
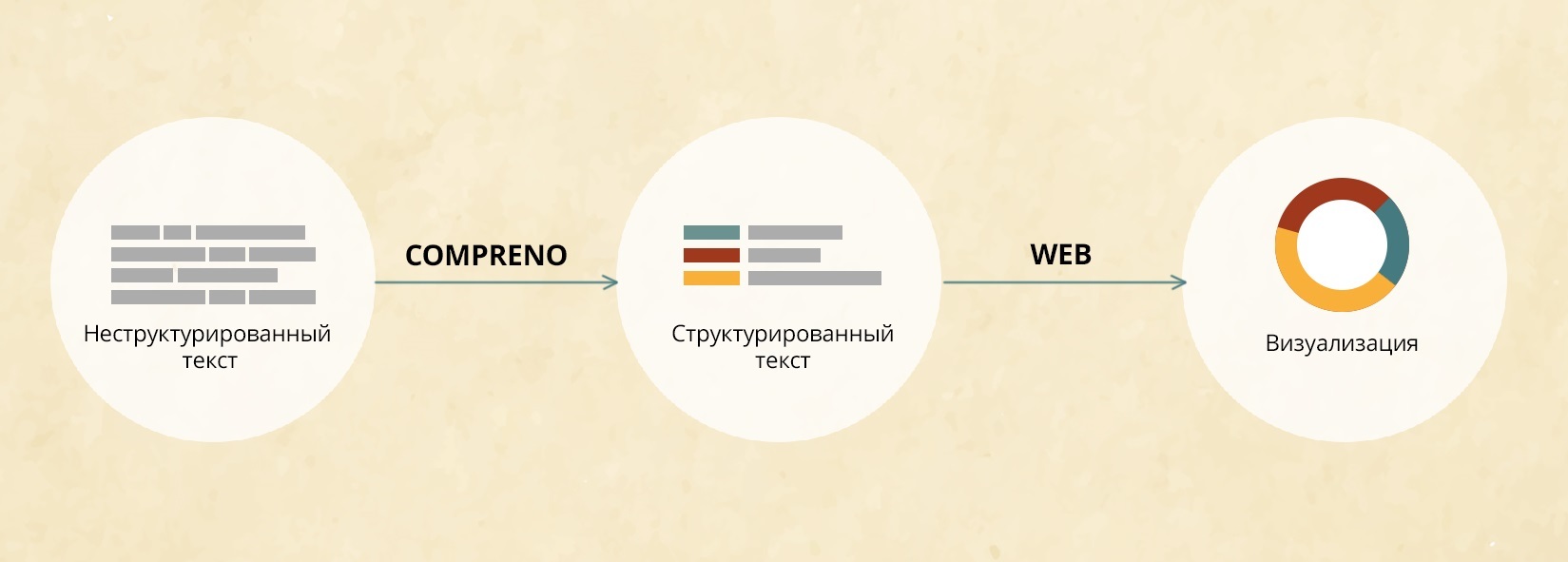
С постоянно растущим объемом текстовой информации и уровнем развития инструментов web-визуализации возникает желание все эти объемы визуализировать. Демонстрация возможности такой визуализации — задача, которая была поставлена перед командой студентов в рамках работы ABBYY Labs и курса “Промышленное программирование” на Факультете инноваций и высоких технологий (ФИВТ) в МФТИ (если вы ещё ни разу не читали в нашем блоге о студенческих лабораториях ABBYY, есть смысл вернуться вот к этому посту).
Пятнадцати третьекурсникам-разработчикам и четырем четверокурсникам-менеджерам, студентам ФИВТ, было предложено за три месяца исследовать современные open-source решения визуализации структурированных данных и затем, выбрав для себя тему, визуализировать текстовую информацию на естественном языке. Переход от неструктурированной информации к структурированной предлагалось осуществить при помощи семантико-синтаксического парсера ABBYY Compreno.
Одно из самых бурных обсуждений за всё время работы над проектом было посвящено выбору текста-основы визуализации. Вариантов было множество: от старых советских газет и научных статей до серии романов “Песнь Льда и Пламени” и комиксов вселенной Marvel.
Поскольку многие тексты, которые нам нравились, были защищены авторскими правами, мы решили остановиться на классических литературных произведениях с истекшим сроком действия авторского права. Тут тоже не обошлось без дискуссий: предлагали и Шерлока Холмcа, и Тома Сойера, и многие другие романы, в итоге мы сошлись на том, что трилогия романов Жюля Верна “Дети капитана Гранта”, “Двадцать тысяч лье под водой” и “Таинственный остров” хорошо подходит для наших целей и нравится нам всем :). Для анализа мы взяли англоязычный и русскоязычный переводы.
Желающих читателей мы сразу приглашаем на сайт julesvernetrilogy.com — вы можете параллельно читать статью и нажимать на кнопки. Итак, выбираем язык (русский или английский) — и поехали.
Извлечением данных из текстов романов занималась отдельная группа. Ребятам нужно было выделить локации и события, которые встречаются в романах, найти взаимосвязи между героями, составить описание внешности и речевые портреты персонажей, а также сделать умную разметку текстов книг. Чтобы решить каждую из этих задач, студенты использовали разнообразную информацию о тексте, полученную при помощи парсера ABBYY Compreno. Подробно о работе парсера мы писали здесь, а сейчас расскажем, как он нам помог структурировать информацию из романов Жюля Верна.

Как вы, конечно, знаете, выбранная нами для анализа трилогия Жюля Верна — это серия приключенческих романов, объединённых общим миром и персонажами. Поскольку львиная доля информации в романах строится вокруг героев, их свойств, действий и перемещений, то сперва следовало научиться выделять сущности, соответствующие героям романов.
Это не такая простая задача, как может показаться на первый взгляд, потому что один и тот же человек может описываться совершенно разными способами. В качестве примера можно рассмотреть часть первой главы книги “Дети капитана Гранта” (жирным выделены упоминания лорда Гленарвана):
Поскольку Compreno умеет справляться с такими случаями, у команды получилось грамотно классифицировать упоминания персонажей, дополнительно разрешая местоименные анафоры. После этого можно было кластеризовать данные и исследовать статистику, связанную со свойствами персонажей.
В каждой главе герои взаимодействовали друг с другом или, говоря в терминах Compreno, встречались в качестве заполнителей некоторых атрибутов одного и того же факта. Нарисовав иконки для всех основных персонажей трилогии и выделив графы взаимодействий персонажей в каждой главе, мы получили наглядное представление социальной активности героев трилогии.
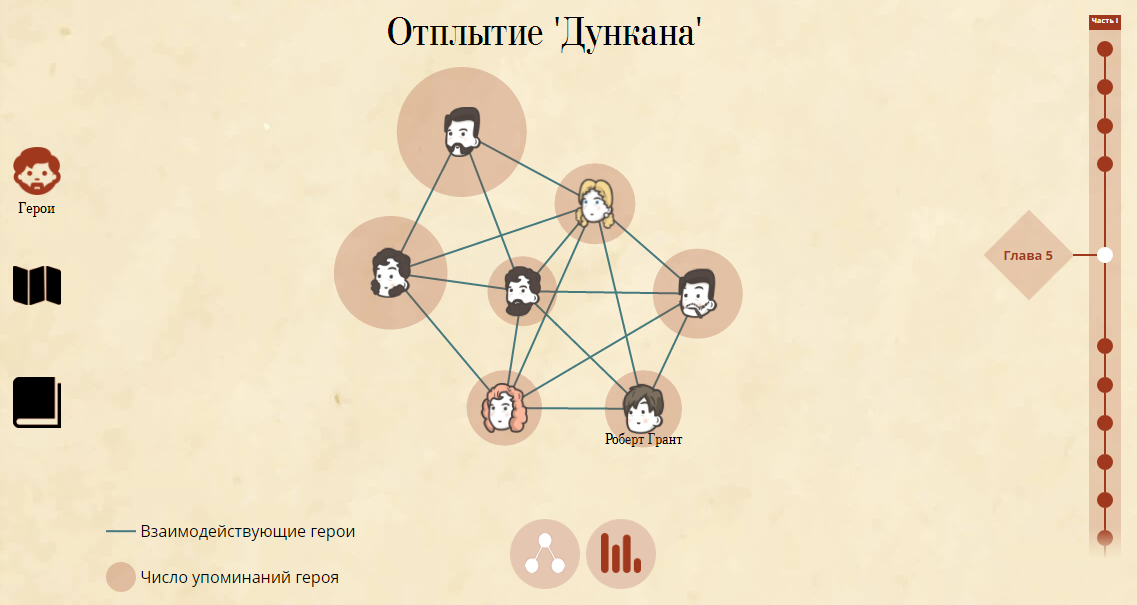
Удалось рассказать подробнее и об активности многих персонажей в различных главах, выделив их действия и описательные характеристики. Нажав на иконку персонажа в графе, можно увидеть его описание в контексте данной главы.
Для обнаружения таких характеристик использовались различные эвристики. Одна из них заключалась в поиске прилагательных, зависящих от персон или имеющих с ними общих предков.
Рассмотрим ее работу на примере такого предложения из романа:
Разбор предложения c помощью Compreno выглядит так:
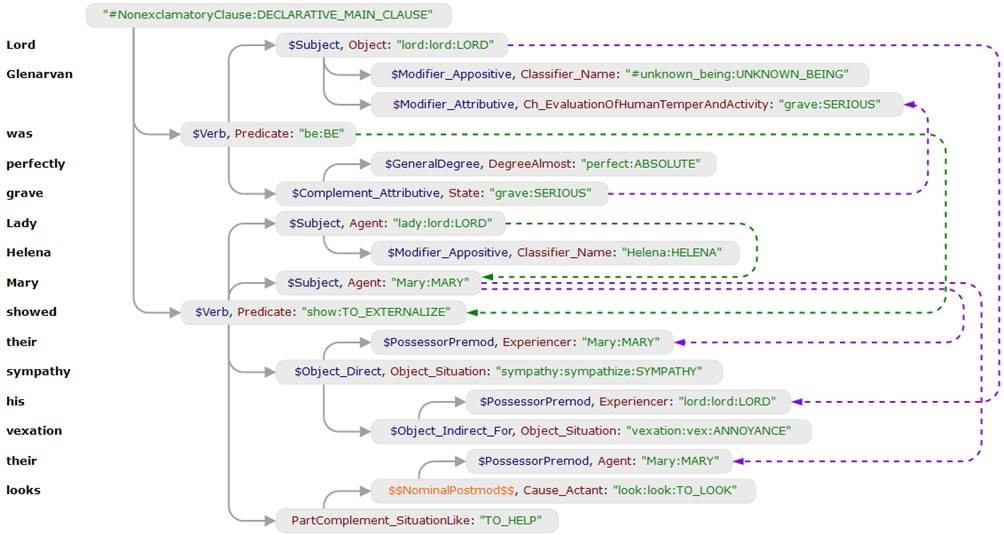
В результате получаем характеристику perfectly grave, которая отображается на сайте:

Другая эвристика помогала извлекать из текста описание одежды персонажей — для этого искались слова с семантическим классом “CLOTHES”. После этого дополнительно фильтровались упоминания самого слова “одежда” и искались зависимости, как в предыдущей эвристике.
В категорию действий попали связки вида “глагол + прямое дополнение” и “причастные обороты”. По сути, алгоритма поиска здесь два.
Первый алгоритм, который строил причастные (или деепричастные) обороты, проверял зависимости у главного слова, а затем, проходя по дереву синтаксического разбора предложения, собирал всю компоненту, после чего выстраивал слова в том же порядке, в котором они встречались в предложении. Таким образом выделялись иногда даже довольно длинные описательные фрагменты. Рекорд — это 48 слов на английском языке с забавной арифметикой:
От таких конструкций, к сожалению, пришлось отказаться, так как они не удовлетворяли формату вывода данных для сайта.
Второй алгоритм искал глагол, у которого в зависимых словах указывался интересующий нас персонаж. Затем находил у этого же глагола его прямое дополнение, после чего так же записывал это с сохранением порядка слов в предложении.
Если изучить получившиеся данные, то можно обнаружить много интересных фактов. Например, узнать о том, насколько бедный Наб был полезен колонии:

Или узнать об образованности храброго Жака Паганеля. Давайте на примере Жака посмотрим, как и какие данные берёт из текста Compreno. У Жюля Верна есть вот такое предложение:
Парсер Compreno разбирает его следующим образом:

На выходе получаем вот такую карточку с характеристиками личности Жака:

Также можно познакомиться с очень активным персонажем из романа “Таинственный остров”:

Герои, помимо активных действий, много разговаривали, и, чтобы определить самых болтливых персонажей, мы построили еще один граф — граф речевой активности. Дополнительный анализ их речи позволил найти самых любознательных героев (задающих множество вопросов) или самых спокойных (практически не использовавших в своей речи восклицательные предложения).
Для того, чтобы это сделать, в RDF-представлении текста, полученном Compreno, мы находили факты типа “прямая речь”. В этих фактах хранится сам отрывок с речью и ссылка на автора слов, поэтому выделить предложения с разным типом речи и связать их с произносившими оказалось довольно просто. Хотя и не обошлось без небольших проблем в разметке (попробуйте найти главу, где у Топа (Таинственный остров) просыпается любопытство). Её оставили нарочно, как своего рода “пасхалку” для самых внимательных.
Поскольку в книге герои постоянно путешествуют, нам показалось интересным извлечь из текста информацию о местах, которые посетили герои, и построить интерактивную карту, которая показывала бы местоположение героев в разных главах. При помощи технологии Compreno это удалось сделать быстро и эффективно, исключив возможность ошибки из-за невнимательности.
Например, так выглядит фрагмент карты для девятой главы первой части романа “Дети капитана Гранта”:
После получения основных локаций захотелось понять, какие события происходили в тех или иных местах. Событиями было решено называть действия с заполненным атрибутом “Where”, в которых принимали участие персонажи визуализируемых книг. Такие факты были выделены при помощи Compreno и отображены на интерактивной карте в соответствующей главе. На них можно увидеть участников события и его краткое описание.
Чтобы можно было получать дополнительную информацию о героях, событиях и локациях прямо во время чтения книги, была добавлена “умная” разметка прямо в тексты книг, которые доступны для чтения в режиме онлайн на сайте. Она была реализована на основе уже извлеченных данных о событиях и локациях и дополнительного поиска персон в тексте с разрешением местоименной анафоры.
Пример размеченного фрагмента из первой главы первой части романа “Дети капитана Гранта”:

Размеченный отрывок из третьей главы первой части книги “Таинственный остров”:

Жюль Верн известен и любим по всему миру, поэтому в наши дни в интернете без труда можно найти много разнообразной информации об авторе и его произведениях. Мы так и поступили, наполнив сайт различной дополнительной информацией.
Интересной особенностью произведений французского писателя являются предсказания технических открытий, сделанные на страницах книг. Современники Жюля Верна не могли и представить, что когда-нибудь будет повсеместно распространена добыча полезных ископаемых с морского дна или что видеотелефония будет чем-то совершенно естественным. А Жюль Верн смог и довольно ясно описал технологии нашего времени в своих романах. Именно таким предсказаниям автора посвящен один из разделов сайта. К описаниям изобретений можно также перейти при помощи разметки прямо во время чтения книги.

Часто во время чтения интересной книги появляется желание узнать побольше об авторе и о других его произведениях. Именно этому посвящен отдельный раздел, основанный на материалах Википедии. В нем можно найти информацию о библиографии и биографии писателя.
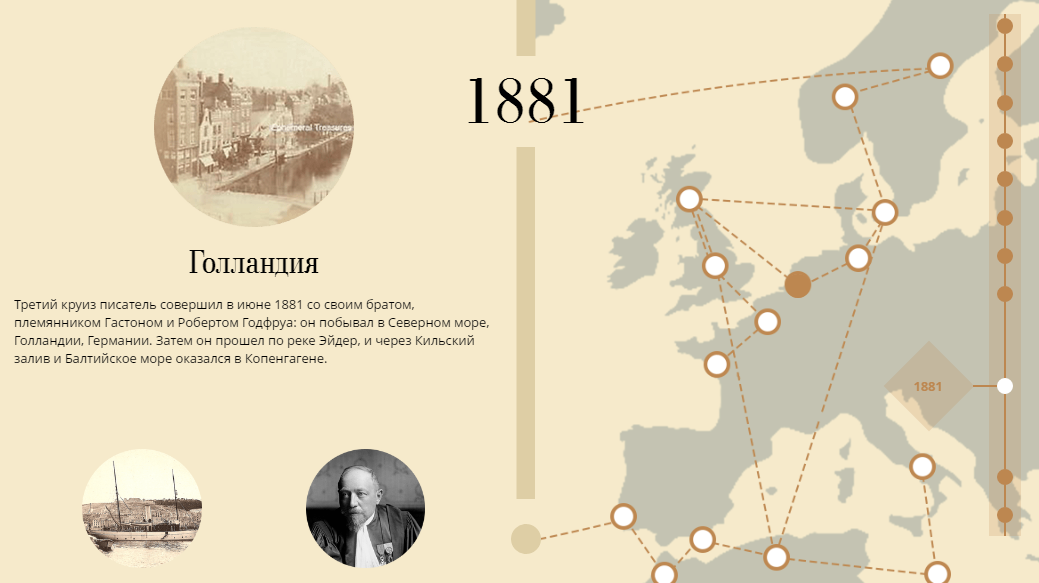
Как и герои его книг, Жюль Верн много путешествовал. Поэтому наглядней всего проследить его жизненный и творческий путь можно на интерактивной карте, при помощи которой мы визуализировали его биографию.
Помимо информации об авторе, во время чтения, благодаря разметке, можно получить дополнительную информацию о местах, героях и событиях. Для этого надо выбрать пункт “База данных” (“Data Base”) в меню или нажать на одну из многочисленных надписей “Читать еще” (“Read more”). Для таких описаний использовались материалы Википедии и отрывки романов трилогии.

Посмотреть на команду, которая осуществила все, о чем рассказано в статье, можно на специальной странице сайта.
Успех подобных проектов — это прежде всего удачный “фасад”, результат работы дизайнеров и web-разработчиков, поэтому для них работа над проектом стала настоящим вызовом: ребятам требовалось за пару месяцев с нуля обучиться web-разработке, совмещая это с напряжённой учёбой, что во многом повлияло на наш выбор средств — большой акцент делался на лёгкость освоения технологий.
Для реализации SPA была использована устаревшая, зато отлично документированная библиотека RactiveJS в сочетании с Page.js. Основной библиотекой визуализации данных стала d3 — с её помощью реализованы граф героев и речевая статистика. Для построения интерактивных карт была использована библиотека Leaflet.
Наша работа над проектом на этом не заканчивается, как и наш курс на физтехе, и уже осенью мы планируем снова активно окунуться в работу. В наших планах создание универсального сайта-конструктора для визуализации литературных произведений. Ведь действительно, и граф героев, и карта с событиями хорошо подойдут практически для любого литературного произведения. Еще одна задумка — это “оживление” сайта при помощи интерактивных заданий по текстам книг.
Пока мы думаем о будущем, все желающие могут на сайте погрузиться в любимый с детства мир, созданный Жюлем Верном, на английском или русском языке.
Мария Сандрикова,
Департамент разработки технологий
Пятнадцати третьекурсникам-разработчикам и четырем четверокурсникам-менеджерам, студентам ФИВТ, было предложено за три месяца исследовать современные open-source решения визуализации структурированных данных и затем, выбрав для себя тему, визуализировать текстовую информацию на естественном языке. Переход от неструктурированной информации к структурированной предлагалось осуществить при помощи семантико-синтаксического парсера ABBYY Compreno.
А если не Жюль Верн, то кто?
Одно из самых бурных обсуждений за всё время работы над проектом было посвящено выбору текста-основы визуализации. Вариантов было множество: от старых советских газет и научных статей до серии романов “Песнь Льда и Пламени” и комиксов вселенной Marvel.
Поскольку многие тексты, которые нам нравились, были защищены авторскими правами, мы решили остановиться на классических литературных произведениях с истекшим сроком действия авторского права. Тут тоже не обошлось без дискуссий: предлагали и Шерлока Холмcа, и Тома Сойера, и многие другие романы, в итоге мы сошлись на том, что трилогия романов Жюля Верна “Дети капитана Гранта”, “Двадцать тысяч лье под водой” и “Таинственный остров” хорошо подходит для наших целей и нравится нам всем :). Для анализа мы взяли англоязычный и русскоязычный переводы.
Желающих читателей мы сразу приглашаем на сайт julesvernetrilogy.com — вы можете параллельно читать статью и нажимать на кнопки. Итак, выбираем язык (русский или английский) — и поехали.
Переходим к структурированной информации
Извлечением данных из текстов романов занималась отдельная группа. Ребятам нужно было выделить локации и события, которые встречаются в романах, найти взаимосвязи между героями, составить описание внешности и речевые портреты персонажей, а также сделать умную разметку текстов книг. Чтобы решить каждую из этих задач, студенты использовали разнообразную информацию о тексте, полученную при помощи парсера ABBYY Compreno. Подробно о работе парсера мы писали здесь, а сейчас расскажем, как он нам помог структурировать информацию из романов Жюля Верна.
Знакомимся с героями с помощью Compreno
Как вы, конечно, знаете, выбранная нами для анализа трилогия Жюля Верна — это серия приключенческих романов, объединённых общим миром и персонажами. Поскольку львиная доля информации в романах строится вокруг героев, их свойств, действий и перемещений, то сперва следовало научиться выделять сущности, соответствующие героям романов.
Это не такая простая задача, как может показаться на первый взгляд, потому что один и тот же человек может описываться совершенно разными способами. В качестве примера можно рассмотреть часть первой главы книги “Дети капитана Гранта” (жирным выделены упоминания лорда Гленарвана):
«If your Lordship would simply break off the neck, I think we might easily withdraw the papers,» suggested John Mangles. «Try it, Edward, try it,» said Lady Helena. Lord Glenarvan was very unwilling, but he found there was no alternative; the precious bottle must be broken. They had to get a hammer before this could be done, though, for the stony material had acquired the hardness of granite. A few sharp strokes, however, soon shivered it to fragments, many of which had pieces of paper sticking to them. These were carefully removed by Lord Glenarvan, and separated and spread out on the table before the eager gaze of his wife and friends.
Поскольку Compreno умеет справляться с такими случаями, у команды получилось грамотно классифицировать упоминания персонажей, дополнительно разрешая местоименные анафоры. После этого можно было кластеризовать данные и исследовать статистику, связанную со свойствами персонажей.
Общение — наше все
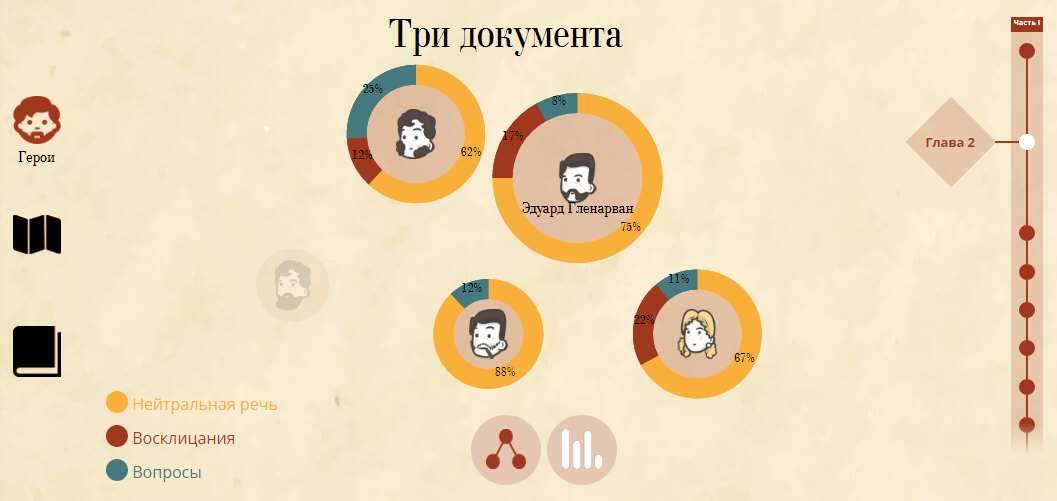
В каждой главе герои взаимодействовали друг с другом или, говоря в терминах Compreno, встречались в качестве заполнителей некоторых атрибутов одного и того же факта. Нарисовав иконки для всех основных персонажей трилогии и выделив графы взаимодействий персонажей в каждой главе, мы получили наглядное представление социальной активности героев трилогии.
Lord Glenarvan was perfectly grave
Удалось рассказать подробнее и об активности многих персонажей в различных главах, выделив их действия и описательные характеристики. Нажав на иконку персонажа в графе, можно увидеть его описание в контексте данной главы.
Для обнаружения таких характеристик использовались различные эвристики. Одна из них заключалась в поиске прилагательных, зависящих от персон или имеющих с ними общих предков.
Рассмотрим ее работу на примере такого предложения из романа:
Lord Glenarvan was perfectly grave, and Lady Helena and Mary showed their sympathy for his vexation by their looks.
Разбор предложения c помощью Compreno выглядит так:
В результате получаем характеристику perfectly grave, которая отображается на сайте:
Другая эвристика помогала извлекать из текста описание одежды персонажей — для этого искались слова с семантическим классом “CLOTHES”. После этого дополнительно фильтровались упоминания самого слова “одежда” и искались зависимости, как в предыдущей эвристике.
Образованный Жак Паганель
В категорию действий попали связки вида “глагол + прямое дополнение” и “причастные обороты”. По сути, алгоритма поиска здесь два.
Первый алгоритм, который строил причастные (или деепричастные) обороты, проверял зависимости у главного слова, а затем, проходя по дереву синтаксического разбора предложения, собирал всю компоненту, после чего выстраивал слова в том же порядке, в котором они встречались в предложении. Таким образом выделялись иногда даже довольно длинные описательные фрагменты. Рекорд — это 48 слов на английском языке с забавной арифметикой:
told but Cyrus Harding having him that even if he managed to count three hundred grains a minute or nine thousand an hour it would take him nearly five thousand five hundred years to finish his task the honest sailor considered it best to give up the idea
От таких конструкций, к сожалению, пришлось отказаться, так как они не удовлетворяли формату вывода данных для сайта.
Второй алгоритм искал глагол, у которого в зависимых словах указывался интересующий нас персонаж. Затем находил у этого же глагола его прямое дополнение, после чего так же записывал это с сохранением порядка слов в предложении.
Если изучить получившиеся данные, то можно обнаружить много интересных фактов. Например, узнать о том, насколько бедный Наб был полезен колонии:
Или узнать об образованности храброго Жака Паганеля. Давайте на примере Жака посмотрим, как и какие данные берёт из текста Compreno. У Жюля Верна есть вот такое предложение:
О, вы, милейший Паганель, останетесь, – отозвался майор. – Вы слишком хорошо знаете и тридцать седьмую параллель, и реку Гуамини, и вообще все пампасы, чтобы покинуть нас.
Парсер Compreno разбирает его следующим образом:
На выходе получаем вот такую карточку с характеристиками личности Жака:
Также можно познакомиться с очень активным персонажем из романа “Таинственный остров”:
Нахождение разговорчивых и эмоциональных персонажей
Герои, помимо активных действий, много разговаривали, и, чтобы определить самых болтливых персонажей, мы построили еще один граф — граф речевой активности. Дополнительный анализ их речи позволил найти самых любознательных героев (задающих множество вопросов) или самых спокойных (практически не использовавших в своей речи восклицательные предложения).
Для того, чтобы это сделать, в RDF-представлении текста, полученном Compreno, мы находили факты типа “прямая речь”. В этих фактах хранится сам отрывок с речью и ссылка на автора слов, поэтому выделить предложения с разным типом речи и связать их с произносившими оказалось довольно просто. Хотя и не обошлось без небольших проблем в разметке (попробуйте найти главу, где у Топа (Таинственный остров) просыпается любопытство). Её оставили нарочно, как своего рода “пасхалку” для самых внимательных.
Интерактивная карта путешествий
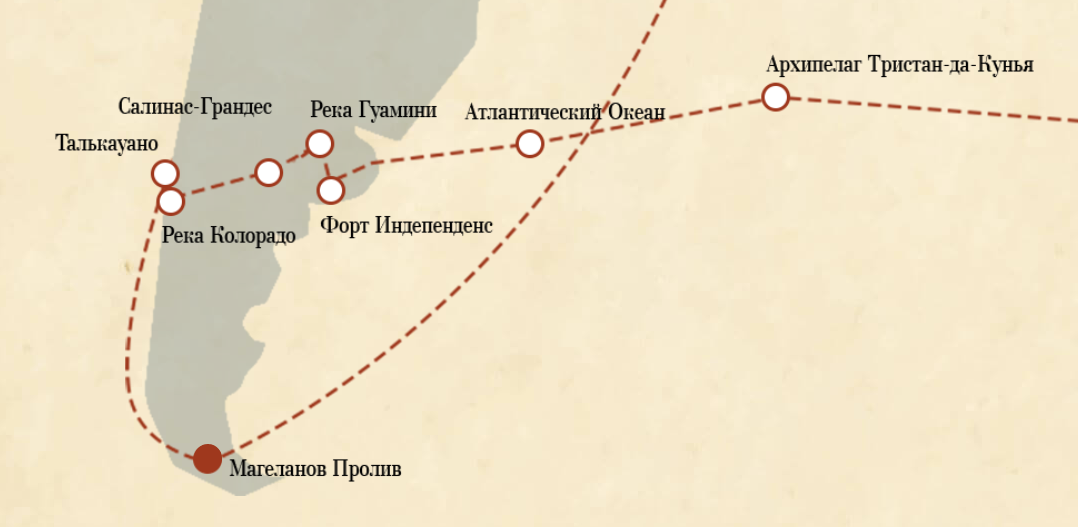
Поскольку в книге герои постоянно путешествуют, нам показалось интересным извлечь из текста информацию о местах, которые посетили герои, и построить интерактивную карту, которая показывала бы местоположение героев в разных главах. При помощи технологии Compreno это удалось сделать быстро и эффективно, исключив возможность ошибки из-за невнимательности.
Например, так выглядит фрагмент карты для девятой главы первой части романа “Дети капитана Гранта”:
Выделение событий
После получения основных локаций захотелось понять, какие события происходили в тех или иных местах. Событиями было решено называть действия с заполненным атрибутом “Where”, в которых принимали участие персонажи визуализируемых книг. Такие факты были выделены при помощи Compreno и отображены на интерактивной карте в соответствующей главе. На них можно увидеть участников события и его краткое описание.
“Умное” чтение
Чтобы можно было получать дополнительную информацию о героях, событиях и локациях прямо во время чтения книги, была добавлена “умная” разметка прямо в тексты книг, которые доступны для чтения в режиме онлайн на сайте. Она была реализована на основе уже извлеченных данных о событиях и локациях и дополнительного поиска персон в тексте с разрешением местоименной анафоры.
Пример размеченного фрагмента из первой главы первой части романа “Дети капитана Гранта”:
Размеченный отрывок из третьей главы первой части книги “Таинственный остров”:
Контекст книги из дополнительных источников
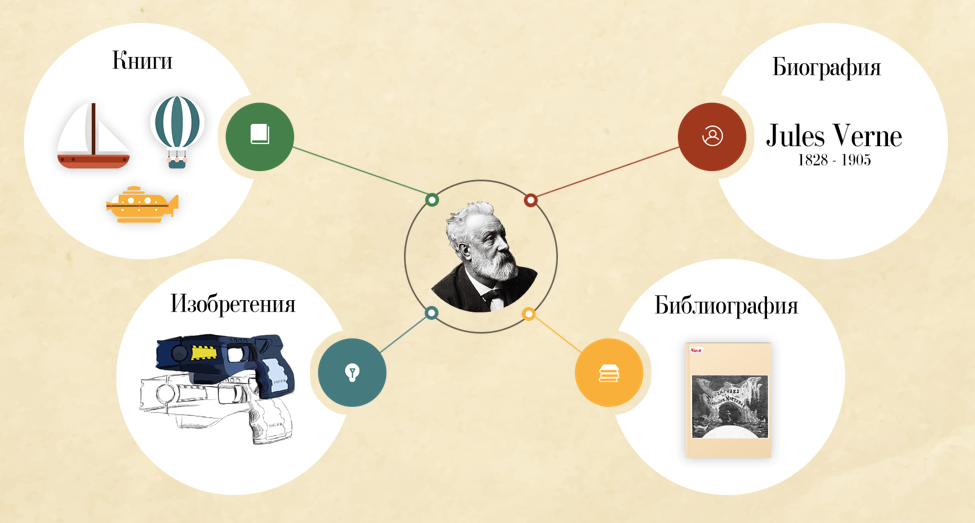
Жюль Верн известен и любим по всему миру, поэтому в наши дни в интернете без труда можно найти много разнообразной информации об авторе и его произведениях. Мы так и поступили, наполнив сайт различной дополнительной информацией.
Предсказанные изобретения
Интересной особенностью произведений французского писателя являются предсказания технических открытий, сделанные на страницах книг. Современники Жюля Верна не могли и представить, что когда-нибудь будет повсеместно распространена добыча полезных ископаемых с морского дна или что видеотелефония будет чем-то совершенно естественным. А Жюль Верн смог и довольно ясно описал технологии нашего времени в своих романах. Именно таким предсказаниям автора посвящен один из разделов сайта. К описаниям изобретений можно также перейти при помощи разметки прямо во время чтения книги.
Подробнее о Жюле Верне
Часто во время чтения интересной книги появляется желание узнать побольше об авторе и о других его произведениях. Именно этому посвящен отдельный раздел, основанный на материалах Википедии. В нем можно найти информацию о библиографии и биографии писателя.
Как и герои его книг, Жюль Верн много путешествовал. Поэтому наглядней всего проследить его жизненный и творческий путь можно на интерактивной карте, при помощи которой мы визуализировали его биографию.
Дополнительные описания локаций, событий и героев
Помимо информации об авторе, во время чтения, благодаря разметке, можно получить дополнительную информацию о местах, героях и событиях. Для этого надо выбрать пункт “База данных” (“Data Base”) в меню или нажать на одну из многочисленных надписей “Читать еще” (“Read more”). Для таких описаний использовались материалы Википедии и отрывки романов трилогии.
Web-разработка и команда
Посмотреть на команду, которая осуществила все, о чем рассказано в статье, можно на специальной странице сайта.
Успех подобных проектов — это прежде всего удачный “фасад”, результат работы дизайнеров и web-разработчиков, поэтому для них работа над проектом стала настоящим вызовом: ребятам требовалось за пару месяцев с нуля обучиться web-разработке, совмещая это с напряжённой учёбой, что во многом повлияло на наш выбор средств — большой акцент делался на лёгкость освоения технологий.
Для реализации SPA была использована устаревшая, зато отлично документированная библиотека RactiveJS в сочетании с Page.js. Основной библиотекой визуализации данных стала d3 — с её помощью реализованы граф героев и речевая статистика. Для построения интерактивных карт была использована библиотека Leaflet.
Куда дальше?
Наша работа над проектом на этом не заканчивается, как и наш курс на физтехе, и уже осенью мы планируем снова активно окунуться в работу. В наших планах создание универсального сайта-конструктора для визуализации литературных произведений. Ведь действительно, и граф героев, и карта с событиями хорошо подойдут практически для любого литературного произведения. Еще одна задумка — это “оживление” сайта при помощи интерактивных заданий по текстам книг.
Пока мы думаем о будущем, все желающие могут на сайте погрузиться в любимый с детства мир, созданный Жюлем Верном, на английском или русском языке.
Мария Сандрикова,
Департамент разработки технологий
Поделиться с друзьями

Vladimir_Sklyar
Проект действительно интересный, и по «светлой» и «доброй» идее, и по удачной реализации силами студентов. Вы говорите, что планируете продолжать визуализацию литературных произведений. А есть понимание об ограничение метода? Очевидно, что такой подход хорош для приключенческой и детективной литературы. Можно придумать замороченные жанры (философия, психология и т.п.) К каким типам произведений сервис нельзя или не имеет смысла применять?
mashaka
Как вы верно отметили, основные элементы визуализации (граф героев и карта) хорошо подходят для приключенческой и детективной литературы, насыщенной героями и событиями. Но и в сторону других жанров мы тоже смотрим. Например, в книгах научной направленности, в том числе по философии и психологии, можно визуализировать текст в виде графа взаимосвязей основных понятий, а не героев. Такое представление может помочь быстрее усвоить новой материал.
Продолжая идею обучения с помощью визуализации, можно задуматься и о различных учебниках. В частности, учебники истории можно довольно красиво и информативно отобразить в виде графа взаимосвязей исторических персонажей, карты и временной ленты событий.
В целом, в большинстве книг присутствуют основные действующие «сущности» (персонажи, термины, исторические события и т.д.), объединенные различными связями (общение, причино-следственные связи и т.д.). А сущностей и связей уже достаточно для визуализации в виде графа, поэтому довольно сложно привести пример произведения, к которому не получится применить сервис.
Bedal
Для детективной — особенно хорошо. Читаешь размеченный текст, кликаешь по «дворецкий», а там «молчалив, из дома не выходил, убийца».
alexeyqu
А с другой стороны, можно сделать «интерактивный» детектив.
Чтобы наполнение страницы дворецкого содержало только инфу, доступную на данный момент книги, а читатель мог удобно сравнивать всех подозреваемых и сам думать.