
 Казалось бы, Chromium был рассмотрен нами неоднократно. Внимательный читатель задастся логичным вопросом: «Зачем нужна еще одна проверка? Разве было недостаточно?». Бесспорно, код Chromium отличается чистотой, в чем мы убеждались каждый раз при проверке, однако ошибки неизбежно продолжают выявляться. Повторные проверки хорошо демонстрируют, что чем чаще будет применяться статический анализ, тем лучше. Хорошо, если проект проверяется каждый день. Ещё лучше, если анализатор используется программистами непосредственно при работе (автоматический анализ изменённого кода).
Казалось бы, Chromium был рассмотрен нами неоднократно. Внимательный читатель задастся логичным вопросом: «Зачем нужна еще одна проверка? Разве было недостаточно?». Бесспорно, код Chromium отличается чистотой, в чем мы убеждались каждый раз при проверке, однако ошибки неизбежно продолжают выявляться. Повторные проверки хорошо демонстрируют, что чем чаще будет применяться статический анализ, тем лучше. Хорошо, если проект проверяется каждый день. Ещё лучше, если анализатор используется программистами непосредственно при работе (автоматический анализ изменённого кода).Немного предыстории
Chromium проверялся с помощью PVS-Studio уже четыре раза:
- первая проверка (23.05.2011)
- вторая проверка (13.10.2011)
- третья проверка (12.08.2013)
- четвертая проверка (02.12.2013)
Ранее все проверки были произведены Windows-версией анализатора PVS-Studio. С недавнего времени PVS-Studio работает и под Linux, поэтому для анализа использовалась именно эта версия.
За это время проект вырос в размерах: в третью проверку число проектов достигало отметки 1169. На момент написания статьи их стало 4420. Заметно вырос и объем исходного кода до 370 Мб (на 2013 год размер составлял 260 Мб).
За четыре проверки было отмечено высочайшее качество кода для столь большого проекта. Изменилась ли ситуация спустя два с половиной года? Нет. Качество по-прежнему на высоте. Однако из-за большого объема кода и постоянного его развития мы вновь находим много ошибок.
А как проверять?
Остановимся подробнее на том, как произвести проверку Chromium. На этот раз мы сделаем это в Linux. После загрузки исходников с помощью depot_tools и подготовки (подробнее здесь, до раздела Building) собираем проект:
pvs-studio-analyzer trace -- ninja -C out/Default chromeДалее выполняем команду (это одна строка):
pvs-studio-analyzer analyze -l /path/to/PVS-Studio.lic
-o /path/to/save/chromium.log -j<N>где флаг "-j" запускает анализ в многопоточном режиме. Рекомендуемое число потоков — число физических ядер CPU плюс один (например, на четырехъядерном процессоре флаг будет выглядеть как "-j5").
В результате будет получен отчет анализатора PVS-Studio. При помощи утилиты PlogConverter, которая идет в составе дистрибутива PVS-Studio, его можно перевести в один из трех удобочитаемых форматов: xml, errorfile, tasklist. Мы будем использовать для просмотра сообщений формат tasklist. В текущей проверке будут просматриваться только предупреждения общего назначения (General Analysis) всех уровней (High, Medium, Low). Команда конвертации будет выглядеть следующим образом (одной строкой):
plog-converter -t tasklist -o /path/to/save/chromium.tasks
-a GA:1,2,3 /path/to/saved/chromium.logПодробнее о всех параметрах PlogConverter'а можно прочитать здесь. Загрузку tasklist'а «chromium.tasks» в QtCreator (должен быть предварительно установлен) выполним при помощи команды:
qtcreator path/to/saved/chromium.tasksКрайне рекомендуется начать просмотр отчета с предупреждений уровней High и Medium — вероятность, что найдутся ошибочные инструкции в коде, будет очень высока. Предупреждения уровня Low также могут указывать на потенциальные ошибки, но вероятность ложного срабатывания у них выше, поэтому при написании статей они, как правило, не изучаются.
Сам же просмотр отчета в QtCreator будет выглядеть следующим образом:

Рисунок 1 — Работа с результатами анализатора из-под QtCreator (нажмите на картинку для увеличения)
Что поведал анализатор?
После проверки проекта Chromium было получено 2312 предупреждений. На следующей диаграмме представлено распределение предупреждений по уровням важности:
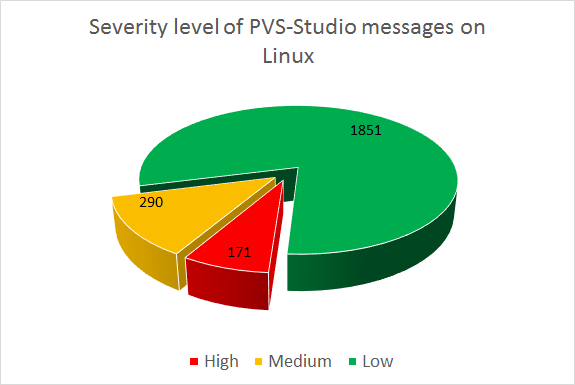
Рисунок 2 — Распределение предупреждений по уровням важности
Кратко прокомментируем приведенную диаграмму: было получено 171 предупреждений уровня High, 290 предупреждений уровня Medium, 1851 предупреждение уровня Low.
Несмотря на достаточно большое число предупреждений, для такого гигантского проекта это немного. Суммарное количество строк исходного кода (SLOC) без библиотек — 6468751. Если учитывать только предупреждения уровня High и Medium, то среди них я, пожалуй, могу указать на 220 настоящих ошибок. Цифры цифрами, а на деле получаем плотность ошибок, равной 0,034 ошибки на 1000 строк кода. Это, конечно, плотность не всех ошибок, а только тех, которые находит PVS-Studio. А вернее — тех ошибок, которые заметил я, просматривая отчет.
Как правило, на других проектах мы получаем большую плотность найденных ошибок. Разработчики Chromium молодцы! Впрочем, расслабляться не стоит: ошибки есть, и они далеко небезобидные.
Рассмотрим подробнее наиболее интересные ошибки.
Новые найденные ошибки
Copy-Paste

Предупреждение анализатора: V501 There are identical sub-expressions 'request_body_send_buf_ == nullptr' to the left and to the right of the '&&' operator. http_stream_parser.cc 1222
bool HttpStreamParser::SendRequestBuffersEmpty()
{
return request_headers_ == nullptr
&& request_body_send_buf_ == nullptr
&& request_body_send_buf_ == nullptr; // <=
}Классика жанра. Программист дважды сравнил указатель request_body_send_buf_ с nullptr. Вероятно, это опечатка, и с nullptr следовало сравнить ещё какой-то член класса.
Предупреждение анализатора: V766 An item with the same key '«colorSectionBorder»' has already been added. ntp_resource_cache.cc 581
void NTPResourceCache::CreateNewTabCSS()
{
....
substitutions["colorSectionBorder"] = // <=
SkColorToRGBAString(color_section_border);
....
substitutions["colorSectionBorder"] = // <=
SkColorToRGBComponents(color_section_border);
....
}Анализатор сообщает о подозрительной двойной инициализации объекта по ключу «colorSectionBorder». Переменная substitutions в данном контексте является ассоциативным массивом. В первой инициализации переменная color_section_border типа SkColor (определен как uint32_t) переводится в строковое представление RGBA (судя из названия метода SkColorToRGBAString) и сохраняется по ключу «colorSectionBorder». При повторном присваивании color_section_border конвертируется уже в другой строковый формат (метод SkColorToRGBComponents) и записывается по тому же самому ключу. Это означает, что предыдущее значение по ключу «colorSectionBorder» будет уничтожено. Возможно, так и задумывалось, но тогда одну из инициализаций следует убрать. В ином случае следует сохранять компоненты цвета по другому ключу.
Примечание. Кстати, это первая ошибка, найденная с помощью диагностики V766 в реальном проекте. Тип ошибки достаточно специфичен, но проект Chromium столь велик, что в нём можно повстречать и экзотические дефекты.
Неверная работа с указателями

Предлагаю читателям немного размяться и попытаться найти ошибку самостоятельно.
// Returns the item associated with the component |id| or nullptr
// in case of errors.
CrxUpdateItem* FindUpdateItemById(const std::string& id) const;
void ActionWait::Run(UpdateContext* update_context,
Callback callback)
{
....
while (!update_context->queue.empty())
{
auto* item =
FindUpdateItemById(update_context->queue.front());
if (!item)
{
item->error_category =
static_cast<int>(ErrorCategory::kServiceError);
item->error_code =
static_cast<int>(ServiceError::ERROR_WAIT);
ChangeItemState(item, CrxUpdateItem::State::kNoUpdate);
} else {
NOTREACHED();
}
update_context->queue.pop();
}
....
}Предупреждение анализатора: V522 Dereferencing of the null pointer 'item' might take place. action_wait.cc 41
Здесь программист решил явным способом прострелить себе ногу. В коде последовательно обходится очередь queue, содержащая идентификаторы в строковых представлениях. Из очереди извлекается идентификатор, затем метод FindUpdateItemById должен вернуть указатель на объект типа CrxUpdateItem по идентификатору. Если в методе FindUpdateItemById произойдет ошибка, то будет возвращен nullptr, который затем разыменуется в ветке then оператора if.
Корректный код может выглядеть следующим образом:
....
while (!update_context->queue.empty())
{
auto* item =
FindUpdateItemById(update_context->queue.front());
if (item != nullptr)
{
....
}
....
}
....Предупреждение анализатора: V620 It's unusual that the expression of sizeof(T)*N kind is being summed with the pointer to T type. string_conversion.cc 62
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2])
{
const UTF8 *source_ptr = reinterpret_cast<const UTF8 *>(in);
const UTF8 *source_end_ptr = source_ptr + sizeof(char);
uint16_t *target_ptr = out;
uint16_t *target_end_ptr = target_ptr + 2 * sizeof(uint16_t); // <=
out[0] = out[1] = 0;
....
}Анализатор обнаружил код с подозрительной адресной арифметикой. Как видно из названия, функция конвертирует символ из кодировки UTF-8 в UTF-16. Действующий стандарт Unicode 6.х предполагает расширение символа UTF-8 до четырех байт. В связи с этим, UTF-8 символ декодируется как 2 символа UTF-16 (UTF-16 символ кодируется жестко двумя байтами). Для декодирования используются 4 указателя — указатели на начало и конец массивов in и out. Указатели на конец массивов в коде действуют подобно итераторам STL: они ссылаются на область памяти за последним элементом в массиве. Если в случае с source_end_ptr указатель был получен верно, то с target_end_ptr все не так «радужно». Подразумевалось, что он должен был ссылаться на область памяти за вторым элементом массива out (то есть сместиться относительно указателя out на 4 байта), однако вместо этого указатель будет ссылаться на область памяти за четвертым элементом (смещение out на 8 байт).
Проиллюстрируем сказанные слова, как должно было быть:
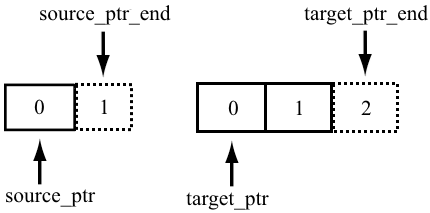
Как получилось на самом деле:

Корректный код должен выглядеть следующим образом:
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2])
{
const UTF8 *source_ptr = reinterpret_cast<const UTF8 *>(in);
const UTF8 *source_end_ptr = source_ptr + 1;
uint16_t *target_ptr = out;
uint16_t *target_end_ptr = target_ptr + 2;
out[0] = out[1] = 0;
....
}Анализатор также обнаружил еще одно подозрительное место:
- V620 It's unusual that the expression of sizeof(T)*N kind is being summed with the pointer to T type. string_conversion.cc 106
Различные ошибки

Предлагаю снова размяться и попробовать найти ошибку в коде самостоятельно.
CheckReturnValue& operator=(const CheckReturnValue& other)
{
if (this != &other)
{
DCHECK(checked_);
value_ = other.value_;
checked_ = other.checked_;
other.checked_ = true;
}
}Предупреждение анализатора: V591 Non-void function should return a value. memory_allocator.h 39
В коде выше имеет место неопределенное поведение: стандарт C++ говорит, что любой non-void метод должен возвращать значение. Что же в коде выше? В операторе присваивания происходит проверка на присваивание самому себе (сравнение объектов по их указателям) и копирование полей (если указатели разные). Однако, метод не вернул ссылку на самого себя (return *this).
Нашлось еще пару мест в проекте, где non-void метод не возвращает значения:
- V591 Non-void function should return a value. sandbox_bpf.cc 115
- V591 Non-void function should return a value. events_x.cc 73
Предупреждение анализатора: V583 The '?:' operator, regardless of its conditional expression, always returns one and the same value: 1. configurator_impl.cc 133
int ConfiguratorImpl::StepDelay() const
{
return fast_update_ ? 1 : 1;
}Код всегда возвращает задержку, равной единице. Возможно, это задел на будущее, но пока от такого тернарного оператора нет пользы.
Предупреждение анализатора: V590 Consider inspecting the 'rv == OK || rv != ERR_ADDRESS_IN_USE' expression. The expression is excessive or contains a misprint. udp_socket_posix.cc 735
int UDPSocketPosix::RandomBind(const IPAddress& address)
{
DCHECK(bind_type_ == DatagramSocket::RANDOM_BIND
&& !rand_int_cb_.is_null());
for (int i = 0; i < kBindRetries; ++i) {
int rv = DoBind(IPEndPoint(address,
rand_int_cb_
.Run(kPortStart, kPortEnd)));
if (rv == OK || rv != ERR_ADDRESS_IN_USE) // <=
return rv;
}
return DoBind(IPEndPoint(address, 0));
}Анализатор предупреждает о возможном избыточном сравнении. В коде происходит привязка случайного порта к IP адресу. Если привязка произошла успешно, то останавливается цикл (который означает число попыток привязки порта к адресу). Исходя из логики, можно оставить одно из сравнений (сейчас цикл останавливается, если привязка произошла успешно, или не возвращена ошибка использования порта другим адресом).
Предупреждение анализатора: V523 The 'then' statement is equivalent to the 'else' statement.
bool ResourcePrefetcher::ShouldContinueReadingRequest(
net::URLRequest* request,
int bytes_read
)
{
if (bytes_read == 0) { // When bytes_read == 0, no more data.
if (request->was_cached())
FinishRequest(request); // <=
else
FinishRequest(request); // <=
return false;
}
return true;
}Анализатор сообщил об одинаковых операторах в ветвях then и else оператора if. К чему это может привести? Исходя из кода, некэшированный URL запрос (net::URLRequest *request) будет завершен также, как и кэшированный. Если так и должно быть, тогда можно убрать оператор ветвления:
....
if (bytes_read == 0) { // When bytes_read == 0, no more data.
FinishRequest(request); // <=
return false;
}
....Если же подразумевалась другая логика, то будет вызван не тот метод, что может привести к «бессонным ночам» и «морю кофе».
Предупреждение анализатора: V609 Divide by zero. Denominator range [0..4096]. addr.h 159
static int BlockSizeForFileType(FileType file_type)
{
switch (file_type)
{
....
default:
return 0; // <=
}
}
static int RequiredBlocks(int size, FileType file_type)
{
int block_size = BlockSizeForFileType(file_type);
return (size + block_size - 1) / block_size; // <=
}Что же мы видим здесь? Данный код может привести к трудноуловимой ошибке: в методе RequiredBlocks происходит деление на значение переменной block_size (вычисляется при помощи метода BlockSizeForFileType). В методе BlockSizeForFileType по переданному значению перечисления FileType в switch-операторе происходит возврат некоторого значения, однако было также предусмотрено значение по умолчанию — 0. Представим, что перечисление FileType решили расширить и добавили новое значение, но не добавили новую case-ветвь в switch-операторе. Приведет это к неопределенному поведению: по стандарту C++ деление на ноль не вызывает программного исключения. Вместо него будет вызвано аппаратное исключение, которое не отловить стандартным блоком try/catch (вместо этого применяются обработчики сигналов, подробнее можно почитать тут и тут).
Предупреждение анализатора: V519 The '* list' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 136, 138. util.cc 138
bool GetListName(ListType list_id, std::string* list)
{
switch (list_id) {
....
case IPBLACKLIST:
*list = kIPBlacklist;
break;
case UNWANTEDURL:
*list = kUnwantedUrlList;
break;
case MODULEWHITELIST:
*list = kModuleWhitelist; // <=
case RESOURCEBLACKLIST:
*list = kResourceBlacklist;
break;
default:
return false;
}
....
}Типичная ошибка при написании switch-оператора. Ожидается, что если переменная list_id примет значение MODULEWHITELIST из перечисления ListType, то строка по указателю list инициализируется значением kModuleWhitelist и прервется выполнение switch-оператора. Однако из-за пропущенного оператора break произойдет переход на следующую ветку RESOURCEBLACKLIST, и в *list на самом деле будет сохранена строка kResourceBlacklist.
Выводы
Chromium остается «крепким орешком». И всё равно анализатор PVS-Studio вновь и вновь может находить в нем ошибки. При использовании методов статического анализа ошибки могут быть найдены еще на этапе написания кода, до этапа тестирования.
Какие инструменты можно использовать для статического анализа кода? На самом деле инструментов много. Я же естественно предлагаю попробовать PVS-Studio: продукт очень удобно интегрируется в среду Visual Studio, или возможно его применение с любой системой сборки. А с недавнего времени стала доступна и версия для Linux. Подробнее с информацией про Windows и Linux версии можно ознакомиться здесь и здесь.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Phillip Khandeliants. Heading for a Record: Chromium, the 5th Check.
Комментарии (64)

HabraBabra
26.10.2016 17:31+1Сколько времени заняла эта пятая проверка исходников Хромиум?

EvgeniyRyzhkov
26.10.2016 17:36+5- Пункт 1. Сделать Linux-версию анализатора.
- Пункт 2. Проверить Chromium.
По сравнению с пунктом 1 — не так уж и много, наверное. :-)
wikipro
26.10.2016 18:21А можно PVS-Studio (или какой либо открытый статический анализатор) прикрутить git чтобы на лету проверять корректность загруженного в репозиторий кода и чтобы он подсвечивал сомнительные участки и сам делал посты в багтреккер?
Можно ли натаскать нейросеть не выявление какой либо одной ошибки к коде одного конкретного языка программирования?lorc
26.10.2016 18:29Первое в принципе осуществимо. Есть git hooks, есть jenkins, есть плагины дженкинса к всяким треккерам.
А вот второе — очень интересная исследовательская задача. Лично я о таком не слышал.
SvyatoslavMC
26.10.2016 18:30-1Промазал с ответом, но ладно.
Первое — не правильно!lorc
26.10.2016 18:32Почему неправильно? Я где-то видел такой вариант. git hook триггерит job на jenkins, тот в свою очередь проверяет проект. Правда, таски автоматически не создавались. Но зато он умел отписываться в уже существующие таски, если их упоминали в commit message.
SvyatoslavMC
26.10.2016 18:36Всё правильно, есть много способов автоматизировать проверку и сделать рассылку людям, которые закоммитили этот код. Но такой код не должен попадать в репозиторий. В идеале.
А выявление ошибки уже на этапе проверки, например, на сервере, говорит о том, что кто-то подзабил на анализ.lorc
26.10.2016 18:39+1Ну я всё-таки привык к модели принятой в open source. С обязательным code review живыми людьми. Если перед этим сервер сам автоматически прогонит патч на статическом анализаторе — это плюс.
Конечно, я понимаю, что это противоречит вашей бизнес модели и вы хотите что бы копия анализатора стояла на машине каждого разработчика… Но называть сходу «неправильным» такой подход нельзя.SvyatoslavMC
26.10.2016 18:44Это методология статического анализа, а не бизнес-модель. Мы продвигаем именно методику, в которую входят разные способы контроля качества кода, На примере нашего анализатор. Code Review тоже часть методологии. Но если бы Code Review был так эффективен, то не было бы статических анализаторов — по сути это инструменты автоматического Code Review.
lorc
26.10.2016 19:03+1Ну вот именно. А теперь берем инструмент для ручного code review такой как gerrit или тот же github. Они все работают как сервера. Потому что удобно в одном месте видеть и комментарии других разработчиков и отчет системы статического анализа. В конце-концов разработчик может запушить патч забив на сообщения анализатора. А вот когда анализатор сидит на сервере и ставит таким патчам "-1" — это совсем другое дело.
По вашей модели мне придется слить патч себе, запустить анализатор локально, что бы убедиться что к патчу нет претензий и только потом делать review глазами.
Удобней же, когда ты открываешь патч и видишь, что вот система CI прогнала тесты и ничего не упало, статический анализатор не нашел ничего криминального, checkpatch говорит что с форматированием всё в порядке, живые люди поставили плюсики…EvgeniyRyzhkov
26.10.2016 19:32Вы используете gerrit?
lorc
26.10.2016 19:37На прошлых проектах использовали всегда. Сейчас мы работаем в основном с open source комьюнити и поэтому пушим патчи в мейнлайн по их правилам.
EvgeniyRyzhkov
26.10.2016 19:52Тогда давайте обсуждать конкретные случаи, когда они будут, а не теоретические. По нашему опыту обсуждение теоретических случаев не дает практически полезных результатов.
lorc
26.10.2016 20:03+2Так я и говорю. На предыдущих проектах мы всегда использовали gerrit. Это конкретные случаи. Извините, NDA не позволяет указывать названия проектов.
На некоторых проектах был прикручен klocwork в качестве статического анализатора, на некоторых jenkins проверял не сломается ли билд. А ещё был бот который запускал checkpatch. На некоторых проектах это всё работало вместе. И всё это добро писало комментарии прямо в gerrit и сразу же ставило оценку. Было очень удобно. Это самый что ни на есть конкретный случай.
Нечто подобное сейчас есть на гитхабе. Каждый патч может проверятся travis`ом, анализироваться с помощью coverity, благо они легко интегрируются с гитхабом и доступны бесплатно независимым разработчикам. В результате прямо в pull request виден результат анализа и прямо там есть ссылка на страничку с деталями. Это тоже практика.

Tujh
27.10.2016 09:01Для расширения кругозора, есть такой коммерческий продукт от очень известной конторы — TFS.
В нём есть настройка (по умолчанию — отключена), что любой коммит, отправляемый на сервер проходит стадию сборки и тестирования на build-станции ДО собственно внесения его в основную ветку разработки. Основной недостаток у этого подхода — от нажатия кнопки «отправить» до результата (успех/провал) проходит значительное время: делается клон основного репозитория, накладываются вносимые изменения, производится сборка и запуск автоматических тестов.
Так что этот подход уже давно применяется и не относится к «бизнес-модели» обсуждаемого тут продукта, равно, как и не требует установки не рабочее место каждого разработчика.lorc
27.10.2016 13:49+1Вы кажется меня не поняли. То что вы описали — это continuous integration. Она может быть реализована разными средствами: в TFS, с помощью Travis, Jenkins и т.д. Можно интегрировать её с code review. Можно заставить систему CI гонять статический анализатор. Можно интегрировать статический анализатор с системой code review. Можно запускать его локально на машине разработчика. Всё можно.
Но тут приходят чуваки из PVS Studio и говорят что правильный только один вариант — запускать статический анализатор на машине разработчика. А все остальные варианты — неправильные. Я с этим не согласен, о чем и написал.EvgeniyRyzhkov
27.10.2016 13:54А вы нас не поняли.
Мы говорим, что МАКСИМАЛЬНЫХ результатов можно добиться, если запускать анализ кода и на машине разработчика, и на сервере (ночью или каждый коммит) — уже детали.
Причина проста.
Если анализ запускается на локальной машине до того как код будет на сервере, то анализатор для программиста — это друг, который предотвратил появление ошибки.
Если анализ запускается только на сервере, то анализатор враг, так как позорит программиста перед коллегами.
Вы можете сколько угодно говорить: «Ой, да ладно, что такого, что другие увидят про мою ошибку», но психология людей работает именно так.lorc
27.10.2016 15:03+2Ну наверное мы с вами в разных командах работаем. У нас в команде реакция на замечания в code review приблизетльно одинакова: «ой, провтыкал, сейчас исправлю». Какой толк злиться и обижаться на коллегу если он нашел в твоем коде реальную ошибку? А как можно злиться на анализатор кода — я вообще не представляю. Это всё равно что обижаться на warning от компилятора.
Но я понимаю что в менее сыгранных командах всё может быть совсем по другому. В том числе и боязнь опозориться перед коллегами.EvgeniyRyzhkov
27.10.2016 16:25Я говорю про людей. Поверьте, что я их видел некоторое количество и знаю, о чем говорю.
lorc
27.10.2016 16:45Ну я тоже вроде не с роботами работал.
Просто разные проекты, разные команды, разные требования к разработчикам. В том числе и к общей адекватности. У нас тут в embedded всё строго, выжывают только сильнейшие :)

DarkEld3r
27.10.2016 16:49+2Верить-то верю, но не понимаю какие проблемы это вызывает. В смысле, всё равно многие тулзы (valgrind, coverity и т.д.) вынужденно запускаются на билд-серверах. Плюс некоторые проблемы вылазят только на отдельных платформах. Люди могут обижаться/раздражаться и… что? Начнут бастовать и требовать отключить всё это дело ради душевного спокойствия?
Мне кажется, что если continuous integration уже имеется и статический анализатор просто добавится к этому списку, то дискомфорта это ни у кого не вызовет.
И уж если говорить о людях, то запускать вручную анализ каждый раз они могут и будут лениться. (:
wikipro
26.10.2016 20:19-1а если у нас например будет корпоративный git внутри ЛВС, очень удобно будет, особенно при импорте открытого кода из разных проектов для их объединения в своём, например legasy кода от предыдущего исполнителя. я думаю это реально много времени сэкономит. можно было бы Овнеру проекта сделать условие внесения кода в основную ветвь — прохождение без предупреждений PVS-Studio.
А если вы прикрутите PVS-Studio к github или чему то подобному…
Я немного не понимаю как выглядит проверка кода я должен загрузить ком в MSVisualStudio и проверить PVS-Studio или я могу PVS-Studio проверять каждый вечер несколько репозиториев на корпоративном github-е?EvgeniyRyzhkov
26.10.2016 20:29+1А если бы PVS-Studio сам код писал, то цены бы ему не было.
Вы уж про какие-то вообще фантастические сценарии.У реальных клиентов нет таких проблем, о которых вы тут пишете.
SvyatoslavMC
26.10.2016 18:30А можно PVS-Studio (или какой либо открытый статический анализатор) прикрутить git чтобы на лету проверять корректность загруженного в репозиторий кода и чтобы он подсвечивал сомнительные участки и сам делал посты в багтреккер?
Тут вы уже слишком далеко зашли с ошибками) Программист должен проверить анализатором код изменённых файлов, а только потом делать коммит в репозиторий.
Можно ли натаскать нейросеть не выявление какой либо одной ошибки к коде одного конкретного языка программирования?
Натаскать, наверное, можно. Но никто не пробовал, чтобы посмотреть на результат.

springimport
26.10.2016 18:44+6После каждой статьи радуюсь что %product_name% станет лучше и быстрее. Это вдохновляет, спасибо.

robert_ayrapetyan
26.10.2016 22:59Странно, почему после четырех репортов они все еще не купили ваш продукт?
EugeneZelenko
27.10.2016 08:43Странно видеть первую ошибку. Её должен был бы отловить Clang-tidy misc-redundant-expression, созданный одним из разработчиков Chromium.
Кстати, а можно ли было бы повторит анализ LLVM/Clang/Clang extra tools/LLD/LLDB/Polly/compiler-rt/libunwind/libcxx/libcxxabi/Include What You Use/Clazy?
Andrey2008
27.10.2016 09:08Как раз недавно проверял LLVM и писал статью. Ждите, скоро будет. PVS-Studio вновь порвал LLVM, найдя в нём разнообразные ошибки.
EugeneZelenko
27.10.2016 20:14Спасибо большое! Но если можно, то не забудьте, пожалуйста, о сопутствующих проектах :-)
hdfan2
27.10.2016 09:32Non-void function should return a value
Очень странно, что это не поймал компилятор. Хотя, по крайней мере в VS это по умолчанию то ли отключено, то ли варнинг. А на деле это крайне жёсткий баг. Особенно когда возвращается не ссылка (тут программа хотя бы сразу упадёт, если ничего не вернуть), а, например, int. В результате вернётся мусор, и можно очень долго ничего не замечать. Сам в своё время поимел кучу геморроя с такой хренью.
Ну а break в switch'е вообще рептилоиды придумали для завоевания Земли. Как и возможность написать "=" вместо "==" в сравнении.
Tujh
27.10.2016 12:35+1возможность написать "=" вместо "==" в сравнении
Это вполне легальная операция, кстати.
if ( a = foo() ) { ...
одновременно и присваиваем результат переменной «а» и проверяем его на неравенство нулю, эквивалент:
a = foo(); if ( a != 0 ) {...hdfan2
27.10.2016 12:51-1Естественно, легальная. И раньше сам так писал. А теперь, много раз налетев на эти детские грабли, считаю, что за это нужно очень сильно бить.

Andrey2008
27.10.2016 09:46+1На Хабре решили не публиковать, а то зачастили. Но возможно читателям будет интересен очередной пример проверки проекта под Linux. Это CodeLite.
Linux-версия PVS-Studio не смогла обойти стороной CodeLite
severgun
27.10.2016 11:31+1Исходя из кода, некэшированный URL запрос (net::URLRequest *request) будет завершен также, как и кэшированный.
В одном слуае вернет true в другом false.
правка автора статьи всегда вернет false.
qark
28.10.2016 08:50ResourcePrefetcher::ShouldContinueReadingRequest вернёт true, если bytes_read != 0, иначе — false. Правка автора статьи ничего в этом смысле не меняет.

EugeneZelenko
27.10.2016 20:17А доступны ли все результаты анализа? Я сообщил о Вашей статье разработчикам Chromium, которых знаю по LLVM/Clang.
Andrey2008
27.10.2016 20:50А смысл? Проще получить от нас на время ключ и самостоятельно провреить самый последний вариант кода.
Tujh
28.10.2016 07:33А как же ваше правило всегда сообщать авторам проекта о результатах тестирования?
Andrey2008
28.10.2016 08:14Так мы сообщаем. Хотят, могут поправить то, что описано в статье. А могут более внимательно проанализировать.

Lof
28.10.2016 10:38Ошибку в action_wait.cc сразу поправили:
https://codereview.chromium.org/2453783002
olekl
28.10.2016 10:43-1А был ли у вас кейс «пользуемся опенсорс продуктом, но мешает какой-нибудь противный баг, проверяем анализатором, находим баг, исправляем, компилим и пользуемся дальше, уже без бага»?
Andrey2008
28.10.2016 11:18Обращение ко всем пользователям Linux-версии PVS-Studio 6.10.
WARNING! Хочу обратить внимание, что сырой лог, полученный сразу после проверки использовать нельзя! Он не предназначен для просмотра и служит только как источник данных для программы plog-converter.
К нам стало приходить большое количество писем, что результатами работы PVS-Studio пользоваться невозможно. Программисты получают огромный файл, с тысячами одинаковых сообщений на один заголовочный *.h файл и прочим мусором. Мучаются, жалуются. Другие, наверное, не жалуются, а молча теряют интерес к PVS-Studio.
Эти файлы и не предназначены для просмотра. Для преобразования их в «человеческий» формат служит утилита plog-converter, описанная в документации. Эта утилита не только преобразует лог, но и удаляет в нём дубликаты для h-файлов, фильтрует сообщения и так далее. Например, есть смысл начать изучение отчета с предупреждений общего назначения первого и второго уровня (ключ -a GA:1,2). Это очень важно, так как иначе программист просто утонет в сообщениях.
В следующей версии, мы планируем изменить изначального формат лога, чтобы было понятно, что это некий бинарный формат и он не предназначен для просмотра. Это должно подсказать программисту, что с этим файлом надо ещё что-то сделать и он, продолжив в чтение документации, будет узнавать про plog-converter.

ad1Dima
28.10.2016 18:36А сразу нормальный результат выдать нельзя?
Andrey2008
28.10.2016 19:30Можно, но есть две причины так не делать.
1. Скорость. Сейчас при параллельном анализе каждый процесс просто пишет в конец файла. Таким образом файл блокируется только для однократной записи. Это быстро и разные анализаторы друг друга почти никогда не ждут. Если сразу фильтровать дубликаты для h-файлов, каждый раз нужно делать поиск по файлу. Это значительно дольше и анализаторы начнут ждать друг друга. Начнутся простои и время анализа увеличится.
2. Наличие полного списка всех сообщений позволяет делать разные выборки без необходимости заново проводить полный анализ. Т.е. посмотрели некий отчёт, поняли, что не хотим смотреть диагностики 3-его уровня. Поправили настройки, запустили plog-converter и через минуту имеем новый отчёт. Иначе пришлось бы ждать час пока вновь будет анализироваться проектad1Dima
28.10.2016 19:59Я не понимаю, то вы говорите, то выходом пользоваться нельзя, то говорите, что он страсть как нужен. Но даже так, почему нельзя запускать plog-converter автоматически после окончания текущего процесса?
Andrey2008
Очень тихо. Оставлю первый комментарий.
Мы очень любим Linux и теперь будем стараться проверять больше Linux проектов. Спасём Linux от багов!
lorc
А само ядро слабо протестировать? Его, правда и так всё время гоняют под разными анализаторами. Но вдруг найдете парочку новых 0day уязвимостей?
EvgeniyRyzhkov
Coming soon…
gentux
Хотите обсуждений, проверьте systemd.
Tihon_V
Ну хотя бы NetworkManager…
Andrey2008
PVS-Studio покопался во внутренностях Linux (3.18.1): http://www.viva64.com/ru/b/0299/. Но будет и ещё.
lorc
Вам, кстати, не помешали бы теги в вашем блоге. Я честно хотел проверить есть ли статья про ядро на сайте. Но просматривать вообще все статьи как-то не с руки. А вот был тег linux…
SvyatoslavMC
Ознакомиться с полным списком проверенных проектов можно сразу на одной странице.
lorc
А как насчет community edition версии? Я бы вот хотел проверить ядро OP-TEE. А ещё лучше — прикрутить его к travis, что бы он на каждом коммите проверял.
SvyatoslavMC
Пока нет такой версии, но Вам могут дать временный ключ для анализа, если напишите в поддержку.
wikipro
Он реально их находит? Любопытно можно ли отбить деньги на покупку PVS-Studio продавая найденные им 0day уязвимости в открытых проектах?
lorc
Ну в ядре он вряд ли найдет что-то. Ядро регулярно проверяется самыми разными анализаторами. Думаю, другие крупные проекты — тоже.
С другой стороны даже одна 0-day уязвимость с RCE скорее всего окупит покупку.
Правда, я не знаю сколько стоит PVS-Studio, потому что автора в лучших традициях не имеет фиксированной цены.