
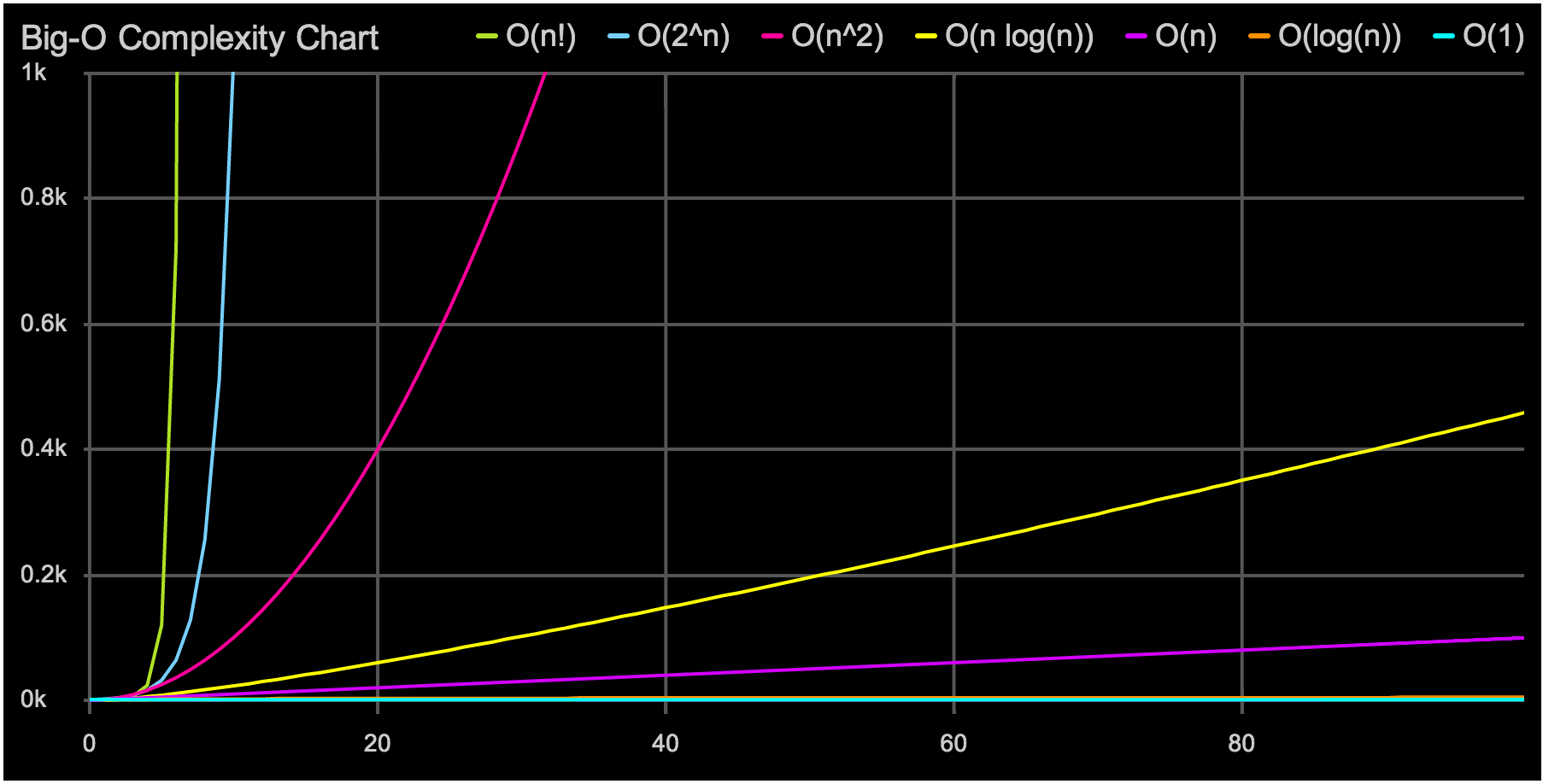
"О" большое — это отличный инструмент. Он позволяет быстро выбрать подходящую структуру данных или алгоритм. Но иногда простой анализ "О" большого может обмануть нас, если не подумать хорошенько о влиянии константных множителей. Пример, который часто встречается при программировании на современных процессорах, связан с выбором структуры данных: массив, список или дерево.
Память, медленная-медленная память
В начале 1980-х время, необходимое для получения данных из ОЗУ и время, необходимое для произведения вычислений с этими данными, были примерно одинаковым. Можно было использовать алгоритм, который случайно двигался по динамической памяти, собирая и обрабатывая данные. С тех пор процессоры стали производить вычисления в разы быстрее, от 100 до 1000 раз, чем получать данные из ОЗУ. Это значит, что пока процессор ждет данных из памяти, он простаивает сотни циклов, ничего не делая. Конечно, это было бы совсем глупо, поэтому современные процессоры содержат несколько уровней встроенного кэша. Каждый раз когда вы запрашиваете один фрагмент данных из памяти, дополнительные прилегающие фрагменты памяти будут записаны в кэш процессора. В итоге, при последовательном проходе по памяти можно получать к ней доступ почти настолько же быстро, насколько процессор может обрабатывать информацию, потому что куски памяти будут постоянно записываться в кэш L1. Если же двигаться по случайным адресам памяти, то зачастую кэш использовать не получится, и производительность может сильно пострадать. Если хотите узнать больше, то доклад Майка Актона на CppCon — это отличная отправная точка (и отлично проведенное время).
В результате этого массивы стали лучшей структурой данных, когда важна производительность, даже если согласно анализу "О" большого массив должен работать медленнее. Там, где вы хотели использовать дерево, отсортированный массив с двоичным поиском может подойти лучше. Там, где вы хотели использовать очередь, растущий массив может подойти лучше, и так далее.
Связный список и динамический массив
Когда вы поняли важность доступа к последовательной памяти, для вас не будет сюрпризом тот факт, что если нужно быстро пройти по коллекции, то массив будет быстрее связного списка. Окружения с умным управлением памятью и сборщиками мусора, возможно, будут хранить узлы связного списка более последовательно, но они не могут гарантировать это. Использование сырого массива обычно требует более сложного кода, особенно когда нужно вставлять или добавлять новые элементы, так как придется обрабатывать рост массива, перемещение элементов, и так далее. В большинстве языков есть родные библиотеки, содержащие ту или иную реализацию динамических массивов. В C++ естьvector, в C# есть List (в F# используется под именем ResizeArray), а в Java есть ArrayList. Обычно эти структуры предоставляют такой же или похожий интерфейс, как и связный список. В этой статье я буду называть такие структуры динамическими массивами (Array List), но имейте ввиду, что в примерах на C# используется класс List, а не более старый ArrayList.
Что, если нужна структура данных, в которую можно быстро вставлять элементы и быстро проходить по ним? Давайте представим, для этого примера, что у нас такой случай: мы будем вставлять в начало коллекции примерно в 5 раз чаще, чем проходить по ней. Давайте также представим, что и у связного списка, и у динамического массива в нашей среде есть одинаково приятные для работы интерфейсы. Остается только решить, что будет более эффективным решением. Мы можем обратиться к анализу "О" большго для оптимизации нашего ценного времени. Обратимся к полезной подсказке про "О" большое, соответствующие сложности для этих структур данных это:
| Проход | Вставка | |
|---|---|---|
| Динамический массив | O(n) | O(n) |
| Связный список | O(n) | O(1) |
Проблема динамических массивов заключается во вставке, как минимум нужно будет копировать и двигать каждый элемент на единицу после точки вставки чтобы освободить место для нового элемента. Отсюда O(n). Иногда нужно создать новый массив, больший по размеру чтобы появилось место для вставки. В нашем случае вставка происходит в 5 раз чаще, чем проход, так что, кажется, вывод очевиден. Пока n достаточно большой, связный список должен в целом быть эффективнее.
Эксперимент
Но чтобы удостовериться, лучше посчитать. Давайте проведем эксперимент с C#, используя BenchMarkDotNet. В C# есть коллекция LinkedList, которая является классическим связным списком, и List, который является динамическим массивом. Интерфейсы у обоих похожи, и оба можно с легкостью применить в нашем случае. Рассмотрим худший случай для динамического массива — вставка всегда происходит в начало, так что приходится копировать весь массив при каждой вставке. Конфигурация окружения тестирования такая:
Host Process Environment Information:
BenchmarkDotNet.Core=v0.9.9.0
OS=Microsoft Windows NT 6.2.9200.0
Processor=Intel(R) Core(TM) i7-4712HQ CPU 2.30GHz, ProcessorCount=8
Frequency=2240910 ticks, Resolution=446.2473 ns, Timer=TSC
CLR=MS.NET 4.0.30319.42000, Arch=64-bit RELEASE [RyuJIT]
GC=Concurrent Workstation
JitModules=clrjit-v4.6.1590.0
Type=Bench Mode=Throughput
Тест-кейсы:
[Benchmark(Baseline=true)]
public int ArrayTest()
{
//In C#, List<T> is an array backed list.
List<int> local = arrayList;
int localInserts = inserts;
int sum = 0;
for (int i = 0; i < localInserts; i++)
{
local.Insert(0, 1); //Insert the number 1 at the front
}
// For loops iterate over List<T> much faster than foreach
for (int i = 0; i < local.Count; i++)
{
sum += local[i]; //do some work here so the JIT doesn't elide the loop entirely
}
return sum;
}
[Benchmark]
public int ListTest()
{
LinkedList<int> local = linkedList;
int localInserts = inserts;
int sum = 0;
for (int i = 0; i < localInserts; i++)
{
local.AddFirst(1); //Insert the number 1 at the front
}
// Again, iterating the fastest possible way over this collection
var node = local.First;
for (int i = 0; i < local.Count; i++)
{
sum += node.Value;
node = node.Next;
}
return sum;
}
Результаты:
| Метод | Размер | Вставки | Медиана |
|---|---|---|---|
| ArrayTest | 100 | 5 | 38.9983 us |
| ListTest | 100 | 5 | 51.7538 us |
Динамический массив выигрывает с неплохим отрывом. Но это маленький список, "О" большое описывает производительность только растущего до больших размеров n, так что результаты теста должны в итоге перевернуться наоборот при увеличении n. Давайте попробуем:
| Метод | Размер | Вставки | Медиана |
|---|---|---|---|
| ArrayTest | 100 | 5 | 38.9983 us |
| ListTest | 100 | 5 | 51.7538 us |
| ArrayTest | 1000 | 5 | 42.1585 us |
| ListTest | 1000 | 5 | 49.5561 us |
| ArrayTest | 100000 | 5 | 208.9662 us |
| ListTest | 100000 | 5 | 312.2153 us |
| ArrayTest | 1000000 | 5 | 2,179.2469 us |
| ListTest | 1000000 | 5 | 4,913.3430 us |
| ArrayTest | 10000000 | 5 | 36,103.8456 us |
| ListTest | 10000000 | 5 | 49,395.0839 us |

Неожиданные для многих результаты. Каким бы большим ни был n, динамический массив все равно оказывается лучше. Чтобы производительность стала хуже, отношение вставок к проходам должно измениться, а не только размер коллекции. Заметьте, что это не ошибка анализа "О" большого, это просто человеческая ошибка — мы неправильно применяем метод. Если углубиться в математику, то "О" большое покажет, что обе структуры данных будут расти с одной скоростью пока отношение вставок к проходам не меняется.
Где находится переломный момент, зависит от множества факторов, но хорошее приближенное правило предложено Чандлером Каррутом из Google: динамический массив будет эффективнее связного списка до тех пор, пока вставок не станет на порядок больше, чем проходов. В нашем случае правило работает хорошо, потому что при отношении 10:1 можно увидеть сдвиг в сторону связного списка:
| Метод | Размер | Вставки | Медиана |
|---|---|---|---|
| ArrayTest | 100000 | 10 | 328,147.7954 ns |
| ListTest | 100000 | 10 | 324,349.0560 ns |
Дьявол в деталях
Динамический массив побеждает потому, что числа, по которым происходит проход, находятся в памяти последовательно. Каждый раз, когда происходит запрос числа из памяти, целый набор чисел добавляется в кэш L1, так что следующие 64 байта данных уже готовы к обработке. При работе со связным списком каждый вызов node.Next перенаправляет указатель на следующий узел, и нет гарантий, что этот узел будет находится в памяти сразу за предыдущим. Поэтому иногда мы будем попадать мимо кэша. Но нам не всегда приходится работать с типами, хранящими непосредственно значения, особенно в объектно-ориентированных языках, где проход зачастую происходит по ссылочным типам. В таком случае, не смотря на то, что в динамическом массиве сами указатели находятся в памяти последовательно, объекты, на которые они указывают — нет. Ситуация все еще лучше, чем со связным списком, где вам придется дважды разыменовывать указатели для каждого элемента, но как это влияет на общую производительность?
Производительность значительно ухудшается, в зависимости от размера объектов и особенностей железа и софта. Если заменить в примере выше числа на маленькие объекты (12 байт), то точка "перелома" опускается до 4 вставок к одному проходу:
| Метод | Размер | Вставки | Медиана |
|---|---|---|---|
| ArrayTestObject | 100000 | 0 | 674.1864 us |
| ListTestObject | 100000 | 0 | 1,140.9044 us |
| ArrayTestObject | 100000 | 2 | 959.0482 us |
| ListTestObject | 100000 | 2 | 1,121.5423 us |
| ArrayTestObject | 100000 | 4 | 1,230.6550 us |
| ListTestObject | 100000 | 4 | 1,142.6658 us |
Управляемый код на C# сильно страдает в этом случае, потому что проход по динамическому массиву создает излишние проверки границ массива. Вектор в С++, скорее всего, будет работать эффективнее. Если быть совсем агрессивным в решении этой задачи, то можно написать более быстрый класс для динамического массива с использованием небезопасного кода C# чтобы избежать проверки границ массива. Относительная разница также будет сильно зависеть от того, как распределитель памяти и сборщик мусора управляют динамической памятью, насколько большие объекты и от других факторов. Более крупные объекты обычно улучшают производительность динамических массивов в моей среде. Когда речь идет о целых приложениях, относительная производительность динамических массивов может также улучшаться с увеличением фрагментации динамической памяти, но чтобы удостовериться, нужно проводить тестирование.
Еще один момент. Если объекты достаточно маленькие (от 16 до 32 байтов или меньше в разных ситуациях), то стоит рассмотреть вариант хранения их по значению (struct в .NET), а не в объекте. Это не только сильно улучшит производительность благодаря последовательному распределению в памяти, но также теоретически уменьшит дополнительную нагрузку из-за сборки мусора, в зависимости от сценария использования этих данных:
| Метод | Размер | Вставки | Медиана |
|---|---|---|---|
| ArrayTestObject | 100000 | 10 | 2,094.8273 us |
| ListTestObject | 100000 | 10 | 1,154.3014 us |
| ArrayTestStruct | 100000 | 10 | 792.0004 us |
| ListTestStruct | 100000 | 10 | 1,206.0713 us |
Java здесь может показать лучшие результаты, потому что она автоматически делает умные изменения маленьких объектов, или можно просто использовать отдельные массивы примитивных типов. И хотя такое писать очень нудно, это может оказаться быстрее, чем массив структур. Все зависит от особенностей обращения к данным в вашем коде. Имейте это ввиду, когда производительность особенно важна.
Убедитесь, что абстракция себя оправдывает
Часто люди не согласны с такими выводами, и их аргументы— это чистота кода, корректность и поддерживаемость. Конечно, в каждой сфере есть свои приоритеты, но я считаю, что когда абстракция лишь ненамного улучшает чистоту когда, а производительность страдает сильно, нужно взять за правило выбирать производительность. Если не жалеть времени на изучение среды, то можно узнать о случаях, когда существует более быстрое и не менее чистое решение, как это часто бывает в случае с динамическими массивами вместо списков.
Информация для размышления: вот семь разных способов найти сумму списка чисел в C#, со временем исполнения и использованием памяти. Везде используется арифметика с проверкой переполнения, чтобы сравнение с Linq, где метод Sum использует именно такую арифметику, было корректным. Заметьте, насколько лучший метод быстрее остальных. Заметьте, насколько затратный самый популярный способ. Заметьте, что абстракция foreach хорошо работает с массивами, но не с динамическими массивами или связными списками. Каким бы ни был ваш язык и окружение, важно понимать эти детали чтобы принимать правильные решения по умолчанию.
| Method | Length | Median | Bytes Allocated/Op |
|---|---|---|---|
| LinkedListLinq | 100000 | 990.7718 us | 23,192.49 |
| RawArrayLinq | 100000 | 643.8204 us | 11,856.39 |
| LinkedListForEach | 100000 | 489.7294 us | 11,909.99 |
| LinkedListFor | 100000 | 299.9746 us | 6,033.70 |
| ArrayListForEach | 100000 | 270.3873 us | 6,035.88 |
| ArrayListFor | 100000 | 97.0850 us | 1,574.32 |
| RawArrayForEach | 100000 | 53.0535 us | 1,574.84 |
| RawArrayFor | 100000 | 53.1745 us | 1,577.77 |
[Benchmark(Baseline = true)]
public int LinkedListLinq()
{
var local = linkedList;
return local.Sum();
}
[Benchmark]
public int LinkedListForEach()
{
var local = linkedList;
int sum = 0;
checked
{
foreach (var node in local)
{
sum += node;
}
}
return sum;
}
[Benchmark]
public int LinkedListFor()
{
var local = linkedList;
int sum = 0;
var node = local.First;
for (int i = 0; i < local.Count; i++)
{
checked
{
sum += node.Value;
node = node.Next;
}
}
return sum;
}
[Benchmark]
public int ArrayListFor()
{
//In C#, List<T> is an array backed list
List<int> local = arrayList;
int sum = 0;
for (int i = 0; i < local.Count; i++)
{
checked
{
sum += local[i];
}
}
return sum;
}
[Benchmark]
public int ArrayListForEach()
{
//In C#, List<T> is an array backed list
List<int> local = arrayList;
int sum = 0;
checked
{
foreach (var x in local)
{
sum += x;
}
}
return sum;
}
[Benchmark]
public int RawArrayLinq()
{
int[] local = rawArray;
return local.Sum();
}
[Benchmark]
public int RawArrayForEach()
{
int[] local = rawArray;
int sum = 0;
checked
{
foreach (var x in local)
{
sum += x;
}
}
return sum;
}
[Benchmark]
public int RawArrayFor()
{
int[] local = rawArray;
int sum = 0;
for (int i = 0; i < local.Length; i++)
{
checked
{
sum += local[i];
}
}
return sum;
}Комментарии (64)

nightwolf_du
30.08.2016 14:36freetonik где-нибудь можно найти собранные библиотеки «быстрых» вариантов алгоритмов для c#?
Точнее, дополнения методами расширения на IEnumerable/другие интерфейсы для LINQ методов, по скорости сравнимых с RawArrayFor, дерева на динамическом массиве, и т. д.?

zartdinov
30.08.2016 15:05-3Похоже всевозможные умные компиляторы, двухуровневые кэши и предсказатели переходов на нейронках не оставляют мне больше выбора, как просто писать код
Bombus
30.08.2016 15:28Все вертится относительно того, что ядро процессора работает быстрее, чем оперативная память. А как организовано дальнейшее взаимодействие и с памятью? Т.е. одно ядро произвело вычисления, которые должны изменить набор данных. Далее эти данные нужно записать в более медленную оперативную память. Как это происходит по значению или массивом значений? А в кэш считывание происходит последовательно или однократно массивом? Может кратко разъяснить или дать ссылку на ликбез.
ToSHiC
30.08.2016 16:09+2What every programmer should know about memory, http://lwn.net/Articles/250967/
Есть переводы на русский разной степень хорошести.

BloodUnit
30.08.2016 16:30+1Если объекты достаточно маленькие (от 16 до 32 байтов или меньше в разных ситуациях), то стоит рассмотреть вариант хранения их по значению (struct в .NET), а не в объекте.
Откуда взяты эти цифры, чем плоха структура меньше 16 байт?

Sing
30.08.2016 16:30+14> В нашем случае вставка происходит в 5 раз чаще, чем проход, так что, кажется, вывод очевиден. Пока n достаточно большой, связный список должен в целом быть эффективнее.
Судя по всему, автор не понимает Big-O. Вне зависимости от того, на какое константное число раз вставок будет больше, чем проходов, O(F(x)) не изменится.
т.е. мы имеем для массива вставку и проход = O(n) + 5O(n) = O(n)
для связного списка O(n) + 5O(1) = O(n)
Делаем графики, они действительно растут примерно одинаково, но это почему-то:
> Неожиданные для многих результаты.
> Чтобы производительность стала хуже, отношение вставок к проходам должно измениться, а не только размер коллекции.
Если делать ТОЛЬКО вставки, то связный список будет СУЩЕСТВЕННО лучше, только об этом говорит Big-O. Он не говорит ни о конкретной реализации, ни о том, кто из двух O(n) быстрее. Ему, если хотите, всё равно. Для Big-O разница в 2 раза — это не «неплохой отрыв», это пшик.
Для реальных применений, конечно, разница даже в миллисекунду может иметь значение. Но тут единственное правило — измеряйте. Big-O даёт отличный старт для поиска оптимального решения и оно не «подводит», как написано в заголовке (или, как у оригинала, «обманывает»).
playermet
30.08.2016 18:40> Если делать ТОЛЬКО вставки, то связный список будет СУЩЕСТВЕННО лучше, только об этом говорит Big-O
Если быть точнее, Big-O говорит о том, как изменяется производительность алгоритма при изменении n. Какой из двух разных алгоритмов будет лучше он не говорит.Sing
30.08.2016 18:47Если быть ещё точнее, то Big-O описывает классы производительности алгоритмов при достаточно больших n. Именно эти классы и есть ориентир на то, какой алгоритм будет лучше. Алгоритм класса O(n^2) будет настолько хуже алгоритма O(n), что их нет смысла даже сравнивать, выбирайте сразу O(n).
А вот какой из двух разных алгоритмов одного класса (!) будет лучше — да, он не говорит. Там уже есть смысл упражняться в оптимизациях и сравнениях (чем и занимается автор статьи), но это уже вопросы куда более мелкие.playermet
30.08.2016 19:04+1> Алгоритм класса O(n^2) будет настолько хуже алгоритма O(n), что их нет смысла даже сравнивать, выбирайте сразу O(n)
Ничто не мешает существовать алгоритму с O(n), на каждое n которого на практике тратиться секунда, имея в то же время аналог с O(n^2), где на каждое n тратится миллисекунда.
> что их нет смысла даже сравнивать
Для начала стоит еще взглянуть на сложность по памяти, а то так недалеко и сортировку подсчетом везде брать.Sing
31.08.2016 02:15+1> Ничто не мешает существовать алгоритму с O(n), на каждое n которого на практике тратиться секунда, имея в то же время аналог с O(n^2), где на каждое n тратится миллисекунда.
Да, не мешает. Пусть n равен миллиону. Первый выполнил за 11 дней, второй — за более чем 31 год. Если у нас задача только для ограниченных n, мы вернулись к эмпирическому правилу измерений. Собственно, и ваши «секунда» и «миллисекунда» — это тоже результат измерений, а не приближения уровня Big-O. Не стоит путать эти вещи, как сделал автор.
> Для начала стоит еще взглянуть на сложность по памяти, а то так недалеко и сортировку подсчетом везде брать.
Сомневаюсь, что сортировку со временем O(n^2) стоит использовать везде. Сложность по памяти, конечно, тоже стоит учитывать.playermet
31.08.2016 13:27> это тоже результат измерений, а не приближения уровня Big-O
Я этого и не утверждал.
> Сомневаюсь, что сортировку со временем O(n^2) стоит использовать везде
И это тоже.
oprofen
31.08.2016 10:28+1Sing все правильно написал, если только говорить о Big-O где n стремиться к бесконечности то сравнивать два разных класса не имеет смысла.
Например:
есть алгоритм А где одна операция стоит 1 (секунду, или мили секунду, или наносекунду) с O(n^2)
и есть алгоритм B где одна операция стоит 1000 c O(n), так вот есть такое n где алгоритм А «обойдет» по скорости В
в данном случае при n > 1000.
Какую бы вы стоимость одной операции вы не взяли всегда найдется такое n, где O(n) «быстрее» O(n^2). Это из определения Big-O, потому что стоимость операции это константа, которая зависит от архитектуры, ос и т.д.
А автор статьи сравнил теплое с мягким, Big-O это не о железе и реализациях, это абстракция.
Конечно не всегда уместно использовать «быстрые» алгоритмы, но помогает вначале сделать выбор и оно не «обманывает» если знать определение.
Ради смеха можно реализовать список при помощи массивов и посмотреть на «скорость».

LifeKILLED
30.08.2016 17:34-3Реакция после прочтения: «Какого *#$?!». Последняя табличка выморозила даже не тем, что перебор последовательного массива гораздо быстрее перебора связного списка. Как бы так и должно быть, свои плюсы и минусы, свои цели. Вымораживает то, что встроенная в язык команда foreach оказалась в 2 два раза медленнее конструкции for! Как так вообще произошло?! В какой день рухнул мир?! (а уж про Sum() и говорить страшно, только покрутить пальцем у виска)

Viacheslav01
30.08.2016 17:36+2foreach имеет оптимизацию для массивов, в остальных случаях он работает как положено через енумератор, с прогнозируемыми накладными расходами.
LifeKILLED
30.08.2016 18:33Ну и здесь ведь тоже енумератор:
Пример[Benchmark] public int LinkedListFor() { var local = linkedList; int sum = 0; var node = local.First; for (int i = 0; i < local.Count; i++) { checked { sum += node.Value; node = node.Next; } } return sum; }
ulltor
30.08.2016 19:48+1Ответ кроется в реализации метода
List<T>.Enumerator.MoveNext(), который используется конструкциейforeach:
1) Он проверяет, не изменился лиList<T>.
2) Он проверяет выход за границы массива.
ulltor
30.08.2016 19:41+3Когда CLR видит стандартную конструкцию вида
for (int i = 0; i < array.Lengh; i++), она (среда выполнения) убирает проверку на выход за границы массива. Из-за этогоRawArrayForработает так быстро.
Когда CLR видит конструкцию вида
foreach (var x in array), гдеarray— это обычный массив, она заменяетforeachна обычныйfor, а дальше применяется упомянутая выше оптимизция. Из-за этогоRawArrayForEachработает так же быстро.
Когда CLR встречает конструкцию
for(...)илиforeach(...), работающую сList<T>или любой другой динамической коллекцией, все становится плохо:
а) При использованииfor(...)CLR не может убрать проверки на выход за границу коллекции, т. к. размер списка может быть изменен другим потоком во время работы цикла.
2) При использованииforeach(...)CLR не может заменить его наfor(...), т. к. при обходе коллекции каждый раз проверяется отсутствие изменений и инвалидация итератора в противном случае.
Mingun
30.08.2016 21:22Разве CLR не может увидеть, что других потоков нет и никто на динамическую коллекцию не претендует? И выкинуть связанные с этим проверки.
nightwolf_du
30.08.2016 21:52В .net приложении больше одного потока, даже если их создавали не вы.
Для проверки утверждения стоит собрать однопоточное простое приложение и заглянуть в диспетчер системы.Mingun
30.08.2016 23:25Если поток создан не нами, а самой CLR, она в курсе, кто и зачем в нем требует объекты, так что это не должно ей мешать. Она же знает, что в своем потоке не трогает объект, знает, что объект трогается только в одном пользовательской потоке, что мешает оптимизировать?
nightwolf_du
31.08.2016 19:02Главное, о чем вы забыли — c# управляемый язык. Вы не должны получать неуправляемые ошибки памяти при выходе за границу массива, и, тем более, неопределенное / неуточняемое поведение.
И указатель на метод после компиляции (метода), и указатель на коллекцию будут находиться в соответствующих таблицах, до них можно докопаться reflection-ом и другими методами.
Просматривать по месту компиляции: «уплывет этот указатель куда-нибудь в другой поток или нет» — тяжело или невозможно, но в любом случае очень дорого.
И в конце-концов, ничто не мешает под debugger-ом/reflection-ом добавить/убрать элемент в эту динамическую коллекцию. Если циклы for/foreach не будут проверять размер обходимой коллекции — должны получить нативную ошибку (этот факт проверю в неуправляемом коде, не натыкался раньше).

lair
30.08.2016 23:18Нет, не может.
Mingun
30.08.2016 23:25А почему?
lair
30.08.2016 23:34Потому что на момент JIT-компиляции (а оптимизация происходит именно тогда) jitter понятия не имеет, что происходит с объектом за пределами метода. Возможно, если объект локален для метода и никуда не передается (в бенчмарках в посте — не так) — можно было бы сделать такую оптимизацию, но для этого надо точно знать, что происходит внутри вызываемых методов коллекций (откуда CLR знать, что то, что лежит за этим
IListне является генератором?), что тоже требует времени.

semenyakinVS
30.08.2016 19:57Помню-помню. В первый месяц работы в геймдевной компании закоммитил код с использование std::map и недоумевал за что мои изменения откатили обратно. Умный тимлид открыл глаза — и с тех пор знакомых удивляю этой информацией.
Если по делу, мне вот какая штука всегда была интересна… В Objective-C есть такая штука, как class cluster. Если коротко, идея их такая: под интерфейсом-фасадом публичного класса (например, NSNumber — класс, который хранит числа: как целые, так и с плавающей точкой) могут прятаться в качестве реализации универсального приватного интерфейса объекты разных приватных классов, оптимизированные под конкретный тип (например, для хранения интов, чаров, и т.д.). К чем я это…
Если взять такую идею и перенести её на коллекции вообще, то, как мне кажется, возможно выделить основные поведения для групп коллекций — например, достаточно двух: «массив» и «словарь» — и сделать набор реализаций, оптимизированных под конкретный стиль работы с коллекцией. Больше вставок — в реализации список. Больше проходов по элементам — значит массив.
А дальше можно сделать либо автоматический выбор реализации в зависимости от стиля использования коллекции (теоретически — вплоть до сбора статистики использования коллекции во времени), либо дать пользователю возможность выбирать нужную реализацию вручную.
В плюсах такую фичу можно легко реализовать вообще без каких-либо потерь на динамическом полиморфизме — с помощью шаблонов.
slonopotamus
30.08.2016 20:46+1Что не так с std::map?
semenyakinVS
30.08.2016 22:18Он с помощью дерева реализован, то есть с помощью «неплотной» (забыл как по-английски) структуры данных, с описанными в статье проблемами кеш-промахов. Если элементов относительно немного (у нас брали правило «не больше сотни»), то быстрее будет работать массив пар.
slonopotamus
30.08.2016 23:11Как показывает практика, от map'ов довольно редко нужна упорядоченность. Может вам бы подошел std::unordered_map (у нормальных людей это называется HashMap, но C++ — он такой)?
semenyakinVS
31.08.2016 00:38+1Да, std::unordered_map действительно лучше std::map в этом смысле. Как я понял, std::unordered_map организована как массив списков пар ключ-значение (список этот называется корзиной, как я понимаю), где индекс массива — хэш ключа, а список нужен чтобы бороться с коллизиями хэшей ключей. Таким образом получение значения по ключу требует прохода по «неплотной» структуре данных только в случае коллизии хеша ключа. При этом вместо реализации корзины с помощью списка можно использовать массив с реаллокацией при изменении размера (не знаю насколько имеет смысл в реальности...).
Интересно было бы сравнить быстродействие std::unordered_map и мапу, сделанную на базе std::vector как массив пар. Скорее всего, std::unordered_map будет обходить по скорости наивную реализацию с помощью std::vector на достаточно небольшом количестве элементов.
П.С.: Кстати, по поводу операций вставки и удаления в «плотных» структурах данных. Насколько я знаю, для оптимизаций ещё используется техника nondestructive удаления элементов, когда вместо удаления и сдвига элементов делается swap с «незанятым» элементом в выделенном блоке данных. Такой подход работает как раз в ситуациях, когда нас не интересует порядок элементов. В данном случае подойдёт.
Ссылки:
1. Ссылка на cppreference.
2. Весьма хорошая статья в блоге bannalia.

wataru
06.09.2016 11:11Ну это же очевидно. O-большое начинает работать только для больших значений n. Для маленьких значений гораздо чаще самая простая структура работает быстрее, чем сложная. Даже если у второй ассимптотика лучше. Потому что map требует, допустим, 100500*log(n) операций, а массив — 42*n. Map обгонит массив только для весьма больших n. Нужно всегда помнить о константе, спрятанной за O().
guzoff
01.09.2016 00:20динамический массив будет эффективнее связного списка пока вставок на порядок больше, чем проходов
Сперва подумал, что я чего-то не понимаю. Но потом заглянул в оригинал. У Вас ошибка в переводе: в оригинале стоит предлог «until», а не «while». То есть правильно: «динамический массив будет эффективнее связного списка до тех пор, пока вставок не станет на порядок больше, чем проходов».

paceholder
06.09.2016 11:53Оставлю видео по теме здесь. Мой коллега расказыавет на конференции про разнообразные структуры данных из стандартной библиотеки C++ и просит аудиторию угадать, что будет быстрее, а что медленнее, и далее показывает результаты. Видео на английком
https://www.youtube.com/watch?v=LrVi9LHP8Bk
Monnoroch
Вставка в динамический массив O(1). Потому у вас графики и параллельные вышли.
lair
… в начало-то?
Monnoroch
Да, с началом вы правы, мой bias против вставки в начало меня подвел, я даже не рассматривал подсознательно этот вариант :)
LifeKILLED
А зачем вообще вставлять в начало последовательного массива? Кто вообще будет так поступать? Обычно последовательность элементов вообще не имеет значения, перебирать ведь так или иначе придётся сразу все. Насчёт удаления из списка — тут тоже честное удаление не требуется, достаточно прописать в элементе «флаг» deleted=true, и просто пропускать его при переборе, а после N-ного числа удалений, так уж и быть, подчищать их. Ясное дело, что это заковыкистые хитрости, которые усложняют читабельность кода, но уж извините, оптимизации — они такие и есть. Их применяют с умом. И если тестировать самый неудачный вариант применения динамического массива, то какой прок от такого тестирования, если это по сути тест на криворукость?
Labunsky
Стоит учесть, что для вставки в произвольное место используется смещение с помощью memcpy и подобных, а не простой пробег for'ом. Не знаю, как именно оно работает в .Net, но даже при равной асимптотике, скорость может быть выше на порядок, отсюда и почти параллельные графики.
Viacheslav01
А чем memcpy отличается от пробега фором, каким он по сути и является.
Labunsky
Имелся в виду простой пробег for'ом на тестируемом языке. Да и есть разница. Например тем, что memcpy оперирует исключительно словами. Или тем, что реализован нативно, что дает ему нехилую прибавку в скорости, нежели он был бы реализован на том же C# внутри функции Insert.
LifeKILLED
Если брать C/C++, то суть такова:
http://stackoverflow.com/questions/4544804/in-what-cases-should-i-use-memcpy-over-standard-operators-in-c
В примере не for, а вообще ручное копированое без проверок, но вкрадце — другие ассемблерные команды, которых получается меньше, и они работают быстрее. В C# так сильно не углублялся и даже не знаю, есть ли подобные оптимизации в этом языке, но почему бы и нет?
Labunsky
В C# за это ответственна Arrays.Copy(), правда я немного ошибся с прогнозом, вместо memcpy оно использует свой аналог memmove. Разница не принципиальна, но это, в любом случае, более быстрый вариант, чем предполагается в статье.
Источник: https://msdn.microsoft.com/en-us/library/k4yx47a1(v=vs.110).aspx
Viacheslav01
Есть еще Buffer.BlockCopy, для тех же целей.
kmu1990
memcpy вызов стандартной библиотеки, которую обычно стараются оптимизировать с учетом особенностей различных архитектур/ОС. В частности, мне припоминается, что когда-то в glibc для какой-то хитрой ОС была оптимизация memcpy использующся интерфейс ОС для доступа к таблице страниц, т. е. вместо копирования целой страницы просто пару-тройку указателей в нужных местах прописали, в tlb запись для нужного адреса пофлашили и все. Гарантий, что memcpy будет быстрее чем рукописный цикл for, конечно, никто не дает, но без измерений заменять memcpy на что-то самописное вряд ли стоит.
Вот кстати парочка сслок про эту опитимзацию:
1. https://stuff.mit.edu/afs/sipb/project/hurddev/tb/libc/sysdeps/mach/pagecopy.h — код макроса, который собственно копирует страницы и вызывается из memcpy
2. https://sourceware.org/ml/libc-alpha/2014-01/msg00274.html — а это, похоже неудачная, попытка удалить эту оптимизацию из glibc (и хитрая ОС, похоже, это Hurd).
Viacheslav01
Согласный я, ступил, даже без экзотики, когда то давно я вполне себе использовал команду Z80 LDIR для копирования памяти, но вспомнил об этом после примера магии.
isotoxin
Не все объекты перемещаемы в памяти. std::vector, например, вообще считает что таких и вовсе нет (это разумное упрощение, т.к. копировать через конструктор копирования перемещаемые объекты безопасно, перемещать memcpy'ем неперемещаемые — быть беде). Так что memcpy там только в самых простых случаях и только если оптимизатор молодец. Поправьте знающие, но, вроде как в Qt (сам я знаком с этой библиотекой шапочно) динамический массив позволяет указывать признак перемещаемости, как раз с целью применять memcpy.
slonopotamus
А в чем проблема? Какая-то фундаментальная причина запрещает существование Array List'а который при ресайзе будет оставлять свободное место с *обеих сторон* от данных? Или такого, который хранит внутри себя элементы в обратном порядке?
MacIn
Зашел в комментарии, чтобы написать эту мысль. Делая resize, резервируем в начале, скажем, страницу памяти и пишем туда, пока не заполнится.
Можно сделать комбинированный контейнер: в пределах блока, скажем, страницы, данные хранятся как массив, сами блоки — произвольно с двунаправленными ссылками. Тогда и добавление в начало дешевое (выделили страницу, записали элемент в самый конец ее, связали ее с предыдущей первой страницей, потом при добавлении в начало идем по странице назад, как в стеке), и изменение размера дешевое, и проход по контейнеру не так плох — в пределах страницы данные будут в кеше, мисс один, когда переходим на следующую.
slonopotamus
Ну по сути ваш вариант — это LinkedList, затюненый под жизненные реалии (Random Access Memory вопреки своему названию существенно лучше работает при последовательном доступе). При N много большем чем размер страницы big-O у них (классический LinkedList vs. ваш вариант) одинаковый.
MacIn
Именно, ведь об этом и идет речь в статье.
Да, но если говорить о последовательном переборе, то… «жизненные реалии». Плюс дешевая вставка.
lair
Фундаментальная — не запрещает. Но в .net реализовано не так.
mird
Ну рассмотрите вставку не в начало, а в самую середину. Все равно получите O(n). Динамический массив — он такой. В него можно вставить значение в любое место.
MacIn
Вариант со связанными блоками (см. https://habrahabr.ru/post/308818/#comment_9779616) — если поддерживать заполненность блоков на уровне меньше 1, то сдвиг будет не более половины размера блока, который фиксирован. Или выделение новой страницы и связка ее. Поиск методом дихотомии все равно на ранних стадиях будет скакать по памяти, будть то список блоков или единый массив.
mird
Можно и так. Только, во первых по памяти вы проиграете, а во вторых, константы в ассимптотическом анализе увеличатся (из-за логики по определению какой блок, в какую сторону сдвигаем и т.п.) Ну и да, с уменьшением размера блока структура все больше походит на linked list
MacIn
Тут уж как в золотом законе механики.
Верно, но при последовательном просмотре у нас все так же элементы попадают в кэш — раз, меньше выгрузки-загрузки страниц памяти — два.
Размер блока можно задать, это не вопрос.
lair
Подождите, а какая в "варианте со связанными блоками" стоимость доступа к произвольному элементу? Разве O(1)?
MacIn
А кто говорит про произвольный доступ? Разумеется, доступ дорогой — O(n). У разных контейнеров свои задачи, плюсы и минусы. Здесь конкретно дешевый проход насквозь, удаление и вставка. Поиск дихотомией чуть дороже чем в массиве, потому что надо сначала отобрать блок, потом делать поиск внутри массива в блоке, а количество блоков зависит не только от n, но и от самих данных, количества вставок и удалений. Т.е. под какие-то задачи — вполне себе компромисс.
lair
… тогда это не динамический массив, а хитрый вариант связанного списка. Это само по себе не плохо, но просто не та структура, с которой разговор начался.
И да, я действительно могу себе представить задачи, где эта структура полезна.
MacIn
Это не список, и не массив, это гибрид, потому что в пределах блока мы все же имеем возможность произвольного доступа за O(1) — это означает, например, что мы можем производить поиск разбиением пополам внутри блока так же быстро, как на массиве.
mird
Вставка в середину у вас по факту не слишком дешевая. Не О(1) и даже не O(размер блока).
Потому что блок вам надо еще найти (видимо перебирая блоки подряд). То есть у вас будет что-то вроде O(n/размер блока)+O(размер блока) что, внезапно, эквивалентно O(n).
MacIn
Это можно улучшить, вводя вспомогательные структуры и вопрос будет решаться уже не по ассимптотике, а по константам (статья как раз об этом). Хотя и по ассимптотике — если взять тот же массив указателей на блоки, его придется двигать только при создании блока, а поиск будет логарифмический.
freetonik
В лучшем случае. В худшем — O(n).
JeStoneDev
O(f(n)) определяет верхнуюю границу сложности алгоритма (т.е. наихудший случай для алгорима), так что не имеет значение в начало или конец массива производится вставка, верхняя граница сложности будет O(n).
Для лучшего случая (т.е. нижней границы сложности алгоритма) есть свое обозначение через ?, про которое все всегда забывают.
quantum
Почему О(1)? Вставка не в конец, а в произвольную позицию со сдвигом