
DDD. Выводы
- ОЧЕНЬ дорого
- Работает хорошо в устоявшихся бизнес-процессах
- Иногда – это единственный способ сделать то, что нужно
- Плохо масштабируется
- Сложно реализовать в высоконагруженных приложениях
- Плохо работает в стартапах
- Не подходит для построения отчетов
- Требует особого внимания с ORM
- Слова Entity лучше избегать, потому что его все понимают по-своему
- С LINQ стандартная реализация Specification «не работает»
Очень дорого
Все руководители разработки, применяющие DDD, с которыми я обсуждал тему, отметили «дороговизну» этой методологии, в первую очередь из-за отсутствия в книге Эванса ответов на практические вопросы «как мне сделать FooBar, не нарушая принципов DDD?».
Самый распространенный в гугл-группе CQRS, вопрос по словам Грега Янга: «Босс просит меня построить годовой отчет. Когда я поднимаю в оперативную память все корни агрегации у меня начинает все тормозить. Что мне делать?». На этот вопрос есть очевидный ответ: «нужно написать SQL-запрос». Однако, написание ручного SQL-запроса – это однозначно против правил DDD.
Сам Эванс согласился с Янгом в том, что книгу следовало бы написать в другом порядке. Ключевыми являются концепции Bounded Context и Ubiquitous Language, а не Entity и ValueObject.
Отчеты не нуждаются доменной модели. Отчет – это просто таблица с данными. Data Driven – гораздо лучше подходит для отчетов, чем Domain Driven. На первый взгляд в этот момент нужно сказать DDD sucks. Однако, это не так. Просто применение DDD для построения отчетов – не верный Bounded Context.
Bounded Context
Самый важный тезис DDD – не следует пытаться разрабатывать одну большую доменную модель для всего приложения. Это слишком сложно и никому не нужно. Создать одну доменную модель для всего приложения возможно, только если на уровне управления компанией принято решение о том, что все отделы используют единую терминологию и понимают все бизнес-процессы одинаково.
Entity все понимают по-своему
Мы убедились в том, что очень сложно договориться со всеми членами команды о терминологии. Камнем преткновения стал термин Entity: мы пытались использовать интерфейс IEntity<TKey>, однако быстро поняли, что Id могут использовать и ValueObject’ы для передачи команд. Использование IEntity<TKey> для таких объектов путало людей, и мы отказались от IEntity в пользу IHasId.
DDD требует особого внимания с ORM
На Stack Overflow довольно много обсуждений NHibernate vs Entity Framework for DDD. NHibernate, в целом, справляется лучше, но проблем остается много. Стандартный подход при использовании ORM – использование беспараметрических конструкторов и установка значений через сеттеры свойств. Это разлом инкапсуляции. Есть определенные проблемы с коллекциями и Lazy Load. Кроме этого, команда должна принять решение о том, где заканчивается «домен» и начинается «инфраструктура» и как обеспечить Persistence Ignorance.
С LINQ стандартная реализация Specification «не работает»
Эванс – человек из мира Java. Кроме этого книга была написана достаточно давно.
public abstract class Specification<T>
{
public abstract bool IsSatisfiedBy(T entity)
};
Этот интерфейс позволяет работать с коллекциями в памяти, но никак не подходит для построения SQL-запросов. В современном C# больше подходит такой вариант:
public abstract class Specification<T>
{
public bool IsSatisfiedBy(T item)
{
return SatisfyingElementsFrom(new[] { item }.AsQueryable()).Any();
}
public abstract IQueryable<T> SatisfyingElementsFrom(IQueryable<T> candidates);
}
Область применения
Моделирование предметной области – не простая задача. DDD предполагает делегирование части задач по аналитике разработчикам. Это оправдано в случаях, когда стоимость ошибки велика. Не важно, как быстро вы написали код и как быстро работает ваша система, если она работает не верно, и вы теряете деньги. На самом деле, верно обратное – если вы разрабатывает ПО для HFT и до конца не понимаете, как оно должно работать, лучше, чтобы ваше ПО тормозило или вообще не работало. Так вы по крайней мере не будете терять деньги на супер-быстром, но не верном трейдинге :)
В неустоявшихся бизнесах (особенно стартапах) часто нет никакого понимания предметной модели. Все может меняться ежедневно. В этих условиях бесполезно требовать от участников бизнес-процесса использовать единую терминологию.
CQRS
Вывод очевиден: DDD – не «серебряная пуля», а жаль:) Однако, можно получить значительный выигрыш за счет «точечного применения» DDD в определенных Bounded Context.
В 1980 Бертран Мейер сформулировал очень простой термин CQS. В начале двухтысячных Грег Янг расширил и популяризовал эту концепцию. Так появился CQRS… и CQRS во многом повторил судьбу DDD, в том, смысле, что был неоднократно не верно истолкован.
Несмотря на то, что материалов по CQRS в интернете предостаточно, все «готовят» его по-разному. Многие команды используют принципы CQRS, хотя не называют это так. В системе может не быть абстракций Command и Query. Их Может заменить IOperation или даже Func<T1, T2> и Action<T>.
Этому есть простое объяснение. Первые результаты по запросу CQRS выдают нечто вроде изображения ниже:
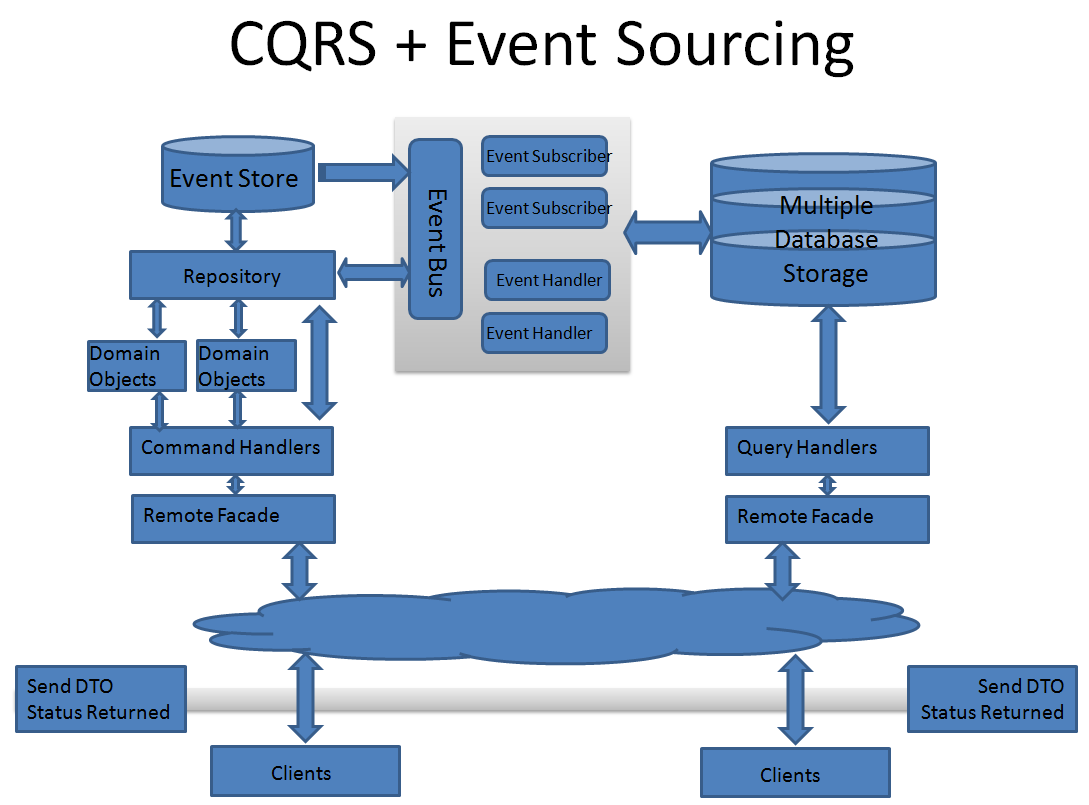
Эту реализацию Дино Эспозито называет DELUXE. Дело здесь в том, что CQRS интересует Грега Янга в основном в контексте Event Sourcing. На самом деле для Event Sourcing необходимо использовать CQRS, но не наоборот.
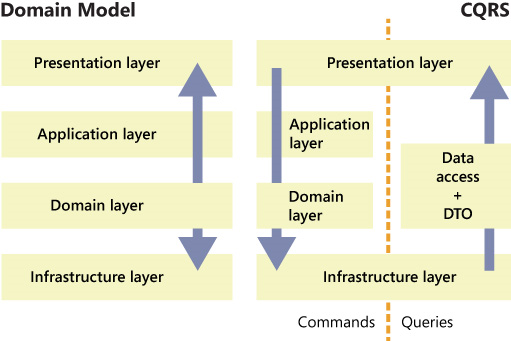
Таким образом, используя CQRS мы можем решить проблему тормозных отчетов, разделив стеки приложения на Read и Write и не используя Domain Model в Read-стеке. Read-стек может использовать другую БД и/или другое более оптимальное API доступа к данным.
Разделение приложения на команды, обработчики и запросы имеет еще одно преимущество: лучшая прогнозируемость. В случае DDD, чтобы знать где искать ту или иную бизнес-логику необходимо понимать предметную область. В случае CQRS программист всегда знает, что запись происходит в обработчиках команд, а для доступа к данным используются Query. Кроме этого есть еще несколько не очевидных, на первый взгляд, плюсов. Их мы рассмотрим ниже.
CQRS основные выводы
- Event Sourcing требует CQRS, но не наоборот
- Дешево
- Подходит везде
- Масштабируется
- Не требует 2 хранилища данных. Эта одна из возможных реализаций, а не обязаловка
- Обработчик команды может возвращать значение. Если не согласны спорьте с Грегом Янгом и Дино Эспозито, а не со мной
- Если обработчик возвращает значение он хуже масштабируется, однако есть async/await, но надо понимать как они работают
Основные интерфейсы в CQRS могут выглядеть так:
[PublicAPI]
public interface IQuery<out TOutput>
{
TOutput Ask();
}
[PublicAPI]
public interface IQuery<in TSpecification, out TOutput>
{
TOutput Ask([NotNull] TSpecification spec);
}
[PublicAPI]
public interface IAsyncQuery<TOutput>
: IQuery<Task<TOutput>>
{
}
[PublicAPI]
public interface IAsyncQuery<in TSpecification, TOutput>
: IQuery<TSpecification, Task<TOutput>>
{
}
[PublicAPI]
public interface ICommandHandler<in TInput>
{
void Handle(TInput input);
}
[PublicAPI]
public interface ICommandHandler<in TInput, out TOutput>
{
TOutput Handle(TInput input);
}
[PublicAPI]
public interface IAsyncCommandHandler<in TInput>
: ICommandHandler<TInput, Task>
{
}
[PublicAPI]
public interface IAsyncCommandHandler<in TInput, TOutput>
: ICommandHandler<TInput, Task<TOutput>>
{
}
Мы договорились о том, что:
- Query всегда только получает данные, но не изменяет состояние системы. Для изменения системы используются команды
- Query могут возвращать необходимые проекции на прямую, в обход доменной модели
В этом случае в отсутствии команд все Query всегда возвращают одинаковые результаты на одинаковых входных данных. Такая организация сильно упрощает отладку, потому что в Query нет состояния, которое могло бы изменить возвращаемый результат.
При необходимости Audit Log или полноценный Event Sourcing можно подключить ко всем обработчикам команд, через базовый класс.
Не трудно заметить, что основные интерфейсы CQRS можно привести к Func<T1, T2> и Action<T>. Добавьте stateless и immutable, и вы получите чистые функции (привет функциональное программирование;) Строго говоря, это конечно не так, потому что большинство Query будут работать с файловой системой, БД или сетью. Вы также наверняка захотите закешировать результаты выполнения Query, однако пользу от линеаризации data-flow и компонуемости получить можно.
CQRS over HTTP
Принципы CQRS очень хорошо подходят для реализации по протоколу HTTP. Спецификация HTTP четко говорит GET-запросы должны возвращать данные с сервера. POST, PUT, PATCH – изменять состояние. Хорошим тоном в web-программировании считается редирект на GET после выполнения POST-операции, например, сабмита формы.
Итак
- GET– это Query
- POST/PUT/PATCH/DELETE – это Command
Базовые классы для часто используемых операций
Отчеты – не единственная частая задача чтения данных. Более общее определение типовых операций чтения это:
- Фильтрация
- Пагинация (постраничный вывод)
- Создание проекций (представление агрегатов в необходимом на клиентской стороне виде)
Мы активно используем AutoMapper для построения проекций. Одной из отличительных особенностей этого маппера являются Queryable-Extensions: возможность построить Expression для преобразования в SQL, вместо маппинга в оперативной памяти. Не всегда эти проекции точны и производительны, но для быстрого прототипирования подходят идеально.
Для постраничного вывода из любой таблицы в БД и поддержкой фильтрации можно использовать всего одну реализацию IQuery.
public class ProjectionQuery<TSpecification, TSource, TDest>
: IQuery<TSpecification, IEnumerable<TDest>>
, IQuery<TSpecification, int>
where TSource : class, IHasId
where TDest : class
{
protected readonly ILinqProvider LinqProvider;
protected readonly IProjector Projector;
public ProjectionQuery([NotNull] ILinqProvider linqProvier, [NotNull] IProjector projector)
{
if (linqProvier == null) throw new ArgumentNullException(nameof(linqProvier));
if (projector == null) throw new ArgumentNullException(nameof(projector));
LinqProvider = linqProvier;
Projector = projector;
}
protected virtual IQueryable<TDest> GetQueryable(TSpecification spec)
=> LinqProvider
.GetQueryable<TSource>()
.ApplyIfPossible(spec)
.Project<TSource, TDest>(Projector)
.ApplyIfPossible(spec);
public virtual IEnumerable<TDest> Ask(TSpecification specification)
=> GetQueryable(specification).ToArray();
int IQuery<TSpecification, int>.Ask(TSpecification specification)
=> GetQueryable(specification).Count();
}
public class PagedQuery<TSortKey, TSpec, TEntity, TDto> : ProjectionQuery<TSpec, TEntity, TDto>,
IQuery<TSpec, IPagedEnumerable<TDto>>
where TEntity : class, IHasId
where TDto : class, IHasId
where TSpec : IPaging<TDto, TSortKey>
{
public PagedQuery(ILinqProvider linqProvier, IProjector projector)
: base(linqProvier, projector)
{
}
public override IEnumerable<TDto> Ask(TSpec spec)
=> GetQueryable(spec).Paginate(spec).ToArray();
IPagedEnumerable<TDto> IQuery<TSpec, IPagedEnumerable<TDto>>.Ask(TSpec spec)
=> GetQueryable(spec).ToPagedEnumerable(spec);
public IQuery<TSpec, IPagedEnumerable<TDto>> AsPaged()
=> this as IQuery<TSpec, IPagedEnumerable<TDto>>;
}
Метод ApplyIfPossible проверит осуществляется фильтрация на уровне агрегата или проекции (бывает нужно и так и так). Метод Project создаст проекцию с помощью AutoMapper.
AutoFilter и Dynamic Linq могут помочь, если вы работает с большим количеством однотипных форм.
public static class AutoFilterExtensions
{
public static IQueryable<T> ApplyDictionary<T>(this IQueryable<T> query
, IDictionary<string, object> filters)
{
foreach (var kv in filters)
{
query = query.Where(kv.Value is string
? $"{kv.Key}.StartsWith(@0)"
: $"{kv.Key}=@0", kv.Value);
}
return query;
}
public static IDictionary<string, object> GetFilters(this object o) => o.GetType()
.GetTypeInfo()
.GetProperties(BindingFlags.Public)
.Where(x => x.CanRead)
.ToDictionary(k => k.Name, v => v.GetValue(o));
}
public class AutoFilter<T> : ILinqSpecification<T>
where T: class
{
public IDictionary<string, object> Filter { get; }
public AutoFilter()
{
Filter = new Dictionary<string, object>();
}
public AutoFilter([NotNull] IDictionary<string, object> filter)
{
if (filter == null) throw new ArgumentNullException(nameof(filter));
Filter = filter;
}
public IQueryable<T> Apply(IQueryable<T> query)
=> query.ApplyDictionary(Filter);
}
Для построения агрегатов из команд на создание/редактирование можно использовать обобщенный TypeConverter.
Для того, чтобы упросить регистрацию в контейнере можно использовать соглашения.
Заключение
Мы активно используем CQRS без Event Sourcing в работе и пока впечатления очень хорошие.
- Проще тестировать код, потому что классы маленькие и гарантированно отвечают только за одну вещь
- По этой-же причине упрощается внесение изменений в систему
- Упростилась коммуникация, исчезли споры о том где тот или иной код должен находиться. Код разных участников команды стал единообразным
- DDD используется для первоначального моделирования системы и создания агрегатов. Агрегаты могут вообще не инстанцироваться, в случае, если все методы над соответствующей таблице жестко оптимизированы (реализованы в обход ORM)
- Event Sourcing в full banana – реализации ни разу не потребовался, Audit Log реализуется довольно часто.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (42)

RouR
19.10.2016 16:33При редактировании объекта, post запрос содержит только изменяемые поля {id:someid, param:newval}, как решаете проблему проверка прав доступа? Если у объекта некоторые поля нельзя менять вообще (createdby), а некоторые может менять только создатель. Так или иначе, при обработке ICommandHandler, объект надо будет загрузить целиком из БД. Это будет IQuery внутри ICommandHandler? Или напрямую через EF запрос делать будете?

marshinov
19.10.2016 16:51+1При редактировании объекта, post запрос содержит только изменяемые поля {id:someid, param:newval}, как решаете проблему проверка прав доступа?
В простейшем случае так, хотя лучше использовать АОП:
void Handle(PostUpdateCommand command) { if(!CheckAccess(command)) throw new SecurityException("Don't try to hack me!"); //... }
Так или иначе, при обработке ICommandHandler, объект надо будет загрузить целиком из БД. Это будет IQuery внутри ICommandHandler? Или напрямую через EF запрос делать будете?
По-умолчанию загружаем напрямую весь агрегат из ORM с помощью TypeConverter (ссылка на код в статье) для AutoMapper. ORM абстрагирована за ILinqProvider, поэтому завязки на конкретную реализацию нет. Может использоваться Query для получения каких-то объектов. Если система много пишет, то ORM не используется. Dapper пишет напрямую.

osmirnov
19.10.2016 17:30+1Статья годная, спасибо. На мой взгляд есть проблема over engineering и перекос в сторону strong consistency. Как результат «Обработчик команды может возвращать значение.» и маштабирование через async/await. Если есть опыт работы с eventual consistency реализацией, то будет интересно прочитать аналогичную квинтэссенцию.
marshinov
19.10.2016 17:38Используйте тот ICommandHandler что с void и будет eventual consistency. Если вы когда-нибудь столкнетесь с ЭЦП, то понятно будет зачем возвращать значения. Ну и ссылка на видео с Янгом тоже для вас. Если CommandHandler возвращает bool, например, то это вполне себе ок. А async/await — это вообще холиворная тема. Для приложений активно взаимодействующих с БД / сетью как раз очень неплохо подходит.
Sovent
19.10.2016 19:29Все руководители разработки, применяющие DDD, с которыми я обсуждал тему, отметили «дороговизну» этой методологии, в первую очередь из-за отсутствия в книге Эванса ответов на практические вопросы «как мне сделать FooBar, не нарушая принципов DDD?».
Странно у вас как DDD используется. DDD это ведь не набор правил, это набор рекомендаций к дизайну приложений, в конечном счёте сводящийся к тому, что бизнес превыше всего. Если у вас есть бизнес-необходимость, сделайте отдельную read-модель для отчёта.
DDD предполагает делегирование части задач по аналитике разработчикам.
Не предполагает. Предполагается понимание аналитиков разработчиками и наоборот, но работу аналитиков делают по прежнему аналитики.
В неустоявшихся бизнесах (особенно стартапах) часто нет никакого понимания предметной модели. Все может меняться ежедневно. В этих условиях бесполезно требовать от участников бизнес-процесса использовать единую терминологию.
В стартапах или нет, модель всегда эволюционирует вместе с её пониманием разработчиками. DDD не предполагает единовременное формирование всех знаний о предметной области, DDD лишь про фокус на модели.
Event Sourcing требует CQRS
Строго говоря, это неверно. Я вполне могу представить себе как клиенты делают запросы напрямую в агрегат, который собирается из эвентов. Это убивает некоторые возможности, но это возможности CQRS, а не ES.
В случае DDD, чтобы знать где искать ту или иную бизнес-логику необходимо понимать предметную область. В случае CQRS программист всегда знает, что запись происходит в обработчиках команд, а для доступа к данным используются Query.
Почему вы их противопоставляете? CQRS отлично работает на DDD бэкграунде, потому что конкурировать там нечему. Это всё равно что говорить, что CQRS лучше Agile.
Hydro
20.10.2016 08:54Если у вас есть бизнес-необходимость, сделайте отдельную read-модель для отчёта.
У отчета может быть не read модель?Sovent
20.10.2016 11:52Да, если у вас составление отчёта кастомизируется, требует вызовов внешних систем, продолжительно во времени (сага), то вам понадобится для этого сценария write-модель.

3DFace
20.10.2016 12:25+3По-моему, сага моделирует многошаговый бизнес-процесс. И если мы говорим в контексте CQRS, то write model нужен для изменения состояния.
Разве при формировании отчета мы намереваемся изменить состояние системы?
По-вашему, если операция продолжительная, то сразу сага? То, что построение отчета занимает много времени, выполняется асинхронно, с возможностю указания параметров… — это уже детали реализации read-model, имхо.Sovent
20.10.2016 13:02+1Если в вашем приложении отчёт является полноценной сущностью со своим жизненным циклом (пусть и коротким), то он будет корнем агрегата или находится в составе агрегата.
У read-model не должно быть деталей реализации, read-model — это проекция состояния системы на определённый клиентский запрос, она должна быть в оптимальной для этого запроса форме и в идеале, доставаться за один запрос в БД. Когда у вас есть какая-то логика в получении read-модели, возможно, у вас не полноценный CQRS.3DFace
20.10.2016 13:41+1Если в вашем приложении отчёт является полноценной сущностью со своим жизненным циклом (пусть и коротким), то он будет корнем агрегата или находится в составе агрегата.
Я решил, что под отчетом подразумевается «информация оформленная в удобном для пользователя виде» — статистика, графики и т.п. Если же «отчет» — это термин предметной области, то спору нет.
read-model — это проекция состояния системы на определённый клиентский запрос, она должна быть в оптимальной для этого запроса форме и в идеале, доставаться за один запрос в БД. Когда у вас есть какая-то логика в получении read-модели, возможно, у вас не полноценный CQRS
Соглашусь, что read-model открывает возможности для оптимизации операций чтения. Но не могли бы вы пояснить (или поделиться ссылкой) — почему наличие read-логики делает CQRS неполноценным?Sovent
20.10.2016 14:08+1Я решил, что под отчетом подразумевается «информация оформленная в удобном для пользователя виде» — статистика, графики и т.п. Если же «отчет» — это термин предметной области, то спору нет.
Так это Hydro спросил, может ли отчёт быть больше, чем просто read-модель. Да, может, но я говорю о ситуации, когда отчёт необходим как статистика, графики и т.п. И да, там достаточно только read-модели.
Но не могли бы вы пояснить (или поделиться ссылкой) — почему наличие read-логики делает CQRS неполноценным?
Автор тезисом указал, что это не реализуется с использованием DDD. Я же в этом сценарии не вижу в DDD никакой помехи: если отчёт — это бизнес-понятие, то оно должно быть отражено в виде сущности в том или ином контексте, а в терминах CQRS стать частью write-модели. Если отчёт — это лишь ещё одна проекция состояния системы и собственного жизненного цикла не имеет, то вы можете на основе имеющейся в системе информации подготовить read-модель, именуемую «отчёт» и сохранить её в максимально удобной для получения форме. Именно подготовить, а не строить на лету какие-то SQL запросы с JOIN'ами и кверить все агрегаты в системе.
Про это писал Vaughn Vernon в книге Implementing Domain Driven Design, часть его труда посвящена как раз использованию CQRS вместе с DDD.
marshinov
19.10.2016 19:35Скажите, сколько проектов, какой длительности вы реализовали, следуя принципам DDD и каким был размер команды разработки? Понимая под DDD в том числе моделирование бизнес-процессов в коде именно так, как они «работают» в реальном мире.

indestructable
20.10.2016 01:09+1В общем-то, можно добавить, что CQS (разделение чтения и изменения данных) — это крайне полезный паттерн при любой архитектуре.

customtema
20.10.2016 08:21-2DDD. Выводы
ОЧЕНЬ дорого
Работает хорошо в устоявшихся бизнес-процессах
Плохо масштабируется
Сложно реализовать в высоконагруженных приложениях
Плохо работает в стартапах
Не подходит для построения отчетов
Требует особого внимания с ORM
Слова Entity лучше избегать, потому что его все понимают по-своему
Программиста нанимать не пробовали?
Мой 6-ти летний опыт с DDD дает ровно обратные выводы.
varanio
20.10.2016 09:43+1А как вы формируете отчеты?
Типа относительный средний заработок за прошлую неделю деленный на фазу луны?customtema
20.10.2016 11:21Получить данные из базы, подсчитать и вывести нужное.
При необходимости реплицировать и кешировать.
Какие проблемы-то?
Hydro
20.10.2016 08:57+1Больше спасибо за такую информативную статью, обязательно почитаю что-нибудь из литературы приведенной в презентации.
Sybe
20.10.2016 10:09+2Спасибо за очень познавательную статью. Можете привести пример, как в подобной архитектуре производится валидация, например, проверка уникальности email-адреса нового пользователя, и как происходит возвращение результата валидации пользователю?
marshinov
20.10.2016 10:12+1Можно вот так
public static class ValidationExtensions { public static string Check<T>(T obj, Func<T, bool> func, string message) => func(obj) ? null : message; public static string[] Check<T>(this Func<T, string>[] funcs, T data) => funcs .Select(x => x.Invoke(data)) .Where(x => x != null) .ToArray(); public static ValidationResult GetResult<T>(this Func<T, string>[] funcs, T data) { var checkResult = funcs.Check(data); return checkResult.Any() ? new ValidationResult(checkResult.Join(",")) : ValidationResult.Success; } public static string Join(this IEnumerable<string> strings, string delimiter) => strings.Aggregate((c, n) => $"{c}{delimiter}{n}"); } public interface IValidator<in T> { ValidationResult Validate(T obj); }
Вообще, валидацию лучше выносить в отдельные классы, потому что есть разница хотите вы сделать 1 запись в БД или импортировать 500.000. Желательно иметь возможность использовать код валидации и сохранения как на массовых операциях, так и единичных. За исключением случаев, когда нужно вставлять действительно большие массивы данных очень быстро это возможно за счет map/reduce и управления batch size и лайфтамом контекста БД через explicit scope
Если нравится АОП и производительность позволяет, можно еще так: http://simpleinjector.readthedocs.io/en/latest/aop.html#decoration

Szer
20.10.2016 10:09+1Делал проект с DDD+CQRS (без ES). Была одна непонятка, объяснение которой я не нашёл.
Вот допустим у нас есть проекты и их менеджеры. Есть требование что обращаться по-любому поводу к «чужому» проекту нельзя, даже имя узнать.
Агрегат Проект решал эти вопросы доступа сам, зная кто его менеджер и вся эта логика (она была сложнее и касалась не только проектов) была на стороне Command, в агрегатах.
На стороне Query всю эту логику приходилось дублировать чтобы люди запросами типа GetProjectBudgets(id) не узнали лишнего.
Думал над вынесением логики доступа к ресурсам в отдельный слой, ещё над разделением потоково на Command и Query. Не успел, сменил свой рабочий проект.
Что бы вы посоветовали сделать в этом случае в рамках CQRS и DDD?indestructable
20.10.2016 13:56+1Я делаю так: есть два вида секьюрити: безопасность данных и безопасность операций.
Секьюрити операций сейчас пропустим.
Безопасность данных — это ограничение доступа к "чужим" данным, как на чтение, так и на запись. Реализуется она в виде фильтров данных, либо на стороне базы (row-level security или самопальный велосипед), либо генерацией и применением SQL фильтра (
where) ко всем (в том числеupdate) запросам из сервера приложения. Если используется LINQ, можно такой фильтр генерировать в терминах доменной модели.
Основная проблема — это создать архитектуру данных, которая позволит сохранить баланс между избыточностью (денормализацией данных) и производительностью таких секьюрити-фильтров.
Отвечая более конкретно на ваш вопрос — если запись и чтение происходят в два источника, то логику придется дублировать, другой вопрос, что можно дублирование минимизировать, используя похожую структуру данных в read model и master data, интерфейсы и полиморфизм и т.п. Ну и конечно, надо отделить вычисление прав пользователя от преобразования набора прав в конкретный фильтр для сущности.
Szer
20.10.2016 14:10+1Вот да. Проблема ещё и в отчётах из read-model.
Декораторы и AOP помогают когда можно полностью запретить или полностью разрешить вызов command/query.
А для запросов по площади типа GetAllProjects() от конкретного юзера надо городить в самом теле запроса логику фильтрации.
В read-model у меня была тонна .Where(UserBelongsToProject) или что-то вроде .Where(EntityNotDeleted) и если я в каком-то запросе пропустил эти фильтры — это потенциальная брешь в безопасности данных.
А если взять какой-то сложный запрос на финансовый отчёт по всем доступным проектам, тут вообще кошмар, т.к. приходится джойнить таблицы и не забывать что для каждой такой таблицы надо тоже применять фильтры.
Получается что мне нужен кто-то на стороне Query, кто решает вопрос доступа к данным, а значит там надо городить отдельную доменную модель, что убивает смысл CQRS.marshinov
20.10.2016 14:31Вы можете LINQ засунуть за абстракцию и накрутить на контейнере хитрую логику резолва LinqProvider'а. Чтобы GetQueryable возвращало не SELECT * FROM <TABLE_NAME>, а SELECT * FROM <TABLE_NAME> WHERE BLAH-BLAH-BLAH. Where добавлять динамически в зависимости от контекста, откуда вы резолвите этот самый LinqProvider.
indestructable
20.10.2016 18:48Проблема, повторюсь, в том, что это логика защиты данных, и решать ее надо на уровне данных (хотя сами вычисления прав доступа станут частью бизнес-логики).
CQRS создан для оптимизации производительности (ну и плюс некоторые задачи на него хорошо ложаться), он не декларирует никак доступ к данным (ну за исключением разделения read/write data model), и ждать от него изящества в работе с данными не стоит, разве что можно добавлять фильтрацию по правам при восстановлении агрегата из набора событий.
Изящного решения этой проблемы нет даже в DDD, есть только более-менее удачные для конкретного проекта.
Удачное решение, как по мне, — это дополнительная модель данных, автоматически включающая секьюрити.
marshinov
20.10.2016 10:21Думал над вынесением логики доступа к ресурсам в отдельный слой, ещё над разделением потоково на Command и Query. Не успел, сменил свой рабочий проект.
Все верно думали. Просто нужно иметь абстракцию, которую вы сможете переиспользовать и там и там. Не всегда это просто. Чтобы была конкретика нужно код смотреть.
Один из вариантов: выносить такую логику в АОП, например так. Погуглите Cross-cutting concern. Вот здесь кое-что есть по-русски на эту тему.Szer
20.10.2016 10:44+1Один из вариантов: выносить такую логику в АОП, например так. Погуглите Cross-cutting concern. Вот здесь кое-что есть по-русски на эту тему.
Я так и сделал. все что требовало доступа уровня проекта имело маркерный интерфейс IProjectRequest, на который был настроен декоратор, отказывающий пользователю, если это не его проект. Но приходилось это делать и на командах, и на запросах.
Таким образом у меня бизнес логика «протекала» из агрегатов и размазывалась по декораторам. А сам агрегат уже не был самодостаточной сущностью и мог правильно существовать только с внешними декораторами.
Та же проблема и с выделением логики во внешний слой. Логика утекает вообще не пойми куда, а агрегат Проект должен надеяться что вопрос доступа к конкретному проекту был решён за него.marshinov
20.10.2016 10:54-1Ясно. Боюсь, что без кода и глубокого понимания требований проекта и взаимоотношений в команде разработки дать конкретный ответ не получится, тем более что вы на проекте уже не работаете.
Я обычно при выборе архитектурных решений иду не от паттернов-шматтернов, а от Jira (или что там используется): смотрю где ботлнеки, начинаю прикидывать на что уходит время.
То, что у вас логика расползлась — это, конечно, не очень. С другой стороны, вы считали несете ли вы убытки от этого в монетарном выражении? Не теряли ли вы больше времени на другие задачи?
У нас аутсорсинговая компания, поэтому CQRS нам сейчас хорошо подошел. Когда я работал в трейдинге (продуктовая разработка), мы использовали более DDD-шный подход.

Ogoun
20.10.2016 14:31+1Самый распространенный в гугл-группе CQRS, вопрос по словам Грега Янга: «Босс просит меня построить годовой отчет. Когда я поднимаю в оперативную память все корни агрегации у меня начинает все тормозить. Что мне делать?». На этот вопрос есть очевидный ответ: «нужно написать SQL-запрос». Однако, написание ручного SQL-запроса – это однозначно против правил DDD.
В своем проекте решал проблему так, все спецификации реализуют паттерн Посетитель, в итоге для каждого типа репозитория вызывается свой вариант проверки, для in-memory это простая лямбда, для SQL Server создается фрагмент для вставки в WHERE часть запроса. Поднимать в память данные из базы для фильтрации — недопустимо.
Соответственно при создании новых вариантов отчета добавляются новые спецификации, или используется комбинация готовых.
marshinov
20.10.2016 14:33Интересный подход, а можете код показать?
Ogoun
20.10.2016 15:04+1Немного обманул, Посетитель был в ранних версиях, сейчас упрощено, но суть та же, уже не помню почему не подошла первая реализация.
На уровне абстракций
public interface ISpecification<T> where T : IEntity { bool IsSatisfied(T t); } public interface IRepository<T> where T: IEntity { // .... IEnumerable<T> Get(ISpecification<T> specification); // .... }
Немного ниже где известно про типы репозиториев:
public interface ISqlServerSpecification { SqlServerSpecification GetWhereFragment(); }
Пример спецификации:
public class AgeLessThenSpecification: ISpecification<Human>, ISqlServerSpecification { private readonly short _maxAge; public AgeLessThenSpecification(ushort maxAge) { _maxAge = maxAge; } public bool IsSatisfied(Human h) { return h.Age <= _maxAge; } public SqlServerSpecification GetWhereFragment() { return new SqlServerSpecification { Where = "WHERE [Age] <= @Age", Parameters = new SqlParameter[] { new SqlParameter("Age", _maxAge) } }; } }
На уровне репозитория (SQL) выполняется проверка реализует ли спецификация расширение для SQL, если да, то будет использоваться запрос.
private bool TryGetWhere(ISpecification<T> specification, out SqlServerSpecification condition) { var sqlSpecification = (specification as ISqlServerSpecification); if (sqlSpecification == null) { condition = SqlServerSpecification.EmptySpecification; return false; } condition = sqlSpecification.GetWhereFragment(); return true; }marshinov
20.10.2016 15:25У вас без ORM, сразу все в SQL собирается?
Ogoun
20.10.2016 15:44+1NHibernate и EF не использую. Но есть своя прослойка которая реализует часть функционала ORM, в частности, кроме указанных частей запроса больше ничего руками не пишется, запросы формируются автоматом по анализу базы данных или модели.
Ogoun
20.10.2016 17:46+1Раз уж есть обсуждение, по Эвансу и прочим подходам, нигде не нашел описание такого вопроса — допустим клиент выполняет изменение состояния, как пример, можно представить добавление книги в библиотеку, и в транзакции мы хотим выполнить сразу набор изменений:
- добавить книгу
- если автора еще нет, создать автора
- изменить статистику общую (сколько книг, авторов и т.п.)
- изменить статистику по автору
Т.е. до того как отработает UnitOfWork или его аналог, нужно создать набор этим изменений. И вот как их правильно собирать, ни у кого не встречал.
По правильности имеется в виду следующее, иметь обощенный инструмент, который позволяет:
- формировать набор операций для транзакции
- собрать ключи объектов которые будут затронуты операцией
- блокировка ключей на время транзакции
- после создания списка операций выкинуть те, которые не приводят к изменению состояния
- создание виртуальной модели будущего состояния для вычисляемых полей (по примеру, количество книг автора, и общее количество книг)
- автоматическое определение слабосвязанных объектов, затрагиваемых изменением и их обновление
- выполнение транзакции и откат по всем репозиториям в случае ошибок (например, откат в кэше оперативы и в базе данных)
Был ли такой опыт и как решали этот вопрос у себя, или использовали что-то готовое?
В итоге был написан отдельный фреймворк, который сначала позволяет собрать план выполнения запросов в транзакции, затем оптимизирует этот план, и затем исполняет в одной транзакции.marshinov
20.10.2016 18:14+1Делали нечто подобное. Кейс был такой: добавляем товар. Нужно пересчитать статистику, обновить индекс в эластик сёрч, обновить ленты подписки пользователей, отправить push-уведомления в приложение, смс, письма.
Решали так: в основное хранилище пишем транзакционно «добавили товар» и выкидываем событие «товар добавлен». Событие ловит диспетчер. В диспетчере логика: добавили товар — выкинь еще события «обнови эластик», «обнови ленты», и т.д. В случае облома обработчика любого события пишем в лог.
События отправляются в RabbitMQ / Akka.net, обработчики уже за пределами транзакции БД. Если что-то обламалось по логам вызываем заново обработчики. Если все жестко сломалось Вызываем Supervisor, который может по корневому хранилищу (релаяционная БД) построить эластик и т.д. Пуш уведомления, СМС и все-такое в этом случае не рассылаем, потому что можно разослать все повторно.
«Жестко сломалось» было пару раз при сильном изменении корней агрегации.
indestructable
21.10.2016 10:51+1По идее, вот это
- формировать набор операций для транзакции
- собрать ключи объектов которые будут затронуты операцией
- блокировка ключей на время транзакции
- после создания списка операций выкинуть те, которые не приводят к изменению состояния
функционал Unit Of Work.
Sovent
21.10.2016 12:08+1Я бы в вашем кейсе сделал так: добавил книгу, опубликовал событие предметной области, обработчик которого создал бы автора, изменил общую статистику и изменил статистику по автору. С трудом верится, что для последних двух изменений необходима strong consistency, но для добавления книги+автора может по какой-то причине добавиться. В таком случае сначала бы добавил автора, одной транзакцией, другой транзакцией — книгу. Если добавление книги отвалится, ничего страшного, новый автор в базе никому не помешает. От конкретного кейса зависит, конечно, но в целом проблем не вижу.
Ogoun
21.10.2016 12:22+1Пример выдуман, в реальном проекте мне была нужна именно полная согласованность данных, и подход когда обновление происходит по частям не подходил. Т.е. по примеру требовалось чтобы и книга, и автор и статистика обновились в одной транзакции, при этом транзакция должна отработать одновременно на базе и на кэше.
marshinov
21.10.2016 13:22Лучше не использовать кеш тогда. Либо кеш хранить в той-же субд, что и данные. Можно же даже файлы транзакционно писать, через тот-же File Table в MsSQL
Ogoun
21.10.2016 14:08+1Для решения был написан декоратор, который позволяет добавлять поддержку TransactionScope любым репозиториям, в итоге если транзакция не прошла, откат будет во всех затронутых репозиториях. А кэш использовал самый простой, in-memory
lair
Можно ссылку на то, где Янг это подтверждает?
marshinov
Здесь на 25:00 после can I user query in command?
marshinov
И еще 28:00 Про ATM.