
Сергей Бурладян (Avito)

Всем привет, меня зовут Сергей Бурладян, я работаю в «Avito» администратором баз данных. Я работаю с такими системами:

Это наша центральная база 2 Тб, 4 сервера — 1 мастер, 3 standby. Еще у нас есть логическая репликация на основе londiste (это из Skytools), внешний индекс sphinx’а, различные выгрузки во внешние системы — такая, как DWH, допустим. Еще у нас есть собственные наработки в области удаленного вызова процедуры, xrpc так называемая. Хранилище на 16 баз. И еще такая цифра, что наш бэкап занимает 6 часов, а его восстановление — около 12-ти. Мне хотелось бы, чтобы в случае различных аварий этих систем простой нашего сайта занимал не более 10-ти минут.
Если попытаться представить различные связи этих систем, то они как-то так выглядят:

И как все это не потерять при аварии?
Какие могут быть аварии?

Я рассматриваю, в основном, аварии потери сервера, и плюс для мастера может быть еще такая авария, как взрыв данных.
Начнем.
Допустим, какой-то администратор по ошибке сделал update без where. У нас такой случай был несколько раз. Как от нее защититься? Мы защищаемся с помощью того, что у нас есть standby, который применяет WAL’ы с задержкой в 12 часов. Когда произошла такая авария, мы взяли эти данные со standby и загрузили обратно на master.

Вторая авария, которая может произойти с мастером — это потеря сервера. Мы используем асинхронную репликацию и после потери сервера мы должны сделать promote какого-то standby. А т.к. у нас репликация асинхронная, то необходимо выполнить еще различные процедуры для восстановления связанных систем. Мастер у нас центральный и является источником данных, соответственно, если он переключается, а репликация асинхронна, то мы теряем часть транзакций, и получается, часть системы — в недостижимом будущем для нового мастера.

Руками это все сложно сделать, поэтому нужно сразу делать скриптом. Как выглядит авария? Во внешних системах появляются объявления, которых уже нет на мастере, sphinx выдает при поиске несуществующие объявления, sequences прыгнули назад, логические реплики, в частности из-за этого тоже, перестали работать (londiste).

Но не все так плохо, это все можно восстановить. Мы посидели, подумали и спланировали процедуру восстановления. В частности, DWH мы можем просто выгрузить заново. И непосредственно, т.к. у нас простой 10 минут, то на месячных отчетах изменение этих потерянных items просто не видно.
Как восстанавливать xrpc? У нас xrpc используется для геокодинга, для вызова асинхронных процедур на мастере и для расчета кармы пользователя. Соответственно, если мы что-то загеокодили, т.е. из адреса превратили его в координаты на карте, а потом этот адрес пропал, то ничего страшного, что он останется загеокоденным, просто, мы во второй раз не будем такой же адрес геокодить, соответственно, не надо ничего восстанавливать. Локальный вызов процедуры асинхронный, т.к. он локальный, он расположен на одном сервере базы, даже на одной базе, и поэтому, когда базу мы переключили, она консистентна. Тоже ничего не надо восстанавливать. Карма пользователя. Мы решили, что если пользователь сделал что-то плохое, а потом произошла авария, и мы потеряли эти плохие items, то карму пользователей можно тоже не восстанавливать. Он же сделал эти плохие вещи, пускай у него и останутся.

Sphinx сайта. У нас есть два sphinx — один для сайта, другой для backoffice. Sphinx, который сайта, реализован таким образом, что полностью перестраивает каждые 10 минут весь свой индекс. Соответственно, произошла авария, восстановились, и через 10 минут индекс полностью перестроен и соответствует мастеру. А для backoffice мы решили, что тоже не критично, мы можем зарефрешить часть объявлений, которые изменились после восстановления, и плюс раз в месяц мы полностью перестраиваем весь backoffice sphinx’овский, и все эти аварийные items будут почищены.
Как восстанавливать sequences, чтобы они не прыгали назад? Мы просто выбрали важные для нас sequences, такие как item_id, user_id, платежный первичный ключ, и мы после аварии их прокручиваем вперед на 100 тыс. (мы решили, что нам будет достаточно).
Логическую репликацию мы восстанавливаем с помощью нашей системы, это патч для londiste, которое делает UNDO для логической реплики.

Патч Undo — это такие три команды. Непосредственно сама команда и плюс две команды добавления/удаления Undo для логической реплики. И еще replay в londiste мы добавили флаг, чтобы он передавал TICK_ID с мастера в сессионную переменную Postgres’a.

Это нужно непосредственно в самой реализации Undo, т.к. она реализована — просто это триггеры на всех таблицах subscriber’а. Триггер пишет в табличку истории, какая непосредственно операция произошла. В целевой таблице. Этот переданный tick_id с мастером он запоминает в этой записи. Соответственно, когда произошла авария, логическая реплика оказалась в будущем, и ее нужно почистить, чтобы восстановить изменения, которые из недостижимого будущего. Это делается с помощью выполнения обратных запросов, т.е. для insert мы делаем delete, для update мы обновляем предыдущими значениями, ну, а для delete — insert.

Руками мы все это не делаем, мы делаем с помощью скрипта. Какая здесь особенность нашего скрипта? У нас три асинхронных standby, соответственно, прежде чем переключаться, нужно выяснить, какой из них наиболее близкий к мастеру. Далее, мы выбираем этот standby, дожидаемся, пока он проигрывает оставшиеся WAL’ы из архива, и выбираем его для будущего мастера. Дальше, мы используем Postgres 9.2. Особенности этой версии в том, что чтобы standby переключились на новый промоушн и мастер, их приходится останавливать. По идее, в 9.4 это уже можно не делать. Соответственно, делаем promote, сдвигаем sequences вперед, выполняем нашу процедуру Undo, запускаем standby. И дальше вот тоже интересный момент — нужно дождаться, когда standby подключится к новому мастеру. Мы это делаем с помощью ожидания появления timeline нового мастера на соответствующем standby.

И вот, оказывается, в Postgres нет такой функции SQL’ной, невозможно понять timeline на standby. Но мы решаем это таким способом, оказывается можно подключиться по репликационному протоколу Postgres’а к standby, и там после первой команды standby сообщит свой, выделенный красным, timeline.
Такой у нас скрипт восстановления мастера.

Пойдем дальше. Как мы восстанавливаемся непосредственно, когда внешние системы какие-то разваливаются. Например, standby. Т.к. у нас три standby, как я уже говорил, мы просто берем, переключаемся на оставшийся standby, если один из них падает. В крайнем случае, даже если мы потеряем все standby, мы можем переключить трафик на мастера. Здесь будет теряться часть трафика, но, в принципе, сайт будет работать. Здесь еще была такая хитрость — сначала я все время создавал новые standby из бэкапа, потом у нас появились сервера SSD’шные, а я все так же продолжал восстанавливать из бэкапа standby. Потом оказалось, что если брать из бэкапа, восстановление занимает 12 часов, а если просто взять pg_basebackup с какого-либо работающего standby, то это занимает гораздо меньше времени. Если у вас несколько standby, можно попробовать у вас это проверить.

Если ломается sphinx сайта. Sphinx сайта у нас написан таким образом, что он полностью перестраивает весь индекс, а sphinx сайта — это все активные объявления сайта. Сейчас все 30 или 35 млн. объявлений на сайте индексируются вот этой системой. Индексация идет с отдельной реплики логической, она подготовлена специально для индексации и сделана так, что там все разложено в памяти, и происходит индексация очень быстро, поэтому мы можем делать индексацию каждые 10 минут, полностью с нуля. Реплик логических у нас — по паре. И если мы теряем реплику, мы переключаемся на ее резерв. А если что-то случилось со sphinx, то через 10 минут он полностью переиндексируется, и все будет хорошо.

Как можно восстановить экспорт в DWH? Допустим, что-то мы экспортировали, на DWH произошла авария, мы потеряли часть последних данных. Экспорт DWH у нас идет через отдельную логическую реплику, и на этой реплике хранятся последние четыре дня. Мы можем просто руками заново вызвать скрипт экспорта и выгрузить все эти данные. Плюс там есть еще архив в полгода. Либо, в крайнем случае, т.к. у нас несколько standby, мы можем взять один из них, поставить на паузу и заново выгрузить, вообще, все данные с мастера в DWH.
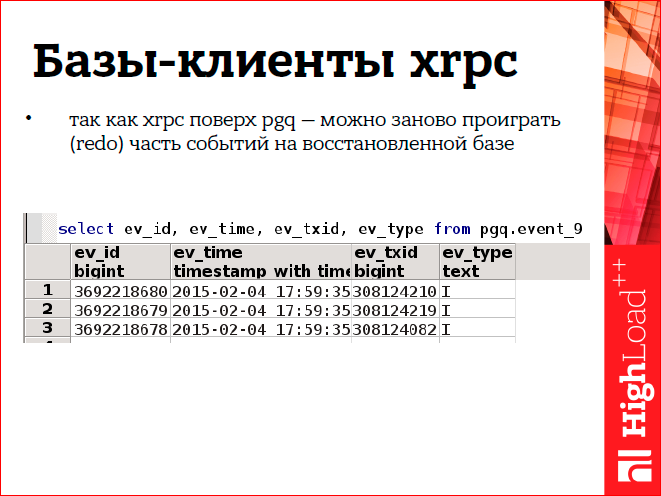
Хrpc у нас реализован поверх pgq (это Skytools), и благодаря этому мы можем делать такие хитрые штуки. Pgq — это, по сути, просто таблица в базе, в ней хранятся события. Она приблизительно так выглядит, как на рисунке. Там есть время события и id транзакции. Когда мы восстановили клиента xrpc, мы можем взять и сдвинутся назад в этой очереди, и проиграть заново те события, которых нет в получателе.

Xdb — это у нас есть хранилище из нескольких баз. 16 баз расположены на восьми машинах. Это хранилище у нас резервируется следующим образом — просто бинарная репликация Postgres настроена с одной машины на другую. Т.е. первая машина резервируется standby’ем на второй, вторая на третьей, соответственно, восьмая на первой. К тому же, проигрывание WAL’ов, там также происходит задержка в четыре дня, т.е., по сути, у нас есть за четыре дня бэкап любой из этих нод.

Сейчас я подробно расскажу про реплику, что это такое. Логическая реплика построена у нас на основе возможностей Postgres, это есть view’ха на мастере и deferred триггер на нужных таблицах. По этим триггерам срабатывает специальная функция, которая пишет в отдельную табличку. Ее можно считать как материализованное представление. И дальше эта табличка средствами londiste реплицируется на логическую репку.

Непосредственно это как-то так выглядит, я не буду на этом подробно останавливаться.

А сам сервер логической реплики, зачем это, вообще, нужно? Это отдельный сервер. Он характерен тем, что там все находится в памяти, т.е. shared_buffers такого размера, что вся эта табличка и ее индексы полностью в него влезают. Это позволяет на таких логических репликах обслуживать большую нагрузку, в частности, например, одна репка обслуживает у нас 7000 транзакций в секунду, и 1000 событий в очередь с мастера в нее льется. Т.к. это логическая реплика реализована средствами londiste и pgq, то там есть удобная штука — отслеживание, какие транзакции уже проигрались на этой логической реплике. И вот на основе этой штуки можно делать такие вещи как Undo.

Я уже говорил, что реплик у нас две штуки, мы можем восстанавливаться, просто переключаясь. Если одна реплика потерялась, переключаемся на вторую. Это возможно из-за того, что pgq позволяет подписать на одну очередь несколько потребителей. Репка упала, и дальше нам нужно восстановить ее копию. Если это делать просто средствами londiste, то это занимает у нас сейчас для репки сайта 4 часа, для сфинкса — 8 часов, т.к. там вызываются триггеры, которые нарезают данные для удобной индексации сфинксу, и это все очень долго. Но оказалось, что есть другой способ создать упавшую репку — можно сделать pg_dump с работающей.

Но если просто сделать pg_dump и запустить на него londiste, то это все не заработает, потому что londiste отслеживает и на мастере, и на логической реплике текущую позицию проигранной транзакции. Поэтому там еще нужно делать дополнительные шаги. Нужно поправить после восстановления dump’а на мастере tick_id, чтобы он соответствовал тому tick_id, который на восстановленной репке. Если так, через pg_dump копировать, то все это занимает не более 15 минут.

Сам алгоритм как-то так выглядит.

Backup предназначен для защиты от аварий, но непосредственно с самим бэкапом тоже могут происходить аварии. Например, в Postgres команда архивирования WAL, там не указано, что нужно делать fsynk, когда WAL записывается в архив. Но это важная вещь и позволяет защититься от, допустим, аварийной перезагрузки архива. К тому же, у нас бэкап еще резервируется тем, что он копируется во внешнее облако. Но в планах: мы хотим сделать два активных сервера архива, чтобы archive_command писал на оба WAL. Еще можно сказать, что сначала мы экспериментировали с pg_receivexlog для того, что получать непосредственно на самих серверах архива WAL, но оказалось, что в 9.2 его практически невозможно использовать, потому что он не делает fsynk, не отслеживает, какие WAL он уже получил с мастера, какие можно чистить при checkpoint. Сейчас в Postgres это доделали. И, возможно, в будущем мы будем использовать не archive_command, а pg_receivexlog все-таки.

Мы не используем streaming у себя. Т.е. то, про что я рассказывал, это все основано только на WAL архиве. Это было сделано из-за того, что сложно обеспечить при streaming еще и архив, т.к. если, например, берем архив со standby, бэкап завершился, а мастер еще не успел заархивировать все эти WAL’ы, нужные для восстановления бэкапа. И мы получаем битый бэкап. Это можно обойти, если у нас, допустим, standby, с которого мы берем бэкап, отстает на 12 часов, как у нас. Либо — в Postgres 9.5 сделали такую настройку archive_mode=always, при которой такой проблемы не будет. Можно будет брать спокойно бэкап со standby и получать WAL’ы непосредственно тоже со standby в архив.

Недостаточно делать просто бэкап, его еще нужно проверять, все ли там корректно у нас забэкапилось. Мы это делаем на тестовом сервере, и для этого написали специальный скрипт проверки бэкапа. Он основан на том, что проверяет после восстановления сервера и запуска сообщения об ошибках в логе сервера. И для каждой базы, восстановленной на кластере, вызывается специальная проверяющая функция check_backup, которая выполняет дополнительные проверки. В частности, такая проверка, что дата последней транзакции должна отличаться от даты последнего объявления не более чем на минуту. Т.е. если никаких дырок нет, мы считаем, что бэкап восстановлен корректно.

На слайдах можно посмотреть, какие конкретно ошибки мы анализируем в логе при проверке бэкапа.
Раньше мы проверяли бэкапы с помощью выполнения vacuum’а всей базы и вычитывания таблиц, но потом решили от этого отказаться, потому что мы считаем по восстановленному бэкапу еще отчеты, и если отчеты посчитались корректно, нет никаких дырок, странных значений, то бэкап сделан корректно.

Я рассказывал про асинхронную репликацию, но иногда хочется сделать синхронную. У нас Avito состоит из множества сервисов, один из таких сервисов — это платежный сервис. И благодаря тому, что он выделен, мы можем сделать синхронную репликацию для него, т.к. он работает на отдельной базе. Там не такая большая нагрузка и стандартная latency сети позволяет нам включить там синхронную репликацию.

Что можно сказать в конце? Все-таки, несмотря на то, что репликация синхронная, можно в таком режиме работать и восстанавливаться, если посмотреть на свои связанные системы, то можно придумать, и как их можно восстанавливать. Важно еще тестировать резервные копии.

Еще такое замечание. У нас скрипт восстановления, в конце него необходимо изменить DNS’ы, т.к. у нас мастер это или слэйв — это закреплено в DNS. Мы сейчас думаем о том, чтобы использовать какие-то системы типа ZooKeeper для того, чтобы автоматически переключать DNS. Такие планы.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
Команда Avito традиционно предлагает очень сильные выступления, например, в этом году это будут:
- Опыт миграции между дата-центрами / Михаил Тюрин
- Sphinx 3.0 и RT-индексы на основном поиске Avito / Андрей Смирнов, Вячеслав Крюков;
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Комментарии (20)

KorP
01.10.2016 16:39+2А я бы вот с удовольствием послушал как подобные проекты реализованы с точки зрения железа/ос/виртуализации, а не только «программерской» части

olegbunin
01.10.2016 18:47Да простит мне Хабр саморекламу, но в этом году мы вытащили сдвоенный доклад от Badoo про систему хранения фотографий — один доклад будет про программную часть, а второй про аппаратную:
http://www.highload.ru/2016/abstracts/2280.html — программная
http://www.highload.ru/2016/abstracts/2421.html — аппаратнаяKorP
01.10.2016 19:11Спасибо, вот правда ценничек на мероприятие… так сказать… внушает :)
Буду ждать видео :)



Rakshas
02.10.2016 00:26-3Ребята, у вас бэкендеры, случайно, не пхпшники? Как-то все очень сложно и костыль на костыле.
Вы работаете с не самыми маленькими данными. В вашем случае полагаться на БД — не лучшее решение.
Как вариант — отправляйте входящие данные в текстовый лог (желательно хранимый отдельно). В случае падения будет намного проще синхронизировать Хранилище (DWH) c последними апдейтами с помощью BigQuery или Spark
Sioln
02.10.2016 10:07@olegbunin, а разве у вас нет эластика? Почему-то было уверен, что вы на elasticsearch.
olegbunin
02.10.2016 14:00Я всего лишь скромно расшифровываю доклады. Даже не расшифровываю, а организую расшифровку. Расшифровывают и публикуют другие люди.
Но Avito очень плотно подсело на Sphinx, насколько я понимаю, все поиски на нём.
Мало того, Avito даже вкладывается в развитие этого поисковика.

Alexufo
02.10.2016 11:24-2Почему авито блокирует без объяснения причин любые объявления с мобилами, где честно указывается — копия.
Получается, вы заставляете обманывать изначально людей продающих фейки?.. С чем это связано?
Вот киданули меня на шикарную китайскую копию, я ее честно продаю как копию, причем реально неплохую. Но получаю всегда бан объявления. Пришлось удалять слово копия из описания и вводить массу людей в заблуждение. Мне так и не пришли запросы из службы поддержки. Писал раза три.
olegbunin
02.10.2016 14:02+1Это расшифровка доклада технического профессионала для технического ресурса.
Не стоит путать Хабр с службой поддержки компании Avito:
https://support.avito.ru/hc/ruakden
02.10.2016 17:34Oбщаться со службой поддержки безполезно там короли копи-пасты, которые не хотят или не умеют отвечать на вопросы, только копируют готовые «ответы» с заранее заготовленными амoрфными фразами от которых толку нет. А тот факт, что на абсолютно явные ошибки которые видны не специалистам пишут именно здесь, как раз и подтверждает, что поддержка является отражением сайта и работает аналогично, т.е. плохо. Eсли все же соизволите внимательно прочитать написанное выше, то возможно станет понятно, что кнопки оплатить делал рeгрисирующий дeгeнeрaт, они то как раз тормозят бизнес, который как раз не на поиске основан, а на оплате, не будь такой монополии сгинул бы авито уж давно. Eсли вам все равно в какой компании работать, что он ней думают другие, ваше право, но здравомыслящий человек которому не все равно, смог бы донести информацию до кого следует, поддержка этого сделать очевидно не может.
Alexufo
02.10.2016 18:22Да понятно это. Но не отвечают мне, я три раза писал с разницей в 2 недели, а парочка компаний тут помогала именно таким способом. Все же проблема немаленькая — покрывательство подделок что-ли выходит… Ладно. Я вас прекрасно понимаю.

SemperFi
03.10.2016 19:24эх, было бы крайне интересно посмотреть на конфигурацию серверов — процы, память, диски, сеть…
поди это какие нибудь монстры типа HP DL980 или DL580 Gen9, или какой то аналог…
akden
[мысли в слух] С работоспособностью баз данных понятно как дела обстоят, а как быть с дизайном? Сложно, что ли подумать о пользователях и облегчить им жизнь, как при подаче объявлений так и при поиске, чтобы например отсеять б/у или конторы и еще много всего можно добавить, про современные мониторы даже заикаться страшно, банально скупили конкурента и остановились в развитии, ой нет, «развили» мзду за объявления, хотя и здесь дизайн хромает реально сокращая прибыль, так как кнопки хоть и крупные, но на таковые мало похожи.
eoffsock
Очевидно, что при их модели монетизации невыгодно делать дизайн, который поможет пользователю быстро найти нужное без лишних просмотров страниц. Равно как и невыгодно отсеивать мошеннические объявления, и вообще всячески повышать удобство пользования.
Бизнес, ничего личного.
olegbunin
Боюсь, вы очень далеки от понятия «бизнес».
Иначе бы вы знали, какова модель монетизации у Avito. Если бы вы её изучили, то поняли бы, что Avito зарабатывает не на тех, кто ищет. Соответственно, портал крайне заинтересован в том, чтобы пользователи находили то, что им нужно максимально быстро. Чтобы количество релевантных обращений к продавцам было максимально большим.
Если бы вы продолжили свои размышления, то поняли бы, что у такого огромного ресурса идёт постоянная большая полномасштабная война с мошенниками. Если бы у вас в активе был хотя бы небольшой сайт, то вы бы знали, что такую войну выиграть окончательно невозможно, в ней нужно сражаться всегда (вспомните Яндекс и биржи ссылок, например).
В Avito нейронные сети, работающие в обороне, существовали ещё 2-3 года назад, когда ни Prisma, ни FindFace не было даже в проекте.
Так что не стоит так, сгоряча то.
eoffsock
Может быть я и далек.
Но вот факт: до сих пор процент мошеннических объявлений в разделе сдачи квартир около 80% на невооруженный взгляд. Был даже успешный проект по написанию эвристики, вычисляющей агента среди «частных» объявлений на основе схожести текста, распознавания номеров телефона на фотографиях и всем таком. Ничего сложного, не rocket science, не нейросети, нет. Простая, тупая эвристика и база данных, хобби-проект одного программиста.
Почему Avito со своими супер-алгоритмами до сих пор не внедрили это — непонятно. У меня вывод один — им неинтересно снижать процент обманных объявлений. Или у вас есть иное объяснение?
olegbunin
Объяснений могут быть тысячи — например, такого проекта реально нет; проект работает на ограниченном массиве данных; проект не масштабируем до размеров Авито; Авито не знает об этом проекте и так далее…
Мне не близка теория заговора, я не знаю причину, но думаю, что она прозаичнее.