

Сегодня внезапно будет совсем не про презентации. Дело в том, что в прошлом я немного занимался a/b тестированием и вчера, в очередной раз попав на статью, где написано, что перед началом экспериментов нужно провести a/a тест (то есть такой, где контрольная группа видит ту же версию сайта, что и экспериментальная), я решил, что могу и должен добавить в этот вопрос свои две копейки. Получается непрофильно для моего блога, но один раз можно, наверное. Иначе меня разорвёт, да.
Одни из самых дорогостоящих ошибок a/b тестирования в смысле потерянных человеческих жизней были допущены при поисках лекарства от цинги. Уже после того, как вроде бы выяснилось, что лимоны от неё помогают, эксперимент был перепроведён, и там, уже в клинических условиях, больных лечили концентратом лимонного сока. А как в восемнадцатом веке получали концентрат? Конечно, длительным кипячением. Ну, вы поняли: клиническая проверка ранее полученные результаты не подтвердила. А нужно-то было всего лишь лечиться, как на фотографии к посту. Можно надеяться, что от ошибок в вашей системе a/b тестирования человеческие жизни напрямую не зависят, но нельзя считать, что ошибок в ней нет. И вот какова связь некоторых из них с a/a тестами.
Чем же плох контрольный эксперимент?
Терминологическое отступление
Я иногда буду называть a/a тест контрольным экспериментом или даже просто контролем. Также в случае настоящего a/b эксперимента контролем называется та совокупность пользователей, которая видит продакшен версию (она же контрольная группа или контрольная выборка), а не экспериментальную. Постараюсь, чтобы из контекста всегда было понятно, о чём именно идёт речь, и понятия «контроль» и «контроль» не путались.
Также я не смогу каждый раз писать «эксперимент выявил победителя с заданной статистической значимостью», и буду вместо этого использовать слова сработал или выстрелил. Если не выявил, то, стало быть, не сработал.
Собственно, претензия
Контроль перед началом реальных экспериментов недостаточен. Зачем люди его проводят? Чтобы проверить, что из двух одинаковых версий системы ни одна не выигрывает. Мы же все стреляные воробьи, знаем, что нужна статистическая значимость (знаем, правда ведь?), и устанавливаем её порог в наших инструментах, в зависимости от доступных пользователей, в 0.95 (если у нас в плане пользователей дремучая безысходная бедность), 0.99 (это плюс-минус нормальный случай) или в 0.999 и больше (если мы типа Гугл или Яндекс или придумали очень хорошую метрику, которую можно оценить с маленьким разбросом).
Что значат эти цифры? Порог статистической значимости нам говорит только о том, какую долю ошибок мы готовы допустить. Число 0.95 означает, что мы готовы принимать неверное решение в 0.05 случаев, то есть в среднем один раз из двадцати, при 0.99 — это уже один раз из ста и так далее. То есть некий фиксированный процент контролей имеет право показывать победителя, когда система работает штатно. Внимание, риторический вопрос: можно ли проверить штатную работу системы с одного запуска? Конечно, нет. Если в реализацию закралась проблема, то вовсе не обязательно все контроли будут выявлять победителя (выдавать т.н. false positive). Возможно, что их таких просто будет не один из двадцати, а два или три. Или даже полтора.
Можно ли проверить штатную работу системы двадцатью контрольными экспериментами для случая со значимостью 0.95? Как вы считаете, сколько должно быть false positive'ов из двадцати контролей при корректной работе системы?
Вероятности получить разное число срабатываний выглядят примерно так (справа там тоже не нули, просто их в таком масштабе не видно):
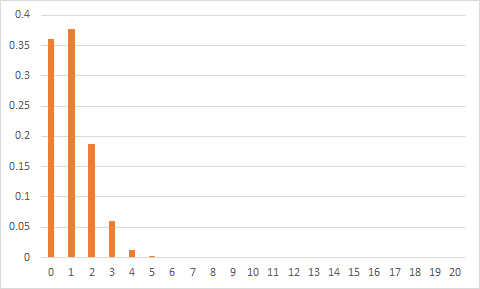
То есть вероятности получить один и не получить ни одного очень близки и велики, два — тоже легко, хотя и чуть сложнее, три — подозрительно, но возможно, при четырёх можно ставить деньги на то, что система работает некорректно, при пяти и более можно уже ставить не деньги, а части тела на то, что всё чёрт возьми растак и разэдак вообще в хлам сломано.
Не следует излишне радоваться, если мы не получили ни одного срабатывания. В этом случае нельзя исключать поломки в обратную сторону: у нас могла получиться система, которая вообще никогда не выявляет победителя. Это придётся проверить отдельно.
А теперь представим себе, что из двадцати экспериментов у нас срабатывают пять (то есть всё очень плохо), а мы провели только один. Шансы, что он сработает, всего лишь 0.25 (5 из 20). То есть, проведя один контроль над такой некорректной системой, мы в трёх случаях из четырёх ничего даже не заподозрим.
Так что же делать вместо контрольного эксперимента?
Вместо одного контрольного эксперимента в начале нужно проводить такие эксперименты постоянно (это в идеале) или хотя бы регулярно и следить за накапливаемой статистикой. Если вы вносите модификации, даже самые безобидные, в систему экспериментов, имеет смысл рассматривать статистику, накопленную в последней версии, отдельно. Если контрольные эксперименты выстреливают чаще, чем им полагается заданным уровнем значимости, это сильный сигнал о том, что что-то идёт не так.
О том, как именно это поможет
Конечно, постоянные контрольные эксперименты — не панацея, и с их помощью нельзя подстраховаться от вообще всех возможных проблем. Но довольно многие вещи вы со временем заметите, что я на примерах покажу ниже.
Классификация поломок
Прежде всего, отметим, что ошибка в системе экспериментов может прятаться в одном из двух мест:
- Система запуска экспериментов. Разбиение пользователей, определение, какому пользователю что показывать, вот это всё.
- Обсчёт результатов экспериментов. Вычисление метрики, реализация статтеста.
Ошибка может крыться как в реализации, так и в алгоритме или самой концепции того, как вы принимаете решения.
Ошибки в обсчёте результатов чуть менее травматичны: если у вас сохраняются логи пользовательской активности (логи? какие ещё логи?), то вы можете исправить ошибку и пересчитать все затронутые эксперименты задним числом, чтобы восстановить картину. Пользователи, конечно, не развидят то, что вы им по некорректным результатам экспериментов решили выкатить в продакшен, но вы хотя бы сможете понять, насколько плохо это было. Если же сломана система запуска экспериментов, то всё хуже. Чтобы понять, что же вы выкатывали все эти полгода, пока она работала некорректно, вам надо перепровести все затронутые эксперименты. Понятно, что для динамично развивающегося сайта восстановить версию, которая была полгода назад — фантастика, неосуществимая в реальной жизни.
Для пущей убедительности приведу по одному примеру концептуальных проблем в проведении экспериментов и в системе обсчёта.
Проблема с разбиением пользователей
Если наш проект растёт, у нас становится больше разработчиков и дизайнеров, и в какой-то момент пропускная способность системы экспериментов становится блокером для внедрения всего того потока
Это позволяет стандартизировать объём эксперимента внутри компании (если на этом фиксированном объёме за фиксированное время улучшение не выигрывает, значит, изменение недостаточно хорошо), а также избегать простоя пользователей. Выгода примерно такая же, как от контейнерных перевозок, эксперименты становится очень просто запускать и отслеживать.
Так вот, если некоторому бакету-неудачнику мы по ошибке покажем в эксперименте что-то по-настоящему ужасное (неработающие кнопки, битую вёрстку или очень плохой алгоритм агрегации контента) и заметим это не сразу, то пользователи из такого бакета ещё долго будут несчастны, и их поведение окажется отлично от поведения обычных пользователей, которые не подвергались пыткам. Товарищи из Бинга целенаправленно поймали такую ситуацию, когда после плохого эксперимента освободившийся бакет сделали контрольной группой. Число сессий на пользователя, которое там является основной метрикой (это и правда хорошая мера лояльности пользователей), в этом несчастном бакете ещё очень долго было ниже, чем в другом контрольном:
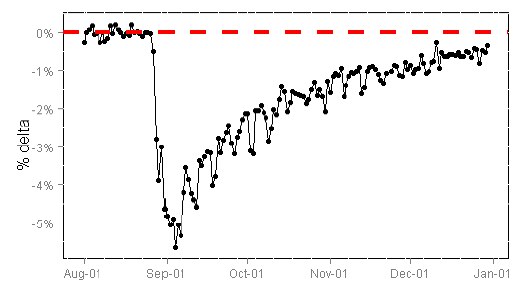
Картинка отсюда: www.exp-platform.com/documents/puzzlingoutcomesincontrolledexperiments.pdf
Хочу отдельно отметить, что реальность гораздо драматичнее этой картинки: люди разбиваются на бакеты по хэш-коду от куки, а за три месяца в бакете наверняка обновился довольно значимый процент пользователей, просто из-за протухания кук. То есть к концу третьего месяца в бакете уже довольно много
Мой собственный опыт подтверждает наличие постэффектов от эксперимента.
Если регулярно проводить контроли, то есть шанс заметить эту проблему и исправить её. Нет, шанс не 100%: если какие-то бакеты зафиксированы под контроли навечно, то там это не проявится. Но всё же. Для исправления, например, можно регулярно перемешивать пользователей между бакетами, добавляя ко всем пользовательским кукам (или тому, что вы используете для хэширования вместо кук) одинаковый модификатор.
Проблема в системе обсчёта экспериментов
В случаях, когда мы не ориентируемся непосредственно на конверсию (если мы не интернет-магазин, то это нормально), нам нужен какой-то показатель, вычисляемый из действий пользователя. Клики, заходы на сайт, whatever. Опасность таится в том, чтобы собирать все действия всех пользователей в одну большую кучу и считать среднее значение по ней.
Расчёт статистической значимости разницы полученных средних по заданной метрике в контрольной и экспериментальной выборках базируется на Центральной Предельной Теореме (в дальнейшем — ЦПТ). Она говорит нам, что среднее имеет нормальное распределение, а значит, мы можем хорошо оценивать доверительные интервалы и выносить вердикт о том, отличаются ли средние в контрольной и экспериментальной группах.
Подвох тут в том, что ЦПТ требует независимости усредняемых измерений.
На пальцах о независимости событий для тех, кто забыл
События считаются независимыми, если известный исход одного никак не влияет на вероятность наступления другого. Яркий пример зависимых событий — дожитие одним и тем же человеком до 80 и до 90 лет. Если мы знаем, что человек дожил до 90, то вероятность дожить до 80 для него равна 1. В обратную сторону, если человек не дожил до 80, то и до 90 он уже точно не доживёт. Некоторые исходы одного события влияют на вероятности исходов второго. В противоположность этому, для двух незнакомых, не связанных друг с другом людей дожитие до одного и того же возраста — события независимые. Конечно, всё в мире взаимосвязано, и для некоторых пар таких людей зависимость всё-таки есть, но на практике ею приходится пренебрегать.
Так вот, действия одного и того же пользователя на нашем сервисе в общем случае не являются независимыми событиями. Из близких мне примеров, предположим, что человек последовательно спрашивает у поиска что-то такое:
автомат калашникова цена
автомат калашникова купить
автомат калашникова настоящий купить
автомат калашникова не макет купить
нанять киллера
Если, скажем, мы считаем факт клика по каждому запросу (abandonment rate, хотя для поиска это и позавчерашний день, но, допустим, нам зачем-то понадобилось), то даже такой юзер, как в примере выше, скорее всего, не станет кликать по тем документам, на которые заходил из выдачи по предыдущим запросам. Ну или будет кликать с меньшей вероятностью, чем если бы задал такой запрос напрямую. И конечно, напрямую он бы его вообще не задал, если бы не предыдущие результаты. Особенно его расстроит то, что сказать «не макет» — верная гарантия получить макет, а он этого не понимает.
Уверен, каждый, кто захочет, и сам придумает другие метрики, для которых от одного пользователя берётся не одна, а несколько цифр в усреднение. Создать новую метрику и не заметить, что в ней есть элемент зависимости, очень легко. Так вот, бывает, что в такой ситуации контроли начинают срабатывать значительно чаще, чем им положено выбранным порогом значимости. Это, несомненно, значит, что и a/b эксперименты часто срабатывают случайно, и принимать по их результатам решения опасно.
Подведу итог
Выделять такой же объём пользователей под постоянный a/a эксперимент (или под несколько), как и под a/b эксперименты, которые вы проводите, — хорошая практика. Если следить за накапливаемой статистикой, то это помогает заметить некоторые проблемы, возникающие в системе проведения и обсчёта результатов пользовательских экспериментов. Контрольные эксперименты не должны в среднем выявлять победителя чаще, чем им положено заданным уровнем значимости. Если вы видите, что вместо одного эксперимента из двадцати у вас систематически срабатывают два-три, это повод задуматься. Такой мониторинг — не панацея, таким образом видно не всё, что там может сломаться, но дело однозначно полезное.