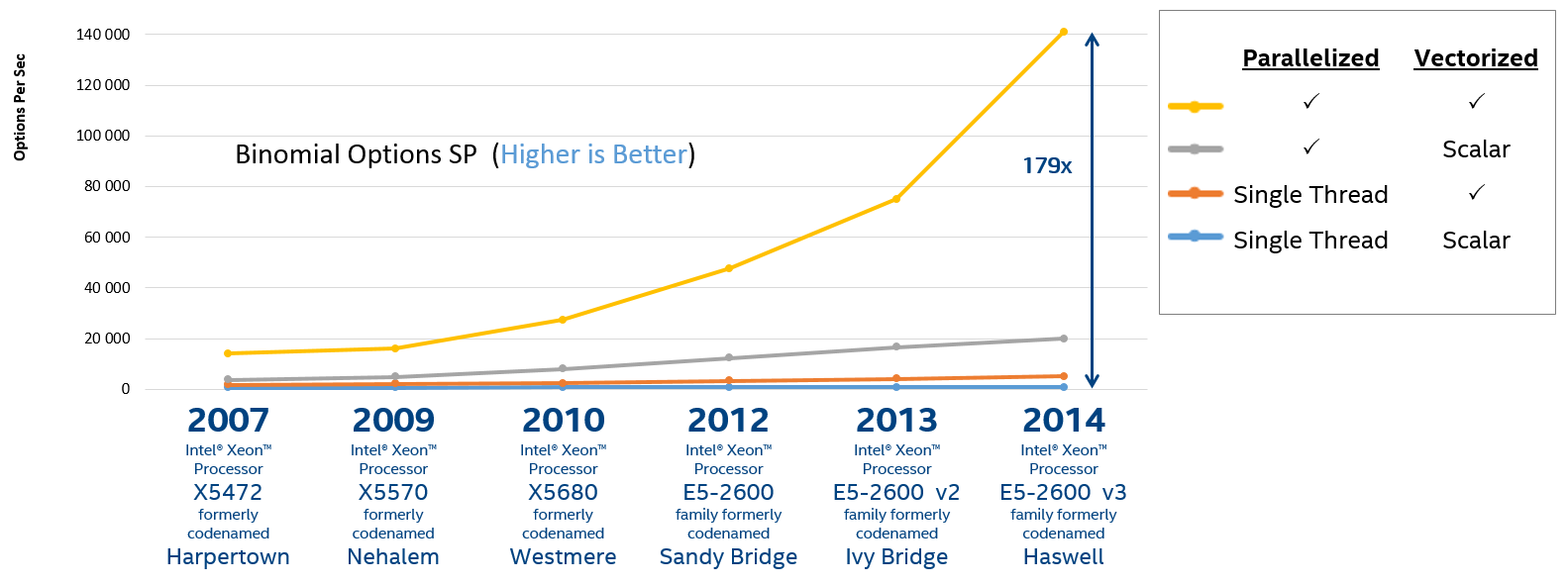
Рисунок 2. Производительность разных версий программы расчета биноминальных опционов
Несмотря на возможную синтетичность данного бенчмарка, он говорит о том, что не только уже знакомый многим параллелизм (threading), но и эффективное использование векторных регистров является ключевым фактором для достижения максимальной производительности. Существует несколько популярных путей достижения векторизации:
Кроме того, существуют более сложные способы, например, использование интринсиков и использование векторных инструкций в ассемблерном коде.
К счастью, с выходом новых версий компиляторов автовекторизация становится все более доступной и эффективной. Чтобы увидеть, насколько компилятор преуспел в этом деле можно добавить ключи компиляции (-optreport для Intel® Compilers) и прочитать отчет о векторизации с детализацией по каждому циклу и полученному ускорению. Но для многих случаев все далеко не так просто и приходится каким-либо образом помочь компилятору понять, что код можно и нужно векторизовать, либо переписать код, сделав код векторизуемым. Также, не стоит думать, что векторизованный код является по умолчанию максимально эффективным с точки зрения производительности. Часто можно увидеть, что цикл хоть и векторизовался, но реальное ускорение довольно невелико. Эти проблемы делают работу инженеров по оптимизации довольно трудной и рутинной: нужно изучить код, посмотреть сообщения от компилятора, исследовать ассемблерный код и шаблоны доступа к данным, проверить корректность новой версии, модифицировать требуемую часть, оценить производительность и т.д.
Хорошие новости: Vectorization Advisor существенно упрощает рутинную часть!
Пакет Intel® Parallel Studio XE даёт широкие возможности анализа кода на предмет оценки производительности, однако ранее оценка векторизации кода покрыта была не полностью. Intel® Parallel Studio XE 2016 Beta включает сильно обновлённый Intel® Advisor XE 2016 Beta, объединяющий фактически два продукта:
С чего начать? Чтобы сфокусироваться на проблемах производительности и их возможных причинах необходимо запустить Survey.
Итак, первое, что делает Vectorization Advisor – запускает ваше приложение и профилирует его. Инструмент представляет полный отчет по каждому циклу, включающий в себя анализ горячих точек (hotspots), статический анализ бинарных модулей, сообщения компилятора. Более того, новый продукт включает в себя рекомендации и диагностики от экспертов по векторизации, лишь часть из которых можно найти на Intel Developer Zone.

Рисунок 3. Подробный отчет о программе после Survey анализа
На приведенном здесь и ниже скриншотах видно, что после Survey пользователь получает много важной информации: сначала стоит обратить внимание на время, проведенное в цикле (Self и Total time), чтобы выбрать наиболее затратные по времени. Далее можно сфокусироваться на еще не векторизованных циклах. На рисунке 3 отмечен скалярный цикл, который мы далее будем рассматривать и оптимизировать. Для данного цикла имеется диагностика компилятора — информация о причинах, по которым цикл не был векторизован, здесь компилятор предполагает наличие зависимостей. Также, как показано ниже на скриншоте этапа 1.1 (рисунок 4), Vectorization Advisor ищет проблемы производительности и пути их решения, причем использует для этого не только информацию компилятора, но и статический анализ бинарного файла: оценки ускорения, различные характеристики ассемблерных инструкций, типы данных и так далее. Все эти данные можно найти здесь же, для каждого цикла.
Предполагается, что информации, полученной на этом этапе, достаточно, чтобы решить, что нужно улучшать и сделать первые шаги на пути к хорошо оптимизированной программе.
Часто для решения проблем с неэффективной генерацией векторизованных циклов нужно знать число итераций в цикле. Если число итераций не постоянно (соответственно, компилятор не может его оценить и использовать для оптимизации), то его можно измерить и дать компилятору подсказку. Для этого в Vectorization Advisor появился новый тип анализа — Trip Counts. Еще один плюс этого анализа – это то, что он интегрируется в общий профиль программы, собранный после Survey.
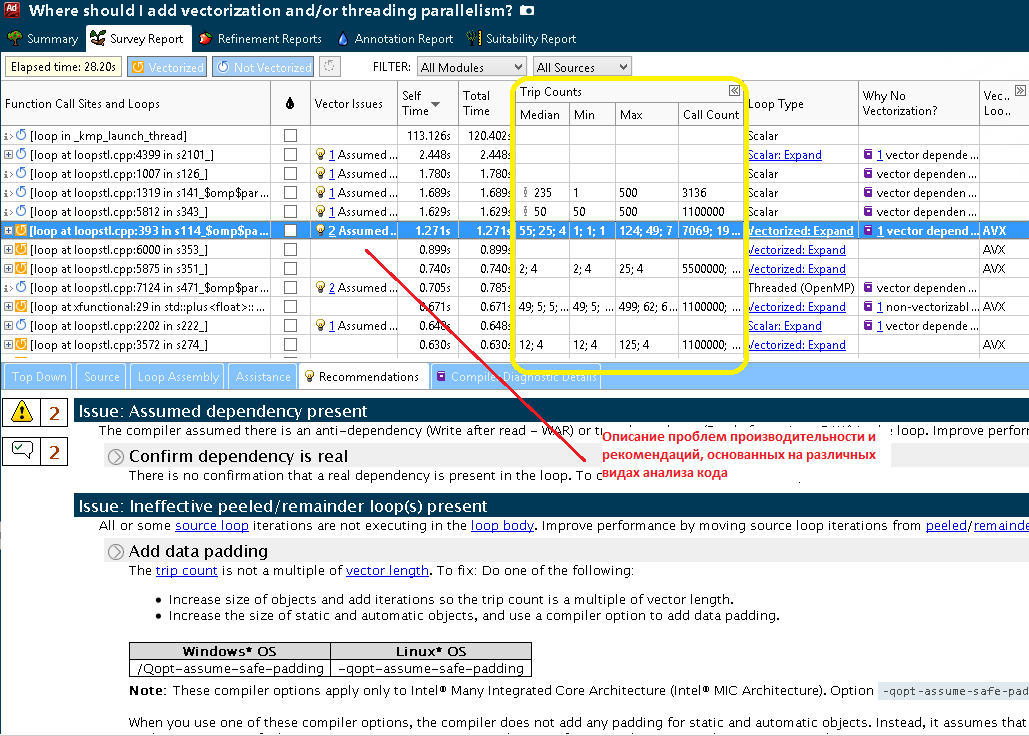
Рисунок 4. Отчет о программе, дополненный количеством итераций циклов
Желтым отмечены колонки, появившиеся после поиска числа итераций. Здесь мы видим среднее, минимальное и максимальное число итераций, а также число вхождений в цикл и индикатор, показывающий значительное число вхождений, имеющих отличное от среднего число итераций. Как было отмечено ранее, выбранный нами цикл не был векторизован из-за предполагаемого наличия зависимостей. Рассмотрим подробнее код примера:
Внешний цикл распараллелен с помощью потоков OpenMP. Внутренний цикл неплохо было бы векторизовать, однако Advisor XE говорит о возможных зависимостях по данным, проверим это.
Для проверки возможных зависимостей по данным, потенциально препятствующим векторизации, отмечаем интересующие нас циклы и запускаем Correctness.
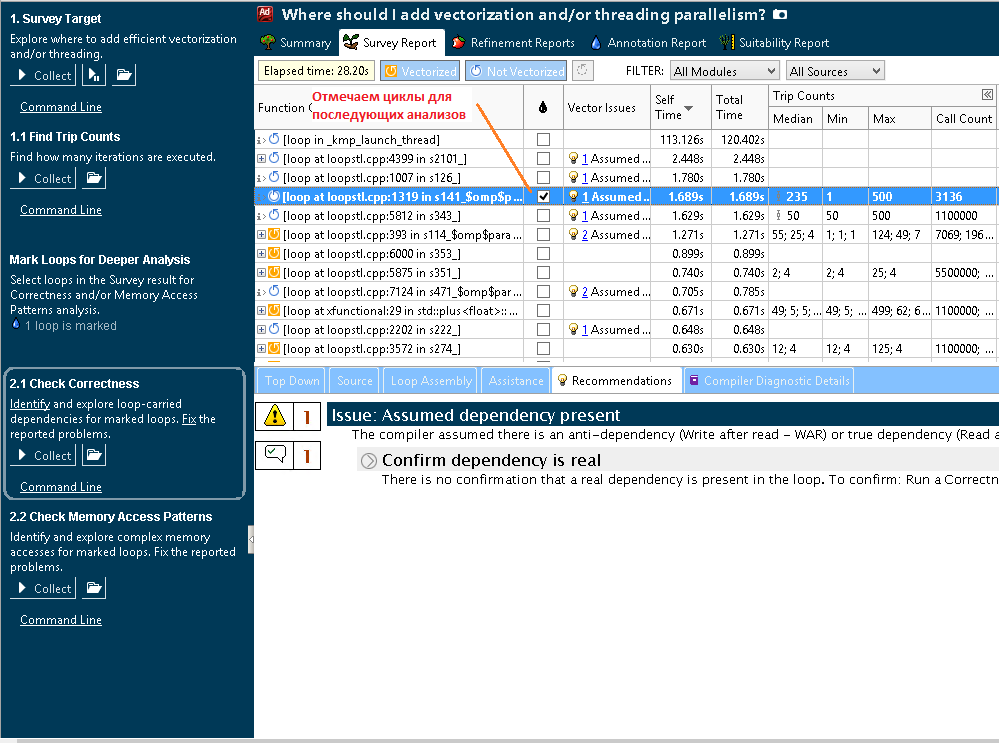
Рисунок 5. Выбор циклов для последующего анализа на корректность
После сбора данных видим, что Advisor XE не обнаружил на данном примере никаких проблем, исключающих возможность векторизовать код:

Рисунок 6. Отчет после анализа корректности
Поскольку мы убедились в безопасности векторизации (No dependencies found на рисунке 6), то «заставим» компилятор векторизовать интересующий нас цикл, для этого добавим директиву
Пересоберем Survey и получим следующий результат:

Рисунок 7. Полученный результат для выбранного для оптимизации цикла
Цикл векторизовался с использованием AVX инструкций. Время цикла упало до 0.77 секунды — получили ускорение более чем в 2 раза!
Аналогично анализу корректности, выбранные циклы можно проверить на эффективность работы с памятью. Это важно, поскольку векторизация может быть более или менее эффективна в зависимости от порядка доступа к данным, например, обращение к выровненным данным обычно дает более производительный код. Отметим циклы, по которым хочется получить информацию и запустим анализ Memory Access Patterns.
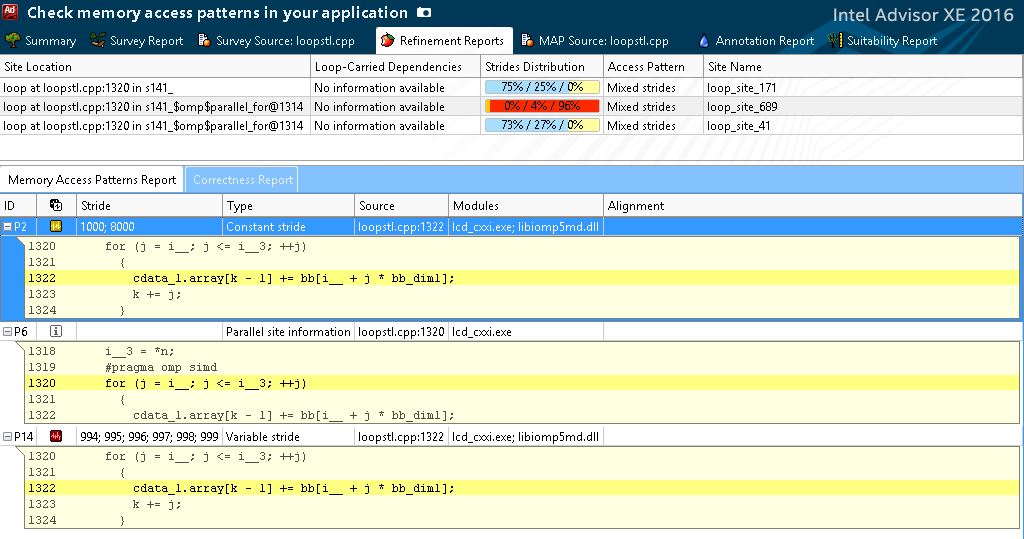
Рисунок 8. Отчет о шаблоне доступа к данным
Как мы видим на рисунке 8, шаг прохождения по массиву bb (stride) является константным и равен 8000 либо 1000 (равный в разных вызовах bb_dim1). Шаг же по массиву c_data_1.array является вариативным (994; 995; 996…), что, однако, исправить без переписывания алгоритма сделать довольно тяжело. Желательно сделать шаг единичным, организуя тем самым предвыборку данных, чем в конечном итоге занимается компилятор. Это можно увидеть по анализу инструкций в колонке Instruction Set Analysis, там присутствуют специфичные для этого Insert и Shuffles.
Vectorization Advisor будет полезен там, где уже есть работающий код, который нужно дополнительно векторизовать. При помощи нового инструмента каждый может получить не только полный отчет, содержащий в себе детализированное представление «узких» мест приложения, но и получить рекомендации по их устранению. Те, кто до появления Vectorization Advisor пытался проделать анализ вручную – будет экономить огромное количество времени, а те, кто еще не знал о том, что это возможно – получат замечательную возможность оптимизировать свое приложение самостоятельно!
Введение
Рисунок 1. Ширина векторных регистров для разных микроархитектур процессоров
Важной частью новых микроархитектур процессоров является увеличения длины векторных регистров и появление новых наборов векторных инструкций, всем известных как MMX, SSE, AVX и AVX2, благодаря которым несколько однотипных операций становится возможным выполнять за одну инструкцию. Чтобы лучше понять, насколько векторизация может ускорить вашу программу, взглянем на следующий график.
Рисунок 2. Производительность разных версий программы расчета биноминальных опционов
Несмотря на возможную синтетичность данного бенчмарка, он говорит о том, что не только уже знакомый многим параллелизм (threading), но и эффективное использование векторных регистров является ключевым фактором для достижения максимальной производительности. Существует несколько популярных путей достижения векторизации:
- автовекторизация компилятором;
- использование стандарта OpenMP* 4.0 (именно им я буду пользоваться далее) и Intel® Cilk™ Plus.
- управляемая компиляторная векторизация — использование векторных директив, таких как #pragma ivdep и #pragma vector;
- Intel® Cilk™ Plus Array Notation;
Кроме того, существуют более сложные способы, например, использование интринсиков и использование векторных инструкций в ассемблерном коде.
К счастью, с выходом новых версий компиляторов автовекторизация становится все более доступной и эффективной. Чтобы увидеть, насколько компилятор преуспел в этом деле можно добавить ключи компиляции (-optreport для Intel® Compilers) и прочитать отчет о векторизации с детализацией по каждому циклу и полученному ускорению. Но для многих случаев все далеко не так просто и приходится каким-либо образом помочь компилятору понять, что код можно и нужно векторизовать, либо переписать код, сделав код векторизуемым. Также, не стоит думать, что векторизованный код является по умолчанию максимально эффективным с точки зрения производительности. Часто можно увидеть, что цикл хоть и векторизовался, но реальное ускорение довольно невелико. Эти проблемы делают работу инженеров по оптимизации довольно трудной и рутинной: нужно изучить код, посмотреть сообщения от компилятора, исследовать ассемблерный код и шаблоны доступа к данным, проверить корректность новой версии, модифицировать требуемую часть, оценить производительность и т.д.
Хорошие новости: Vectorization Advisor существенно упрощает рутинную часть!
Пакет Intel® Parallel Studio XE даёт широкие возможности анализа кода на предмет оценки производительности, однако ранее оценка векторизации кода покрыта была не полностью. Intel® Parallel Studio XE 2016 Beta включает сильно обновлённый Intel® Advisor XE 2016 Beta, объединяющий фактически два продукта:
- Threading assistant – всё, что было в Intel Advisor раньше, с несколькими улучшениями.
- Vectorization Advisor – совершенно новый инструмент анализа SIMD программ.
С чего начать? Чтобы сфокусироваться на проблемах производительности и их возможных причинах необходимо запустить Survey.
Этап 1. Профилировка (Survey Target)
Итак, первое, что делает Vectorization Advisor – запускает ваше приложение и профилирует его. Инструмент представляет полный отчет по каждому циклу, включающий в себя анализ горячих точек (hotspots), статический анализ бинарных модулей, сообщения компилятора. Более того, новый продукт включает в себя рекомендации и диагностики от экспертов по векторизации, лишь часть из которых можно найти на Intel Developer Zone.
Рисунок 3. Подробный отчет о программе после Survey анализа
На приведенном здесь и ниже скриншотах видно, что после Survey пользователь получает много важной информации: сначала стоит обратить внимание на время, проведенное в цикле (Self и Total time), чтобы выбрать наиболее затратные по времени. Далее можно сфокусироваться на еще не векторизованных циклах. На рисунке 3 отмечен скалярный цикл, который мы далее будем рассматривать и оптимизировать. Для данного цикла имеется диагностика компилятора — информация о причинах, по которым цикл не был векторизован, здесь компилятор предполагает наличие зависимостей. Также, как показано ниже на скриншоте этапа 1.1 (рисунок 4), Vectorization Advisor ищет проблемы производительности и пути их решения, причем использует для этого не только информацию компилятора, но и статический анализ бинарного файла: оценки ускорения, различные характеристики ассемблерных инструкций, типы данных и так далее. Все эти данные можно найти здесь же, для каждого цикла.
Предполагается, что информации, полученной на этом этапе, достаточно, чтобы решить, что нужно улучшать и сделать первые шаги на пути к хорошо оптимизированной программе.
Этап 1.1 Нахождение числа итераций (Find Trip Counts)
Часто для решения проблем с неэффективной генерацией векторизованных циклов нужно знать число итераций в цикле. Если число итераций не постоянно (соответственно, компилятор не может его оценить и использовать для оптимизации), то его можно измерить и дать компилятору подсказку. Для этого в Vectorization Advisor появился новый тип анализа — Trip Counts. Еще один плюс этого анализа – это то, что он интегрируется в общий профиль программы, собранный после Survey.
Рисунок 4. Отчет о программе, дополненный количеством итераций циклов
Желтым отмечены колонки, появившиеся после поиска числа итераций. Здесь мы видим среднее, минимальное и максимальное число итераций, а также число вхождений в цикл и индикатор, показывающий значительное число вхождений, имеющих отличное от среднего число итераций. Как было отмечено ранее, выбранный нами цикл не был векторизован из-за предполагаемого наличия зависимостей. Рассмотрим подробнее код примера:
#pragma omp parallel for private(i__3,j,k,i__) schedule(guided) if(i__2 > 101)
for (i__ = 1; i__ <= i__2; ++i__)
{
k = i__ * (i__ + 1) / 2;
i__3 = *n;
for (j = i__; j <= i__3; ++j)
{
cdata_1.array[k - 1] += bb[i__ + j * bb_dim1];
k += j;
}
}
Внешний цикл распараллелен с помощью потоков OpenMP. Внутренний цикл неплохо было бы векторизовать, однако Advisor XE говорит о возможных зависимостях по данным, проверим это.
Этап 2.1 Проверка зависимостей (Check Correctness)
Для проверки возможных зависимостей по данным, потенциально препятствующим векторизации, отмечаем интересующие нас циклы и запускаем Correctness.
Рисунок 5. Выбор циклов для последующего анализа на корректность
После сбора данных видим, что Advisor XE не обнаружил на данном примере никаких проблем, исключающих возможность векторизовать код:
Рисунок 6. Отчет после анализа корректности
Поскольку мы убедились в безопасности векторизации (No dependencies found на рисунке 6), то «заставим» компилятор векторизовать интересующий нас цикл, для этого добавим директиву
#pragma omp simd#pragma omp parallel for private(i__3,j,k,i__) schedule(guided) if(i__2 > 101)
for (i__ = 1; i__ <= i__2; ++i__)
{
k = i__ * (i__ + 1) / 2;
i__3 = *n;
#pragma omp simd
for (j = i__; j <= i__3; ++j)
{
cdata_1.array[k - 1] += bb[i__ + j * bb_dim1];
k += j;
}
}
Пересоберем Survey и получим следующий результат:
Рисунок 7. Полученный результат для выбранного для оптимизации цикла
Цикл векторизовался с использованием AVX инструкций. Время цикла упало до 0.77 секунды — получили ускорение более чем в 2 раза!
Этап 2.2 Проверка шаблона доступа к данным Memory Access Patterns
Аналогично анализу корректности, выбранные циклы можно проверить на эффективность работы с памятью. Это важно, поскольку векторизация может быть более или менее эффективна в зависимости от порядка доступа к данным, например, обращение к выровненным данным обычно дает более производительный код. Отметим циклы, по которым хочется получить информацию и запустим анализ Memory Access Patterns.
Рисунок 8. Отчет о шаблоне доступа к данным
Как мы видим на рисунке 8, шаг прохождения по массиву bb (stride) является константным и равен 8000 либо 1000 (равный в разных вызовах bb_dim1). Шаг же по массиву c_data_1.array является вариативным (994; 995; 996…), что, однако, исправить без переписывания алгоритма сделать довольно тяжело. Желательно сделать шаг единичным, организуя тем самым предвыборку данных, чем в конечном итоге занимается компилятор. Это можно увидеть по анализу инструкций в колонке Instruction Set Analysis, там присутствуют специфичные для этого Insert и Shuffles.
Выводы
Vectorization Advisor будет полезен там, где уже есть работающий код, который нужно дополнительно векторизовать. При помощи нового инструмента каждый может получить не только полный отчет, содержащий в себе детализированное представление «узких» мест приложения, но и получить рекомендации по их устранению. Те, кто до появления Vectorization Advisor пытался проделать анализ вручную – будет экономить огромное количество времени, а те, кто еще не знал о том, что это возможно – получат замечательную возможность оптимизировать свое приложение самостоятельно!
ivorobts
Кроме того, что Vectorization Advisor будет полезен там, где уже есть работающий код, который нужно дополнительно векторизовать, он ещё помогает понять почему уже векторизованный код выполняется неэффективно.