
Авторы публикации — Дмитрий Сергеев и Юлия Петропавловская.
Недавно закончился первый в России Виртуальный хакатон от компании Microsoft при поддержке Forbes. Нашей команде, состоящей из двух человек, удалось занять первое место в номинации от WorldClass, в которой требовалось предсказать вероятности перехода каждого клиента компании в статус бывшего члена клуба. В этой статье мы бы хотели поделиться нашим решением и рассказать о его основных этапах.

Подготовка данных
Большую часть времени провели в очистке, восстановлении и объединении данных, так как датасеты были сильно загрязнены и сгруппированы по четырём отдельным категориям:
- Контракты клиентов
- Посещаемость
- Заморозки
- Коммуникации между клиентами и клубом
Тестовые и тренировочные наборы данных были разбиты по месяцам. Train содержал информацию о клиентах за декабрь 2015 года, а Test — за март 2016. Для каждой из категорий мы объединили Train и Test части для дальнейшей обработки.
Контракты клиентов
Контракты стали первым набором данных, за который мы взялись, так как именно там содержалась целевая переменная — "продлил ли клиент свой договор", а также коды контрактов и клиентов в количестве 17631 штук, послуживших ключами для объединения всех остальных датасетов. Небольшое количество пропущенных значений в переменных были восстановлены модами. Затем создали фичи для сезона (зима, весна...), месяца и дня, в который был заключен контракт с клубом, и переменные "длительность контракта", "остаток дней заморозки" и "остаток бонусов на счету". Различные категориальные переменные, такие как возрастная группа, сегмент клуба и т.д. оставили без изменений.
Посещаемость
Начали с создания переменной — длительность разового похода в фитнес-клуб.

Выяснилось, что особо усердные клиенты могут проводить почти по 9 часов на территории клуба, возможно, это связано с прохождением комплексных процедур.
Также в датасете присутствовали категориальные переменные, градации которых мы решили сгруппировать в более общие категории. Например, "КатегорияТренера":
additional = ['Сотрудник СПА', 'Врач']
coach = ['Тренер мастер', "Тренер фитнес"]
coach_vip = ["Тренер персональный", "Тренер элит"]
other = ['Другое']Аналогично — "НаправлениеУслуги":
sport = ["Тренажерный зал", "Водные программы", "Аэробика", "Боевые искусства", "Mind Body",
"Танцевальные программы", "Игровые программы", "Йога", "Групповые программы"]
health_beauty = ["Солярий", "Парикмахерские услуги", "Лечебный массаж", "Маникюр, педикюр", "Массаж_SF",
"Терапевтические процедуры", "Физиотерапевтические процедуры", "Косметические услуги",
"Аппаратная косметология", "Окрашивание", "Аппаратная косметология_SF", "Врачи", "Врачи_SF",
"Продажа косметических товаров", "Инъекции", "Прочие услуги SPA", "Лечебное питание", "Инъекции_SF", "SPA"]Наконец, добавили переменную с частотой посещения клуба в месяц и суммарные количества посещений в различные сезоны (зима, весна..) и сгруппировали данные по кодам клиентов, содержавшихся в датасете по контрактам. Итого, из 3 700 000 записей осталось ~15 000 наблюдений.
Заморозки
Изначально мы выяснили, что в датасете имеются дубликаты. После небольшого исследования оказалось, что один и тот же номер контракта с одинаковыми операциями по заморозке содержится и в Train, и в Test, так как клиентская история заморозок переносилась в тестовый набор. Чтобы в будущем избежать переобучения моделей, мы выкинули повторяющиеся значения из теста.
В течение года каждый клиент мог замораживать свою карту несколько раз, и нам показалось полезным в каком-то виде сохранить временную структуру его заморозок. Для этого мы создали четыре переменных для каждого времени года, в которые записывали суммарное число дней заморозки, израсходованных том или ином сезоне. В результате получили такую структуру данных:

Коммуникации
В сырых данных было три основных столбца: "Дата", "Вид" и "Состояние" взаимодействия. Под "видом" скрывались такие варианты как "телефонный звонок", "встреча", "смс" и т.д., "состояние" же характеризовалось тремя уровнями: "состоялось", "отменено", "запланировано". Как и в заморозках, сначала мы удалили дубликаты из тестовых данных, чтобы очистить их от клиентской истории, а затем перешли к созданию переменных.
Практически у каждого клиента было по несколько десятков коммуникаций того или иного вида. Чтобы сжать эту информацию в одну строку для последующего объединения по уникальному коду контракта мы создали несколько новых фичей.
Сначала разбили переменную "Вид взаимодействия" на 3 дамми:
- личная встреча
- телефон
- другое
Затем посчитали для каждого клиента общее и успешное ("состоялось") число коммуникаций. Разделив одно на другое получили переменную "доля успешных коммуникаций".
Последней находкой стало создание дамми-переменной "были ли коммуникации за последние два месяца". Мы предположили, что если человек собирается продлевать свой контракт, он постарается так или иначе связаться с клубом, когда его текущий контракт будет подходить к концу.
В результате, из 1 500 000 строк получили 15500 и объединили их с финальным датасетом. После преобразования категориальных переменных в дамми количество столбцов раздулось до 72 штук.
Машинное обучение
Итак, бинарная классификация клиентов, классы представлены примерно поровну, всё хорошо и можно обучаться. Кандидатами в модели, помимо очевидного, стали:
- Random Forest
- Neural Network
- SVM
- k-NN
- Naive Bayes
- Logit regression
- Decision Stumps
Каждый из классификаторов, в целом, показывал очень неплохие результаты на валидации. Random Forest на 1000 деревьев с 10-fold cv давал 0.9499 AUC, двухслойная нейронная сеть смогла поднять результат до 0.98, а гроза соревнований на Kaggle, XGB, показал впечатляющие 0.982. Также xgboost помог с визуализацией важности признаков:

Первая тройка достаточно ожидаема — "длина контракта", "остаток бонусных баллов" и "средняя длина визита". Также в первой десятке "количество успешных коммуникаций", "остаток дней заморозки" и, внезапно, "посещал ли фитнес зимой".
Остальные модели, кроме решающих пеньков, в среднем, давали по 0.92-0.94 AUC и были добавлены в ансамбль для уменьшения коррелированности между различными предсказаниями.
Ансамбль задумывался в виде двух уровней — на первом сотня decision stumps, предсказания по которым объединялись при помощи принципа большинства голосов (majority vote), т.е. если 51 пенёк был "за", а 49 "против", то ставилась единица. На втором — подключались предсказания по остальным классификаторам для последующего объединения.
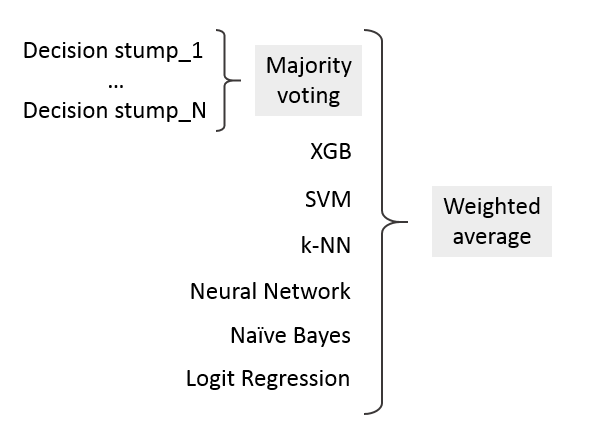
Для создания ансамбля использовался метод взвешенных средних, каждый классификатор тренируется отдельно, а затем из их предсказаний создается линейная комбинация:

aj — веса, с которыми предсказания входят в ансамбль
yj(x) — индивидуальные предсказания классификаторов
p — число используемых моделей
Веса определялись путём минимизации logloss-а ансамбля, при помощи замечательной функции minimize, возвращавшей оптимальные значения вектора весов x0.
from scipy.optimize import minimize
opt = minimize(ensemble_logloss, x0=[1, 1, 1, 1, 1, 1, 1])Модели, которым давался отрицательный вес, из ансамбля выкидывались, чтобы избежать подгонки под тренировочные данные, хотя есть интересное мнение, что так делать не обязательно в случае отрицательно коррелированных ошибок моделей.
В результате такого отбора отпала логистическая регрессия и, сожалению, все пеньки, зато AUC вырос ещё на пару тысячных процента и составил 0.98486. Totally worth it.
Наконец, на тестовом датасете были сделаны предсказания, и чтобы иметь хотя бы какое-то представление об их качестве, были построены две гистограммы: первая для предсказанных ансамблем вероятностей продления клиентом контракта на валидационной выборке, вторая — на тестовой выборке.

Если предположить, что Train и Test выборки были более-менее однородны, и число продлившихся должно быть примерно равно числу отказавшихся, то налицо более чем двукратное завышение моделями вероятности продления контракта. Однако мы решили довериться решению ансамбля и не стали наказывать его за излишнюю наглостьоптимистичность прогноза. И как оказалось — не зря.
В завершении хотелось бы сказать огромное спасибо организаторам хакатона за очень интересную практическую задачу и незабываемый опыт.
Ссылка на репозиторий.
Комментарии (4)

molec
06.07.2016 11:53Мне кажется, что посещение фитнес-клуба — это в первую очередь процесс. Соответственно, прекращение посещений — терминальное событие в этом процессе. Исходя из этого логичнее было бы предсказывать дату прекращения посещений, ну или вероятность прекращения в ближайшее время, если это удобнее для текущего метода.
Бизнес-цель работы — дать менеджменту время (в идеале месяц-два), чтобы замотивировать потерявшего интерес посетителя к продолжению, т.е. предоставить систему, маркирующую клиентов как имеющих тенденцию к непродлению абонемента.
Исходя из этого, логичнее было бы:
1) использовать методы анализа процессов, а не конечных наборов данных
2) все же искать поведенческие паттерны, характерные для клиентов, потерявших интерес к занятиям. (наверняка среди них будут нерегулярность посещений, частые заморозки, уменьшение количества потребляемых услуг, неравномерная длительность посещений, снижение частоты посещений)
Резюмируя, мое мнение — выбранный метод вообще не соответствует задаче (не исключаю, что и предоставленный заказчиком набор данных не слишком ей соответствовал).
Статья довольно куцая и из нее тяжело понять, как конкретно работала представленная система и какой точности предсказания удалось добиться, что были за исходные данные.
Skolopendriy
06.07.2016 15:11Добрый день! Безусловно, вы правы, — цели бизнеса отличаются от целей данного соревнования. Для бизнеса важно понимать процесс взаимодействия клиента с предоставляемыми услугами, отслеживать тенденции, предупреждать возможный отток и т.д. Соответственно необходим ввод различных метрик для учёта паттернов и изменений, а также методов для удержания клиентов, отнесённых к зоне риска.
На хакатоне же необходимо было предсказать вероятность продления клиентом контракта с клубом на конкретный период времени, т.е. некоторого конечного события в текущем процессе. Конечно, поведенческие паттерны необходимы и здесь, и мы постарались в некотором виде учесть их временную структуру при создании финального набора данных (в том числе регулярность посещений, частоту звонков, сезоны наибольшей активности и т.п.). Однако, так как не было необходимости проводить анализ выживаемости, с построением временного распределения вероятности оттока клиента, мы решили отказаться от непосредственного анализа процессов.
В результате, получили некоторую «гибридную» систему, которая искала придуманные нами признаки во временных рядах и отмечала их наличие/отсутствие в конечном наборе данных. К сожалению, точность на тестовых данных организаторами не сообщалась, но на валидации AUC составил порядка 0.98.
imwode
Я, может, невнимательно читал — почему не зря-то?
Skolopendriy
Под «не зря» подразумевалась победа в хакатоне :)
Судя по всему, на тестовых данных именно такое решение показало наибольшую точность