
И как бы, всё это погонять на стенде, чтобы убедиться в правильности выбора?
С учетом курса одной, всем известной валюты, хочется чего-то простого, без излишеств и, по возможности, бесплатного. Тем более, когда речь идет о малой или средней компании (стартапе), ограниченной в бюджете.
Что нам требуется?
- Совместимый с оборудованием гипервизор
- Кластер, с доступом к админке через веб-интерфейс
- High Availability для виртуальных машин в кластере
- Функция бэкапа и восстановления из коробки
- Доступность для понимания и работы среднему администратору (вчерашнему школьнику-студенту).
Из Open-Source решений, наиболее простым в установке и настройке является Proxmox. Чтобы не оскорблять любителей oVirt и пр. (это не рекламная статья), оговорюсь, что изначальное требование к простоте установки и администрирования, на мой взгляд, у Proxmox все же более выражено. Также, повторюсь, у нас не ЦОД, а всего лишь кластер из 2-3 нод для небольшой компании.
В качестве гипервизоров он использует KVM и LXC, соответственно держит KVM ОС (Linux, *BSD, Windows и другие) с минимальными потерями производительности и Linux без потерь.
Итак, поехали:
Установка гипервизора простейшая, качаем его отсюда:
Инсталлируется буквально в несколько кликов и ввод пароля админа.
После чего, нам выдается окно консоли с адресом для веб-интерфейса вида
172.16.2.150:8006(здесь и далее адресация тестовой сети).
Далее, устанавливаем вторую и третью ноды, с аналогичным результатом.
Запускаем кластер:
1. Настраиваем hosts на pve1.local:
root@pve1:~# nano /etc/hosts
127.0.0.1 localhost.localdomain localhost
172.16.2.170 pve1.local pve1 pvelocalhost
172.16.2.171 pve2.local pve2
2. Настраиваем hosts на pve2.local:
root@pve2:~# nano /etc/hosts
127.0.0.1 localhost.localdomain localhost
172.16.2.171 pve2.local pve2 pvelocalhost
172.16.2.170 pve1.local pve1
3. По аналогии настраиваем hosts на pve3.local
4. На сервере pve1.local выполняем:
root@pve1:~# pvecm create cluster
5. На сервере pve2.local выполняем:
root@pve2:~# pvecm add pve1
6. Точно так же, настраиваем и добавляем в кластер третий хост pve3.local.
Обновляем все ноды:
Приводим в соответствие репозиторий:
root@pve1:~# nano /etc/apt/sources.list
deb http://ftp.debian.org.ru/debian jessie main contrib
# PVE pve-no-subscription repository provided by proxmox.com, NOT recommended for production use
deb http://download.proxmox.com/debian jessie pve-no-subscription
# security updates
deb http://security.debian.org/ jessie/updates main contrib
Комментируем ненужный репозиторий:
root@pve1:~# nano /etc/apt/sources.list.d/pve-enterprise.list
# deb https://enterprise.proxmox.com/debian jessie pve-enterprise
И обновляемся (на каждой ноде соответственно):
root@pve1:~# apt-get update && apt-get dist-upgrade
Все, кластер готов к бою!

Здесь, мы уже из коробки имеем функцию бэкапа (называется резервирование), что подкупает практически сразу же!
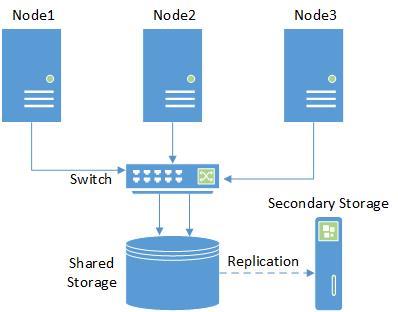
Хранилище:
Далее, возникает вопрос выбора общего хранилища.
Выбираем ISCSI (как наиболее бюджетный вариант) Storage:
В принципе, при настройке можно ограничиться одним интерфейсом, однако в кластере нельзя иметь одну точку отказа, поэтому лучше использовать multipath от Proxmox, либо объединение интерфейсов от самой хранилки.
Здесь, можно взять какое-то коммерческое хранилище, дисковую полку и пр.
Собственно, первый тест проводился как раз вместе с решением от Infortrend.
Но опять же, что делать если бюджет ограничен просто донельзя (или его просто нет)?!
Проще всего, набить дисками то железо, что есть, и сделать из него хранилище, позволяющее добиться поставленных целей.
В итоге, нам необходимы возможности (с учетом того, что компания может резко расшириться):
- Unified storage: NAS/SAN
- iSCSI target functionality
- CIFS, NFS, HTTP, FTP Protocols
- RAID 0,1,5,6,10 support
- Bare metal or virtualization installation
- 8TB+ Journaled filesystems
- Filesystem Access Control Lists
- Point In Time Copy (snapshots) support
- Dynamic volume manager
- Powerful web-based management
- Block level remote replication
- High Availability clustering
- Основные функции должны присутствовать в Open-Cource/Community версии.
После некоторых мук выбора, остались OpenFiler и NexentaStor.
Хотелось бы конечно, использовать Starwind или FreeNAS (NAS4Free), но если одному для работы нужен Windows и шаманство с ISCSI, то у другого функция кластеризации допиливается хорошим напильником.
OpenFiler к сожалению, имеет скудный GUI и последняя версия у него от 2011 года. Так что остается NexentaStor.
У неё, конечно же, схема работы active-active в кластере Nexenta уже платная, если вам такой понадобится в дальнейшем. Также если в хранилище 2 ноды (контроллера) то поддержка второго тоже за деньги! Собственно, все плагины доступны только в Enterprise версии.
Однако то, что доступно в Community версии, покрывает большинство начальных потребностей. Это и 18ТБ объема хранилища, и ZFS со снэпшотами, и возможность репликации из коробки!
Установка NexentaStor Community Edition:
Прежде всего, необходимо изучить Compatibility List.
Дистрибутив качаем отсюда (понадобится регистрация, чтобы получить ключ для установки).
Процедура установки проста, насколько это возможно, в ее процессе настраиваем IP-адрес с портом для настройки в GUI.
Далее, последовательно кликая по запросам визарда, задаем в GUI пароль и массив (в Nexenta он называется Volume).
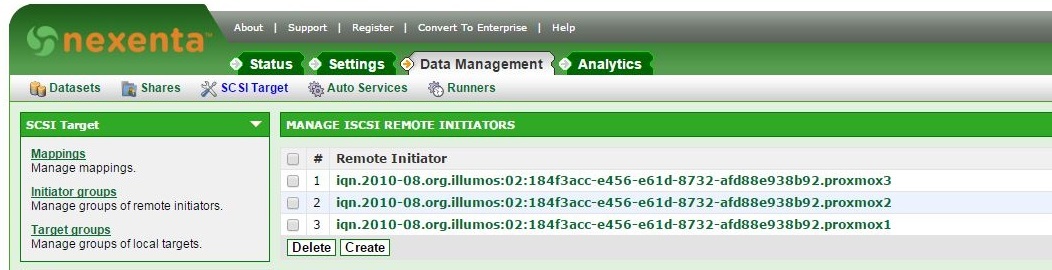
Далее идем в раздел SCSI Target и последовательно создаем:
- Target Portal Groups
- Targets
- Remote Initiators — для каждой ноды:
Далее, в соответствии с мануалом:
root@pve1:~# mkdir /etc/pve/priv/zfs
root@pve1:~# ssh-keygen -f /etc/pve/priv/zfs/172.16.2.150_id_rsa
root@pve1:~# ssh-copy-id -i /etc/pve/priv/zfs/192.16.2.150_id_rsa.pub root@172.16.2.150
Копируем ключ на каждую ноду:
root@pve1:~# ssh -i /etc/pve/priv/zfs/172.16.2.150_id_rsa root@172.16.2.150
Подцепить ISCSI хранилище в Proxmox, можно двумя способами:
Через меню ISCSI в добавлении хранилища (придется создавать дополнительный LVM) — см.мануал.
Через меню ZFS over ISCSI — см.мануал.
Мы пойдем вторым путём, так как он даёт нам возможность создания и хранения снэпшотов. Также, это может делать и Nexenta.
Процесс настройки в GUI выглядит вот так:
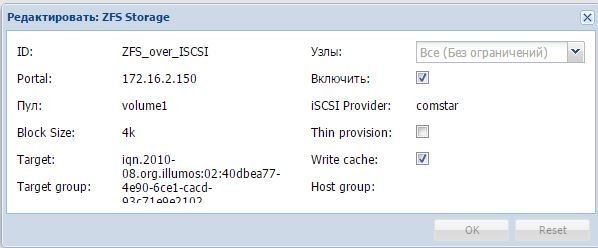
В итоге получается:
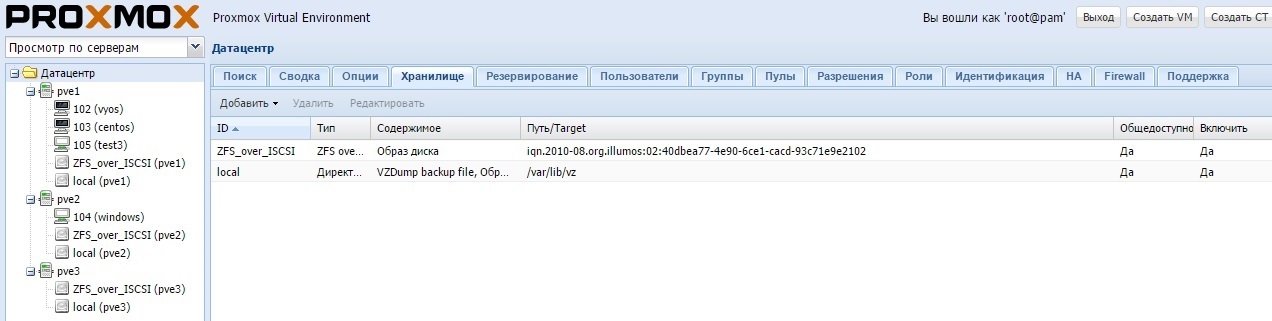
При настройке не перепутайте имя пула (в nexenta он аналогичен Datastore):
root@nexenta:~# zpool status
pool: volume1
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
volume1 ONLINE 0 0 0
c0t1d0 ONLINE 0 0 0
errors: No known data errors
Теперь мы можем выбирать, как и что бэкапить.
Можем сделать автоматический бэкап VM на удаленное хранилище прямо из Proxmox:
Т.е. заходим во вкладку «Хранилище» и добавляем NFS-массив. Это может быть как обыкновенная NAS-хранилка, так и xNIX-сервер с папкой доступной через NFS (кому что удобнее). Затем, указываем содержимое (backup).
Или же, можно сделать репликацию средствами Nexenta:
Реализуется в GUI вкладками Data Management -> Auto Services -> Auto-Tier Services -> Create.
Здесь мы имеем в виду удаленное хранилище (или просто Linux-машина) с запущенной службой Rsync. Поэтому, перед этим нам необходимо создать связь между хостами.
Вкладки Settings -> Network -> SSH-bind помогают поднять коннект.
Настройка HA:
Настраивается полностью через GUI.
- Выделяем Датацентр, кликаем вкладку HA сверху.
- Жмем Группы снизу и создаем группу из хостов, на которые может мигрировать VM.
- Далее жмем Ресурсы и там добавляем VM, которую мы хотим.
Можно также посмотреть статус в консоли:
root@pve1:~# ha-manager status
quorum OK
master pve1 (active, Sun Mar 20 14:55:59 2016)
lrm pve1 (active, Sun Mar 20 14:56:02 2016)
lrm pve2 (active, Sun Mar 20 14:56:06 2016)
service vm:100 (pve1, started)
Теперь проверим работоспособность кластера.
Устанавливаем VM, с Windows, с диском в общем хранилище, и пробуем миграцию вручную:
Работает!
Отлично, теперь проверяем его отказоустойчивость, выключаем сервер через IPMI. Ждем переезда. Машина автоматически мигрирует через полторы минуты.
В чём проблема? Здесь необходимо понимать, что механизм fencing в версии 4.х поменялся. Т.е. сейчас работает Whatchdog fencing, который не имеет активной поддержки оборудования. Будет исправлено в версии 4.2.
Заключение
Итак, что же мы получили в итоге?
А получили мы Production-ready кластер, поддерживающий большинство ОС, с простым интерфейсом управления, возможностью кратного резервирования данных (это и сам Proxmox и Nexentastor со снэпшотами и репликацией).
Плюс ко всему, мы всегда имеем возможности масштабирования и добавления функций, как со стороны Proxmox, так и со стороны Nexenta (в этом случае придется таки купить лицензию).
И все это совершенно бесплатно!
По моему мнению, настройка всего этого не требует ни особых временных затрат, ни детального изучения разнообразных мануалов.
Конечно же, без некоторых грабель не обходится, тут сравнение с ESXi + VMWare vCenter будет в пользу последнего. Однако, всегда можно задать вопрос на форуме поддержки!
В итоге, почти 100% функционала, чаще всего используемого админом небольшого проекта (компании), мы получили сразу из коробки. Поэтому, рекомендую каждому задуматься, а стоит ли тратиться на излишние возможности, лишь бы они были лицензированы?
P.S. В вышеописанном эксперименте использовалось оборудование:
4 х Сервера STSS Flagman RX237.4-016LH в составе:
- X9DRi-LN4F+
- 2 х Xeon E5-2609
- 8 х 4GB DDR-III ECC
- ASR-6805 + FBWC
Три сервера из четырёх использовались как ноды, один — был забит 2ТБ-дисками и использовался в качестве хранилки.
В первом эксперименте в качестве NAS использовалась готовая СХД Infortrend EonNAS 3016R
Оборудование выбиралось не для тестирования производительности, а для оценки концепции решения в целом.
Вполне возможно, что есть и более оптимальные варианты реализации. Однако тестирование производительности в разных конфигурациях, не входило в рамки данной статьи.
Спасибо за внимание, жду Ваших комментариев!
Комментарии (71)

kvaps
22.03.2016 09:51+4Скажите: Nexenta не имеет ограничений на объем хранилища?
Еще хочу рассказать про CEPH. Это тоже неплохой вариант организации хранения образов виртуальных машин.
Здесь вам не нужно отдельное физическое хранилище, вы можете настроить распределенное хранилище прямо на нодах, оно также будет отказоустойчевым и к тому же поддерживается Proxmox.
Если интересно, вот ссылка на wiki-страничку на сайте Proxmox и на мою статью.

merlin-vrn
22.03.2016 10:11+1Интересный это вариант. Мы пробовали вплоть до запуска Ceph на самих нодах виртуализации. В сухом минимальном остатке требуется три компа и коммутатор.




WayMax
22.03.2016 11:06+1Спасибо за статью, было интересно прочитать.
А вы не подскажете вариант настройки отказоустойчивого кластера (на какой угодно программной платформе) который бы обеспечивал 100% времени доступа к ресурсам (т.е. при выходе из строя одной ноды — сам кластер работал бы как ни в чем не бывало)?
sarge74
22.03.2016 11:14+1Первое что приходит в голову — это VMWare Fault Tolerance. См. ссылку. Там суть в том что на определенном вами ресурсе (VM) всегда работает резервная копия на другой ноде.
При падении рабочей ноды, ресурс работать не прекращает.
Опять же, в этом случае надо покупать лицензию!sarge74
22.03.2016 11:51+1Также похожий функционал, есть у XenServer, скорее всего дешевле чем у VMWare, но там надо уточнять.
Вот кстати интересная штука.
У Proxmox, VM переезжает на другую ноду с рестартом.Turilion
22.03.2016 12:23Не, вы не правы. При использовании ISCSI — таргета и правильной настройки тригеров HA, виртуалка продолжает работать как ни в чём не бывало.
sarge74
22.03.2016 14:33+1Буду рад ошибиться, к сожалению онлайн-миграция бывает только при старте вручную.
Это показано в ролике, в конце статьи.
Если нода по каким-то причинам падает, то VM рестартуют на другом хосте в соот-и с настройками HA.
Если же у вас работает по другому, давайте подробнее про ваши настройки?!
de1m
22.03.2016 14:21-1Все нормальные гипервизоры предлогают такой функционал — VMWare, Hyper-V, KVM, Xen
Работает всё примерно одинаково — все ноды обращаются к одному хранилищу, а актуальное состояние реплицируется через сеть. Всё в принципе уперается в общее хранилище. Под линукс или виндовс есть возможноси объеденить локальные диски в одно хранилище.
У VMWare есть дополнительная опция. Если у вас к примеру нету общего хранилища, то можно образовать одно из дисков в нодах, что-то типа рейда через сеть, название забыл. Делали, работает не очень быстро и доступно только половина памяти.
В линуксе можно сделать к примеру ceph кластер, можно на те же сервера где proxmox установить, поэтому не понятно нафига огорот с iscsi городить.
Hyper-v с отдельным хранилищем работает как кластер очень хорошо, виртуальные машины перекидываются без проблем и без обрывов, во всяком случае версия начиная с 2012WayMax
22.03.2016 15:03Настраивал (по инструкциям в интернете, в том числе с хабра) кластер на Hyper-V (сервер AD + две ноды + СХД от IBM) везде стояла 2012 R2, СХД была настроена как общий ресурс с кворумом, MPIO и т.д. При выключении "активной" ноды виртуальные машины мигрировали и были недоступны примерно с минуту. Хотелось бы узнать как всетаки правильно создать кластер, чтобы виртуальные машины не перезагружались при выходе из строя "активной" ноды, какие ПО и железо использовать.
rsunix
22.03.2016 11:14Используем в работе, при обновлениях иногда меняется протокол (может нам повезло) и с одних нод уже не получается управлять другими, пока не обновишь все ноды.

quartz64
22.03.2016 12:05+2Хорошая статья, но в подобных решениях часто зацикливаются на отказоустойчивости узлов виртуализации и забывают про отказоустойчивость СХД (или всей SAN). В данном случае мы получаем кластер, работа которого зависит от одиночного сервера с Нексентой и одиночного свитча.
Конечно, если по условиям задачи клиента устраивает соответствующее RTO, то почему бы и нет. Только RTO нужно просчитать заранее:
— время замены свитча (взять новый из запасов на складе, или дожидаться замены по гарантии от поставщика, находящегося в 500 км)
— время восстановления СХД при различных сценариях. Например, переустановить Нексенту + восстановить данные из бэкапа или переключиться на использование резервной СХД на время диагностики/ремонта основной СХД.sarge74
22.03.2016 13:01+2Все правильно, здесь мы упростили схему по максимуму.
Время простоя, можно минимизировать даже в бесплатном варианте.
Т.е. добавить в схему второй свитч(это недорого) + сделать в качестве Secondary Storage такую же Nexenta.
Переключение на другой сторадж, займет какое-то время, но это не сравнить с его заменой.
Схема работы двух хранилищ NexentaStor в режиме Active-Active конечно же есть, но уже за деньги.
Все зависит от желания и возможностей клиента. Можно сделать по разному.
FNkey
22.03.2016 12:43Товарищи, насколько сложно построить такую систему на базе «гиперконвергентной» платформы Supermicro 2022TG-HTRF?
Я так понимаю, в таком случае можно будет отказаться от Nexenta и задействовать Ceph, но я с ним ни разу не сталкивался.
srs2k
22.03.2016 12:43+1Хотелось бы конечно, использовать Starwind или FreeNAS (NAS4Free), но если одному для работы нужен Windows и шаманство с ISCSI, то у другого функция кластеризации не предусмотрена вообще.
Однако, у Nas4Free (или FreeNAS) есть кластеризация. Называется HAST (+ CARP).
Пару лет назад тоже выбирал платформу для бюджетного софтового дискового хранилища, пробовал нексенту и нас4фри. Остановился на последнем варианте, потому что нексента показалась мне бедной по функционалу, при том тяжеловесной и чрезмерно требовательной к ресурсам.FNkey
22.03.2016 13:05+1Эта схема в продакшене работала?
Я пробовал около полугода назад на VMware поднять тестовый кластер из nas4free.
Собирается, реплицирует между собой данные, но вот добиться автоматического восстановления или устойчивой работы не удалось.
Возможно, из-за некорректной настройки виртуальных сетевых интерфейсов. Железа для теста на физике не хватило.srs2k
22.03.2016 15:11Пару лет использую Nas4Free в качестве Shared Storage для виртуалок, для бэкапов и в качестве Samba-шар, однако HAST не пользовался, т.к. эта фича довольно долгое время была в состоянии экспериментальной.
Тоже пробовал поднимать хранилище из-под виртуалки, но понял что это не есть гуд — страдает производительность, и как пишут — файловая система ZFS лучше работает с физическими накопителями, нужно как минимум пробрасывать HBA-контроллер в гостевую систему.
sarge74
22.03.2016 13:27+2Спасибо за замечание, исправлю. Здесь акцент на то, что доступно из коробки и Production-Ready.
Действительно, их(FreeNAS (NAS4Free)) можно допилить до кластера.
Но можно ли рекомендовать получившееся решение в Production?
Лично я бы не стал.
Turilion
Неплохая статья, очень в тему для меня сейчас.
У нас крутиться кластер из 4 нод, правда на локальных дисках, так что из всех плюшек кластера получаем только единый интерфейс управления. Как раз задумываемся об ISCSI таргете, что бы уже ни что не мешало пользоваться всеми прелестями кластера на полную.
А как на счёт производительности?
Было бы очень интересно взглянуть на резульаты каких-никаких тестов на производительность дисковой подсистемы из самого Proxmoxa и из виртуалки. Это очень обогатло бы вашу статью.
sarge74
По производительности, это тянет на отдельную статью.
Повторюсь, решение собрано из того что было под рукой, поэтому на тестах дисковой подсистемы не акцентировались.
Здесь, конечно можно поиграться с SSD, агрегированием каналов и пр. И будут разные результаты.
Предложите Ваши варианты конфигурации дисковой подсистемы, мы постараемся реализовать и протестировать.
Turilion
RAID1 — массив. WD диски. Из железа — широкодоступное что-то. Например D-link (Cisco) гигабитные свичи. Остально оставить как есть.
С агрегацией, ну скажем 2 (или 4) каналов.
srs2k
Имхо, RAID-массив избыточен(и даже вреден), если используется ZFS.