

Из этого дерева понятно, что связаны слова «мама» и «мыла», а также «мыла» и «раму», а слова «мама» и «раму» напрямую не связаны.
Статья будет полезна тем, кому понадобился синтаксический анализатор, но не понятно, с чего начать.
Я занимался этой темой несколько месяцев назад, и на тот момент нашел не много информации по поводу того, где бы взять готовый и желательно свободный анализатор.
На Хабре есть отличная статья об опыте работы с MaltParser. Но с тех пор некоторые пакеты, используемые для сборки, переехали в другие репозитории и чтобы собрать проект с нужными версиями библиотек, придется хорошенько потрудиться.
Есть и другие варианты, среди которых SyntaxNet. На Хабре я не нашел ничего про SyntaxNet, поэтому восполняю пробел.
Что такое SyntaxNet
По сути SyntaxNet — это основанная на TensorFlow библиотека определения синтаксических связей, использует нейронную сеть. В настоящий момент поддерживается 40 языков, в том числе и Русский.
Установка SyntaxNet
Весь процесс установки описан в официальной документации. Дублировать инструкцию здесь смысла не вижу, отмечу лишь один момент. Для сборки используется Bazel. Я попробовал собрать проект с его помощью у себя на виртуалке с Ubuntu 16.04 x64 Server с выделенными 4-мя процессорами и 8 ГБ оперативной памяти и это не увенчалось успехом — вся память съедается и задействуется своп. После нескольких часов я прервал процесс установки, и повторил всё, выделив уже 12 ГБ оперативной памяти. В этом случае все прошло гладко, в пике задействовался своп только на 20 МБ.
Возможно есть какие-то настройки, с помощью которых можно поставить систему в окружении с меньшим объемом оперативной памяти. Возможно сборка выполняется в нескольких параллельных процессах и стоило выделять виртуальной машине только 1 процессор. Если вы знаете, напишите в комментариях.
После завершения установки я оставил для этой виртуальной машины 1ГБ памяти и этого хватает с запасом для того, чтобы успешно парсить тексты.
В качестве размеченного корпуса я выбрал Russian-SynTagRus, он более объемный по сравнению с Russian и с ним точность должна получаться выше.
Использование SyntaxNet
Чтобы распарсить предложение, переходим в каталог
tensorflow/models/syntaxnet и запускаем (путь к модели — абсолютный):echo "Мама мыла раму" | syntaxnet/models/parsey_universal/parse.sh /home/tensor/tensorflow/Russian-SynTagRus > result.txtВ файле result.txt получаем примерно такой вывод, я заменил данные в 6-й колонке на "_", чтобы тут не переносились строки, иначе неудобно читать:
cat result.txt
1 Мама _ NOUN _ _ 2 nsubj __
2 мыла _ VERB _ _ 0 ROOT _ _
3 раму _ NOUN _ _ 2 dobj __Данные представлены в формате CoNLL-U. Тут наибольший интерес представляют следующие колонки:
1. порядковый номер слова в предложении,
2. слово (или символ пунктуации),
4. часть речи, тут можно посмотреть описание частей речи,
7. номер родительского слова (или 0 для корня).
То есть мы имеем дерево, в которм слово «мыла» — корень, потому что оно находится в той строке, где колонка номер 7 содержит «0». У слова «мыла» порядковый номер 2. Ищем все строки, в которых колонка номер 7 содержит «2», это дочерние элементы к слову «мыла». Итого, получаем:

Кстати, если разобраться подробнее, то дерево не всегда удачно представляется все зависимости. В ABBYY Compreno, например, в дерево добавляют дополнительные связи, которые указывают на связь элементов, находящихся в разных ветках дерева. В нашем случае таких связей мы не получим.
{kind=link}
Интерфейс
Если вам критична скорость парсинга текстов, то можно попробовать разобраться с TensorFlow Serving, с помощью него можно загружать модель в память один раз и далее получать ответы существенно быстрее. К сожалению, наладить работу через TensorFlow Serving оказалось не так просто, как казалось изначально. Но в целом это возможно. Вот пример, как это удалось сделать для корейского языка. Если у вас есть пример как это сделать для русского языка, напишите в комментариях.
В моем случае скорость парсинга не была сильно критичной, поэтому я не стал добивать тему с TensorFlow Serving и написал простое API для работы с SyntaxNet, чтобы можно было держать SyntaxNet на отдельном сервере и обращаться к нему по HTTP.
В этом репозитории есть и веб интерфейс, который удобно использовать для отладки, чтобы посмотреть как именно распарсилось предложение.

Чтобы получить результат в JSON, делаем такой запрос:
curl -d text="Мама мыла раму." -d format="JSON" http://<host where syntax-tree installed>Получаем такой ответ:
[{
number: "2",
text: "мыла",
pos: "VERB",
children: [
{
number: "1",
text: "мама",
pos: "NOUN",
children: [ ]
},
{
number: "3",
text: "раму",
pos: "NOUN",
children: [ ]
}
]
}]Уточню один момент. Bazel интересным образом устанавливает пакеты, так, что часть бинарников хранится в
~/.cache/bazel. Чтобы получить доступ к их исполнению из PHP, я на локальной машине добавил права на этот каталог для пользователя веб сервера. Наверное той же цели можно добиться более культурным путем, но для экспериментов этого достаточно.Что еще
Еще есть MaltParser, о котором я упомянул вначале. Позже я обнаружил, что тут можно скачать размеченный корпус SynTagRus и даже успешно обучил на нем свежую версию MaltParser, но не нашел пока времени довести дело до конца и собрать MaltParser целиком, чтобы получать результат парсинга. Эта система немного иначе строит дерево и мне для своей задачи интересно сравнить результаты, получаемые с помощью SyntaxNet и MaltParser. Возможно в следующий раз удастся написать об этом.
Если вы уже успешно пользуетесь каким-либо инструментом для синтаксического анализа текстов на русском языке, напишите в комментариях, чем вы пользуетесь, мне и другим читателям будет интересно узнать.
UPD
Весьма полезные уточнения от buriy в комментарии ниже:
синтаксический анализ там намного лучше работал бы, если бы не было ошибок в модели морфологии, которая не основана на словарях, а тоже является нейросетью
Во входном формате знаки пунктуации — отдельные токены.
Поэтому предложения на вход надо подавать таком виде, чтобы знаки препинания были с двух сторон отделены пробелами.
Ну и ещё точка в конце предложения иногда что-то меняет
Перед финальной точкой тоже должен стоять пробел, так устроен входной формат и на таких примерах модель обучалась
Комментарии (20)

opaopa
14.12.2016 18:24+3Поскольку у меня нет машины с 12Г ОЗУ, спрошу здесь.
Как у него с классикой:
1. Эти типы стали…
2. На косой косе Косой…
mnv
14.12.2016 18:38Не удивлюсь, что если я выделил бы 1 процессор для виртуалки вместо 4, то оперативной памяти понадобилось бы раза в 4 меньше, т.е. хватило бы 3 ГБ. Возможно, количество параллельных процессов при сборке можно задать где-то в конфигурации Bazel, я не искал.
mnv
14.12.2016 18:53Насчет классики, результаты такие:
Эти типы стали есть на складе

MisterParser
14.12.2016 22:35Скажите, пожалуйста, в какой реальной задаче может потребоваться такое дерево? На ум приходит только перевод текста, но с этой задачей успешно справляются уже существующие сервисы. Неужели вы пилите велосипед-переводчик?
mnv
14.12.2016 22:39+1Мне синтаксическое дерево понадобилось в модуле определения тональности слов/коротких фраз в тексте. Если построить дерево, то становится понятно, какие тональные признаки связаны с интересующей фразой, а какие нет.

buriy
14.12.2016 22:53+2На самом деле, синтаксический анализ там намного лучше работал бы, если бы не было ошибок в модели морфологии, которая не основана на словарях, а тоже является нейросетью. Кто бы взялся это починить…
Нарисуйте, пожалуйста, вывод для фразы «Маша увидела зелёного крокодила». Я долго смеялся, какой частью речи оказался бедный крокодил.
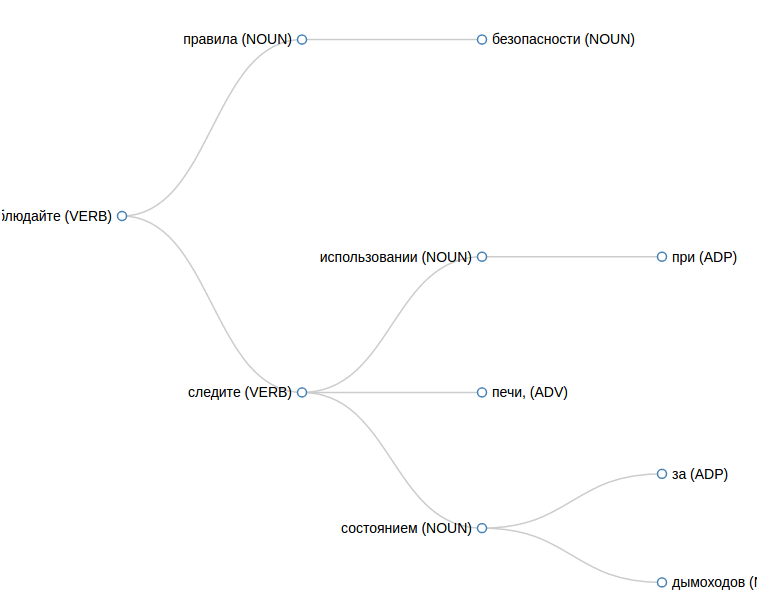
P.S. Во входном формате знаки пунктуации — отдельные токены. Пожалуйста, отделите пробелом запятую после слова «печь» в посте, тогда прикрепление этого и соседних слов должно исправиться.
Ну и ещё точка в конце предложения иногда что-то меняет, например, в этом предложении — dobj на nmod у слова «состоянием».mnv
14.12.2016 23:26Да, действительно, с точкой и без точки разница может быть весьма существенной, пробелы перед символами пунктуации тоже влияют на результат. Тоже обращал на это внимание, но за давностью дел забыл упомянуть об этом в тексте. Спасибо. Ваши примеры:
С точкой:
Маша увидела зелёного крокодила.
buriy
15.12.2016 00:17+1Что значит «лучше скармливать»? Перед финальной точкой тоже должен стоять пробел, так устроен входной формат и на таких примерах модель обучалась. Знаки пунктуации моделью должны выдаваться как отдельный токен под названием PUNCT, если таких токенов нет — значит, вы их не отбили пробелом от слов :)
(И, наверное, лучше добавление пробелов сделать с помощью регулярного выражения у вас в коде, чтобы больше так не ошибаться :) ).
Крокодила — глагол, потому что такого слова морф. модель не видела, и оно похоже по форме на «родила». А «крокодила.», с точкой на конце, — это совсем другое слово, которое модель морфологии считает существительным.mnv
15.12.2016 00:27Мне в плане пробелов перед знаками пунктуации повезло, потому что я перед построением синтаксического дерева разбиваю текст на предложения с помощью Томита-парсера от Яндекса, а он отдает результат как раз в таком виде.
masai
15.12.2016 18:24+2В какой-то книге видел такой пример для обмана анализаторов: «Дочь генерала на балконе». Там «генерала» тоже как глагол парсился.

alex4321
16.12.2016 20:46+1В нашем случае:
1 Дочь _ VERB _ Animacy=Inan|Case=Nom|Gender=Fem|Number=Sing|fPOS=NOUN++ 0 ROOT _ _
2 генерала _ NOUN _ Animacy=Anim|Case=Gen|Gender=Masc|Number=Sing|fPOS=NOUN++ 1 nmod _ _
3 на _ ADP _ fPOS=ADP++ 4 case _ _
4 балконе _ NOUN _ Animacy=Inan|Case=Loc|Gender=Masc|Number=Sing|fPOS=NOUN++ 1 nmod _ _
Дочь — это определенно новый глагол :-)mnv
16.12.2016 21:23Действительно. Причем если дочь с маленькой буквы, то уже определяется как существительное

eugin_b
28.03.2017 12:57Мне наверное показалось, но лазерный дальномер, технически довольно сложная вещь. Если крутиться вокруг оси, то проскальзывания могут внести погрешность. Тут нужно тогда направлять луч, по методу радара. Не знаю может ли его заменить УЗ датчик. От двух видеокамер, более информативное изображение, но тоже нетривиальное для распознавания. Разработка нейросети тоже довольно ресурсоемкое занятие. У автора вариант с видеокамерой в комнате самый простой. Простота в том, что нужно распознавать не все подряд, а только сам пылесос. Камера видит ИК. И пылесос тоже можно снабдить ИК меткой. Даже просто 4 ИК диода на корпусе, позволят довольно легко распознать расположение пылесоса в комнате, а заодно и его ориентацию в пространстве, если их расположить несимметрично. Под влиянием данного проекта, просмотрел еще несколько самодельных проектов роботов-пылесосов, НО НИ ОДИН ИЗ НИХ не является умным. Все они реализуют довольно простые алгоритмы движения и не являются умней, чем мой покупной. Мой может залезть в какую-то дыру и совершать бесчисленные однотипные итерации, пока не закончится время его работы. Даже в какой-то степени обидно. Потратить кучу сил на разработку девайса, а в результате получить довольно посредственное устройство, тем более, что он не так дорого и стоит…

ServPonomarev
15.12.2016 08:22+1Сам пользуюсь синтаксическим парсером для русского английского языков и весьма доволен.
Можно попросить тестовый доступ к парсеру Аббии Compreno — обычно не отказывают.
Или можно посмотреть актуальный список парсеров здесь.
Моё мнение — решения на нейронных сетях всё ещё проигрывают основанным на наборах правил. Особенно во всяких экзотических случаях, характерных для тяжёлого канцелярита или высокого штиля.
А лучшие результаты дают комбинированные решения — правила плюс обучения на корпусах.
elingur
15.12.2016 09:35Спасибо, интересная вещь. А что со скоростью, можно ли на поток ставить?
mnv
15.12.2016 10:00В том виде, как я установил на виртуалку — скорость не высокая. В среднем текст, отправленный на парсинг, обрабатывается 7 секунд, 6.5 из которых загружается в память сам анализатор. Если тексты обрабатываются фоновыми процессами, то это приемлемая скорость, особенно если обработка разных текстов идет в нескольких параллельных процессах.
Скорость можно увеличить раз в 10, если настроить связку с Tensorflow Serving. Может быть еще есть способы.
INemo
16.12.2016 13:49+2Недавно сделал для Syntaxnet на русском докер-контейнер: inemo/syntaxnet_rus. С докером установка еще проще:
echo "мама мыла раму" | docker run --rm -i inemo/syntaxnet_rus
barkalov
Пользуясь случаем хотел спросить.
А есть ли что-то подобное (русский язык из коробки), но для Thrano/Keras?
mnv
А для других языков там есть реализации? Если есть пример как это делают для другого языка, то скорее всего удастся сделать по аналогии, обучив на нужном корпусе.