
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и наличие уточняющих вопросов
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало.
Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
AlphaGo дополняет этот поиск по дереву оценочными функциями на основе deep learning, чтобы оптимизировать пространство перебора. Статья изначально появилась в Nature (и она там за пейволлом), но в интернетах ее можно найти. Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Сначала поговорим про составные кусочки, а потом как они комбинируются
Шаг 1: тренируем нейросеть, которая учится предсказывать ходы людей — SL-policy network
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека.
Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела)
Важный момент — что нейросети дается на вход:
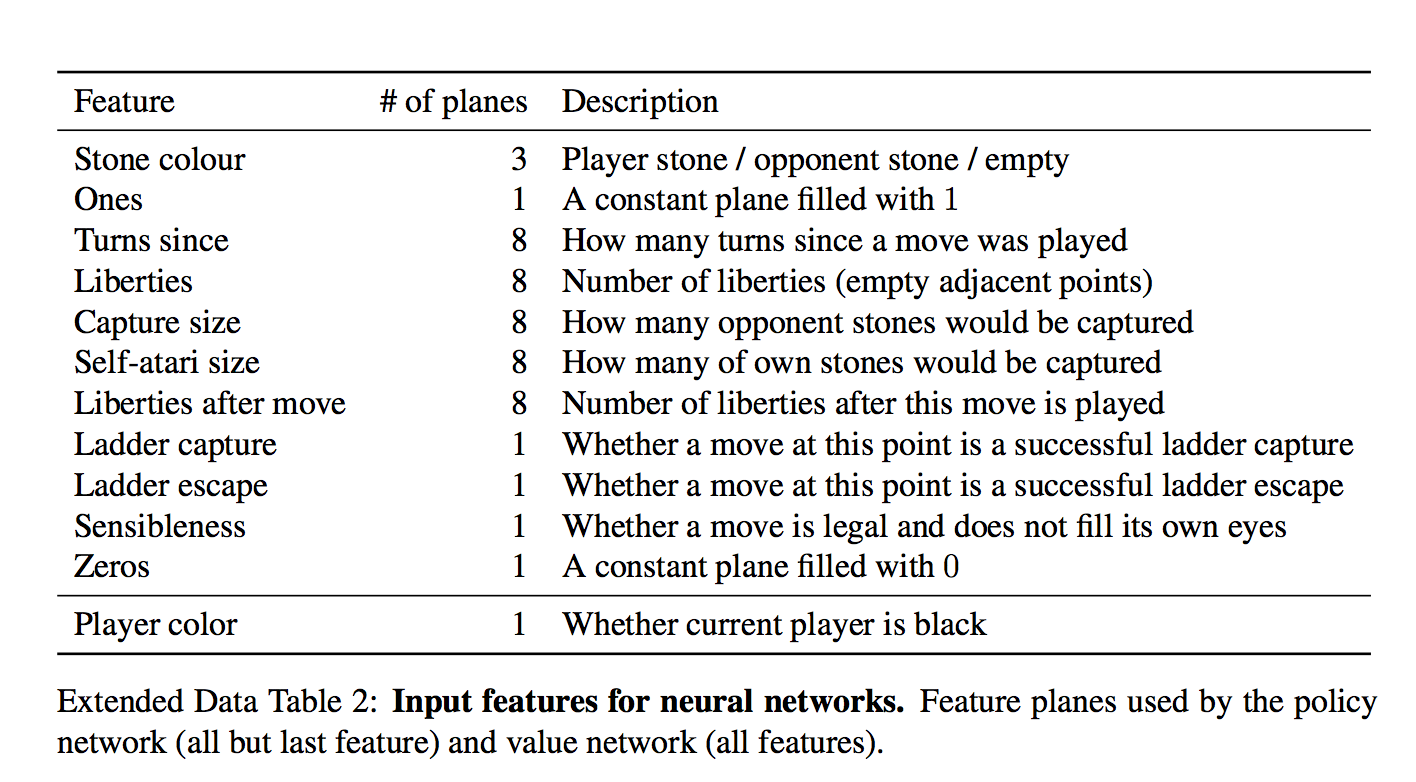
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича)
Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там!
Есть и тривиально вычисляющиеся фичи типа "количество степеней свободы камня", или "количество камней, которые будут взяты этим ходом"
Есть и формально неважные фичи типа "как давно было сделан ход"
И даже специальная фича для частого явления "ladder capture/ladder escape" — потенциально долгой последовательности вынужденных ходов.
а что за "всегда 1" и "всегда 0"?
Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен.
Авторы показывают, впрочем, что даже небольшие улучшения в точности сильно сказываются на силе в игре (сравнивая сетки разной мощности)
Отдельно от SL-policy, тренируют fast rollout policy — очень быструю стратегию, которая является просто линейным классификатором.
Ей на вход дают еще больше заготовленных фич

То есть, ей дают фичи в виде заранее заготовленных паттернов
Она гораздо хуже, чем модель с глубокой сетью, но зато сверх-быстрая. Как она используется — будет понятно дальше
Шаг 2: тренируем policy еще лучше через игру с собой (reinforcement learning) — RL-policy network
Выбираем противника из пула прошлых версий сети случайно (чтобы не оверфитить на саму себя), играем с ним партию до конца просто выбирая наиболее вероятный ход из предсказания сети, опять же без всякого перебора.
Единственный reward — это собственно результат игры, выиграл или проиграл.
После того, как reward известен, вычисляем как нужно сдвинуть веса — проигрываем партию заново и на каждом ходу двигаем веса, влияющие на выбор выбранной позиции, по градиенту в + или в — в зависимости от результата. Другими словами, применяем этот reward как направление градиента к каждому ходу.
(для любознательных — там чуть более тонко и градиент умножается на разницу между результатом и оценкой позиции через value network)
И вот повторяем и повторяем этот процесс — после этого RL-policy значительно сильнее SL-policy из первого шага.
Предсказание этой натренированной RL-policy уже рвет большинство прошлых программ, играющих в Го, без всяких деревьев и переборов.
Включая DarkForest Фейсбука?
С ней не сравнивали, непонятно.
Интересная деталь! В оригинальной статье пишется, что этот процесс длился всего 1 день (остальные тренировки — недели).
Шаг 3: натренируем сеть, которая "с одного взгляда" на расстановку говорит нам, какие у нас шансы выиграть! — Value network
Т.е. предсказывает всего одно значение от -1 до 1.
У нее ровно та же архитектура, что и у policy network (есть один лишний convolution layer, кажется) + естественно fully connected layer в конце.
То есть у нее те же фичи?
value network дают еще одну фичу — играет игрок черными или нет (policy network передают "свой-чужой" камень, а не цвет). Я так понимаю, это чтобы она могла учесть коми — дополнительные очки белым, за то что они ходят вторыми
Оказывается, что ее нельзя тренировать на всех позициях из игр людей — так как много позиций принадлежит игре с тем же результатом, такая сеть начинает оверфитить — т.е. запоминать, какая это партия, вместо того, чтобы оценивать позицию.
Поэтому ее обучают на синтетических данных — делают N ходов через SL network, потом делают случайный легальный ход, потом доигрывают через RL-network чтобы узнать результат, и обучают на ходе N+2 (!) — только на одной позицию за сгенерированную игру.
Итак, вот есть у нас эти обученные кирпичики. Как мы с их помощью играем?
TL;DR: Policy network предсказывает вероятные ходы чтобы уменьшить ширину перебора (меньше возможных ходов в ноде), value network предсказывает насколько выигрышна позиция, чтобы уменьшить необходимую глубину перебора
Внимание, картинко!
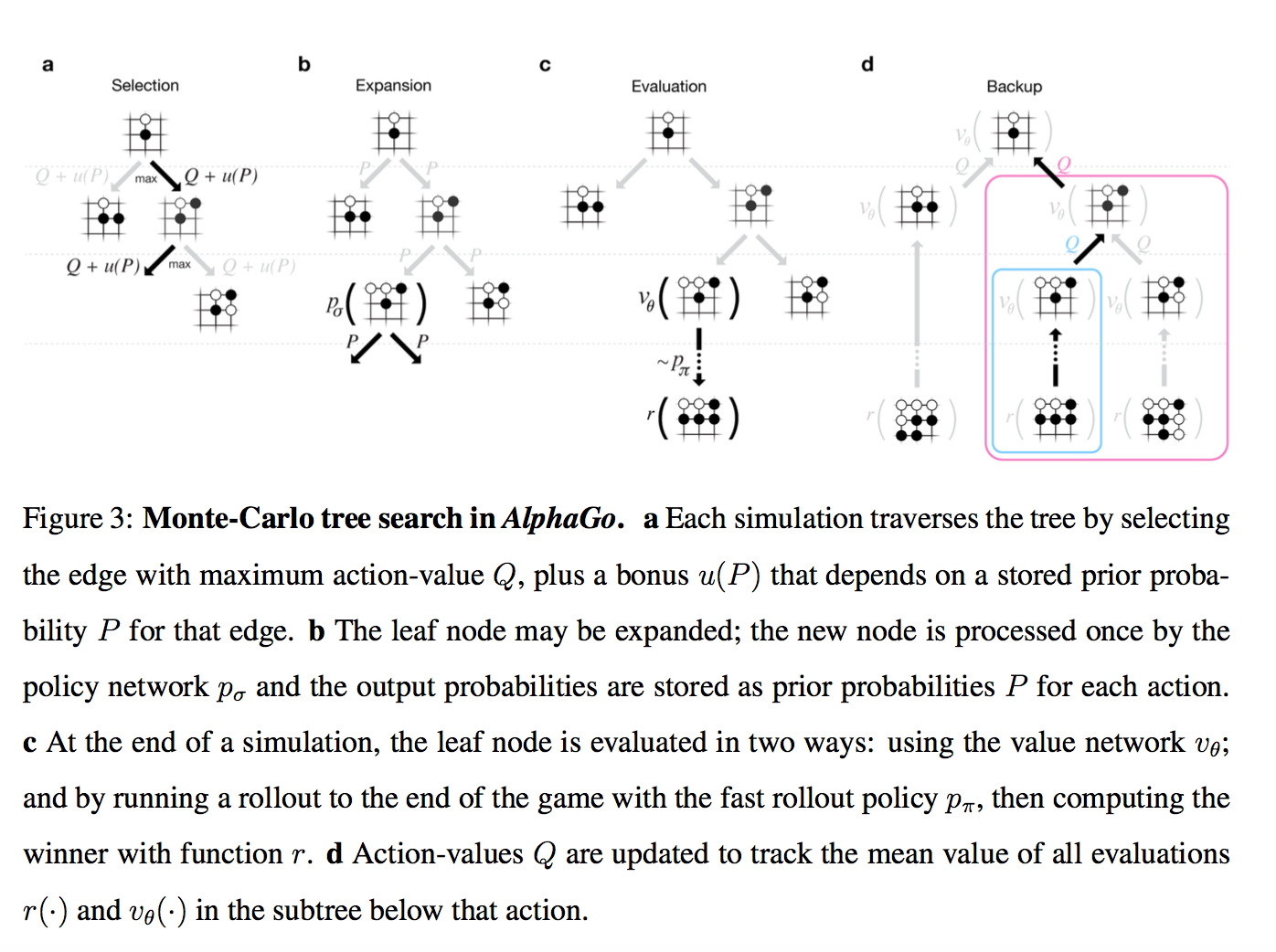
Итак, у нас есть дерево позиций, в руте — текущая. Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе.
Мы на этом дереве параллельно проводим большое количество симуляций.
Каждая симуляция идет по дереву туда, где больше Q + m(P). m(P) — это специальная добавка, которая стимулирует exploration. Она больше, если policy network считает, что у этого хода большая вероятность и меньше, если по этому пути уже много ходили
(это вариация стандартной техники multi-armed bandit)
Когда симуляция дошла по дереву до листа, и хочет походить дальше, где ничего еще нет…
То новый созданный нод дерева оценивается двумя способами
- во-первых, через описанный выше value network
- во-вторых, играется до конца с помощью супер-быстрой модели из Шага 1 (это и называется rollout)
Результаты этих двух оценок смешиваются с неким весом (в релизе он натурально 0.5), и получившийся score записывается всем нодам дерева, через которые прошла симуляция, а Q в каждом ноде апдейтится как среднее от всех score для проходов через эту ноду.
(там совсем чуть-чуть сложнее, но можно пренебречь)
Т.е. каждая симуляция бежит по дереву в наиболее перспективную область (с учетом exploration), находит новую позицию, оценивает ее, записывает результат вверх по всем ходам, которые к ней привели. А потом Q в каждом ноде вычисляется как усреднение по всем симуляциям, которые через него бежали.
Собственно, все. Лучшим ходом объявляется нод, через который бегали чаще всех (оказывается, это чуть стабильнее чем этот Q-score). AlphaGo сдается, если у всех ходов Q-score < -0.8, т.е. вероятность выиграть меньше 10%.
Интересная деталь! В пейпере для изначальных вероятностей ходов P использовалась не RL-policy, а более слабая SL-policy.
Эмпирически оказалось, что так чуть лучше (возможно, к матчу с Lee Sedol уже не оказалось, но вот с Fan Hui играли так), т.е. reinforcement learning нужен был только для того, чтобы обучить value network
Напоследок, что можно сказать про то, чем версия AlphaGo, которая играла с Fan Hui (и была описана в статье), отличалась от версии, которая играет с Lee Sedol:
- Кластер мог стать больше. Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
- Похоже, стала больше тратить времени на ход (в статье все эстимейты даны для 2 секунд на ход) + добавился некий ML на тему менеджмента времени
- Было больше времени на тренировку сетей до матча. Мое личное подозрение — принципиально то, что больше времени на reinforcement learning. 1 день в изначальной статье это как-то даже не смешно.
Пожалуй, все. Ждем 5:0!
Бонус: Попытка опенсурсной реализации. Там, конечно, еще пилить и пилить.
Комментарии (42)

varagian
11.03.2016 20:07+3Воодушевляет, что они собрали довольно известные методы, очень грамотно их настроили-объединили и получили такой скачок в результатах.
Что интересно, можно ли получить существенный прогресс, добавив туда expert knowledge, в духе классические шаги завершения комбинаций или локальные-глобальные стратегии?
sim0nsays
11.03.2016 20:12+2В некотором смысле, где есть feature engineering, там есть и expert knowledge. Часть системы — линейный классификатор на основе заранее заданных фич, что попадает в эту категорию. Возможно, если есть какие-то еще инсайты, можно добавить их к оценке нода.
Но все равно похоже они должны быть заданы так, чтобы модель можно было обучать. Иначе не получится адаптировать это для стратегии, которая эволюционирует через reinforcement learning.

dimview
12.03.2016 00:35+4Похоже, что уже нет. Майкл Редмонд (очень сильный профессионал, который комментирует матчи) характеризует некоторые ходы AlphaGo как странные, и только дальше по ходу матча выясняется, какая от этих ходов польза.
Кроме того, человеческая стратегия отличается от компьютерной, и похоже что это одна из причин, которая позволяет AlphaGo показывать такой хороший результат. Например, AlphaGo не пытается нарастить своё преимущество. Выигрыш на камень с вероятностью 90% для неё лучше выигрыша на пять камней с вероятностью 89%. Человек обычно пытается выиграть с некоторым запасом.sim0nsays
12.03.2016 01:10+5Второе, кстати, прямое следствие выбранного алгоритма — так как все метрики оперируют бинарным reward (победил или нет), то максимальным score будет обладать ветка, которая максимизирует именно это, а не margin.
Вообще говоря, можно натренировать версию, которая будет стремиться именно подавлять оппонента разгромным счетом :)

KvanTTT
11.03.2016 20:51+5Пожалуй стоит добавить в статью эту ссылку, энтузиасты начали воссоздавать ИИ AlphaGo на основе публикации и выложили это на гитхаб: AlphaGoReplication.

hasu0
12.03.2016 07:05+1По-моему, они выложили раньше, чем начали что-то воссоздавать. Ткнулся в десяток случайных файлов — все либо пустые, либо без какого-то внятного содержимого.
KvanTTT
11.03.2016 21:05+1Интересно, насколько ухудшится уровень, если запустить этот ИИ на обычно компьютере? И можно ли его так оптимизировать, чтобы его можно было перенести на обычный компьютер практически без ухудшения качества расчета. Просто Deep Blue, обыгравший Каспарова, тоже был суперкомпьютером, а сейчас даже с обычным компьютером практически бесполезно соревноваться. Понятно, что с тех времен мощности сильно выросли, но все же интересно, можно ли это сделать в теории с очень хитрыми и мощными эвристиками или же все упирается в вычислительную способность?
hombre
11.03.2016 21:10+2В статье в Nature подробно описывают, как изменяется сила алгоритма игры измеренная рейтингом ELO при различных вычислительных ресурсам
см. страницу 11
https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
hombre
11.03.2016 21:14+2Как пишут сами авторы по сравнению с Deep Blue, анализируется на 3 порядка меньше комбинаций:
AlphaGo evaluated thousands of times fewer positions than Deep Blue did in its chess match against Kasparov
Правда, насколько я понимаю, в этой оценке они ни учитывают стадию rollouts
sim0nsays
11.03.2016 23:48Теоретически если бы нейросети были натренированы лучше, то необходимое количество ресурсов становится радикально меньше. Весь вопрос — можно ли лучше натренировать? Никаких теоретических оценок или ограничений нет, в других задачах получается находить архитектуры и решения все точнее и точнее.
Глядишь и тут будет прогресс.KvanTTT
12.03.2016 01:45Мне кажется, что все ресурсы в основном уходят на перебор вариантов в Monte Carlo Tree Search. А с учетом этого:
Предсказание этой натренированной SL-policy (SL — supervised learning) уже рвет все прошлые программы Го, без всяких деревьев и переборов.
Походу на обычном компьютере или даже на планшете AlphaGo будет играть очень неплохо.sim0nsays
12.03.2016 02:34+2О, про это есть немного информации в статье. Проход по дереву выполняется всего на одной машине, кластер из 280 GPUs и 1500 чтоли CPU занимается исключительно вычислением policy и value networks + rollouts для новых годов дерева. Т.е. основная нагрузка перебора — это именно нейросети. Если бы они сужали перебор лучше, нужно было бы меньше перебирать.
Про второе — ну да, будет играть неплохо даже просто с SL-policy, но Lee Sedol не выиграет :)
sim0nsays
12.03.2016 07:06+3Кстати, в продолжение разговора —
Distributed version is only ~75% win rate against single machine version! Using distributed for match but single machine AG very strong also
https://twitter.com/demishassabis/status/708489093676568576
Даже на одной машине с ней могут соревноваться не больше 100 человек в мире поди
KvanTTT
12.03.2016 01:48В переводе не нашел информации, сколько весят нейронные сети в общем и по отдельности. И что означает
+ добавился некий ML на тему менеджмента времени.
sim0nsays
12.03.2016 02:37+1В каком переводе?.. То что у меня — это скорее вольное изложение :)
Про время — это что AlphaGo нужно принимать решение, сколько дозволенного времени тратить на ход. В статье про это было написано очень расплывчато, а потом Demis Hassabis в каком-то интервью сказал, что они обучили для этого какую-то модель


ProstoTyoma
12.03.2016 03:33А когда нейросети научатся программы писать?
И где в неолуддиты записываться? =)
dmandreev
12.03.2016 22:46+1Пока только научились с помощью LSTM "изучить" Linux kernel и на основе этой информации генерить нечто бредовое, но очень похожее. Важным в этом контексте являются Neural Turing Machines. Если это все как то хитрым способом скомбинировать, то наверное что то получится.
sashagil
12.03.2016 07:46Спасибо Семён! Я статью из Nature распечатал ещё тогда и просмотрел по диагонали, но не изучил. Ты пишешь очень доходчиво.
По делу — с точки зрения отличия от "настоящего" AI у меня к AlphaGo две претензии / предложения, попроще и посложнее:
попроще: было бы интересно узнать, во сколько раз больше вычислительных ресурсов потребовалось бы, чтобы натренировать сети до такого же отличного уровня игры чисто через игры с самой собой, без обучения на большой базе игр экспертов (ты про этот аспект написал, кстати? вроде не вижу...); посложнее: параметры системы (картинки-таблицы в твоей статье: топология сетей и параметры MCTS) тоже люди же подбирали, не само выросло... Вот эти дела чтобы самовыводились, это интересная (и гораздо более ресурсоёмкая) задача. Ты читал / слышал про General Game World Championships? http://www.general-game-playing.de/ (почему-то с 2011 года соревнования не проводились... Но сайт обновляется!)sim0nsays
12.03.2016 08:34+1Очень странная разметка у тебя :)
Насколько я понимаю, про успехи тотального reinforcement learning ничего не понятно. Демис из Deepmind только несколько раз упоминал, что прикольно было бы сделать без бутстрапа с человеческими партиями (он описан в Шаге 1 в этом посте).
Выбирать оптимальные гиперпараметры (это не только параметры сети, их в любом процессе много) — это отдельная специальная наука. Наиболее перспективны на сейчас — так называемые Gaussian Processes. Грозятся, что с некоторыми допущениями получается гарантировать близость к глобальному оптимуму за некоторое число шагов. Я статьи сам еще не прочитал, прочитаю — доложусь.sashagil
13.03.2016 05:11"прочитаю — доложусь" — давай! Я буду тебе напоминать.
"Очень странная разметка у тебя :)" — у них тут какой-то агрессивный markdown. Я всего лишь поставил то ли два, то ли три пробела в начале двух параграфов "попроще: ..." и "посложнее: ..." и, видимо, эти пробелы послужили сигналами, что я цитирую код или что-то такое. Потом, почему английский подхватился жирным, а после // пошло сереньким синтезированным италиком, ну, я не хочу даже разбираться (посты здесь не пишу, нет смысла инвестировать внимание в это).

leshabirukov
12.03.2016 16:36Интересно, не тренировали ли сеть на игру против конкретного человека? Просто меняя обучающую выборку. Это объяснило бы, почему игру Фан Хуэя так критиковали.
YoungSkipper
12.03.2016 16:55+2Не тренировали. Более того, ее даже не тренируют между матчами текущей партии для чистоты эксперимента.
sim0nsays
12.03.2016 20:25Им нужна обучающая выборка как можно больше, поэтому они просто берут все игры, до которых могут дотянуться.
leshabirukov
13.03.2016 08:24Вот неочевидно, что было бы, если бы из обучающей выборки исключили все игры Ли Седоля.

DennyRolling
13.03.2016 10:02+2ничего бы не было. количество его (да и всех человеческих) игр, по сравнению с играми которые АльфаГо играла сама с собой пренебрежимо мало.

f0rk
13.03.2016 21:30+1На пресс-конференции представитель гугла сказал, что в их базе партий Ли Седоля нет, по его словам я понял, что там вообще только партии сильных любителей были.
sim0nsays
13.03.2016 22:11Ага, было известно что у них только онлайн-матчи в изначальной выборке для тренировки, но я как-то думал, профессионалы в онлайне тоже играют

novoselov
12.03.2016 20:15+1AlphaGo выиграл со счетом 3-0
sim0nsays
12.03.2016 20:31+3Кто бы сомневался! Мы, кстати на http://closedcircles.com смотрим каждую игру в чате, сочувствующие — присоединяйтесь.
Вот инвайт
alex_blank
13.03.2016 10:35Ыы, привет. Сто лет тут тебя не было видно :) Как раз недавно перечитывал твою старую статью про mem latency тут, вспоминал старый геймдев.ру. В общем, здорово тебя тут видеть снова.
Набрел, кстати, на этот ваш closedcircles (через gamedeff.com), даже зарегался. А инвайт дает какие-то преференции?


zuborg
Мне кажется, это лазейка, чтобы подловить AlphaGo. Очередность ходов имеет значение. Есть камни, которые рано или поздно должны быть поставлены, но поставленные слишком рано они приносят не столько пользы, сколько поставленные в свое время.
sim0nsays
Ммм, следующий ход выбирается только из непосредственных детей рута. Т.е. это ближайший ход из возможных, через который чаще всего бегала симуляция.
zuborg
Т.е. частота это просто счетчик того, насколько детально анализировалась позиция (кол-во просмотренных (до конца?) дочерних подпозиций, грубо говоря)? Т.е. расчет делается на то, что чем более перспективный оказывается ход, тем более детально он рассматривается.
sim0nsays
В некотором смысле да, но я уточню.
Так как вероятность просмотра напрямую зависит от того, какой у позиции Q-score (симуляция выбирает ходы с максимумом Q + m(P)), то он очень коррелирует с тем, насколько выгодны позиции дерева за ним. Теоретически, можно выбирать и по максимуму Q-score напрямую, но вот они обнаружили, что по количеству чуть стабильнее.
У них в финальной версии даже есть эвристика, что если эти две метрики не сочетаются, надо прогнать дополнительные симуляции.