
Когда я начал работать над виджетом рекомендаций aka «Читайте также», я даже не подозревал о том, что данные, полученные для формирования рекомендаций могут быть не менее полезны, чем сами рекомендации. Собственно, этими данными я и хочу сегодня с вами поделиться в топике. Из них вы можете почерпнуть интересные знания о специфике посещаемости разных сайтов. Под катом вас ждёт geek porn краткий экскурс с описанием, как эти данные формируются, разбор графов нескольких типовых подопытных, а также бонус 18+.
Для подогрева интереса вот вам картинка одного из подопытных:

Для начала небольшое введение об алгоритмах рекомендации. Большинство рекомендательных систем основаны на коллаборативной фильтрации. Это семейство алгоритмов, которые высчитывают рекомендации пользователю на основе выбора других пользователей. Это семейство в свою очередь делится на две основных категории:
И именно вторая категория — наш случай. Дело в том, что у очень многих медийных сайтов до 95% пользователей не являются постоянными читателями, либо наоборот читают до 100% материалов сайта, поэтому объективный портрет пользователя составить проблематично. И для такого алгоритма мы строим по сайту граф, где каждый узел — это страница сайта, а звено между двумя узлами устанавливается, если один пользователь прочитал обе эти страницы (на деле всё сложнее, но в общем виде выглядит примерно так). Звенья взвешенные, и вес их тем больше, чем больше пользователей прочитали обе эти страницы в течении одной сессии на сайте. На представленных ниже графах выбраны 120 самых «тяжёлых» звеньев, а размер узлов обозначает суммарный вес присоединённых звеньев.
Для визуализации на сервисе использована библиотека Vis.js, а точнее её Force-directed layout. Это такой алгоритм визуализации графов, с помощью которого пересечения рёбер сводятся к минимуму и формируется более-менее человеко-понятная картинка. Для этого к узлам и рёбрам применяется симуляция воздействия «сил» из реального мира (силы упругости по закону Гука в данном случае).
Приступим к препарации первого подопытного. На картинке выше — тематический профессиональный портал. Из схемы можно почерпнуть следующую интересную информацию:
Узел под цифрой 1 — это страница поиска по сайту. При такой активности пользователей через эту страницу я бы на месте владельца портала задумался о реорганизации навигации на сайте.
Узел 3 — это страница «последних материалов в блоге». В общем-то ничего удивительного, просто она наглядно собрала самые популярные материала блога вокруг себя.
Ну и узлы 2 и 4 — это материалы, привлекающие большое количество поискового трафика. От них происходит много переходов к материалам в смежных разделах, поэтому они собрали вокруг себя такие «звёзды».
Вокруг также можно заметить плавающие «орфанные» пары — это просто страницы с очень похожим содержанием, дополняющие друг друга. В рекомендациях друг к другу они, соответственно, также будут выпадать на первом месте.
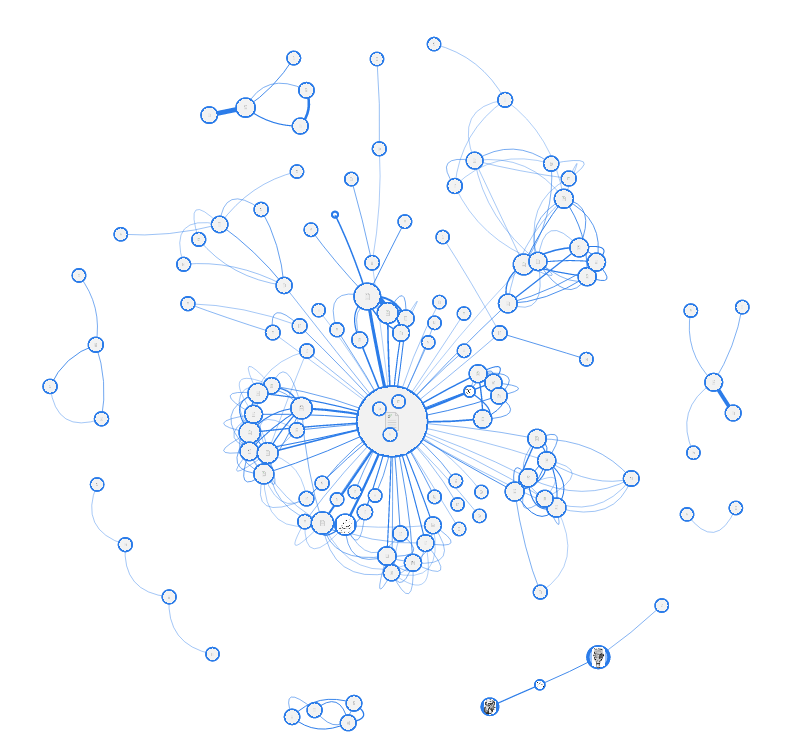
Следующий подопытный — это тоже портал, языковой на этот раз. По центру самый «жирный» узел — на этот раз не поиск, и даже не самая посещаемая, а навигационная страница, которая содержит список подразделов. Вообще эту картинку я привёл сюда для того, чтобы показать вам различие со следующими подопытными. Как нетрудно заметить, у порталов заметна чёткая иерархия и систематика контента, поэтому получаются такие «звёзды». На этой картинке даже заметно, как внутри основной «звезды» контент сбивается в кучки по подразделам (для этого я, правда, специально взял 250 самых жирных ребёр вместо 120).
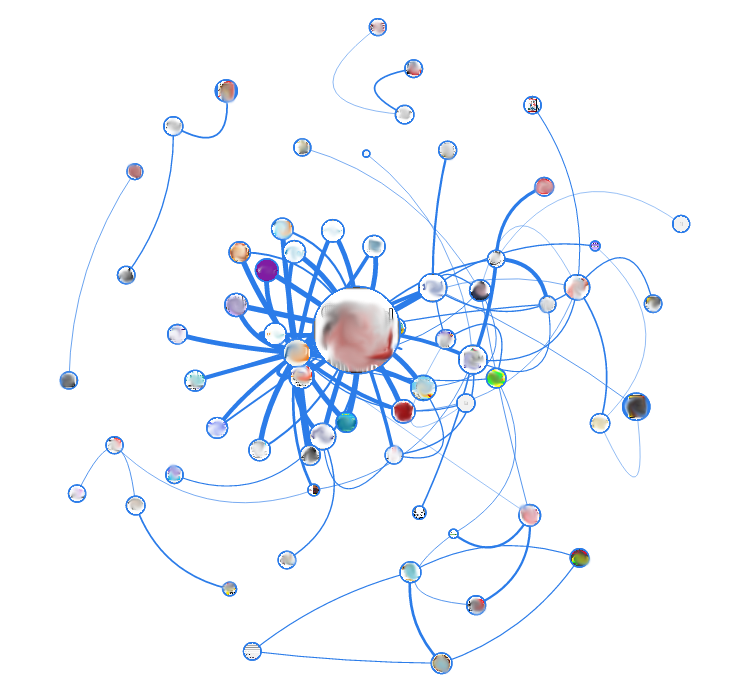
На очереди у нас SEO-блог. По этому графу уже заметна большая случайность связей между страницами. Однако, из него можно почерпнуть одну очень важную вещь. Легко заметить, что по центру находятся два самых «жирных» узла (самый большой, и поменьше около него), которые дают больше всего самых «жирных» связей. Так вот, это — далеко не самые посещаемые страницы. Блог привлекает большую часть трафика из поисковиков, и большая его часть не остаётся на сайте дальше одного просмотра. Зато эти две страницы распространяют трафик «вглубь» сайта.

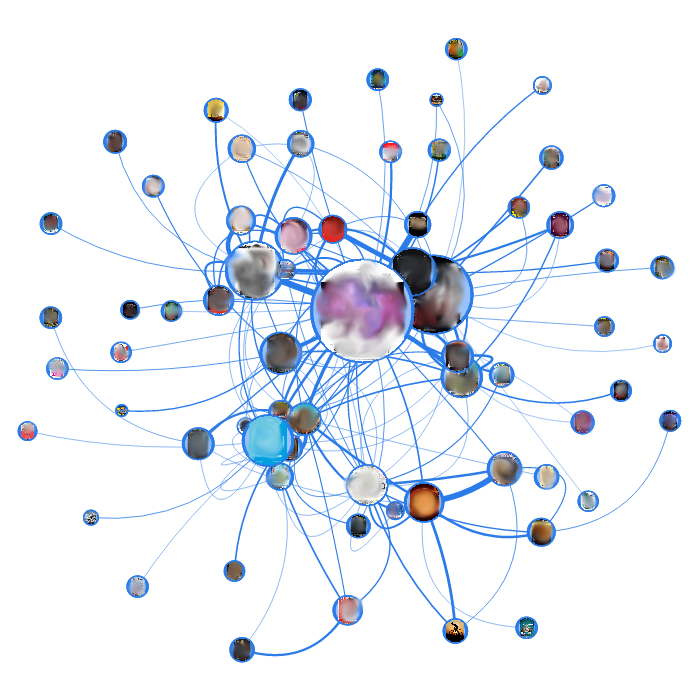
Эти два графа — это региональное СМИ и региональная афиша событий соответственно. У обоих пациентов заметна такая же случайность дуг, однако если присмотреться, то номинальная группировка узлов заметна. У СМИ причина группировки у каждой группы разная (даты, общая тематика, проект и т.п.), у афиши — страницы кучкуются по дате события. Именно исходя из такой ориентированной на даты специфики я сейчас готовлю для таких сайтов отображение графа с фильтрацией страниц по неделям.
Ну и последние на сегодня пациенты — обещанный бонус 18+! (Конечно тоже с замазанными узлами, а вы как думали).
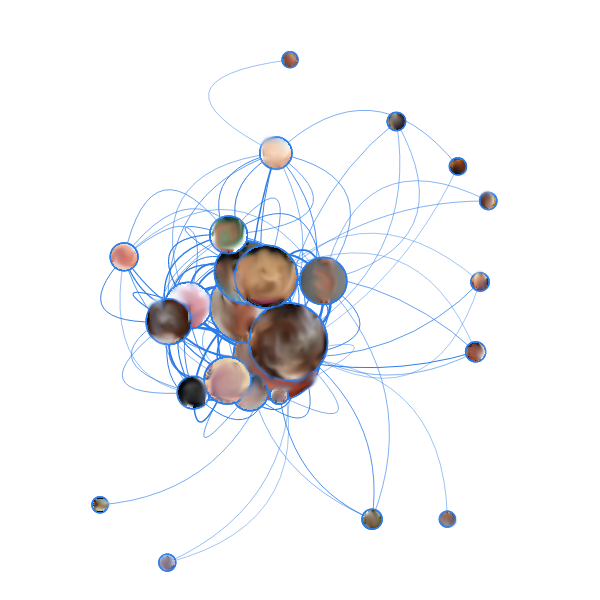
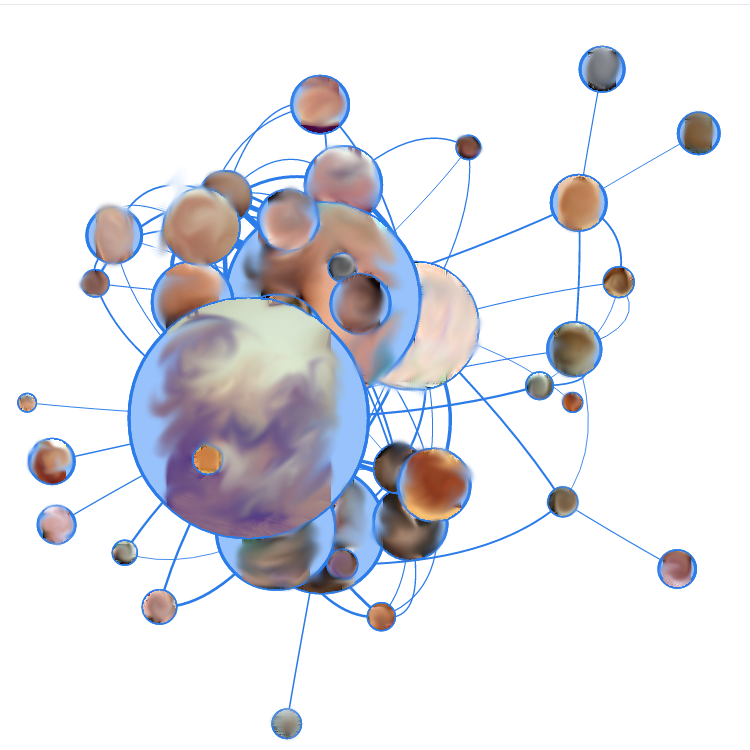
Нетрудно догадаться по обилию бежевого цвета, что это — порно-блоги. Характерной чертой этих двух графов является то, что, несмотря на обилие (сотен) разнообразных страниц, на графах есть чётко выделенное ядро из десятка самых «жирных» страниц, на которые чаще всего переходят из поиска, и между которыми больше всего внутренних переходов. Эта концепция сохраняется даже при увеличении выборки рёбер для графа: вместо пропорционального увеличения «маленьких» узлов по краям, кучка посередине ещё больше сбивается вместе. Также тут, как и у SEO-блога, замечено то, что самые «жирные» узлы не являются самыми посещаемыми.
Для подогрева интереса вот вам картинка одного из подопытных:

Для начала небольшое введение об алгоритмах рекомендации. Большинство рекомендательных систем основаны на коллаборативной фильтрации. Это семейство алгоритмов, которые высчитывают рекомендации пользователю на основе выбора других пользователей. Это семейство в свою очередь делится на две основных категории:
- User-based рекомендации — находят пользователей, чьи вкусы наиболее похожи на ваши, и формирует выдачу на их основе. Алгоритмы из этой категории хороши, когда вы можете составить в среднем довольно точный портрет пользователя (к примеру на основе покупок или рейтинга просмотренных фильмов), и когда вам нужна выдача, не зависящая от контекста (т.е. советовать следующий к просмотру фильм на основе вкусов пользователя независимо от просматриваемой сейчас страницы какого-либо фильма).
- Item-based рекомендации — ставят в центр внимания похожесть рекомендуемых единиц (на основе тех же просмотров пользователей, правда). Используются там, где user-based неэффективны: там, где трудно составить чёткий портрет пользователя, много случайного фактора в выборе записей, и когда высчитывание модели схожести пользователей слишком накладно в виду специфики данных
И именно вторая категория — наш случай. Дело в том, что у очень многих медийных сайтов до 95% пользователей не являются постоянными читателями, либо наоборот читают до 100% материалов сайта, поэтому объективный портрет пользователя составить проблематично. И для такого алгоритма мы строим по сайту граф, где каждый узел — это страница сайта, а звено между двумя узлами устанавливается, если один пользователь прочитал обе эти страницы (на деле всё сложнее, но в общем виде выглядит примерно так). Звенья взвешенные, и вес их тем больше, чем больше пользователей прочитали обе эти страницы в течении одной сессии на сайте. На представленных ниже графах выбраны 120 самых «тяжёлых» звеньев, а размер узлов обозначает суммарный вес присоединённых звеньев.
Для визуализации на сервисе использована библиотека Vis.js, а точнее её Force-directed layout. Это такой алгоритм визуализации графов, с помощью которого пересечения рёбер сводятся к минимуму и формируется более-менее человеко-понятная картинка. Для этого к узлам и рёбрам применяется симуляция воздействия «сил» из реального мира (силы упругости по закону Гука в данном случае).
Приступим к препарации первого подопытного. На картинке выше — тематический профессиональный портал. Из схемы можно почерпнуть следующую интересную информацию:
Узел под цифрой 1 — это страница поиска по сайту. При такой активности пользователей через эту страницу я бы на месте владельца портала задумался о реорганизации навигации на сайте.
Узел 3 — это страница «последних материалов в блоге». В общем-то ничего удивительного, просто она наглядно собрала самые популярные материала блога вокруг себя.
Ну и узлы 2 и 4 — это материалы, привлекающие большое количество поискового трафика. От них происходит много переходов к материалам в смежных разделах, поэтому они собрали вокруг себя такие «звёзды».
Вокруг также можно заметить плавающие «орфанные» пары — это просто страницы с очень похожим содержанием, дополняющие друг друга. В рекомендациях друг к другу они, соответственно, также будут выпадать на первом месте.

Следующий подопытный — это тоже портал, языковой на этот раз. По центру самый «жирный» узел — на этот раз не поиск, и даже не самая посещаемая, а навигационная страница, которая содержит список подразделов. Вообще эту картинку я привёл сюда для того, чтобы показать вам различие со следующими подопытными. Как нетрудно заметить, у порталов заметна чёткая иерархия и систематика контента, поэтому получаются такие «звёзды». На этой картинке даже заметно, как внутри основной «звезды» контент сбивается в кучки по подразделам (для этого я, правда, специально взял 250 самых жирных ребёр вместо 120).

На очереди у нас SEO-блог. По этому графу уже заметна большая случайность связей между страницами. Однако, из него можно почерпнуть одну очень важную вещь. Легко заметить, что по центру находятся два самых «жирных» узла (самый большой, и поменьше около него), которые дают больше всего самых «жирных» связей. Так вот, это — далеко не самые посещаемые страницы. Блог привлекает большую часть трафика из поисковиков, и большая его часть не остаётся на сайте дальше одного просмотра. Зато эти две страницы распространяют трафик «вглубь» сайта.


Эти два графа — это региональное СМИ и региональная афиша событий соответственно. У обоих пациентов заметна такая же случайность дуг, однако если присмотреться, то номинальная группировка узлов заметна. У СМИ причина группировки у каждой группы разная (даты, общая тематика, проект и т.п.), у афиши — страницы кучкуются по дате события. Именно исходя из такой ориентированной на даты специфики я сейчас готовлю для таких сайтов отображение графа с фильтрацией страниц по неделям.
Ну и последние на сегодня пациенты — обещанный бонус 18+! (Конечно тоже с замазанными узлами, а вы как думали).


Нетрудно догадаться по обилию бежевого цвета, что это — порно-блоги. Характерной чертой этих двух графов является то, что, несмотря на обилие (сотен) разнообразных страниц, на графах есть чётко выделенное ядро из десятка самых «жирных» страниц, на которые чаще всего переходят из поиска, и между которыми больше всего внутренних переходов. Эта концепция сохраняется даже при увеличении выборки рёбер для графа: вместо пропорционального увеличения «маленьких» узлов по краям, кучка посередине ещё больше сбивается вместе. Также тут, как и у SEO-блога, замечено то, что самые «жирные» узлы не являются самыми посещаемыми.
Комментарии (4)

zodiak
19.05.2015 21:55Подскажите для желающих поэксперементировать откуда брали данные о посещенных страницах в рамках разных сессий?

axeax
Порно ядро из десятка самых жирных?
GearHead Автор
да, звучало странновато, добавил слово «страниц»