
Введение
Задача размещения вершин графа на линейке является NP-полной[1]. Это означает то, что на данный момент не существует универсального алгоритма, который мог бы находить решение за полиномиальное время.
Данная задача имеет теоретическую ценность теории алгоритмов. Ее ценность заключается в том, что если будет найдет «полиномиально быстрый» алгоритм решение данной задачи, то и любая другая задача из класса NP может быть решена также «быстро», а это в свою очередь докажет равенство классов
 и
и  . До недавнего времени не существовало эффективного метода поиска решений NP-полных задач. С появлением эволюционного моделирование стало возможно находить квазиоптимальные решение за «приемлемое время».
. До недавнего времени не существовало эффективного метода поиска решений NP-полных задач. С появлением эволюционного моделирование стало возможно находить квазиоптимальные решение за «приемлемое время».Обоснования выбора генетического алгоритма:
- генетические алгоритмы продемонстрировали свою эффективность для решения задачы, плохо поддающихся решению традиционными методами;
- вычислительное время генетических алгоритмов для большинства приложений практически линейно зависит от размера задачи и числа оптимизируемых параметров;
Постановка задачи
Приведем постановку задачи. Основная цель алгоритмов размещения минимизировать общую суммарную длину ребер графа или гиперграфа.
В каждую ячейку в линейке может быть размещена вершина графа или гиперграфа. Расстояние между вершинами считается на основе следующей формулы[2]:
 (1)
(1)Здесь
 — позиции
— позиции  элементов (вершин графа) в линейке,
элементов (вершин графа) в линейке,  — расстояние между вершинами
— расстояние между вершинами  в линейке.
в линейке.Общая суммарная длина ребер графа вычисляется формулой[2]:
 (2)
(2)Здесь
 — общая суммарная длина ребер графа
— общая суммарная длина ребер графа  в линейке,
в линейке,  — количество вершин графа,
— количество вершин графа,  ,
,  — количество ребер соединяющих вершины ,
— количество ребер соединяющих вершины ,  .
.В оптимизационной задачи размещения входными данными являются вершины графа или гиперграфа
 , множество ребер графа
, множество ребер графа  или гиперграфа
или гиперграфа  и множество позиций
и множество позиций  . Причем
. Причем  , если производится размещение на заданные позиции.
, если производится размещение на заданные позиции.Сформулируем задачи размещение как оптимизационную. В качестве целевой функции выбирается формула (2) которую нужно минимизировать т. е.
 . Выходными данными будут позиции назначения каждой вершины. Теперь определим ограничения. Для каждого
. Выходными данными будут позиции назначения каждой вершины. Теперь определим ограничения. Для каждого  назначается только одна позиция
назначается только одна позиция  . Для каждой позиции соответствует, по крайней мере, одна вершина. Следовательно сформулирована задача размещения как оптимизационная.
. Для каждой позиции соответствует, по крайней мере, одна вершина. Следовательно сформулирована задача размещения как оптимизационная.Описание алгоритма
Генетические алгоритмы предназначены для решения задач оптимизации. В основе генетических алгоритмов лежит метод случайного направленного поиска. Для нашей задачи мы будем использовать классическую модель ГА, предложенную в 1975 г. Джоном Холландом (John Holland) в Мичиганском университете[3].
Схема алгоритма Холланда:
- Сгенерировать исходную популяцию, состоящую из
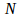 особей;
особей; - Оценить приспособленность хромосом в популяции на основе целевой функции
 ;
; - Выполнить операцию селекции;
- Применить генетические операторы (мутация, скрещивание);
- Сформировать новую популяцию;
- Если критерий останова алгоритма не достигнут, перейти к шагу 2, иначе завершить работу;
 ;
;Кодирование решений
Для начала нам нужно выбрать способ представления графа в виде хромосомы. Проанализировав различные способы кодирования, было выбрано кодирование перестановка: такой способ выбран по причине того, что нам нужно чтобы гены в хромосоме не повторялись. Приведем кодирование решений: имеется вектор
 ,
,  — количество вершин графа, как показано на рис. 1. Таким образом мы определили кодирование решений(хромосом).
— количество вершин графа, как показано на рис. 1. Таким образом мы определили кодирование решений(хромосом).
Рис. 1. Кодировка хромосомы
Стратегия отбора
В качестве метода селекции был выбран турнирный отбор[4]. Данный метод можно описать следующим образом: из популяции, содержащей
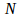 особей, выбирается случайным образом
особей, выбирается случайным образом  особей и лучшая особь записывается в промежуточную популяцию (между выбранными особями проводится турнир). Это операция повторяется раз. Затем особи в полученной промежуточной популяции скрещиваются (также случайным образом). С ростом параметра ужесточается отбор между особями, т.к. если у особи низкий показатель приспособленности, у нее нет шансов «завести потомство». Преимуществом данной стратегии является то, что она не требует дополнительных вычислений и упорядочивания особей в популяции по возрастанию приспособленности.
особей и лучшая особь записывается в промежуточную популяцию (между выбранными особями проводится турнир). Это операция повторяется раз. Затем особи в полученной промежуточной популяции скрещиваются (также случайным образом). С ростом параметра ужесточается отбор между особями, т.к. если у особи низкий показатель приспособленности, у нее нет шансов «завести потомство». Преимуществом данной стратегии является то, что она не требует дополнительных вычислений и упорядочивания особей в популяции по возрастанию приспособленности.Оператор скрещивания
В качестве оператора скрещивания (кроссинговера) был выбран модифицированный одноточечный[5] кроссинговер. По принципу работы оператора похож на одноточечный кроссинговер Холанда но т. к. нам нельзя чтобы гены в хромосоме после скрещивания повторялись использовался модифицированный оператор кроссинговера. Например у нас имеются пара хромосом-родителей. Случайным образом выберем точку разреза
 ,
,  . После того как была выбрана точка разреза, мы переносим все гены до точки разреза из родителя 1 в первого потомка, а из родителя 2 во второго потомка. Для того чтобы закончить потомка нам нужно заполнить вторую часть хромосом; для этого мы начинаем переносить гены после точки разреза из родителя 1 во второго потомка, а из родителя 2 в первого, но когда мы встречаем повторяющийся ген в потомке мы его пропускаем, так двигаясь до самого конца генов родителей. Если у нас получается так, что гены потомка еще не до конца заполнены, то мы начинаем брать гены сначала родителя, т. е. делаем цикличный сдвиг хромосомы в лево. Проиллюстрируем все выше сказанное. Например у нас имеется точка разреза
. После того как была выбрана точка разреза, мы переносим все гены до точки разреза из родителя 1 в первого потомка, а из родителя 2 во второго потомка. Для того чтобы закончить потомка нам нужно заполнить вторую часть хромосом; для этого мы начинаем переносить гены после точки разреза из родителя 1 во второго потомка, а из родителя 2 в первого, но когда мы встречаем повторяющийся ген в потомке мы его пропускаем, так двигаясь до самого конца генов родителей. Если у нас получается так, что гены потомка еще не до конца заполнены, то мы начинаем брать гены сначала родителя, т. е. делаем цикличный сдвиг хромосомы в лево. Проиллюстрируем все выше сказанное. Например у нас имеется точка разреза  , хромосомы-родители рис. 2.
, хромосомы-родители рис. 2.
Рис. 2. Хромосомы-родители
Теперь применим к ним описанный оператор кроссинговера рис. 3.

Рис. 3. Хромосомы-потомки
Таким образом мы получили двух потомков со схожими значениями приспособленности.
Оператор мутации
Оператор мутации в генетических алгоритмах используется для того, что бы «выбивать» решения из локальных оптимумов, которые далеки от глобальных.
Для мутации генов использовался простой способ обмена двух генов. Например у нас есть такая хромосома рис. 4. Теперь выберем случайно два гена и поменяем их местами рис. 5.

Рис. 4. Хромосома до мутации

Рис. 5. Хромосома после мутации
Параметры генетического алгоритма
Параметры подбирались методом проб и ошибок: алгоритм запускался с разными значениями параметров. Значение параметра считается «хорошим» если решения получились «хорошими». Вполне приемлемые результаты получались со следующими параметрами:
- порог вероятности мутации 0,01-0,1;
- размер популяции 20-30;
- параметр
 (количество особей в турнире);
(количество особей в турнире);
 (количество особей в турнире);
(количество особей в турнире);Заполнение исходной популяции выполнялось случайным образом.
Экспериментальные исследования
Отладка и тестирование проводились на ЭВМ типа IBM PC с процессором Intel Core i3 с ОЗУ-4Гб. Язык программирования C++. Были проведены исследования по определению эффективности предложенного генетического алгоритма. Проведенные экспериментальные исследования показали преимущество использования генетического алгоритма стандартным методам. Следующий пример показывает эффективность данного метода, на неком графе с
 . На рис. 6. случайная хромосома с общей суммарной длинной ребер
. На рис. 6. случайная хромосома с общей суммарной длинной ребер  .
.
Рис. 6. Случайная хромосома
После запуска алгоритма на 15 поколений общая суммарная длинна стала
 рис. 7.
рис. 7.
Рис. 7. Лучшая хромосома на 15 поколении
Если перебрать все варианты размещения для данного графа легко убедится, что целевая функция графа принимает меньшее значения при таком размещении. На самом деле целевая функция для данного графа является многоэкстремальной и мы просто нашли один из ее экстремумов.
Заключение
Результаты исследования позволяют сделать вывод о том, что предложенный подход к решению данной задачи оказывается эффективнее известных методов. Алгоритм хорошо подходит для графов больших размерностей, в таких случаях стандартные методы оказываются неэффективными по сравнению с методами эволюционного моделирования.
Список литературы
1. Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. Алгоритмы. Построение и анализ.
2. Емельянов В. В., Курейчик В. В., Курейчик В. М. Теория и практика эволюционного моделирования. — М.: ФИЗМАТЛИТ, 2003. — С. 264-275.
3. Holland J.N. Adaptation in Natural and Artificial Systems. Ann Arbor, Michigan: Univ. Michigan Press, 1975.
4. Цой Ю.Р. Стратегии отбора и формирования нового поколения [Электронный ресурс] / Ю. Цой. — Режим доступа: www.qai.narod.ru/GA/strategies.html
5. Панченко, Т. В. Генетические алгоритмы: учебно-методическое пособие / под ред. Ю. Ю. Тарасевича. — Астрахань: Издательский дом«Астраханский университет», 2007. — С. 20.
Комментарии (19)

hellman
26.04.2015 23:22+3Статья ни о чём.
Результаты исследования позволяют сделать вывод о том, что предложенный подход к решению данной задачи оказывается эффективнее известных методов.
Что за бред? Какие результаты? Две куцые картинки и предложение «Проведенные экспериментальные исследования показали преимущество использования генетического алгоритма стандартным методам»?
Vladislav_Dudnikov Автор
26.04.2015 23:37-2вот тебе график для графа на 100 вершин. Ось x — поколения, ось y — значение ЦФ.

второй график — график разности между полным перебором и ГА. Сначала я сгенерировал 1000 графов на 8 вершин. Потом нашел минимальные ЦФ полными перебором. Наконец получил результаты для тех же графов используя ГА(15 поколений). Ну и вычел результаты ГА от полного перебора.

Vladislav_Dudnikov Автор
26.04.2015 23:41Хочу заметить, что число комбинаций для графа на 100 вершин равно 9,332621544?10???.



iroln
27.04.2015 09:18-2Я думаю, автору надо определиться с целевой аудиторией и почитать вот эту статью: habrahabr.ru/post/217411

Mrrl
27.04.2015 09:37Я взял простейшую эвристику.
Строим последовательность вершин таким образом:
— задаём первую вершину
— дальше в цикле
— — для каждой из остальных вершин считаем разность между числом её соседей, которые уже добавлены в последовательность, и числом соседей, которые ещё не добавлены
— — добавляем в последовательность ту вершину, для которой эта разность максимальна.
После этого перебираем все перестановки пар вершин, и применяем те из них, которые улучшают целевую функцию — пока такие есть.
Повторяем для всех возможных первых вершин, выдаём лучший вариант.
На случайном графе из 100 вершин и 500 рёбер эта эвристика даёт результат на 6-10% лучше, чем генетический алгоритм с просчётом 1000 поколений — проверял на 100 графах — при приемлемом времени работы (её сложность примерно N^3, но, наверное, можно и улучшить).
A[k], добавляя к ней каждый раз ту вершину,Vladislav_Dudnikov Автор
27.04.2015 16:24Ну возможно так и есть. Но хотелось бы подробнее — дабы знать наверняка.

SemenovVV
27.04.2015 10:02+1До недавнего времени не существовало эффективного метода поиска решений NP-полных задач.
— так их и сейчас не существует.
С появлением эволюционного моделирование стало возможно находить квазиоптимальные решение за «приемлемое время»
— для оптимизации NP сложных задач существуют и другие методы, например
- Монте-Карло
- имитации отжига
- муравьинные
- и т.д.
— генетический алгоритм не единственный
Vladislav_Dudnikov Автор
27.04.2015 14:40имитации отжига
муравьинные
это эволюционное моделирование.
— так их и сейчас не существует.
Зависит от задачи. Можно найти удовлетворяющее решения посредством стохастических алгоритмов.SemenovVV
27.04.2015 15:11это эволюционное моделирование.
генетическое моделирование не является эволюционным?
До недавнего времени не существовало эффективного метода поиска решений NP-полных задач.
решение любой NP-полной задачи возможно для маленьких размерностей тупым перебором.Это эффективно. При увеличении размерности происходит экспоненциальный рост времени.
Смысл всех эволюционных и пр. эвристик в том, что сначала вы настраиваете свой алгоритм на маленьких размерностях и большом объеме случайных данных ( там где еще можно дождаться окончания перебора и получения точного решения) сравнением с реальным оптимумом, а потом предлагаете использовать эвристику на больших размерностях (где проверить результат перебором возможно будет еще не скоро)
Vladislav_Dudnikov Автор
27.04.2015 16:22Гм. Не «генетическое моделирование», а эволюционное. Вы просто мне предложили методы решения. Я сказал, что имитация отжига и муравьиный алгоритм это тоже ЭМ:
С появлением эволюционного моделирование стало возможно находить квазиоптимальные решение за «приемлемое время»
Вы же написали:
— для оптимизации NP сложных задач существуют и другие методы
Зачем было писать это? Если муравьиный и имитация отжига это тоже ЭМ?
решение любой NP-полной задачи возможно для маленьких размерностей тупым перебором.Это эффективно. При увеличении размерности происходит экспоненциальный рост времени.
Смысл всех эволюционных и пр. эвристик в том, что сначала вы настраиваете свой алгоритм на маленьких размерностях и большом объеме случайных данных ( там где еще можно дождаться окончания перебора и получения точного решения) сравнением с реальным оптимумом, а потом предлагаете использовать эвристику на больших размерностях (где проверить результат перебором возможно будет еще не скоро)
я собственно это и сделал. К чему это сказано?SemenovVV
27.04.2015 16:431 у вас в названии текста написано генетический алгоритм и далее тоже
именно поэтому я и добавил еще другие виды алгоритмов
2 то что вы это сделали никак не следует из вашего текста.
нет сравнительных результатов точное решение — ваше решение на разных исходных данных.
то что ваше решение дало правильные результаты на 1 варианте, хорошо но недостаточно.
Vladislav_Dudnikov Автор
27.04.2015 17:19Я написал, что с появлением ЭМ стало возможным… Муравьиный и имитация отжига это часть ЭМ.
вот график сравнения для 1000 графов:

отличие решения ГА от глобального состовляет максимум 6, а много где (в четверти я бы сказал) ГА нашел именно глобальный. Это для маленького количества поколений.

andy_p
27.04.2015 19:54+2> Емельянов В. В., Курейчик В. В., Курейчик В. М. Теория и практика эволюционного моделирования. — М.: ФИЗМАТЛИТ, 2003. — С. 264-275.
А, Курейчик. Знаем-знаем.
Valle
Больше всего мне понравилось «ЭВМ типа IBM PC».
valemak
Сразу ассоциативно всплывает персонаж Папанова, разрабатывающий план по захвату Семёна Семёновича Горбункова возле ресторана «Плакучая ива».
prolis
Пост проплачен.