

Популярность языка программирования Си трудно переоценить, особенно вспоминая его былые заслуги. Наверное, каждый разработчик, как минимум, знает о его существовании, и, как максимум, пробовал на нем программировать. Си является предшественником таких языков, как C++, Objective-C, C#, Java.
Компания Microsoft для разработки родного языка к своей платформе .Net выбрала именно Си-подобный синтаксис. Более того, на Си написано множество операционных систем.
Конечно, Си не идеален: создатели языка – Кен Томпсон и Деннис Ритчи – долгое время дорабатывали его. Стандартизация Си продолжается до сих пор. Он существует более 45 лет и активно используется.
С ним часто ассоциируют не один, а два языка программирования — C/C++. Однако ниже речь пойдет именно о «чистом» Си.
Язык Си восходит корнями к языку ALGOL (расшифровывается как ALGorithmic Language), который был создан в 1958 году совместно с комитетом Европейских и Американских учёных в сфере компьютерных наук на встрече в Швейцарской высшей технической школе Цюриха. Язык был ответом на некоторые недостатки языка FORTRAN и попыткой их исправить. Кроме того, разработка Си тесно связана с созданием операционной системы UNIX, над которой также работали Кен Томпсон и Деннис Ритчи.
UNIX
Проект МАС (Multiple Access Computer, Machine-Aided Cognition, Man and Computer) начался как чисто исследовательский в MIT в 1963 году.
В рамках проекта МАС была разработана операционная система CTSS (Compatible Time-Sharing System). Во второй половине 60-х было создано несколько других систем с разделением времени, например, BBN, DTSS, JOSS, SDC и Multiplexed Information and Computing Service (MULTICS) в том числе.
Multics – совместная разработка MIT, Bell Telephone Laboratories (BTL) и General Electric (GE) по созданию ОС с разделением времени для компьютера GE-645. Последний компьютер под управлением Multics выключили 31 октября 2000 года.
Однако BTL отошел от этого проекта еще в начале 1969 года.
Некоторые его сотрудники (Кен Томпсон, Деннис Ритчи, Стью Фельдман, Дуг МакИлрой, Боб Моррис, Джо Оссанна) захотели продолжить работу самостоятельно. Томпсон работал над игрой Space Travel на GE-635. Ее написали сначала для Multics, а потом переписали на Фортране под GECOS на GE-635. Игра моделировала тела Солнечной системы, а игроку надо было посадить корабль куда-нибудь на планету или спутник.
Ни софт, ни железо этого компьютера не годились для такой игры. Томпсон искал альтернативу, и переписал игру под бесхозный PDP-7. Память была объемом 8К 18-битных слов, и еще был процессор векторного дисплея для вывода красивой для того времени графики.

Изображение с сайта slideshare.net
Томпсон и Ритчи полностью вели разработку на кросс-ассемблере на GE и переносили код на перфолентах. Томпсону это активно не нравилось, и он начал писать ОС для PDP-7, начиная с файловой системы. Так появилась UNIX.
Томпсон хотел создать комфортабельное вычислительное окружение, сконструированное в соответствии с его дизайном, используя любые доступные средства. Его замыслы, что очевидно оглядываясь назад, вбирали в себя многие инновации Multics, включая понятие процесса как основы управления, древовидную файловую систему, интерпретатор команд в качестве пользовательской программы, упрощённое представление текстовых файлов и обобщённый доступ к устройствам.
PDP-7 UNIX также положил начало высокоуровневому языку B, который создавался под влиянием языка BCPL. Деннис Ритчи сказал, что В — это Си без типов. BCPL помещался в 8 Кб памяти и был тщательно переработан Томпсоном. В постепенно вырос в С.
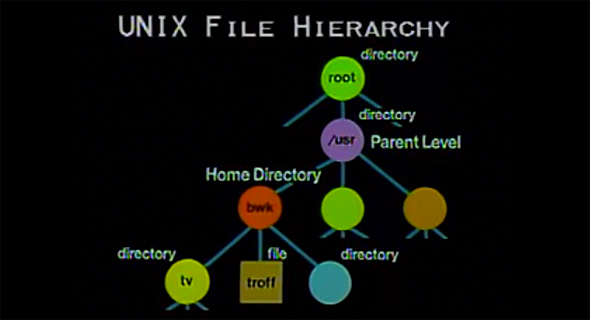
Изображение с сайта it-world.com
К 1973 году язык Си стал достаточно силён, и большая часть ядра UNIX, первоначально написанная на ассемблере PDP-11/20, была переписана на Си. Это было одно из самых первых ядер операционных систем, написанное на языке, отличном от ассемблера.
Получается, что Си – это «сопутствующий продукт», полученный во время создания операционной системы UNIX.
Прародители Си
Вдохновлённые языком ALGOL-60, Математическая лаборатория Кембриджского Университета совместно с Компьютерным отделом Лондонского университета создали в 1963 году язык CPL (Combined Programming Language).
Язык CPL посчитали сложным, и в ответ на это Мартином Ричардсоном был создан в 1966 году язык BCPL, основное предназначение которого заключалось в написании компиляторов. Сейчас он практически не используется, но в своё время из-за хорошей портируемости он играл важную роль.
BCPL использовался в начале 1970-х в нескольких интересных проектах, в числе которых — операционная система OS6 и частично в зарождающихся разработках Xerox PARC.
BCPL послужил предком для языка Би (B), разработанного в 1969 в уже знакомой всем AT&T Bell Telephone Laboratories, не менее знакомыми Кеном Томпсоном и Деннисом Ритчи.
Как и остальные операционные системы того времени, UNIX был написан на ассемблере. Отладка программ на ассемблере настоящая мука. Томпсон решил, что для дальнейшей разработки ОС необходим язык высокого уровня и придумал небольшой язык B. За основу Томпсон взял язык BCPL. Язык B можно рассматривать как C без типов.
Во многих деталях BCPL, B и C различаются синтаксически, но в основном они похожи. Программы состоят из последовательности глобальных деклараций и объявлений функций (процедур). В BCPL процедуры могут быть вложенными, но не могут ссылаться на нестатические объекты определённые в содержащих их процедурах. B и C избегают такого ограничения, вводя более строгое: вложенных процедур нет вообще. Каждый из языков (за исключением самых древних версий B) поддерживает раздельную компиляцию и предоставляет средства для включения текста из именованных файлов.
В противоположность повсеместному изменению синтаксиса, которое происходило во время создания B, основная семантика BCPL — его структура типов и правила вычисления выражений — осталась нетронутой. Оба языка — безтиповые, вернее имеют единственный тип данных — «слово» или «ячейка», набор битов фиксированной длины. Память в этих языках — массив таких ячеек, а смысл содержимого ячейки зависит от операции, которая к ней применяется. Например, оператор "+" просто складывает свои операнды при помощи машинной инструкции add, и другие арифметические операции также безразличны к смыслу своих операндов.
Ни BCPL, ни B, ни C не выделяют в языке символьные данные; они считают строки векторами целых чисел и дополняют общие правила несколькими соглашениями. И в BCPL, и в B строковый литерал означает адрес статической области инициализированный символами строки упакованными в ячейки.
Как создавался Си
В 1970 Bell Labs приобрела для проекта компьютер PDP-11. Так как B был готов к работе на PDP-11, Томпсон переписал часть UNIX на B.
Но модель B и BCPL подразумевала издержки при работе с указателями: правила языка, определяя указатель как индекс в массиве слов, делали указатели индексами слов. Каждое обращение к указателю при исполнении генерировало масштабирование указателя в адрес байта, который ожидал процессор.
Поэтому становилось ясно, что для того, чтобы справиться с символами и байтовой адресацией, а также подготовиться к грядущей аппаратной поддержке вычислений с плавающей точкой, нужна типизация.
В 1971 году Ритчи начал создавать расширенную версию B. Сначала он назвал её NB (New B), но когда язык стал сильно отличаться от B, название сменили на C. Вот что, писал об этом сам Ритчи:
Я хотел, чтобы структура не только характеризовала абстрактный объект, но и описывала набор бит, который мог быть прочитан из каталога. Где компилятор смог бы спрятать указатель, наname, которого требует семантика? Даже если бы структуры были бы задуманы более абстрактными, и место для указателей могло бы быть спрятано где-нибудь, как бы я решил техническую проблему корректной инициализации этих указателей при выделении памяти для сложного объекта, возможно структуры содержащей массивы, которые содержат структуры, и так до произвольной глубины?
Решение состояло в решительном скачке в эволюционной цепочке между безтиповым BCPL и типизированным C. Он исключал материализацию указателя в хранилище, а вместо этого порождал его создание, когда имя массива упоминалось в выражении. Правило, которое сохранилось и в сегодняшнем C, состоит в том, что значения–массивы, когда они упоминаются в выражении, конвертируются в указатели на первый из объектов, составляющих этот массив.
Второе нововведение, которое наиболее ясно отличает C от его предшественников, — вот эта более полная структура типов и особенно её выразительность в синтаксисе деклараций. NB предлагал основные типы int и char совместно с массивами из них и указателями на них, но никаких других способов скомпоновать их.
Требовалось обобщение: для объекта любого типа должно быть возможным описать новый объект, который объединяет несколько таких объектов в массив, получает его из функции или является указателем на него.
Изображение из книги «Язык Си»: M. Уэйт, С. Прата, Д. Мартин
Для любого объекта такого составного типа, уже был способ указать на объект, который является его частью: индексировать массив, вызвать функцию, использовать с указателем оператор косвенного обращения. Аналогичное рассуждение приводило к синтаксису объявления имён, который отражает синтаксис выражения, где эти имена используются. Так
int i, *pi, **ppi;объявляет целое, указатель на целое и указатель на указатель на целое. Синтаксис этих объявлений отражает тот факт, что i, *pi, и **ppi все в результате дают тип int, когда используются в выражении. Похожим образом
int f(), *f(), (*f)();объявляют функцию, возвращающую целое, функцию возвращающую указатель на целое, указатель на функцию возвращающую целое;
int *api[10], (*pai)[10];объявляют массив указателей на целое, указатель на массив целых.
Во всех этих случаях объявление переменной напоминает её использование в выражении, чей тип – это то, что находится в начале объявления.
70-е годы: «смутное время» и лже-диалекты
Язык к 1973 стал достаточно стабилен для того, чтобы на нём можно было переписать UNIX. Переход на C обеспечил важное преимущество: переносимость. Написав компилятор C для каждой из машин в Bell Labs, команда разработчиков могла портировать на них UNIX.
По поводу возникновения языка Си Питер Мойлан в своей книге «The case against C» пишет: «Нужен был язык, способный обойти некоторые жесткие правила, встроенные в большинство языков высокого уровня и обеспечивающие их надежность. Нужен был такой язык, который позволил бы делать то, что до него можно было реализовать только на ассемблере или на уровне машинного кода».
C продолжил развиваться в 70-х. В 1973–1980-х годах язык немного подрос: структура типов получила беззнаковые, длинные типы, объединение и перечисление, структуры стали близкими к объектам–классам (не хватало только нотации для литералов).
Первая книга по Cи. Книга «Язык программирования Си», написанная Брайаном Керниганом и Деннисом Ритчи и опубликованная в 1978 году, стала библией программистов на Си. При отсутствии официального стандарта эта книга – известная также как K&R, или «Белая Книга», как любят называть поклонники си – фактически стала стандартом.

Изображение с сайта learnc.info
В 70-х программистов на Cи было немного и большинство из них были пользователями UNIX. Тем не менее, в 80-х Cи вышел за узкие рамки мира UNIX. Компиляторы Cи стали доступны на различных машинах, работающих под управлением разных операционных систем. В частности, Си стал распространяться на быстро развивающейся платформе IBM PC.
K&R ввёл следующие особенности языка:
• структуры (тип данных struct);
• длинное целое (тип данных long int);
• целое без знака (тип данных unsigned int);
• оператор += и подобные ему (старые операторы =+ вводили анализатор лексики компилятора Си в заблуждение, например, при сравнении выражений i =+ 10 и i = +10).
K&R C часто считают самой главной частью языка, которую должен поддерживать компилятор Си. Многие годы даже после выхода ANSI Cи он считался минимальным уровнем, которого следовало придерживаться программистам, желающим добиться от своих программ максимальной переносимости, потому что не все компиляторы тогда поддерживали ANSI C, а хороший код на K&R C был верен и для ANSI C.
Вместе с ростом популярности появились проблемы. Программисты, писавшие новые компиляторы брали за основу язык, описанный в K&R. К сожалению, в K&R некоторые особенности языка были описаны расплывчато, поэтому компиляторы часто трактовали их на своё усмотрение. Кроме того, в книге не было чёткого разделения между тем, что является особенностью языка, а что особенностью операционной системы UNIX.
После публикации K&R C в язык было добавлено несколько возможностей, поддерживаемых компиляторами AT&T, и некоторых других производителей:
• функции, не возвращающие значение (с типом void), и указатели, не имеющие типа (с типом void *);
• функции, возвращающие объединения и структуры;
• имена полей данных структур в разных пространствах имён для каждой структуры;
• присваивания структур;
• спецификатор констант (const);
• стандартная библиотека, реализующая большую часть функций, введённых различными производителями;
• перечислимый тип (enum);
• дробное число одинарной точности (float).
Ухудшало ситуацию и то, что после публикации K&R Си продолжал развиваться: в него добавлялись новые возможности и из него вырезались старые. Вскоре появилась очевидная необходимость в исчерпывающем, точном и соответствующем современным требованиям описании языка. Без такого стандарта стали появляться диалекты языка, которые мешали переносимости – сильнейшей стороне языка.
Стандарты
В конце 1970-х годов, язык Си начал вытеснять BASIC, который в то время был ведущим в области программирования микрокомпьютеров. В 1980-х годах он был адаптирован под архитектуру IBM-PC, что привело к значительному скачку его популярности.

Разработкой стандарта языка Си занялся Американский национальный институт стандартов (ANSI). При нём в 1983 году был сформирован комитет X3J11, который занялся разработкой стандарта. Первая версия стандарта была выпущена в 1989 году и получила название С89. В 1990, внеся небольшие изменения в стандарт, его приняла Международная Организация Стандартизации ISO. Тогда он стал известен под кодом ISO/IEC 9899:1990, но в среде программистов закрепилось название, связанное с годом принятия стандарта: С90. Последней на данный момент версией стандарта является стандарт ISO/IEC 9899:1999, также известный как С99, который был принят в 2000 году.

Среди новшеств стандарта С99 стоит обратить внимание на изменение правила, касающегося места объявления переменных. Теперь новые переменные можно было объявлять посреди кода, а не только в начале составного блока или в глобальной области видимости.
Некоторые особенности C99:
• подставляемые функции (inline);
• объявление локальных переменных в любом операторе программного текста (как в C++);
• новые типы данных, такие, как long long int (для облегчения перехода от 32- к 64-битным числам), явный булевый тип данных _Bool и тип complex для представления комплексных чисел;
• массивы переменной длины;
• поддержка ограниченных указателей (restrict);
• именованная инициализация структур: struct { int x, y, z; } point = { .y=10, .z=20, .x=30 };
• поддержка однострочных комментариев, начинающихся на //, заимствованных из C++ (многие компиляторы Си поддерживали их и ранее в качестве дополнения);
• несколько новых библиотечных функций, таких, как snprintf;
• несколько новых заголовочных файлов, таких, как stdint.h.
Стандарт С99 сейчас в большей или меньшей степени поддерживается всеми современными компиляторами языка Си. В идеале, код написанный на Си с соблюдением стандартов и без использования аппаратно- и системно-зависимых вызовов, становился как аппаратно- так и платформенно-независимым кодом.
В 2007 году начались работы над следующим стандартом языка Си. 8 декабря 2011 опубликован новый стандарт для языка Си (ISO/IEC 9899:2011). Некоторые возможности нового стандарта уже поддерживаются компиляторами GCC и Clang.
Основные особенности С11:
• поддержка многопоточности;
• улучшенная поддержка Юникода;
• обобщенные макросы (type-generic expressions, позволяют статичную перегрузку);
• анонимные структуры и объединения (упрощают обращение ко вложенным конструкциям);
• управление выравниванием объектов;
• статичные утверждения (static assertions);
• удаление опасной функции gets (в пользу безопасной gets_s);
• функция quick_exit;
• спецификатор функции _Noreturn;
• новый режим эксклюзивного открытия файла.
Несмотря на наличие стандарта 11 года, многие компиляторы до сих пор не поддерживают полностью даже версии C99.
За что критикуют Си
У него достаточно высокий порог вхождения, что затрудняет его использование в обучении в качестве первого языка программирования. Программируя на Си, нужно учитывать множество деталей. «Будучи рождён в среде хакеров, он стимулирует соответствующий стиль программирования, часто небезопасный, и поощряющий написание запутанного кода», пишет Википедия.
Более глубокую и аргументированную критику высказал Питер Мойлан. Он посвятил критике Си целых 12 страниц. Приведем пару фрагментов:
Проблемы с модульностью
Модульное программирование на языке Си возможно, но лишь в том случае, когда программист придерживается ряда довольно жестких правил:
• На каждый модуль должен приходиться ровно один header-файл. Он должен содержать лишь экспортируемые прототипы функций, описания и ничего другого (кроме комментариев).
• Внешней вызывающей процедуре об этом модуле должны быть известны только комментарии в header-файле.
• Для проверки целостности каждый модуль должен импортировать свой собственный header-файл.
• Для импорта любой информации из другого модуля каждый модуль должен содержать строки #include, а также комментарии, показывающие, что, собственно, импортируется.
• Прототипы функций можно использовать только в header-файлах. (Это правило необходимо, поскольку язык Си не имеет механизма проверки того, что функция реализуется в том же модуле, что и ее прототип; так что использование прототипа может маскировать ошибку «отсутствия функции» — «missing function»).
• Любая глобальная переменная в модуле, и любая функция, кроме той, что импортируется через header-файл, должны быть объявлены статическими.
• Следует предусмотреть предупреждение компилятора «вызов функции без прототипа» (function call without prototype); такое предупреждение всегда нужно рассматривать как ошибку.
• Программист должен удостовериться в том, что каждому прототипу, заданному в header- файле, соответствует реализованная под таким же именем в том же модуле неприватная (т.е. нестатическая в обычной терминологии Си) функция. К сожалению, природа языка Си автоматическую проверку этого делает невозможной.
• Следует с подозрением относиться к любому использованию утилиты grep. Если прототип расположен не на своем месте, то это, скорее всего, ошибка.
• В идеале программисты, работающие в одной команде, не должны иметь доступа к исходным файлам друг друга. Они должны совместно использовать лишь объектные модули и header-файлы.
Очевидная трудность в том, что мало кто будет следовать этим правилам, ибо компилятор не требует их неукоснительно соблюдать. Модульный язык программирования по меньшей мере частично защищает хороших программистов от того хаоса, который создают плохие программисты. А язык Си этого сделать не в силах.

Изображение с сайта smartagilee.com
Проблемы с указателями
Несмотря на все достижения в теории и практике структур данных, указатели остаются для программистов настоящим камнем преткновения. На работу с указателями приходится значительная часть времени, расходуемого на отладку программы, и именно они создают большинство проблем, осложняющих ее разработку.
Можно различать важные и неважные указатели. Важным в нашем понимании считается указатель, необходимый для создания и поддержания структуры данных.
Указатель считается неважным, если он не является необходимым для реализации структуры данных. В типичной программе на языке Си неважных указателей намного больше, чем важных. Причины тому две.
Первая состоит в том, что в среде программистов, использующих язык Си, стало традицией создавать указатели даже там, где уже существуют иные ничем не уступающие им методы доступа, например, при просмотре элементов массива.
Вторая причина — правило языка Си, согласно которому все параметры функций должны передаваться по значению. Когда вам нужен эквивалент VAR-параметра языка Паскаль или inout- параметра языка Ada, единственное решение состоит в том, чтобы передать указатель. Этим во многом объясняется плохая читаемость программ на языке Си.
Ситуация усугубляется, когда бывает необходимо передать важный указатель в качестве входного/выходного параметра. В этом случае функции надо передать указатель на указатель, что создает затруднения даже для самых опытных программистов.
Си – жив
Согласно данным на июнь 2016 года, индекс TIOBE, который измеряет рост популярности языков программирования, показал, что C занимает 2 место:

Пусть кто-то скажет, что Си устарел, что его широкое распространение — следствие удачи и активного PR. Пусть кто-то скажет, что без UNIX язык Си никогда бы не создали.
Тем не менее, Си стал своего рода стандартом. Он, так или иначе, прошел испытание временем в отличие от многих других языков. Си-разработчики до сих пор востребованы, а создателей языка IT-сообщество вспоминает добрым словом.
Комментарии (142)

Ivan_83
24.06.2016 15:45+2Указатель на указатель сложно для чтения/понимания!?
куда катится этот мир…
iroln
24.06.2016 16:13+8Мир катится в сторону увеличения надёжности и безопасности ПО. Чтобы понапрасну не отстреливать себе и другим ноги, руки и другие важные части тела.
Ivan_83
24.06.2016 17:11+8Ну вот опять.
Вполне очевидно что при использовании оружия нужно его направлять на цель а не на себя.
Если при использовании оружия или даже инструмента человек колечит себя то это означает что он не соблюдал технику безопасности/инструкцию по использованию то почему когда речь заходит о Си сразу предлагают заменить оружие на палку из пенопласта?
Не ужели не понятно что это не эквивалентный обмен?
Если ещё не понятно скажу прямо: мне язык… не нужен, я на нём ничего не напишу из того что мне нужно, либо это будет не оправданно долго и трудоёмко.
Я не хочу забивать медведя на охоте пенопластовой палкой, я хочу его пристрелить пока он меня не порвал.
2 myxo:
По идее там сложного нет, если знать как оно внутри устроено.
Вероятно сложности у тех у кого базовых знаний не хватает, и в таком случае они не могут понять что рекурсия ограничена стёком потому что не знают что это такое.
Но с указателями вроде проще: это адрес на кусок памяти.
Указатель на указатель: адрес на кусок памяти где записан адрес другого куска памяти. Термины вроде совсем бытовые и доступные, в отличии от стёка.iroln
24.06.2016 17:50+8По идее там сложного нет, если знать как оно внутри устроено
Но с указателями вроде проще: это адрес на кусок памяти.
На низком уровне это может быть очевидно, но код с указателями на указатели, с указателями на функции и т. п. нечитабельный и сложный для разбора и понимания человеком, потому что это не просто "адрес на адрес на кусок памяти" — это то, над чем построены структуры данных, то над чем работают алгоритмы, связанные между собой в единую систему, работу которой надо понимать в целом. Это то же самое, что сказать про сложный часовой механизм "это просто шестерёнки, они просто крутятся".Ivan_83
24.06.2016 18:57+1Читабельность — дело привычки.
Притом для меня читабельность при непривычном форматировании падает сразу, не зависимо от того что там.
Я когда то вполне себе читал и писал на асме, а временами ещё и в машинные коды переводил по памяти.
Указатели на функции выглядят также как и просто функции, разницы особой нет, так чтобы восприятие проседало.
Указатели на указатели читаются легко.
Короче, хватит натягивать «я ниасилил» на весь остальной мир.
Кому нужно — пишут и оно работает, остальные гундят про то какие есть замечательные языки которые думают за них.iroln
24.06.2016 19:25+4Короче, хватит натягивать «я ниасилил» на весь остальной мир.
Не знаю, как в вашем мире, но в остальном мире общепризнанно, что указатели являются опасным инструментом, поэтому в современных языках их использование сведено к минимуму и/или сделано более безопасным. Все эти умные люди, которые разработали современные языки тоже "ниасилили" указатели? Не знаю как вам, а мне смешно.Ivan_83
24.06.2016 20:46+7Кухонный нож, опасная бритва, спички — тоже опасные. Общепризнанно. Автомобили называют средством повышенной опасности.
Мне глубоко всё равно что они там делают и думают, у меня есть своё мнение и свои дела.
Про указатели.
Нет никакой сложности, всё используется просто и прозрачно.
Если сильно не хакать и включить максимальные варнинги компелятор предупредит заранее о всех местах где перепутали указатель с указателем на указатель.
Вы свои личные аспекты восприятия языка/кода на остальных не распространяйте.
Да, Си требует внимания к мелочам, и иногда имеет смысл для высокоуровневой логики использовать другие языки.
Плюсы можно сказать уже отдельный язык, в другой нише. С тем же успехом можно говорить о том, кто портировал свой код в любой другой язык поэтому переписал всё указатели на что то ещё.
Всё страшилки которые вы пишите про указатели в Си которые типа приводят к багам имеют вообще очень мало общего с реальностью, это вам скажет любой здесь присутствующий с опытом кодинга на Си больше года.
bay73
24.06.2016 21:48+6опасная бритва, спички — тоже опасные. Общепризнанно.
Да, общепризнано, и поэтому в большинстве мест их не используют, а заменяют более безопасными аналогами, которые справляются не хуже. А используют только там, где достойной замены нет.
То же самое и с языками программирования. Подавляющее большинство задач с успехом решается «безопасными» языками без использования возможностей C. И использовать C для таких задач при наличии безопасных аналогов достаточно глупо. А вот в тех местах, где достойных аналогов нет надо, несомненно, пользоваться C, несмотря на проблемы с «отстреленными ногами».

snuk182
24.06.2016 22:02+4Извините, но не общепризнано ни разу. Тем более что явно или неявно, но они используются везде, и при написании более-менее сложного приложения все равно с концепцией указателя нужно знакомиться и считаться.

NeoCode
24.06.2016 19:04+9Что сложного в понятии «указатель на указатель»? Адрес ячейки памяти, в которой лежит адрес какого-то другого объекта. Гиперссылка на страничку в интернете, на которой написана другая гиперссылка — уже на интересную статью на Хабре.
Я вот тут изучаю PHP (после 15 лет C/C++), это боже мой — как можно жить, не объявляя переменные? Ну ладно слабая типизация, фиг с ней. Но без объявлений… любая опечатка — и у тебя новая переменная, а ты даже не догадываешься. Вот где сложность! А Си — простой язык.iroln
24.06.2016 19:20+7Что сложного в понятии «указатель на указатель»?
Да ничего сложного нет в низкоуровневом понятии указателя! Вы серьёзно сейчас пытаетесь мне рассказать, что такое указатель на указатель?
Сложен код сам по себе, который их использует, сложен для восприятия и понимания в целом, в контексте программы, потому что нужно помнить о низкоуровневых аспектах, которые не относятся к предметной области решаемой задачи.NeoCode
24.06.2016 19:42-1Если честно, то я не очень понимаю разницу между понятием «указатель на указатель» самим по себе и понятием «указатель на указатель» в контексте сколь угодно сложной программы :)

Alex_ME
24.06.2016 21:44+5Легко понять, что такое указатель на указатель, да хоть указатель на указатель на… на указатель. Проблема в том, что чем больше указателей содержит код, особенно если есть арифметика указателей, то тем больше вероятность допустить где-то ошибку: обратиться по неправильному указателю, привести к неправильному типу, обратиться к NULL, к не обнуленному указателю.
Сама по себе концепция указателя проста. И есть правила — "не направляй оружие на себя", но случайно его можно нарушить. И они нарушаются, тысячами программистов, и они обстреливают ноги, и дебажат, дебажат.
Поэтому и появляются языки с управляемым кодом, умные указатели, владение из RUST и прочие методы, призванные как-то это дело упростить.
Ivan_83
24.06.2016 22:31-3Ещё раз повторяю: проблем с указателями очень мало. И как правило они легко дебажатся.
Гораздо сложнее дебажить разные выходы за границы, неправильные размеры на области памяти в разных mem*() и пр функциях где передаётся размер вместе с указателем.
Повторное освобождение памяти, использование после освобождения, нарушения совместного доступа. Особенно в многопоточных прогах.
Ещё хуже когда ты написал алгоритм а он не работает. Вроде всё правильно но не работает. А потом при пошаговой отладке выясняется что это бага компилятора и инстрикт возвращает совсем не то. Мир просто рушится. но это редко бывает.

EyeGem
25.06.2016 12:01Проблемы с указателями, как и с целостным кодированием, всегда по недомыслию. И в плохом порядке кодирования. Если писать код строго придерживаясь простых правил, вытекающих друг из друга, то проблем исчезающе мало. Каких правил? Разнообразных контрактов использования и владения структурами данных. Они как бы неявные, но если приложить мысль и абстрактное мышление, то выводятся на счёт раз и далее используются на-автомате. Только поняв эти особенности можно и следует писать код. И это так для любого языка программирования.
Если кратко — следует ПОЛНОЦЕННО соблюдать ОО т.е. область определения аргументов и собственных данных при кодировании любой функции (в т.ч. с учётом контракта) и блоков кода, а также постоянно учитывать ОДЗ т.е. область допустимых значений данных после вычислений и преобразований. Указатель лишь частный случай. Если «программист» не способен полноценно соблюдать ОО и учитывать ОДЗ, но какой язык ему не дай, будет лишь обезьяна с гранатой.splav_asv
25.06.2016 13:24+1Rust как раз именно это проверяет сам. Другое дело что обезьяна просто плюнет и выберет другую гранату после 120-ой ошибки компиляции.
Ivan_83
25.06.2016 13:32Руста можно сказать что вообще ещё нет.
splav_asv
25.06.2016 13:46Я бы согласился, но тогда получится, что я 90% кода пишу на несуществующем языке.
Ivan_83
25.06.2016 20:58-3Сочувствую :)
Как язык он ещё не сформировался.
Поддерживаемых платформ мизер.
Проектов на нём практически нет.
И далеко не факт что оно вообще взлетит и будет как то использоваться.
DarkEld3r
27.06.2016 10:49Как язык он ещё не сформировался.
И в чём это проявляется?Ivan_83
27.06.2016 16:24Слишком мало времени прошло.
Скорее всего что то ещё будет добавляться, что то уйдёт.
Опять же, либ оч мало: https://habrahabr.ru/post/303976/
для си их на порядок больше только живых, а с мёртвыми и закрытыми ещё больше.
Декларируемые решения проблем с многопоточностью часто на си решаются просто адекватным дизайном, когда потоки очень мало общаются и делают это через специальные механизмы.DarkEld3r
27.06.2016 16:30Скорее всего что то ещё будет добавляться, что то уйдёт.
Дык, и в С++ кое-что депрекейтяд и новое добавляют. Обратную совместимость после 1.0 пообещали ведь.
Относительно либ: было бы странно, если у языка с сорокалетней историей их было бы меньше. Ну то есть, да, это "проблема", но очевидная. И тут уже надо смотреть есть ли нужные либы или нет и насколько затратно писать если что. Даже при таких условиях в дропбоксе кое-что на расте решили написать.
EyeGem
26.06.2016 04:30+1Rust делает больше, чем C/C+, позволяя автоматизировать соблюдение некоторых контрактов. Не идеально, конечно, но вполне удобно. Только вот чего такого сложного в самостоятельном понимании и соблюдении контрактов? По опыту работы с программистами на C++ считаю, что они либо забивают на качество и продуманность своего кода, либо недопонимают что должен делать или делает их код. «Ленятся лениться.» Пропускают состояния, путаются в вариантах, недообрабатывают частные случаи. И таких много, очень много. Корректный код на любом языке умеют писать, похоже, считанные единицы, которых действительно можно назвать программистами. Остальные постоянно фейлят. Почему так?
splav_asv
26.06.2016 07:16-1Ключевое слово опыт. Его надо где-то набрать. И если набирать его на том же С++, то 1) подопытный становится обезьяной с гранатой, 2) работу статического анализатора берет на себя reviewer(превращающийся в няньку), 3) учиться, наступая на грабли и отлавливая потом баги долго и выматывает(это если нет хорошего старшего). Может это конечно лучше запоминается в таком виде, но иметь альтернативу как минимум не плохо.
А после всего этого — да, это не сложно. И всё же глупые ошибки делают с той или иной периодичностью все.EyeGem
28.06.2016 14:58Все три пункта зависят от включенности мозга в работу. Не просто памяти, логики и интуиции, но также и критического мышления. Есть такой подход — осторожное разумное исследование неизвестной территории с опорой на самые надёжные методы и постоянной перепроверкой их надёжности. Требует адаптировать ассоциативную память под как можно более быстрые и полные (с учётом деталей) выборки и синтез вариантов решения для каждого случая. Делается выборка/синтез из N разносторонних вариантов, далее мысленно проверяется насколько каждый подходит для решения. Отбраковываются неподходящие, адаптируются подходящие, выбирается лучший. Далее ищется M подтверждений что этот вариант действительно лучший из всех N. Замечу, что именно разносторонний N даёт качественный эффект. Постоянно вижу как программисты используют 1 вариант который привычен или первым пришёл в голову. Но ведь задача программиста не сделать «как-нибудь», а сделать в т.ч. качественно т.е. способ решения тоже имеет значение.
DarkEld3r
27.06.2016 10:53-1Только вот чего такого сложного в самостоятельном понимании и соблюдении контрактов?
Именно вот эта "самостоятельно" (то есть "постоянно и вручную") часть и "сложна". В том плане, что даже если есть понимание и опыт, то всё равно можно наступить на грабли: невнимательность, отвлекли, да мало ли что. Конечно, с опытом проблемы находить и исправлять становится проще, особенно при помощи разнообразных тулзов типа статических анализаторов.
Собственно, всё что делает раст — это выносит часть контрактов на уровень языка. По моему, это очень здорово и удобно.
Ну и как бонус в языке есть другие "мелкие приятности".EyeGem
28.06.2016 15:05-1Вопрос в том стоит ли переходить на другой язык только ради некоторых улучшений?
Лично моё мнение что скорее стоит доработать C++, добавив механизмов для описания и автоматического или полу-автоматического соблюдения важных контрактов разного уровня (от указателей до схем работы модулей). И тут получается, что Rust выступает как полигон для обкатки подобных механизмов.
Ну ещё очень хочется нормальной поддержки сериализации =)DarkEld3r
29.06.2016 12:10Стоит или нет — зависит от обстоятельств. При всей любви к языку, не стал бы предлагать переписывать наш проект — просто из-за того, что это огромная потеря по времени. Опять же, у нас имеется достаточно опытных разработчиков и процесс отлажен: обязательное ревью, постоянная сборка и запуск тестов на разных платформах, валгринд и т.д. При всём этом, кстати, проблемы всё равно иногда всплывают. (:
С другой стороны, если начинать новый проект, то раст вполне может оказаться хорошим выбором. Насколько я знаю, именно так и получилось в дропбоксе: они честно сказали, что будь у них готовая инфраструктура на С++, то на нём и писали бы. Но её не было и они выбрали раст и довольны.
Да, многие штуки в плюсы можно добавить в том или ином виде. Но тут у раста есть преимущество (которое является и недостатком, ага) в виде отсутствия легаси. Фичи проще прикручивать в нормальном виде, а не думать как их добавить так, чтобы ничего не поломать. Если в С++ завезут паттерн матчинг или нормальные макросы и модули, то это всё равно вынуждено будет жить параллельно с тем, что уже есть.
А с сериализацией что не так?
EyeGem
01.07.2016 00:53Да хочется чего-то элементарного и простого, без магий, с автоматической поддержкой только для тех типов к которым может быть обращение и при этом полностью отдельно от самих данных. При этом шаблоны тоже нужно поддерживать через определение списка типов при инстансировании шаблонов. Либо для явно указанных типов при динамическом способе доступа (по имени), если таковой поддерживать.
for ( auto field : AnyType:::Fields ) // AnyType:::Fields.size(), etc.
{
// field.offset, field.size, field.type, field.ToString(obj), field.FromString(obj)
}
for ( auto method : AnyType:::Methods ) // ...
{
// method.Call(obj), method.ToString(), method.FromString()
}
DynType:::BuildMetaData;
void foo()
{
BaseType:::DynamicDerivedType derivedType( "DynType" );
// derivedType.Fields(), derivedType.Methods()
}
Можно вместо ::: любой другой подходящий символ для доступа к метаданным. Синтаксис для добавления поддержки для динамических типов тоже может другой, конечно же.

FreeMind2000
24.06.2016 19:33+8«почему когда речь заходит о Си сразу предлагают заменить оружие на палку из пенопласта?»
— Скорее не на палку из пенопласта, а на самонаводящиеся ракеты со встроенной защитой от суицидальных наклонностей прогеров :) Поэтому прогеры больше не думают о самосохранении и как там внутри эти ракеты устроены, просто выбрал цель, нажал кнопку и… задача решена :)
Быстро с точки зрения разработки, безопасно и очень удобно, но… мозги у таких прогеров почему-то превращаются в кашу при виде конструкции «указатель на указатель», поэтому такие вещи объявляются «опасными». А если выбранная цель движется слишком быстро для их самонаводящихся ракет, то конечно же, самое очевидное решение — сменить процессор на более быстрый и продолжать жить в своем простом и безопасном мирке. Настоящие же джедаи своим световым мечем пользуются филигранно и виртуозно, поэтому все конечности у них всегда на своем месте и даже самые быстрые цели всегда получают свой еще более быстрый и выверенный удар :)iroln
24.06.2016 20:00+3мозги у таких прогеров почему-то превращаются в кашу при виде конструкции «указатель на указатель», поэтому такие вещи объявляются «опасными»
Вы преувеличиваете, существует множество вещей, на порядок более сложных чем какие-то указатели. Я уверен, ни у кого, кто пишет свои программы на Си, мозги в кашу от указателей не превращаются, но это не значит, что те люди не делают ошибки в своих программах. Мозги, при написании программы, должны думать не об указателях, а о предметной области. А, во-вторых, тот, кто, скажем, начинает писать на том же C++, с удовольствием заменяет все свои сырые указатели на умные и прекрасно себя чувствует. Минимальный оверхед при многих плюсах. И ведь гораздо приятнее просто держать свои мозги в тонусе, не давая им превратиться в кашу, думая об сложных и интересных проблемах и новых подходах к решению этих проблем, чем о том, что снова надо вылавливать эти странные баги, которые появились, возможно, из-за тех самых звёздочек. :)FreeMind2000
24.06.2016 21:53«Вы преувеличиваете, существует множество вещей, на порядок более сложных чем какие-то указатели.»
Именно об этом и речь, «какие-то указатели» читаются/пишутся на автомате, и только там где они уместны, поэтому проблем из-за звездочек не бывает — это всего-лишь синтаксис, который нужно знать. Звездочки никак не отвлекают от понимания кода, и проблем предметной области. Основная причина ошибки на любом языке — это невнимательность. И самонаводящиеся ракеты эту невнимательность развивают, превращая элементарные ** для некоторых в непонятную/опасную кашу.

Vadius
24.06.2016 22:02-1Тут, наверное, вопрос больше в перспективности такого подхода, чем в споре «хорошо или плохо применять сырые указатели».
Начинающий на С++, использующий умные указатели, несомненно, освободит мозг для лучшего обдумывания функциональности, но с набором квалификации всё равно возникнет вопрос: изучать ли сырые указатели и повышать производительность своего софта (например, когда 95% операций в нагруженной программе проводятся с динамическими объектами, даже минимальный оверхед на интеллектуальные обёртки даёт себя знать) или же остаться в уютном мире относительно медленного ПО и не думать о том, как программа работает на низком уровне.
Поэтому речь о вылове странных багов при повышении квалификации в С++ всё равно возникнет. А насчёт опасности указателей… да, вы верно отметили, что все делают ошибки, так что это всего лишь вопрос дисциплины и внимательности, а не врождённое свойство технологии. За всё, в т.ч., производительность, надо чем-то платить.

semenyakinVS
26.06.2016 02:26Мозги, при написании программы, должны думать не об указателях, а о предметной области
Вот мне кажется, что в этом предложении выявлено зерно развернувшейся дискуссии. С вступает в дело именно там, где эффективность реализации, либо необходимость работать близко к железу (тобишь, там, где есть необходимость мыслить об указателях) превалирует над важностью передачи мыслей о предметной области. И мне кажется, что именно эту мысль пытается донести Ivan_83. Каждый инструмент хорош для своих задач. Нужна простота написания кода? Пишите на Java. Нужна эффективность — пишите на С.
Все языки хороши, у всех есть своя ниша для использования. Мне всегда были непонятны эти холливары по поводу того, какой язык хуже или лучше без чёткого определения области использования языка.
П.С.: Кстати, если уж тут пошёл батл Java vs C (достаточно странный батл, на мой взгляд) никто не мешает делать обвязки API через JNI и получить с одной стороны красоты Java в высокоуровневой организации архитектуры, и, с другой стороны, высокую эффективность программы в реализациях подключаемых С-шных библиотек.Ivan_83
27.06.2016 15:15-1На си тоже можно писать высокоуровневый код, не парясь особо с выделениями памяти и прочим: для этого нужно заюзать подходящую либу.
Например OpenCV, код что на си что на питоне не сильно будет отличатся, и даже производительность будет сходная, если свалить всю обработку на на саму либу.
Примерно также с FFMpeg: там тоже куча готовых обработчиков, знай только передавай им данные да параметры.
При этом всякие вебстранички всё же на си делать не удобно, от части потому что нет (или я не знаю потому что не интересуюсь) подходящих либ.
Проще взять тот же PHP и за пару минут накидать там пару строк, даже если не знать его.
Холивары они от того что области применимости часто перекрываются, и тут кому что удобнее.
snuk182
24.06.2016 23:47+3В случае Rust на оружие навешано кучу проверок типа есть ли патрон, а куда ты собрался стрелять, а как правильно ты прицеливаешься, а как ты держишь оружие, а одел ли ты шапку, а покушал ли перед выстрелом, и все такое. Вы все еще думаете, что указатели это страшно и сложно? ))
asdf87
26.06.2016 08:16И если ты не покушал, то он (Rust) не кормит тебя, а дает тебе возможность самому решить как это лучше сделать. В итоге и сыт, и мозг в тонусе, и ноги целы!.. Это ли не счастье? ))
snuk182
29.06.2016 12:06-2А не дает.
На каждую подзадачу у Раста есть ровно один способ решения, соответствующий его парадигме разработки. Это не плохо и дисциплинирует, с одной стороны, но с другой — резко повышает порог вхождения в язык.DarkEld3r
29.06.2016 12:13Почему резко повышает? По моему, "один способ" работает наоборот — просто используешь его, а не выбираешь между кучей вариантов "сделать это".
Ну и про "ровно один способ" относительно раста тоже можно поспорить. (:
snuk182
29.06.2016 19:44Этот один способ еще надо знать, он не так очевиден. К примеру, каст к трейту пишется через одно место, довольно странным способом через энумы. Парень, пытавшийся реализовать DI, со спецификой абстракций в расте воевал довольно долго.
DarkEld3r
30.06.2016 10:25+1Так ведь при наличии многих способов тоже можно ни один не знать. Или узнать один, не самый подходящий, и пытаться его применить не подозревая, что есть более удобные варианты. Если же способ один, то его нагуглить, по идее, проще. Остальное — издержки молодости языка. Со временем будет больше литературы, ответов на стековерфлоу и т.д.
Насчёт каста к трейту не совсем понял в чём проблема:
trait T {} struct S {} impl T for S {} let s = S{}; let t: &T = &s;
Ну и то, что новый язык предлагает другие абстракции и старые не ложатся напрямую — это нормально, как по мне. Вон в недавней рассылке проскакивала статья с мыслью, что если "условный джавист" возьмётся за раст, то будет ожидать от языка сложностей и они будут. А если возьмётся "условный плюсовик", то будет думать, что всё должно быть просто: ведь со всякими низкоуровневыми нюансами он знаком. Но нет, сложности тоже будут — ведь язык другой.
Не уверен, что полностью согласен, но что-то в этом есть. Лично мне раст не показался особо сложным, если не брать всякие навороты из растономикона. На "базовом уровне" всё нормально. "Проблемы" были разве что с "принятием" — в том смысле, что "непривычно".snuk182
30.06.2016 10:59Непривычно — да, совершенно согласен. Даже не скажу, что плохо или не очевидно, просто неожиданно.
Про касты я имел в виду вот такое
https://stackoverflow.com/questions/26126683/how-to-match-trait-implementorsDarkEld3r
30.06.2016 11:23Ну это каст из трейта. (:
Всё-таки в языке структуры и трейты связаны не через традиционное наследование, так что не удивительно, что обратно перейти нельзя. Да, может быть неудобно, но это повод пересмотреть архитектуру.
Кстати, если мы точно знаем, что в трейте лежит конкретный объект, то можно извернуться через raw::TraitObject, но надо понимать, что это не dynamic_cast и если мы в своём предположении ошиблись, то будет плохо.
snuk182
30.06.2016 16:45Если реализация трейта скрыта, то не знаем (это мой случай). Есть еще transmute, но он небезопасный и тоже работает только с объектами.
DarkEld3r
30.06.2016 17:21Дык, если реализация скрыта, то тем более странно приводить к ней, разве нет?
snuk182
01.07.2016 01:52Есть иерархия интерфейсов с одним родителем. На вход поступает неизвестная имплементация родительского типа, и надо ее кастнуть к более узкоспециализированному интерфейсу без необходимости раскрытия имплементации.

FFormula
25.06.2016 14:08+1Сложно/просто — это второй вопрос.
На первый план на сегодняшний день, всё-таки, выходит безопасность архитектуры.
Именно поэтому язык Java первый в списке рейтинга, любая написанная на нём
программа может извне ограничиваться в своих возможностях.
С другой стороны, для некоторых задач такой язык, как Си — более удобный,
потому что позволяет создавать быстрые, короткие и эффективные программы.Ivan_83
25.06.2016 16:04-21. Есть куча способов ограничить возможности программы со стороны ОС.
Даже в венде начиная с 2к есть песочницы (АПИ), до 2к были только манипуляции с ACL в SID процесса (или как то так, когда можно забрать у программы даже возможность писать файлы и ходить по диску).
В не винде ограниченные учётки, chroot, jail.
2. Джава тормозная и громоздкая, на десктопе и серверах у меня нет ни одной проги на джаве и я постараюсь чтобы не было.
3. Даже моя дырявая память помнит инциденты обхода/побега из песочницы за последние лет 5.
Касательно рейтинга.
Мне не очень понятно почему джава оказалась сверху, возможно куча народу где то на ней пишут какой то SAP который обычные люди в жизни никогда не видят.
Питон, пхп, перл я вижу гораздо чаще.
Может кто то из тех 20% перепутал джаву и джаваскрипт, тогда оно становится более понятно.semenyakinVS
26.06.2016 02:35+1Насколько я понимаю (сам плюсовик, не имевший опыта с embded, могу ошибаться), Java такая популярная за счёт простоты языка и широты спектра устройств, на которых умеет запускаться — от детской машинки до шагающих экскаваторов. Тут можно сказать, что С так же умеет компилироваться под те же миллионы разных устройств… Но в С есть указатели на указатели (с), которые для простой задачи типа «написать гую для банкомата» (на эффективность кода пофигу — мы на банкомате не будем Навье-Стокса решать) действительно могут сделать написание кода необоснованно сложным.
khim
26.06.2016 14:32+2Java такая популярная за счёт PR. В своё время её продвигал Sun, #1 на рынке UNIX-систем. Соответственно весь enterprise, который не остался на мэйнфреймах подсел на Java. На Windows, правда, Java «не пошла», там её брат-близнец C# рулит.
Качество самого языка в таких вопросах — дело десятое. Всё решают дяди, которые сами, в общем, ничего не пишут — но дальше начинает раскручиваться спираль: раз у нас упор на Enterprise, то это значит что у нас работают 100500 «индусов», которые ни черта не понимают в программировании (так как у нас ограничен не общий фонд заработной платы, а размер «ставки», то нанять 100 крутых профессионалов мы не можем, а 10000 индусов — как раз можем), дальше под это начинают затачиваться все инструменты и так — пока язык не окажется малопригоден для использования кем-либо, кроме вот этой вот самой толпы «индусов».
Ещё есть, немного сбоку, Android: там, с одной стороны, есть Java (чтобы, опять-таки, привлечь «индусов»), а с другой — все популярные программы написаны не на Java (в них нативные библиотеки, где, как раз и происходит всё самое интересное). Так и живём.semenyakinVS
26.06.2016 17:06+2нанять 100 крутых профессионалов мы не можем, а 10000 индусов — как раз можем
пока язык не окажется малопригоден для использования кем-либо, кроме вот этой вот самой толпы «индусов»
Ну так правильно. Дело вовсе не в PR, а именно в том, что на Java могут писать эти самые десять тысяч индусов. На С та же тима написала бы код, который валился бы от каждого чиха. Поэтому менеджеры выбирают Java.
Дисклеймер об индусахДабы не кормить стереотип, подчеркну: тут речь идёт не о всяких индусах, а о низкоквалифицированных работниках из Индии. Частенько индусы — весьма башковитые прогеры. Однажды, например, я проходил course era по openGL… Курс вёл индус. И это не единственный пример, когда обитатели полуострова индостан показывали класс.khim
27.06.2016 00:24+3Дело вовсе не в PR, а именно в том, что на Java могут писать эти самые десять тысяч индусов.
Дело именно в PR. Вначале Java была «продана» как что-то, на чём можно писать большие проекты — но из этого не вышло ровным счётом ни-че-го: почитайте на досуге о судьбе HotJava, Corel Office for Java, Network Computer… Про Java-applet'ы, в конце-концов, вспомните…
Однако признаться в том, что деньги были вбуханы в чушь собачью было страшно и потихоньку-полегоньку Java превратилась-таки «в суп из топора». Лет примерно через 10 начали появляться большие непровальные проекты типа Eclipse (переписанный на Java IBM Visual Age), IntelliJ и прочих, со временем для «индусов» всё и приспособили.semenyakinVS
29.06.2016 21:12Ну, любой язык переживает период становления, когда проекты на нём не взлетают. Приведённые примеры неудач отображают, скорее, не проблемы языка как такового, а проблемы его экосистемы, которая рождалась в муках.
Если я правильно понимаю, Java создавался как такой язык, что:
1. Код, написанный на Java, мог исполняться кроссплатформенно.
2. При написании кода на Java программист не обязан вручную контролировать память — что делает написание кода на Java более комфортным (ценой некоторых потерь быстродействия).
Если я правильно понимаю (если нет — интересно было бы глянуть на тогдашних конкурентов), Java оказался языком, создатели которого успели первыми реализовать описанные полезные и востребованные рынком особенности. И именно за счёт этого Java должна была «выстрелить» рано или поздно. В самом крайнем случае появился бы другой язык, который реализовывал бы описанные две киллер-фичи Java, но категорически лучше чем она.
Перефразируя известную фразу — если бы Java не было, её стоило бы придумать. Поэтому-то я и считаю, что (в меру моего понимания истории языка) PR послужил не главным фактором триумфа Java и приведённые примеры ничего не доказывают.khim
29.06.2016 22:56+3Если я правильно понимаю (если нет — интересно было бы глянуть на тогдашних конкурентов), Java оказался языком, создатели которого успели первыми реализовать описанные полезные и востребованные рынком особенности.
Ага, конечно. А как же P-код, Smalltalk, Lisp-машины и прочее?
И именно за счёт этого Java должна была «выстрелить» рано или поздно.
В том-то и дело, что в Java не было никаких «прорывов». Java была первым языком, создателям которого которым удалось убедить крупную компанию вбухать деньги в технологию, которая, в конечном итоге, эту самую фирму и похоронила — это да. А чисто технологически — всё это перепевки вещей, которые были придуманы задолго до того, как Sun решил покончить жизнь самоубийством.
В самом крайнем случае появился бы другой язык, который реализовывал бы описанные две киллер-фичи Java, но категорически лучше чем она.
Этих языков — как грязи. И до Java и после. Lisp — это даже не 60е, а 50е годы (правда самый конец), CLOS и Smalltalk — 80е. Но только одному из конкурентов посчастливилось получить сравнимую поддержку — C# (кстати забавно что результат сравним: Microsoft оказался покрепче, чем Sun, к банкротству увлечения архитектурной астронавтикой не привели, но мобильный рынок в результате был успешно профукан).
Перефразируя известную фразу — если бы Java не было, её стоило бы придумать.
Зачем? Чтобы превратить VisualAge в Eclipse?
Поэтому-то я и считаю, что (в меру моего понимания истории языка) PR послужил не главным фактором триумфа Java и приведённые примеры ничего не доказывают.
Они бы «ничего не доказывали бы», если был бы хоть один «выстреливший» проект, рождённый в первые 2-3 года после появления Java, когда все ВУЗы переходили на неё (кто с Lisp'а, а кто и со Smalltalk'а). Но нет ни-че-го. Совсем ничего. Все успешные проекты на Java — это либо проекты переведённые на Java «декретом» (с сегодняшнего дня мы вместо Cobol'а/Smalltalk'а используем Java), либо разработки середины нулевых годов (когда Java было уже много лет и в её развитие вбухали много миллионов долларов). Много из этих проектов вы знаете? А ведь это — 1999й год, когда Java уже преподавалась в ВУЗах и когда уже несколько лет объяснялось, что «Java — это будущее»!
Согласитесь — несколько странная ситуация для языка, который якобы «выехал за счёт своих качеств», а не за счёт PR?semenyakinVS
29.06.2016 23:24Ух, спасибо за столь подробный ответ! И если Lisp ещё не совсем проходит как «С для быдлокода» (функциональное программирование мне всегда казалось изотериков), то Smalltalk… Виртуальная машина, сборка мусора… Не знал всего этого. Спасибо. Теперь убедили.
П.С.: Кстати, материал выглядит как синопсис остросюжетной статьи о становлении императора Java в мире программирования. Если бы не опасность породить холливар — с удовольствием почитал бы «полный метр» по мотивам.DarkEld3r
30.06.2016 10:33Lisp довольно условно функциональный, особенно по нынешним меркам. Там есть и ООП и запросто можно императивный код писать. Нет заморочек с побочными эффектами как в хаскеле, нет (в Common Lisp) сопоставления с образцом из коробки и т.д. Синтаксис — да, непривычный.
semenyakinVS
30.06.2016 12:59Ну, я имел в виду Lisp тех бурных времён творения современного прогерского мира, когда он мог выступать конкурентом Java на её поле — безопасный по работе с памятью, кроссплатформенный и простой для понимания язык… Или в Lisp с самого начала был задуман как мультипарадигменный язык, поддерживающий и функциональную и объектноориентированную парадигмы?
DarkEld3r
30.06.2016 13:23+2Могу что-то упускать, но Java появилась в 1995 году. Common Lisp стандартизирован в 1994, появился ещё раньше. CLOS (грубо говоря, ООП-часть языка) в стандарт вошла.
Как по мне, язык этот в плане функциональной парадигмы не сильно от современного С++ ушёл. И то из-за того, что в плюсах, скажем, лямбды более громоздко выглядят из-за необходимости не забывать про низкоуровневое предназначение языка. В языке есть циклы, мутабельные данные, побочные эффекты и т.д.
Может код на нём и пишут/писали больше в функциональной парадигме, но язык не заставляет.
А ещё у Common Lisp с тех пор новых стандартов не было. Да, реализации вносят что-то новое, но в основном, в виде функций, библиотек и т.д. То есть можно сейчас взять книгу "Practical Common Lisp" (кажется) 2003 года и посмотреть как было на тот момент.
khim
30.06.2016 21:17+1В языке есть циклы, мутабельные данные, побочные эффекты и т.д.
Главное что в нём есть — это рефлексия. По большому счёту развитие Java и C# медленно и со скрипом движется в направлении реализации фич, которые существуют в Lisp'е уже не одно десятилетие.
Например задумайтесь над вопросом: что должно произойти с уже существующими объектами, если программа изменит стуктуру класса, который их описывает? Ни Java, ни C# до этой стадии ещё не дошли (может в какой-нибудь верии 20.0 доберутся) — а книжка которая обсуждает и решает эту проблему для Lisp'а появилась в 1991м году.
А ещё у Common Lisp с тех пор новых стандартов не было.
Да — это большая проблема. Есть много реализаций, но они довольно заметно «разъехались».DarkEld3r
30.06.2016 22:47что должно произойти с уже существующими объектами, если программа изменит стуктуру класса, который их описывает?
Вроде как, в erlang на эту тему что-то есть, но я с языком, к сожалению, не особо знаком. Но вообще это может решаться и другими методами. Скажем, если у нас сервис по многим нодам размазан, то мы можем спокойно вырубать часть для обновления. И даже есть смысл какое-то время оставлять параллельно две версии на случай если в новой что-то плохо пойдёт. Да и нужно оно не везде — скажем в каком-нибудь десктопном приложении без этого прожить не сложно.
А насчёт того, что в языке главную, как мне кажется, мнения разойдутся. Кто-то будет рассказывать насколько неполноценно ООП без мультиметодов, а меня больше всего привлекали макросы.
Ну и мне больше по душе статическая типизация, так что периодически продолжаю (typed) racket ковырять. Тем более, что схема вообще больше на "строгости" акцент делает.
khim
30.06.2016 23:19Но вообще это может решаться и другими методами.
Ну это-то понятно. В конце-концов вся современная электроника — это сложные, многоуровневые, конструкции из кучки ячеек памяти и стралеки Пирса.
Да и нужно оно не везде — скажем в каком-нибудь десктопном приложении без этого прожить не сложно.
Да, но какой ценой? Никогда не приходилось перезагружать компьютер после установки обновления? А почему, собственно, это нужно делать? Вот именно потому что обновить программу «на лету» нельзя! 40 лет назад для оригинала — это проблемой не было, а сегодняшние подделки — иначе не умеют! Я не говорю, что это — прям катастрофа, без этого жить нельзя. Но… неудобно. Да и опасно: всякие критические системы могут не обновляться месяцами из-за этого, что, как бы, явно не делает наш мир лучше и безопаснее.
P.S. Только не надо думать, что я предалагаю взять и перейти всем на Lisp. Боже упаси. То же отсутствие статической типизации — далеко не всегда достоинство. Я просто хочу показать что многие вещи, которые там появились многие десятилетия назад в «прогрессивных», «новых» языках — до сих пор не реализованы.DarkEld3r
01.07.2016 00:14А почему, собственно, это нужно делать?
Справедливости ради: линукс, вроде, умеет обновляться и без перезагрузки и это без использования лиспа. Да и в целом меня это не особо напрягает, особенно в рамках отдельных программ — они как правило хотят всего-лишь перезапуска, а не рестарта системы целиком.
С другой стороны, лисп мог бы оставаться лиспом и со статической типизацией. А в новых языках упор на другое. Искать что-то прорывное в мейнстриме и правда не стоит, но обкатанные решения туда постепенно попадают.
khim
01.07.2016 11:59Справедливости ради: линукс, вроде, умеет обновляться и без перезагрузки и это без использования лиспа.
Не умеет. Новые библиотеки оказываются на диске, но запущенные процессы продолжают использовать старые. Есть, правда, Ksplice который пытается «что-то такое» сделать, но у него куча ограничений.
Да и в целом меня это не особо напрягает, особенно в рамках отдельных программ — они как правило хотят всего-лишь перезапуска, а не рестарта системы целиком.
Ну да, это не конец света — просто показывает, что проблема, на самом деле, есть и она довольно-таки неприятна (и с увеличением сложности программ и частотой выхода новых версий становится всё острее: одно дело 90е, когда «заплатки» выходили два-три раза в год, другое — сейчас, когда они уже чуть не каждый день выходят).
Искать что-то прорывное в мейнстриме и правда не стоит, но обкатанные решения туда постепенно попадают.
Одно дело, когда туда попадают решения, которые только-только обкатали где-нибудь в академиях, другое — когда туда возвращаются вещи, уже бывшие мейнстримом лет 30-40 назад…
С другой стороны, лисп мог бы оставаться лиспом и со статической типизацией.
Только работать с ним стало бы гораздо сложнее. Вы метапрограммы на C++ писали? Вот это — почти что «Lisp со статической типизацией»… сложный он. И часто нелогичный…vinograd19
10.11.2016 13:00Не до конца понял идею.
У меня есть два яблока: красное и зеленое. Красное я кладу в коробку и закрываю коробку. Через минуту я открою коробку, но уже сейчас я знаю, что я точно увижу там красное яблоко. Это тоже путешествие во времени?
khim
30.06.2016 21:04Или в Lisp с самого начала был задуман как мультипарадигменный язык, поддерживающий и функциональную и объектноориентированную парадигмы?
Во времена, когда Lisp был создан ещё не было ни той, ни другой парадигмы. Lisp использовался для того, чтобы их изобрести :-) А также для того, чтобы придумать современный GUI, мышь и многое другое. Вот только тяжёл он был для тех лет — машинки стоили самолёт. А насчёт «мультипарадигменности»… когда в языках появляются всякие «суперфичи» типа expression trees и реализованной «поверх них» LINQ — то в среде лисперов обычно возникают только дискуссии по типа «мы это имели уже в 60х годах или всё-таки только в 70х?».
А основная беда Lisp'а (особенно современных диалектов типа Scheme) — в том что он очень «математический», что ли. Почему-то у людей подход с кучей явно выраженных парадигм вызывает меньше проблем, чем когда одно решение используется для всего (начиная с той же префиксной записи математических выражений).
alex86_m6
24.06.2016 16:15+2Если программировал на ASM для DEC PDP-11 то ничего сложного :-)
Впрочем С и вырос из системы команд DEC PDP-11

myxo
24.06.2016 16:28+2да, довольно сложно. Говорю как преподаватель, когда начинаешь изучать программирование, 2 самые сложные темы — рекурсия и указатели.
IIvana
25.06.2016 04:08+1А, вот оно оказывается как… Не моноиды в категории эндофункторов, не эндоморфизмы под композицией, не замыкания/продолжения/корутины, не комбинаторы неподвижной точки при нормальном и аппликативном порядке редукции и не море всего другого — а вызовы функций и адреса ячеек памяти — самые сложные темы!..
MacIn
25.06.2016 15:07+1Вы совершенно зря доводите до абсурда аргумент о сложности указателей, сводя его к «неспособности понять концепцию адреса ячейки памяти». Это не говоря о том, что в ВУЗе (моем, например) сначала изучается Си, во 2 или 3 семестре, если я правильно помню, а на 4м курсе — ассемблер, организация ЭВМ — то, что дает ту самую концепцию «адреса ячейки». Но бог с ним, проблема не в самой концепции, а в сложночитаемом синтаксисе, на мой взгляд. И я не о простом «указатель на инт», а об указателе на массив или массив указателей и т.п.
У многих ли языков синтаксис неудобоварим настолько, что пишутся статьи вида «как читать type declaration» или сайт-переводчик
http://cdecl.org/
Можно говорить о том, что такие конструкции есть только потому, что язык позволяет их создать, и тут уж вопрос рук программиста. Но тому, кто будет поддерживать чужой код, от этого не легче.
MacIn
24.06.2016 21:07Понимается — элементарно, особенно для тех, кто писал на Ассемблере. Втч и более сложные структуры вида указателей на функцию, возвращающей указатель на указатель на что-то.
Но читается ровно никак. Это субъективно, да.

LynXzp
24.06.2016 22:02Не знаю, но неужели проблема именно в указателях? Мне кажется когда говорят про указатели в половине случаев имеются в виду проблемы динамического выделения памяти.
spermwhale
24.06.2016 15:52А это правда, что операторные скобки { и } вместо английских слов были введены в язык только для экономии памяти?
gmvbif
24.06.2016 16:30Тоже слышал, что раньше были текстовые редакторы, которые не могли редактировать файлы с большим количеством символов. И эти редакторы повлияли на синтаксис языка и стандартной библиотеки
MacIn
25.06.2016 00:44Ну, на PDP (во времена) были в ходу строчные редакторы, а не оконные.
Вряд ли дело в редакторе, даже оконный работает с кусками файла. Другое дело перфокарты, особенно с поколоночной набивкой.

kemiisto
24.06.2016 16:48Не памяти, а времени набора программ.
spermwhale
24.06.2016 23:42Экономия времени, надо полагать, тоже была актуальна в 70-х? Вроде программисты не машинистки.
MacIn
25.06.2016 00:45Если исходить из тезиса об экономии времени, то надо вспомнить, что в те далекие годы еще были в ходу пакетные системы.
kemiisto
26.06.2016 15:13Я не знаю, была ли эта проблема актуальна вообще, но она по какой-то причине было точно актуальна для Кена Томпсона: уже при создании языка B он стремился улучшить компактность программ за счёт уменьшения числа символов. В самом начале Users' Reference to B читаем «Because of the unusual freedom of expression and a rich set of operators, B programs are often quite compact.» Была ли у этого устремления какая-то реальная физическая причина (например, большие задержки при вводе) или это был просто «бзик» утверждать не берусь.
P.S. Хотя конкретно операторные скобки {...} были уже и в предшественнике B, языке BCPL, просто часто вместо них писали $(...$) по причине частого отсутствия кнопочек для ввода фигурных скобок на клавиатурах тех дней.

potan
24.06.2016 16:23Переносимость все-таки ограничена. На машинах, где указатели принципиально отличаются от данных и отсутствует адресная арифметика (Intel iMAX 432), реализация C затруднена.

youROCK
24.06.2016 19:52-1Перевод очень корявый. Оригинал (немного отличный от статьи) я лично нашел по одной из ссылок в статье: http://givi.olnd.ru/chist/chist.html
luarviq
24.06.2016 22:02-3K&R заложили бомбу в типобезопасность С (одну из бомб!), когда написали в стандарте 1978 года, что все операции с плавающей точкой должны проводиться с операндами двойной точности (double). Поэтому, например, следующий фрагмент кода:
float value=1.0/3.0;
if (value==1.0/3.0) printf(«equal»);
else printf(«not equal»);
стабильно выдавал «not equal», что, вероятно вызывало легкое помешательство у тогдашних программистов. Тут уже не до указателей, когда простые арифметические выражения живут своей жизнью.

MaxAkaAltmer
24.06.2016 22:57+2Константу для проверки нужно дать правильного размера:
if (value==1.0f/3.0f) printf(«equal»);
И будет «equal».
А вообще, лучше сравнивать числа с плавающей запятой с учетом погрешности, независимо от языка.luarviq
25.06.2016 12:00Да кто спорит-то? Или, еще лучше, написать double value = 1.0/3.0. Проблема-то не в том, что написать, а в стандарте языка. Зная его, безусловно, можно обойти все подводные камни. Я могу себе представить программиста 1978 года, работающего за каким-нибудь PDP-11, долго смотрящего на экран, а потом плюющего и начинающего переписывать все на старом добром ассемблере, где, можно применить, условно говоря, команду FDIV, а потом забрать значение из регистра, и спать всю ночь сном праведника.
MaxAkaAltmer
25.06.2016 20:31+2Я предложил решение, просто на какую-то бомбу это не тянет, в любом языке, который поддерживает несколько типов с плавающей запятой будет тоже самое, стандарт тут не при чем, так работает сопроцессор. Вот пожалуйста пример для Java, абсолютно то же самое:
float xxx=1.0f/3.0f;
if(xxx==1.0/3.0)xLog(«Equal»);
else xLog(«Not Equal»);
Стандарт мне тоже местами не нравится, особенно моменты известные как «неопределенное поведение». Но сам язык лично мне нравится тем, что я могу случайно отстрелить себе ногу — это да, но зато я не обязан отстреливать себе яйца. Иначе говоря, я могу выбирать и меня никто не ограничивает в средствах достижения цели.
HabrDev
25.06.2016 14:26Всегда сравниваю вещественные числа в Си с использованием макроса с константой DBL_EPSILON (или FLT_EPSILON) из float.h и ни один линтер не ругается :)
veprbl
24.06.2016 22:59Вовсе не потому:
root [1] float value = 1./3.;
root [2] value == 1./3.
(bool) false
root [3] value == 1.f/3.f
(bool) true
root [4] value == float(1./3.)
(bool) true
Дело в том к какому типу приводится левый и правый операнды оператора ==. В вашем случае к double (для избежания потери точности).
Типичный FPU, кстати, не умеет делать операции над float. Регистры x87, например, 80-битные.
Alex_ME
25.06.2016 12:05+2Тут и без этого можно ноги отстрелить, если сравнивать числа с плавающей точкой на полное равенство.

BalinTomsk
24.06.2016 22:15+1---• Следует с подозрением относиться к любому использованию утилиты grep. Если прототип расположен не на своем месте, то это, скорее всего, ошибка.
20 лет писал на С еше с PDP-11 и никогда грепом непользовался, какое он имеет отношение к языку C?myxo
24.06.2016 23:05+1Ну, например, используете вы какую-нибудь функцию, хотите посмотреть её аргументы, а она фиг знает где объявлена. Если не пишешь в IDE, то нужно грепать. Но тут действительно какой-то странный юз кейс. «Прототип объявлен не на своем месте», это действительно фигня какая-то.
third112
26.06.2016 00:10-1Забавно, что не только «С- жив», но и мамонт по кличке Кобол (последняя строчка 1ой страницы TIOBE). Видимо, не все спецы так любят новации, как пытаются убедить инноваторы :) По сравнению языков есть интересный сборник корифеев: Языки программирования: Ада, Си, Паскаль. Сравнение и оценка. М.: Радио и связь, 1989. Столько лет прошло, а до сих пор актуально :)

Morozov_5F
26.06.2016 00:58Мне не совсем понятно, почему лиспа нет в этом рейтинге, а кобол есть. Даже если по вакансиям смотреть, то у нас в городе есть несколько мест на CL, а про кобол уже никто давным-давно не слышал)
khim
26.06.2016 01:17+1Вы не поверите, но компьютеризация началась не с Воронежа, так что всё закономерно :-)
Кобол — это окомпьютеризированные в 60е годы банки, с которыми, в общем, за пределами США мало кто сталкивается (Европа докатилась до компьютеризации банков в 70е, а в других странах это произошло ещё позже), зато как раз там — сотни тысяч программистов, миллионы клерков… достаточно, чтобы попасть на 1ю страницу, пусть и на последнюю строчку.
А LISP — это для «высоколобых умников», их, в общем, никогда особо много не было.
third112
26.06.2016 02:05См. TIOBE : Lisp 28 место, далее Ада, но не самые плохие места: Пролог, нпр., на который возлагали столько надежд — 33 место, даже детский язык Лого его обогнал. А Go — вообще 48-ое. Интересно, что в начало второй страницы на 21 место Fortran переехал, который так поддерживали многие для научных вычислений (в квантовой механике, нпр.) и Интел поддерживал ;) Однако и у С/С++ тенденции к спаду.
guai
26.06.2016 00:53D подрос… и перл почему-то
Ну насчёт D ожидаемо и радует, а вот перл удивил. Интересно, как они это считают?..third112
26.06.2016 02:21Я на Perl не пишу, но когда участвовал в обсуждении рукописи книги John Levine, Linkers and Loaders, спросил автора: почему он выбрал перл для примеров? Он ответил, что эти же примеры на другом языке увеличили бы в 2-3 раза объем книги и она стала бы трудно читаемой.
third112
26.06.2016 02:40BTW А чем D хорош? Механизмом вывода типов? contract-based programming from Eiffel?
guai
26.06.2016 12:24+1Ну много чем, как и другие языки, которые целенаправлено исправляют косяки в предшественниках, которые без потери совместимости уже не поправишь. Компиляется быстрее, т.к. за один проход работает, и местами параллельно. Местами более вменяемый синтаксис, сборка мусора подавляющему большинству программ на пользу идет, более казуально можно программить, но так же и спускаться до низкого уровня не мешает. Всякие коллекции, модульность, юникод, дженерики, миксины — много всякого прикольного. С сишными либами линковааться можно, анонсировали, что и с плюсовыми можно будет, но вроде пока не допилили.
Вроде уже даже начали появляться конторы, которые всё на D пилят, игрухи какие-то…
На хабре писали…third112
26.06.2016 12:50Спасибо. Нужно будет присмотреться внимательнее к этому языку. Хотя про исправление косяков у меня очень пессимистичные впечатления. Если в целом взглянуть на последние десятилетия — то прогресс в языках тормознул: случилась в прошлом веке так называемая ОО-революция (ей предшествовали структурная и модульная революции) и больше никаких революций. Хоть и японцы 5-ое поколение обещали, другие высказывали мнения, что макросы электронных таблиц — качественно новый уровень языков программирования. Тот же Eiffel контракты предложил. Были еще всякие манифесты новых парадигм, только пока никаких революционных сдвигов, сравнимых с ООП, они не произвели.
guai
26.06.2016 13:20А может их вообще не будет больше, тех революций, так что пока довольствуемся плодами эволюции, которые, кстати говоря, тоже приносят много ништяков. Допустим, у меня революционная идея есть, каков шанс, что я ее реализую сразу в идеальном варианте? Кучу всяких идей еще состыковать надо, тут тоже налажать можно сильно :)
Мне еще нравится язык цейлон, так на его систему типов взглянешь и прибалдеешь, а вроде и интерфейсы и дженерики были до этого, и вроде никакой революции особой нет, а круто неимоверно :)third112
26.06.2016 14:10-1Может революций и не будет. Тогда софт еще больше отстанет от железа :(
Ceylon не знаю. Вики утверждает, что он со строгой статической типизацией. Это не попытка наступить второй раз на грабли Виртовского Паскаля, где была невозможна универсальная функция умножения двух матриц? ;)
third112
26.06.2016 14:23-1Может и не надо запихивать в язык максимум известного? Нпр., стрелку Пирса — достаточно других Булевых операций, чтобы реализовать эту ;)
guai
26.06.2016 15:49А чего ради ограничивать себя? Двадцать первый век на дворе, хочется же и строго типированных API, и поддержки IDE, и модульности из коробки, и поддержки тестирования, и встроенных доков, и всякого такого прочего, что и так возникнет в большом проекте, только возникнет как костыли и велосипеды энное количество раз. Да, это сложнее для разрабов языка, но я не разраб языка, я его потребитель. Пусть заморочатся один раз, а потом тысячи нас будут этой работой пользоваться.
Насчёт матриц в цейлоне не уверен, так-то он под jvm и js и нацелен на энтерпрайз, а не на числодробилки, ну и все радости jvm типа боксинга там есть, никуда от них не денешься. Ну к этому еще в яве все привыкли, в нем даже меньше внимания уделено примитивам. Но, как и в D, можно спуститься на уровень ниже, на чистой яве запилить чего-то, или даже до jni добраться…third112
26.06.2016 22:55-1Чем сложнее язык — тем больше багов окажется в его реализации, тем сложнее организовать достаточно полное тестирование. Но дело не только в разработчиках/кодерах языка и в его тестерах, но и в переносимости на другие платформы, в том числе, появившиеся уже после реализации языка. Кроме того, возрастает сложность стандартизации. Сложность изучения будет тормозить распространение языка. Это студентам хорошо, когда, помимо других предметов, на изучение какого-нибудь языка отводится целый семестр с лекциями и семинарами. Если студент не тупой лентяй, то может не торопясь вникать и разбираться. А работающему в коммерческой компании программисту обычно отводят очень сжатые сроки на изучение. И изучать он постарается не весь язык, а только то, что нужно для конкретной работы. Для больших проектов, чем сложнее и гибче язык, тем сложнее руководителю проекта установить правила написания и документирования кода. Чаще будут возникать ситуации, когда один кодер жалуется на другого, что тот пишет слишком трудно читаемый и трудно модифицируемый код. BTW C/C++ за это критиковали. В.Ш.Кауфман в одной из статей утверждает, что как бы ни старались разработчики языка и его стандартизаторы, любой язык будут содержать неоднозначности («темные места»). Количество этих неоднозначностей — один из основных параметров оценки качества языка. Исходя из общих соображений: чем сложнее язык и чем он гибче, тем больше будет неоднозначностей — ниже качество.
Что касается умножения матриц — они нужны не только в числодробилках. Например, в теории графов куча нечисленных задач с очень широким кругом приложений: от химии до интернет-технологий. Многие из этих задач решаются в том числе и матричным подходом.guai
26.06.2016 23:35так мы не в чистом поле языки выбираем, есть языки старше нас, стабильные и отлаженные. если новые недостаточно отлажены или стабильны, или их нет на нужной платформе — не обязательно за них хвататься.
иначе так и будут появляться простые/примитивные языки, которые потом обрастают легаси и их уже не поменяешь. вчера писали на руби, сегодня на ноде, завтра на го — а толку то? те же проблемы на каждой следующей платформе, ну или разный их состав.
лучше день потерять, потом за пять минут долететь :)
и не обязательно гибкость несет с собой больше сложности, тот же D субъективно проще, хотя и не менее мощный, чем плюсы.
особенно если языки пилят с прицелом на минимизацию необычности для программиста с каким-то бэкграундом.
у цейлона полторы свои необычные фичи, система типов более мощная, у всех прочих новых фич есть аналоги в других языках, а остальное вообще как в яве. именно на состыковку фич направлено было много усилий, ну и совокупный эффект виден сразу, без всяких революций.third112
27.06.2016 05:31-2Вики утверждает, что сейчас более восьми тысяч языков программирования и их число растет. Т.о. вероятность новому языку стать популярным уменьшается. Если не произойдет никаких революций, то языки скоро перестанут изобретать. М.б. это и к лучшему ;)
guai
27.06.2016 10:008000 языков, авторы которых были уверенны в их революционнсти. :) иначе зачем бы они их делали?
а вот эволюционировавших раз-два и обчелся.
я вот два знаю. оба нацелены на существующие толпы программистов, оба оставляют от предшественников, что там было и так хорошо, нацелены на продуктивность через модульность и поддержку IDE и т.п., оба целенаправлено правят косяки предшественников.
Ну еще сильно влияет, кто язык делает.
Я тоже могу свой язык запилить, тока кому он нужен будет? :)third112
27.06.2016 11:20-1Зачем делают языки — хороший вопрос. Могу предположить несколько не очевидных вариантов.В Вики есть статья «Эзотерический язык программирования» — «в качестве шутки». В большинстве универов мира препод должен заниматься научной работой. Создать язык для отчетов подойдет :) BTW были утверждения, что Си был создан в качестве шутки :)
DarkEld3r
27.06.2016 11:22А работающему в коммерческой компании программисту обычно отводят очень сжатые сроки на изучение.
Работаю "в коммерческой компании" и как-то умудряюсь новое изучать, пусть и на энтузиазме. Собственно, если настанет день когда мне будет лень этим заниматься, значит как программист я перегорел. (:third112
27.06.2016 11:34Ok. Бывает 2 случая: 1) изучать для расширения кругозора, когда никто не требует и не торопит; 2) изучать, когда срочно требуется для основной работы.
kemiisto
27.06.2016 11:43Значит, ничего принципиально нового не изучаете. Скажем, родственные языки в рамках одной парадигмы — это не новое, это просто «перепевы». А надо, как там это говориться, «покинуть зону комфорта»! :D Вот попробуйте тот же Haskell, скажем, изучить в «сжатые сроки», или даже, чтоб не меняя парадигму, ту же Ada.
third112
27.06.2016 12:03Про Аду много читал одну из ссылок привел выше:
Языки программирования: Ада, Си, Паскаль. Сравнение и оценка. М.: Радио и связь, 1989.
:)
DarkEld3r
27.06.2016 12:49+2Значит, ничего принципиально нового не изучаете
Из чего это следует? Основной мой инструмент — С++. В своё время осилил "Practical Common Lisp", кое-что писать пробовал. Предпринимал несколько попыток за хаскель взяться и хочется думать, что в итоге более-менее в этом преуспел, хотя без постоянной практики, конечно, всё забывается. Про Racket периодически почитываю. Хотя в последнее время "делал упор" на Rust. Достаточно чтобы покинуть "зону комфорта"?
А сжатые сроки зачем? Изучаю ведь ради самообразования и расширения кругозора.
Наверное, можно придётся представить, что мне на каком-то незнакомом по работе придётся что-то написать, хотя и придётся изрядно напрячь фантазию. Разумеется, из-за срочности "ощущения" будут совсем другие, но что это доказывает? Ведь должное понимание не факт, что возникнет.
В любом случае, мне "учиться" нравится. Так что если даже придётся решать задачу непривычным инструментом, то (при условии, что он заинтересует) присмотрюсь получше уже в спокойной обстановке.kemiisto
27.06.2016 13:09Это не изучение, это «ковыряние». Полистал книжку, что-то в Интернете глазами пробежал, что-то простенькое накидал «на коленках». Это всё «ради самообразования и расширения кругозора», как Вы и сказали, но не более. Речь о том, что на изучение монструозных языков (С++) до уровня «решать задачу», а не «поковырять», нужно потратить слишком много времени, что, как и утверждал third112, «будет тормозить распространение языка». Вы, собственно, именно этот его тезис пытаетесь оспорить. Поэтому я и говорю: либо изучаете, но не новое, либо новое, но не изучаете. Иначе бы у Вас физически времени не хватило. Вот С++ Вы сколько изучали? До уровня «решать задачу» имеется ввиду.
DarkEld3r
27.06.2016 13:35Вот С++ Вы сколько изучали?
До сих пор изучаю, благо язык продолжает развиваться. (:
Для начала уточню: я спорил не с тем, что "с наскоку" "принципиально новый" язык освоить сложно, а с тем, что будучи "работающем в коммерческой компании программистом" тоже можно (и я бы даже сказал нужно) изучать новое. Не обязательно в рамках "рабочего процесса".
Ну и всё-таки поспорю: знание (любых) языков помогает в освоении даже "совсем других". Задачи, опять же, разные бывают. Одно дело большой проект — он на любом языке будет большим и сложным. Другое — что-то небольшое, но вполне возможно полезное, для себя сделать. Тут и начальные знаний хватит, а в процессе их как раз углубить можно.
Опять же, вряд ли кто-то будет переписывать "более-менее обычный проект" с джавы на хаскель. В том числе потому что вряд ли из команды все его знать будут или захотят изучать. А вот в то, что возьмут скалу или котлин, ну или, по крайней мере, часть проекта на них напишут, поверить можно. И да, на них можно писать поначалу "как на джаве" и углубляться постепенно.
Аналогично с С, С++ и растом: да, есть много своих нюансов, но будучи знакомым с одним из них, другие освоить проще.
И ещё я не верю в "простые языки": если они развиваются, то продолжают вбирать фичи. Джава многими считается простой и консервативной, но лямбды и до неё добрались и дальше фичи пихать будут. C# от плюсов недалеко ушёл, хотя правильно будет сказать "стремительно догоняет": версии языка выходят чаще, фичи и "сахар" добавлять не стесняются. Возьмём Racket казалось бы — казалось бы, наследник минималистичной Scheme. Да, как всякий лисп, язык позволяет расширять себя и многие (все?) фичи и сделаны средствами языка, но толку? Если заглянуть в гайд, то глаза разбегаются от обилия "прикольных штук".
Разве что Go идёт по "другому пути" и то судить ещё рано, посмотрим через десяток лет и N версий языка.third112
28.06.2016 00:09Простые языки подходят для решения очень многих задач. Не для рекламы, а только в качестве примера упомяну наш проект игрового бота. Там, на мой взгляд, совершенно обосновано в качестве языка скриптов взят стандартный Паскаль. А взяли бы мы что-то посложней (или что-то попроще — совсем примитивное), до сих пор бы на старте буксовали :)
DarkEld3r
29.06.2016 11:58Простые языки подходят для решения очень многих задач
Подходят. Вот только для разных задач, скорее всего, будут разные языки. Ну и скриптовые языки и всякие ДСЛ — это несколько отдельная ниша.
И идея ДСЛ мне вполне импонирует, но это не "язык общего назначения".
Кстати, Паскаль ведь тоже развивается — в виде Делфи. Что-то там добавляют и наворачивают. А то ведь можно взять джаву 1.0 и говорить, что это простой язык.third112
30.06.2016 01:55+1Согласен, что скриптовые языки зачастую узко специализированы, но у нас другой случай: мы использовали язык общего назначения (Паскаль) в качестве скриптового :)
Согласен, что Паскаль развивается. В том числе и в виде Дельфи (есть еще и Free Pascal и др.). До Delphi-7 (включительно) развитие шло органично: делались пристройки, но сохранялось основное очень простое ядро. Отсюда была хорошая совместимость со старыми версиями. А потом стало несовместимым, и многие из тех, у кого много старого кода, продолжают использовать Delphi-7. Пример: игра КР (для которой упомянутый бот).third112
30.06.2016 02:04PS В боте язык не изменяли, только добавили предопределенные функции. Для многих других случаев можно использовать такой путь. Язык останется тем же.
DarkEld3r
30.06.2016 10:40Статью про бота читал некоторое время назад, но в первую очередь из-за любви к рейнджерам. (:
На форум тоже заглядывал, но если честно, аргументы в пользу паскаля забылись (если они там приводятся). Спорить не буду — вам, как разработчикам, виднее, тем более, что сами КР тоже на паскеле. Не буду отрицать — против паскаля есть некоторое предубеждение, так что самостоятельный проект на нём я бы не начинал.
third112
30.06.2016 23:28Первоначально одной из основных целей Паскаля была «учебный язык», т.е. язык для обучения программированию. Поэтому даже неискушенному новичку на Паскале написать очень плохой код гораздо труднее, чем на других языках :) Си, например, тоже довольно простой язык (если сравнивать с С++), но он очень гибкий. Опытные кодеры считают эту гибкость достоинством, но новичкам она вредит: такого понаписать можно… Описание Паскаля занимает всего 30 страниц — по силам прочитать и понять любому фанату КР, даже если никогда до этого не программировал и в школе информатику не учил :) И на форумах фрагменты кода на Паскале обсуждать удобно — никто не говорит, что не понимает столь простого языка :))
MaxAkaAltmer
01.07.2016 11:53Про очень плохой код на паскале…
Помню будучи студентом, стукнуло мне в голову сделать «очень плохой код», а именно реализовать в функции массив указателей на метки (по которым goto работает) и прыгать на них вот так: goto labels[index];
СИ разумеется мне этого не позволил, как бы я не пытался, а вот Паскаль к моему глубоком удивлению позволил! Дело было вроде в Turbo Pascal 7.1, если память не изменяет…third112
02.07.2016 02:14Turbo Pascal с первых версий ради удобств сильно отходил от стандартов. Поэтому, например, в США многие преподаватели считали его не учебным. Интерпретатор нашего бота не позволяет написать «goto labels[index]^», выдавая две синтаксических ошибки: «integer expected» и «illegal symbol».
MaxAkaAltmer
02.07.2016 11:42Стандарты ограничивают, лучше иметь рекомендации и возможность им следовать или не следовать, по крайней мере для учебного языка, ведь экспериментировать — это хорошо. В свое время я разрабатывал 2д рендер для простенькой системы на древнем ARM7 (40МГц), мне очень не хватало производительности, и тогда я написал серию самомодифицирующихся функций на ассемблере для отрисовки графики, выиграв при этом прилично скорости. Мне до сих пор интересно какими бы были язык высокого уровня и архитектура процессора в которых самодификация была бы стандартным явлением.
Кстати, по словам знакомых инженеров из Эльбруса — в DOOM для ПК тоже этим страдали, он из-за этого много ресурсов отбирает на их бинарном рекомпиляторе.third112
03.07.2016 02:48Да. Стандарты ограничивают и дисциплинируют. Прежде всего, производителей компиляторов и других инструментов программирования. Благодаря стандартам к «болту» одного производителя всегда можно подобрать «гайку» другого. От любого из существующих стандартов можно отказаться и оформить тот же текст в виде рекомендаций, но если среднего школьника, которому положено посещать уроки информатики и который не собирается стать профессиональным программистом, заставить вызубрить эти рекомендации – такая задача будет ему не по силам. А стандарты школьникам зубрить не нужно: компилятор обругает в том месте, где ученик отошел от стандарта. Думаю, что в школе и на первых курсах института самомодифицирующийся код изучать не надо: пусть сначала плавать научатся. И я любил работать на ассемблере: вплоть до Intel 80486 включительно удавалось творить чудеса (особенно для NP задач), а потом возросшие ресурсы позволили реализовать мощные оптимизаторы – я (и мои знакомые и сослуживцы по ассемблерным делам) быстро обнаружили, что из написанного на языке высокого уровня кода получается гораздо более быстрый «экзешник», чем нам удается сделать на ассемблере.
MaxAkaAltmer
03.07.2016 12:08-1Против технических стандартов ничего не имею. Я имел ввиду немного другое — неписанные стандарты, кто-то вот решил, что указатели это зло и сказал — в школе будем изучать язык без указателей — это будет стандарт обучения. Я считаю здесь должен быть как минимум выбор. Человек очень быстро учится пока молодой, потом тяжелее и тяжелее. Поэтому, если когда-то и надо изучать что-то новое и сложное, то именно тогда когда ты учишься. Зубрить ничего не надо, надо понимать суть, для остального есть справочники, а школьные задачи можно решить на любом языке — пусть ученик сам решает — на сколько он готов выпендриваться. У нас в школе так и было, кто-то писал на Бейсике, кто-то на Паскале, я писал на Си.
"… я (и мои знакомые и сослуживцы по ассемблерным делам) быстро обнаружили, что из написанного на языке высокого уровня кода получается гораздо более быстрый «экзешник», чем нам удается сделать на ассемблере....."
Весь код на ассемблере после появления языков высокого уровня писали наверное только те, кому время девать некуда. А критические участки реализуют на ассемблере по сей день, и если что — я и мои знакомые можем делать на ассемблере код более быстрый, чем на языке высокого уровня :)third112
04.07.2016 04:56+1Я имел ввиду немного другое — неписанные стандарты, кто-то вот решил, что указатели это зло и сказал — в школе будем изучать язык без указателей — это будет стандарт обучения.
Бывают не только глупые/бездарные ученики, но и учителя :)
Зубрить ничего не надо, надо понимать суть, для остального есть справочники
Согласен. Но традиционно, даже в лучших универах, математику и естественные науки изучают путем зубрежки формул, теорем, доказательств и т.д. (А студенты-историки даты зубрят :))
а школьные задачи можно решить на любом языке — пусть ученик сам решает — на сколько он готов выпендриваться. У нас в школе так и было, кто-то писал на Бейсике, кто-то на Паскале, я писал на Си.
А если ученик возьмет совсем экзотический язык, который мало кто знает? Нпр., в моей коллекции есть описания и трансляторы языков T и Dee. Слышали о таких? ;)
А критические участки реализуют на ассемблере по сей день, и если что — я и мои знакомые можем делать на ассемблере код более быстрый, чем на языке высокого уровня
Сможете доказать? ;) Вот Вам и тема для очередной Хабр-статьи: возьмите какую ни будь задачку из общеизвестных (игра Жизнь, задача коммивояжера и т.д.), решите на языке высокого уровня, а потом ускорьте критические участки, переписав их на ассемблере. В статье сравните время выполнения и поделитесь секретами успеха, приложите исходный код. Уверен, что такая статья многих здесь заинтересует.MaxAkaAltmer
04.07.2016 09:25+1«А если ученик возьмет совсем экзотический язык, который мало кто знает? Нпр., в моей коллекции есть описания и трансляторы языков T и Dee. Слышали о таких? ;)»
Пусть берет, главное, чтобы результат был правильный. Необязательно преподавателю знать все языки.
«Сможете доказать? ;) Вот Вам и тема для очередной Хабр-статьи: возьмите какую ни будь задачку из общеизвестных (игра Жизнь, задача коммивояжера и т.д.)»
Есть задачи, которые компилятор на языке высокого уровня решить лучше человека не сможет, по крайней мере пока, поэтому да смогу, но пример выбирать не вам. Доказывать очевидное не буду, лучше возьмите открытые кодеки и системы распознавания образов — думаете люди от нечего делать там целые функции на ассемблере или интрисиками пишут?
khim
04.07.2016 16:21Но традиционно, даже в лучших универах, математику и естественные науки изучают путем зубрежки формул, теорем, доказательств и т.д. (А студенты-историки даты зубрят :))
Ничего не знаю про студентов-историков, но на мой вопрос «у меня плохая память на имена потому слова „теорема Такого-то Сякого-то“ мне ни о чём не говорят — не могли бы вы сказать о чём она?» преподаватели реагировали всегда вполне благосклонно — при условии, конечно, что я на самом деле знал как доказать эту самую теорему.
А вот к людям путающим значки ? и ? или не знающих что ?x… расшифровывается не как ?x¬…, а как ?x¬… — отношение было совсем другое.
Вот Вам и тема для очередной Хабр-статьи: возьмите какую ни будь задачку из общеизвестных (игра Жизнь, задача коммивояжера и т.д.), решите на языке высокого уровня, а потом ускорьте критические участки, переписав их на ассемблере.
А вот тут — как бы хороший пример на путаницу ? и ?. Для многих задач компилятор может сгенерировать весьма неплохой год (хотя как раз Жизнь ускорить с использованием ассемблера можно изрядно), но в любой программа размера чуть выше среднего находятся куски, которые на ассемблер ложатся плохо.
Если проект, над которым я сейчас работаю когда-нибудь отопенсорсят я приведу бенчмарки — делать 100500ю синтетическую статью (типа такого) как-то не хочется.
P.S. Почему я говорю о кусках кода с интринзиками как об «ассемблере»? Потому что фактически — это оно и есть. Каждая команда типа …sad_epu… — транслируется ровно в одну инструкцию, потому когда вы пишите «на интризиках» вы получаете почти оптимальный код. Который легко может обойти переносимую реализацию по скорости в 2-3 раза, иногда и больше. А вот ассемблер уже выигрывает по сравнению с этим какие-то слёзы — несколько процентов, если повезёт.

Shifty_Fox
11.11.2016 01:55Да, все так.
Я говорил о том, что нужно изменить точку восприятия. Замедляется «течение» объекта, его скорость «исполнения». Причинно-следственные связи на месте, времени нет, есть только понятие скорости изменения состояния объекта.
Что есть часы на спутниках GPS? Это физические объекты, которые меняют состояние, и через их состояние мы условно меряем время. Объекты оказались в гравитационном поле\движутся с ускорением — их скорость смены состояний меняется, и мы вынуждены корректировать их, чтобы их именно «условное состояние», положение стрелки часов — совпадало с земным.

lizarge
Не стоит забывать в таком ключе о objective-c эта реализация С c ООП гораздо ближе к оригиналу чем C++.
semen_grinshtein
Да, точно. Добавил.
kemiisto
Это смотря, что считать «оригиналом» ООП: Симулу или Смолтолк.
AndreyRubankov
В данном контексте под «Оригиналом» имелся ввиду язык Си, а не ООП.
Objective-C ближе к Си, чем C++.
aknew
Objective-C не просто ближе к С, а имеет с ним полную обратную совместимость (по крайней мере это декларируется) т.е. любой кусок кода на С можно просто вставить в Obj-C и он заведется (если конечно не брать нечто уж очень древнее типа void f(){return 1}, но такое и не все си компиляторы съедят), а вот с C++ так сделать получится не всегда
quite_happy
Можете привести пример, когда кусок кода на С, не будет работать в C++, кроме более жесткого контроля типов при «ручном» выделении памяти.
aknew
А почему это «кроме более жесткого контроля типов при «ручном» выделении памяти.»? Как-то странно получается, я говорю что код на С не всегда соберется C++ компилятором, но собирается при этом obj-c, а мне в ответ «ну покажи код с несовместимой фичей, только чур несовместимую фичу не используй», поэтому проигнорирую это условие и приведу пример кода как раз с ним (из книжки Thinking in C++, хотя искал я там другой пример — было еще что-то с массивами):
int i = 10;
void* vp = &i;
int* ip = vp;
Собирается в c и obj-c, но не в c++
grechnik
Разная семантика inline. Программа из двух файлов. test1.c:
test2.c:
Валидно в C, ошибка линковки в C++. Если второй файл убрать, то валидно в C++, ошибка линковки в C (точнее, программа не соответствует стандарту, и может быть ошибка линковки в зависимости от настроения компилятора — будет с gcc -O0, не будет с gcc -O2).
На Википедии есть пример с
sizeof('x').Молчаливое преобразование к/из void*, как выше уже привели пример, отнюдь не ограничивается «ручным» выделением памяти.
Ну а если смотреть на новые стандарты, то они вообще по-разному развиваются: _Bool вместо bool, float _Complex, всякие