

Всем привет!
Хочу представить вам собственную разработку для создания API-документации. Она еще немного «сыровата», поскольку я уделил ей всего неделю, кроме того, я не являюсь веб-разработчиком. Однако на данном этапе, с целью написания API-документации для своего будущего проекта, она меня полностью устраивает.
Сама разработка находится на GitHub: github.com/gatools/restful-visual-editor
Заинтересовавшихся — милости прошу под кат.
Немного предистории
Изначально у меня не было в планах писать какой-либо редактор документации для API. Стоял выбор писать в Markdown или в RAML. Markdown отпал сразу же, поскольку в этих целях он не особо удобен для меня. Поэтому выбор пал на RAML, ведь к нему есть интересный конвертер raml2html. Потренировавшись работать в нем, я пришел к выводу, что не хочу писать документацию на языке YAML. И тут появилась идея создать визуальный редактор, в котором я могу просто и удобно заполнить нужные поля. В интернете есть разные коммерческие редакторы, но бесплатных среди них я не нашел.
Редактор
После создания проекта на начальном экране вводим основную информацию, а именно: версия документации, ссылка на сервер и описание.
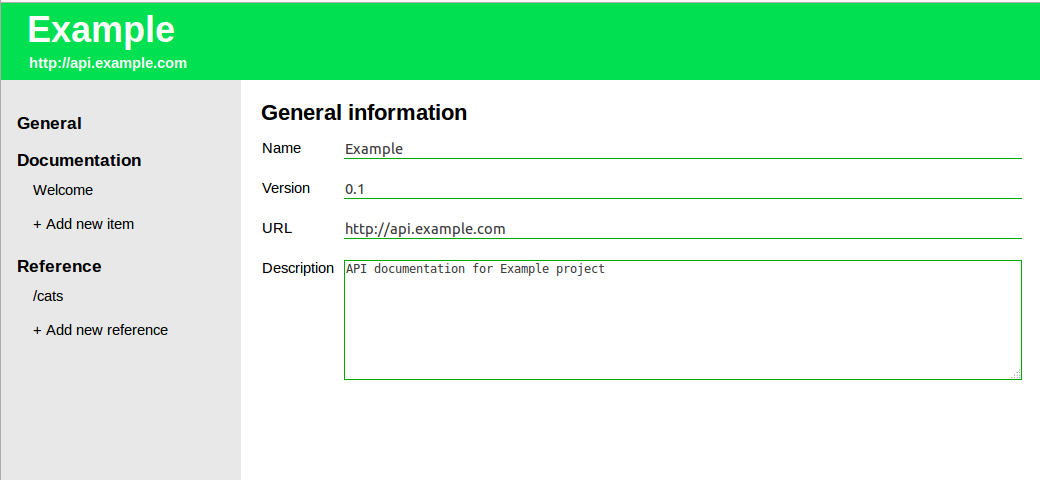
В разделе документации можно добавить дополнительные аннотации к проекту. Для удобства я добавил SimpleMDE редактор.

И наконец основная часть — это пути и работа с ними:
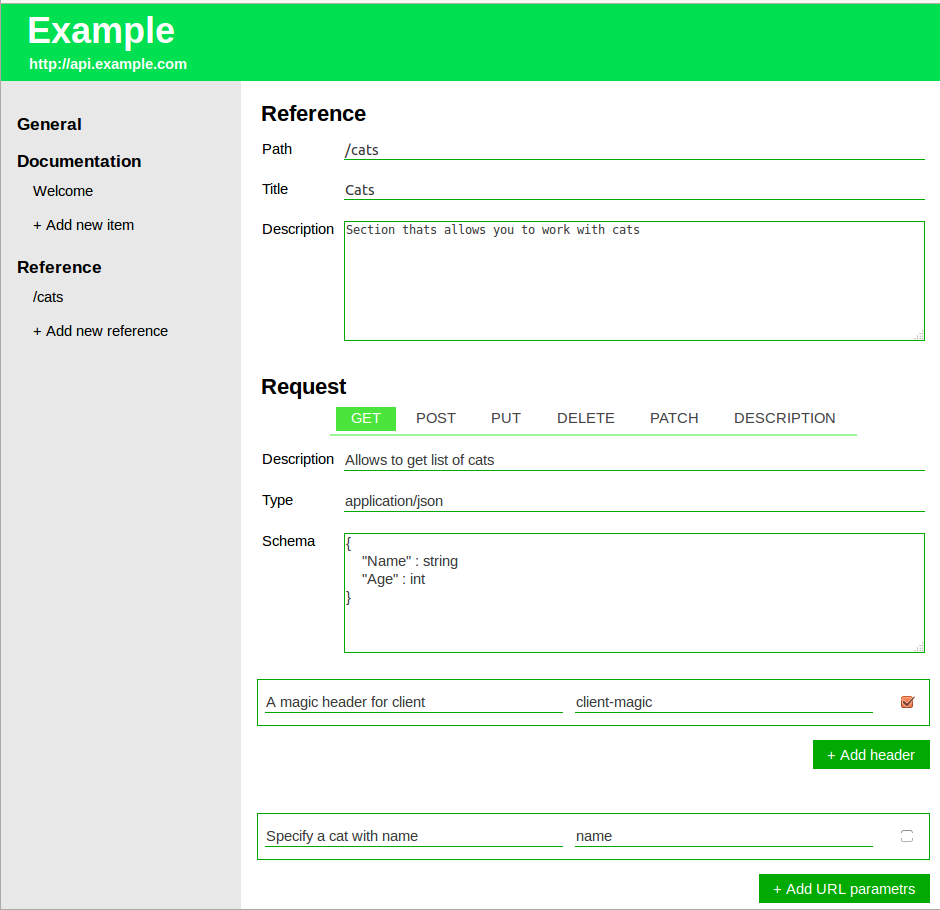
Тут можно добавить тип запроса, описание хедеров, обязательные и необязательные параметры, пример использования и ответы от сервера.
Немного о коде и структуре
Редактор состоит из двух частей: сервер на Node.JS, который обеспечивает работу с файлами, и веб-клиент, внутри которого происходит формирование проекта в формате JSON.
В серверной части кода ничего особенного — обычный веб-сервер с парой функций для ajax-запросов.
Клиентская часть немного сложнее. Есть основной экран, который через ajax-запросы подгружает другие экраны (subview). Выглядит это так:
/* Show documentation view for specified index */
function showDocumentationView(event) {
$("#content").empty();
currentDocumentationIndex = event.data.index;
if (currentDocumentationIndex < 0) return;
$("#content").load("view/documentation-view.html", (response, status, xhr) => {
if (status == "error") alert("Somthing was wrong, check Node.Js logs");
});
}
/* Show reference view for specified index */
function showReferenceView(event) {
$("#content").empty();
currentReferenceIndex = event.data.index;
if (currentReferenceIndex < 0) return;
$("#content").load("view/reference-view.html", (response, status, xhr) => {
if (status == "error") alert("Somthing was wrong, check Node.Js logs");
});
}
В редакторе проекта используются четыре (на данный момент) основных глобальных переменных:
projectRootObject = {};
projectFileName = "";
сurrentDocumentationIndex = -1;
currentReferenceIndex = -1;
Благодаря этим переменным подгруженные экраны могут знать, какую часть данных им загрузить и отобразить.
Планы на будущее
- возможность конвертирования проекта в RAML и Swagger
- совместное редактирование
- экспорт в HTML
- сравнение версий
Установка
Для работы необходимо установить Node.JS, скачать его можно с официального сайта.
Далее скачиваем с репозитория сам редактор и устанавливаем зависимости:
git clone https://github.com/gatools/restful-visual-editor.git
cd restful-visual-editor
npm install
Для запуска используем команду:
node app.js
После запуска открываем в браузере:
http://localhost:3000Вот в принципе и все. Спасибо за внимание к моей статье. Буду рад узнать ваши мнения! А также пишите свои замечания и предложения по усовершенствованию данной разработки.
Комментарии (53)

lair
23.04.2016 14:33+1Эм, а вы точно хотите писать документацию к API отдельно от самого API?

Fesor
23.04.2016 14:42+1Я — хочу. У меня документация к API обычно предшевствует самому API. Но это нюансы избранного workflow. Правда конкретно эта тулза мне не подходит.
lair
23.04.2016 14:43+2В вашем рабочем процессе, я надеюсь, предусмотрен инструмент, который проверяет, что API соответствует документации?

defuz
23.04.2016 18:22+1А если документация к API храниться в перемешку с исходным кодом, то это соответствие достигается как-бы автоматически?
lair
23.04.2016 19:07Как минимум пути и структуры входящих и исходящих сообщений — да. А дальше зависит от того, как у вас код структурирован, можно и типовое поведение (не найдено, отказ доступа, ошибка версионности) автоматически выводить.
VolCh
23.04.2016 15:16+1Вполне применимый подход для команд. Разрабатывается документация, потом одновременно начинают работать разработчик сервера, клиента и тестировщик.
lair
23.04.2016 16:32+3Разрабатывается документация, потом
Вам это, случайно, водопадную модель не напоминает?
разработчик сервера
Я выше уже спрашивал, и тут снова спрошу: а инструмент, который проверяет, что API соответствует документации, этим подходом предусмотрен?
разработчик [...] клиента
А заглушка для разрабочика клиента откуда берется? Или вслепую?
Fesor
23.04.2016 17:06Вам это, случайно, водопадную модель не напоминает?
Это напоминает водопадную модель так же, как если бы мы сначала писали всю API и потом уже отдавали ее мобильщикам/фронтэндерам. Но мы же так не делаем, верно? Документация к API так же пишется ровно столько, сколько нужно для текущего скоупа задач.
а инструмент, который проверяет, что API соответствует документации, этим подходом предусмотрен?
Да. Предусмотрен. Есть различные тулзы, в зависимости от формата приготовления документации. В моем случае это api blueprint и dredd. Однако сейчас все больше подумываю о том, что бы отказаться от него в сторону кодогенерации клиента на PHP и использования его в моих тестовых сюитах (для того что бы удобнее практиковать ATDD). Проверка соответствия происходит по json schema.
А заглушка для разрабочика клиента откуда берется? Или вслепую?
Для всех существующих форматов описания API (blueprint, raml, swagger) есть тулзы для поднятия mock-сервера.lair
23.04.2016 17:11Для всех существующих форматов описания API (blueprint, raml, swagger) есть тулзы для поднятия mock-сервера.
… это если у вас "документация" — это, на самом деле, формально описанный контракт. Аналогично и выше, для проверки соответствия нужна не документация, а контракт.
Впрочем, не суть. Я, в принципе, могу понять прелесть contract-driven-разработки API, но в моем личном опыте, к сожалению, он себя оправдывает намного меньше, нежели живая разработка сервера под требования клиента вкупе с фиксацией этих требований (и, как следствие, контракта) в тестах.
Fesor
24.04.2016 17:22+1нежели живая разработка сервера под требования клиента вкупе с фиксацией этих требований (и, как следствие, контракта) в тестах.
Давайте не будем подменять понятия. У меня есть к примеру проект, есть мобильное приложение, есть бэкэнд к ниму. После того, как для фичи были детализированы требования (в виде формального описания, в gherkin формате или как-то еще) можно приступать к описанию слоя интеграции мобильного приложения и бэкэнда.
Далее, имея на руках описание API (то что нужно сделать бэкэнд разработчику и то что должен использовать мобильщик) а так же детализированное представление о том как должна работать фича (ну или же не детализированное, а только предположение о том как оно должно работать) мы можем вести абсолютно паралельную разработку.
Причем это нисколечки не отменяет необходимости писать тесты (интеграционные как минимум). Но что если тесты не пишутся? (ну вот бывает такое иногда, чего уж тут… не все разработчики пишут тесты) Тогда мы можем просто прогнать реализацию бэкэнда на соответствие документации к API и уже чуть снизить риски.
Если же тесты пишутся — мы можем сгенерировать для интеграционных тестов код клиента для нашей API, который попутно будет верифицировать json-схему ответов.
При генерации документации на основании реализации у нас отсутствует необходимость проверки реализации на соответствие документации (ибо мы тогда сами себя проверять будем, в этом нет смысла). Однако мы полностью теряем возможность паралельной разработки, так как в этом случае у нас нет заранее задекларированного слоя интеграции двух систем.
Так же у документации лежащей отдельно есть отдельная плюшка которая мне кажется дико удобной — возможность отслеживать изменения. Скажем мобильщик может через неделю после отпуска например вернуться, открыть репозиторий и посмотреть diff документации к API. Поскольку форматы типа raml или api blueprint позволяют удобно DRY-ить структуры данных, мы получим красивый и небольшой DIFF описывающий изменения в API. С генерацией документации по исходникам мы этого не получим как не старайся.
А далее мы можем для особо простых и небольших проектов просто сделать кодогенерацию API из документации к оной и получить больше профита. Я вот хочу все придти к этому потому как простые апишки писать немного скучно, а существующие решения либо не используют кодогенерацию (а значит плохо масштабируются) либо просто кривые и надо писать свои шаблоны.
boolive
25.04.2016 00:03Хочу сервис, в котором с одной стороны вручную пишешь документацию к апи с примерами ответов (заглушки) и тем самым сразу можно применять в приложении. С другой стороны бэкенд генерирует доку к апи. Две доки сервисом соединяются, проверяются расхождения. И получается АПИ с уже реализованными методами, методы на заглушках и методы, сделанные вперед ручного описания. В документации как-то помечается статус реализации метода.
Есть ли такие?Fesor
25.04.2016 02:41С другой стороны бэкенд генерирует доку к апи. Две доки сервисом соединяются, проверяются расхождения.
Интересная концепция. К сожалению в моем случае не выйдет так как не из чего сгенерировать документацию норамльно (мэппинги структур данных не статичны, я использую один компонент для формирования структур данных (вместо отдельных DTO объектов) и еще один который хэндлит за меня рутины (вроде трансформациии типичных объектов вроде дат и тд.)
То есть в моем случае информации полной о структурах данных нет и придется всеравно что-то руками дописывать. А если же я буду прописывать все DTO-ки руками, и мэппинги делать так как мне это удобно и при этом что бы вся информация о типах сохранялась — я потрачу на это больше времени при отсутствии профита.
С другой стороны, есть тулзы которые берут ваши примеры запросов и просто бомбят сервер этими примерами и проверяют ответы. Вот к примеру один из них: dreddboolive
25.04.2016 15:02Соглашусь, что кто-то из сторон в этом случаи полениться делать доку, если она уже есть. Хм, хотя если бэкенд предоставляет апи вперед ручного описания, то можно её принять. А для бэкенда можно предложить аннотацию для копипаста…
Fesor
25.04.2016 17:50А для бэкенда можно предложить аннотацию для копипаста…
Можете пояснить мысль?boolive
25.04.2016 17:56Для прописывания сваггер аннотации к методу, чтобы с генерированная потом дока соответствовала требуемой.
Fesor
25.04.2016 21:33Повторюсь, не всегда есть информация о мэппингов респонсов и реквестов (я вот ленивый и юзаю вместо DTO динамические структурки данных), а стало быть придется руками писать доку, а стало быть шансы проиграть остаются.
Мне больше нравится следующий сценарий:
— договариваемся как должна работать фича со всей командой
— договариваемся о том как должна выглядеть API между заинтересованными лицами. Кто именно напишет доку к апишке для этой фиче — без разницы.
— Пишем тест уровня приложения (интеграционный) используя доку для генерации клиента к апишке
— Пишем апишку.
И тогда все хорошо, и мы еще и тестами покрыли фичу.
lair
25.04.2016 10:30Давайте не будем подменять понятия
Например, какие и чем?
имея на руках описание API [...] мы можем вести абсолютно паралельную разработку.
Тут есть две проблемы. Во-первых, описание API надо породить, и пока это будет происходить, все разработчики будут простаивать. Во-вторых, в моем личном опыте — возможно, это просто я не умею API готовить — ни одно описание API не выживало дольше суток разработки (а чаще — пары часов разработки), после чего немедленно начинались правки, и это описание устаревало.
При генерации документации на основании реализации [...] мы полностью теряем возможность паралельной разработки, так как в этом случае у нас нет заранее задекларированного слоя интеграции двух систем.
Почему же? Вот разработчик бэкэнда начал работу. Начал он ее с того, что определил (сразу в коде) свой внешний контракт (ресурсы, методы, структуры) — причем в том объеме, в котором это можно построить из текущих бизнес-требований. На основании этого кода построилось формальное описание, которое может потребить разработчик фронтэнда — после чего их работа прекрасно параллелится.
Так же у документации лежащей отдельно есть отдельная плюшка которая мне кажется дико удобной — возможность отслеживать изменения.
Ну вообще по коду дифф тоже прекрасно строится. Более того, если мобильный разработчик не умеет читать серверный код, то можно сгенерить промежуточные форматы (тот же raml) по обеим версиям, и взять все тот же дифф.
PS А еще бывает разработка открытого API, где нет никакого заранее известного клиента.
Fesor
25.04.2016 12:56Во-первых, описание API надо породить, и пока это будет происходить, все разработчики будут простаивать.
Это занимает как правило не так много времени. Причем не важно кто именно будет «порождать» API, это может сделать мобильщик пока ожидает предыдущее API или же кто-то еще. У меня был проект где члены команды географически находились в разных местах и мы ввели там такую схему работы именно для оптимизации процессов.
Правда следует уточнить что для этого все члены команды должны быть адекватными, а это увы не всегда так. Конкретно там это дало значительный профит, но были ситуации, когда бэкэнд разработчик просто забывал предупреждать о том что хочет поменять API и об этом узнавали когда что-то ломалось на клиенте. Но опять же, это вопрос коммуникации и его можно решить (как просто разговором так и автоматизацией какой-то части этих процессов).
ни одно описание API не выживало дольше суток
А можете привести пример? Может быть проблема с исходными требованиями? У меня просто такие проблемы бывают, но это скорее исключение из правил. Да и как бы подправить markdown файлик занимает пару минут.
Почему же? Вот разработчик бэкэнда начал работу. Начал он ее с того, что определил (сразу в коде) свой внешний контракт [...] если мобильный разработчик не умеет читать серверный код
Вы тут делаете допущение что:
— есть возможность декларировать контракты в каком-то виде (мэппинги структур данных, все типы явно заданы и известны и все такое). А я вот пишу на PHP, и вместо DTO использую отдельные либы, которые позволяют мне использовать мэппинги на динамические структурки данных. Это существенно ускоряет в моем случае разработку но за счет этого у меня нет достаточно информации о том что бы заранее иметь какой-то контракт. Введение полноценного слоя DTO с мэппингами и т.д. сильно удорожает разработку, потому идти на это я не хочу (я пробовал).
— разработчик клиента мониторит исходники. Причем на одном проекте может использоваться PHP, на другом node.js на третьем java.
Словом слишком сложно. В рамках сложившейся команды — это нормальный и более чем жизнеспособный подход. А в моем случае это работать не будет.
lair
25.04.2016 13:10Это занимает как правило не так много времени.
У всех по-разному, к сожалению.
А можете привести пример?
Сходу — нет, дело полугодичной давности.
Может быть проблема с исходными требованиями?
Нет, это проблема с тем, что требования неоднозначно преобразуются в реализацию, все-таки.
Да и как бы подправить markdown файлик занимает пару минут.
Это пара минут, которых можно избежать, если править сразу код.
есть возможность декларировать контракты в каком-то виде
Да, конечно. Если такой возможности нет, то и говорить не о чем.
разработчик клиента мониторит исходники
… или мониторит что-то, куда публикуются дифы. То же допущение, что и у вас.
Словом слишком сложно.
В моем случае оказалось слишком "сложно" (скорее, слишком много оверхеда) вести разработку с предварительным описанием контракта.
boolive
25.04.2016 15:13Для разработчика сервера все равно пишется некое ТЗ по АПИ. У нас это фактически дока. Конечно писать её сразу правильно в формате сваггера лениво и мы реальную доку генерируем по коду. Но может визуальные редакторы бы облегчили задачу. А в купе с заглушками, пока сервер не готов, было бы совсем здорово. Я поэтому в ветке выше и подумал о сервисе, который бы автоматизировал рутинные процессы для двух сторон разработки.
lair
25.04.2016 15:16Для разработчика сервера все равно пишется некое ТЗ по АПИ.
А точно ли пишется? Всегда?
boolive
25.04.2016 15:34Чаще чем никогда :) API — это не только результат творчества разработчика сервера. Требования пользователей API нужно учитывать. По моему, задокументировать эти требования лучше всего.
lair
25.04.2016 15:38Есть разница между "задокументировать требования пользователей" (что, кстати, происходит не всегда) и "написать ТЗ на АПИ". А разработка сопряженных фронта и бэка по бизнес-требованиям — это третья вещь.
boolive
25.04.2016 16:17Детализируя требования, получаем документацию. Сделать это могут не все, и не ставится вопрос о практичности детализировать на 100%. Сгенерированная по коду документация будет полнее (хотя не факт). Но содержать будет только то, за что взялись разработчики. Когда как для пользователей (разработчиков фронта, приложений...) можно вручную описать будущее API, для разработчиков сервера оно снимет лишние вопросы. И разве это плохо или не правильно? Я бы хотел инструмент, где сосуществовали оба подхода к документированию, дополняли друг друга.
lair
25.04.2016 16:20Детализируя требования, получаем документацию
На самом деле, нет. Документация и требования отвечают на разные вопросы.
Но содержать будет только то, за что взялись разработчики.
… то есть то, что реализовано, и то, как реализовано. Это ли не прекрасно?
для разработчиков сервере оно снимет лишние вопросы
Снимет ли? Или создаст новые, в формате "но мне же так неудобно делать, как теперь поменять"?
boolive
25.04.2016 16:35Вы на стороне сервера и вас волнует компетенция человека, описывающего вручную доку. Меня одновременно волнуют компетенции бэкендщика, который решил сам придумать АПИ, и фронтендщика, с фантазиями как бы хорошо было бы… Поэтому и хочу сервис, где согласовывались бы обе стороны. Если бэкенд опережает на месяц и супер адекват — его вариация доки примется в большей степени. И наоборот. Или отдельный адекватный, который найдет компромисс :)
lair
25.04.2016 16:49Поэтому и хочу сервис, где согласовывались бы обе стороны.
Угу, вместе с кнопками "комментировать", "откатить" и "согласовать".

gatools
23.04.2016 16:33Я понимаю что было бы более правильно использовать инструмент который на основе api генерирует код но к сожалению сначала взялся писать минималистический код а потом тока начал документацию и лишь потом только обратил внимание на тот же swagger
lair
23.04.2016 16:58+2было бы более правильно использовать инструмент который на основе api генерирует код
Лично я считаю, что "правильно" использовать инструмент, который на основе кода генерирует документацию.
к сожалению сначала взялся писать минималистический код а потом тока начал документацию и лишь потом только обратил внимание на тот же swagger
Но если вы понимаете, что это неправильно, зачем продолжать?
gatools
23.04.2016 17:05Вы правы. Попробую данный инструмент довести до ума. Возможно, посоветуете, на какой инструмент ориентироваться?
lair
23.04.2016 17:06Попробую данный инструмент довести до ума
Какой "данный"?
Возможно, посоветуете, на какой инструмент ориентироваться?
Я пока предпочитаю Swagger (и его WebAPI-реинкарнацию Swashbuckle), но он не без недостатков.
Fesor
23.04.2016 17:10+1Лично я считаю, что «правильно» использовать инструмент, который на основе кода генерирует документацию.
В этом случае «потребители» API сильно зависят от того, когда будет готова API. То есть это больше похоже на ватерфол. К сожалению далеко не всегда удается сделать так, что бы бэкэнд разработчики пилили апишку на шаг вперед от мобильщиков тех же. Я чаще сталкивался с ситуацией где бизнес аналитик/продукт оунер/стэкхолдеры не успевали требования для фич согласовать что бы загрузить бэкэнд разработчика на 100%.
А если мы в начале итерации задекларируем слой интеграции, и, разумеется при исплользовании средств верификации на соответствие документации, мы можем вести разработку клиента и серера практически независимо друг от друга, тем самым сильно ускоряя процесс разработки и снижая риски.
Ну и опять же, я сейчас работаю над шаблонами для кодогенерации. В доброй половине случаев у меня API требует банального CRUD-а и как-то хочется его просто генерировать. Причем так, что бы можно было потом код подправить а не выкидывать. В этом случае для очень простых проектов мобильщик может описать полностью API которая ему нужна, а бэкэнд разработчику останется просто сгенерить код, подправить в паре мест и вылить.lair
23.04.2016 17:12В этом случае «потребители» API сильно зависят от того, когда будет готова API.
Не API, а тот контракт API, на основании которого генерится документация — что, в принципе, ничем не хуже документации, только гарантированно не разойдется с кодом.
Fesor
24.04.2016 17:24Можете пояснить о чем вы? А если я хочу что бы этот «контракт» предоставил мне мобильщик? Ну мол, допустим мне просто лень/некогда вникать в фичу для проектирования API, и мобильщики люди тоже не глупые и вполне могут под задачу спроектировать пару методов API за меня. А я просто получу это как дополнительную информацию о том как мне что делать.
lair
25.04.2016 10:33Можете пояснить о чем вы?
О том, как раньше работали (некоторые) SOAP-сервисы, и как сейчас может работать, скажем, WebAPI в связке со Swashbuckle — я просто определяю класс, который будет обрабатывать запросы, прописываю пути, методы и структуры, добавляю cross-cutting-атрибуты (типа авторизации) — и уже можно получить, с одной стороны, документацию (включая формальные описания), а с другой — точку входа для тестов.
А если я хочу что бы этот «контракт» предоставил мне мобильщик?
В этом случае вам придется пойти со стороны мобильного клиента. И если у того нет возможности сгенерить промежуточное описание из своего кода — тогда вам придется написать это промежуточное описание руками.

auk
23.04.2016 20:46+2Мы в своё врея остановились на swagger.
У них есть замечательный инструмент swagger-editor: http://editor.swagger.io/#/
который работает, как на этом сайте, так и локально.
Представление API в json, либо yaml.
Для просмотра есть swagger-ui: http://swagger.io/swagger-ui/
Вот пример того, как может выглядеть api: http://petstore.swagger.io/
Совсем для затравки — у swagger есть плагины для gradle и maven: swagger -> asciidoc -> { pdf, html5 }
Наши потребности он перекрывает на все 100%.
Удобно, попробуйте.
Stan_1
23.04.2016 21:04+2Вот, прямо +1.
Во1, описание методов API можно вести в проектах Rails прямо не отрываясь от кода, причем не «замусоривая» код.
Во2, сразу получается интерактивная система, где можно вызывать методы API и смотреть результат.


akzhan
24.04.2016 01:26https://apiary.io/ и подлежащий https://apiblueprint.org/ — по-моему, первое, что вы должны были рассмотреть.
И, конечно, http://swagger.io/

leorush
24.04.2016 08:19+1Fesor
24.04.2016 17:27А есть примерчики именно md файлов, а то сходу не нашел.
leorush
24.04.2016 19:12index.html.md — прямо в дистре )
Fesor
24.04.2016 21:04+1Ясно, то есть это всего-лишь шаблончики для md файлов, никакой магии. В целом мило, но далеко не самый эффективный способ.
К примеру я использую api blueprint именно из-за возможности DRY-ить документацию, реюзать структуры данных и т.д. А примеры как дергать запросы через CURL — это можно сгенерить.

artgrosvil
24.04.2016 09:04Хорошая практика писать сначала документацию к api, а потом уже само api. Как и тесты. Swager здесь является неким стандартом, на мой взгляд, для api. Лично я использую apidocjs.com в маленьких проектах. Приятный синтаксис и встроенный клиент для тестирования прямо из документации. Но в большим проектах, особенно за рубежом, ничего кроме swager'а не признают.
Ваша разработка будет полезна, но приятнее писать документацию прямо в коде, что бы были видны сразу входящие данные, ответы апи и прочее, а потом уже генерировать на основе этого кода документацию.
eshimischi
25.04.2016 10:05+1Просто оставлю это тут raml.org
eshimischi
25.04.2016 10:22https://habrahabr.ru/company/selectel/blog/265337/ — на хабр уже было упоминание.
gatools
25.04.2016 11:18Как я уже и писал, я пробовал писать на RAML но мне такой способ не удобен, уж лучше тогда Swagger взять
ragimovich
А вы принципиально не искали альтернативы? Есть же прекрасный Postman (https://www.getpostman.com/), который еще и код умеет генерировать для конкретного вызова на десятке языков.
gatools
К сожалению данный редактор не попадался в поиске. И я так понимаю Postman не относиться к опен сорс проектам. Я искал именно опен сорс.