

Сегодня мы хотим рассказать, как оцифровывали издания Национальной библиотеки Латвии. Если вы следите за нашим блогом, вы наверняка читали, как наши технологии помогают оцифровать литературное наследие разных библиотек, а также статьи, посвященные отдельным проектам — оцифровке в Сахалинской библиотеке, королевском ботаническом саду Эдинбурга и библиотеке Хартли. Сегодня история о том, как это было в Риге. Итак, Национальная библиотека Латвии – крупнейшая в стране, основана в 1919 году, обладает 4,5-миллионным собранием книг и документов, в том числе на латышском языке в уникальном готическом написании.
С XVI века запись всех текстов велась готическим шрифтом, подтверждение тому – старейшие памятники печати на латышском языке: католический Катехизис П. Канизия (Вильнюс, 1585) и Малый Катехизис М. Лютера (Кенигсберг, 1586). Готический шрифт использовался для записи латышского языка вплоть до ХХ века. Самое интересное, что он отличался от привычного многим (и уже знакомого нам) немецкого языка в готическом исполнении.


Изначально планировалось обработать материалы, которые физически повреждены или популярны среди читателей, либо считаются исторически важными. Они должны были быть «спасены», по крайней мере, в цифровом виде. Примерный объем работ составлял 2,5 тыс. страниц периодических изданий, что равно около 1000 самих изданий и 1,5 млн. страниц книг – это примерно 7000 штук.
История знакомства
К моменту нашего знакомства библиотека уже сотрудничала с компанией-поставщиком услуг по оцифровке, которая, в свою очередь, использовала OCR-технологии ABBYY. Но распознать сканы не получалось – проблемы была в том, что наши технологии не могли правильно «увидеть» латышскую готику, поскольку не были обучены таким символам. Тогда библиотека обратилась в ABBYY.
Готическое распознавание
К тому времени наш ABBYY FineReader Engine уже поддерживал готический шрифт, но латышская готика отличалась от схожей и известной нам немецкой. Чтобы научить продукт новому шрифту, пришлось добавить много новых символов.
От библиотеки нам пришел пакет изображений. Вот так выглядит часть первого пакета.


Мы взяли небольшую часть изображений из этого пакета и разделили её на две базы: обучающую, по которой обучаются графемы, и тестовую, с которой мы сверяем правильность распознавания. Графема – это конкретный способ графического представления символа. Отношение между символами и графемами достаточно сложное – в европейских языках одной графеме может соответствовать несколько символов (маленькая «с» и большая «С» в латинице и кириллице – это все одна графема), а одному символу может соответствовать несколько графем (буква «a» в разных шрифтах может быть обозначена разными графемами).

Мы добавляем графемы, а дальше для каждой графемы с помощью классификаторов (у нас их несколько, например, омнифонтовый, контурный и растровый – о работе классификаторов мы подробно писали здесь) подбираются векторы признаков, так чтоб множество изображений этой графемы разбилось на группы (кластеры), внутри каждой из которых все изображения максимально похожи друг на друга и одновременно изображения из разных групп были максимально не похожи. Таким образом можно вычислить базовую уверенность в том, что встретившийся при распознавании текста символ является какой-то графемой (он будет принадлежать к определенному кластеру этой графемы с некой уверенностью).
На случай, если для одного и того же изображения при распознавании нашлось несколько вероятных вариантов, составляются дифференциальные пары. Это пары разных графем, которые, похожи между собой и, соответственно, могут быть перепутаны. Для таких пар выделяют разные признаки, с помощью которых их можно было бы различать.
Некоторые из них показаны ниже.
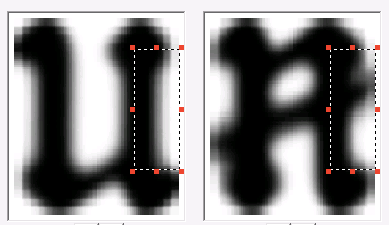
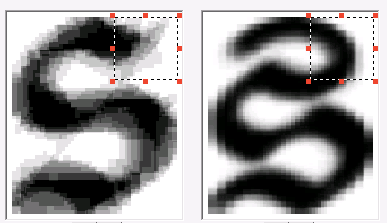
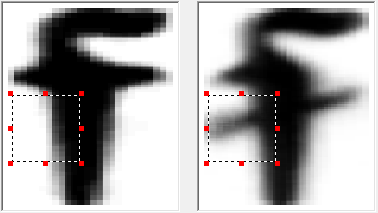
После того, как описаны все признаки и программа на тестовом пакете изображений показывает меньше 5% ошибок (точность в 95% вообще достаточна для того, чтобы считать, что в первом приближении язык мы поддерживаем хорошо), работу по добавлению шрифта можно считать законченной. Всего мы добавили 39 символов. Мы сделали версию FineReader Engine с новым шрифтом и отправили в библиотеку. Чуть позже нам прислали ещё один пакет изображений – в нём встречались символы, которых не было в первом пакете. И все началось заново – конечно, по объему новые вводные оказались меньше, все равно технологию пришлось «доучивать».
Изменения неизбежны
Наконец FineReader Engine с поддержкой готики в латышском написании был готов. Когда мы отправили его клиенту, выяснилось, что библиотека перестала сотрудничать с прежним поставщиком услуг по оцифровке. Для нас это означало, что встроить наш SDK в конечный продукт, который должен был распознавать книги, теперь некому. Нам ничего не оставалось, кроме как переделать Engine в конечный продукт – в результате за один день мы сделали приложение, которое брало все изображения из одной папки и складывало результат распознавания в заданном формате в другую папку – очень сильно упрощённый аналог ABBYY Recognition Server. Тем временем руководство библиотеки искало замену компании, предоставляющей услуги по оцифровке и обслуживанию библиотечного ПО. Выбор пал на немецкую компанию CCS, которая уже работала с нашими продуктами и технологиями. Им было достаточно просто встроить уже готовый Engine с готическим шрифтом в свою систему и начать работу.
И, как это принято в подобных историях, — немного статистики под конец. Чуть больше года потребовалось для обработки 4 миллионов страниц древних книг и современных изданий. В пиковые периоды проекта 60 операторам сканирования и верификации приходилось работать по три восьмичасовые смены ежедневно.
Цифровые версии книг Национальной библиотеки Латвии вы можете найти на сайте www.periodika.lv.
Комментарии (19)

Shultc
18.05.2016 13:34Национальная библиотека Латвии – крупнейшая в стране, основана в 1919 году
На кдпв изображено новое здание библиотеки, построенное пару лет назад. Так называемый «Замок Света». Не путайте людей, в 1919 у нас такое бы не построили…
expeon
18.05.2016 16:41+1Библиотека-учреждение и библиотека-здание — две разные вещи. В данный момент учреждение находится в Замке Света, не вижу путаницы.
Shultc
18.05.2016 13:41+1Вот смотрю я на ваши сканы… А где все гарумзими? Латышские тексты обычно ими кишат.

ernt
18.05.2016 14:34+2Правописание довольно сильно поменялось в начале XX века. Сравните третью строчку на третьем скриншоте: «schee wilkahs Schlesija eekscha un gribbeja to» с современным «sie vilkas Slezija ieksa un gribeja to» (точнее, Silezija, но это уже не про буквы). Если правильно понимаю, в готическом написании гарумзиме ставились только на концах слов в локативе, в середине же обходились добавлением «h» после гласной. В то же время букв со знаками смягчения («n», «k») в том же тексте полно.
ernt
18.05.2016 15:42+2Немало материалов также было отредактированно (поправлено) вручную, сайт-каталог periodika.lv даёт возможность отредактировать оцифрованный материал.
Например самый активный пользователь Aigars Liepins сделал 6086 изменения, а вообще вот топ изменений http://periodika.lv/#userTops;content=editors;timeRange=allTime

sanja1989
18.05.2016 17:52+1А с чуть более современным латышским разбирались? Я оцифровывал несколько документов 40-х годов. Тогда использовались буквы, которых уже нет сейчас и в шрифтах я их не смог найти. К примеру, есть брошюра «ТРИ ГОДА ОТЕЧЕСТВЕННОЙ ВОЙНЫ СОВЕТСКОГО СОЮЗА (военные и политические итоги).» 1944 года на латышском и в ней используется мягкая буква «R» (с запятой под ней, как "K"). Возможно есть шрифты в которых такие буквы можно найти?
ernt
18.05.2016 17:56+2Вообще, ради этих двух букв я как-то раз и сделал letters.ernt.lv. Ну, делал ради этих, но слегка увлёкся…


Dmitry_4
18.05.2016 17:52Интересно, когда услуги распознавания книг начнут предоставлять на каждом углу. Я бы перевел домашнюю библиотеку в цифру, многие книги уже просто не купить.
APXAHGEL
18.05.2016 17:52А можете дать ссылочку где хорошо описан омнифонтовый классификатор? И ещё про дифференциальный не совсем понял, зона с отличиями для близких символов жёстко прописывается? И что, собственно, дальше с этой зоной делают?

TonyMas
18.05.2016 18:53+1В нашем же блоге была пара статей про устройство нашего распознавания.
Первая часть и вторая часть. Вам нужна больше вторая часть. Только омнифонтовый классификатор там назван байесовским, чтобы быть более приближенным к стандартной терминологии.
У нас есть несколько классификаторов, построенных следующим образом: выбираем много (порядка сотни) базовых признаков, собираем из них вектор, объявляем такие вектора нашим пространством признаков и строим на них байесовский классификатор
Это как раз про омнифонтовый классификатор (в самой статье сильно больше написано).
Про устройство дифференциального классификатора там тоже отдельный раздел, название в этом случае совпадает :)
roboter
Просто для интереса, а сторонняя компания может сделать сама поддержку новых графем, или всё завязано на вас?
luciana
Вы имеете в виду сделать сама поддержку и интегрировать с нашим продуктом?
roboter
сделать поддержку без интеграции, используя SDK
luciana
Растровый классификатор можно обучать пользовательским эталонным изображениям символов. В продукте (ABBYY FineReader Engine) это называется User Patterns Training.
Позволяет обучить OCR в общем случае произвольному изображению какого-либо символа или группы символов.
Есть ограничения:
• Шрифт и условия сканирования при обучении и распознавании должны совпадать. Никакой «омнифонтовости».
• Китайский, корейский и японский языки не имеют такой возможности.
• Встроенный механизм деления на символы должен довольно надежно отделять целевую графему от прочих.