

В Python всё немного сложнее: парсеров два. Первый парсер руководствуется грамматикой, заданной в файле
Grammar/Grammar в виде регулярных выражений (с не совсем обычным синтаксисом). По этой грамматике при помощи Parser/pgen во время компиляции python генерируется целый набор конечных автоматов, распознающих заданные регулярные выражения — по одному КА для каждого нетерминала. Формат получающегося набора КА описан в Include/grammar.h, а сами КА задаются в Python/graminit.c, в виде глобальной структуры _PyParser_Grammar. Терминальные символы определены в Include/token.h, и им соответствуют номера 0..56; номера нетерминалов начинаются с 256.Проиллюстрировать работу первого парсера проще всего на примере. Пусть у нас есть программа
if 42: print("Hello world").
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
suite: simple_stmt | NEWLINE INDENT stmt+ DEDENT
simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
small_stmt: expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt
expr_stmt: testlist_star_expr (annassign | augassign (yield_expr|testlist) | ('=' (yield_expr|testlist_star_expr))*)
testlist_star_expr: (test|star_expr) (',' (test|star_expr))* [',']
test: or_test ['if' or_test 'else' test] | lambdef
or_test: and_test ('or' and_test)*
and_test: not_test ('and' not_test)*
not_test: 'not' not_test | comparison
comparison: expr (comp_op expr)*
expr: xor_expr ('|' xor_expr)*
xor_expr: and_expr ('^' and_expr)*
and_expr: shift_expr ('&' shift_expr)*
shift_expr: arith_expr (('<<'|'>>') arith_expr)*
arith_expr: term (('+'|'-') term)*
term: factor (('*'|'@'|'/'|'%'|'//') factor)*
factor: ('+'|'-'|'~') factor | power
power: atom_expr ['**' factor]
atom_expr: [AWAIT] atom trailer*
atom: '(' [yield_expr|testlist_comp] ')' | '[' [testlist_comp] ']' | '{' [dictorsetmaker] '}' |
NAME | NUMBER | STRING+ | '...' | 'None' | 'True' | 'False'
trailer: '(' [arglist] ')' | '[' subscriptlist ']' | '.' NAME
arglist: argument (',' argument)* [',']
argument: test [comp_for] | test '=' test | '**' test | '*' test
static arc arcs_0_0[3] = {
{2, 1},
{3, 1},
{4, 2},
};
static arc arcs_0_1[1] = {
{0, 1},
};
static arc arcs_0_2[1] = {
{2, 1},
};
static state states_0[3] = {
{3, arcs_0_0},
{1, arcs_0_1},
{1, arcs_0_2},
};
//...
static arc arcs_39_0[9] = {
{91, 1},
{92, 1},
{93, 1},
{94, 1},
{95, 1},
{19, 1},
{18, 1},
{17, 1},
{96, 1},
};
static arc arcs_39_1[1] = {
{0, 1},
};
static state states_39[2] = {
{9, arcs_39_0},
{1, arcs_39_1},
};
//...
static arc arcs_41_0[1] = {
{97, 1},
};
static arc arcs_41_1[1] = {
{26, 2},
};
static arc arcs_41_2[1] = {
{27, 3},
};
static arc arcs_41_3[1] = {
{28, 4},
};
static arc arcs_41_4[3] = {
{98, 1},
{99, 5},
{0, 4},
};
static arc arcs_41_5[1] = {
{27, 6},
};
static arc arcs_41_6[1] = {
{28, 7},
};
static arc arcs_41_7[1] = {
{0, 7},
};
static state states_41[8] = {
{1, arcs_41_0},
{1, arcs_41_1},
{1, arcs_41_2},
{1, arcs_41_3},
{3, arcs_41_4},
{1, arcs_41_5},
{1, arcs_41_6},
{1, arcs_41_7},
};
//...
static dfa dfas[85] = {
{256, "single_input", 0, 3, states_0,
"\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\102"},
//...
{270, "simple_stmt", 0, 4, states_14,
"\000\040\200\000\002\000\000\000\012\076\011\007\000\000\020\002\000\300\220\050\037\100"},
//...
{295, "compound_stmt", 0, 2, states_39,
"\000\010\140\000\000\000\000\000\000\000\000\000\262\004\000\000\000\000\000\000\000\002"},
{296, "async_stmt", 0, 3, states_40,
"\000\000\040\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"},
{297, "if_stmt", 0, 8, states_41,
"\000\000\000\000\000\000\000\000\000\000\000\000\002\000\000\000\000\000\000\000\000\000"},
// ^^^
//...
};
static label labels[176] = {
{0, "EMPTY"},
{256, 0},
{4, 0}, // №2
{270, 0}, // №3
{295, 0}, // №4
//...
{305, 0}, // №26
{11, 0}, // №27
//...
{297, 0}, // №91
{298, 0},
{299, 0},
{300, 0},
{301, 0},
{296, 0},
{1, "if"}, // №97
//...
};
grammar _PyParser_Grammar = {
86,
dfas,
{176, labels},
256
};
(За нижеследующим описанием работы парсера удобно было бы следить по этому листингу — например, открыв его в соседней вкладке.)
Парсер начинает разбор с КА для
single_input; этот КА задан массивом states_0 из трёх состояний. Из начального состояния выходят три дуги (arcs_0_0), соответствующие входным символам NEWLINE (метка №2, символ №4), simple_stmt (метка №3, символ №270) и compound_stmt (метка №4, символ №295). Входной терминал "if" (символ №1, метка №97) входит во множество d_first для compound_stmt, но не для simple_stmt — ему соответствует бит \002 в 13-том байте множества. (Если во время разбора оказывается, что очередной терминал входит во множества d_first сразу для нескольких исходящих дуг, то парсер выводит сообщение о том, что грамматика неоднозначна, и отказывается продолжать разбор.) Итак, парсер переходит по дуге {4, 2} в состояние №2, и одновременно переключается к КА compound_stmt, заданному массивом states_39. В этом КА из начального состояния выходят сразу девять дуг (arcs_39_0); выбираем среди них дугу {91, 1}, соответствующую входному символу if_stmt (№297). Парсер переходит в состояние №1 и переключается к КА if_stmt, заданному массивом states_41. 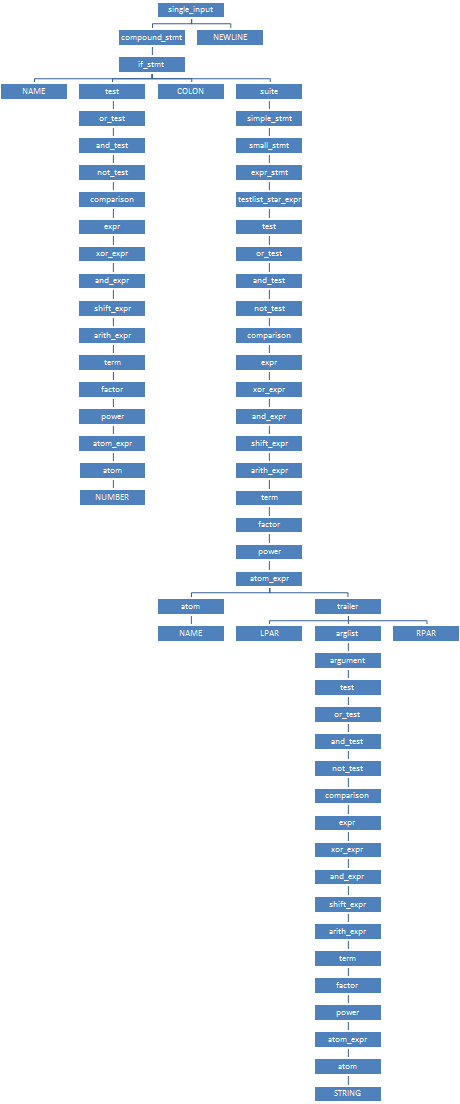
Из начального состояния этого КА выходит всего одна дуга
{97, 1} "if". По ней парсер переходит в состояние №1, откуда опять выходит единственная дуга {26, 2}, соответствующая нетерминалу test (№305). По этой дуге парсер переходит в состояние №2 и переключается к КА test, и так далее. После долгого-предолгого превращения числа 42 в нетерминал test, парсер вернётся в состояние №2, из которого выходит единственная дуга {27, 3}, соответствующая терминалу COLON (символ №11), и продолжит разбор нетерминала if_stmt. В качестве результата его разбора парсер создаст узел конкретного синтаксического дерева (структура node), у которого будет тип узла №297, и четыре ребёнка — типов №1 (NAME), №305 (test), №11 (COLON) и №304 (suite). В состоянии №4 создание узла для if_stmt завершится, парсер вернётся в состояние №1 КА compound_stmt, и вновь созданный узел для if_stmt станет единственным ребёнком узла, соответствующего compound_stmt. Целиком КСД нашей программы будет выглядеть так, как показано справа. Заметьте, как короткая программа из семи терминалов NAME NUMBER COLON NAME LPAR STRING RPAR превратилась в «бамбук» — огромное, почти неветвящееся дерево разбора из аж 64 узлов! Если считать в байтах, то исходная программа занимает 27 байт, а её КСД — на два порядка больше: полтора килобайта на 32-битной системе, и три — на 64-битной! (64 узла по 24 либо 48 байтов каждый). Именно из-за безудержно растягивающегося КСД попытки пропустить через python исходные файлы размером всего в несколько десятков мегабайт приводят к фатальной MemoryError.Для работы с КСД в Python есть стандартный модуль
parser:$ python
Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import parser
>>> parser.suite('if 42: print("Hello world")').tolist()
[257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '42']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, '"Hello world"']]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
>>>
В его исходном коде (
Modules/parsermodule.c) для проверки КСД на соответствие грамматике Python были >2000 рукописных строк, которые выглядели примерно так://...
/* simple_stmt | compound_stmt
*
*/
static int
validate_stmt(node *tree)
{
int res = (validate_ntype(tree, stmt)
&& validate_numnodes(tree, 1, "stmt"));
if (res) {
tree = CHILD(tree, 0);
if (TYPE(tree) == simple_stmt)
res = validate_simple_stmt(tree);
else
res = validate_compound_stmt(tree);
}
return (res);
}
static int
validate_small_stmt(node *tree)
{
int nch = NCH(tree);
int res = validate_numnodes(tree, 1, "small_stmt");
if (res) {
int ntype = TYPE(CHILD(tree, 0));
if ( (ntype == expr_stmt)
|| (ntype == del_stmt)
|| (ntype == pass_stmt)
|| (ntype == flow_stmt)
|| (ntype == import_stmt)
|| (ntype == global_stmt)
|| (ntype == nonlocal_stmt)
|| (ntype == assert_stmt))
res = validate_node(CHILD(tree, 0));
else {
res = 0;
err_string("illegal small_stmt child type");
}
}
else if (nch == 1) {
res = 0;
PyErr_Format(parser_error,
"Unrecognized child node of small_stmt: %d.",
TYPE(CHILD(tree, 0)));
}
return (res);
}
/* compound_stmt:
* if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated
*/
static int
validate_compound_stmt(node *tree)
{
int res = (validate_ntype(tree, compound_stmt)
&& validate_numnodes(tree, 1, "compound_stmt"));
int ntype;
if (!res)
return (0);
tree = CHILD(tree, 0);
ntype = TYPE(tree);
if ( (ntype == if_stmt)
|| (ntype == while_stmt)
|| (ntype == for_stmt)
|| (ntype == try_stmt)
|| (ntype == with_stmt)
|| (ntype == funcdef)
|| (ntype == async_stmt)
|| (ntype == classdef)
|| (ntype == decorated))
res = validate_node(tree);
else {
res = 0;
PyErr_Format(parser_error,
"Illegal compound statement type: %d.", TYPE(tree));
}
return (res);
}
//...
Легко догадаться, что такой однообразный код можно было бы и автоматически генерировать по формальной грамматике. Немногим сложнее догадаться, что такой код уже генерируется автоматически — именно так работают автоматы, используемые первым парсером! Выше я затем в подробностях объяснял его устройство, чтобы пояснить, каким образом я в марте этого года предложил заменить все эти простыни рукописного кода, которые нужно править каждый раз, когда меняется грамматика, — на прогон всех тех же самых автоматически сгенерированных КА, которыми пользуется сам парсер. Это к разговорам о том, нужно ли программистам знать алгоритмы.
В июне мой патч был принят, так что в Python 3.6+ вышеприведённых простыней в
Modules/parsermodule.c уже нет, а зато есть несколько десятков строк моего кода.Работать с таким громоздким и избыточным КСД, как было показано выше, довольно неудобно; и поэтому второй парсер (
Python/ast.c), написанный целиком вручную, обходит КСД и создаёт по нему абстрактное синтаксическое дерево. Грамматика АСД описана в файле Parser/Python.asdl; для нашей программы АСД будет таким, как показано справа.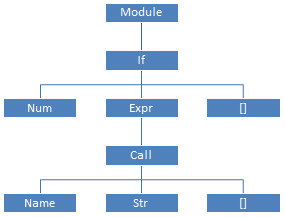
Вместо работы с КСД при помощи модуля
parser, документация советует использовать модуль ast и работать с абстрактным деревом:$ python
Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import ast
>>> ast.dump(ast.parse('if 42: print("Hello world")'))
"Module(body=[If(test=Num(n=42), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hello world')], keywords=[]))], orelse=[])])"
>>>
Как только АСД создано — КСД больше низачем не нужно, и вся занятая им память освобождается; поэтому для «долгоиграющей» программы на Python нет большого значения, сколько памяти занимало КСД. С другой стороны, для больших, но «скорострельных» скриптов (например, поиск значения в огромном
dict-литерале) — размер КСД как раз и будет определять потребление памяти скриптом. Всё это впридачу к тому, что именно размер КСД определяет, хватит ли памяти для того, чтобы загрузить и запустить программу.Необходимость прохода по длинным «бамбуковым ветвям» делает код
Python/ast.c просто отвратительным:static expr_ty
ast_for_expr(struct compiling *c, const node *n)
{
//...
loop:
switch (TYPE(n)) {
case test:
case test_nocond:
if (TYPE(CHILD(n, 0)) == lambdef ||
TYPE(CHILD(n, 0)) == lambdef_nocond)
return ast_for_lambdef(c, CHILD(n, 0));
else if (NCH(n) > 1)
return ast_for_ifexpr(c, n);
/* Fallthrough */
case or_test:
case and_test:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка булевых операций
case not_test:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка not_test
case comparison:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка comparison
case star_expr:
return ast_for_starred(c, n);
/* The next five cases all handle BinOps. The main body of code
is the same in each case, but the switch turned inside out to
reuse the code for each type of operator.
*/
case expr:
case xor_expr:
case and_expr:
case shift_expr:
case arith_expr:
case term:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
return ast_for_binop(c, n);
// case yield_expr: и его обработка
case factor:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
return ast_for_factor(c, n);
case power:
return ast_for_power(c, n);
default:
PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n));
return NULL;
}
/* should never get here unless if error is set */
return NULL;
}
Многократно повторяющиеся на всём протяжении второго парсера
if (NCH(n) == 1) n = CHILD(n, 0); — иногда, как в этой функции, внутри цикла — означают «если у текущего узла КСД всего один ребёнок, то вместо текущего узла надо рассматривать его ребёнка».Но разве что-то мешает сразу во время создания КСД удалять «однодетные» узлы, подставляя вместо них их детей? Ведь это и сэкономит кучу памяти, и упростит второй парсер, позволяя избавиться от многократного повторения
goto loop; по всему коду, от вида которого Дейкстра завращался бы волчком в своём гробу!В марте, вместе с вышеупомянутым патчем для
Modules/parsermodule.c, я предложил ещё один патч, который: - Добавляет в первый парсер автоматическое «сжатие» неветвящихся поддеревьев — в момент свёртки (создания узла КСД и возврата из текущего КА в предыдущий) «однодетный» узел подходящего типа заменяется на своего ребёнка:
diff -r ffc915a55a72 Parser/parser.c --- a/Parser/parser.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Parser/parser.c Mon Sep 05 08:30:19 2016 +0100 @@ -52,16 +52,16 @@ #ifdef Py_DEBUG static void s_pop(stack *s) { if (s_empty(s)) Py_FatalError("s_pop: parser stack underflow -- FATAL"); - s->s_top++; + PyNode_Compress(s->s_top++->s_parent); } #else /* !Py_DEBUG */ -#define s_pop(s) (s)->s_top++ +#define s_pop(s) PyNode_Compress((s)->s_top++->s_parent) #endif diff -r ffc915a55a72 Python/ast.c --- a/Python/ast.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Python/ast.c Mon Sep 05 08:30:19 2016 +0100 @@ -5070,3 +5056,24 @@ FstringParser_Dealloc(&state); return NULL; } + +void PyNode_Compress(node* n) { + if (NCH(n) == 1) { + node* ch; + switch (TYPE(n)) { + case suite: case comp_op: case subscript: case atom_expr: + case power: case factor: case expr: case xor_expr: + case and_expr: case shift_expr: case arith_expr: case term: + case comparison: case testlist_star_expr: case testlist: + case test: case test_nocond: case or_test: case and_test: + case not_test: case stmt: case dotted_as_name: + if (STR(n) != NULL) + PyObject_FREE(STR(n)); + ch = CHILD(n, 0); + *n = *ch; + // All grandchildren are now adopted; don't need to free them, + // so no need for PyNode_Free + PyObject_FREE(ch); + } + } +}
- Соответствующим образом исправляет второй парсер, исключая из него обход «бамбуковых ветвей»: например, вышеприведённая функция
ast_for_exprзаменяется на:
static expr_ty ast_for_expr(struct compiling *c, const node *n) { //... switch (TYPE(n)) { case lambdef: case lambdef_nocond: return ast_for_lambdef(c, n); case test: case test_nocond: assert(NCH(n) > 1); return ast_for_ifexpr(c, n); case or_test: case and_test: assert(NCH(n) > 1); // обработка булевых операций case not_test: assert(NCH(n) > 1); // обработка not_test case comparison: assert(NCH(n) > 1); // обработка comparison case star_expr: return ast_for_starred(c, n); /* The next five cases all handle BinOps. The main body of code is the same in each case, but the switch turned inside out to reuse the code for each type of operator. */ case expr: case xor_expr: case and_expr: case shift_expr: case arith_expr: case term: assert(NCH(n) > 1); return ast_for_binop(c, n); // case yield_expr: и его обработка case factor: assert(NCH(n) > 1); return ast_for_factor(c, n); case power: return ast_for_power(c, n); case atom: return ast_for_atom(c, n); case atom_expr: return ast_for_atom_expr(c, n); default: PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n)); return NULL; } /* should never get here unless if error is set */ return NULL; }
С другой стороны, у многих узлов в результате «сжатия ветвей» дети теперь могут быть новых типов, и поэтому во многих местах кода приходится добавлять новые условия.
- Поскольку «сжатое КСД» уже не соответствует грамматике Python, то для проверки его корректности в
Modules/parsermodule.cвместо «сырой»_PyParser_Grammarтеперь нужно использовать автоматы, соответствующие «транзитивному замыканию» грамматики: например, для пары продукций
—добавляются следующие «транзитивные» продукции:or_test ::= and_test test ::= or_test 'if' or_test 'else' test
test ::= or_test 'if' and_test 'else' test test ::= and_test 'if' or_test 'else' test test ::= and_test 'if' and_test 'else' test
Во время инициализации модуляparser, функцияInit_ValidationGrammarобходит автосгенерированные КА в_PyParser_Grammar, на основе них создаёт «транзитивно замкнутые» КА, и сохраняет их в структуреValidationGrammar. Для проверки корректности КСД используется именноValidationGrammar.
Сжатое КСД для нашего примера кода содержит всего 21 узел:
$ python
Python 3.7.0a0 (default:98c078fca8e0+, Oct 31 2016, 09:00:27)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import parser
>>> parser.suite('if 42: print("Hello world")').tolist()
[257, [295, [297, [1, 'if'], [324, [2, '42']], [11, ':'], [270, [271, [272, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [324, [3, '"Hello world"']]]], [8, ')']]]]], [4, '']]]], [4, ''], [0, '']]
>>>
С моим патчем стандартный набор бенчмарков показывает сокращение потребления памяти процессом
python до 30%, при неизменившемся времени работы. На вырожденных примерах сокращение потребления памяти доходит до трёхкратного!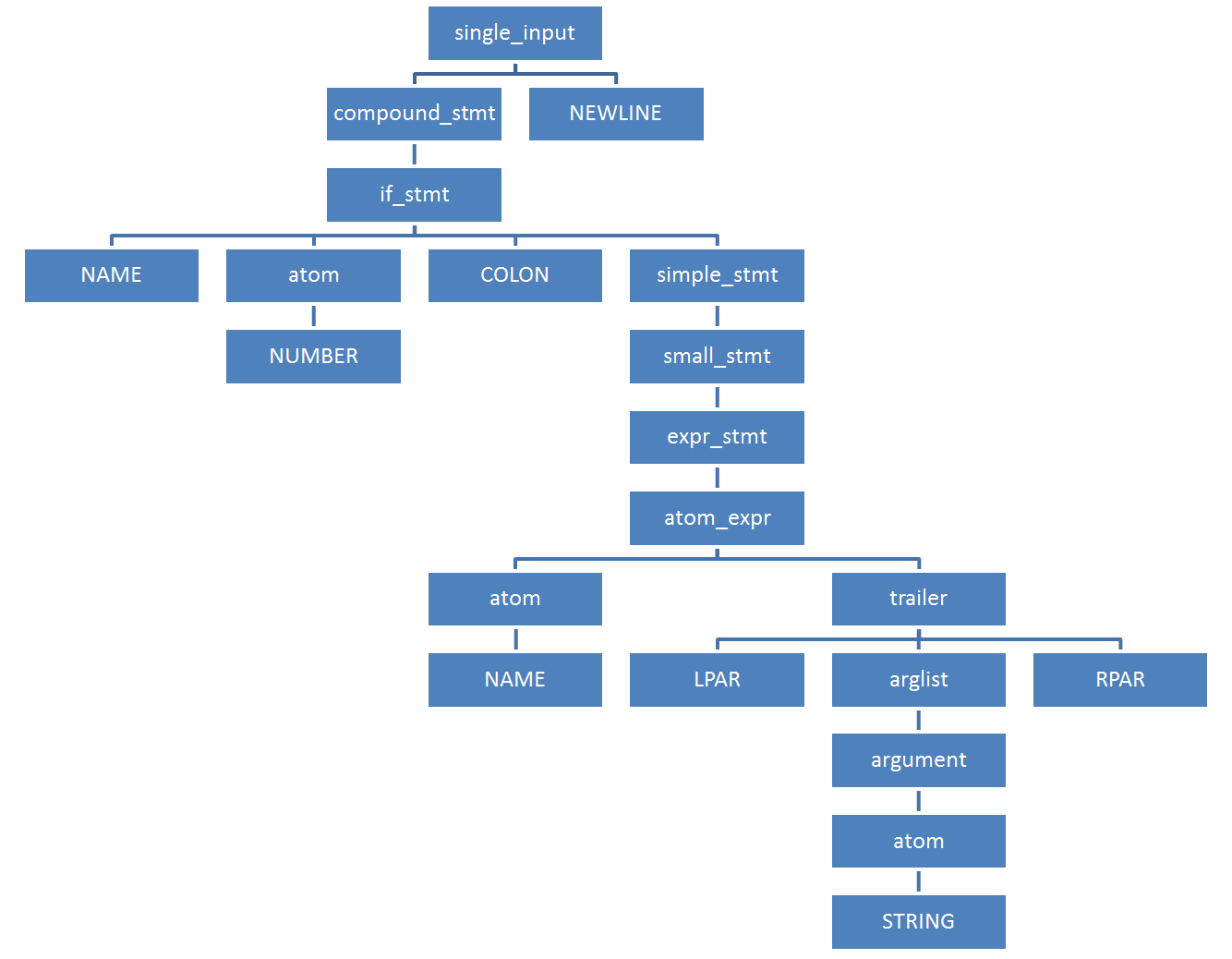
Но увы, за полгода с тех пор, как я предложил свой патч, никто из мейнтейнеров так и не отважился его отревьюить — настолько он большой и страшный. В сентябре же мне ответил сам Гвидо ван Россум: «Раз за всё это время никто к патчу интереса не проявил, — значит, никого другого потребление памяти парсером не заботит. Значит, нет смысла тратить время мейнтейнеров на его ревью.»
Надеюсь, эта статья объясняет, почему мой большой и страшный патч на самом деле нужный и полезный; и надеюсь, после этого объяснения у Python-сообщества дойдут руки его отревьюить.
Комментарии (66)

Iceg
07.11.2016 00:52+3Если так трактовать фразу «Изучения программирования нужно начинать с Python», то — да :)

maxfox
07.11.2016 01:16+3Подскажите, пожалуйста, человеку, далекому от C и парсеров/компиляторов… Насколько нормален такой код (как по ссылкам) в мире системного программирования и разработки ЯП? Ну т.е. писать такое руками? Это считается качественным кодом? Просто выглядит жутковато…
iCpu
07.11.2016 06:28+3Нет, это не считается качественным кодом. Тем не менее, можно взять один из формальных параметров: статистический анализ кода и его результаты. https://habrahabr.ru/company/pvs-studio/blog/306204/
Судя по нему, ситуация достаточно стандартная.
Любой синтаксический анализ, и, тем более, анализ сложных языковых систем — большая задача. «Большая» в системном смысле, для её решения приходится многократно повторять очень похожие языковые конструкции. Поэтому ужасное, но работающее решение из первой версии может спокойно перекочевать в последнюю, потому как в определённый момент ничего лучше не было, а сейчас любые попытки исправления ситуации выглядят ужасающе. Собственно, именно такую реакцию и проявило руководство группы разработчиков. И это тоже стандартно. И, если они не изменят решения, то, вполне возможно, они потеряют лидирующие позиции при разработке стандартов в пользу тех групп, чьи альтернативные интерпретаторы не будут выжирать ВСЮ память, чтобы запустить «Hello, Kitty!»

jam31
07.11.2016 01:50Я регулярно упираюсь в лимиты памяти при программировании быстрых и грязных системных утилит на питоне. Из недавнего: при анализе многоугольников внутри векторной графики потребление памяти достигло десятка гигабайт. По хорошему, нужно переключаться на C etc., но времени для этого нет. Так что если Ваш патч не примут, Вы всё равно можете создать свою сборку и облегчить жизнь многим людям.
blueboar2
07.11.2016 06:52+4А теперь смотрите — приняли его патч. Этот патч, как я понял, уменьшает количество памяти, требуемое на ПАРСИНГ программы. Сколько у вас весит исходный код? Мегабайт? Ну может два, и то такое редко бывает. Допустим даже, что при разборе понадобится в 50 раз больше памяти. 100 Мегабайт. Даже 200. Как заявляет автор, его патч уменьшит это число на 30%. Будет 140 Мегабайт. 60 сэкономится. И толку вам с этих 60 Мега(!)байт, если ваша программа ворочает десятками гига(!)байт?

tyomitch
07.11.2016 08:09+51) количество памяти, требуемое на парсинг, уменьшается в среднем втрое (200 Мб -> 67 Мб); для некоторых реальных программ это означает уменьшение памяти, нужной на загрузку и работу в сумме, на 30%.
2) если программа во время работы выполняет динамически генерируемый код, что для скриптовых языков типа Python обычное дело, — то объём кода, который нужно распарсить, не ограничен единицами мегабайт исходников.blueboar2
07.11.2016 09:51+1Хм. Ну даже и в три раза. Для его десятков гигабайт это мелочи. Около 1%. А выполнять динамически генерируемый код — я б не сказал, что это прямо «обычное дело». Ну бывает, да. Но чтобы в каждой второй программе…
Не поймите, что я против этого патча. Любое улучшение это плюс. Просто оно не такое чтобы прямо супер, как тут пишут.
saboteur_kiev
09.11.2016 04:09-1скриптов на питоне, которые быстро прогоняют через себя сотни мегабайт логов или скл данных, и это все крутится на виртуалках. Постоянное выделение и освобождение памяти — кластер будет доволен.

sebres
10.11.2016 22:22+1скриптов на питоне, которые быстро прогоняют через себя сотни мегабайт логов или скл данных
Не путайте, ибо в контексте статьи и патчей, важно сколько те скрипты через себя (питоньих) исходников или jit (eval и иже с ними) "прогоняют".

igrishaev
07.11.2016 17:06+1Объясните, пожалуйста, что вы имели в виду под "динамически генерируемым кодом"? Eval, скрипты в играх?

Antervis
07.11.2016 09:55а вам не кажется, что любая, пусть даже мало значимая оптимизация в коде интерпретатора/компилятора очень ценна, т.к. эта оптимизация скажется на миллионах пользователей?
blueboar2
07.11.2016 10:01+2Я выше комментатору написал — я всецело за оптимизации, и понимаю, что она принесет пользу. Просто показать что она не такая огромная. А то что польза есть — тут я не спорю, надо внедрять.

thatsme
07.11.2016 01:51+5Спасибо за статью и за ПАТЧ!
Жаль, что мантейнеры его не осилили.
У меня от самого рождения питона, было чёткое убеждение, что Гвидо плохо себе представляет, что такое формальные грамматики, и или брезгует, или на момент создания не знал о том, что есть генераторы парсеров.

Flux
07.11.2016 03:47+7«Раз за всё это время никто к патчу интереса не проявил, — значит, никого другого потребление памяти парсером не заботит. Значит, нет смысла тратить время мейнтейнеров на его ревью.»
Схоронил статью, будет во что тыкать носом фанатов писать на голом питоне всё, от обработки изображений до тяжелой математики.
YaakovTooth
07.11.2016 07:11+6Зачем это писать на голом питоне если есть pillow, numpy и scipy?
Flux
07.11.2016 22:33+1Потому что могут это писать на голом питоне.
Шучу, потому что не могут не на питоне. Вообще, этот вопрос задавать нечестно — смысловой посыл такой же как в моём комменте на который вы отвечали.
kozzztik
07.11.2016 18:29А что, собственно, кого-то волнует место, занимаемое программой после того как ее разобрал интерпретатор? Это настолько незначительно, что действительно никого особо не заботит, и Гвидо тут в некотором роде прав.
С другой стороны, если можно сэкономить, почему нет. Времени у ментейнеров не очень то много, и оно пойдет на что-то другое, вероятно еще более полезное.
Вообще если вы угораете по экономии памяти, то, очевидно, питон далеко не самый подходящий язык.tyomitch
07.11.2016 18:43Вообще если вы угораете по экономии памяти, то, очевидно, питон далеко не самый подходящий язык.
Какой язык вы бы предложили для упомянутой мной задачи (поиск значения в огромномdict-литерале)? sqlite?kozzztik
07.11.2016 21:02а sqlite это язык? Простите, из очевидного — Си, с плюсами и без. Даже Паскаль подойдет лучше, чем питон, если вам важна память. Ассемблер если борода позволяет. Есть еще много языков, которые обращаются с памятью лучше питона.
Питон это в первую очередь скорость и качество разработки. При том скорость разработки, а не исполнения. Зачастую это единственное что важно, даже в хайлоаде. Но если нужно экономно работать с памятью или действительно качественно утилизировать процессор, то очевидно питон не лучший выбор.tyomitch
08.11.2016 01:36У меня не было цели сэкономить память, у меня была цель «сделать как можно быстрее и удобнее» — и речь именно о скорости разработки, а не исполнения. В данной задаче проблема была не в том, что мне было для Python жалко лишний гигабайт памяти, — а в том, что у меня этого лишнего гигабайта тупо не было в системе, так что скрипт не запускался.
(Если вам интересно, то конкретно эту задачу я пробовал решать на Си, — и GCC точно так же, как и Python, вылетает при попытке объявить многомегабайтную структуру-литерал.)
Deosis
08.11.2016 07:44Вы пытаетесь данные представить как код, где-то выше писали, что выгоднее сложить их в отдельный файл и вручную загрузить и распарсить. Оверхед в рантайме будет настолько мал, что выгода от прямого включения данных в код перевесит ручную загрузку только при соотношении запусков скрипта к его компиляциям примерно 1000 к 1.
tyomitch
08.11.2016 12:11+1Это-то ясно, но с точки зрения удобства и скорости разработки есть большая разница: в одном случае надо писать код для загрузки и парсинга данных, а также начальной генерации файла с даннами; в другом случае не надо писать вообще ничего — дамп данных в чистом виде как раз и является кодом скрипта.
(В конечном итоге я именно по-вашему свой скрипт и реализовал, через pickle.)
kozzztik
08.11.2016 15:33Ну, это должно как бы намекнуть, что вы что-то делаете кардинально не так, и дело уже совсем не в питоне. Я не к тому, что фикс не нужен. Выпилить спагетти и получить хоть и небольшой, но профит — я лично всегда за. Но не нужно удивляться тому, что ни у кого из разработчиков не нашлось времени поревьювить — кейс более чем странный. На столько, что никто не считает его важным. Так делать просто не нужно (я про кейс, а не фикс). Делать фикс того, что язык работает не очень хорошо, когда его используют неправильно никто не хочет.
Тут был хороший совет выйти на кого-то из разработчиков напрямую, и убедить в том что это надо. Можно еще сменить стратегию — не нужно рассказывать о том что вы пытались создать многомегабайтную структуру литерал и у вас не вышло. Об этом вообще на самом деле лучше никому не рассказывать ) Взять стандартные кейсы, что стандартная программа будучи запущенной будет занимать на столько то меньше памяти и еще что-то, что этот фикс дает при нормальном ежедневном использовании. Это будет явное описание того, какую он на самом деле ценность представляет.tyomitch
08.11.2016 15:44+2Можно еще сменить стратегию — не нужно рассказывать о том что вы пытались создать многомегабайтную структуру литерал и у вас не вышло. Об этом вообще на самом деле лучше никому не рассказывать ) Взять стандартные кейсы, что стандартная программа будучи запущенной будет занимать на столько то меньше памяти и еще что-то, что этот фикс дает при нормальном ежедневном использовании. Это будет явное описание того, какую он на самом деле ценность представляет.
В моём тикете (как и в этой статье) вся история описана целиком: «у меня был странный кейс, я подпилил Python чтобы он справлялся с моим кейсом, и в результате на стандартном наборе бенчмарков потребление памяти снизилось на 30%». Именно последний факт — мой главный аргумент.kozzztik
08.11.2016 16:01+1По комментарию Гвидо, он судя по всему зацепился за сам кейс. Может прочитал по диагонали, и взгляд зацепился только за это. Он вообще, судя по всему, весьма специфичный товарищ. Собственно PEP20, пункт 14. Кстати говоря можно попробовать сослаться на этот самый PEP в аргументации почему этот фикс все таки нужен.

0xd34df00d
11.11.2016 23:05+1качество разработки
Лично для меня сомнительна применимость термина «качество» к динамически, пусть и сильно, типизированному коду.kozzztik
12.11.2016 00:05-1Если вы отправляете ракету в космос, то да. Но на «обычных» проектах вполне достаточно аннотаций с инспекциями. И больше важны такие вещи как легко и быстро обвешать все тестами и быстро написать сам код, что бы было больше времени и на тесты, и на документацию и а на рефакторинг. А время ресурс обычно весьма ограниченный. Ну и что немаловажно — в питоне только один стандарт написания кода. Имхо, когда нужно много, быстро и качественно — питон лучший выбор. До тех пор пока не нужно «очень %s», как то производительно, качественно, параллельно и т.д. Там уже есть более подходящие инструменты.
0xd34df00d
12.11.2016 20:17+2легко и быстро обвешать все тестами
А всё не надо обвешивать, часть проблем может поймать тайпчекер, которые иначе вообще непонятно как ловить, кстати… Кроме того, посмотрите вот, разве не легко и не быстро? А чистота и прочие ништяки (которые вытекают из системы типов) гарантируют, что тесты имеют смысл.
Ну и да, система типов же позволяет фреймворку для тестов автоматически генерировать входные значения и сужать их для нахождения конкретного входа, на котором фейлятся тесты.
быстро написать сам код
На выразительном статически типизированном языке это делать не медленнее, чем на динамическом.
на документацию
Чистота и естественным образом имеющиеся сигнатуры функций (пусть и выведенные компилятором, кстати) помогают писать эту документацию.
на рефакторинг
Рефакторинг в каком-нибудь хаскеле делать вообще одно удовольствие. Поменяли что вам надо, добились, что программа компилируется, значит, скорее всего, все тесты будут зелеными.
Flux
07.11.2016 22:26Так-то не очень корректный вопрос, с задачей практически любой язык справится. Но если бы от этой задачи зависело быстродействие системы и оно было бы важно, то решал бы на чем угодно что компилируется или jit-компилируется. Скорее всего на C++.
tyomitch
08.11.2016 01:30О быстродействии речь не шла вообще, ни в статье ни в комментариях. При чём тут оно?
Любую задачу, имеющую решение, можно решить на любом тюринг-полном языке, так что «практически любой язык справится» — не аргумент. Фортран тоже справится, может на нём надо было писать?
(Если вам интересно, то конкретно эту задачу я пробовал решать на Си, — и GCC точно так же, как и Python, вылетает при попытке объявить многомегабайтную структуру-литерал.)
0xd34df00d
11.11.2016 23:04А откуда dict берётся? По нему один раз вы проходите? Если да, то тогда можно и с хаскелем побаловаться, можно и в constant memory уложиться будет достаточно натурально.
Flux
07.11.2016 22:31+2Да, от потребления памяти парсером зависит в конечном итоге не так много. Больше огорчает общий настрой разработчиков языка, которые мало того что не пилят производительный код с первого раза, так еще и брезгуют своим «ценным временем» когда им под нос суют готовую, сделанную оптимизацию.
Тут рукой подать до подхода «память не ресурс», а когда такой подход применяется не конкретным разработчиком а рантаймом языка — это звездец.
Собственно именно по этим причинам питон так и останется языком для вызова оберток над нормальным кодом или написания нетребовательных приложений.
Sirikid
08.11.2016 15:10С одной строны готовая оптимизация, а с другой стороны рефакторинг такого спагетти что даже автор не поручается за корректность результата.
tyomitch вы большой молодец, надеюсь все написано верно, возможно патч примут когда кто-нибудь из ревьюверов сам столкнется с этой проблемой. Вы не в курсе, есть какие-нибудь баги в этой подсистеме python?
kozzztik
08.11.2016 15:19Вы не забывайте, что это опенсорс. Заявлять что ментейнеры «брезгуют своим ценным временем» это как минимум некрасиво и очень лицемерно. Вы побрезговали своим ценным гораздо больше — вы даже не потратили его на то что бы стать ментейнером, не говоря о том что бы отревьювить как ментейнер.
К тому же нужно понимать, что всегда приходится выбирать. Время можно потратить на одно, а можно на другое. Выбрали другое. Видимо оно было важнее.
К слову говоря не слышал, что бы кого-то не устраивало текущее положение питона как языка. Вроде бы всех устраивает.

Zada
07.11.2016 04:00+4Посмотрел, мало что понял. Но ты крут!
Куда писать/пиговать/голосовать за патч? Надо его проталкивать.
caban
07.11.2016 06:55+2А почему не используется Lexx и Yacc? Я думал для таких проектов это норма?

Duduka
07.11.2016 08:22+3Lexx для любителей фантастики, а Lex и Yacc для «домашнего» языко-строения, yacc парсит LR(1) с кубической сложностью.
tyomitch
07.11.2016 10:17yacc работает за линейное время. Кубическая сложность (в теории) нужна для произовольной КСГ, без ограничений LR(1).
Парсер Python тоже работает за линейное время. К скорости его работы никаких нареканий у меня нету.

KvanTTT
07.11.2016 12:04А что скажете про ANTLR 4?
tyomitch
07.11.2016 12:26Скажу, что это LL-парсер, и поэтому он спотыкается на грамматиках с левой рекурсией, в отличие от yacc и подобных ему LR-парсеров.
KvanTTT
08.11.2016 00:34+1У вас устаревшие сведения: ANTLR 4 не спотыкается на леворекурсивных правилах: Left-recursive rules.
RPG
07.11.2016 10:06На самом деле, даже такая мелочь как потребление памяти "хелловордом" в Python крайне раздражает. Python, который ещё ничего не делает, съедает сразу 6 МБ. Если мне надо запустить сотню скриптов параллельно — это уже проблема. Или другой пример — минималка CentOS, куча демонов — postfix, imap, https, systemd, rsyslog, у всех потребление памяти ~ 6-10 МБ. И выделяется firewalld, который по сути ничего не делает и жрёт при этом 25 МБ. Подозреваю, тут уже не в интерпретаторе дело, а в каких-нибудь хэш-таблицах, сделанных через односвязный список...
Но вот что интересно, если 100 человек отправит в апстрим аналогичный патч, снижающий потребление ОЗУ, то возможно сообщество прислушается?
tyomitch
07.11.2016 10:22Нет, такие вопросы решаются не голосованием. Мейнтейнеры Python — добровольцы, и единственный способ добиться ревью патча — убедить ревьюера, что лично ему этот патч интересен.

apro
07.11.2016 10:42+4Обычно если нужно "протолкнуть" патч типа этого, его разбивают на как можно
большое количество более мелких патчей, и проводят много разных бенчмарков
подтверждающих его пользу. Можно еще с кем-то из мантейнеров лично поговорить
на какой-нибудь конференции.tyomitch
07.11.2016 11:49+1Тут дело не столько в бенчмарках, сколько в корректности. Python/ast.c — это такая кастрюля спагетти-кода, что определить «на глазок», вносит мой патч ошибки или не вносит, крайне тяжело. Я бы и сам не дал руку на отсечение, что не вносит.
Нехорошо, когда в ядре проекта лежит спагетти-код десятилетней давности, в котором никто из ныне действующих разработчиков не разбирается и не хочет разбираться; но, как выше отметил iCpu, это довольно типичная ситуация.

zagayevskiy
07.11.2016 10:53-1в каких-нибудь хэш-таблицах, сделанных через односвязный список
Wat?
burjui
07.11.2016 11:27Научу гуглить за умеренную плату.
zagayevskiy
07.11.2016 11:30Спасибо, я в курсе. Только вот человек это сказал в контексте большого потребления памяти. Прямо десятки мегабайт оно у него жрет.


Gorthauer87
07.11.2016 12:04Интересно, а какой парсер в piston'е используется? Может его разработчики будут посговорчивее?
tyomitch
07.11.2016 12:20Код парсера там полностью другой, так что описанные в статье проблемы к их парсеру не относятся.
saw_tooth
07.11.2016 14:17-3Гвидо верно ответил: вопрос памяти никого не интересует, потомоу что ее в любой момент можно добавить (давайте без крайностей). А вот многопоточность вменяемая интересует всех, потому что с ней решится куча вопросов, и облегчится жизнь. На пайконе 2016 там серия докладов была по этому поводу, и народец вроде как разшевелился.
kozzztik
07.11.2016 18:32+2Так что, кто то придумал что-то лучше GIL?
ggrnd0
16.02.2017 14:06qwerty-клавиатура практически стандарт.
Ее используют в экранных и физических клавах банально потому что 99.9% людей с ней знакомы.
И использовать какую-либо ее особого смфысла просто нет...
Здесь скорее вопрос в спросе.
Спроса на plugable-mini-qwerty будет скорее всего больше чем на ваш оригинальный октодон...
В любой случае, я предлагаю расширить ассортимент и начать как раз с slide-клавиатуры если она не защищена патентом… иначе остается только вариант с фиксированной задней панелью и зеркальным qwerty...
С учетом разверов лопат 5"+ slider-клава будет нереально удобной=)
kozzztik
08.11.2016 21:31Ну, обнадеживающий он только в том случае если вы его либо слушали не внимательно, либо не до конца. Ибо в конце были замечательные графики падением производительности до 25 раз. Лучший тест «всего лишь» вдвое медленнее чем на GIL.
И это при том, что все проблемы до сих пор не решны до конца. В частности нужно, всего лишь, поменять сборщик мусора, по хорошему переписать все С extentions… По сути все там же где и было — на понимании того, что отказ от GIL это боль и без него все будет тормозить. Докладчик просто очень оптимистично все это рассказывал )


wOvAN
картинка [Делайте добро]
iCpu
Картинка [и не надейтесь остаться безнаказанными]