
 Как было понятно из прошлой статьи “Четыре порока обслуживания”, мы активно внедряем ITSM подходы в нашей компании. Сегодня хотелось бы поговорить о том, с чего обычно начинается внедрение ITSM в компании — о каталоге услуг.
Как было понятно из прошлой статьи “Четыре порока обслуживания”, мы активно внедряем ITSM подходы в нашей компании. Сегодня хотелось бы поговорить о том, с чего обычно начинается внедрение ITSM в компании — о каталоге услуг.Выделение услуг оказалось не совсем простой задачей и мы столкнулись с массой сложностей:
- Можно принимать за ИТ-услугу программный комплекс или нет?
- Как выделить единого ответственного, если услуга составная и поддерживается двумя программными комплексами?
- Как определять по какой услуге зарегистрировать инцидент, если рухнула ИТ-инфраструктура в целом и почти все услуги не предоставляются.
Вот каких принципов мы придерживаемся при выделении любой услуги:
- Любая услуга должна иметь единого ответственного, который полностью отвечает за ее качество (своевременное устранение инцидентов, доступность и т.д.)
- Название и описание услуги должны быть понятны конечному потребителю (внутреннему клиенту) и при этом услуга должна предоставлять понятную ценность.
- Действующая услуга должна поддерживать как минимум один бизнес-процесс.
Давайте разберем эти принципы немного подробнее и поймем, как они помогут нам правильно выделять услуги. Да! Сразу хочу предупредить, что это наши принципы и мы не настаиваем на их применимости во всех организациях. Я лично видел несколько каталогов услуг, которые не подчиняются данным принципам.
Любая услуга должна иметь единого ответственного, который полностью отвечает за ее качество
Логически вроде все понятно. Если не будет единого ответственного, то не исключена проблема потери ответственности и последующий пинг-понг в устранении инцидентов, про который я писал в прошлой статье.
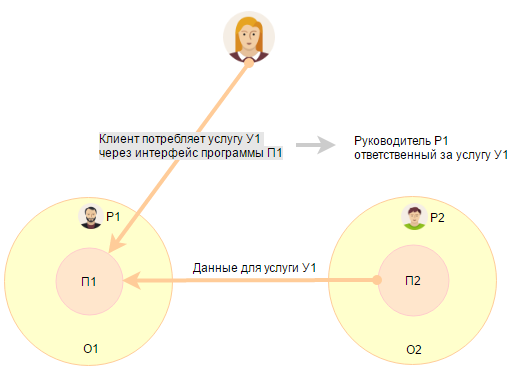
Но как определить ответственного за составную услугу. Например, есть услуга У1, суть которой в предоставлении интерфейса к определенному набору данных. Есть программное обеспечение П1, которое разрабатывает отдел О1. Программное обеспечение П1 только отображает данные, предоставляемые в рамках услуги У1, для всех сотрудников компании. Все данные для программного обеспечения П1 предоставляет программное обеспечение П2, которое разрабатывает отдел О2.
Кто является единым ответственным за услугу У1?
Мы для себя решили, что у нас действует интерфейсный принцип определения ответственности.
Что это значит?
Интерфейсный принцип определения ответственности
Ответственный за услугу = ответственному за приложение, в котором внутренний клиент потребляет услугу.
Почему? Потому что для клиента не должна быть понятна внутренняя архитектура услуги. Клиент потребляет услугу У1, используя интерфейс программы П1 и если с услугой что-то не так, то будет страдать имидж сотрудника, ответственного за программу П1 (имидж программы П1). И тут уже не важно, что 80% проблем с данными в программе П1 связаны с тем, что программа П2 плохо выгружает данные.
Ответственность за услугу на том, кто отвечает за конечное представление данных и его задача наладить взаимодействие с ответственным за приложение П2 так, чтобы воспринимаемое качество его услуги не страдало.
Название услуги должно быть понятно конечному потребителю и отражать понятную клиенту ценность
С первой частью все должно быть понятно. С клиентом нужно общаться на понятном ему языке, в общем. А в частности, называть услуги так, как они будут понятны клиенту.
Не надо использовать в названиях услуг имена протоколов передачи данных и тому подобные технические термины.
Например, вместо услуги “Передача сообщений по протоколу XMPP ” лучше использовать “Сервис передачи мгновенных сообщений”
Однажды я открыл методичку по физическому практикуму и во втором абзаце прочел следующее:
“Инжектированные в базу дырки должны диффундировать в направлении коллектора”
Надо быть проще и тогда будет понятнее.
Из названия услуги клиенту должна быть понятна ценность. Например, услуга “Автоматизация кассовых операций” несет понятную клиенту ценность. А услуга “Сеть передачи данных” нет. Не понятно в чем ценность такой услуги для обычного рядового пользователя. Зачем ему передавать данные !? Какую ценность он получит !?
ITIL достаточно строго определяет понятие ценности:
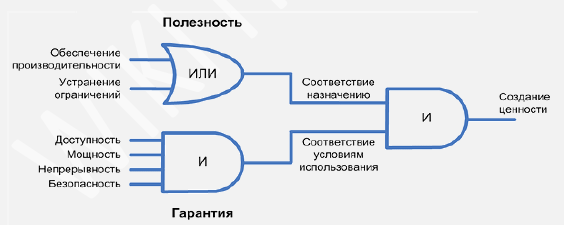
Услуга “Автоматизация кассовых операций” обеспечивает производительность, услуга “Прием заявок на сайте” устраняет ограничения (необходимость физически присутствовать в торговой точке). Услуга “Сеть передачи данных” не понятна рядовому пользователю и поэтому ценности для него не несет. Но несет ценность для ИТ-специалиста, который эту ценность понимает.
Данный принцип уберегает нас от внесения в каталог услуг того, что там быть не должно: внутренних услуг (таких, например, как ЛВС, виртуальные сервера и т.п.)
Недавно зашел на сайт nalog.ru и увидел, что чтобы получить налоговый вычет нужно потребить услугу “Заполнить справку 3НДФЛ” такая услуга не несет ценность. Во-первых 3НДФЛ термин бухгалтерский и непонятный, во-вторых совершенно неясно в чем ценность услуги. А вот услуга “Вернуть 13% от суммы медицинских расходов” несла бы ценность.
Действующая услуга должна поддерживать как минимум один бизнес-процесс
Опять же, все логично. Если услуга не поддерживает бизнес-процесс, то она бизнесу не нужна. И в каталоге услуг ей не место.
Именно этот принцип навел нас на мысль о том, что программный комплекс в самом общем случае нельзя принимать за ИТ-услугу. Программный комплекс может быть заменен другим программным комплексом, при этом услуга остается неизменной. Например, услуга “Телефония” поддерживает бизнес-процессы в call-центре. При замене одного программно-аппаратного комплекса ip-телефонии другим, услуга не должна меняться. Поэтому, услуги “IP-телефония Oktell” у нас нет.
Этот же принцип помогает нам понять, когда в одном и том же программном обеспечении следует выделить различные ИТ-услуги.
Если различные логические модули одного приложения поддерживают различные бизнес-процессы, то и услуги должны быть разными.
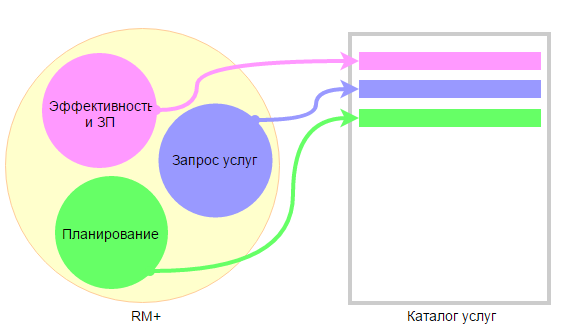
Например, есть приложение RM+, которое реализует различные аспекты управления компанией: Расчет эффективности и начисление ЗП, Планирование, Запрос услуг (Service Desk) и т.д.
Различные модули приложения RM+ поддерживают разные бизнес-процессы компании. Поэтому и услуги разные.
С другой стороны, есть сервис электронной почты, который тоже поддерживает самые различные бизнес-процессы компании, но при этом в сервисе нельзя выделить логические модули, которые бы поддерживали различные бизнес-процессы. Всем бизнес-процессом нужна одна и та же функциональность отправки электронных писем.
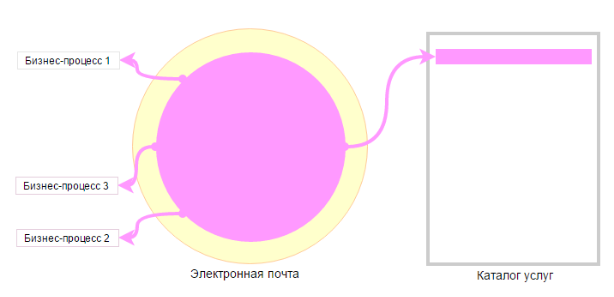
Поэтому в данном случае, услуга у нас одна — “Электронная почта”.
Есть еще один 4-ый принцип, про который явно не написал в начале статьи.
Если рухнул кусок инфраструктуры, то инциденты нужно заводить по тем услугам, которые клиент не может потребить в текущий момент.
Разберем на примере, что это значит.
Допустим клиент потребляет три услуги: Услуга 1, Услуга 2, Услуга 3. Все три услуги напрямую зависят от внутренней услуги: “Сеть передача данных” (данной услуги нет в каталоге услуг пользователя).
Допустим, что-то происходит с корневым свитчом. Внутренняя услуга “Сеть передачи данных” перестает предоставляться. Вслед за ней перестают предоставляться услуги из каталога услуг: Услуга 1, Услуга 2, Услуга 3.
Конечные клиенты ничего не знают об Услуге “Сеть передачи данных”. Все три услуги из каталога услуг в текущий момент не работают. По какой услуге Service Desk должен завести инцидент от конечного клиента, по какой услуге должны примениться SLA-нормы устранения инцидента и т.д.?
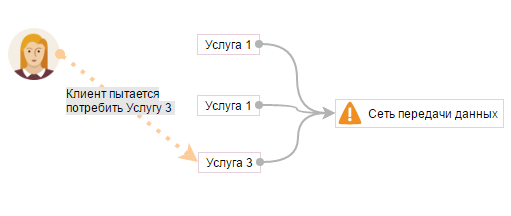
Наш ответ: По той, которую прямо сейчас хочет, но не может потребить клиент и по внутренней, про которую клиент ничего не знает. В данном случае по услугам: “Услуга 3” и внутренней услуге “Сеть передачи данных”. Если остальные услуги клиента не работают, но он и не пытается их использовать, то по ним инциденты можно не заводить.
Это все, чем хотелось бы поделиться в рамках данной статьи. Надеюсь, вам понравилось. Спасибо!
Немного подарков

Скидка в 20% на плагин Service Desk, который поможет оказывать услуги согласно ITSM-подходу в вашей компании, а также реализует много других полезных вещей.
Скидка действует в течение 3 недель.
Наши плагины для Redmine используются по всему миру и славятся своей гибкостью и низкой стоимостью.
Поделиться с друзьями
Комментарии (14)

Rigiditas
25.01.2017 16:47+1Опять же, все логично. Если услуга не поддерживает бизнес-процесс, то она бизнесу не нужна. И в каталоге услуг ей не место.
немного поспорил бы.
Как известно, каталог услуг состоит из двух ключевых элементов — Каталог Услуг для Бизнеса и Технический Каталог Услуг. Так вот, в каталог услуг нужно вносить и то, и другое, а Бизнесу показывать только интересующую его часть(разграничение прав доступа, отличный от общего каталога интерфейс и т.д.).
В такой каталог вносятся как основные услуги(которые видны Бизнесу), так и вспомогательные(без чего услугане сможет функционировать). Помимо этого в каталог услуг так же вносятся дополняющие услуги(делающая услугу более привлекательной для Заказчика).
Поэтому если речь идёт конкретно о Каталоге Услуг для Бизнеса, то не совсем корректно называть его Каталогом Услуг.
По той, которую прямо сейчас хочет, но не может потребить клиент и по внутренней, про которую клиент ничего не знает. В данном случае по услугам: “Услуга 3” и внутренней услуге “Сеть передачи данных”.
Опять поспорю. Изначально инцидент действительно должен заводиться на услугу, видную Бизнес-Пользователям. Однако на первой линии поддержки в рамках диагностики инцидента он должен быть переназначен на конкретную услугу, в которой произошёл сбой. зачастую квалификации ПЛП не достаточно и это происходит на Второй Линии, но это мало меняет дело.
Пойду перечитаю ваши предыдущие статьи, но сложилось ощущение, что начать стоило с построения CMS(или хотя бы CMDB), тогда бы не возникало вопросов, приведённых в заголовке статьи.
ikormachev
Внедрение ITSM в компании нужно начинать не с определения каталога услуг, а с ответа на вопрос: «для чего нашей компании ITSM?». После честного ответа на этот вопрос все остальные вещи структурируются сами-собой.
Лично я использую ITSM для контроля двух аспектов работы ИТ-отдела:
1) Какой уровень сервиса получает компания от ИТ.
2) Сколько компания тратит на ИТ и куда уходят эти деньги.
По теме статьи:
1) ИТ-сервисы разделяются на пользовательские и на инфраструктурные. Естественно, пользовательские сервисы опираются на инфраструктурные и эта связь должна быть определена — она помогает при локализации инцидентов, а также нужна для расчета итоговой доступности пользовательских сервисов.
2) В случае сбоя инфраструктурного сервиса, достаточно завести заявку по инфраструктурному сервису. К этой заявке уже можно привязать все обращения пользователей. Нет никакого смысла насиловать свой хелпдеск необходимостью заводить 40 тикетов по каждому пользовательскому сервису из-за того, что в серверной отключили электроснабжение.
3) Стоимость владения нужно считать отдельно по инфраструктурным и пользовательским сервисам.
4) Доступность сервиса для пользователей не составляет труда вычислить зная доступности инфраструктурных сервисов и количество изолированных сбоев пользовательских сервисов, не связанных с инфраструктурными.
mtivkov
Поддерживаю.
Но всё же информацию какие именно пользовательские сервисы пострадали и насколько сильно, все равно хорошо бы иметь в системе управления инцидентами, чтобы потом проще было получать отчет о доступности пользовательских сервисов.
Не всегда есть жесткая связь между инфр. и пользовательскими сервисами.
paranoya_prod
Пользователь ничего не знает про инфраструктуру, у него просто 1С перестала работать. И он хочет знать, когда 1С заработает. Поэтому он позвонить и спросит на счёт своего тикета на 1С, у Вас же его нет, потому как у Вас есть тикет на «отключение электроэнергии».
Другими словами, когда звонит юзер и сообщает о том, что у него не работает 1С, ещё никто не знает, что в серверной отключили электричество. И регистрировать надо именно этот тикет «1С не работает», после чего необходимо начать расследование причин того, почему не работает 1С. Если расследование приводит к выводу о том, что в серверной нет электричества, то дальнейшие действия зависят от построения процесса обработки и регистрации заявок на инфраструктурные услуги — завести внутреннюю заявку отдельно или привязать к исходной некую подзаявку или сделать что-то еще.
При этом продолжать регистрировать все поступающие заявки по не работающей 1С, не отправленной почте, не загруженных котиках. Потому что не зарегистрированные заявки плохо сказываются на ощущениях пользователей об уровне оказываемого сервиса.
mtivkov
А вот это не хорошо. Мониторинг нужно подтягивать на уровень повыше, чтобы о таких вещах дежурной смене становилось известно ещё до звонков юзеров.
paranoya_prod
Это уже другой вопрос и подтягивать нужно не только мониторинг, но Service delivery, вкупе с планированием — в правильной серверной стоит, как минимум, ИБП и как максимум — дизель в дизельной. :)
И на отключение основного питания автоматически создаётся внутренний тикет, который сразу назначается нужному человеку или группе.
tdvsdv
Это достаточно философское высказывание, с которым сложно спорить. Можно, например, сказать, что нужно начинать не с ответа на вопрос «для чего нашей компании ITSM?», а с ответа на вопрос: «Какие проблемы с обслуживанием есть у нас в ИТ-отделе?»
Ряд книг рекомендует начинать именно с каталога услуг, я солидарен с авторами этих книг.
Не совсем понятно, что тут понимается под обращением пользователя с технической точки зрения. Будет допустим тикет на инцидент один. Service Desk тогда будет насиловаться заведение обращений пользователей, они же (обращения) сами по себе в системе не появятся!?
Фиксировать обращения пользователей в виде обращений или инцидентов надо! Это явно рекомендует ITIL.
ikormachev
Все правильно, но 1 обращение = 1 заявка, а не 1 обращение = 30 заявок по всем затронутым сервисам.
tdvsdv
Так я нигде вроде такого в статье и не писал. Какую услугу в текущий момент не может потребить пользователей, по той и надо заводить инцидент.
Собственно, это и отражено на картинке в статье
ikormachev
Давайте конкретный пример разберем:
Звонок пользователя: «у меня ничего не работает».
По какой услуге будете заводить заявку?
tdvsdv
На мой взгляд, нужно выяснить что конкретно не работает и потом заводить инцидент. Если комп не включается, то услуга «Рабочая станция», если какая-то прога, то выяснить какая вот прям сейчас не запускается и по ней заводить.
Какую услугу в текущий момент не может потребить, по той и заводить.
ikormachev
«Почта не получается, из базы выбило, документы не открываются, не могу на принтере распечатать — я же говорю: ничего не работает!» — по какой услуге будете заводить заявку?
paranoya_prod
В таком случае заводится неклассифицируемая первоначально заявка, если она такая первая вообще, если уже были такие случаи, тогда классифицируется так, как фирме ранее определила класс таких заявок. Если-же это в первый раз, то в дальнейшем, следуя внутренним правилам заводится новый класс — «форс-мажорный». При этом, все, что не работает у юзера включается в эту заявку. Это если выпедндриваться, а обычно в таких случаях тикет заводится на услугу «рабочая станция». Потому как даже услуга «почта» зависит от услуги «рабочая станция», не говоря об услуге «хранилище файлов». :)
ikormachev
На самом деле, коректно выставить затронутый сервис мы можем только после того, как устраним инцидент. Процедура устранения инцидента выглядит следующим образом:
1) Регистрируем заявку со слов пользователя («В 1С ничего не работает!!!111ОдинОдинОдин111!!!!»)
2) Разбираемся что могло случиться у пользователя и локализуем причину инцидента.
3) Устраняем предполагаемую причину.
4) Связываемся с пользователем и уточняем, что теперь все работает.
5) Закрываем заявку, проставляем фактически затронутый сервис и в решении указываем причину инцидента и ее решение. В данном случае затронутым сервисом может быть сервис печати (при том что пользователь жаловался на 1С), а решение будет — «из-за зависания сервера печати пользователь не мог распечатать документ из 1С. Перезапустили сервер печати».
Точно также при закрытии заявки она может быть отнесена к инфраструктурным сервисам (рабочая станция, локальная сеть, сервера), если причиной послужили они.
Далее не только легко считать стоимость владения сервисом и его доступность, но и аргументированно вести диалог с руководством об общей адекватности пользователей и/или их технической подкованности и необходимости обучения.