
SAP HANA: как это работает
Основным ядром в SAP HANA является компонент СУБД, позволяющий обрабатывать большие объёмы данных с помощью технологии In-Memory и на базе языкового инструмента SQL. В основе СУБД SAP HANA используется реляционная модель данных, но также существует возможность обращения к данным с помощью «графового» языка запросов WIPE. Гибкость в выборе языка запросов обусловлена архитектурными возможностями SAP HANA и заключается в использовании единого представления данных в In-Memory хранилище. Таким образом, у пользователя есть возможность обращения к данным с помощью различных семантических конструкций, используя при этом единую копию данных в памяти СУБД. Классический подход, принятый в ряде других OpenSource СУБД, отличается от вышеуказанного, потому что подразумевает использование как минимум двух хранилищ данных и разделение способа хранения графовых структур и реляционных таблиц.
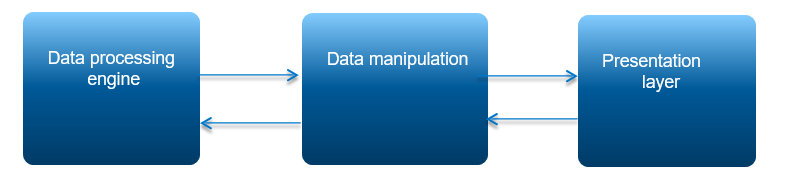
Рисунок 1. Концепция управления данными
На рисунке выше отражена общая схема управления данными в SAP HANA и суть концепции управления с помощью различных языков – в частности, SQL и WIPE. Используя движок Data Processing, можно сформировать на уровне Data Manipulation новый семантический уровень для работы с данными, но при этом будет применена единая копия исходных данных, что существенно повышает возможности платформы SAP HANA для решения задач, где требуется представление информации в виде графовых структур.
Технология In-Memory в СУБД SAP HANA позволяет хранить и обрабатывать данные в памяти, используя уникальные алгоритмы[1], разработанные в компании SAP и на базе платформы Intel x86. Недавно SAP также анонсировала поддержку платформы IBM Power для SAP Hana. Уникальность и высокая скорость обработки запросов к данным заключается в возможности их хранить и выполнять. Они находятся в сжатом виде в памяти RAM. Благодаря разработанному алгоритму обработки данных в SAP HANA удалось реализовать подход Unified Tables, который обеспечивает высокую скорость чтения и записи данных в таблицу поколоночного хранения. Поэтому одним из главных преимуществ SAP HANA является возможность выполнять аналитические запросы сразу на транзакционных данных, которые добавляются в реальном времени. При этом система автоматически берёт на себя обеспечение прозрачного доступа к данным. Таким образом, новые данные в таблице сразу доступны для анализа без предварительной обработки.
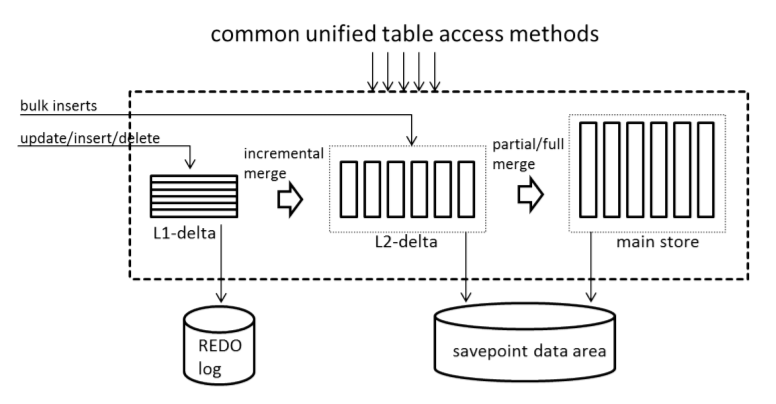
Рисунок 2. Архитектура концепции Unified Table
Архитектурно SAP HANA поддерживает конфигурацию, в рамках которой в составе единой инстанции СУБД используются один и более вычислительных узлов (Scale-out см. Рис.3 и www.hanatutorials.com/p/scale-up-or-scale-out-hana-configuration.html). Такая конфигурация особенно актуальна для задач по обработке больших массивов данных в режиме реального времени. Обработка запроса SQL в SAP HANA происходит одновременно на всём объёме данных вне зависимости от месторасположения данных.
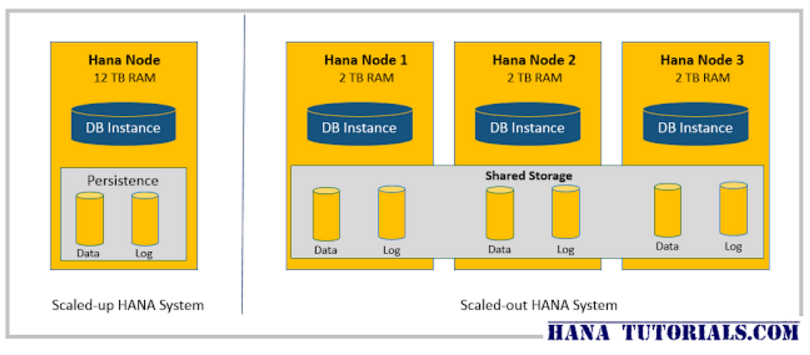
Рисунок 3. Конфигурация Scale-out HANA
В отличие от Hadoop Spark и Hadoop Hive, платформа SAP HANA позволяет реализовать более быстрый и простой механизм загрузки данных и выполнения запросов для большого объёма структурированных данных с помощью языка SQL.
При обработке больших массивов неструктурированных данных (например, видео или фотоматериалы) рекомендуется использовать возможность интеграции SAP HANA и Hadoop Spark с помощью инструмента HANA Vora, который представляет собой компактный вариант In-Memory СУБД, интегрированной в Hadoop Spark.
Платформа SAP HANA предлагает также использовать разные опции при выборе языка программирования для создания приложений в рамках новой концепции Bring your own language. Встроенный сервер приложений SAP HANA XS advanced позволяет создавать независимые контейнеры приложений на базе языков JavaScript (движок Google V8 и Node.JS), Java (Tomcat Java), Python, Ruby, C++.
Рассмотрим один из примеров из области машинного обучения для задач распознавания и классификации образов на основе базы изображений с помощью Hadoop, а также потоковых данных с помощью компонента SAP HANA Smart Data Streaming (см. Рис.4).
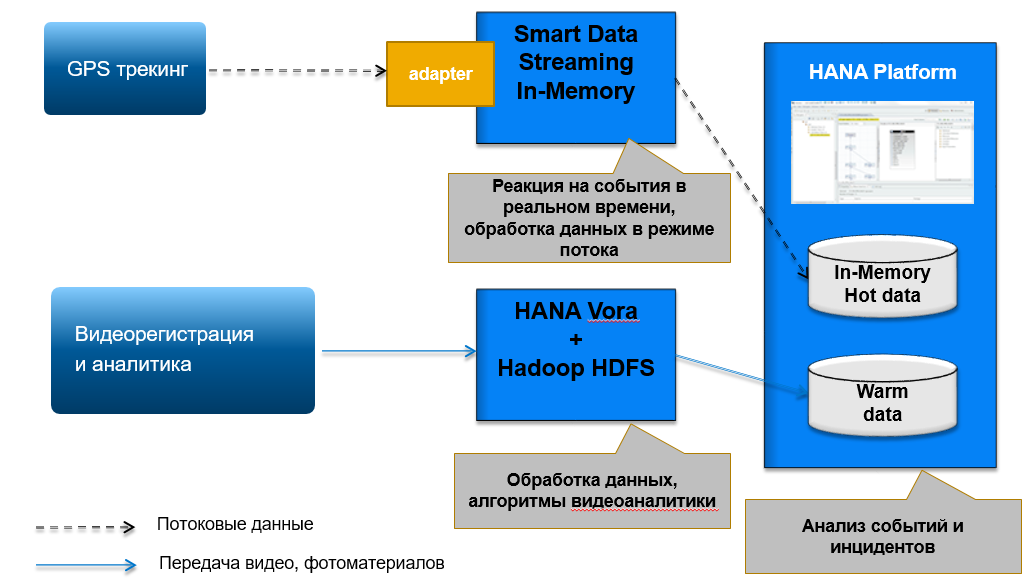
Рисунок 4. Архитектура системы контроля движущихся объектов на базе SAP HANA
При реализации видео алгоритмов в SAP HANA возможно также использовать популярные пакеты Caffe, Theano, Torch, Tensorflow и переносить уже разработанные приложения без изменений в контейнеры на базе HANA XS Advanced или среду Hadoop Spark.
В следующих статьях мы покажем реальные примеры реализации кода для задач машинного обучения на платформе SAP HANA.
Примеры сценариев по использованию SAP HANA для работы с большими данными в системах контроля движущихся объектов:
«Цифровой склад» на базе SAP HANA
Важная задача для крупных дистрибьюторских компаний – это управление погрузкой и разгрузкой товаров, а также их маршрутизацией для формирования заказов и подготовке к отправлению. Своевременное отслеживание товаров и погрузчиков, мониторинг и управление процессом погрузки и разгрузки позволяет оперативно планировать и корректировать планы по подготовке товаров к отправке, а также избежать проблем с простоем товара на складе.
Модель «цифрового склада», построенная на базе SAP HANA и компонента для Smart Data Streaming, помогает собирать информацию о доступности средств погрузки и разгрузки товара, информацию о местонахождении, управлять персоналом с помощью своевременной корректировки плана. Использование специализированных датчиков позволяет собирать информацию о состоянии транспортировочной ленты, рабочих мест персонала и отслеживать статус мест для погрузки и разгрузки товара.
На обычных складах в процессе комплектации заказа возможны ошибки из-за человеческого фактора. Чтобы минимизировать это, в «цифровом складе» используются встроенные возможности SAP HANA по распознаванию специализированных меток в виде QR кодов. Метки позволяют автоматически определять комплектацию заказов и позиции товаров на основе кода заказа и информации о нем из SAP ERP.
Используя SAP HANA и её возможности по анализу информации в режиме реального времени, компании могут построить систему для управления складом в режиме реального времени, которая будет учитывать изменения планов при обработке товаров и формировании заказов, позволит снизить время простоя товара и обеспечить адекватную загрузку персонала.
Дополнительно в рамках SAP HANA с помощью средств прогнозной аналитики можно строить анализ данных на основе статистики о выполненных работах с целью оптимизации процесса работы склада.
«Цифровая парковка» для автомобилей
Одна из важных задач при управлении городским движением – это отслеживание доступных парковочных мест для контроля загрузки городских парковок. Специализированные датчики, которые устанавливаются на парковках, могут отслеживать количество свободных и занятых мест. Cистема контроля на базе SAP HANA Smart Data Streaming позволяет в реальном времени отслеживать состояние датчиков и управлять картой парковочных мест.
Дополнительно, при использовании видеорегистраторов, для соблюдения условий платной парковки возможно собирать информацию о номерах автомобилей и отслеживать статус парковки.
Цифровая система контроля качества доставки товаров
Управление и отслеживание процессом доставки товара является важной задачей для крупных городских сетей доставки. В больших городах, в условиях ограниченного времени доставки и большого количества заказов необходимо своевременно реагировать на изменения в заказах и планировать доставку товаров с учётом меняющихся требований со стороны клиентов.
Интеграция системы SAP HANA Smart Data Streaming помогает обработать несколько миллионов заявок на доставку товаров в минуту и в дальнейшем с помощью специализированных инструментов своевременно корректировать планы по доставке товаров в режиме реального времени.
Источники
[1] Vishal Sikka, Franz Farber, Wolfgang Lehner, Sang Kyun, Thomas Peh, Christof Bornhovd “Ef?cient Transaction Processing in SAP HANA Database – The End of a Column Store Myth”. SIGMOD '12 Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. Pages 731-742
Комментарии (8)

DiglatorR
06.02.2017 21:13Вспоминая 1 февраля, интересно почитать как это все будет восстанавливаться… Как происходит процесс отслеживания реплики особенно в scale out инсталляциях. Слегка прочитав документацию, реализован режим работы master — slave, на сколько быстро происходит переключение таких гигантов?
Какие примерные нагрузки на дисковую подсистему, если просто посчитать, то запуск такой базы должен занимать не меньше 1 часа, даже на СХД c ssd кешем… Или данное решение живет только на All-Flash? Или это будет в следующей статье?SAP
06.02.2017 21:20+1В scaleout системах каждый узел может работать самостоятельно и каждый узел является мастером при обработке транзакции, в документации описывается конфигурация master-slave в которой владелец конфигурации кластера является master, а это один сервер, и он заменяется в случае выхода его из строя на другой рабочий сервер в конфигурации. Вместо термина slave у нас используется worker и standby. В случае worker сервер отвечает и обслуживает запросы, т.е. он может быть точкой входа приложения, а в случае slave сервер не отвечает на запросы, но может быть использован, чтобы заменить сбойный узел.
Для случаев переключения узлов в scaleout предусмотрен режим синхронной и асинхронной репликации, когда данные в реплике доступны сразу же на чтение и запись в случае нештатной ситуации, т.е. выхода из строя master узла владельца реплики.
В случае дисковой системы для HANA не требуется High Enterprise Storage и в том числе Flash системы хранения, вполне подойдёт Mid Range, но только из списка сертифицированных СХД.
Диск используется только в трёх случаях – во время бэкапа, старта БД, начального импорта данных. Во время работы СУБД HANA также используется механизм Redo Log для управления транзакциями и в этом случае рекомендуется использовать для Redo Log SSD или NVMe диски для уменьшения времени отклика, но стоимость такого решения небольшая, так как Redo не требует большого объёма хранилища.
Данные в SAP HANA можно хранить на кластерной файловой системе GPFS, поддерживается также XFS, также есть вариант использования Raw устройств блочного доступа.
Можно ознакомиться с конфигурациями СХД у сертифицированных производителей, который совместно с SAP создали свои конфигурации СХД.

bolonov
07.02.2017 00:24>в составе единой инстанции СУБД
По-русски инстанция означает совсем другое.
А здесь лучше сказать «экземпляр».

mephistopheies
07.02.2017 13:37-1а сколько стоит сап хана?
SAP
07.02.2017 14:47Стоимость может зависеть от каждого конкретного случая. Если у Вас есть определенный кейс, по которому хотели бы получить более подробную информацию — пожалуйста, напишите нам в личные сообщения
dmitry_ch
Хана…
Не для России название!
kail
— Game over, игра окончена.
— Здесь «ХАНА» написано.
— Это одно и то же.
— И это что, обучающая игра?
— А что? Пусть дети сразу и готовятся.
«Бедная Саша»