

«Холодный» дата-центр Facebook в Орегоне
Одна из причин популярности сервисов типа Facebook — высокая производительность, благодаря чему задержек и лагов в работе сайта практически нет (или почти нет). Если бы задержки при загрузке фоточек и видео случались бы постоянно, то, вероятно, Facebook не смогла бы развиваться настолько активно, как это происходило ранее и происходит сейчас. Но высокая популярность сервиса означает необходимость постоянно наращивать производительность, причем настолько быстро, настолько это возможно.
При этом используются не только экстенсивные, но и интенсивные методы наращивания производительности. Другими словами, требуется оптимизировать все и вся. И здесь — очередная проблема, ведь даже в небольшой компании на оптимизацию работы компьютерной сети зачастую тратятся большие средства. Что уж тут говорить о таком гиганте, как Facebook — здесь затраты на оптимизацию считают десятками, если не сотнями миллионов. Тем не менее, при таких масштабах даже небольшой удачный пример оптимизации может сэкономить миллионы долларов.
«Инфраструктурная» команда Facebook тратит практически все свое время на обдумывание возможностей повышения эффективности оборудования или ПО (локального или облачного — разницы особой нет). В начале этого года команда разработала интересный план по оптимизации работы социальной сети, причем этот план оказался весьма эффективным.
Так, два дата-центра Facebook были спроектированы и построены с практически единственной целью — сохранять все пользовательские фото и видео, плюс качественное обслуживание соответствующего трафика. Поскольку эти дата-центры (их назвали датацентрами «cold storage») были «заточены» под небольшое количество задач, команда смогла оптимизировать очень большое количество систем, снизив потребление энергии дата-центром, а также использовав не самое дорогое оборудование для хранения.
Как это работает?
Компания стала использовать не самый сложный, но весьма эффективный способ хранения медиа-фалов. Так, каждое изображение пользователей Facebook хранится в нескольких копиях, размещенных в ДЦ компании. Копии хранятся как в главных дата-центрах, так и в центрах «холодного хранения».
Более новые, более популярные файлы хранятся в большем количестве копий в «горячих» дата-центрах, чем более старые фото, которые мало кто просматривает. Главная функция систем «холодного хранения» — убедиться, что все файлы доступны всегда, в любое время.
Поскольку в системах «холодного хранения» размещаются копии не слишком популярных фото, то инженеры решили не использовать резервную электрическую инфраструктуру или аварийные генераторы. Это один из способов сэкономить средства.
Системы холодного хранения представляют собой несколько модифицированную версию Open Vault, стандарта систем хранения, разработанный в рамках Open Compute Project. Здесь интересным моментом является то, что в корзине одномоментно работает только один жесткий диск.

Модифицированная система хранения данных Open Rack, с небольшим количеством элементов питания, кулеров и прочих элементов
Специальное программное обеспечение контролирует каждый из дисков, включая только тот, который нужен в данный момент. Таким образом, «холодные» системы хранения данных потребляют энергию, необходимую для одновременной работы только 6% всех жестких дисков, которые работают в системе. В итоге, потребляется только 25% энергии, которую используют традиционные системы хранения данных, где работают сразу все жесткие диски. В свою очередь, это позволяет использовать в Open Rack только одну секцию питания (power shelve) вместо трех. Также здесь используется 5 источников питания вместо 7. А количество проводящих шин в Open Rack снижено с 3 до 1. Да и количество кулеров снижено с трех до одного, все по той же причине — единовременно работает очень малое количество жестких дисков.
10+10=14
В дополнение к оптимизации аппаратного обеспечения, инженеры Facebok оптимизируют и программное обеспечение. Например, в системах хранения данных используется технология исправления ошибок, которая называется Reed-Solomon. Она позволяет снизить объем памяти, требуемый для сохранения копий медиафайлов. Технология обеспечивает хранение копий не целиком, а частями. При необходимости Reed-Solomon собирает из частей весь файл, из всех областей, которые доступны в данный момент.
Так, если файл разделен на 10 частей, храниться в двух (к примеру) местах будет не 20 частей, а только 14.
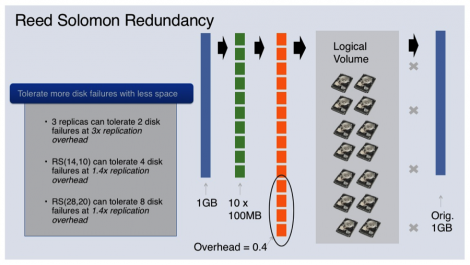
Объяснение технологии Reed-Solomon от Facebook
Что дальше?
Несмотря на то, что «холодные» системы хранения данных работают отлично, и в двух дата-центрах вполне достаточно объема для хранения большего, чем сейчас, количества информации, команда Facebook обдумывает свой следующих ход.
Так, сегодня данные, хранимые в «горячем» дата-центре Западного Побережья, дублируются в «холодной» системе хранения данных на Восточном Побережье, и наоборот. Следующим шагом компании будет использование технологии Reed-Solomon во всех «холодных» системах хранения данных.
Когда будет построена третья такая система, третий «холодный» дата-центр, система будет виртуально безошибочной, сверх-надежной. Даже, если один из дата-центров уйдет в оффлайн, данных, хранимых в двух остальных ДЦ, будет достаточно для поддержания нормальной работы Facebook. Ну, а вероятность отключения сразу двух дата-центров чрезвычайно мала.
Комментарии (36)

stalkerg
12.05.2015 08:50+22У меня facebook тормозил и тормозит. Что в Москве, что в Вильнюсе. Вконтакт по сравнению с ним летает.

igordata
12.05.2015 09:11+11Вы наверное неслишком популярные фоточки из холодных копий просматриваете. Один диск, все дела… Зато экономия.

bachin
12.05.2015 11:00+5Так тормозит ведь актуальная лента, а не архив. Отмотать же фейсбук на несколько дней назад — мучение то ещё.
Мне лично подгрузка страницы снизу никогда не нравилась: и когда я юзером сижу и наматываю километры мышиным колесом, и когда мне приходилось такое поведение в коде реализовывать.
sferrka
12.05.2015 11:38Мне лично подгрузка страницы снизу никогда не нравилась:
Отмотать же фейсбук на несколько дней назад
Проблема не в infinity-scroll, а в отсутствии доп. навигации. В Яндекс.Почте например и то и то есть. Скроллом удобно последовательно идти по списку, он не создан для поиска. Или вы знаете какое-то универсальное решение лучше?bachin
12.05.2015 13:21+3> Или вы знаете какое-то универсальное решение лучше?
«Туда-сюда» на хабре меня устраивает чуть менее, чем полностью.

netcitizen
12.05.2015 09:15+4Например, в системах хранения данных используется технология исправления ошибок, которая называется Reed-Solomon. Она позволяет снизить объем памяти, требуемый для сохранения копий медиафайлов.
Исправление ошибок наоборот требует внесения некоторой избыточности в исходные данные. Помехоустойчивое кодирование Рида-Соломона, которое, вероятно, вы пытались описать никак не может снизить объем памяти, требуемый для сохранения копий медиафайлов.
zaitsevyan
12.05.2015 09:28Так оно и не снижает. В статье указано, что, первоначально, файл имеет размер 10 «частей». И они экономят на том, что хранят 2 копии не как 20 частей, а только как 14
netcitizen
12.05.2015 09:33+1Смысл в том, что сравнивать резервирование и кодирование некорректно. Файл увеличился на 1,4 — это факт.
FYR
12.05.2015 11:18+2Избыточное кодирование как альтернативный репликации способ обеспечить отказоустойчивость? Если требование «отказоустойчивость» является обязательным то 2х и 1,4х к размеру файла вполне себе профит.

Chamie
12.05.2015 19:07Да, но если основная копия умрёт полностью, то эти 0.4 ничем не помогут.

dj_raphael
12.05.2015 19:55Не существует основной копии, есть 10 частей + 4 части дополнительно. И все они раскиданы по 14 разным носителям. Для восстановления нужно всего 10 частей, ЛЮБЫХ. может умереть 4 диска и файл всё равно будет доступен. ну вычислить недостающие 4 части снова не составляет трудности. И у нас снова 14 частей на разных носителях.
Chamie
15.05.2015 11:37Но тогда это простой RAID5.
Вообще, RAID5 + «размазывание» меня несколько пугает:
Пусть вероятность «смерти» диска за оцениваемый период — 1%. Тогда вероятность смерти одного из 14 дисков — 14%. Вероятность смерти 5 из 14 дисков (точка отказа) — 0.145 = 0.0000537824, при этом умрёт безвозвратно весь массив.
Если добиваться того же простым зеркалированием каждого диска (без объединения зеркал в RAID0), то понадобилось бы 20 дисков. Из которых может отказать до 10 без потерь вообще. С вероятностью 0.012 = 0.0001 откажут именно два диска зеркалирующие друг друга. С одной стороны, вероятность вдвое больше, чем отказ массива RAID5, с другой — потеряется только информация с этих двух дисков, т.е., только 10% от всего массива.Chamie
15.05.2015 11:44Расчёты выше ^ можно не читать, там ошибки.
Chamie
15.05.2015 12:07+1Правильный расчётПусть вероятность отказа одного диска = Р. Вероятность смерти хотя бы одного из 14 дисков = 14·Р.
Вероятность отказа 5 из 14 дисков (точка отказа массива RAID5) = 14!/9! ?P5 = 240240·P5.
Вероятность отказа 2 дисков, зеркалирующих друг друга, из 10 (точка отказа RAID1) = 14·P2. Итого, RAID1 надёжнее при Pотказа > ?(14/240240) ? 4%.dj_raphael
15.05.2015 13:20Надо уточнить что такое P. это должна быть вероятность отказа за срок который пройдет после сигнализации отказа и замены диска в массиве. В большем датацентре за день наверно не заменят. Пусть будет неделя. Так вот вероятность отказа диска в течении недели = равно 1 / среднее время жизни дисков этой партии в неделях. Тут был недавно обзор дисков от какого то хостера — там диски в среднем живут 4 года. это 200 недель то вероятность отказа P ? 0.5%.
Ну а при холодном режиме работы, как тут описывается — наверно ещё меньше.
А экономия в размере массива 60%.Chamie
15.05.2015 14:03А я опять в расчётах облажался, кстати. Теперь — для RAID1, там же 20 дисков, а не 14.
Так что вероятность отказа = 20·P2 и RAID1 надёжнее при Pотказа > ?(20/240240) ? 4.37%.
FYR
18.05.2015 12:17Вообще да это и есть аналог рейда, но только на уровне частей файлов. И размазаный по датацентру, а не на одном контроллере.

nsinreal
12.05.2015 10:46+2Насколько я понимаю изначальная цель — сделать так, чтобы при креше данных можно было восстановить файл. Поэтому если использовать коды Рида-Соломона, то размер файла увеличивается в 1.4 раза; а если делать по тупому, то размер файла увеличивается в 2 раза.
Chamie
12.05.2015 19:08-1Но если мы потеряем файл целиком, то уже не сможем его восстановить из такой «копии».
nsinreal
13.05.2015 01:49+1Не совсем.
Разбиваем файл на 10 частей, 5 частей на один жесткий диск, 5 частей на другой. Таким образом добиваемся того, что каждая часть хранится более-менее независимо и при возникновении бедов некорректные данные появляются только в некоторых, а не во всех частях.
С некорректными данными (шумами) можно бороться или избыточным дублированием или помехоустойчивым кодированием (и коды Рида-Соломона это один из вариантов такого кодирования).
Частичная утеря данных — это тоже вариант помех. Допустим мы знаем вероятность того, что может посыпаться жесткий диск абсолютно полностью. Исходя из этой вероятности и необходимой вероятности выживания медиа рассчитываем на сколько жестких дисков нужно раскидывать файл.
Чаще всего срок жизни оборудования известен, поэтому где-то перед его предпологаемой смертью можно забекапить все на следующую жертву. И скорее всего оборудование просто так не сыпется полностью, а начинает распадаться по частям — появляется все больше и больше бедов. Беды отслеживаются, данные восстанавливаются, данные бекапятся.
Судя по всему инженеры фейсбука грамотно рассчитали вероятности и обеспечили необходимую отказоустойчивость. Хотя схема выглядит довольно сложной, но тем не менее основана на банальном теорвере поверх сложного проверенного работающего мат. аппарата и статистики смерти жестких дисков — продажной девки имперализмаChamie
15.05.2015 12:09+1Чаще всего срок жизни оборудования известен
Известно (примерно) его математическое ожидание.

Milfgard
12.05.2015 13:20+13Что-то мне подсказывает, что переводчик-интерпретатор даже не понмал, что пишет. Технология «Бойль и Мариотт» )

Yavanosta
12.05.2015 09:28+15Не совсем понятно зачем использовать в тексте «Reed Solomon», если есть устоявшийся перевод: Код Рида — Соломона
nile1
12.05.2015 09:52+5Facebook решает проблему экономного хранения данных на всех уровнях:
— Оригинал статьи o Cold Storage code.facebook.com/posts/1433093613662262/-under-the-hood-facebook-s-cold-storage-system-
— F4 («Warm» storage для фотографий) code.facebook.com/videos/334113483447122/f4-photo-storage-at-facebook-scale-presentation
— Haystack («Hot» storage для фотографий) www.facebook.com/notes/facebook-engineering/needle-in-a-haystack-efficient-storage-of-billions-of-photos/76191543919
crea7or
12.05.2015 13:46Он ещё их пережимает до практически непотребного уровня. Причём даже png пережимает в jpg.

boblenin
12.05.2015 10:11+7Наводит на мысль о потенциальных DDoS использующих такие особоенности инфраструктуры.

splav_asv
12.05.2015 12:22Так в худшем случае пострадают «холодные» данные. Почти никто и не заметит.
Можно разве что искусственным подбором обращений к редким данным добиться снижения ресурса дисков за счет постоянных остановок-раскруток.boblenin
12.05.2015 15:19+1Я скорее думаю о том, что делая целью холодные данные — их можно слегка подогреть, создав доп. фин. рассходы которых компания так сильно старалась избежать.
JuniorIL
12.05.2015 12:03+4Хм, быть может мне стоит поудалять данные с фейсбука, гугл драйва и прочих сервисов облачного хранения данных во имя окружающей среды?

amarao
12.05.2015 13:03+16В литературе код Рида-Соломона обычно переводится, а не spelling 'as is', because it is much easer to stop translate anything and just switch to the default language.
DjOnline
12.05.2015 15:43+7Отвратительный перевод.
Перевожу на русский: «мы включили парковки головки диска, и перешли с RAID1 на RAID5/6».
dj_raphael
12.05.2015 17:05+1Я думал они горячий контент стали раздавать через p2p. Для видео уже вроде кто-то сделал. Вот думал и до фоточек добрались.
DjOnline
12.05.2015 17:50Нет, так только VK делал для видео и только на Flash, сейчас это вроде как выключено.

altman
неплохо придумано. Вообще, технология применима, как мне кажется, к большинству контента в сети, наверняка к этому так или иначе придут все крупные корпорации