

Занимаясь программированием рендеринга графики, мы живём в мире, в котором обязательны низкоуровневые оптимизации, чтобы добиться GPU-фреймов длиной 30 мс. Для этого мы используем различные методики и разработанные с нуля новые проходы рендеринга с повышенной производительностью (атрибуты геометрии, текстурный кеш, экспорт и так далее), GPR-сжатие, скрывание задержки (latency hiding), ROP…
В сфере повышения производительности CPU в своё время применялись разные трюки, и примечательно то, что сегодня они используются для современных видеокарт ради ускорения вычислений ALU (Низкоуровневая оптимизация для AMD GCN, Быстрый обратный квадратный корень в Quake).
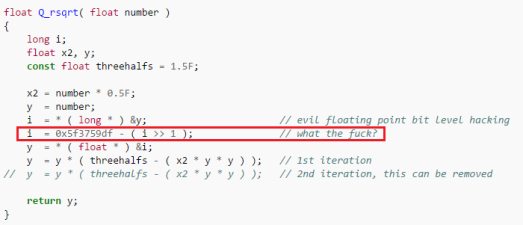
Быстрый обратный квадратный корень в Quake
Но в последнее время, особенно в свете перехода на 64 бита, я заметил рост количества неоптимизированного кода, словно в индустрии стремительно теряются все накопленные ранее знания. Да, старые трюки вроде быстрого обратного квадратного корня на современных процессорах контрпродуктивны. Но программисты не должны забывать о низкоуровневых оптимизациях и надеяться, что компиляторы решат все их проблемы. Не решат.
Эта статья — не исчерпывающее хардкорное руководство по железу. Это всего лишь введение, напоминание, свод базовых принципов написания эффективного кода для CPU. Я хочу «показать, что низкоуровневое мышление сегодня всё ещё полезно», даже если речь пойдёт о процессорах, которые я мог бы добавить.
В статье мы рассмотрим кеширование, векторное программирование, чтение и понимание ассемблерного кода, а также написание кода, удобного для компилятора.
Зачем вообще переживать?
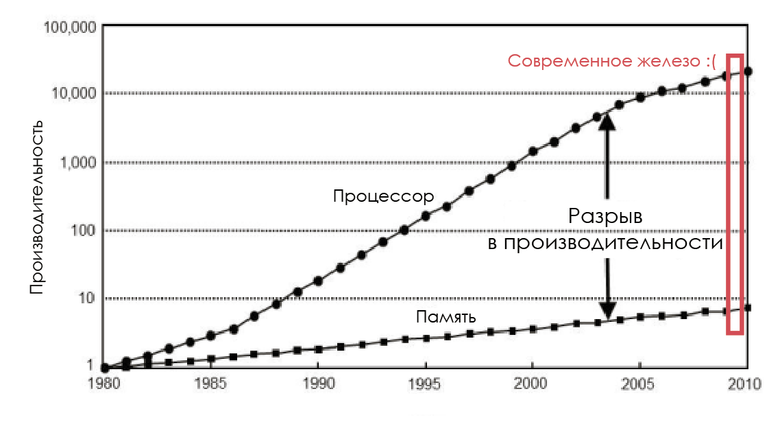
Не забывайте о разрыве
В 1980-е частота шины памяти равнялась частоте CPU, а задержка была почти нулевой. Но производительность процессоров логарифмически росла в соответствии с законом Мура, а производительность чипов ОЗУ увеличивалась непропорционально, так что вскоре память стала узким местом. И дело не в том, что нельзя создать более быструю память: можно, но невыгодно экономически.
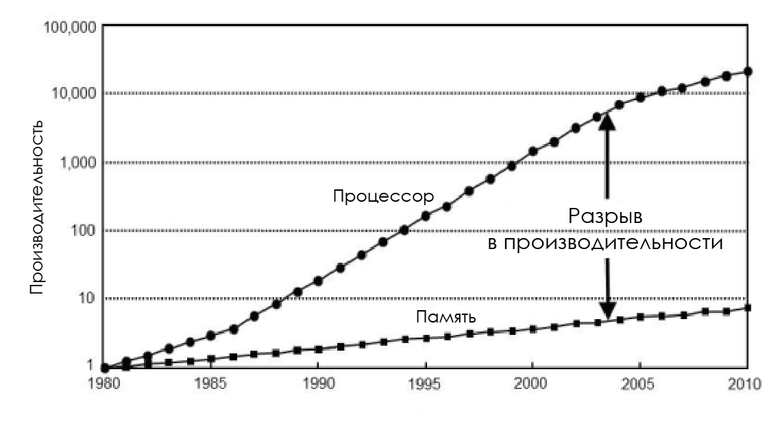
Изменение скорости процессоров и памяти
Чтобы снизить влияние производительности памяти, разработчики CPU добавили крохотное количество этой очень дорогой памяти между процессором и основной памятью — так появился кеш процессора.
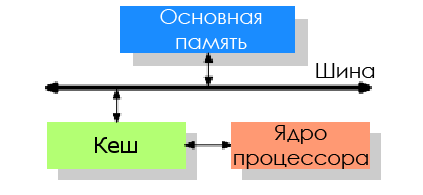
Идея такова: есть неплохая вероятность, что в течение короткого промежутка времени снова может потребоваться тот же код или данные.
- Пространственная локальность: циклы в коде, так что один и тот же код исполняется раз за разом.
- Временная локальность: даже если участки памяти, использовавшиеся в течение коротких промежутков времени, не находятся рядом друг с другом, то всё равно высока вероятность, что те же данные вскоре будут использованы вновь.
Кеш CPU — это сложная методика повышения производительности, но без помощи программиста она не будет работать корректно. К сожалению, многие разработчики не представляют себе стоимости использования памяти и структуры кеша CPU.
Архитектура, ориентированная на обработку данных
Нас интересуют игровые движки. Они обрабатывают всё увеличивающиеся объёмы данных, преобразуют их и выводят на экран в реальном времени. Учитывая это, а также необходимость решения проблем с эффективностью, программист обязан понимать, какие данные он обрабатывает, и знать оборудование, с которым будет работать его код. Следовательно, он должен осознавать необходимость внедрения архитектуры, ориентированной на данные (data oriented design, DoD).
А может, за меня это сделает компилятор?

Простое добавление. Слева — C++, справа — получившийся код на ассемблере
Давайте рассмотрим вышеприведённый пример применительно к процессору AMD Jaguar (похожему на те, что используются в игровых приставках) (полезные ссылки: AMD’s Jaguar Microarchitecture: Memory Hierarchy, AMD Athlon 5350 APU and AM1 Platform Review — Performance — System Memory):
- Операция загрузки (около 200 циклов без кеширования)
- Фактическая работа: inc eax (1 цикл)
- Операция хранения (~3 цикла, та же кеш-строка)
Даже в таком простом примере большая часть времени процессора тратится на ожидание данных, и в более сложных программах ситуация не становится лучше, пока программист не уделит внимание базовой архитектуре.
Если кратко, компиляторы:
- Не видят всю картину, им очень трудно спрогнозировать, как будут организованы данные и как к ним будут обращаться.
- Могут хорошо оптимизировать арифметические операции, но иногда эти операции — лишь вершина айсберга.
У компилятора довольно мало пространства для манёвра, когда речь идёт об оптимизации доступа к памяти. Контекст известен только программисту, и только он знает, какой код хочет написать. Поэтому вам необходимо понимать течение информационных потоков и в первую очередь исходить из обработки данных, чтобы выжать всё возможное из современных CPU.
Жестокая правда: ООП против DoD
Влияние схемы доступа к памяти на производительность (Mike Acton GDC15)
Объектно ориентированное программирование (ООП) сегодня — доминирующая парадигма, именно её в первую очередь изучают будущие программисты. Она заставляет мыслить в терминах объектов реального мира и их взаимоотношений.
В классе обычно инкапсулирован код и данные, поэтому объект содержит всю свою информацию. Заставляя применять массивы структур (array of structures) и массивы *указателей на* структуры/объекты, ООП нарушает принцип пространственной локальности, на котором базируется ускорение доступа к памяти с помощью кеша. Помните о разрыве между производительностью процессоров и памяти?
Чрезмерное инкапсулирование идёт во вред при работе на современном железе.
Я хочу сказать вам, что при разработке ПО нужно сместить акцент с самого кода на понимание преобразований данных, а также отреагировать на сложившуюся культуру программирования и положение вещей, навязанное сторонниками ООП.
В заключение хочу процитировать три больших лжи, сказанных Майком Эктоном (Mike Acton) (CppCon 2014: Mike Acton, «Data-Oriented Design and C++»)
Программное обеспечение — это платформа
- Нужно понимать железо, с которым вы работаете
Архитектура кода формируется по модели мира
- Архитектура кода должна соответствовать модели данных
Код важнее данных
- Память — узкое место, данные — однозначно самая важная вещь
Изучить железо
Кеш микропроцессора
Процессор физически не подключён напрямую к основной памяти. Все операции с оперативной памятью (загрузка и хранение) на современных процессорах выполняются через кеш.
Когда процессор занят командой вызова (загрузки), контроллер памяти сначала ищет в кеше запись с тегом, соответствующим адресу памяти, по которому ему нужно выполнить чтение. Если такая запись обнаруживается — то есть случается попадание в кеш, — то данные могут быть загружены напрямую из кеша. Если нет — промах кеша, — то контроллер попытается извлечь данные из более низких уровней кеша (например, сначала L1D, затем L2, затем L3) и, наконец, из оперативной памяти. Затем данные будут сохранены в L1, L2 и L3 (инклюзивный кеш).
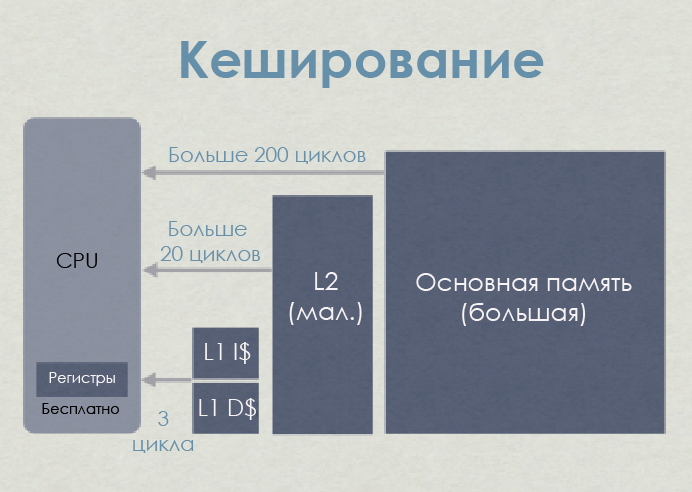
Задержка памяти на приставках — Jason Gregory
На этой упрощённой иллюстрации процессор (AMD Jaguar, используемый в PS4 и XB1) имеет два уровня кеша — L1 и L2. Как видите, кешируются не просто данные, L1 разделён на кеш кодовых инструкций (code instruction) (L1I) и кеш данных (L1D). Области памяти, необходимые для кода и данных, независимы друг от друга. В целом L1I создаёт куда меньше проблем, чем L1D.
С точки зрения задержки L1 на порядки быстрее, чем L2, который в 10 раз быстрее основной памяти. В числах выглядит грустно, но не за каждый промах кеша приходится платить полную цену. Можно снизить расходы с помощью сокрытия задержки (hiding latency), диспетчеризации и так далее, но это уже выходит за рамки поста.

Задержка обращения к памяти — Andreas Fredriksson
Каждая запись в кеше — кеш-строка — содержит несколько смежных слов (64 байта для AMD Jaguar или Core i7). Когда CPU исполняет инструкцию, извлекающую или сохраняющую значение, вся кеш-строка передаётся в L1D. В случае с сохранением та кеш-строка, в которую делается запись, помечается как грязная (dirty), пока не будет сделана запись обратно в оперативную память.
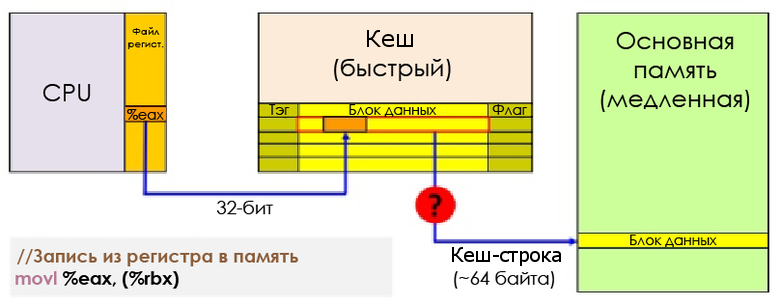
Запись из регистра в память
Чтобы иметь возможность загрузить в кеш новые данные, почти всегда необходимо сначала освободить место, выселив (evict) кеш-строку.
- Эксклюзивный кеш (Exclusive cache): при извлечении кеш-строка перемещается из L1D в L2. Это значит, что в L2 должно быть выделено место, что может привести к переносу данных снова в основную память. Перенос извлекаемой строки из L1D в L2 влияет на задержку при промахе кеша.
- Инклюзивный кеш (Inclusive cache): каждая кеш-строка в L1D представлена также и в L2. Извлечение из L1D происходит гораздо быстрее и не требует никаких дальнейших действий.
Свежие процессоры Intel и AMD используют инклюзивный кеш. Поначалу это может выглядеть ошибочным решением, но у него есть два преимущества:
- Он снижает задержку при промахе кеша, поскольку нет необходимости переносить кеш-строку на другой уровень при извлечении.
- Если одному ядру нужны данные, с которыми работает другое ядро, то оно может извлечь самую свежую версию из верхних уровней кеша, без прерывания работы другого ядра. Поэтому инклюзивный кеш стал очень популярен с развитием многоядерных архитектур.
Коллизии кеш-строки: хотя несколько ядер могут эффективно считывать кеш-строки, операции записи могут приводить к снижению производительности. Понятие «ложное разделение» (False sharing) означает, что разные ядра могут изменять независимые данные, находящиеся в одной кеш-строке. Согласно протоколам согласованности кеша (cache coherence protocols), если ядро пишет в кеш-строку, то строка в другом ядре, ссылающаяся на ту же память, признаётся недействительной (пробуксовка кеша, cache trashing). В результате при каждой операции записи возникают блокировки памяти. Ложного разделения можно избежать, сделав так, чтобы разные ядра работали с разными строками (использовав дополнительное пространство — extra padding, выровняв структуры по 64 байта и так далее).

Избегаем ложного разделения, в каждом треде записывая данные в разные кеш-строки
Как видите, понимание аппаратной архитектуры — это ключ к обнаружению и исправлению проблем, которые в противном случае могут остаться незамеченными.
Coreinfo — утилита, работающая из командной строки. Она предоставляет подробную информацию обо всех наборах инструкций, находящихся в процессоре, а также сообщает, какие кеши приписаны к каждому логическому процессору. Вот пример для Core i5-3570K:
*--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*--- Unified Cache 0, Level 2, 256 KB, Assoc 8, LineSize 64
**** Unified Cache 1, Level 3, 6 MB, Assoc 12, LineSize 64
-*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*-- Unified Cache 2, Level 2, 256 KB, Assoc 8, LineSize 64
--*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
--*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
--*- Unified Cache 3, Level 2, 256 KB, Assoc 8, LineSize 64
---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
---* Unified Cache 4, Level 2, 256 KB, Assoc 8, LineSize 64Здесь кеш L1 на 32 Кб, кеш инструкций L1 на 32 Кб, кеш L2 на 256 Кб, и кеш L3 на 6 Мб. В этой архитектуре L1 и L2 приписаны к каждому ядру, а L3 используется совместно всеми ядрами.
В случае с AMD Jaguar CPU каждое ядро имеет выделенный кеш L1, а L2 используется совместно группами по 4 ядра — кластерами (в Jaguar нет L3).
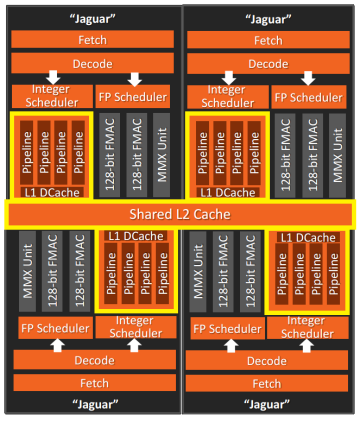
4-ядерный кластер (AMD Jaguar)
Работая с такими кластерами, следует проявлять особую осторожность. Когда ядро делает запись в кеш-строку, она может стать недействительной в других ядрах, что снижает производительность. Причём при такой архитектуре всё может стать ещё хуже: извлечение ядром данных из ближайшего L2, расположенного в том же кластере, занимает около 26 циклов, а извлечение из L2 другого кластера может занять до 190 циклов. Сопоставимо с извлечением данных из оперативной памяти!
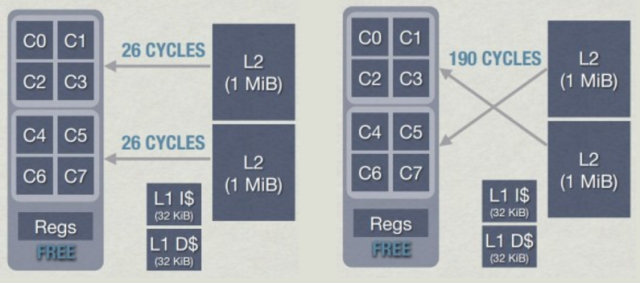
Задержка L2 в кластерах в AMD Jaguar — Jason Gregory
За дополнительной информацией о согласованности кеша обратитесь к статье Cache Coherency Primer.
Основы ассемблера
x86-64 бит, x64, IA-64, AMD64… или рождение архитектуры x64
Intel и AMD разработали свои собственные 64-битные архитектуры: AMD64 и IA-64. IA-64 разительно отличается от процессоров x86-32 бит в том смысле, что ничего не унаследовала от архитектуры x86. Приложения под x86 должны работать на IA-64 через уровень эмуляции, следовательно, у них на этой архитектуре низкая производительность. Из-за нехватки совместимости с x86 IA-64 так и не взлетела, если не считать коммерческой сферы. С другой стороны, AMD создала более консервативную архитектуру, расширив имевшуюся свою x86 новым набором 64-битных инструкций. Intel, проигравшая 64-битную войну, была вынуждена внедрить те же расширения в свои x86-процессоры. В этой части мы рассмотрим x86-64 бит, также известную как архитектура x64, или AMD64.
В течение многих лет PC-программисты использовали x86-ассемблер для написания высокопроизводительного кода: mode’X', CPU-Skinning, коллизии, программные растеризаторы (software rasterizers)… Но 32-битные компьютеры медленно заменялись 64-битными, и ассемблерный код тоже изменился.
Знать ассемблер необходимо, если вы хотите понимать, почему одни вещи работают медленно, а другие быстро. Также это поможет понять, как использовать intrinsic-функции для оптимизирования критических частей кода, и как отлаживать оптимизированный (например, -О3) код, когда отладка на уровне исходного кода уже не имеет смысла.
Регистры
Регистры — это маленькие фрагменты очень быстрой памяти с почти нулевой задержкой (обычно один процессорный цикл). Они используются в качестве внутренней памяти процессора. В них хранятся данные, напрямую обрабатываемые процессорными инструкциями.
x64-процессор имеет 16 регистров общего назначения (general-purpose register, GPR). Они не используются для хранения конкретных типов данных, во время исполнения в них находятся операнды и адреса.
В x64 восемь x86-регистров расширены до 64 бит, а также добавлено 8 новых 64-битных регистра. Имена 64-битных регистров начинаются с r. Например, 64-битное расширение eax (32-битного) называется rax. Новые регистры проименованы с r8 по r15.

Общая архитектура (software.intel.com)
В число регистров x64 входят:
- 16 64-битных регистров общего назначения (GPR), из них первые восемь называются rax, rbx, rcx, rdx, rbp, rsi, rdi и rsp. Вторые восемь: r8—r15.
- 8 64-битных MMX-регистров (набор MMX-инструкций), покрывающий регистры с плавающей запятой fpr (x87 FPU).
- 16 128-битных векторных XMM-регистров (набор SSE-инструкций).
В более новых процессорах:
- 256-битные YMM-регистры (набор AVX-инструкций), расширяющие XMM-регистры.
- 512-битные ZMM-регистры (набор AVX-512 инструкций), расширяющие XMM-регистры и увеличивающие их количество до 32.

Взаимосвязи между ZMM-, YMM- и XMM-регистрами
По историческим причинам несколько GPR называются иначе. Например, ax был регистром Accumulator, cx — Counter, dx — Data. Сегодня большинство из них потеряли своё специфическое предназначение, за исключением rsp (Stack Pointer) и rbp (Base Pointer), которые зарезервированы для управления аппаратным стеком (hardware stack) (хотя rbp часто может быть «оптимизирован» и использоваться как GRP — omit frame pointer в Clang).
К младшим битам x86-регистров можно обращаться с помощью субрегистров. В случае с первыми восемью x86-регистрами используются легаси-названия. Более новые регистры (r8—r15) используют такой же, только упрощённый подход:
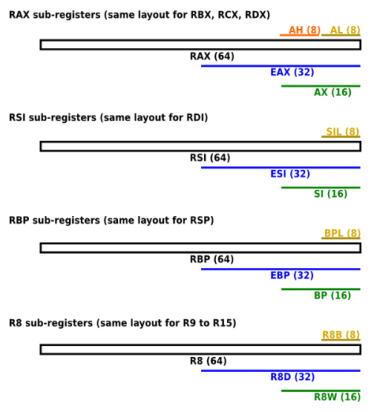
Поименованные скалярные регистры
Адресация
Когда ассемблерным инструкциям требуется два операнда, то обычно первый — пункт назначения (destination), а второй — источник. Каждый из них содержит данные, которые надо обработать, или адрес данных. Есть три основных режима адресации:
- Немедленная
- mov eax, 4; перемещает 4 в eax
- Из регистра в регистр
- mov eax, ecx; перемещает содержимое ecx в eax
- Косвенная:
- mov eax, [ebx]; перемещает 4 байта (размер eax) по адресу ebx в eax
- mov byte ptr [rcx], 5; перемещает 5 в byte по адресу rcx
- mov rdx, dword ptr [rcx+4*rax]; перемещает dword по адресу rcx+4*rax в rdx
dword ptr называется директивой размера (size directive). Она говорит ассемблеру, какой размер следует брать, если существует неопределённость по размеру области памяти, на которую ссылаются (например: mov [rcx], 5: должен записать байт? dword?).
Это может означать: байт (8-бит), word (16-бит), dword (32-бит), qword (64-бит), xmmword (128-бит), ymmword (256-бит), zmmword (512-бит).
Наборы SIMD-инструкций
Скалярная реализация обозначает операции с одной парой операндов за раз. Векторизация — это процесс преобразования алгоритма, когда вместо работы с одиночными порциями данных за раз он начинает обрабатывать по несколько порций за раз (ниже мы посмотрим, как он это делает).
Современные процессоры могут использовать преимущества набора SIMD-инструкций (векторные инструкции) для параллельной обработки данных.
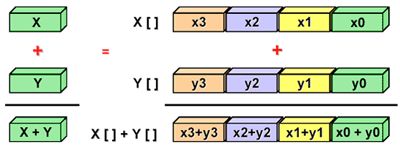
SIMD-обработка
Наборы SIMD-инструкций, которые доступны в x86-процессорах:
- Multimedia eXtension (MMX)
- Легаси. Поддерживает арифметические операции над целочисленными значениями, упакованными в 64-битные векторные регистры.
- Streaming SIMD Extensions (SSE)
- Арифметические операции над числами с плавающей запятой, упакованными в 128-битные векторные регистры. В SSE2 была добавлена поддержка целочисленных и значений с двойной точностью.
- Advanced Vector Extensions (AVX) — только x64
- Добавлена поддержка 256-битных векторных регистров.
- AVX-512 — только x64
- Добавлена поддержка 512-битных векторных регистров.
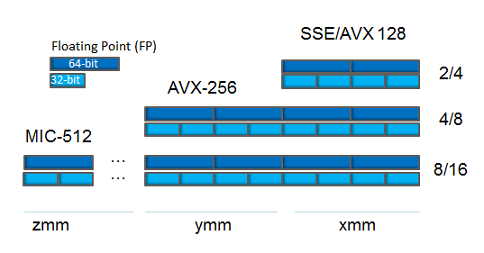
Векторные регистры в x64-процессорах
Игровые движки обычно тратят 90 % времени исполнения на запуск маленьких порций кодовой базы, в основном итерируя и обрабатывая данные. В подобных сценариях SIMD может иметь большое значение. SSE-инструкции обычно применяют для параллельной обработки наборов из четырёх значений с плавающей запятой, упакованных в 128-битные векторные регистры.
SSE в основном ориентировано на вертикальное представление (структура массивов — Structure of Arrays, SoA) данных и их обработку. Но вообще-то производительность SoA по сравнению с Array of Structures (AoS) зависит от шаблонов доступа к памяти.
- AoS, вероятно, самый естественный вариант, простой в написании. Удовлетворяет парадигме ООП.
- У AoS лучше локальность данных, если выполняется доступ ко всем членам вместе.
- SoA предлагает больше возможностей по векторизации (вертикальная обработка).
- SoA зачастую использует меньше памяти благодаря применению паддинга только между массивами.
// Array Of Structures
struct Sphere
{
float x;
float y;
float z;
double r;
};
Sphere* AoS;
Размещение в памяти (структура выравнена по 8 байтов):
------------------------------------------------------------------
| x | y | z | r | pad | x | y | z | r | pad | x | y | z | r | pad
------------------------------------------------------------------
// Structure Of Arrays
struct SoA
{
float* x;
float* y;
float* z;
double* r;
size_t size;
};
Размещение в памяти:
------------------------------------------------------------------
| x | x | x ..| pad | y | y | y ..| pad | z | z | z ..| pad | r..
------------------------------------------------------------------
AVX — это естественное расширение SSE. Размер векторных регистров увеличивается до 256 битов, это означает, что до 8 чисел с плавающей запятой могут быть упакованы и параллельно обработаны. Процессоры Intel изначально поддерживают 256-битные регистры, а с AMD могут быть проблемы. Ранние AVX-процессоры AMD, такие как Bulldozer и Jaguar, раскладывают 256-битные операции на пары 128-битных, что увеличивает задержку по сравнению с SSE.
В заключение скажу, что не так-то просто ориентироваться исключительно на AVX (может быть, для внутренних инструментов, если ваши компьютеры работают на Intel), а AMD-процессоры по большей части не поддерживают их нативно. С другой стороны, на любых x64-процессорах можно априори рассчитывать на SSE2 (это часть спецификации).
Внеочередное исполнение
Если конвейер (pipeline) процессора работает в режиме внеочередного исполнения (Out-of-Order, OoO), то исполнение инструкций может задерживаться из-за неготовности необходимых входных данных. В этом случае процессор пытается найти более поздние инструкции, чьи входные данные уже готовы, чтобы выполнить сначала вне очереди.
Цикл выполнения команды (instruction cycle) (или цикл «получение — декодирование — исполнение») — это процесс, в ходе которого процессор получает инструкцию из памяти, определяет, что с ней нужно делать, и исполняет её. Цикл выполнения команды в режиме внеочередного исполнения выглядит так:
- Получение/декодирование: инструкция извлекается из L1I (кеш инструкций). Затем она преобразуется в более мелкие операции, называющиеся микрооперациями, или µops.
- Переименование: из-за существующих зависимостей между регистром и данными может возникнуть блокировка исполнения. Для решения этой проблемы и устранения ложных зависимостей процессор предоставляет набор безымянных внутренних регистров, использующихся для актуальных вычислений. Переименование регистра — это процесс преобразования ссылок на архитектурные регистры (логические) в ссылки на безымянные регистры (физические).
- Буфер переупорядочивания (Reorder Buffer): он содержит ожидающие исполнения микрооперации, хранящиеся в порядке поступления, а также уже выполненные, но ещё не выбывшие (retired).
- Диспетчеризация: микрооперации, хранящиеся в буфере переупорядочивания, могут быть в любом порядке переданы в модули параллельного исполнения, с учётом зависимостей и доступности данных. Результат микрооперации записывается обратно в буфер переупорядочивания вместе с самой микрооперацией.
- Увольнение: модуль выбывания (retirement unit) постоянно проверяет статус микроопераций в буфере, записывает результаты исполненных микроопераций обратно в архитектурные регистры (доступные пользователю), а затем убирает микрооперации из буфера.
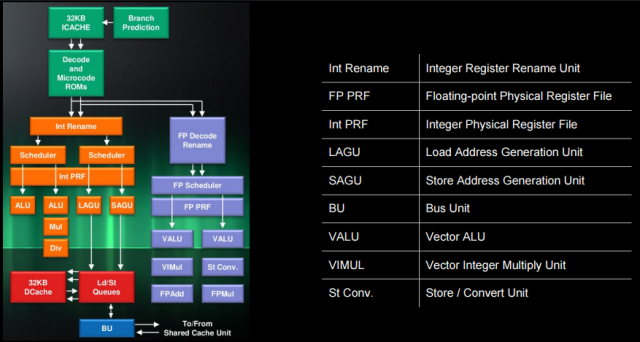
Архитектура процессора AMD Jaguar
В архитектуре процессора AMD Jaguar мы можем обнаружить все вышеупомянутые блоки. Для целочисленного конвейера:
- «Decode and Microcode ROMs»
- = модуль получения/декодирования
- «Int Rename» and «Int PRF» (физический регистровый файл)
- = модуль переименования
- Модуль управления выбыванием (Retire Control Unit, RCU), здесь не показанный, управляет переименованием регистров и выбыванием микроопераций.
- Диспетчеры
- Внутренний диспетчер (Int Scheduler, ALU)
- Может передавать по одной микрооперации на конвейер (два ALU-модуля исполнения I0 и I1) во внеочередном порядке.
- AGU-диспетчер (загрузка/хранение)
- Может передавать по одной микрооперации на конвейер (два AGU-модуля исполнения LAGU b SAGU) во внеочередном порядке.
- Внутренний диспетчер (Int Scheduler, ALU)
Примеры микроопераций:
Инструкция µops
add reg, reg 1: add
add reg, [mem] 2: load, add
addpd xmm, xmm 1: addpd
addpd xmm, [mem] 2: load, addpdГлядя на раздел про AMD Jaguar в замечательной таблице инструкций на сайте Agner, мы можем понять, как выглядит конвейер исполнения для этого кода:
Пример кода
mov eax, [mem1] ; 1 - load
imul eax, 5 ; 2 - mul
add eax, [mem2] ; 3 - load, add
mov [mem3], eax ; 4 - store
Конвейер исполнения (Jaguar)
I0 | I1 | LAGU | SAGU | FP0 | FP1
| | 1-load | | |
2-mul | | 3-load | | |
| 3-add | | | |
| | | 4-store | |Здесь инструкции прерывания (breaking instructions) в микрооперациях позволяют процессору использовать преимущества модулей параллельного исполнения, частично или целиком «пряча» задержку при выполнении инструкции (
3-load и 2-mul выполняются параллельно, в двух разных модулях). Но такое не всегда возможно. Цепочка зависимостей между
2-mul, 3-add и 4-store не даёт процессору переорганизовать эти микрооперации (4-store нужен результат 3-add, а 3-add нужен результат 2-mul). Так что для эффективного использования модулей параллельного исполнения избегайте длинных цепочек зависимостей.Опции Visual Studio
Чтобы проиллюстрировать генерируемый компилятором ассемблер, я воспользуюсь msvc++ 14.0 (VS2015) и Clang. Сильно рекомендую вам делать то же самое и привыкать сравнивать разные компиляторы. Это поможет лучше понимать, как взаимодействуют друг с другом все компоненты системы, и составлять своё мнение о качестве генерируемого кода.
Несколько полезностей:
- Опция Show Symbol Names может показать имена локальных переменных и функций в дизассемблированном виде, вместо адресов инструкций или стековых адресов.
- Сделайте ассемблер более читабельным:
- Project settings > C/C++ > Code Generation > Basic Runtime Checks, измените значение на Default.
- Записывайте результат в .asm-файл:
- Project settings > C/C++ > Output Files > Assembler Output, сделайте значение Assembly With Source Code.
- Опускание указателя фрейма (Frame-Pointer omission) говорит компилятору о том, что не надо использовать ebp для управления стеком:
- /Oy (только x86, в Clang: -fomit-frame-pointer, работает в x64)
Базовые примеры дизассемблирования
Здесь мы рассмотрим очень простые примеры кода на C++ и их дизассемблирование. Весь код на ассемблере переорганизован и полностью задокументирован, чтобы новичкам было легче, но я рекомендую проверить, нет ли у вас сомнений относительно того, что делают инструкции.
Для простоты восприятия прологи и эпилоги функций удалены, здесь мы не будем их обсуждать.
Примечание: локальные переменные объявлены в стеке. Например, mov dword ptr [rbp + 4], 0Ah; int b = 10 означает, что локальная переменная ‘b’ помещена в стек (на неё ссылается rbp) по относительному адресу (offset) 4 и инициализирована как 0Ah, или 10 в десятичном выражении.
Арифметические операции с плавающей запятой с простой точностью
Арифметические операции с плавающей запятой можно выполнять с помощью x87 FPU (80-битная точность, скалярная) или SSE (32- или 64-битная точность, векторизованная). В x64 всегда поддерживается набор SSE2-инструкций, и по умолчанию это используется для арифметических операций с плавающей запятой.
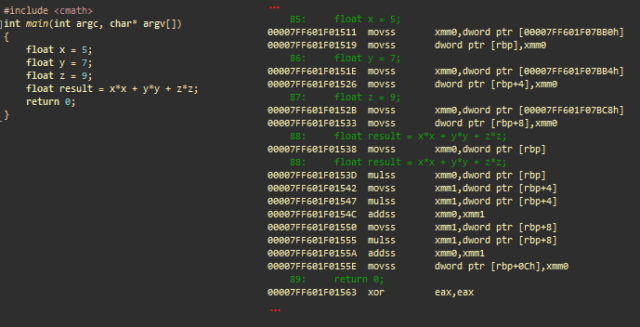
Простая арифметическая операция с плавающей запятой с использованием SSE. msvc++
Инициализации
- movss xmm0, dword ptr [adr]; загружает значение с плавающей запятой, расположенной по адресу adr в xmm0
- movss dword ptr [rbp], xmm0; сохраняет его в стек (float x)
- …; то же самое с y и z
Вычисляет x*x
- movss xmm0, dword ptr [rbp]; загружает скалярное x в xmm0
- mulss xmm0, dword ptr [rbp]; умножает xmm0 (=x) на x
Вычисляет y*y и складывает с x*x
- movss xmm1, dword ptr [rbp+4]; загружает скалярное y в xmm1
- mulss xmm1, dword ptr [rbp+4]; умножает xmm1 (=y) на y
- addss xmm0, xmm1; складывает xmm1 (y*y) с xmm0 (x*x)
Вычисляет z*z и складывает с x*x + y*y
- movss xmm1, dword ptr [rbp+8]; загружает скалярное z в xmm1
- mulss xmm1, dword ptr [rbp+8]; умножает xmm1 (=z) на z
- addss xmm0, xmm1; складывает xmm1 (z*z) с xmm0 (x*x + y*y)
Сохраняет финальный результат
- movss dword ptr [rbp+0Ch], xmm0; сохраняет xmm0 в результат
- xor eax, eax; eax = 0. eax содержит возвращаемое значение main()
В этом примере XMM-регистры использованы для хранения одиночного значения с плавающей запятой. SSE позволяет работать как с одиночными, так и с множественными значениями, с разными типами данных. Посмотрите на SSE-инструкцию сложения:
- addss xmm0, xmm1; каждый регистр как 1 скалярное значение с плавающей запятой с одиночной точностью (scalar single precision floating-point value)
- addps xmm0, xmm1; каждый регистр как 4 упакованных значения с плавающей запятой с одиночной точностью (packed single precision floating-point values)
- addsd xmm0, xmm1; каждый регистр как 1 скалярное значение с плавающей запятой с двойной точностью (scalar double precision floating-point value)
- addpd xmm0, xmm1; каждый регистр как 2 упакованных значения с плавающей запятой с двойной точностью (packed double precision floating-point values)
- paddd xmm0, xmm1; каждый регистр как 4 упакованных dword-значения (packed double word (32-битных целочисленных) values)
Ветвление
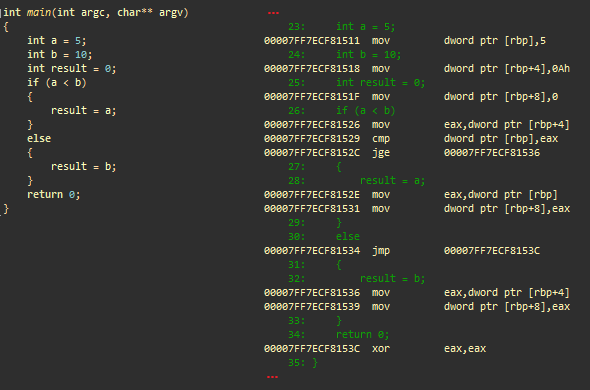
Пример ветвления. msvc++
Инициализации
- mov dword ptr [rbp], 5; сохраняет 5 в стек (целочисленное a)
- mov dword ptr [rbp+4], 0Ah; сохраняет 10 в стек (целочисленное b)
- mov dword ptr [rbp+8], 0; сохраняет 0 в стек (целочисленный результат)
Условие
- mov eax, dword ptr [rbp+4]; загружает b в eax
- cmp dword ptr [rbp], eax; сравнивает a с eax (b)
- jge @ECF81536; делает переход, если a больше или равно b
‘then’ result = a
- mov eax, dword ptr [rbp]; загружает a в eax
- mov dword ptr [rbp+8], eax; сохраняет eax в стек (результат)
- jmp @ECF8153C; переходит к ECF8153C
‘else’ result = b
- (ECF81536) mov eax, dword ptr [rbp+4]; загружает b в eax
- mov dword ptr [rbp+8], eax; сохраняет eax в стек (результат)
- (ECF8153C) xor eax, eax; eax = 0. eax содержит возвращаемое значение main()
Инструкция cmp сравнивает операнд первого источника со вторым, в соответствии с результатом устанавливает флаги статусов в регистре RFLAGS. Регистр ®FLAGS — это регистр статуса x86-процессоров, содержащий текущее состояние процессора. Инструкция cmp обычно используется в сочетании с условным переходом (например, jge). Используемые переходами коды условий зависят от результата инструкции cmp (коды условий RFLAGS).
Арифметические операции с целочисленными и цикл ‘for’
В ассемблере циклы представлены в основном как серия условных переходов (=if… goto).
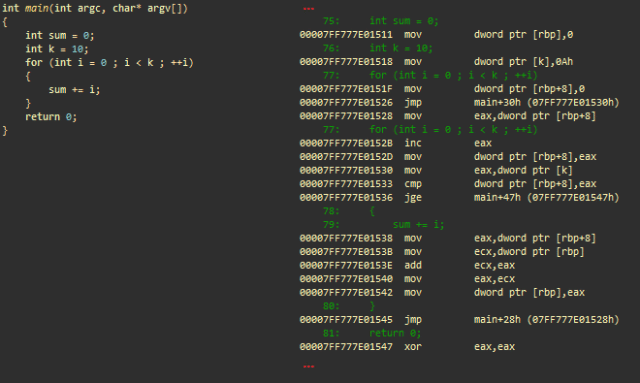
Арифметические операции с целочисленными и цикл ‘for’. msvc++
Инициализации
- mov dword ptr [rbp], 0; сохраняет 0 в стек (целочисленная сумма)
- mov dword ptr [k], 0Ah; сохраняет 10 в стек (целочисленное k)
- mov dword ptr [rbp+8], 0; сохраняет 0 в стек (целочисленное i) для итерирования в цикле
- jmp main+30h; переходит к main+30h
Часть кода, ответственная за инкрементирование i
- (main+28h) mov eax, dword ptr [rbp+8]; загружает i в eax
- inc eax; инкрементирует
- mov dword ptr [rbp+8], eax; сохраняет обратно в стек
Часть кода, ответственная за тестирование условия выхода (i >= k)
- (main+30h) mov eax, dword ptr [k]; загружает k из стека в eax
- cmp dword ptr [rbp+8], eax; сравнивает i с eax (= k)
- jge main+47h; совершает переход (завершает цикл), если i больше или равно k
«Реальная работа»: sum+=i
- mov eax, dword ptr [rbp+8]; загружает i в eax
- mov ecx, dword ptr [rbp]; загружает сумму в ecx
- add ecx, eax; складывает eax с ecx (ecx = сумма + i)
- mov eax, ecx; переносит ecx в eax
- mov dword ptr [rbp], eax; сохраняет eax (сумма) обратно в стек
- jmp main+28h; совершает переход и обрабатывает следующую итерацию цикла
- (main+47h) xor eax, eax; eax = 0. eax содержит возвращаемое значение main()
Встроенные функции (intrinsics) SSE
Ниже приведён типичный пример вертикальной обработки, при которой SSE позволяет программисту параллельно выполнить четыре одинаковые операции (в нашем случае — скалярное произведение). Мы увидим, как встроенные функции легко сопоставляются с их ассемблерными эквивалентами:
- _mm_mul_ps соответствует mulps
- _mm_load_ps соответствует movaps
- _mm_add_ps соответствует addps
- _mm_store_ps соответствует movaps
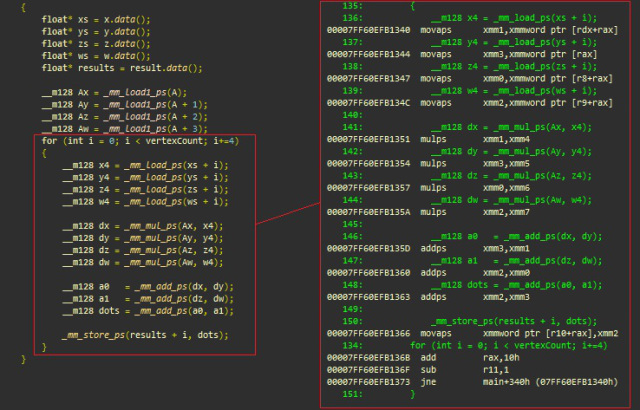
Встроенные функции SSE, msvc++
Инициализации (xmmword имеет ширину 128 бит и эквивалентен четырём dword)
- (main+340h) movaps xmm1, xmmword ptr [rdx+rax]; загружает 128-битный xmmword (четыре значения с плавающей запятой) по адресу xs+i в xmm1
- movaps xmm3, xmmword ptr [rax]; загружает 4 значения с плавающей запятой по адресу ys+i в xmm3
- movaps xmm0, xmmword ptr [r8+rax]; загружает 4 значения с плавающей запятой по адресу zs+i в xmm0
- movaps xmm2, xmmword ptr [r9+rax]; загружает 4 значения с плавающей запятой по адресу ws+i в xmm2
Вычисляет dot(v[i], A) = xi * Ax + yi * Ay + zi * Az + wi * Aw, четыре вершины (vertices) за раз:
- mulps xmm1, xmm4; xmm1 *= xmm4 xn.Ax, n [0..3]
- mulps xmm3, xmm5; xmm3 *= xmm5 yn.Ay, n [0..3]
- mulps xmm0, xmm6; xmm0 *= xmm6 zn.Az, n [0..3]
- mulps xmm2, xmm7; xmm2 *= xmm7 wn.Aw, n [0..3]
- addps xmm3, xmm1; xmm3 += xmm1 xn.Ax + yn.Ay
- addps xmm2, xmm0; xmm2 += xmm0 zn.Az + wn.Aw
- addps xmm2, xmm3; xmm2 += xmm3 xn.Ax + yn.Ay + zn.Az + wn.Aw
Сохраняет результаты по адресу памяти (результаты + сдвиг) и идёт по циклу
- movaps xmmword ptr [r10 + rax], xmm2; сохраняет 128-битный xmmword (4 значения с плавающей запятой) по адресу, на который ссылается r10+rax
- add rax, 10h; складывает 16 с rax (текущий сдвиг = размер 4 значений с плавающей запятой)
- sub r11,1; r11–, оставшиеся итерации цикла
- jne main+34h; выполняет переход и обрабатывает следующую итерацию цикла
Можно очень просто портировать этот код в AVX (256-бит, или 8 значений с плавающей запятой с одиночной точностью):
_m256 Ax = _mm256_broadcast_ss(A);
...
for (int i = 0; i < vertexCount; i+=8) // 8 значений с плавающей запятой (256-бит)
{
__m256 x4 = _mm256_load_ps(xs + i);
..
__m256 dx = _mm256_mul_ps(Ax, x4);
..
__m256 a0 = _mm256_add_ps(dx, dy);
..
_mm256_store_ps(results + i, dots);
}Оператор множественного выбора (switch)
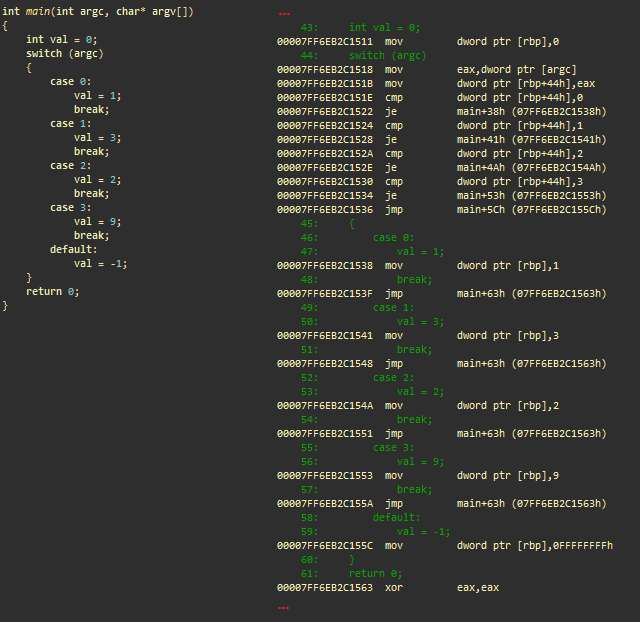
Оператор ветвления. msvc++
Инициализации
- mov dword ptr [rbp], 0; сохраняет 0 в стек (целочисленное значение)
- mov eax, dword ptr [argc]; загружает argc в eax
- mov dword ptr [rbp+44h], eax; сохраняет его в стек
Условия
- cmp dword ptr [rbp+44h], 0; сравнивает argc to 0
- je main+38h; if argc == 0, переходит к main+38h (case 0)
- cmp dword ptr [rbp+44h], 1; сравнивает argc с 1
- je main+41h; if argc == 1, переходит к main+41h (case 1)
- cmp dword ptr [rbp+44h], 2; сравнивает argc с 0
- je main+4Ah; if argc == 2, переходит к main+4Ah (case 2)
- cmp dword ptr [rbp+44h], 3; сравнивает argc с 3
- je main+53h; if argc == 3, переходит к main+53h (case 3)
- jmp main+5Ch; переходит к main+5Ch (по умолчанию)
Case 0
- (main+38h) mov dword ptr [rbp], 1; сохраняет 1 в стек (val)
- jmp main+63h; переходит к main+63h, выходит из оператора ветвления
Case 1
- (main+41h) mov dword ptr [rbp], 3; сохраняет 3 в стек (val)
- jmp main+63h; переходит к main+63h, выходит из оператора ветвления
…
- (main+63h) xor eax, eax; eax = 0. eax содержит возвращаемое значение main()
Этот ассемблерный код сгенерирован на основе серии ветвлений. Если в С++-коде мы заменим оператор ветвления серией if-else, то результат будет очень похожим. В ряде случаев и в зависимости от компилятора ветви могут быть оптимизированы в таблицу поиска адресов переходов.
Полезные ссылки
- What Every Programmer Should Know About Memory
- Intel Instrinsics Guide
- Jaguar Out-of-Order Scheduling
- The Intel Architecture Processors Pipeline
- x86-64bit Opcode and Instruction Reference
- Why do CPUs have multiple cache levels?

Комментарии (96)

lieff
11.01.2017 17:19+3Вот еще хороший сайтик godbolt.org, где можно посмотреть как различные компилеры код оптимизируют.

perfect_genius
11.01.2017 17:35-1разработчики CPU добавили крохотное количество этой очень дорогой памяти между процессором и основной памятью
Интересно, что же там дорогое? Какие-то особые материалы?lorc
11.01.2017 18:17+7Просто в DRAM на один бит нужен один транзистор и один конденсатор. В кешах же используется SRAM, которому надо 6 транзисторов на хранение одного бита. Это одна проблема. Если посмотреть на схему любого современного процессора, то можно увидеть что немалую площадь кристала занимают именно кеши.
Вторая проблема — это то что кеш стоит прямо на кристалле, а модули памяти удалены от процессора на значительное расстояние. Это тоже влияет на тайминги.
Интересный факт: если мы поделим скорость света на 3Ггц, то получим 10 сантиметров. Такое расстояние пройдет свет за один период. В вакууме. Значит, если наша идеальная память будет стоять на расстоянии 10 см от процессора (учитывая длину трасс), то нам в любом случае понадобится минимум два лишних цикла на доступ к памяти.
Gumanoid
11.01.2017 21:28+2И ещё проблема, которая не даёт сделать кэш больше — ограничения управляющей схемы. Ведь кэш должен в каждом вэе взять линии по индексу, сравнить у них тэги, дать считать результат процессору, и всё это за 3 такта.

PsyHaSTe
11.01.2017 21:29Тут на помощь приходят конвеерные техники. При достаточном уровне параллелизации доступа в память задержка будет намного ниже.

Alex_T666
11.01.2017 17:37+2Замечательно, что кто-то до сих пор всерьез задумывается об оптимизации! А то в последнее время никак не покидает ощущение что та или иная игра вполне могла бы пойти на видеокарте и пятилетней давности, если б над игрой хорошенько поработали бы.

nikespawn
11.01.2017 17:59-2А как же хорошо идущий даже на старом железе Doom 3?
lorc
11.01.2017 18:20Doom 3 вышел в 2004 году. Это было 13 лет назад. И да, Кармак всегда много внимания уделял оптимизации. К сожалению, таких как он не очень много.

Lailore
12.01.2017 03:31+2Ага, только из-за этой оптимизации дум по сути провалился. Его обогнали все кому не лень. А без такой оптимизации это был прорыв который обогнал все и вся и на много.

AxisPod
12.01.2017 08:21-2Ну и кто его обогнал? FarCry? (ландшафты большие, деревья, но по кол-ву полигонов в закрытых пространствах и освещению как-то не очень), Riddik? (ну в плане графики близко, но много косяков со светом), Half-Life 2? (Ну тут фанатики меня заплюют и закидают помидорами, но тут даже сравнивать нечего, он в принципе никак не дотягивает). Но и опять же по оптимизации, Half-Life 2 и FarCry на средних настройках у меня выдавали на железяке порядка 40+ FPS, Doom 3 на минималках же выдавал аж целых 13, если упереться в стенку. Если оптимизировали, чтобы тормозило сильнее, то возможно. Имеем графику мощную но и соответственно более высокие требования перед конкурентами тех времен.

Leopotam
12.01.2017 10:27+1Если убрать нормалмапы — весь дум3 резко станет плоским и с максимально простой геометрией — там все держится исключительно на нормалмапах / спеке. Это по поводу остальных игр и «по количеству полигонов не очень». HL2 в этом плане — гораздо более продуманная вещь в плане градации «качества» рендера — можно отключить нормамапы, преломления, можно зарезать качество текстур — и это все-рано будет hl2 визуально и с деталями, сделанными геометрией, в отличие от дума3. По поводу «из-за этой оптимизации дум по сути провалился. Его обогнали все кому не лень.» — как раз из-за того, что упор был сделан на большое количество текстур — часть видеокарт просто затыкалась по объему видеопамяти / филрейту.
ElectroGuard
11.01.2017 18:12-4Так как сейчас большинство кода пишется на различных прослойках — жава, донет, либо браузеры, то статью можно не читать, так как там это всё, увы, просто неприменимо.
Leopotam
11.01.2017 18:34+2Переход с ООП на DoD дает значительный прирост производительности, иногда даже на порядок. И даже на «жаве-дотнете».
RomanArzumanyan
11.01.2017 18:25-4ООП нарушает принцип пространственной локальности
Эх, понеслось… Ну вот какое отношение парадигма программирования имеет к расположению данных в памяти? Инкапсуляция? Наследование? Полиморфизм? Обмен сообщениями? Позднее связывание? Дайте определение пространственной локальности для начала, а?Leopotam
11.01.2017 18:36+3Если положить данные всех инстансов линейно (а не кусочками в каждом инстансе) и прокатить обработчиком без вызова метода каждого инстанса — будет значительный прирост: отсутствие издержек на вызов метода (в том числе виртуального), высокая вероятность попадания в кеш при последовательной вычитке.
RomanArzumanyan
11.01.2017 18:44Ничто не мешает хранить ваши данные как вам угодно (класс картинка с массивом пикселей вместо массива класса пикселей). Это классический принцип SoA vs AoS (Structure of Arrays vs Array of Structures). Вообще необязательно писать на ОО языке программирования, чтобы столкнуться с такой проблемой.
ООП есть некий подход к программированию в целом. Это слишком удалено от конкретных реализаций.Leopotam
11.01.2017 18:49Еще раз прочитайте, что я написал — на большом количестве итераций и большой вложенности методов это все дает хорошее пенальти. Если убрать вызовы ОО-методов из инстансов и прогонять данные локально внутри одного метода — можно получить очень солидный прирост производительности. Но лучше по поводу перераспределения данных в памяти и переделывания ООП в DoD почитать ссылку, которую давали ниже.
RomanArzumanyan
11.01.2017 18:59CUDA поддерживает ООП, например. И всё там прекрасно с обработкой данных и схемами обращения к памяти. В OpenCL есть векторные операции, которые тоже представляют собой разновидность ООП, и там всё ок. Всё это зависит от компилятора, не более того.
Leopotam
11.01.2017 19:03Проблема в том, что компиляторы для GPU на голову выше компиляторов для CPU — сейчас генерится настолько плотный и качественный код, что весьма проблематично переписать руками так, чтобы оно было быстрее. Т.е. там несколько прослоек-трансляторов-компиляторов, каждый делает свою работу хорошо, особенно конечные драйвера. Ну и когда пишешь под конвейерную обработку данных — код пишешь в определенном стиле, как и готовишь данные для него. Это не multipurpose-ООП, к которому привыкло большинство.
RomanArzumanyan
11.01.2017 19:11Это полноценное ООП с широкой аудиторией разработчиков и массой сфер применения.
Меня здорово покоробило от такого заявления, что ООП что-то там нарушает. С++ / Java / C# это языки патологически широкого профиля, на которых можно делать что угодно и как угодно. У них тонны проблем с ненарушением обратной совместимости и прочим. Их пример не показателен.
lieff
11.01.2017 19:19+2Имел счастье работать с nvida компиляторами, вовсе они не лучше. Хотя возражаете вы правильно, ничего там не «прекрасно с обработкой данных и схемами обращения к памяти», у nvidia даже есть специальные документы и статьи по оптимизации работы с памятью. Там все еще сложнее чем с CPU и разброс производительности оптимизированного — не оптимизированного кода может быть гораздо больше.
RomanArzumanyan
11.01.2017 19:25-2Наличие хорошей документации и правильных средств разработки для достижения высокой производительности — это и есть прекрасно. Согласны?
lieff
11.01.2017 19:40+1Согласен, претензий к доке и средствам разработки нет. Я только про то что увы, для GPU доступ к памяти тоже еще как нужно оптимизировать, неважно CUDA это или GLSL\HLSL. Для GPU это даже более актуально, если шейдеры не совсем простые, а работают со структурами данных.
lookid
11.01.2017 18:37Ахаха, лолшто? http://harmful.cat-v.org/software/OO_programming/_pdf/Pitfalls_of_Object_Oriented_Programming_GCAP_09.pdf
ООП убивает кеш и данные приходится тянуть из памяти или из L3. Это недопустимо в тайм-критикал коде, трейдинге, физике, графике. ООП похоронили компиляторы. Сама идея может и норм.RomanArzumanyan
11.01.2017 18:47Вы в точности повторили мой вопрос. Сама идея более чем норм. О ней и шла речь. Есть некие плохие реализации этой идеи, не более того.
lorc
11.01.2017 18:52+3Окей. «Текущие реализации ООП в популярных ЯП нарушают принцип пространственной локальности». Думаю, автору поста стоит сменить формулировку.
RomanArzumanyan
11.01.2017 19:07Уточню — «текущие реализации ООП в популярных ЯП общего назначения». Есть ООП под GPU, там всё в порядке с локальностью.
PsyHaSTe
11.01.2017 21:31+1Не обязательно, языки с GC с поколениями данные кладет как раз-таки рядышком, особенно типа C#, которые позволяют создавать массивы структур, которые физически лежат рядом.
khim
11.01.2017 20:48+2Ну вот какое отношение парадигма программирования имеет к расположению данных в памяти?
Самое прямое.
Инкапсуляция?
Предписывает нам «запаковать» в один объект все его свойства. И не хранить там ничего лишнего. С точки зрения написания кода — здорово. С точки зрения пространственной локальности это качмар: данные с которыми мы оперируем, как правило, представляют собой не всё, что хранится в объекте, а только лишь часть, причём для разных алгоритмов — разную.
Наследование?
Обозначает, что всё, что есть в предке — есть и в потомке. Что приводит к усугублению предыдущей проблемы.
Полиморфизм?
Обозначает, что мы не копируем функциональность, а ссылаемся на неё — и, опять-таки, получаем проблемы с локальностью.RomanArzumanyan
11.01.2017 22:14Спасибо за аргументированный ответ. Давайте разложим по полочкам.
1. Под пространственной локальностью будем понимать следующее: инструкции, выполняющиеся в близкие моменты времени, обращаются к данным с близкими адресами.
2. Инкапсуляция запаковывает в один объект его свойства, но ничего не говорит о расположении данных класса в памяти. Стандарты С и С++ гарантируют нам расположение данных внутри классов и структур. Не знаю, как ситуация обстоит с другими ООП языками — есть ли какие-то гарантии, что данные разных инстансов не будут лежать в близких адресах памяти. Полагаю, что языки с JIT оптимизациями могут и переложить данные.
3. Наследование — ситуация схожая с пред. пунктом. С++ кладёт данные предков и потомков рядом. Что делают другие языки — вопрос. Может быть, данные лежат рядом, а может быть и нет.
4. Полиморфизм накладывает ограничения на время вызова функций и возможности оптимизации со стороны компилятора. Т. е. увеличивает время между выполнением одинаковых инструкций над разными данными в случае подхода AoS (Array of Structures), но не в случае SoA (Structure of Arrays). Так, например, Гауссово размытие, наследующее от простого размытия, будет оперировать одинаковыми инструкциями над разными пикселами в том случае, если в классе изображения пикселы хранятся в массиве. Overhead на вызов виртуального метода будет ничтожен по сравнению со временем применения размытия как такового.
Вы привели частный случай того, как ООП может нарушать принцип пространственной локальности. Несомненно, так оно и есть — всегда можно написать ООП код, который будет его нарушать. Я привёл контрпример (CUDA, C++ AMP, OpenCL), который показывает ложность предпосылки «ООП нарушает пространственную локальность» в общем случае. Подчеркну — то, что я хочу сказать: предпосылка неверна в общем случае.khim
11.01.2017 23:20+1Подчеркну — то, что я хочу сказать: предпосылка неверна в общем случае.
Как раз в общем случае посылка верна. В частных случаях происходит отход от принципов ООП за счёт чего удаётся, во многих случаях, спасти сутацию.
ООП — это AoS, точка. То, что на ООП языках можно реализовать и SoA (как все ваши примеры и делают) — это, собственно, ни о чём не говорит. Да, можно. Но это происходит за счёт отказа от ООП.
Overhead на вызов виртуального метода будет ничтожен по сравнению со временем применения размытия как такового. Так, например, Гауссово размытие, наследующее от простого размытия, будет оперировать одинаковыми инструкциями над разными пикселами в том случае, если в классе изображения пикселы хранятся в массиве.
Несомненно. Только вот беда — у вас после этого обьекты уже не соответствуют предметной области, а, во-многом, являются компромиссом между простотой использования и необходимостью сохранить пресловутую «пространственную локальность».
Так что основной тезис статьи «ООП нарушает принцип пространственной локальности» — таки верен. Другое дело, что, как обычно, достаточно отказаться от строгого следования принципам ООП в 10% кода, чтобы получить 90% выигрыша в быстродействии, дальнейшее усложнение себе жизни будет давать всё меньшую и меньшую отдачу.Saffron
12.01.2017 07:28> Но это происходит за счёт отказа от ООП.
Интересно, а паттерн visitor, которые переподвешивает иерархию за действия вместо объектов — это тоже отказ от ООП?khim
12.01.2017 16:26+2А вы на код посмотрите. Там где до появления visitor'а у вас была одна индиректность — теперь их две. А без ООП было вообще нуль.
А дальше — как обычно с ООП: расширяемость, тестируемость и прочее, прочее. Но из «производительность — в жопе» переходим к «производительность — в полной жопе».
P.S. Я не очень понимаю — что вас удивляет. В реальном мире всё — ровно также: перейдите вместо пайки/сварки к соединениям на болтам — получите лучшую ремонтопригодность, но и больший вес, худшую аэродинамичность и прочее, прочее. Почему вас удивляет, что в программировании — эта дилемма тоже есть?
marsermd
12.01.2017 17:01В этом и дело. Варка нужна в местах, требующих высокую прочность, а не везде. Ремонтопригодность нужна почти всегда.
А в самолетах почти все держится на заклепках, что обеспечивает отличную ремонтопригодность) http://sergeydolya.livejournal.com/394740.htmlkhim
12.01.2017 18:48+2Всё правильно. Потому и ООП живёт и будет жить. Меня удивляет не тот факт, что ООП применяется, при всех его недостатках, а то, что некоторые люди, похоже, искренне не понимают — что ООП-подход реально приводит к повышенному расходу ресурсов. Хотя это же очевидно — ну не бывает «серебрянной пули»: если где-то чего-то прибыло, то где-то чего-то убыло…
Saffron
13.01.2017 15:02> А вы на код посмотрите. Там где до появления visitor'а у вас была одна индиректность — теперь их две. А без ООП было вообще нуль.
Ну и кто мешает вам снова сделать индиректнутость и вместо DataHolder сделать класс DataHandle, которые не хранит сам, а умеет обращаться к массиву? И если нужны какие-то операции над массивами — то это уже другой класс DataOps. А ещё операции можно между собой комбинировать, дабы не создавать промежуточных массивов.khim
13.01.2017 15:17Ничто не мешает. Собственно всё сводится к известному афоризму, верному на 99.9%: Любая проблема в мире компьютеров может быть решена добавлением ещё одного уровня идиректности — за исключением излишнего числа этих уровней.
Однако сегодня в полный роста встаёт проблема: все эти техники разрабатывались в другое время и в другом мире. В мире, где память была быстрой, а процессор — медленный все эти индиректности — «ничего не стоили». CDC 6000, к примеру, имел 10 функциональных юнитов каждый из которых мог независимо обращаться к памяти — и она преспокойно обслуживала все 10! И вокруг них построили кучу парадигм и техник.
А в современном мире… Pointer chasing is just about the most expensive thing you can do on modern CPU's. А во всех учебных заведениях по-прежнему пропогандируются подходы, рассчитанные на тот, старый мир, которого уже давно нету!
В этом вся беда: мир изменился, а подходы к программированию — остались старыми…
ElectroGuard
11.01.2017 19:43-4Вместо минусов лучше бы ответили мотивировано. Или правда глаза колет? :)


SBKarr
11.01.2017 20:10+3А скольким упоротым программистам графики подумалось, что там, в самом начале, должно быть 16 мс?

AllexIn
11.01.2017 22:32Почему 16? Потому что это минимальный шаг GetTickCount()? Мне кажется GetTickCount перестали пользоваться лет пять назад уже вообще все. А больше я не припоминаю привязки к 16 мс нигде.
lorc
11.01.2017 23:51Странно что не помните. Это максимальное время рендеринга одного кадра, если мы хотим уложится в 60 FPS.
При чем рендеринга не в приложении, а вообще (т.е. включая композицию и путь до того, что нынче заменило RAMDAC).AllexIn
12.01.2017 00:42Понятно. СПасибо.
Ни в одном месте где приходилось работать никогда 60 FPS не было ориентиром. Видимо поэтому не отложилось в памяти.

jamakasi666
11.01.2017 20:35+2Почти не понимаю асмы но читал, что называется, в захлёб. Вот бы кто нибудь собрал явные примеры хитрых оптимизаций с небольшим разъяснением.
Часто сложно представить как работает мозг у людей который придумывают такие хитрые оптимизации как например Кармак со своим 0x5f3759df.mkarev
11.01.2017 21:07Вот еще занимательная статейка
PS: оптимизация это безусловно полезно, но перед тем как ею заниматься, необходимо провести детальный анализ производительности: профилирование инструментальное(v-tune, xcode instruments,..) и/или ручное (расстановка замеров времени по коду).
И, да — не удаляйте неоптимизированные версии.
Коллеги, занимающиеся портированием на другие архитектуры/наборы инструкций скажут вам спасибо.mkarev
11.01.2017 21:11PS2: Улетная книга по теме: Крис Касперски «Техника оптимизации программ. Эффективное использование памяти (+ CD-ROM)»
Leopotam
11.01.2017 21:08Почитать доку с примерами по ссылке выше: https://habrahabr.ru/company/mailru/blog/319194/#comment_10006994
jamakasi666
11.01.2017 22:18Тут не согласен, там приводится уже очень сильно устаревшее сравнение. Хотя тоже любопытно.
Leopotam
11.01.2017 22:48Да почему устаревшее? Вот буквально сейчас заинлайнил методы с массивом блоков данных при генерации лабиринтов из темплейтов — получил ускорение в 4 раза. C#, unity, те не асм / c / c++, но все-равно DoD дает о себе знать. Количество итераций вызова самого вложенного метода в ООП парадигме — порядка 10к.
PsyHaSTe
11.01.2017 21:35На википедии есть объяснение:
Данная константа равна значению квадратного корня из половины максимально возможного хранимого значения числа в данном формате.
Что касается того, как это придумывается — лично я, конечно, не Кармак, но зачастую придумывается остов алгоритма, который постепенно модифицируется пока не будет проходить все тесты. После этого идет этап оптимизации — выкидываются ненужные шаги, где можно заменяются структуры данных на более простые (например у меня в одном случае хэш-таблицу получилось заменить на массив). А после этого ты хватаешься за голову и пытаешься понять, как все это работает. Через какое-то время понимаешь, насколько все просто, но теряешься в догадках, как ты до такого дошел… Как-то так.jamakasi666
11.01.2017 22:13+1В вашем случае понятно, это ткнул пальцем в небо и удивился. В случае с тем же Кармаком это пипец какие глубокие познания матана и «узких мест» текущей архитектуры и реалий CPU.
У меня по аналогии с вашей ситуацией было такое что надо было понять направление в 2д плоскости в пределах определенных радиусов. По началу городил огород из куч сложных условий а в последствии выкинул почти все переделав на последовательность минимальных проверок. В итоге это оказалось почти в 8 раз быстрее чем оформление проверки направления в каждое конкретное направление по всем условиям. Вроде бы очевидное решение получилось но с другой стороны «в лоб» такое сморозит не удалось сразу.Leopotam
11.01.2017 22:55Ну так на той же википедии указано, что автор не Кармак, он просто хорошо умел «гуглить» эхи с доками.
PsyHaSTe
11.01.2017 21:49-5Честно говоря, статья довольно однобокая. Представлен типичный взгляд современных людей, далеких от IT, но пользующихся его плодами: дескать, современные программисты лентяи, которые одним пальцем тычут в клавиатуру, а за них все собирается с использованием супер-жирных фреймворков, которые с каждым годом все тормознутее и прожорливее.
Про то, что ООП мешает жить, даже комментировать не хочется. То-то всякие hadoop написаны на Java… Хотя о чем речь, если у человека даже С++ компилятор генерирует медленный код…
Не раз убеждался, и до сих пор считаю: то, что на сегодняшних процессорах является оптимизацией, через поколение-два будет замедлять скорость выполнения относительно наивной реализации, через 3-4 поколения будет вообще давать некорректный результат (например как в случае перехода на 64 бита с 32-битными арифметическими хаками). Не говоря о том, что с такими низкоуровневыми деталями реализация сколько-нибудь сложного алгоритма становится задачей непосильной. Нужно отдавать отчет, что у человека есть предел охвата предметной области, и если он будет думать в рамках регистров и кэшей, то он сможет написать сверх-быструю пузырьковую сортировку, но до быстрой он не додумается. Не потому, что мозгов не хватает, а потому что просто нужно подняться по уровням абстракции выше и посмотреть алгоритмически. И уже написав максимально быстрый алгоритм можно его декомпозировать, переписывать на инстринки и все такое, но блин, это движение сверху вниз, когда проблема с производительностью становится очевидной.
В общем, я понимаю, что это перевод, но тут претензия к автору оригинальной статьи: если он хочет пользоваться ПО, которое не падает по первому чиху, разрабатывается не столетиями, а за адекватный срок и при этом отвечает современному UX и которое не стоит миллионы долларов за копию, то ему придется смириться с оверхедом на уровни абстракции, которые делают возможным то, что в его мире за гранью фантазии по цене/качеству.
Да, разработчику желательно знать, как работает память, какие где задержки и во что компилируется код, но только в случае, если это реально необходимо. Всегда нужно искать золотую середину. Пользователь с удовольствием купит ПО, которое ест гигабайт памяти (7$) и которое стоит еще 50$, но экономит этому пользователю 1000 долларов ежемесячно. Но сомнительно, что он позволит себе купить ПО, которое ест для такой же работы 10МБ памяти(0.07$) и стоит 100000$.JediPhilosopher
11.01.2017 22:57+4Автор вроде бы говорит про вполне конкретное приложение — а именно игры.
В играх производительность критична. Начиная от негативных отзывов от пользователей когда игра тормозит, и заканчивая попросту невозможностью ее издать. Например на PS3 в свое время был строгий чеклист, если игра нарушала хоть один пункт — она не допускалась Sony до релиза на платформе, один из пунктов был в частности про FPS, меньше 30 было нельзя вообще никак, и плевать что у вас там ехала абстракция через паттерн. Больше 33мс на кадр (а за это время надо и логику обсчитать, и отрендерить) — идете нафиг. И вот тут как раз начинается увлекательное впихивание невпихуемого, когда чтобы выкроить хотя бы лишнюю микросекнду на обработке каждого из тысячи объектов на сцене в ход шло все, ассемблерные вставки в том числе.
И да, проблемы с размещением данных в памяти, свои собственные хитрые аллокаторы, укладывание данных в кеш процессора (ну на приставках с этим проще так как у тебя всего один вариант железа) — всего этого вполне пришлось хлебнуть тем, кто делал у нас движок.
Короче разработчики разные бывают. И не все могут наплевать на лишние миллисекунды и мегабайты.PsyHaSTe
11.01.2017 23:12-2Начал писать развернутый ответ, но посреди стены текста прилетели минуса в карму, так что отвечу просто, коротко и по существу: я в дисклеймере снизу написал, что я не призываю к «хренак хренак и в продакшн». Лишних миллисекунд не бывает, вопрос tradeoff'а, и на сегодняшний день нет таких приложений для настольных ПК, которые требуется писать ниже чем на С. Контроллеры/embedded — ладно, тут ниша асма есть, но мир настольных приложений давно захватили gcc/msvc и более высокоуровневые. Писать хитрые аллокаторы и управлять кэшем: замечательно, но только после профилирования и точечно, писать всё приложение в таком стиле — обречь своих товарищей на мучительное сопровождение.
lieff
11.01.2017 23:23+1Неочень понял, статья вроде и не призывает писать все на асме, вроде как раз си восновном, c листингами асма, чтобы понимать что компилер натворил. А вот на С\С++ с оптимизациями на интринзиках, асм вставки, вынесенные в асм критические процедуры — этого для «приложений для настольных ПК» сейчас полно.
Собственно почти все крупные проекты такое содержат, за примерами далеко ходить не надо, из проектов хромиума например libyuv просто напичкан интринзиками и вставками; webrtc, skia — это тоже критичные его части с хардкорной оптимизацией. В ffmpeg полно и вставок и выноса целиком в asm, в libvpx тоже. итд итп.PsyHaSTe
11.01.2017 23:33+2Да, как раз заканчивал перечитывать статью. Неправильно понял изначально, что автор имел ввиду.
В таком разрезе сказанное имеет смысл. Особенно учитывая конкретные советы: разбор получившегося ассемблера, учет out of order, кэшей… Тем более, что я не учел, что советы давались с учетом специфики геймдева, на чем, собственно, и погорел. Ну да ладно, регулирование сообщества для того и есть, чтобы давать отрицательную обратную связь в случае вроде этого. Насчет ссылок на ffmpeg и libvpx спасибо, гляну.

NElias
17.01.2017 11:45+1Прошу заметить, DS1 часто проседает до 15 FPS. Наверно этот чеклист существует только в фантазиях фанбоев сони. )) В то же время, DS2 замечательно оптимизирован, и эта оптимизация сделана за счет удаления лишних объектов, а не какого-то лоу-кодинга.
JediPhilosopher
17.01.2017 15:00По-моему первая игра про которую мы узнали что требования TRC к ней оказались ослабленные (ей разрешалось ронять фпс ниже 30) была Skyrim. У нас тогда много возмущались на эту тему, мол, все игры равны но некоторые ровнее. Нам такого не разрешали, и в ход шло все — от упрощения сцен до низкоуровневых оптимизаций.
В 2011 я из геймдева ушел, но вроде тенденция к ослаблению требований продолжилась, банально потому что новые игры требовали все больше и больше ресурсов, и их было в PS3 уже не впихнуть, а отказывать таким проектам Sony не могли себе позволить.
Сами требования в интернете вы не найдете, они все под NDA. Но можете попробовать погуглить по запросу «Sony TRC» и найти какие-то обсуждения. Не от фанбоев )))))) а от реальных разработчиков.

beeruser
19.01.2017 19:06Правила, как известно, существуют для того чтобы их нарушать.
Поэтому можно договориться о послаблении TRC.
>> а не какого-то лоу-кодинга.
На PS3 без «лоу-кодинга» никак (если волнует результат)
http://www.insomniacgames.com/gdc-2008-insomniac-spu-programming/
В топовых студиях куча SPU кода написана на асме.
Просто потому что так проще чем бороться с компилятором С чтобы получить хоть какой-то приемлемый код.
Работая непосредственно с DMA пакетами стараешься придерживаться эффективных паттернов доступа к памяти.
mkarev
11.01.2017 22:58+2Не раз убеждался, и до сих пор считаю: то, что на сегодняшних процессорах является оптимизацией, через поколение-два будет замедлять скорость выполнения относительно наивной реализации, через 3-4 поколения будет вообще давать некорректный результат
Старые добрые игры, летающие на современном железе, с Вами не согласны.PsyHaSTe
11.01.2017 23:23Почти всегда старые игры летают на современном железе, просто потому что они не нагружают его даже на 10%. Прелесть старых игр не в шикарной графике, которая собственно и есть ресурсы ПК, а в геймплее. Master of Orion одна из моих любимых игр, занимает 5МБ на диске и действительно летает на моем ПК. Но фишка старых игр именно в том, что нагружает не железного друга, а серое вещество — интересная дипломатия, глубокие взаимосвязи, большое количество информации, которую не пытаются агрегировать какими-то искусственными приемами.
Поэтому немного нечестно сравнивать игру, которая пусть на неэффективных оптимизациях теряет 20% от возможной производительности, но получает буст от на порядки более мощного железа.
Выше совершенно верно написали про отказ от ООП в 10% кода ради 90% выигрыша, но в статье о том, что «используйте оптимизации правильно» ни слова, наоборот «программист всегда должен...»
novice2001
13.01.2017 11:25+2Не раз убеждался, и до сих пор считаю: то, что на сегодняшних процессорах является оптимизацией, через поколение-два будет замедлять скорость выполнения относительно наивной реализации
Вы действительно считаете, что через поколение-два или три-четыре правильная работа с памятью будет замедлять работу или вообще будет работать некорректно?
При этом такая оптимизация проводится не на уровне ассемблера, а как раз таки на уровне абстракций языка.
Saffron
11.01.2017 21:56Вы явно переоцениваете пределы человеческих возможностей и недооцениваете старательность инженеров, разрабатывающих непостижимые суперскалярные аберрации. Нет никаких шансов узнать, как они устроены внутри — это неконтролируемые чёрные коробки.
Именно поэтому при установке ATLAS приходится больше часта гонять тесты и бенчмарки, чтобы он подобрал себе подходящий под конкретный процессор алгоритм.

Deosis
12.01.2017 10:13Статья очень интересная, но сильно напрягает, что рассуждают об оптимизациях на уровне инструкций и приводят ассемблерный листинг, полученный сборкой в DEBUG режиме.

AndreyDmitriev
12.01.2017 11:14Я занимаюсь разработкой приложений машинного зрения в реальном времени и, честно говоря, до уровня ассемблера мне приходилось «спускаться» последний раз лет этак пятнадцать назад (там надо было сделать быструю медианную фильтрацию). Современные библиотеки машинного зрения достаточно хорошо оптимизированы сами по себе. Плюс современные компиляторы берут львиную часть работы по оптимизации на себя. В принципе тут важно вовремя распознать, где находится «бутылочное горлышко» и вовремя оптимизировать. «Вовремя» означает, что не надо бросаться в ассемблер сразу же — ранняя оптимизация не очень полезна, да и поддерживать оптимизированный код как правило бывает сложнее. Однако понимать, отчего алгоритм проседает в производительности, конечно нужно. Ну, вот к примеру, вращаем мы картинку на 90 градусов — и тут сразу есть два варианта, если решать задачу «в лоб» — последовательно читать и непоследовательно писать, или наоборот. Что будет быстрее? И странно, что выравниванию данных практически не уделено внимания — а это довольно важная область. Ну и многопоточность ещё — современные процессоры многоядерные, это накладывает определённую специфику — бывает проще раскидать не слишком оптимальный алгоритм по нескольким ядрам, нежели упираться в затягивание гаек в пределах одного потока.
Deosis
12.01.2017 11:573 вариант: читать и писать блоками.
Читаем из 16 линий по одному значению и пишем 16 значений в один блок. (float)
Тогда каждый участок памяти будет подгружаться один раз (+ ошибки префетча)lieff
12.01.2017 12:22libyuv так и делает:
while (i >= 8) { TransposeWx8(src, src_stride, dst, dst_stride, width); src += 8 * src_stride; // Go down 8 rows. dst += 8; // Move over 8 columns. i -= 8; }
TransposeWx8 соответственно транспонирует блоки 8x8 и оптимизирована на sse\neon. Это кстати как раз тот случай где на телефонах без оптимизации производительность сильно проседает.
orgkhnargh
12.01.2017 22:58jge @ECF81536; делает переход, если a больше или равно b
Разве не когда b больше или равно a? Условие же задом наперед записано, а переменные в комментарии местами поменять забыли (в оригинальной статье тоже).

AllexIn
Это удивительно полезная и интересная статья, которую я не дочитал. И, вероятно, никогда не дочитаю.
О кэш-промахах сейчас надо думать очень маленькому количеству людей, которые находятся на острие производительности. В большинстве случаев, если вы не работаете над графическим ядром GTA 6 — вам это всё не нужно, потому что вам все равно не дадут достаточно времени для проведения всех нужных оптимизаций кода.
А если вы работаете над GTA 6 — вы это всё и так уже знаете.
azShoo
Если бы не производительность современных игр, в частности GTA 5 (хотя, может в 6ой и правда всё хорошо?) я бы с вами даже согласился.
У меня, лично, складывается ощущение, что этого всего разработчики не знают.
marsermd
На мой взгляд, GTA V вполне здорово оптимизирована.
У меня старый компьютер, который Assassin's Creed 2(2009) тянет всего на 30 фпс на максимальных настройках и GTA V(pc — 2015) на 20 фпс при средне-низких настройках, что я считаю вполне неплохим результатом, учитывая что Dishonored(2012) работает на низких настройках при 15 фпс и ниже.
azShoo
GTA V не самый плохой пример, спору нет. При этом извините, но всё таки 20 фпс при средне-низких настройках — так себе показатель.
Есть ещё более обидный пример: последняя Цивилизация, у которой память течёт так, что через несколько часов игры начинают лагать и виснуть кат-сцены и переход хода. Это при средних настройках, на более чем нормальном железе.
Есть достойно оптимизированный Overwatch, который не блещет 4к графикой но выдает хороший фпс даже на очень слабых машинах.
Есть, например Ведьмак, который оптимизирован весьма неплохо и даёт хорошую картинку и непросаживающийся фпс на среднем железе. При это для стабильного Ultra всё равно нужен домашний космолёт.
Но это, простите, не MMORPG, где, помимо всего прочего, параллельно несколько сотен тел месятся в войне гильдий. Это сингл-плеер игра (в случае овервотча — тимплей матч 6х6), где динамических объектов в зоне видимости пользователя значительно меньше.
Понятие «старый компьютер» тоже довольно относительное. У меня игровой комп собирался 3 года назад в «хорошей» (но не топовой) комплектации. Сейчас это железо, с точки зрения игр, старое. Вы считаете это нормальным? Я — нет.
Я говорю о том, что отвратительная оптимизация игр фактически не оставляет выбора: если ты хочешь играть на ультра-качестве (т.е. видеть всё, что создал разработчик) и с FPS выше 40 (о стабильных 60 вообще молчу) — будь добр каждые 3 года собирать себе печь с двумя видеокартами и топовым процессором.
А теперь давайте попытаемся ответить себе честно, делает ли за эти три года графика в играх настолько сильный прирост, что бы требовать производительность на 40% выше?
Я вот считаю, что нет.
Мне, лично, кажется что причина значительно проще — в отношении разработчиков к используемым ресурсам. «А, да ладно, докупят ещё одну видяху, есличо».
kumbr_87
20 фпс при средненизких настройках в игре 2015 года в то время как игра 2012 года выдает на низких 15 фпс это отличный показатель. Хотя в любом случае оценивать вот так вот две абсолютно разных игры некорректно от слова совсем. Более того что значит средненизкие настройки, низкие настройки, как вы вот так просто взяли и с бухты барахты оценили что это так себе показатель? может быть средненизкие настройки гта выводят на экран 10 млн полигонов в каждом кадре в то время как в дисхонореде на низких выводится 20к полигонов на экране? вы же не знаете что значит ползунок «низкие» или «средненизкие» и т.д.
Опять же вы так рассуждаете про овервотч и сравниваете его с ММОРПГ просто вот раз и все, наглазок прикинули это сложнее, это проще, вот только прикинуть что динамичный шутер не менее требователен к сети например чем ммо вы не прикинули.
И про печь с топовым ЦПУ и двумя видеокартами вы снова промахнулись. Сейчас зачастую производительность игр не сильно зависит от цпу, само собой если у вас цпу не какой нибудь coreduo 10тилетней давности, даже древний i7 920 тянет все отлично при наличии какой нибудь карточки вида 970 или 1060 которые кстати не такие уж и печи, порядка 150 ватт, если не меньше. в FHD вполне дают жара у высоких-ульта настройках
Судя по всему что вы написали вы не видели этого прироста, просто к слову, сравните скриншоты хотяб battlefield 4 который вышел в 2013 году и battlefield 1 который вышел в 2016 году, чтобы оценить тот самый прирост, или например Call of Duty: Infinite Warfare 2016 года и Call of Duty: Ghosts 2013 года.
Оценивать в 4к сейчас смысла нет потому что 4к сугубо математически при тех же параметрах обрабатывает в 4 раза больше информации нежели в FHD, если это не тупой апскейл. И при всем этом здравый разум мне подсказывает что мониторы 4к есть мало у кого на данный момент так что оценивать это еще рано.
Ну и последнее фи по поводу
зачастую проблема не в самих разработчиках как таковых — тех кто пишет код а в том времени которое им предоставлено, а в современном бизнесе, который оценивает сколько получит компания если ее игра будет тупить на ПК трехлетней давности, без траты кучи времени на оптимизацию. Раз время не тратят значит результат устраивает большинство.
azShoo
Про «средне-низкие» настройки, количество полигонов и прочие истории вы, естественно, правы.
Это всё вполне себе гадание на кофейной гуще и субьективные ощущение, не претендующие на абсолютную истину.
По поводу овервотч, я, к слову, его скорее хвалил в плане оптимизации. Но, согласитесь, требования к динамичному шутеру 6х6 значительно ниже, чем требования к динамичному шутеру 200х200 (условный планетсайд). Просто объем динамики немного другой.
Понятно, что количество игроков — далеко не единственный фактор, который повышает «прожорливость» игры. Факторов много, никто и не спорит.
По поводу печей и ЦПУ: не являюсь экспертом, однако по моим наблюдениям всё зависит от движка. Например последняя мморпг в которую играл, Guildwars2, оказалась в большей степени зависимой от CPU, нежели от GPU. Т.е. замена GPU с относительно старой на топовую почти не дала прироста производительности, а замена проца — дала.
По поводу баттлфиллдов — играл и в то, и в другое. Разница в картинке конечно есть, правда в большинстве своём за счёт пагубного консольного размыливания. Тем не менее, как уже говорил — темпы роста «прожорливости» игр быстро опережают рост качества этих игр.
Что же до «виноваты не разработчики, виноваты менеджеры» — я вполне допускаю, что дело даже в пресловутом «всем выгодно, что бы новое железо покупали».
И не в коем случае не пытаюсь выставить разработчиков некими злыми гениями, вшивающими в глубины графического движка инфинит лупы и майнинг биткоинов, лишь бы мой несчастный ПК грелся и страдал пытаясь запустить их очередное поделие.
Другое дело, что и в просветленных джедаев, готовых писать совершенный и производительный код, но вынужденных говнокодить из-за плохих менеджеров я тоже не очень верю.
Вероятнее, причина и в том, и в другом. Компаниям не выгодно тратить _бешенное_ количество денег на излишнюю оптимизацию, а многие разработчики пренебрегают использовать техники, которые позволили бы им писать более производительный код.
И несмотря на то, что они вполне могут пренебрегать этим по самым разным причинам, одна из возможных причин — банальное незнание, как сделать лучше не увеличив при этом в разы стоимость разработки.
Поэтому я и не согласился с исходным комментарием «те, кто пишет эти движки и так прекрасно знают, как писать».
kumbr_87
Я играл не на консоли, а на ПК в BF, про графику на консолях вобще отдельный разговор, особенно «порадовала» PS4Pro которая как заверяет производитель тянет 4к при том что производительность поднялась только в 2 раза относительно PS4 (и то с морей оптимизаций, упрощений и забивания на кучу реальной информации), а для 4к требуется в 4 раза больше производительность чем для FHD, который к слову тоже в PS4 был не везде честный, так что да, в приставках сплошной апскейл (растягивание картинки), там можно даже не обсуждать, но это в свою очередь очевидное решение когда покупается приставка с железом за 300-400 баксов в то время как для ПК одна видеокарта стоит не меньше.
По поводу разработчиков — реально зачастую так и есть. Сейчас бизнес заинтересован в быстром выпуске продуктов и допиливании их уже после релиза. Достаточно взглянуть на майкрософт, да на самом деле на каждом шагу релиз а потом куча патчей.
marsermd
Достойно оптимизированный овервотч на моем компе выдает нестабильные 20 фпс на самых низких настройках и уполовиненном разрешении. Простите, но вы предвзяты)
И да, при этом я считаю, что овервотч действительно достойно оптимизирован.
beeruser
>> но всё таки 20 фпс при средне-низких настройках
Что у вас за калькулятор?
GTA5 без проблем идёт в 30fps на железе 2006г
https://www.youtube.com/watch?v=y-mXmsDoks8
GPU PS3 <200GFlops
Сейчас даже мобильники быстрее
marsermd
Для моих ежедневных нужд хватает. Симуляцию физики жидкости самописную выдерживает , хоть и на низких fps.
И нет, мобильники не быстрее. Если только на синтетических тестах. Графику такого уровня они в принципе не потянули бы. И не в последнюю очередь из-за overdraw, который как раз таки является измерением производительности в чистом виде, т.к. растеризация отлично параллелится.
beeruser
>> Графику такого уровня они в принципе не потянули бы.
Без особых проблем. Вот анриловская демка, например. Вряд ли она сильно нагружает GPU.
https://www.youtube.com/watch?v=rNCs89ynZ2w
Посмотрите спеки Adreno 530 — там raw преимущество 1.5-2X по сравнению с пастгеном
Дело в том, что разработчики мобильных игр ориентируются на уровень дна, чтобы увеличить аудиторию. Да и перегружать GPU чтобы за полчаса высадить зарядку тоже не круто.
>> И не в последнюю очередь из-за overdraw
WAT? Мобильные чипы, как правило, имеют поддержку TBR/TBDR. В последнем случае overdraw равен нулю.
marsermd
Я знаком с этим видео. Не поймите меня неправильно, демка прекрасная!
Но это indoor сцена, что позволяет не особо задумываться даже о полигонаже. Прозрачные объекты практически отсутствуют, так что и overdraw около нуля. И вместо qubemap используются ScreenSpaceReflections, которые подходят только для поверхностей типа пола — т.е. поверхностей, на которые взгляд почти никогда не падает под прямым углом. Сравните, например, зеркала с зеркалами из оригинала — и поймете о чем я. А из этого и следует, я полагаю, простое и линейное передвижение камеры — при повороте к стене ничего красивого мы не увидим, а будут только заметны неприятные артефакты.
Ну и да, освещение конечно запеченное на 100%. Так что это хорошго оптимизированная демка, которую тяжело сравнивать по масштабам с GTA.
Красиво? Да.
Adreno 530 безусловно мощный для мобильных gpu, но я сомневаюсь, что он может тягаться даже с моим калькулятором. Впрочем, конкретными тестами подтвердить не могу. Если у вас есть доступ к такому девайсу, можем сбацать бенчмарк.
orcy
> О кэш-промахах сейчас надо думать очень маленькому количеству людей, которые находятся на острие производительности
Да, широкого практического применения как-то не видно. Я могу представить например когда создается алгоритм обработки данных (например уменьшения изображения с фильтрацией) — тогда у программиста есть смысл и использовать ассемблер и думать о том как лучше располагать данные относительно кэшей процессора. Когда же идет программирование какой-то логики или например UI, то понимать где у вас какие операции в какой кэш попадают или нет — такое ни на одну голову не налезет.
Zverienish
Как раз есть широкое применение. Сейчас лопатятся очень огромное количество данных. И человек, который не разбирается в этой теме, выберет неправильный алгоритм обработки данных, что может дать заметную регрессию в скорости (в разы и порядки), при том даже без всяких оптимизаций.
kumbr_87
Опять же это зависит от задачи, если вы делаете обычный калькулятор для windows вы будете думать о том чтобы загрузить в кэш данные зная что ваш калькулятор будет только складывать, умножать, делить и вычитать? Здравый смысл подсказывает что не будете. Или если вы будете писать мп3 проигрыватель для ПК… снова вряд-ли вы будете думать об этом. А вот если вы будете писать какой нибудь софт для 3д рендеринга сцены с сотней миллионов полигонов то да, пожалуй там вам уже надо будет задуматься над оптимизациями всерьез и надолго
playermet
Я бы предпочел чтобы используемый мной проигрыватель был оптимизирован. Да, есть программы которые сами по себе не претендующие на максимальные доступные ресурсы, но как раз из-за их непрожорливости их привыкли запускать одновременно с другими непрожорливыми программами.
У большинства пользователей возникает момент когда кроме основного рабочего приложения одновременно открыт браузер, аудио-плеер, файловый менеджер, возможно антивирус, возможно дропбокс, и еще несколько утилит в трее. Даже если по одному они легкие, то все вместе они могут достигнуть неподьемной тяжести для железа. И пользователь предпочтет заменить что-нибудь на более легковесную альтернативу, а не ограничивать себя в числе запущенных приложений.
kumbr_87
На секундочку, у меня зачастую открыто несколько разных браузеров, при этом в одном из них часто больше 30 вкладок включая активно использующие флеш, попутно пару консолей, все это приправлено виртуальной машиной, фотошопом, иногда трассировщиком плат, повершелом, клиентами рдп и вы не поверите но винамп или какая нибудь яндекс музыка не подает признаков нехватки ресурсов.
А еще помню в студенческие времена я работал на ноутбуке с Core2Duo 1.6 Ггц, на котором нанеделю запустил рендеринг и параллельно играл в battlefield 1942.
Ради интереса озвучьте характеристики ПК на котором тормозит связка проигрыватель+антивирус+дропбокс+несколько утилит в трее. Я ведь не просто так справшиваю — прошли те времена когда в требованиях к играм например писали что если вы хотите слушать в игре музыку то потребуется комп помощнее, сейчас не времена пентиум 1-2 и проигрыватель съедает от силы пару процентов от ресурсов ЦПУ. Чтобы быть уверенным в своей правоте даже запустил Windows Media Player, нагрузка колеблется в районе 0-2% общая и 0% у плеера, так что да — если бы я был разработчиком и мой проигрыватель кушал от силы 1-2% от цпу я бы не парился над его оптимизацией. Разве что мне не пришлось бы делать так чтоб он работал 50 часов на мобильном телефоне средней паршивости.
playermet
Я рад что у вас есть печь которая одновременно тянет все что вы перечислили.
Именно так и поступили разработчики большинства плееров, поэтому я отправил их в корзину, ибо держать мою библиотеку музыки они не могут (некоторые даже просто вылетали в попытке ее загрузить), а каждый раз искать папочку и загружать ее в плейлист я не хочу. Да и зачем, если есть плеер который легко справляется с этой задачей. Как видите у каждого свои индивидуальные потребности, а потому если что-то устраивает конкретно вас — не означает что это устраивает кого-то другого.
kumbr_87
Эта так называемая печ всего лишь 4 ядра 2.6Ггц года так 2009го выпуска. Ничего выдающегося. Ваша проблема надуманна. Если бы у вас в процессе игры было сожрано 95% ресурсов и лагал проигрыватель то у вас и игра лагала бы как незнамо что, сказки не рассказывайте тут.
orcy
Приходилось ли вам отлаживать проблемы производительности на уровне попадания данных в кэш CPU? Если было, расскажите, я думаю будет очень интересно. Я слышал только раз байку от яндекса где проблемы с кэшом CPU отражались на воспроизведении видео у них в браузере.
Zverienish
Вот банальный пример того, что не правильная работа с памятью сильно деградирует скорость (в данном случае в 3-4 раза на моем компьютере). А всего то меняется порядок обработки данных и нарваться на такое в реальных задачах можно без проблем.
kumbr_87
При чем здесь приходилось мне или нет? Я не разработчик, но это очевидно. Если вам надо с большой скоростью производить постоянно операции, например, над одним и тем же сравнительно небольшим объемом данных, где лучше его хранить, в кэше или в оперативке или на диске?
Или личный пример из жизни когда оптимизация в десятки раз ускорила бы работу, но делать ее смысла не было — задача в институте — сделать копию исходного файла заменив некоторые элементы (размер элемента 1 байт) на другие, объем файла 100 мегабайт.
Самый простой вариант не думая — считать элемент, проверить, записать в новый файл, и так пока не обработаем весь файл.
Очевидно что вызывать операцию чтения для чтения одного байта неразумно, зная что за одну операцию можно считать 4кБ т.е. 4096 элементов. Программу можно ускорить на три порядка, т.к. на лицо узкое место, но зачем если выполнить условие задачи можно не парясь по поводу скорости?
orcy
> При чем здесь приходилось мне или нет? Я не разработчик, но это очевидно
Я вроде не у вас спрашивал, я согласен с вашим комментарием выше.
kumbr_87
Придется замультипостить, не сразу вспомнил пример из работы — NUMA. Возможно вы слышали что многопроцессорные системы используют такую штуку. Если вкратце то каждый процессор имеет доступ ко всему объему памяти, но он значительно быстрее работает со своей памятью, а к памяти другого процессора ему приходится обращаться используя NUMA что происходит значительно медленнее. Таким образом если вы например разрабатываете гипервизор то вы должны предусмотреть в нем корректное использование NUMA, дабы гипервизор старался хранить виртуальную машину исполняемую на первом процессоре в памяти принадлежащей этому процессору.
А еще внезапно можно столкнуться с неожиданными вещами. Нарпимер можно подумать что раз в сервере 2 процессора и 12 слотов памяти то каждый процессор является владельцем 6-ти плашек памяти и виртуальную машину которая занимает 5 плашек памяти можно разместить одинаково эффективно на любом процессоре. На практике же можно взять замечательный сервер Dell R530 и с удивлением обнаружить что один процессор является владельцем 8 плашек памяти а другой процессор владельцем оставшихся 4-х. В итоге большую виртуальную машину эффективней будет разместить на конкретном процессоре — владельце 8-ми плашек памяти. Для недоверчивых — ссылка на документацию по серверу, смотреть страницу 52.