
Во время общения с медиа мы в Relap.io часто сталкиваемся с массой заблуждений, в которые все верят, потому что так сложилось исторически. На сайте есть блоки типа «Читать также» или «Самое горячее» и т.п. Словом, всё то, что составляет обвязку статьи и стремится дополнить UX дорогого читателя. Мы расскажем, какие заблуждения есть у СМИ, которые делают контентные рекомендации, и развеем их цифрами.
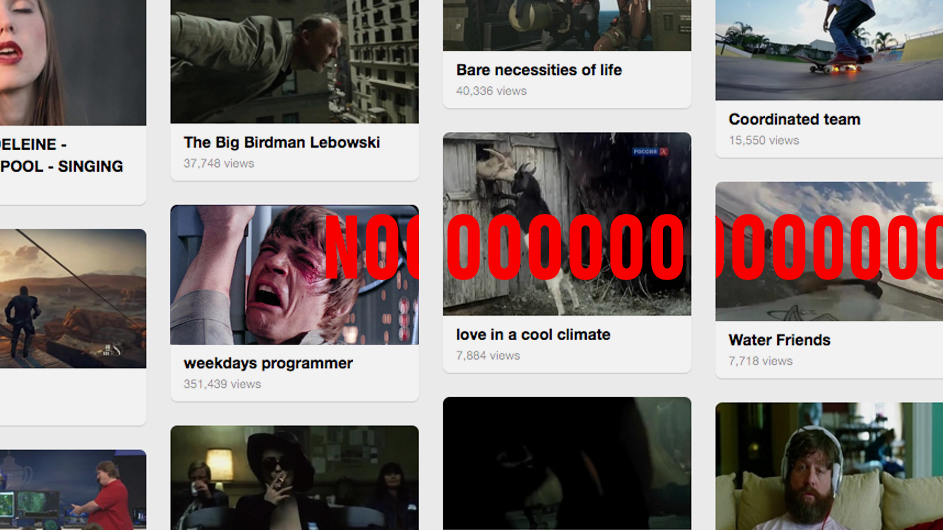
Самое большое и самое популярное заблуждение. Чаще всего СМИ делают рекомендации в конце статьи по тегам. Так поступает Look At Me и РБК, например. Есть материал с тегами: трактор, Путин, сыр. К нему выводятся тексты про трактора, про Путина и сыр. На первый взгляд, логично:

Подобная механика рекомендаций в реальной жизни выглядела бы так. Вы идёте в магазин за продуктами. И кладёте в корзину сливочное масло. К вам подходит консультант с потными от волнения ладошками и говорит: «О, я вижу, вы взяли масло и это значит, что вам нужно масло. Возьмите еще пять видов сливочного деревенского и подсолнечного и козьего масла». Максимум, что может случиться из ряда вон выходящее — вам предложат трансмиссионное, если вы читали что-то про автомобили. И это уже будет считаться rocket science.
Но ситуации, когда можно рекомендовать по тегам существуют: например какой-нибудь сайт с обзорами товаров – тут вполне можно предположить, что человек захочет прочитать несколько обзоров похожих скороварок или телефонов. Но доверять редактору, который проставляет теги, не стоит: разные люди по-разному воспринимают тексты, и, если редакторов больше одного, многообразие тегов, описывающих более-менее одно и то же, поражает.
Лучше положиться на машину и вычленить ключевые слова из текста автоматически. В таком случае мы получаем только те слова (а еще лучше устойчивые словосочетания, коллокации, но это немного другая история), которые важны для конкретного текста, а не список имен/торговых знаков, которые скорее всего встречаются еще в миллионе статей совсем на другие темы.
Самый простой (и, во многих случаяx, весьма действенный) cпособ вычленить ключевые слова из текста это использование tf-idf и его многочисленных вариантов.
tf-idf – term frequency-inverse document frequency. Мы смотрим какие слова и как часто употребляются в документе и даем больший вес тем словам, которые встречаются в корпусе редко. Иными словами, даже если слово «cепулька» встречается в тексте всего один раз, у него гораздо выше вероятность оказаться значимым тегом, чем, например, у слова «масленица» (кроме случаев когда мы индексируем сайт посвященный торговле сепулькариями).
Для тех кто не помнит, обратная частота по корпусу (idf) рассчитывается так

где — собственно корпус (множество документов
— собственно корпус (множество документов  ), а
), а  — терм. Брать логарифм от отношения в общем-то необязательно, сойдет любая монотонная функция (в википедии можно посмотреть на многочисленные варианты этой формулы), главное «наказывать» за излишнюю популярность слова. Логарифм имеет смысл использовать если корпус достаточно большой.
— терм. Брать логарифм от отношения в общем-то необязательно, сойдет любая монотонная функция (в википедии можно посмотреть на многочисленные варианты этой формулы), главное «наказывать» за излишнюю популярность слова. Логарифм имеет смысл использовать если корпус достаточно большой.
Частота терма еще проще:

где число вхождений терма в документ , а сумма в знаменателе просто общее число слов в документе.
число вхождений терма в документ , а сумма в знаменателе просто общее число слов в документе.
Для ранжирования слов по важности мы просто перемножаем эти два числа:

Нетрудно заметить, что обратная частота рассчитывается по всему корпусу, а частота терма зависит от документа, который мы хотим проанализировать. В случае русского языка, неплохо бы (на самом деле обязательно) привести все слова в тексте к словарным формам или хотя бы лемматизировать, но об этом речи в данный момент не идет (интересующиеся могут начинать знакомство с процессом с алгоритма Портера).
Если обсчитать какой-то корпус и ранжировать слова в каждом документе по нисходящему значению , то первые несколько слов будут давать довольно адекватное представление о содержании документа. Такие слова можно использовать как теги, но, как мы уже говорили, не стоит делать такого в новостных сайтах – в конце концов, одной новости о пробках из-за снегопада вполне достаточно. Вспоминать, как шоссе ххх стояло в пробках в 2012 – нет никакой необходимости.
, то первые несколько слов будут давать довольно адекватное представление о содержании документа. Такие слова можно использовать как теги, но, как мы уже говорили, не стоит делать такого в новостных сайтах – в конце концов, одной новости о пробках из-за снегопада вполне достаточно. Вспоминать, как шоссе ххх стояло в пробках в 2012 – нет никакой необходимости.
Мир устроен чуть сложнее. На самом деле, всё работает так: пользователь приходит на сайт, смотрит курс доллара, обзор нового айфона и фотографии панд. Значит, другой человек, который уже посмотрел курс доллара и айфон, скорее всего, захочет посмотреть на панд, как бы это странно ни звучало. Это называется коллаборативная фильтрация. Есть кластеры пользователей и закономерности, с помощью которых можно максимизировать вовлеченность читателя в ваш контент.
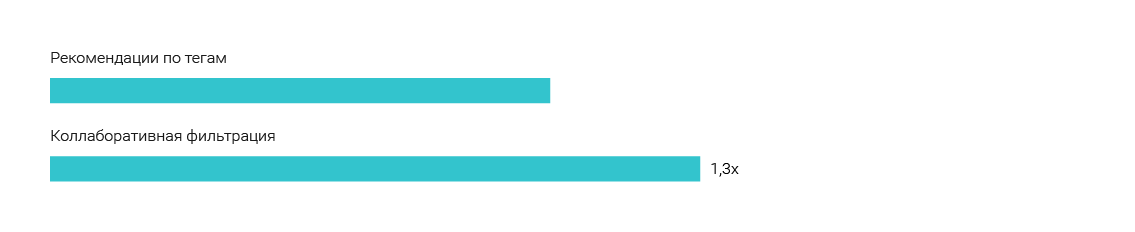
Коллаборативная фильтрация это в какой-то степени продолжение идеи использования tf-idf для вычленения значимой информации, но вместо частоты слов мы используем по-разному взвешенные «голоса» читателей. Под голосом мы понимаем какие-то действия: просмотр страницы, доскролливание до конца, что-то еще – набор событий зависит исключительно от фантазии математиков и свободного времени программиста (который пишет код, всё это великолепие учитывающий).
Просто считать количество событий неправильно, поэтому мы опять рассчитываем веса голосов. Поскольку читатели не ставят оценок (более того, они даже не знают или не задумываются о том, что читая статью про мухомор, выросший на опушке около сельсовета, они помогают собрать статистику читательских предпочтений «Вестника Несреднечерноземного брусникода»), нам нужно определить «важность» голосов используя только анонимную и довольно ограниченную информацию.
Важность голоса читателя зависит от того, насколько он активен, правда, с отрицательным знаком: чем больше статей читает пользователь за какой-то период времени (например 12 часов), тем дешевле стоит его голос. Вес голоса это убывающая функция числа прочитанных статей на ресурсе. Более того, имеет смысл ставить отсечку сверху: человек прочитавший более 100 статей на одном и том же сайте в течение одного дня либо редактор этого сайта, либо маньяк или бот и скорее всего нам не нужны его рекомендации.
Веса можно посчитать например так:

где вес голоса
вес голоса  -го пользователя, а
-го пользователя, а  число голосов этого пользователя. Опять-таки, никто не заставляет нас использовать логарифмы — любая монотонно убывающая функция от сойдет, также можно избавиться и от единички в знаменателе: строго говоря, читателей с нулем голосов учитывать тоже не стоит (убрали же графу «против всех» из избирательных бюллетеней). Сюда же можно добавить что-то еще: например не просто считать число прочитанных статей, а учитывать время проведенное за их чтением, поставленную оценку (если такая информация есть), всё что угодно.
число голосов этого пользователя. Опять-таки, никто не заставляет нас использовать логарифмы — любая монотонно убывающая функция от сойдет, также можно избавиться и от единички в знаменателе: строго говоря, читателей с нулем голосов учитывать тоже не стоит (убрали же графу «против всех» из избирательных бюллетеней). Сюда же можно добавить что-то еще: например не просто считать число прочитанных статей, а учитывать время проведенное за их чтением, поставленную оценку (если такая информация есть), всё что угодно.
Вторая инкарнация предыдущего заблуждения — сегментировать рекомендации по разделам.
Представьте, что консультант отдела сливочного масла берет вас в заложники со словами: «Сегодня ты купишь только маслице, о да, ты купишь много маслица!» Вы с криком выламываете двери, и никогда больше не возвращаетесь в этот магазин.
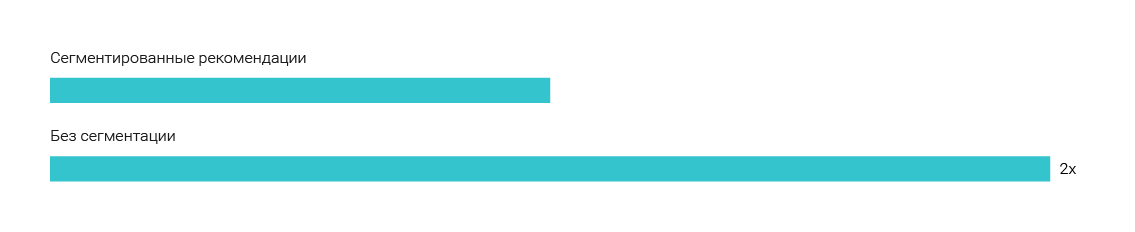
Несложно заметить, что и коллаборативная фильтрация и автоматический расчет тегов в пределах одного сегмента будут работать хуже – ведь разбивая содержимое сайта на сегменты и рассчитывая рекомендации внутри каждого сегмента, мы просто применяем тот же самый подход на меньшей выборке. Более того, мы получаем искаженную картину активности пользователей.
В конце концов, при ранжировании пользователей нам интересно насколько человек активен в сети, а не сколько статей про погоду он/она читает за день. Ну и про корреляцию интересов в таком случае можно забыть: мы же не интересуемся условными вероятностями перехода из одного раздела в другой (вернее возможно и интересуемся, но не собираем статистики для их расчета), так что не запирайте свои рекомендации в клетках разделов, они этого не любят.
Рекомендовать популярные новости — значит рекомендовать ненужные новости, которые все уже видели. Популярное — это материалы, которые посмотрело много людей. Именно так популярное становится популярным. Каждый раз, когда вы хотите сделать у себя на сайте такой блок, вспоминайте это предложение, потому что именно так это и работает. Это новости, которые видели все.

Популярной новости нужно некоторое время для того, чтобы превратиться в баян и рекомендовать что-то, что многим интересно именно сейчас не самая плохая идея. Просто нужно четко понимать – когда читательский интерес начинает затухать, в противном случае мы бы до сих видели только «лабутенов» и подобное при попытке найти свежие приколы на YouTube – а что? Этот ролик набрал миллиард просмотров, значит он хороший!
Как несложно догадаться, убывающая функция от возраста события поможет нам точно так же, как убывающая функция от числа действий совершенных пользователем помогла отсеять ботов и маньяков. Правда, в случае с возрастом просмотров вес каждого голоса должен убывать намного быстреe: пользователей много и тысяча просмотров с утра не значит, что кто-то захочет читать про утренние пробки в обед. Обратная зависимость от логарифма просмотров неплохо работает при взвешивании голосов одного пользователя, для определения популярности лучше работает отрицательная степень возраста: , где
, где  вес голоса для статьи
вес голоса для статьи  ,
,  время прошедшее с момента прочтения, а
время прошедшее с момента прочтения, а  какая-то константа. Новости нужно отранжировать в соответствии с
какая-то константа. Новости нужно отранжировать в соответствии с  и делать это довольно часто, иначе релевантность рекомендаций пропадет.
и делать это довольно часто, иначе релевантность рекомендаций пропадет.
Если посмотреть на последнюю формулу больше трех секунд, то несложно прийти к выводу о том, что собственно сумма весов не так уж и важна, важна скорость с которой она растет. Поэтому еще лучше не ранжировать новости по «совокупности заслуг», а по скорости набора этих самых заслуг. Собственно, если считать эту скорость аккуратно, то можно научиться предсказывать виральность поста и делать другие космические вещи (с оговоркой впрочем, что в таком случае виральность всё-таки не предсказывается, а детектируется на ранней стадии).
Почему новостные издания рекомендуют новости полугодичной давности, понять сложно. Такой подход порождает дикие примеры типа этого:
Медиа думают, что пользователь хочет знать, что было на эту тему раньше. Нет, не хочет! Ему это не интересно, и никому это не интересно.
Чтобы не быть голословными, давайте посмотрим на статистику посещений страниц на сравнительно большой выборке (но меньшей чем описанная в предыдущем абзаце), например в один миллион событий (переходов на страницу) и посмотрим на возраст читаемых статей.
Сначала просто посмотрим сколько разных страниц попало в нашу выборку (все события собраны на одном большом новостном сайте. Получается следущее:
Довольно очевидно что старых урлов много, но также очевидно что нужно считать не просто посещенные урлы, а распределение трафика. Посмотрим на количество посещений:
Как и ожидалось, больше 90% трафика приходится на статьи опубликованные за последние 72 часа.
Это 5 универсальных правил для всех медиа. При этом на каждой площадке есть свои собственные поведенческие паттерны. В зависимости от них настраиваются алгоритмы. Такой же набор законов и запретов можно было бы сформулировать для любой из наших площадок.
Мы очень рады, если эта статья помогла в работе вашей редакции и проектировании интерфейсов. Если есть вопросы, безумные гипотезы и идеи, которые вы хотите реализовать вместе с нами — напишите на lab@relap.io
Если хотите использовать наши технологии, вовлекать читателей и вообще автоматизировать рекомендации контента на сайте, мы с радостью в этом поможем. Пишите на support@relap.io
Рекомендовать по тегам
Самое большое и самое популярное заблуждение. Чаще всего СМИ делают рекомендации в конце статьи по тегам. Так поступает Look At Me и РБК, например. Есть материал с тегами: трактор, Путин, сыр. К нему выводятся тексты про трактора, про Путина и сыр. На первый взгляд, логично:
Подобная механика рекомендаций в реальной жизни выглядела бы так. Вы идёте в магазин за продуктами. И кладёте в корзину сливочное масло. К вам подходит консультант с потными от волнения ладошками и говорит: «О, я вижу, вы взяли масло и это значит, что вам нужно масло. Возьмите еще пять видов сливочного деревенского и подсолнечного и козьего масла». Максимум, что может случиться из ряда вон выходящее — вам предложат трансмиссионное, если вы читали что-то про автомобили. И это уже будет считаться rocket science.
Но ситуации, когда можно рекомендовать по тегам существуют: например какой-нибудь сайт с обзорами товаров – тут вполне можно предположить, что человек захочет прочитать несколько обзоров похожих скороварок или телефонов. Но доверять редактору, который проставляет теги, не стоит: разные люди по-разному воспринимают тексты, и, если редакторов больше одного, многообразие тегов, описывающих более-менее одно и то же, поражает.
Лучше положиться на машину и вычленить ключевые слова из текста автоматически. В таком случае мы получаем только те слова (а еще лучше устойчивые словосочетания, коллокации, но это немного другая история), которые важны для конкретного текста, а не список имен/торговых знаков, которые скорее всего встречаются еще в миллионе статей совсем на другие темы.
Самый простой (и, во многих случаяx, весьма действенный) cпособ вычленить ключевые слова из текста это использование tf-idf и его многочисленных вариантов.
tf-idf – term frequency-inverse document frequency. Мы смотрим какие слова и как часто употребляются в документе и даем больший вес тем словам, которые встречаются в корпусе редко. Иными словами, даже если слово «cепулька» встречается в тексте всего один раз, у него гораздо выше вероятность оказаться значимым тегом, чем, например, у слова «масленица» (кроме случаев когда мы индексируем сайт посвященный торговле сепулькариями).
Для тех кто не помнит, обратная частота по корпусу (idf) рассчитывается так
где
Частота терма еще проще:
где
Для ранжирования слов по важности мы просто перемножаем эти два числа:
Нетрудно заметить, что обратная частота рассчитывается по всему корпусу, а частота терма зависит от документа, который мы хотим проанализировать. В случае русского языка, неплохо бы (на самом деле обязательно) привести все слова в тексте к словарным формам или хотя бы лемматизировать, но об этом речи в данный момент не идет (интересующиеся могут начинать знакомство с процессом с алгоритма Портера).
Если обсчитать какой-то корпус и ранжировать слова в каждом документе по нисходящему значению
Шокирующая правда
Мир устроен чуть сложнее. На самом деле, всё работает так: пользователь приходит на сайт, смотрит курс доллара, обзор нового айфона и фотографии панд. Значит, другой человек, который уже посмотрел курс доллара и айфон, скорее всего, захочет посмотреть на панд, как бы это странно ни звучало. Это называется коллаборативная фильтрация. Есть кластеры пользователей и закономерности, с помощью которых можно максимизировать вовлеченность читателя в ваш контент.
Результаты тестирования
По результатам А/В тестов коллаборативная фильтрация, без дополнительных настроек, дает на 20-30% больше кликов, чем подборка по тегам. И это означает, что никто не должен составлять блоки «Читать также» на основе тегов.
Коллаборативная фильтрация это в какой-то степени продолжение идеи использования tf-idf для вычленения значимой информации, но вместо частоты слов мы используем по-разному взвешенные «голоса» читателей. Под голосом мы понимаем какие-то действия: просмотр страницы, доскролливание до конца, что-то еще – набор событий зависит исключительно от фантазии математиков и свободного времени программиста (который пишет код, всё это великолепие учитывающий).
Просто считать количество событий неправильно, поэтому мы опять рассчитываем веса голосов. Поскольку читатели не ставят оценок (более того, они даже не знают или не задумываются о том, что читая статью про мухомор, выросший на опушке около сельсовета, они помогают собрать статистику читательских предпочтений «Вестника Несреднечерноземного брусникода»), нам нужно определить «важность» голосов используя только анонимную и довольно ограниченную информацию.
Важность голоса читателя зависит от того, насколько он активен, правда, с отрицательным знаком: чем больше статей читает пользователь за какой-то период времени (например 12 часов), тем дешевле стоит его голос. Вес голоса это убывающая функция числа прочитанных статей на ресурсе. Более того, имеет смысл ставить отсечку сверху: человек прочитавший более 100 статей на одном и том же сайте в течение одного дня либо редактор этого сайта, либо маньяк или бот и скорее всего нам не нужны его рекомендации.
Веса можно посчитать например так:
где
Рекомендовать контент из того же раздела
Вторая инкарнация предыдущего заблуждения — сегментировать рекомендации по разделам.
Представьте, что консультант отдела сливочного масла берет вас в заложники со словами: «Сегодня ты купишь только маслице, о да, ты купишь много маслица!» Вы с криком выламываете двери, и никогда больше не возвращаетесь в этот магазин.
Результаты тестирования
Мы показали одной группе юзеров сегментированные рекомендации: человек читает новость из раздела «Общество» — рекомендуем ему статьи только из раздела «Общество». Другая группа получала рекомендации со всего сайта (кросс-сегментные рекомендации). CTR виджета с рекомендациями без учета разделов — в 2 раза выше, процент отказа ниже на 16% и время проведенное на сайте было на 23% выше. Нет никакого смысла ограничивать читателя рамками одного раздела. Будьте разнообразны в своих рекомендациях.
Несложно заметить, что и коллаборативная фильтрация и автоматический расчет тегов в пределах одного сегмента будут работать хуже – ведь разбивая содержимое сайта на сегменты и рассчитывая рекомендации внутри каждого сегмента, мы просто применяем тот же самый подход на меньшей выборке. Более того, мы получаем искаженную картину активности пользователей.
В конце концов, при ранжировании пользователей нам интересно насколько человек активен в сети, а не сколько статей про погоду он/она читает за день. Ну и про корреляцию интересов в таком случае можно забыть: мы же не интересуемся условными вероятностями перехода из одного раздела в другой (вернее возможно и интересуемся, но не собираем статистики для их расчета), так что не запирайте свои рекомендации в клетках разделов, они этого не любят.
Рекомендовать популярное
Рекомендовать популярные новости — значит рекомендовать ненужные новости, которые все уже видели. Популярное — это материалы, которые посмотрело много людей. Именно так популярное становится популярным. Каждый раз, когда вы хотите сделать у себя на сайте такой блок, вспоминайте это предложение, потому что именно так это и работает. Это новости, которые видели все.
Результаты тестирования
Мы сравнивали в A/B тестах популярное и коллаборативную фильтрацию. CTR виджета с коллаборативной фильтрацией выше в 7 раз. Это совсем не значит, что вот наши алгоритмы такие классные. Это значит, что блок популярное на сайте — отстой и не нужен вообще никому. Мы понимаем, что блок «Популярное» на сайте — это must have для большинства медиа, но пора попрощаться с этим заблуждением.
Популярной новости нужно некоторое время для того, чтобы превратиться в баян и рекомендовать что-то, что многим интересно именно сейчас не самая плохая идея. Просто нужно четко понимать – когда читательский интерес начинает затухать, в противном случае мы бы до сих видели только «лабутенов» и подобное при попытке найти свежие приколы на YouTube – а что? Этот ролик набрал миллиард просмотров, значит он хороший!
Как несложно догадаться, убывающая функция от возраста события поможет нам точно так же, как убывающая функция от числа действий совершенных пользователем помогла отсеять ботов и маньяков. Правда, в случае с возрастом просмотров вес каждого голоса должен убывать намного быстреe: пользователей много и тысяча просмотров с утра не значит, что кто-то захочет читать про утренние пробки в обед. Обратная зависимость от логарифма просмотров неплохо работает при взвешивании голосов одного пользователя, для определения популярности лучше работает отрицательная степень возраста:
Если посмотреть на последнюю формулу больше трех секунд, то несложно прийти к выводу о том, что собственно сумма весов не так уж и важна, важна скорость с которой она растет. Поэтому еще лучше не ранжировать новости по «совокупности заслуг», а по скорости набора этих самых заслуг. Собственно, если считать эту скорость аккуратно, то можно научиться предсказывать виральность поста и делать другие космические вещи (с оговоркой впрочем, что в таком случае виральность всё-таки не предсказывается, а детектируется на ранней стадии).
Не ставить ограничение по времени
Почему новостные издания рекомендуют новости полугодичной давности, понять сложно. Такой подход порождает дикие примеры типа этого:
Медиа думают, что пользователь хочет знать, что было на эту тему раньше. Нет, не хочет! Ему это не интересно, и никому это не интересно.
Результаты тестирования
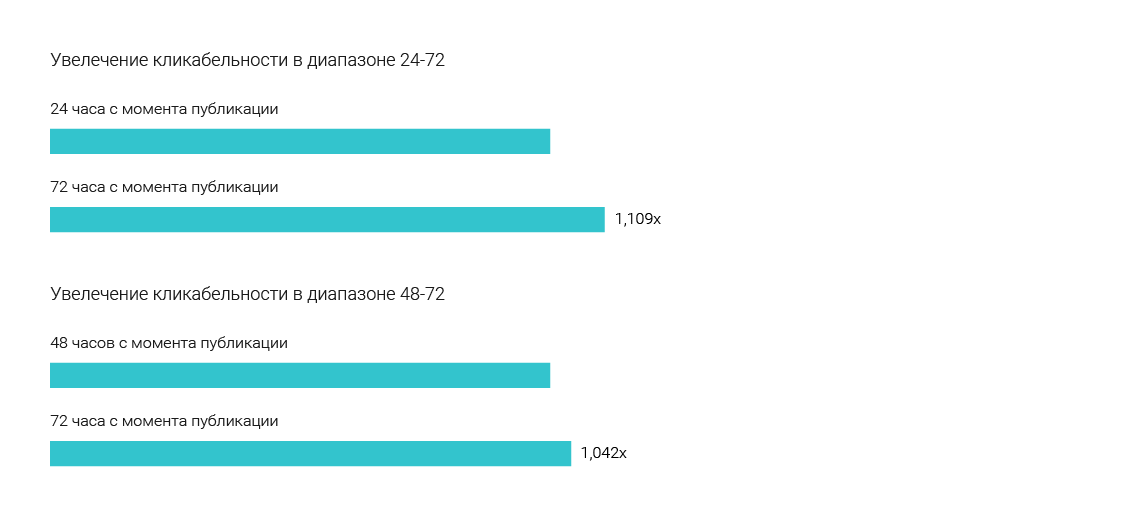
Во время тестов на новостных СМИ мы выясняли наиболее оптимальный возраст новостей, которые стоит рекомендовать посетителям. Было протестировано три варианта: 72, 48 и 24 часа с момента публикации. Тестовая выборка составляла 2.7 миллиона читателей, тест проводился месяц. Большая часть наших коллег ставила на 24 часа, потому что им казалось, что новости очень быстро устаревают, и никто не будет читать вчерашние новости. Чуть меньше людей верило в 48 часов. Видимо, потому, что не все успевают прочесть актуальное за день и, скорее всего, они что-то пропустили за вчера и хотят наверстать упущенное. Никто не верил в 72 часа… Да, 72 часа победили. В этом диапазоне пользователи находят больше всего интересующих материалов и блоки, собранные из таких новостей, кликабельны на 4,2% больше чем 48 часов и на 10,9% больше чем 24 часа. Вероятно, это происходит потому, что люди не успевают (или просто не хотят) потребить весь объем информации, который генерируют медиа. Поэтому новости, вышедшие позавчера, для них еще актуальны. Исключение составляют breaking news.
Чтобы не быть голословными, давайте посмотрим на статистику посещений страниц на сравнительно большой выборке (но меньшей чем описанная в предыдущем абзаце), например в один миллион событий (переходов на страницу) и посмотрим на возраст читаемых статей.
Сначала просто посмотрим сколько разных страниц попало в нашу выборку (все события собраны на одном большом новостном сайте. Получается следущее:
| Возраст (часы) | Число страниц |
|---|---|
| 0-24 | 719 |
| 24-48 | 841 |
| 48-72 | 581 |
| 72-96 | 368 |
| 96-120 | 238 |
| 120-144 | 73 |
| 144-168 | 85 |
| 168-192 | 147 |
| 192-216 | 141 |
| 216-240 | 110 |
| >240 | 8152 |
| Всего | 11455 |
Довольно очевидно что старых урлов много, но также очевидно что нужно считать не просто посещенные урлы, а распределение трафика. Посмотрим на количество посещений:
| Возраст статьи (часы) | Число событий |
|---|---|
| 0-24 | 771 435 |
| 24-48 | 130 431 |
| 48-72 | 26 233 |
| 72-96 | 21 536 |
| 96-120 | 5 214 |
| 120-144 | 673 |
| 144-168 | 287 |
| 168-192 | 965 |
| 192-216 | 1 001 |
| 216-240 | 1 642 |
| >240 | 40 583 |
| Всего | 1000 000 |
Как и ожидалось, больше 90% трафика приходится на статьи опубликованные за последние 72 часа.
Это 5 универсальных правил для всех медиа. При этом на каждой площадке есть свои собственные поведенческие паттерны. В зависимости от них настраиваются алгоритмы. Такой же набор законов и запретов можно было бы сформулировать для любой из наших площадок.
Мы очень рады, если эта статья помогла в работе вашей редакции и проектировании интерфейсов. Если есть вопросы, безумные гипотезы и идеи, которые вы хотите реализовать вместе с нами — напишите на lab@relap.io
Если хотите использовать наши технологии, вовлекать читателей и вообще автоматизировать рекомендации контента на сайте, мы с радостью в этом поможем. Пишите на support@relap.io