
Немного истории
В самом начале 2010 года Vincent Driessen пишет отличную статью A successful Git branching model. Для понимания того, о чем пойдет речь дальше, со статьей нужно, конечно же, познакомиться. А для тех, кому сложен язык оригинальной статьи, на хабре есть её отличный перевод.
С этого момента описанная модель ветвления GitFlow, начинает, что называется, расходиться по миру. Её берут на вооружение многие команды. Авторы пишут много статей об успешном её использовании. Она получает поддержку в большинстве инструментов, которые используют разработчики:
- Плагин к самому Git'у
- Плагины к различным IDE: IDEA, Eclipse
- Встроенная поддержка в GUI клиентах: SourceTree и Git Extensions
- Плагины для систем сборки: Maven, Gradle, и т.д.
- Встроенная поддержка в менеджерах репозиториев: GitHub, BitBucket, GitLab и т.д.

Кажется, что модель идеальна. Быть может так оно и есть, если у вас небольшая команда, неизменяемый скоуп релизов, высокая культура работы с VCS. Тогда, действительно, GitFlow может и удовлетворит все ваши потребности. Но, к сожалению, описанные условия подходят не всем командам и не всем проектам. К слову, найти статьи, в которых бы авторы описывали проблемы этой модели не так уж и просто даже в 2016 году. Но как мы все знаем, серебряной пули нет, а, значит, и в этой модели всё хорошо далеко не для всех.
Что не так с классическим GitFlow?
История начинается с того, что классический GitFlow предполагает большое число merge-коммитов. Причем проблема не в самих merge-коммитах (которые, как вы дальше увидите, всё равно будут присутствовать в истории), а в их огромном количестве. Дебаты на тему «Merge vs Rebase» часто встречаются на просторах интернета (поисковики подскажут). У Atlassian, кстати, есть хорошая статья, в которой описывается разница этих двух подходов. Так в чем же дело?
История коммитов становится просто ужасной. На фото ниже всего один день работы команды.

Да, у нас естьgit log --first-parentи другие возможности отфильтровать дерево, но это несильно помогает полноценному анализу истории. Если же у команды разработчиков, кроме классического GitFlow, нет никаких других соглашений по ведению Git-репозитория, то в этой истории можно будет целыми пачками наблюдать коммиты c абсолютно бессмысленными сообщениями "fix", "refactoring", "", и т.д. Это сделает историю коммитов практически непригодной даже для самого поверхностного анализа.
Если ваш релизный скоуп меняется (а в Agile это бывает не редко), то классический GitFlow вам вряд ли подойдет. Если в вашем рабочем процессе часто встречаются фразы, попадающие под шаблон "Заказчику срочно нужна сборка, в которой [\w]*", то с историей коммитов, наглядно представленной в предыдущем пункте, ваша жизнь превратится в сущий ад. Я не шучу.
- Из-за merge-коммитов усложняется использование
git bisect
А что хотелось бы?
Очень сложно объяснить, почему так важно, чтобы история коммитов была чистой. Опытным разработчикам не требуется объяснения, почему чистым должен быть исходный код, для них это утверждение — аксиома. На мой взгляд аналогия тут абсолютно прямая. Также как и каждая строчка чистого кода, каждый коммит истории должен быть на своем месте и понятен любому, даже стороннему, разработчику. Да, грязный код тоже может быть рабочим, но на сколько удобно с ним работать? Как быстро удастся в нем разобраться новому сотруднику? То же самое и с историей коммитов. Даже грязная история будет знать абсолютно всё обо всех изменениях в проекте, но удобно ли будет с ней работать?
Для того чтобы работа с Git-репозиторием была простой, удобной и понятной, на мой взгляд необходимы всего две вещи:
Линейность истории изменений. Это свойство ограничивает толщину дерева коммитов константой, делая его максимально простым и наглядным для анализа.
- Логическая завершенность каждого коммита. Это свойство сильно увеличивает гибкость истории изменений. В этом случае, если потребуется, отдельные доработки могут быть без лишних сложностей перенесены с помощью команды
git cherry-pick. Или полностью отменены с помощью командыgit revert, которая в случае простого коммита гораздо проще, чем в случае merge-коммита.
Если оба свойства выполняются, дерево коммитов будет выглядеть следующим образом:

Как этого достигнуть?
Нужно совсем не много подредактировать классический GitFlow. При этом работа с develop, master, release и hotfix бранчами остаётся ровно такой же, как и в классическом GitFlow. Правки же коснутся исключительно работы с feature-бранчами.
Перед вливанием feature-бранча в итоговый, ему необходимо сделать интерактивный rebase командой
git rebase -i develop, при этом все промежуточные коммиты в бранче слить (squash'ить) в один. Бывают случаи, когда историю коммитов в feature-бранче имеет смысл оставить, но эти случаи на практике очень редки. При хорошей декомпозиции задач каждая небольшая задача представляет собой атомарное и логически завершенное изменение системы, которое отлично укладывается в одном коммите. Учитывая, что все изменения в рамках задачи можно соединить в один коммит в самый последний момент, во время работы над задачей разработчик может по-прежнему беспрепятственно создавать множество промежуточных коммитов, необходимых ему для потенциального отката. Ну и не лишним будет добавить, что есть отличная команда rerere, помогающая разработчикам, часто выполняющим операцию rebase.
Заливать feature-бранч в удалённый репозиторий необходимо с помощью команды
git push --force, так как в предыдущем пункте мы произвели rebase-бранча.
- Вливать feature-бранч в итоговый необходимо командой
git merge --ff-only feature, так как только в этом случае удастся сохранить линейность истории коммитов и избежать появления merge-коммита.
Как видите, изменений по работе с репозиторием совсем не много. И, подводя некий итог этой части статьи, хочу поделиться ссылкой на отличную статью, где также рассматриваются плюсы и минусы классического GitFlow и Rebase Flow.
Поддержка Rebase Flow в менеджерах репозиториев
Как я уже упоминал в самом начале статьи, поддержка классического GitFlow есть во множестве инструментов, в том числе и в различных менеджерах репозиториев. Поэтому дальше я рассмотрю вопрос о том, как сейчас обстоят дела с поддержкой Rebase Flow в популярных менеджерах репозиториев. При этом моя оценка будет в формате обычной университетской отметки.
GitHub
Поддержка Rebase Flow: ХОРОШО
На самом деле, у GitHub есть практически всё что нужно. В настройках репозитория есть галочка «Allow squash merging».
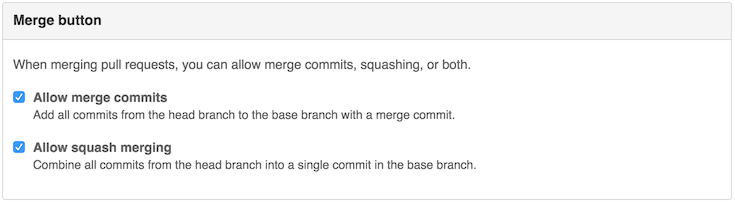
Она позволяет при мерже pull request'а выбрать соответствующий пункт и отредактировать итоговое сообщение к коммиту

В результате pull request будет смержен линейно и все коммиты будут схлопнуты в один.
Единственный минус, который я вижу на стороне GitHub, это
- отсутствие возможности смержить pull request без слияния коммитов. Очень редко, но это всё-таки требуется и, в случае с GitHub, этот мерж придётся выполнить вручную.
Всё вышесказанное относится и к GitHub Enterprise, который может быть развернут на серверах вашей компании.
BitBucket
Поддержка Rebase Flow: НЕУДОВЛЕТВОРИТЕЛЬНО
А по факту её просто нет. Если вы хотите использовать в своей работе Rebase Flow, то BitBucket в этом вам никак не поможет, всё придётся делать самостоятельно.
И это удивительно, учитывая что по тексту этой статьи я не раз ссылался на отличные статьи с сайта Atlassian. Будем надеяться, что в будущем ситуация с поддержкой Rebase Flow изменится, тем более что задачи на это уже давно заведены
- Forced non fast forward merge of pull request?
- Provide the option to use "git merge --squash" for pull requests
- Force fast-forward only merges on pull requests for specific branches
- Detect and handle rebasing and auto-merge in more situations
- и т.д.
Давайте теперь посмотрим, что с поддержкой Rebase Flow у платного продукта от Atlassian.
Atlassian BitBucket Server (a.k.a. Atlassian Stash)
Поддержка Rebase Flow: УДОВЛЕТВОРИТЕЛЬНО
Я рассматриваю BitBucket v4.5.2 и, возможно, в будущих версиях ситуация изменится в лучшую сторону. Сейчас же с поддержкой в BitBucket Server несколько лучше, чем в его облачном брате. Если у вас есть доступ к администраторам, то вы можете их любезно попросить в файле bitbucket.properties поменять для вашего проекта/репозитория настройки мержа pull request'ов (документация)
plugin.bitbucket-git.pullrequest.merge.strategy.KEY.slug— настройка для конкретного репозиторияslugв проектеKEY.plugin.bitbucket-git.pullrequest.merge.strategy.KEY— настройка для конкретного проектаKEY.plugin.bitbucket-git.pullrequest.merge.strategy— глобальное настройка для всего BitBucket Server.
Значения настроек могут быть следующими
no-ff— никакого fast-forward. Это значение по умолчанию.ff–- при возможности, будет выполнен fast-forward мерж.ff-only— всегда fast-forward мерж. Вы просто не сможете смержить pull request, если это нельзя сделать линейно.squash— сливает все коммиты в один и не создает merge-коммита.squash-ff-only— сливает все коммиты в один и не создает merge-коммита, но делает это только в том случае, если возможен fast-forward мерж.
Как вы видите, настройки достаточно гибкие, но есть две проблемы
- Нет web-интерфейса настроек, а обращения к администраторам сильно усложняют рабочий процесс.
- Нельзя выбрать поведение для конкретного pull request'а, минимальной настраиваемой сущностью является репозиторий.
Как только эти две проблемы будут устранены, поддержку Rebase Flow у BitBucket можно будет оценить на отлично. А пока ...
GitLab
Поддержка Rebase Flow: ХОРОШО
Оценивая поддержку на https://gitlab.com, мы, по сути, оцениваем поддержку в продукте GitLab EE, на базе которого он реализован. Что же касается поддержки Rebase Flow в GitLab CE, то её там попросту нет.
Для понимания того, как именно организована поддержка Rebase Flow, взглянем на настройки проекта

Как вы видите, тут даже есть промежуточный вариант полулинейной истории, когда merge-коммиты остаются, но возможность принять pull request появляется только в том случае, если feature-бранч является линейным продолжением. Если выбран этот вариант с полулинейной историей или «Fast-forward merge», у нас появляется дополнительная возможность управления pull request'ом. А именно появляется кнопка «Rebase onto ...», позволяющая сделать из feature-бранча линейное продолжение истории.
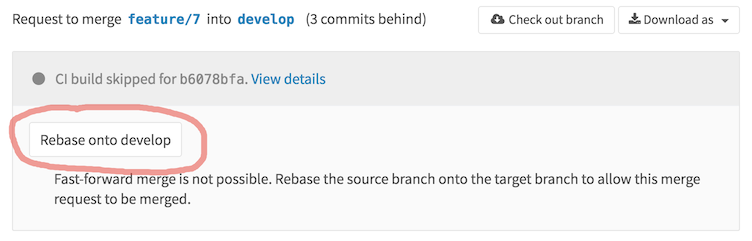
После чего можно без проблем принять pull request, который будет смержен без создания отдельного merge-коммита.

Более подробное описание этой функциональности можно посмотреть в документации (раз, два). Несмотря на то, что скриншоты в ней немного устарели, она не потеряла своей актуальности. На этом в принципе поддержка Rebase Flow заканчивается. То что она вообще есть — это, конечно, плюс, но в ней явно не хватает
- Возможности выбрать поведение для конкретного pull request'а. Да, перед принятием pull request'а можно поменять настройки самого проекта, но это не очень удобно.
- Возможности автоматического слияния коммитов feature-бранча в один.
Что в итоге?
Сейчас большинство менеджеров Git-репозиториев реализуют поддержку Rebase Flow в каком-то виде. И удобство работы в них сейчас на порядок выше, чем несколько лет назад. Но всё-таки, на мой взгляд, минусы пока есть у всех продуктов, и я продолжаю верить, что в будущем они их исправят.
Комментарии (116)

garex
11.05.2016 19:13+5Squash фича-бранча — зло.
Интерактивный ребейз, когда из 100 нанокоммитов делается 2-3-4-5 логически-атомарных коммитов — хорошо.
ihostage
11.05.2016 20:22+4Да, любые манипуляции с историей на первый взгляд кажутся злыми по определению, но я бы не был столь категоричен. Ведь именно этот вариант реализован сейчас в github, а значит многие разработчики пользуются этим функционалом и злом его не считают.
А что, если те самый 2-3-4-5 коммитов были декомпозированы на разные задачи изначально? Тогда их делают разные разработчики и они отдельно тестируются. В итоге мы приходим к ситуации, когда у нас не 1 feature-бранч из 4 коммитов, а 4 feature-бранча из 1 коммита и тогда становится уместным сделать им автоматический squash до того самого единственного коммита.
Но вообще, это уже начинает упираться в вопрос о размерах конкретных задач в конкретной команде на конкретном проекте. И в этот момент лучше использовать гибкость git'а и адаптировать его под командный процесс, чем самим прогибаться. Как я говорил в статье, я убежден что каким-то камандам/разработчикам может никогда и не понадобиться уходить от классического GitFlow.

VladimirAndreev
11.05.2016 19:35+9смушает git push --force. рано или поздно этим можно разрушить репозиторий…
ihostage
11.05.2016 19:52+4На самом деле, не все так страшно. Да, force пуш опасная операция в неопытных руках. Но фатальных последствий можно избежать, если использовать пермишены на force пуш для ключевых бранчей репозитория. Ведь речь идет о force пуше только feature-бранчей. Пермишены можно выставить как локально, для собственной безопасности, так и на удаленном репозитории. Все перечисленные в статье менеджеры репозиториев этой функцией в каком-то виде обладают.

justmara
11.05.2016 22:44+2что мешает его запретить?
в gitlab есть protected branches: т.е. в ветку вообщне нельзя коммитить напрямую — только merge-request'ами
в bitbucket server есть то же самое, но как минимум двумя способами — хуками или правами на юзеров\групп.
защищаешь master + develop + release/* и всё, враг не пройдёт.
ой, не туда ответил. писал для VladimirAndreev

lisper
11.05.2016 23:47За push --force надо бить по рукам, есть большой риск затереть изменения, который другой человек мог параллельно положить в репозиторий. Например, банально забыли повесить пермишны или просто больше одного человека над веткой работают. От того не легче, что затерли коммиты во второстепенном бранче, а не в основном. Конечно из логов можно в таком случае поднять хеш и откатить обратно, но зачем нужны лишние проблемы. Перед вливанием измений в feature-ветку сделать pull --rebase (до кучи autostash в настройках врубить для упрощения процедуры), слив таким образом последние изменения, потом просто push.
ihostage
12.05.2016 00:01+2В статье говорится о ситуации «Перед вливанием feature-бранча в итоговый». В этот момент все работы по feature-бранчу завершены и он мержится в итоговый. Для того, чтобы история была линейной, мы в любом случае вынуждены сделать force-пуш.
Но вы всё верно говорите, так как затрагиваете момент активной работы над бранчем. В этот момент force-пуш лучше не использовать или делать это с уведомлением всех заинтересованных лиц. В своей команде, путем декомпозиции задач до логически атомарных, мы максимально стараемся избегать ситуаций, при которых несколько человек работают над отдельным бранчем. Тогда градус проблем от force пуша понижается практически до нуля, так как в большинстве случаев разработчик никому не навредит, кроме себя.
dkanashevich
12.05.2016 10:56+1Есть еще замечательный параметр --force-with-lease, всегда использую его вместо --force. Защищает от затирания чужих изменений.

Yeah
12.05.2016 00:00+1смушает git push --force. рано или поздно этим можно разрушить репозиторий
git reflog
Arkafon
12.05.2016 09:31-1если пушить в свой форк, то не вижу проблемы. ни разу не сталкивался с ситуацией, чтобы другой разработчик лез в мой репозиторий для того, чтобы утянуть у меня ветку по таску, который я ещё ему не передал. пушить с форсом после передачи ветки в следующие руки — нонсенс.
если форсить ветку с уже созданным пулл-реквестом, это сразу становится видно в overview (github, stash, etc.), что сразу настораживает заинтересованных лиц

evnuh
11.05.2016 19:38+11Я очень против «чистоты истории коммитов», удаления мердженных фича-веток, ребейза, переписывания истории (вообще фу). Причина этому одна — я не вижу никаких плюсов для этого на практике. Вот реально. Скажите мне, зачем люди гонятся за чистотой истории коммитов? Зачем разработчики вообще смотрят на графическое представление истории? Какую задачу они решают, что нужно смотреть на то, чт оесть на скриншотах?
Зато я вижу огромнейшую кучу минусов, что человек делал делал работу, коммитил, соответственно запомнил он всю свою работу именно с теми коммитами, которые он сам делал. А потом нужно порыться в истории, и уже сам разработчик не может вспомнить зачем что и почему, т.к. история коммитов уже другая.
zxcabs
11.05.2016 20:03-3ну так не надо в одной ветке мешать все подряд и тогда чистота истории обретет смысл.
vazquez
11.05.2016 20:24+1>А потом нужно порыться в истории, и уже сам разработчик не может вспомнить зачем что и почему, т.к. история коммитов уже другая.
В истории рыться очень непросто, если она выглядит так, как на первом скриншоте — просто потому что история в экран монитора помещаться перестает. Вдвойне непросто рыться в истории, если рыться приходится другому разработчику а в самой истории куча коммитов вида «fix blah-blah-blah»
ihostage
11.05.2016 20:40+1Признаться я не писал об удалении смерженных бранчей. Смерженный бранч попадает в историю окончательно и оттуда не удаляется. Он просто мержится не в виде merge-коммита, а в виде линейного продолжения истории. Содержимое бранча при этом может остаться абсолютно таким-же.
Зачем смотреть на графическое представление? Тут ответ на самом деле прост. Прийти в эту точку можно в два шага.
1. Я смотрю на строчку кода и пытаюсь выяснить в рамках какой задачи и зачем автор её добавил. Для этого я смотрю к какому коммиту привязана эта строчка. Если в сообщении к коммиту я виже «issue-1 исправлена ролевая модель», то все хорошо. Я получил ответ и не потратил много времени. Если же я вижу «fix bug, refactoring» или что-то в этом духе (что часто возникает при частых коммитах в длинных бранчах), то перехожу на шаг 2.
2. Иду анализировать историю коммитов (те самые картинки на скринах), чтобы понять в рамках каких работ был сделан этот коммит. И если история очень грязная, то это занимает немало времени. Хотя все могло бы закончиться на шаге 1, будь она чистой.
vintage
11.05.2016 22:15-2Почему вы не используете mercurial?
ihostage
12.05.2016 00:46+1"Так исторически сложилось. " ©
Когда-то давно, когда не было никаких github и все радовались gitosis, прошла успешная миграция с SVN на Git. А сейчас причин для очередной миграции просто нет, так как возможности git'а полностью покрывают все потребности командной работы.vintage
12.05.2016 00:59Судя по тому, что вы описали в предыдущем комментарии — покрывают не все потребности. В меркуриале нет этой проблемы и её не приходится решать переписыванием истории.
gturk
12.05.2016 04:06Эмм… а как меркуриал защищает от грязной истории?
vintage
12.05.2016 09:12Мы обсуждали эту проблему: "Я смотрю на строчку кода и пытаюсь выяснить в рамках какой задачи и зачем автор её добавил."
А от "грязной истории" меркуриал никак не защищает. В нём "грязная история" не является такой уж фатальной проблемой.
VolCh
12.05.2016 08:29Он не оставляет места для домыслов при трактовке истории. Одно соглашение по именованию веток и всё становится прозрачным.
gturk
12.05.2016 08:56+2Но я ведь могу точно также в меркуриале наколбасить кучу мерджей
https://yadi.sk/i/VjRj8FmVreQL4
мастер и 2 фичеветки, каждая из них подливает изменения из мастера. из на 3 полезных коммита у меня получилось 4 мерджа. И я всёещё не понимаю как меркуриал уберег меня от каши в истории.
ihostage
12.05.2016 08:59На мой взгляд все иначе. И статья и мой комментарий рассказывают именно о том, как покрыть возникшие потребности используя возможности git'а.
Falstaff
12.05.2016 00:40Не ради спора, а просто в копилку: если слияния делаются с --no-ff, то «git log --merges ..» покажет коммит слияния, у которого интересующий коммит числится в предках. Там скорее всего будет имя feature-ветки, которая мёржилась (что-нибудь вроде «Merge branch '...' into ...»), это чуть более информативно.

zloddey
11.05.2016 20:59+4Весь смысл "чистой истории" в том, чтобы понимать, какую цель несёт каждое конкретное изменение кода. Если цель непонятна или размыта, то сложнее отличить действительно полезный код от какого-то мусора или откровенно вредного кода. Проблема в том, что история коммитов, которая получается в процессе работы, далеко не всегда бывает логична и удобна для чтения.
Представим, что процесс работы происходил так:
- Начал пилить фичу, реализовал половину
- Влепил локальный хак, чтобы упростить дальнейшую работу
- Сделал ещё кусочек фичи
- Понял, что для последего этапа фичи надо сделать рефакторинг, отвёл на него ещё один коммит
- Доделал фичу
- Выпил локальный хак
Что, сильно поможет такая история? Человеку, читающему историю изменений, придётся сначала спрашивать себя "WTF, что это он тут сделал? ЗАЧЕМ????", а потом видеть rollback и фиксировать в голове лишние данные — "так это был хак, оказывается! надо его игнорировать". Аналогично и с фичей, разбитой на три разных куска. Надо понять, что они друг с другом связаны, разобраться в этой связи, отделить значащие коммиты от незначащих и т.д. Это всё лишние операции, которые ухудшают понимание кода.
Куда приятнее иметь дело с такой цепочкой:
- Предварительный рефакторинг (Коммит 4 из предыдущей истории)
- Собственно, новая фича (Слитые коммиты 1, 3, 5)
Коммиты аккуратно слиты так, чтобы в каждом из них было только одно логичное и цельное изменение, то понимать их гораздо проще. Так, тут рефакторинг, он модифицирует интерфейс, но не меняет поведения — и это действительно прослеживается в коде. Так, тут фича, она использует новый интерфейс понятным образом, лишнего кода не содержит, недостающего кода тоже не содержит. Коммиты с хаками вообще не попадают в историю, потому что они будут только мешаться, затрудняя понимание. Теперь при чтении в голове приходится держать куда меньше нерелевантной информации, что весьма существенно, потому что число факторов внимания, удерживаемых в голове, у людей весьма ограничено.
evnuh
11.05.2016 21:37+3Я не очень понял из вашего огромного ответа, чем уменьшенное кол-во коммитов поможет лучше понять «какую цель несёт каждое конкретное изменение кода».
Если мне нужно понять, что вообще делает этот код — я смотрю в название ветки, в которой указано, что в ней пилилось. Если же мне нужно более узко понять, что делают вот эти две строчки — я смотрю каждый коммит разработчика, в котором эти две строчки затрагивались и читаю сообщение к каждому коммиту.
А ежели я буду видеть один огромный сквашенный коммит с кучей зелёненьких строчек, то я из него точно не пойму, что делают конкретно эти две строчки в середине огромного добавленного блока.zloddey
12.05.2016 12:31+3Я при объединении коммитов исхожу из принципа "логической завершённости", как это описано во множестве рекомендаций по стилю (к примеру, здесь). Во время текущей работы у меня чаще всего создаётся много (по нескольку десятков) очень мелких коммитов, каждый из которых не обязательно является логически завершённым. Объединением коммитов я стараюсь добиться именно этой завершённости. Вовсе не обязательно кидаться в крайность и сливать всё в один мега-коммит. Часто бывает, что это только противоречит принципу "одно законченное изменение". В идеале, после слияния в ветке из 20-30-40 коммитов остаётся несколько (1-2-5) цельных законченных изменений.
Git flow, будем честны, используют не все и не везде, поэтому вариант "я смотрю в название ветки, в которой указано, что в ней пилилось" не всегда возможно применять. Ориентация на "цельные коммиты" является более универсальной, потому что она пригождается в любом workflow.
vintage
11.05.2016 22:24+1Вас никто не заставляет заходить в фичеветки — смотрите мерж-коммиты — там как раз у вас будет "добавлена фича такая-то" и все изменения одной пачкой, безо всяких хаков. Ваше разделение на "предварительный рефакторинг" (зачем он?) и "собственно фичу" (одним огромным патчем) — не имеет смысла.
Yeah
11.05.2016 23:58+1
Yeah
11.05.2016 23:50+5Я очень против «чистоты истории коммитов», удаления мердженных фича-веток, ребейза, переписывания истории (вообще фу). Причина этому одна — я не вижу никаких плюсов для этого на практике.
Напоминает религиозные страхи. А на самом деле.
- Одно из главных правил git — commit frequently (комитьтесь чаще). Пачка из 100+ коммитов в develop ветке — отличный подарок всем, кто в отличие от вас хотят читать историю.
- Набор коммитов в фича-ветке — это мысли разработчика при работе над фичей. На кой черт мне нужно читать потом в главной ветке весь этот поток сознания?
- Неудаление смердженных веток — это вообще аут. У нас сейчас в JIRA id тасков перевалило за 4700. По-вашему у меня в репозитории должно быть 4700 старых веток?
- Представьте ситуацию: я ваш заказчик, вы имеете в develop ветке фичи: 1 (13 коммитов), 2 (27 коммитов), 3 (5 коммитов), 4 (19 коммитов), 5 (2 коммита). Я прошу: задеплой мне прямо сейчас на прод фичи 3 и 5. Остальные — не нужно, я хочу протестировать их отдельно. Ваши действия?
переписывания истории (вообще фу)
vintage
12.05.2016 00:04Одно из главных правил git — commit frequently (комитьтесь чаще). Пачка из 100+ коммитов в develop ветке — отличный подарок всем, кто в отличие от вас хотят читать историю.
Слепое следования правилам до добра не доводит. Всё же коммит должен быть более менее осмысленным набором изменений, который как минимум компилируется и сопровождается осмысленным сообщением.
Набор коммитов в фича-ветке — это мысли разработчика при работе над фичей. На кой черт мне нужно читать потом в главной ветке весь этот поток сознания?
А для чего вам нужна история кроме как для понимания что и почему изменял разработчик?
Неудаление смердженных веток — это вообще аут. У нас сейчас в JIRA id тасков перевалило за 4700. По-вашему у меня в репозитории должно быть 4700 старых веток?
Это родовая травма гита. Переезжайте на меркуриал — там с этим проблем нет, так как ветки можно закрывать.
Представьте ситуацию: я ваш заказчик, вы имеете в develop ветке фичи: 1 (13 коммитов), 2 (27 коммитов), 3 (5 коммитов), 4 (19 коммитов), 5 (2 коммита). Я прошу: задеплой мне прямо сейчас на прод фичи 3 и 5. Остальные — не нужно, я хочу протестировать их отдельно. Ваши действия?
Почитайте про github flow.
Yeah
12.05.2016 00:28+1Всё же коммит должен быть более менее осмысленным набором изменений, который как минимум компилируется и сопровождается осмысленным сообщением.
Ага, именно для этого делается squash и фича заходит в develop одним коммитом с осмысленным и красивым сообщением. Но это не значит, что разработчик не может в feature-branch накоммитить 100 коммитов до этого.
А для чего вам нужна история кроме как для понимания что и почему изменял разработчик?
История мне нужна для того, чтобы понимать, что и как поменялось с принятием фичи в develop. Какие файлы поменялись, сколько всего файлов поменял разработчик на протяжении работы с данной фичей. А видеть 100 коммитов с сообщениями вроде: fixed / update / fix / 1… мне совершенно неинтересно.
Это родовая травма гита. Переезжайте на меркуриал
Пфффф, отличный совет. Также рассмотрю от вас совет переписать проект с PHP на Java, потому что у PHP тоже сплошные родовые травмы, развестись с женой, потому что нынешняя не хочет готовить мне блинчики с икрой, и, как апофигей, предложение переехать в другую страну, потому что в нынешней коррупция высокая.
Почитайте про github flow
Пафосно, но мимо. github flow никак не решает поставленную задачу. Они лишь гарантируют, что master всегда готов к деплою. Молодцы, чо. Но задачка состояла в другом.
vintage
12.05.2016 01:33+2Ага, именно для этого делается squash и фича заходит в develop одним коммитом с осмысленным и красивым сообщением. Но это не значит, что разработчик не может в feature-branch накоммитить 100 коммитов до этого.
Ну а без squash фича заходит в develop… одним единственным merge-коммитом с осмысленным и красивым сообщением.
А видеть 100 коммитов с сообщениями вроде: fixed / update / fix / 1… мне совершенно неинтересно.
Ну так и давайте по рукам за такие сообщения. На самом деле вам нужны ветки, настоящие ветки, а не просто указатели на коммиты.
Смотрите, как это выглядит в меркуриале
evnuh
12.05.2016 02:28Абсолютно с вами согласен по всем пунктам, и при этом это никак мне не мешает работать по моему воркфлоу (использую примитивный github flow). Видимо главное различие между нашими подходами в том, что я не смотрю глазами на историю коммитов. Её за меня смотрит гит на blame / bisect / etc. Для изучения глазами того, что творится с проектом я смотрю пулл реквесты, поэтому
1. не смотрю коммиты в девелопе, смотрю принятые пулл реквесты в него
2. смотреть п. 1
3. тоже не вижу проблемы в 5000 ветках, где они мне помешают то? Опять же, нигде ещё не приходилось смотреть весь список веток в репозитории
4. создаю новую ветку от develop, мержу в неё две нужные фичи, выкладываю. UPD: перечитал вопрос, не понял его. Что значит имеем в dev ветке 5 фичей с n коммитами?
kmmbvnr
12.05.2016 07:32+1да, ощущение, что весь сыр бор, из-за того что в git'e в самом нет понятия pull-request'a (как набора взаимосвязанных коммитов)
Yeah
12.05.2016 11:43не смотрю коммиты в девелопе, смотрю принятые пулл реквесты в него
Вы не смотрите, а кто-то возможно смотрит. Например, я хочу посмотреть, какие таски я задеплоил между двумя тегами. Я просто делаю:
git log 2.11..2.12
И получаю красивый список тасков. А вы получите 100+ коммитов с непонятными описаниями.
Это лишь один из примеров.
тоже не вижу проблемы в 5000 ветках
репа начинает дичайше тормозить
создаю новую ветку от develop, мержу в неё две нужные фичи, выкладываю. UPD: перечитал вопрос, не понял его. Что значит имеем в dev ветке 5 фичей с n коммитами
Вы запилили 5 фич, QA проверили, все ок, зарелизились, а через недельку ваш заказчик говорит: чувак, у меня конверсии упали. Давай, пили мне A/B тест: выложи мне на один сервер 1, 3, 5 фичу, а на второй сервер — 2, 4. Отдельные релизные ветки, да, сработают, но после нахождения причины в них появятся новые коммиты с фиксами, которые нужно мерджить и мы снова получаем бардак и нечитабельную историю.

stepank
11.05.2016 20:26Мы уже давно (года три назад, после пары лет использования git flow) перешли на нечто подобное. После того как закончил работать над фичей:
git checkout develop
git merge --squash feature/...
git commit -am '#issue comment'
git push origin develop
git branch -D feature/...
git push origin :feature/...
В итоге история у нас выглядит примерно так:
* <1234567> 2016-05-06 [dev1] (HEAD, origin/develop, develop) version bump
| * <1234567> 2016-05-06 [dev1] (tag: 1.52, master, origin/master) Merge branch 'develop'
| |\
| |/
|/|
* | <1234567> 2016-05-06 [dev1] #99 feature 99
* | <1234567> 2016-05-05 [dev2] #98 feature 98
* | <1234567> 2016-05-04 [dev1] version bump
| * <1234567> 2016-05-04 [dev1] (tag: 1.51) Merge branch 'develop'
| |\
| |/
|/|
* | <1234567> 2016-05-04 [dev1] #97 feature 96
* | <1234567> 2016-05-03 [dev2] #96 feature 97
* | <1234567> 2016-05-02 [dev1] version bump
| * <1234567> 2016-05-02 [dev1] (tag: 1.50) Merge branch 'develop'
| |\
| |/
|/|
* | <1234567> 2016-05-02 [dev1] #97 feature 96
* | <1234567> 2016-05-01 [dev2] #96 feature 97
Тут даже невооруженным взглядом видно, что происходило в проекте: кто, что и когда сделал, что и когда пошло в релиз.
Зачем нужны промежужточный коммиты в фиче бранче, вообще не понятно. За все три года работы по такой модели я ни от одного из коллег не слышал, что ему нужно было знать, что было в промежуточных коммитах.
ivlis
11.05.2016 21:53+1#96 feature 97 Очень информативно, да…
stepank
11.05.2016 23:02А имена разработчиков dev1 и dev2, и одинаковый хэш коммитов вас не смущает? Это просто пример, не буду же я рельные комменты к коммитам здесь выкладывать? Тем не менее, структура дерева коммитов именно такая.
ihostage
11.05.2016 23:25Действительно может показаться что информации маловато. Но в случае с GitHub/GitLab/BitBucket, часть сообщения «#96» — это ссылка на баг-трекер, что позволяет в один клик добраться до нужной информации. На мой взгляд это очень удобно.
ivlis
11.05.2016 23:29Понимаете, как бы суть git это децентрализованная разработка, а вы всё к серверу пытаетесь привязать. Если вместо feature 96 там описание что сделано, то вполне OK.
ihostage
11.05.2016 23:43Я с этим и не спорю. Устраивать холивар на тему "Все ли коммиты должны привязываться к задачам и все ли задачи должны быть заведены в багтрекере" я точно не планировал. Я лишь говорил о том, что даже минимум информации в сообщении к коммиту может дать быстрый доступ к дополнительной информации. При наличии дополнительных инструментов в распоряжении команды, конечно же.
PS: Децентрализации git'а для меня конечно же не новость. Вот только мне ещё ни разу не приходилось встречаться с командами, которые используют git в формате p2p, без выделенного remote-репозитория, к которому подвязаны различные инструменты из области CI. Хотя скорее всего такие команды существуют.
ivlis
11.05.2016 23:48Линус Торвальдс из небольшой команды работающих над Linux Kernel и git (внезапно) просил передать вам привет. :)
stepank
11.05.2016 23:45На всякий случай, если из моего комментария выше это непонятно, то да, после номера тикета идет описание того, что именно было сделано (обычно умещается в одну строку).

markhor
11.05.2016 21:36+1Gerrit очень хорошо поддерживает все возможные модели. Кнопка Rebase там была сколько я его помню. Но у него есть один существенный минус — по одному комиту на ревью, а если отправлять merge, то не виден кумулятивный diff (таск заведен давно, но воз и ныне там). Такие ограничения сильно бьют по количеству пользователей.
ihostage
11.05.2016 23:34Не могу не согласиться. Лично я ещё очень надеюсь, что Upsource составит сильную конкуренцию. Он безумно удобен для проведения Code Review, но вот с поддержкой различных flow по работе с самим репозиторием было не очень (во всяком случае обещалось это ещё в 1.0, но когда я последний раз смотрел на него, этого функционала там ещё не было).
PS: Хотя вот на сайте сейчас для версии 3.0 говорится об интеграции с pull request'ами на github. В каком виде это реализовано не знаю, может кто-то в комментариях подскажет или сам @JetBrains расскажет на какой-нибудь конференции :)
TargetSan
12.05.2016 00:36К сожалению, именно эта маааленькая особенность превращает использование Gerrit в акт мазохизма, по крайней мере для меня. Настройка локальной копии требует подстановки хука для задания Commit ID, что само по себе немного. Но вот каждый новый чейнджсет превращается в:
— сделать rebase+squash
— обновления делать исключительно amend
— в качестве назначения использовать фиктивный ref, о котором надо помнить
— когда приходит добрый сосед и мержится, надо ручками опять делать ребэйз
Короче, мне это сильно напоминает старые добрые времена SVN по количеству рукопашной работы.

Dreyk
11.05.2016 21:46Мне такая модель тоже нравится. Многие опен-сорсный код на гитхабе (по крайней мере в мире Ruby) использует эту модель очень и очень успешно
michael_vostrikov
11.05.2016 22:00Интересует такой вопрос. Возможно, я чего-то не понимаю.
Разработчики A и B создали ветки featureA и featureB от ветки develop.
Сделали изменения, сделали коммит, сделали rebase на текущее состояние develop, сделали push.
Последний коммит в ветке develop — X.
В первой ветке история коммитов «X — A», во второй «X — B».
Главный разработчик мерджит в develop сначала ветку featureA. Там возможен fast forward.
Потом мерджит ветку featureB. Тут уже fast forward не получится, потому что порядок коммитов другой.
Получается, тому кто мерждит, надо сначала вручную сделать rebase ветки featureB на новое состояние develop?ihostage
11.05.2016 22:50+1Если речь идет о ручной реализации Rebase Flow то да, второму придется сделать rebase. Если же используется например GitHub, GitLab или BitBucket, то у них это автоматизировано и при соответствующих настройках репозитория достаточно нажать одну кнопку. По сути именно об этих удобствах вторая часть статьи.
vintage
11.05.2016 22:43Вам не кажется странным, что вопрос отображения вы решаете не средствами отображения, а средствами редактирования? У TortoiseGit есть режим "Compressed Graph" делающий именно то, что вам нужно.
ihostage
12.05.2016 00:23+1Вынужден не согласиться. Проблемы чистоты истории влияют не только на отображение.
Да, как я упомянул в статье, у нас есть ключи для терминального
git logи различные способы фильтрации для GUI клиентов. Тут вы конечно правы и это несколько поможет в проблеме анализа истории и улучшит её визуализацию. Но на этом проблемы не заканчиваются.
Помимо анализа истории возникает необходимость работы с нею. Классический для нас кейс, когда заказчик очень быстро меняет требование к скоупу релиза и просит добавить/убрать из поставки любой набор функционала, который ему захочется. В этой ситуации работать с merge-коммитами далеко не так удобно, как если бы их не было.
vintage
12.05.2016 01:41+1Фактически вы не пользуетесь фиче-ветками. С тем же успехом вы можете коммитить прямо в develop, а перед пушем сквашивать незапушенные коммиты.

sumanai
11.05.2016 22:51А как быть с багфиксами в feature-бренче?
ihostage
11.05.2016 22:52+1Отдельный багфикс в отдельном feature-бранче. Тут подход классический и скорее относится к организации работы команды с баг-трекерами.
sumanai
11.05.2016 23:12То есть feature-бренчи так, только точка для вливания изменений.
Лично я просто за постоянные feature-бренчи, чтобы по ним можно было отследить исправление и улучшение любой конкретной фичи.
Yeah
12.05.2016 00:13А как быть с багфиксами в feature-бренче?
У меня на проекте — так:
- Отдельный багфикс в отдельном hotfix-бранче
- После проверки squash hotfix-бранча
- merge hotfix-бранча в develop
- squash hotfix в develop (нечего ему неприкаянным висеть)
- git push -f
- Все разработчики делают git fetch && git rebase -i origin/develop
PS: Не подходит для open-source проектов, где мы не можем заставить всех сделать последний пункт. Впрочем, squash feature/hotfix бранчей нередко требуют и в open-source проектах. И это — правильно
sumanai
12.05.2016 15:52Опять таки, получается, что «feature-бренчи так, только точка для вливания изменений».
Эх, ни у кого нет workflow для форков крупных проектов, забирающих только релизные версии?
Dicebot
11.05.2016 23:17Тоже используем rebase модель, но без обязательного squash (чтобы история была читабельнее). Написали для этого свою консольную утилиту для работы с GH: https://github.com/sociomantic-tsunami/git-hub
Yeah
12.05.2016 00:08Так ведь squash как раз и дает читабельность истории.
Вот как у нас было до squash
Dicebot
12.05.2016 17:21Отнюдь, у нас семантическое разбиение по коммитам (и читабельность их названий) является частью code review. Проблема с squash в том, что так в один коммит попадает множество не связанных между собой изменений, которые должны в истории храниться отдельно.
Yeah
16.05.2016 18:40Проблема с squash в том, что так в один коммит попадает множество не связанных между собой изменений, которые должны в истории храниться отдельно
Если вы работаете в ветке только с одной фичей, а не с десятком, то все изменения будут связаны между собой как раз этой самой фичей.
Dicebot
16.05.2016 18:54Это недостаточная связность на мой взгляд. Тут две проблемы:
1) Требование создавать по отдельному pull request на каждый баг фикс сильно отяжеляет разработку бюрократией (коммиты напрямую в основные ветки строго запрещены)
2) Типичное для ревью требование отделять коммиты с форматированием от коммитов с семантикой очень полезно и впоследствии при git bisect. Это касается и реализации больших фич — грустно было бы обнаружить, что проблема возникла из-за одного цельного коммита на +5000 -5000.
У сохранении истории коммитов есть, впрочем, свои недостатки. Главные — нужно настраивать CI для тестирования всех коммитов, а не только HEAD; не удобного способа проследить связь между коммитом и pull request. В планах попытаться решить последнюю проблему через https://git-scm.com/docs/git-notesYeah
16.05.2016 19:02У нас бывали случаи, когда в одной ветке делалось несколько фиксов. В этом случае после code review разработчик просто делал squash не всех в один, а группировал по фичам. В конечном итоге merge одного pull request давал столько коммитов в develop ветке, сколько багфиксов делалось в этой ветке.
Dicebot
17.05.2016 14:33И вот именно для того, чтобы облегчить слияние такого рода (`fetch pr-branch` + `rebase upstream/base` + `push upstream/base HEAD`) и была написана утилита, про которую я упоминул изначально. Чтобы можно было просто сделать `git hub pull rebase ID` и получить желаемую историю.

TheShock
13.05.2016 05:07С такими отвратительными названиями коммитов естественно хочется сделать ребейз, чтобы не видеть этот ужас. Все таки стоило начать с культуры разработчиков, а не заметать мусор под кровать.
Yeah
16.05.2016 18:44Разработчик может забыть, забить, пропустить и в дереве коммитов окажется вот это. И дальше что? А если у нас 100 коммитов по фиче? Никакой разработчик не будет выдумывать уникальные и красивые сообщения для каждого коммита.
kmmbvnr
12.05.2016 07:41Действительно сложно объяснить зачем кому-то нужна чистая история.
squash — нужен действительно только тогда, когда первоначальная реализация фичи была не совсем верная. Нет никаких доводов против мерджа как есть фичи сделанной за несколько коммитов, каждый из которых осмысленный и не ломал тесты(ну вы же делаете push каждый раз после коммита, да?)
rebase поверх — для того чтоб CI отработал на той версии кода которая получится после merge в основную ветку.
Все. squash'им только ненужные коммиты, а ребейсим и прогоняем CI чтоб держать общую ветку в рабочем состоянии. А чистая история это побочный продукт, а не самоцель.ihostage
12.05.2016 09:27+1Вы правы, чистая история конечно же не может быть самоцелью и для нас она таковой не являются. На мой взгляд ситуация такова.
Есть потребности (они же цели):
- Тестировать актуальную версию исходного кода
- За минимальное время находить информацию, являющуюся причиной изменения исходного кода
- Иметь возможность быстро реагировать на частые изменения скоупа
Есть средство, гарантирующее удовлетворение обозначенным потребностям — это чистая история. На собственной практике мы убедились, что она действительно это гарантирует.
И есть инструменты (rebase, squash и т.д.), позволяющие организовать чистую историю.
vintage
12.05.2016 09:50Не гарантирует. Допустим вы влили фичи 1, 2 в одну ветку develop, при этом в 1 внесли кучу изменений, от которых зависит 2, который вы ребейснули поверх 1 или даже срезу с 1 и стартанули. Теперь вам нужно выкатить в продакшен фичу 2 без фичи 1. Ваши действия? А если в develop 10 фич, которые также друг от друга зависят? Вам придётся очень постараться, чтобы выудить из всех фич лишь те изменения, которые необходимы тем фичам, что вы собираетесь деплоить.
Ну и ещё пара весёлых историй из жизни "чистой истории":
https://habrahabr.ru/post/179123/
https://habrahabr.ru/post/179673/ihostage
12.05.2016 10:42Мои действия очевидны — ручная кропотливая работа. Когда речь заходит об изменениях скоупа, которые затрагивают зависимые друг от друга изменения, то тут никакой flow не спасет от ручной работы. Поэтому речь всё-таки шла больше о логически атомарных изменениях.
В любом случае для принятия какого-то flow на вооружение команды, его нужно пропускать через призму многих факторов, в том числе и внешних. Когда я писал, что "серебряной пули нет", я не лукавил. Так же как и GitFlow, я не считаю Rebase Flow идеальным. У получаемых возможностей всегда есть цена и риски, о которых нужно знать. Приведенные вами примеры тому подтверждение.
За ссылки спасибо. Хотя я больше сторонник превентивных мер воздействия :) Когда же дело дошло до bisect, то тут хорошего мало, как на это не посмотри.
vintage
12.05.2016 21:45В том-то и дело, что зависимость эта образовалась из-за ответвления от develop и ребейсов. Если бы вы ветвились от мастера и не сливали ветки до деплоя, то и никакой зависимости между ними бы и не было.
Skorpyo
12.05.2016 18:47Не особо понимаю практический смысл такой чистой истории. Если вам не сложно, не могли бы вы пояснить его?
По поводу потребностей:
1) Какое событие инициирует тесты? (вы ведь про ci?)
2) Используйте номер таска в названии коммита.
3) Не до конца понял эту потребность. Какую информацию предоставляет «частое изменение скоупа, полученное из истории гита»?
Я просто не встречал ситуацию на практике, когда мне нужно было использовать графическое представление истории.ihostage
12.05.2016 19:04Не особо понимаю практический смысл такой чистой истории. Если вам не сложно, не могли бы вы пояснить его?
Не совсем понимаю, что конкретно требует пояснения. Старался сделать в это в самой статье, включая ссылки на сторонние статьи. Да и в комментариях уже много информации. Если конкретизируете вопрос по непонятному моменту, постараюсь прокомментировать.
1) Какое событие инициирует тесты? (вы ведь про ci?)
Ну это очень зависит от команды и проекта. У кого-то тесты работают несколько часов и их запускают по крону. У кого-то все тесты проходят за несколько секунд и можно прогонять их после каждого коммита.
2) Используйте номер таска в названии коммита.
Хорошая практика. В своей команде мы её используем.
3) Какую информацию предоставляет «частое изменение скоупа, полученное из истории гита»?
Никакую. Частое изменение скоупа влечет за собой активную работу с бранчами, откуда возникает потребность выполнять эту работу с минимальными сложностями за минимальное время.
Я просто не встречал ситуацию на практике, когда мне нужно было использовать графическое представление истории.
Вы действительно никогда не пользовались командой
git log? На мой взгляд это достаточно странно, хотя быть может каким-то командам в их процессах оно действительно не требуется. Главное ведь, чтобы командная работа была эффективной и без боли :)Skorpyo
12.05.2016 19:52Непонятный момент как раз заключается в том, что мне на практике не приходилось смотреть в историю (графическое представление). Интересно было бы послушать кейс, когда это необходимо.
1) У нас тесты запускаются по факту пуша в ветку и собирают самую актуальную версию ветки (на момент начала сборки). Просто не вижу, как это может быть связано с грязной историей.
3) Не встречал проблем с активной работой с бранчами. Как раз наоборот. Чем их больше, тем проще работать командой. А насчет изменения скоупа. Его разве не проще просматривать в трекере задач?
Насчет команды git log. Пользовался из консоли обычно для того, чтобы откатить свои последние коммиты (git reset). Для того, чтобы найти последние изменения мне хватает ide. Аннотаций или истории файла вполне хватает. Если по истории, то это обычно 1-5 коммитов (включая мерж коммиты). На дерево не смотрел ни разу, если не считать случаев из любопытства. Для того, чтобы понять, как работает функционал, я обычно смотрю в тесты, а не в историю. Единственное, что я могу сейчас предположить, это то, что возможно у вас слишком перенасыщенные классы. Я такие классы советую дробить на более мелкие. Если класс выполняет строго отведенную ему задачу, то его код редко меняется. А разгрузив таким образом основной класс, вы разгрузите и историю изменений этого класса. Возможно проблема кроется в другом.ihostage
12.05.2016 20:44Просто не вижу, как это может быть связано с грязной историей.
В контексте этой ветки коментариев речь идет о том, что когда вы тестируете бранч, не являющийся линейным продолжением текущего состояния проекта, то вы потенциально тестируете бранч с конфликтами. Если тестирование например ручное или автоматизированное, но долгое, то очень дорого обойдется вам это тестирование, так как после разрешения конфликтов нужен будет полный ретест. Поэтому многие стремятся как можно быстрее избавляться от конфликтов, используя мерж или, как в описанном в этой статье флоу, ребейз.
3) Его разве не проще просматривать в трекере задач?
Куда-то совсем не туда. Прочитайте пункт 4 из этого комментария ещё раз. В данном случае речь идет именно об этом изменении скоупа. Утром заказчику нужна поставка с фичами А и Б, а к обеду он уже хочет А, Д и выкинуть поставленную вчера В.
На дерево не смотрел ни разу, если не считать случаев из любопытства.
GUI представление, ни что иное, как визуализация операции git log. Пользовались им, значит смотрели дерево. В какой программе вы на него смотрели, SourceTree или консоль, это не так важно.
возможно у вас слишком перенасыщенные классы
Описываемый в статье флоу потребовался команде из нескольких десятков человек. Из сухой статистики: проекту 4 года, чисто тикетов перевалило за 15К, а число строчек кода уже давно за миллион. В этих условиях могу с уверенностью утверждать, что каких только классов у нас нет, в том числе полно перенасыщенных :))
Skorpyo
12.05.2016 21:18Поэтому мы стараемся задачи делить на максимально мелкие. Такие атомарные бранчи после успешного билда могут сразу мержиться в дев без qa (если это чисто техническая работа). А насчет конфликтов, так любой бранч потенциально может быть конфликтным. Волков бояться, в лес не ходить. Если уж так много проблем доставляет разработка в отдельной ветке, то зачем тогда использовать такой подход? А насчет побыстрее избавиться от ветки, то тут уже не только проблема разработчика. Ветка может застояться и при мерже выдать кучу конфликтов, хотя она и была линейным продолжением. Тут слишком размытые грани, чтобы брать что-то как правило. ИМХО Каждая команда поступает так, как ей удобнее.
По скоупам понял. Могу вам только посочувствовать =( Тут уже никакой workflow не подходит. Вероятно в данном случае ваш подход наиболее продуктивный. Спасибо за пример. Однако, если говорить о хоть каком-то workflow, то в этом я не вижу особой необходимости.
Ну назвать пару коммитов одного файла деревом трудно, но думаю можно и так сказать. Тогда могу сказать, что грязная история лично мне не мешала. Но на вкус и цвет =) А проект по сухому описанию похож на ваш.
Напоследок могу пожелать вам поменьше конфликтов. Спасибо, было приятно и полезно пообщаться.

SabMakc
12.05.2016 10:21-1Использую mercurial и вроде бы понимаю о чем речь, но с указанной проблемой ни разу не сталкивался. Хотя в основе модели ветвления лежит GitFlow.
Я всегда могу в 100 коммитах сделать задачу, влить в мастер / девелоп с осмысленным комментарием. И история не будет захламлена этой сотней коммитов, потому как они в отдельной ветке и не мешаются при просмотре истории основной ветки.
А если кто-то захочет разобраться с тем, как я делал задачу — ему доступна история моих коммитов с комментариями по каждому шагу.
И я против изменения истории коммитов.
Я могу понять, зачем это Open Source проектам. Или в очень больших проектах со сложным workflow…
Ну а в прочих случаях, максимум, который я готов допустить — локальное изменение истории неопубликованных коммитов, например для исправления опечаток или чтобы не проводить слияние одноименных веток.
P.S. Интересно то, что в «А что хотелось бы?» показана практически история коммитов из mercurial, где каждый коммит подписан «к какой ветке он относится».ihostage
12.05.2016 10:53+1Все так. И если на историю просто смотреть, то фильтров отображения будет более чем достаточно. Но бывает так, что команде приходится часто манипулировать коммитами из истории. И тогда сложно отрицать, что revert/cherry-pick отдельного коммита заметно проще и занимает меньше времени, по сравнению с аналогичными операциями для merge-коммитов.

AcidLynx
12.05.2016 12:15-4Может я что-то не понимаю, но зачем настолько много коммитов делать-то? На каждый, извините, пук — новый коммит?
Еще есть вариант просто систематизировать поставку коммитов, чтобы команда делала все коммиты красиво, если хочется красивой истории без изменения истории. Как положительный момент — аккуратные коммиты и разработчики.VladimirAndreev
12.05.2016 18:49например, есть у вас задача.
скажем, подсчитать количество звезд на небе, которые видны в данный момент.
и потом в 50 местах подшаманить формулы с учетом этого самого количества.
как вы не знаю, лично у меня в этой фичаветке будет 51 коммит. минимум.
e_Hector
12.05.2016 19:12-1а почему не один коммит, изменяющий переменную, хранящую в себе количество звезд на данный момент?
ihostage
12.05.2016 20:51Мне кажется VladimirAndreev имел ввиду, что в одном коммите будет реализована функция подсчета видимых звезд, а потом будут 50 отдельных коммитов, в которых будут правиться соответственно 50 мест, в которых эта функция требуется.
vintage
12.05.2016 21:51И в чём прелесть однострочных коммитов?
ihostage
12.05.2016 23:02Мне кажется в комментарии VladimirAndreev речь не шла про однострочные коммиты. Это был абсолютно искуственный пример, демонстрирующий правило "commit frequently". Если разработчику удобнее и привычнее делать десяток коммитов в день, то почему нет.
TheGodfather
12.05.2016 23:03+1Мне одному кажется странным, что вы хотите вместо одного осмысленного и «логически законченного» (с) коммита сделать 50 мелких коммитов вида «update formulas according to change»? Причем сами небось потом этим вашим squash в один сольете? Конечно, «коммитьте чаще», но не настолько же — все поправили, проверили — закоммитили. Никакой лишней мороки с объединением — изначально коммит один.
Не то, чтобы я против мелких коммитов, но я за осмысленные коммиты, причем, подчеркиваю, именно в процессе разработки. Вы же не коммитите «feature #N, line 1», «feature #N, line 2», ..., «feature #N, line 50», вы коммитите "«feature #N». Если вполне реально влить законченное изменение одним коммитом, так почему бы так не сделать, а не делать 50 коммитов, а потом их объединять?ihostage
12.05.2016 23:08Вы правда считаете, что стоит навязывать разработчику формат работы с локальным репозиторием? Лично мне всё равно, что делает разработчик моей команды со своим локальным репозиторием, если результат при этом удовлетворяет всем командным договоренностям.

donRumatta
12.05.2016 23:32Вроде не было речи о навязывании, обычный вопрос, на который мне самому интересен ответ. Зачем делать лишние движения, когда достаточно обычного Ctrl+S?
ihostage
13.05.2016 00:01Ну например в IDEA и он не нужен, там автосохранение :) Но если взять тот же ctrl+s, то люди тоже не сразу к нему пришли. Пару раз весь набранный текст исчезнул в след за крешем редактора или оси и начали чаще сохранять.
Думаю аналогичная история есть и у сторонников очень частых коммитов. Пару раз стоит потерять отличную наработку (изначально таковой не казавшуюся) не сделав промежуточный коммит и личный рабочий процесс немного меняется. Мне правда сложно судить, так как я не считаю себя столь уж частым коммитером. Но учитывая продвинутость современных инструментов разработки могу точно утверждать, что накладные расходы на частые коммиты минимальны — хоткей в IDE и коммит готов.
michael_vostrikov
13.05.2016 06:09Можно откатиться на предыдущее состояние, для отдельного файла или полностью. Полезно, если делаешь что-то большое и сложное, и понимаешь, что сделал немного не так и лучше сделать по-другому. Руками удалять объявление новой функции из класса и ее вызов из 6 разных мест это муторно.
Также удобно смотреть diff между отдельными шагами. Например, делаем класс для работы с внешним API, и на время разработки отключили реальные запросы, добавив в начало функцииreturn. Если просто сохранять, то среди сотни новых строк его можно не заметить, а если перед добавлением сделать промежуточный коммит, то будет видно, что файл изменился.
stankevichEvg
13.05.2016 11:47+1В том то и дело, что «логически законченных» с точки зрения мыслительного процесса работы над задачей может быть и много. Может возникнуть потребность «поэкспериментировать», потом выбросить эти эксперименты или взять только их часть. Тьма локальных коммитов, где каждый представляет собой результат работы за определенный период это не то, о чем я говорю. Коммит != Ctrl+S потому как такие коммиты должны помогать вам организовать работу над задачей а не просто фиксировать изменения. Если у вас нет потребности в такой работе, то и на выходе у вас будет один коммит и ничего сквошить не надо.





ivlis
Зачем это нужно, когда можно всё смерджить у себя на локальном компьютере как хочешь и сделать push?
ihostage
Да, действительно, все это можно сделать и локально, написав предварительно небольшой bash скрипт. Но сделано это все ради экономии времени. Ведь можно пойти дальше и полностью автоматизировать рабочий процесс. Например, выполнять автоматический мерж после того, как N членов команды заапрувили pull request и все автотесты пройдены. Тогда никому ничего локально и не нужно будет делать.
zloddey
Локальное слияние коммитов бывает удобнее в том случае, когда в истории смешаны разные типы изменений: рефакторинги, хаки, собственно фичи, побочные изменения и т.п. В таком случае рулит интерактивный ребэйз, позволяющий аккуратно разложить всё по полочкам. Жаль, что этот момент в статье почти не раскрыт.
SamDark
https://hub.github.com/