
Или как без труда восстанавливать базы данных из длинной цепочки бэкапов

Введение
Если вы используете SQL Server, то, вероятно, слышали про Полную и Простую модель восстановления баз данных. Вы, возможно, знаете, что Простая модель позволяет восстановить данные только на момент создания резервной копии, в то время как Полная — на любой момент времени, надо лишь регулярно делать резервные копии журнала транзакций. Однако, для восстановления данных при Полной модели потребуется «накатить» резервные копии журналов транзакций в определенной последовательности. Это можно без проблем сделать с помощью SSMS, но только на том SQL Server, где создавались резервные копии. Для восстановления на другом сервере потребуется вручную написать T-SQL скрипт. И чем длиннее будет цепочка резервных копий, тем больше будет сам скрипт и тем больше времени уйдет на его создание. По этой же причине администраторы редко используют уже созданные резервные копии, когда требуется развернуть копию базы на другом SQL Server, и предпочитают создавать свежий полный бэкап. Но такая процедура может быть настоящей проблемой для больших баз данных из-за высокой нагрузки на сервер. Кроме этого, если сервер «упал», то, как правило, нет времени писать длинный T-SQL скрипт для восстановления. В такие моменты нужно делать все максимально быстро и без лишней нервотрепки.
В интернете, в том числе и на Хабре (например, тут), можно найти различные способы, решающие задачу автоматизированного построения T-SQL скрипта восстановления. В основном это различные скрипты, базирующиеся на названиях файлов резервных копий или запросы на сервер-источник к истории резервных копий (к базе msdb). В этой статье я хотел бы сделать обзор возможностей XML-планов восстановления, которые появились в Quick Maintenance & Backup for MS SQL начиная с версии 1.6.
Обзор самой утилиты можно почитать в статье по этой ссылке или на официальном сайте. Наличие XML-плана восстановления в сетевой папке вместе с резервными копиями позволит не тратить время на подготовку T-SQL скрипта. Какая бы длинная ни была цепочка резервных копий, вы в несколько кликов восстановите базу данных на другом SQL Server. Также это можно делать по расписанию, на тестовом или рабочем сервере, например, для проверки всей цепочки резервных копий или актуализации копий баз данных.
Что такое XML-план восстановления
XML-план восстановления — это XML-файл, в котором перечислены имена файлов резервных копий в последовательности, необходимой для восстановления одной или нескольких баз данных. Пример содержимого XML-файла:
<?xml version="1.0" encoding="cp866"?>
<RestorationPlanInfo xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.datacontract.org/2004/07/ScriptManagerServer.Core.ScriptManagerServerCore.BackupRestore">
<Version>1</Version>
<ServerName>London</ServerName>
<ServerVersion>10</ServerVersion>
<ServerDescriptrion>Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.1 (X64) </ServerDescriptrion>
<CreationDate>2016-02-16T17:00:04.65625+03:00</CreationDate>
<Databases>
<RestorationPlanDbInfo>
<Name>Northwind</Name>
<RestorePoint>2016-02-16T17:00:02</RestorePoint>
<Files>
<RestorationPlanDbFileInfo>
<FileName>London\Northwind\Full\20160216_155457_London_Northwind_Full.bak</FileName>
<BackupType>Full</BackupType>
<Position>1</Position>
<BackupStartDate>2016-02-16T15:54:57</BackupStartDate>
<FirstLsn>58000000021900037</FirstLsn>
<LastLsn>58000000023500001</LastLsn>
<StopAt i:nil="true" />
</RestorationPlanDbFileInfo>
<RestorationPlanDbFileInfo>
<FileName>London\Northwind\Diff\20160216_162546_London_Northwind_Diff.bak</FileName>
<BackupType>Differential</BackupType>
<Position>1</Position>
<BackupStartDate>2016-02-16T16:25:47</BackupStartDate>
<FirstLsn>58000000024300034</FirstLsn>
<LastLsn>58000000025800001</LastLsn>
<StopAt i:nil="true" />
</RestorationPlanDbFileInfo>
<RestorationPlanDbFileInfo>
<FileName>London\Northwind\Log\20160216_163000_London_Northwind_Log.trn</FileName>
<BackupType>Log</BackupType>
<Position>1</Position>
<BackupStartDate>2016-02-16T16:30:01</BackupStartDate>
<FirstLsn>58000000024300001</FirstLsn>
<LastLsn>58000000025800001</LastLsn>
<StopAt i:nil="true" />
</RestorationPlanDbFileInfo>
<RestorationPlanDbFileInfo>
<FileName>London\Northwind\Log\20160216_170001_London_Northwind_Log.trn</FileName>
<BackupType>Log</BackupType>
<Position>1</Position>
<BackupStartDate>2016-02-16T17:00:02</BackupStartDate>
<FirstLsn>58000000025800001</FirstLsn>
<LastLsn>58000000025800001</LastLsn>
<StopAt i:nil="true" />
</RestorationPlanDbFileInfo>
</Files>
</RestorationPlanDbInfo>
</Databases>
</RestorationPlanInfo>XML-файл всегда размещается в корневой папке с резервными копиями и содержит относительные пути до файлов резервных копий. Такая организация позволяет не терять актуальность после копирования файлов в другое место, например, в сетевую папку.
Создание XML-плана
Программа позволяет создавать XML-план двумя способами:
- Для тех, кто обслуживает базы данных с помощью QMB, достаточно установить свойство Создавать XML-план восстановления в политике обслуживания. Теперь XML-файл будет пересоздаваться каждый раз после создания любой резервной копии в сценарии обслуживания. Если в программе настроено копирование бэкапов в сетевую папку, то файл XML-плана также будет копироваться. Таким образом в сетевой папке будет всегда свежий XML-план восстановления.
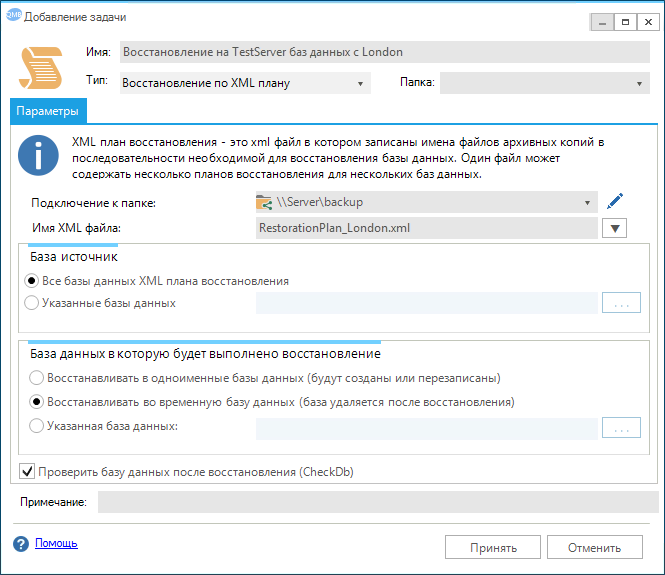
- Тем, у кого уже имеется штатный План обслуживания, создающий бэкапы, можно воспользоваться специальной задачей и по расписанию создавать XML-план восстановления. В задаче необходимо указать имя XML-файла, базы данных и подключение к папке, где будет создан XML-план восстановления, см. рисунок. Для того чтобы задача выполнялась по расписанию, её необходимо включить в сценарий.

Перед созданием XML-файла программа определит последовательность резервных копий по информации, хранимой в системной базе mdsb, аналогично тому, как это делает SQL Server Management Studio. Для первого и второго способов XML-план будет содержать последовательность резервных копий, необходимых для восстановления базы данных на последнее возможное состояние.
Важной особенностью является то, что при создании XML-плана программа всегда выполняет проверку наличия файлов резервных копий. Если хотя бы один из файлов не будет найден, то программа выдаст ошибку. Таким образом дополнительно контролируется целостность всей цепочки. Если XML-план создается при помощи задачи, то можно автоматически скопировать недостающие резервные копии с сервера источника. Для этого в задаче нужно установить соответствующий признак.
Восстановление по XML-плану
Восстановление баз данных по XML-плану может выполняться двумя способами:
1. Вручную. Для этого в программе имеется специальное окно, которое вызывается командой «Восстановить по XML-плану» из контекстного меню в древовидном списке серверов.
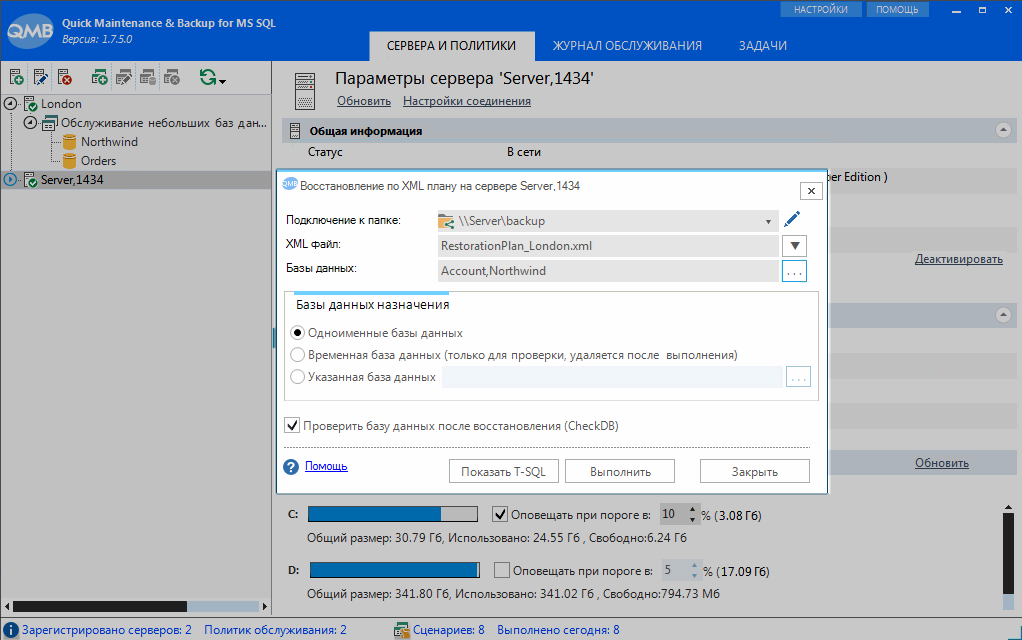
На форме нужно выбрать XML-файл и базы данных, резервные копии которых будут восстановлены. Обратите внимание, восстанавливать можно в одноименные базы данных, во временную, либо в указанную базу данных. Режим восстановления во временную базу данных удобен для проверки цепочки резервных копий. Режим в Указанную базу данных может быть полезен, если требуется восстановить в определенную базу данных, например, с нестандартным размещением её файлов на дисках. По кнопке «Показать Т-SQL» можно просмотреть сформированный T-SQL скрипт, который будет запущен для восстановления.
2. Автоматически по заданному расписанию. Например, если требуется регулярная проверка цепочки резервных копий на тестовом SQL Server, или актуализация баз данных. Для этих целей в программе предусмотрена специальная задача. Параметры, указываемые в задаче, практически аналогичны тем, что задаются на форме восстановления в ручном режиме.
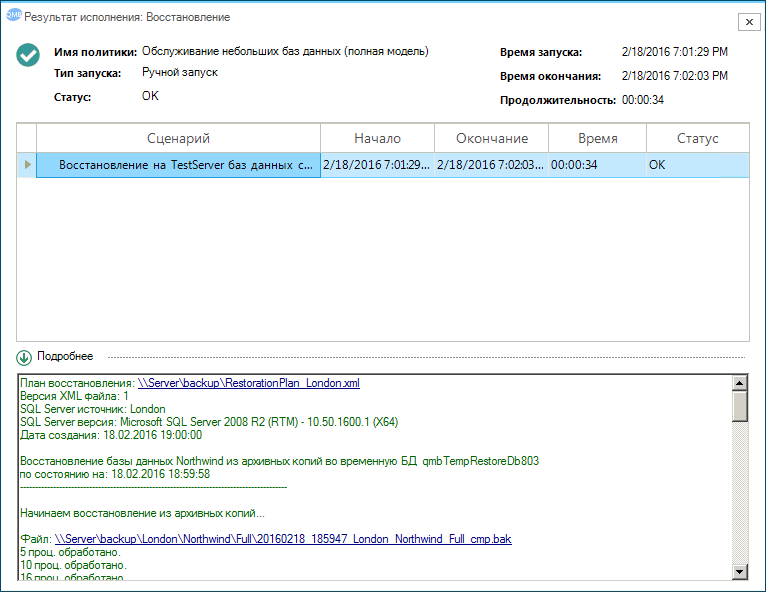
Для того чтобы задача выполнялась по расписанию, её необходимо включить в сценарий. Например, в ночной. Подробный лог восстановления можно просматривать в журнале обслуживания.
Заключение
Механизм XML-планов восстановления в QMB — это отличная возможность, позволяющая значительно облегчить жизнь администраторам при восстановлении данных с километровыми логами, переносе баз на другой SQL Server и проверке бэкапов. Механизм можно задействовать даже в тех случаях, когда для резервного копирования используется стандартный План обслуживания. В дальнейшем мы планируем подготовить статью, о том как это сделать с помощью программы.
Если вы уже используете QMB и не задействовали эту возможность, то скорее включайте XML-план восстановления! С удовольствием ответим на ваши вопросы в комментариях или по электронной почте support@qmbsql.ru
Комментарии (18)

gep2005
22.02.2016 05:27Поскольку предполагаю, что здесь в комментариях соберется большое количество знатоков SQL Server хочу спросить: А влияет ли на быстродействие базы модель восстановления (судя по названию нет :) )?

AlanDenton
22.02.2016 09:39Влияет. Иногда очень существенно. Почитайте про BULK INSERT и команды с минимальным протоколированием.

windcatcher
22.02.2016 13:13Не могу согласиться. Вопрос все-таки был немного другой. Основные модели восстановления это Полная и Простая. И с точки зрения производительности БД один одинаковы, т.к. в обоих случаях ведется журнал транзакций, только при Простой модели он усекается автоматически. Что касается модель восстановления с неполным протоколированием (Bulk Logged), то эта модель предназначена для временной замены Полной модели на период проведения массовых операций, например, массовой вставки данных или перестроением индексов.
AlanDenton
22.02.2016 14:11Разница все таки есть. Я не говорил, что она проявляется везде и всегда. Но она есть! Гипотетический пример. Удаление большого числа данных из таблицы:
SET NOCOUNT ON; DECLARE @r INT = 1 WHILE @r > 0 BEGIN BEGIN TRANSACTION DELETE TOP(10000) dbo.tbl --WHERE ... COMMIT TRANSACTION SET @r = @@ROWCOUNT CHECKPOINT -- SIMPLE BACKUP LOG -- FULL END
В случае SIMPLE модели восстановления, чтобы лог не рос нужно делать CHECKPOINT, для FULL спасает только бекап лога, который априори медленнее работает, чем CHECKPOINT. Хотя опять же с оговорками… Например, можно сделать бекап лога быстрее:
BACKUP LOG db TO DISK 'nul'
но ни к чему хорошему это не приведет, если мы говорим про продакшен.gep2005
22.02.2016 14:16Т.е. получается Full даже медленнее в отдельных случаях?
AlanDenton
22.02.2016 14:22FULL модель восстановления в некоторых случаях более интенсивно использует лог файл. Полноценный пример приведу в комментарии ниже минут через 15.
gep2005
22.02.2016 14:14Спасибо. Всегда было интересно. Просто в моих задачах с точки зрения восстановления простая модель вполне устраивает, но переживал, за быстродействие.
Но рекомендация разносить базу и журнал на разные диски все равно актуальна так? И автоматическое усечение не влияет на производительность?AlanDenton
22.02.2016 14:41SIMPLE:
SET NOCOUNT ON; USE [master] GO IF DB_ID('shrink') IS NOT NULL BEGIN ALTER DATABASE [shrink] SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE [shrink] END GO CREATE DATABASE [shrink] ON PRIMARY (NAME = shrink_data, FILENAME = N'D:\shrink_data.mdf', SIZE = 25MB, MAXSIZE = 200MB, FILEGROWTH = 10%) LOG ON (NAME = shrink_log, FILENAME = N'D:\shrink_log.ldf', SIZE = 3MB, MAXSIZE = 200MB, FILEGROWTH = 10%) GO ALTER DATABASE [shrink] SET RECOVERY SIMPLE USE [shrink] GO CREATE TABLE dbo.tbl ( c1 INT IDENTITY CONSTRAINT pk PRIMARY KEY NONCLUSTERED , c2 CHAR(3000) DEFAULT 'дефолтный бред' ) GO DECLARE @i INT = 1 WHILE @i <= 40000 BEGIN INSERT INTO dbo.tbl DEFAULT VALUES IF @i % 500 = 0 CHECKPOINT SET @i += 1 END GO DECLARE @i INT = 1 WHILE @i <= 20000 BEGIN DELETE FROM dbo.tbl WHERE c1 = @i IF @i % 500 = 0 CHECKPOINT SET @i += 1 END GO CHECKPOINT GO SELECT name, size * 8192 / 1048576 FROM sysfiles GO DBCC SHRINKFILE(shrink_data, 40) WITH NO_INFOMSGS GO SELECT name, size * 8192 / 1048576 FROM sysfiles
До шринка файла данных:
---------------- ----------- shrink_data 169 shrink_log 3
После шринка:
name ---------------- ----------- shrink_data 81 shrink_log 10
FULL:
SET NOCOUNT ON; USE [master] GO IF DB_ID('shrink') IS NOT NULL BEGIN ALTER DATABASE [shrink] SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE [shrink] END GO CREATE DATABASE [shrink] ON PRIMARY (NAME = shrink_data, FILENAME = N'D:\shrink_data.mdf', SIZE = 25MB, MAXSIZE = 200MB, FILEGROWTH = 10%) LOG ON (NAME = shrink_log, FILENAME = N'D:\shrink_log.ldf', SIZE = 3MB, MAXSIZE = 200MB, FILEGROWTH = 10%) GO ALTER DATABASE [shrink] SET RECOVERY FULL BACKUP DATABASE [shrink] TO DISK = 'NUL' USE [shrink] GO CREATE TABLE dbo.tbl ( c1 INT IDENTITY CONSTRAINT pk PRIMARY KEY NONCLUSTERED , c2 CHAR(3000) DEFAULT 'дефолтный бред' ) GO DECLARE @i INT = 1 WHILE @i <= 40000 BEGIN INSERT INTO dbo.tbl DEFAULT VALUES IF @i % 500 = 0 BACKUP LOG [shrink] TO DISK = 'NUL' SET @i += 1 END GO DECLARE @i INT = 1 WHILE @i <= 20000 BEGIN DELETE FROM dbo.tbl WHERE c1 = @i IF @i % 500 = 0 BACKUP LOG [shrink] TO DISK = 'NUL' SET @i += 1 END GO BACKUP LOG [shrink] TO DISK = 'NUL' GO SELECT name, size * 8192 / 1048576 FROM sysfiles GO DBCC SHRINKFILE(shrink_data, 40) WITH NO_INFOMSGS GO SELECT name, size * 8192 / 1048576 FROM sysfiles
До шринка:
-------------- ----------- shrink_data 169 shrink_log 3
После:
-------------- ----------- shrink_data 81 shrink_log 146
Итого: При FULL модели восстановления видим, что лог используется более интенсивно (10 метров против 146).
Но рекомендация разносить базу и журнал на разные диски все равно актуальна так?
Мало дисков не бывает. Если есть возможность, то разносите и радуйтесь жизни :)
И автоматическое усечение не влияет на производительность?
Очень сильно влияет. Увеличивает фрагментацию файлов базы, увеличивает фрагментацию индексов, много ресурсов тратиться на последующий AutoGrow. Почитайте при случае Auto Shrink Events.
windcatcher
22.02.2016 14:44Да, актуальна.
Усечение не влияет на производительность. По крайней мере так, чтобы это заметили пользователи.windcatcher
22.02.2016 14:49Увидел пост коллеги сверху. Поэтому пояснение — выше я писал про автоматическое усечении лога БД в Простой модели восстановления.
gep2005
22.02.2016 14:56Да. Спасибо. Я тоже про Простую модель говорил. Про настройку Автоусечения в параметрах базы знаю и так не делаю. В целом у меня все же складывается мнение, что в моих случаях вернее использовать простую модель, т.к. ни разу не возникало потребности восстановить базу на конкретный момент времени. (только возврат к конкретному бэкапу). Огромное спасибо за разъяснение обоим.
windcatcher
22.02.2016 15:21Восстановление на конкретный момент времени, это скорее доп. фишка, но тоже весомая. Тут главное восстановление на максимально актуальный момент времени. И тут что бы понять Простая или Полная модель вам нужна задайте главный вопрос: за какой период мы можем себе позволить потерять данные? За 15 минут, за 2 часа, за 1 день?
Если толкового ответа получить не у кого, то попытайтесь просчитать последствия сами. Сколько народу вводят данные одновременно? реально ли будет ввести данные повторно, например за день или только с обеда? есть ли другие системы с которыми обменивается ваша БД и будут ли работать обмен, если вы откатите БД? и т.п.
AlanDenton
22.02.2016 14:52И автоматическое усечение не влияет на производительность?
Усечение не влияет на производительность.
Влияет… опять же не всегда и везде! Поэтому может не стоит быть таким категоричным. Вашу статью будут читать в дальнейшем и такие комментарии начинающими могут быть восприняты буквально.gep2005
22.02.2016 15:00Да. Вы правы. Есть некоторая двусмысленность. Насколько я понял — не влияет автоусечение которое происходит само собой при модели восстановления "Простая". Но устанавливать такой параметр в настройках файлов базы и транзакционного лога не стоит.
AlanDenton
22.02.2016 15:15Еще раз повторюсь. Необоснованный SHRINK на производительность влияет всегда… При любой модели восстановления.
«Если Вы включаете AUTO_SHRINK на продакшене, то где-то в страшных муках умирает котенок...» об этом тоже нужно помнить :)
archimed7592
Если хочется без нервотрепки, то должен быть на готове сервер с необходимыми ресурсами (место на диске, память, процессоры). Если есть такой сервер, то достаточно включить log shipping и не нужно будет никакие километры логов восстанавливать, да и время на восстановление уйдёт гораздо меньше.
minamoto
log shipping уже не очень актуален, лучше уж AlwaysOn группу сделать тогда.
windcatcher
AlwaysOn — это кончено замечательно. Но к сожалению не каждая организация может себе позволить иметь резервный сервер, и тем более DBA в штате. Также AlwaysOn не отменяет бэкапы.